基于数据能力聚合的高性能数据流通方法及系统与流程
本发明属于数据流通技术领域,具体涉及一种基于数据能力聚合的高性能数据流通方法及系统。
背景技术:
在现有的数据流通方法中,往往是单个的数据供给方对应单个数据需求方,然而在数据供给方和数据需求方的并发能力不同的情况下,系统需要满足高并发、低延时并且能充分利用数据供给方能力的的要求便成了一个问题。在普通的单点对单点的数据配送系统中,数据供给方和数据需求方的并发能力不同的情况下(数据需求方对数据的并发要求往往高于数据供给方),存在以下问题:
1、由于数据供给方和数据需求方的并发能力不同,导致并发能力高的一方(数据需求方)的实际数据并发配送能力受限于数据供给方。
2、普通的数据配送系统的并发能力很难实现随着业务发展而扩展。
3、由于供方为单点,即仅由一个确定的数据供给方为数据需求方提供数据,而一旦该数据供给方不可用,则会直接导致数据配送无法进行。
技术实现要素:
本发明是为了解决上述问题而进行的,目的在于提供一种能够根据业务需求实时选择不同的数据供给方配送数据,数据配送可靠性高,且能够提高数据配送的并发能力的基于数据能力聚合的高性能数据流通方法及系统。
本发明提供了一种基于数据能力聚合的高性能数据流通方法,其特征在于:多个数据供给方为数据需求方供给数据,所述数据需求方请求数据时,根据该次请求的数据量结合数据需求方和数据供给方的并发能力采用数据聚合的方式选择为该次请求提供数据的数据供给方,并向为该次请求提供数据的数据供给方发起请求。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通方法中,还可以具有这样的特征:其中,所述数据需求方请求数据时,首先查询数据缓存模块中是否存储有请求需要的数据,若有,则从所述数据缓存模块中获取数据,若否,则通过数据聚合的方式从数据供给方获得数据,并将从数据供给方请求的数据缓存到所述数据缓存模块中。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通方法中,还可以具有这样的特征:其中,所述数据缓存模块存储数据时采用分布式缓存。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通方法中,还可以具有这样的特征:其中,对所述数据缓存模块缓存的数据设置存储时间,并对到达所述存储时间的缓存的数据进行删除。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通方法中,还可以具有这样的特征:其中,对数据进行缓存时,对源数据的value值进行编码处理后存入所述数据缓存模块。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通方法中,还可以具有这样的特征:其中,所述数据需求方向所述数据供给方请求数据前,通过心跳包的方式确定当前可用的数据供给方。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通方法中,还可以具有这样的特征:其中,所述数据聚合的方式包括低价优先策略、质高优先策略、轮询策略、以及随机选择策略。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通方法中,还可以具有这样的特征:其中,在确定数据聚合方式时,通过网页的形式为数据需求方提供选择数据聚合方式的接口,设定预定时间,定时拉取数据需求方选择的数据聚合方式,在所述预定时间内,数据需求方向所述数据供给方请求数据时,均按照该次选择的数据聚合方式进行数据配送。
本发明还提供了一种基于数据能力聚合的高性能数据流通系统,其特征在于,包括:数据需求方;多个数据供给方,用于为所述数据需求方提供数据;以及数据聚合模块,用于所述数据需求方发起请求时采用数据聚合的方式选择为该次请求提供数据的数据供给方。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通系统中,还可以具有这样的特征:基于数据能力聚合的高性能数据流通系统还包括:数据缓存模块,用于缓存所述数据需求方从所述数据供给方请求的数据;以及
