一种物流取货操作耗时智能预测方法及系统与流程
本发明涉及物流运输技术领域,尤其涉及一种物流取货操作耗时智能预测方法及系统。
背景技术:
随着物流行业的快速发展,客户对物流服务的时效要求越来越高,因此,衍生出了“当天达”、“次日达”、“隔日达”等限时服务