数据查询模块,用于根据所述数据需求方的请求向所述数据缓存模块或所述数据供给方发起请求。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通系统中,还可以具有这样的特征:其中,所述数据缓存模块设置有时间模块,用于设定数据缓存模块中缓存的数据的存储时间。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通系统中,还可以具有这样的特征:其中,所述数据缓存模块、所述数据查询模块、所述数据聚合模块集成在同一台设备上,该设备与所述数据需求方和多个所述数据供给方通过http或者thrift的方式进行数据传输,且在进行数据交互建立连接时采用长连接的方式。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通系统中,还可以具有这样的特征:其中,所述数据缓存模块、所述数据查询模块、所述数据聚合模块分别集成在不同的设备上,所述数据缓存模块、所述数据查询模块、所述数据聚合模块、所述数据需求方和多个所述数据供给方之间通过http或者thrift的方式进行数据传输,且在进行数据交互建立连接时采用长连接的方式。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通系统中,还可以具有这样的特征:其中,所述数据查询模块通过组建集群来动态扩展服务能力。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通系统中,还可以具有这样的特征:其中,基于数据能力聚合的高性能数据流通系统还包括反向代理服务器,用于接收所述数据需求方的请求,并将请求的结果返回给所述数据需求方。
进一步,在本发明提供的基于数据能力聚合的高性能数据流通系统中,还可以具有这样的特征:其中,基于数据能力聚合的高性能数据流通系统还包括路由查询模块,用于查询各数据供给方的ip和端口。
本发明的优点如下:
根据本发明所涉及的基于数据能力聚合的高性能数据流通方法,由于由多个数据供给方可以为数据需求方提供数据,当数据需求方请求数据时,根据该次请求的数据量结合数据需求方和数据供给方的并发能力采用数据聚合的方式选择为该次请求提供数据的数据供给方,并向为该次请求提供数据的数据供给方发起请求,因此,会有多个数据供给方为数据需求方提供数据,形成一对多的配送策略,从而充分利用了数据供给方的供给能力,提高了数据配送的并发能力,并且因为数据需求方可由多个数据供给方供给数据,所以即使数据供给方中有部分数据供给方不可用,也不会影响整个过程的数据配送,数据配送可靠性高;并且由于由多个数据供给方可以为数据需求方提供数据,因此根据业务需求可选择不同的数据供给方进行数据配送,解决了现有技术中,单个数据供给方对应单个数据需求方时无法扩展业务的问题。
本发明所涉及的基于数据能力聚合的高性能数据流通系统,会有多个数据供给方为数据需求方提供数据,形成一对多的配送策略,充分利用了数据供给方的供给能力,提高了数据配送的并发能力,并且因为数据需求方可由多个数据供给方供给数据,所以即使数据供给方中有部分数据供给方不可用,也不会影响整个过程的数据配送,数据配送可靠性高;并且由于由多个数据供给方可以为数据需求方提供数据,因此根据业务需求可选择不同的数据供给方进行数据配送,解决了现有技术中,单个数据供给方对应单个数据需求方时无法扩展业务的问题。
附图说明
图1是本发明中基于数据能力聚合的高性能数据流通系统的结构框图;
图2是本发明中基于数据能力聚合的高性能数据流通系统的逻辑结构示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下实施例结合附图对本发明基于数据能力聚合的高性能数据流通方法及系统作具体阐述。
基于数据能力聚合的高性能数据流通方法为:多个数据供给方为数据需求方供给数据,数据需求方请求数据时,根据该次请求的数据量结合数据需求方和数据供给方的并发能力采用数据聚合的方式选择为该次请求提供数据的数据供给方,并向为该次请求提供数据的数据供给方发起请求。由于数据需求方会选择多个数据供给方提供数据,采用一对多的配送策略,从而充分利用了数据供给方的供给能力,而数据需求方的数据配送并发能力也不会受到单个数据供给方的限制,提高了数据传输的并发能力,并且因为数据需求方可由多个数据供给方供给数据,所以即使数据供给方中有部分数据供给方不可用,也不会影响整个过程的数据配送,数据配送可靠性高,并且可以根据业务的需求选择不同的数据供给方。
在本实施例中,数据需求方请求数据时,首先查询数据缓存模块中是否存储有请求需要的数据,若有,则从数据缓存模块中获取数据,若否,则通过数据聚合的方式从数据供给方获得数据,并将从数据供给方请求的数据缓存到数据缓存模块中。这样,当数据需求方有相同的请求时,可以直接从数据缓存模块中获取数据,节省了数据需求方请求数据时间。
在本实施例中,数据缓存模块存储数据时采用分布式缓存。利用高性能缓存建立集群,构建分布式缓存系统。如采用redis构建集群。
在本实施例中,对数据缓存模块缓存的数据设置存储时间,并对到达存储时间的缓存的数据进行删除。用于消除无用的缓存数据占用缓存空间。以redis为例,对key值设置存储时间,例如30天,30天后即对该key-value数据进行删除。
在本实施例中,对数据进行缓存时,对源数据的value值进行编码处理后存入数据缓存模块。目的为了降低内存占用量。以redis为例,对源数据的value进行编码的方式为:将所有源数据的value集合进行编码,比如源数据的value为“value1”,将“value1”编码为0,源数据的value为“value2”,将“value2”编码为1。如果源数据的value为“value1”,则在存储到缓存模块时,存入整数0;如果源数据的value为“value2”,则在存储到缓存模块时,存入整数2,因此,存储时,对小整数进行共享存储,即同一份数据只会存储一次,大大降低了内存占用量。
在本实施例中,数据需求方向数据供给方请求数据前,通过心跳包的方式确定当前可用的数据供给方。心跳包的具体方法为:数据需求方和多个数据供给方之间通过数据聚合模块数据连接,数据聚合模块设置有常驻内存的字典,字典的键为各个数据供给方,值为整数值,各个数据供给方每隔一段时间向数据聚合模块发送一个心跳包,数据聚合模块接收到心跳包后,将接收到数据供给方心跳包的字典的键对应的字典的值更新为0,当数据聚合模块超过规定时间未接收到某个数据供给方的心跳包时,与该数据供给方对应的字典的值会增加1,当字典的值大于等于3时,则视为该数据供给方不可用。
在本实施例中,数据聚合的方式包括低价优先策略、质高优先策略、轮询策略、以及随机选择策略。
在确定数据聚合方式时,通过网页的形式为数据需求方提供选择数据聚合方式的接口,设定预定时间,定时拉取数据需求方选择的数据聚合方式,在预定时间内,数据需求方向数据供给方请求数据时,均按照该次选择的数据聚合方式进行数据配送。因此,数据需求方可以动态配置数据集合的方式。
低价优先策略为:
步骤1,计算根据心跳包的方法确定的数据供给方和数据需求方配置的数据供给方的交集。
步骤2,选择交集中价格最低的数据供给方为数据需求方提供数据。
质高优先策略为:
步骤1,计算根据心跳包的方法确定的数据供给方和数据需求方配置的数据供给方的交集。
步骤2,选择交集中质量最好的数据供给方为数据需求方提供数据。
随机选择策略为:
步骤1,计算根据心跳包的方法确定的数据供给方和数据需求方配置的数据供给方的交集,并将交集转换为列表,计算列表的长度n。
步骤2,随机产生一个小于等于n的正整数a,选择所述列表中第a个数据供给方为数据需求方提供数据。
轮询策略为:
步骤1,数据需求方第一次向数据供给方发起轮询请求时会被分配一个随机的32位的值n。
步骤2,计算根据心跳包的方法确定的数据供给方和数据需求方配置的数据供给方的交集,并对交集中的每个数据供给方,根据其访问ip和端口基于md5运算得到交集中的各数据供给方的md5值,其中,计算所得的md5值为数值。
步骤3,选择交集中数据供给方的md5值大于n中md5值最小的数据供给方为数据需求方提供数据,如果交集中数据供给方的md5值均小于n,则选择md5值最小的数据供给方为数据需求方提供数据。
由于采用上述四种数据聚合方式每执行一次选择一个数据供给方,当需要选择多个数据供给方时,则采用上述四种数据聚合方式执行多次选择。
一般情况,数据供给方的并发能力大概为200qps,数据需求方的并发能力为4000qps,在传统的单点对单点的数据配送系统中,整个业务在数据配送过程中的并发能力为200qps;而本发明可以选择多个数据供给方,并采用数据聚合的方法选择数据供给方,因此只要数据供给方数量达到20个及以上,就能使得整个业务并发能力达到数据需方的并发能力,即4000qps。
传统的单点对单点的数据配送系统与本发明的数据流通方法并发能力的比较如表1所示。
表1.传统与本发明数据配送能力比较表
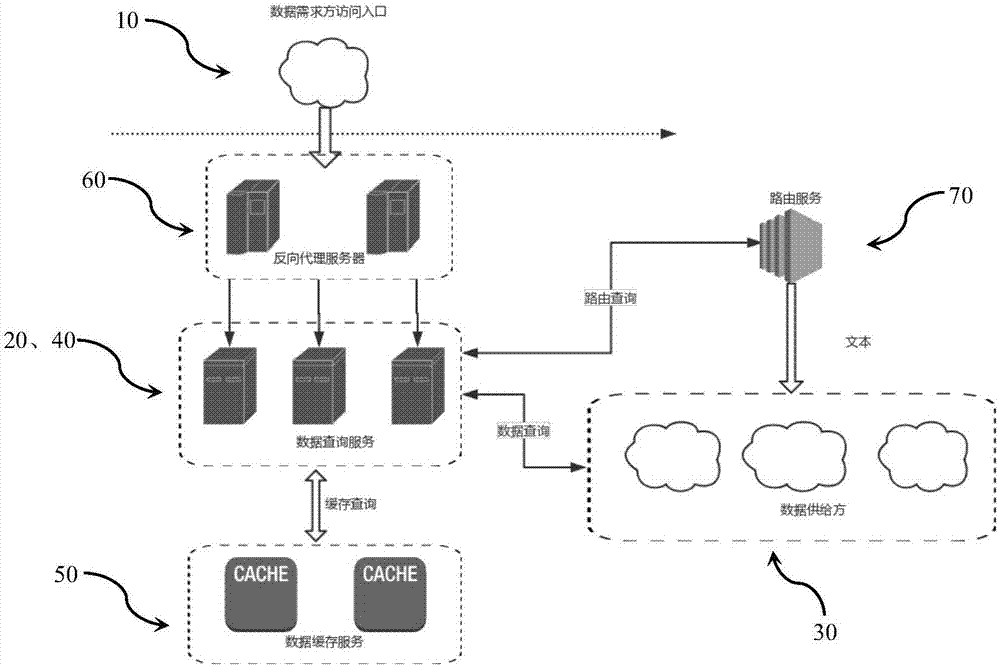
如图1、图2所示,一种基于数据能力聚合的高性能数据流通系统,包括:数据需求方10、数据聚合模块20和多个数据供给方30。
多个数据供给方30为数据需求方10提供数据,在数据需求方10发起请求时,数据聚合模块20采用数据聚合的方式选择为该次请求提供数据的数据供给方30。
在本实施例中,基于数据能力聚合的高性能数据流通系统还包括数据缓存模块40和数据查询模块50。
数据缓存模块40用于缓存数据需求方10从数据供给方30请求的数据。数据缓存模块40设置有时间模块,用于设定数据缓存模块40中缓存的数据的存储时间。数据查询模块50用于根据数据需求方10的请求向数据缓存模块40或数据供给方30发起请求。
数据缓存模块40、数据查询模块50、数据聚合模块20可以集成在同一台设备上,也可以集成在不同的设备上。在本实施例中,如图2所示,数据查询模块50、数据聚合模块20集成在同一台设备上,数据缓存模块40集成在一台设备上。
在本实施例中,各设备之间通过http或者thrift的方式进行数据传输,且各设备在进行数据交互建立连接时采用长连接的方式。两个设备之间通过http进行传输数据的具体方法为:利用fasthttp构建http服务,http服务启动时创建连接池和协程池,当请求发生时,首先从协程池中取协程,然后从连接池中取出连接。两个设备之间通过thrift进行传输数据的具体方法为:利用thrift构建服务,thrift服务启动时创建连接池和协程池,当请求发生时,首先从协程池中取协程,然后从连接池中取出连接。
当数据缓存模块20、数据查询模块30、数据聚合模块40集成在同一台设备上时,该设备与数据需求方和多个数据供给方通过http或者thrift的方式进行数据传输。当数据缓存模块20、数据查询模块30、数据聚合模块40分别集成在不同的设备上时,数据缓存模块、数据查询模块、数据聚合模块、数据需求方和多个数据供给方之间通过http或者thrift的方式进行数据传输,且各设备在进行数据交互建立连接时采用长连接的方式。
在本实施例中,数据查询模块通过组建集群来动态扩展服务能力。即增加数据查询设备的数量组建集群来增加服务能力。数据缓存模块20根据需要缓存的数据量和对外服务的并发能力确定缓存节点。如图2所示,数据查询模块50、数据聚合模块20集成在同一台设备上,增加该设备的数量可以提高服务能力。
在本实施例中,基于数据能力聚合的高性能数据流通系统还包括反向代理服务器60,用于接收数据需求方10的请求,并将请求的结果返回给数据需求方10。反向代理服务器60和数据查询模块、数据需求方之间通过http或者thrift的方式进行数据传输,且反向代理服务器60在与数据查询模块、数据需求方进行数据交互建立连接时采用长连接的方式。
在本实施例中,基于数据能力聚合的高性能数据流通系统还包括路由查询模块70,用于查询各数据供给方的ip和端口。在采用轮询策略选择数据供给方时提供计算需要的各数据供给方的ip和端口。
上述实施方式为本发明的优选案例,并不用来限制本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!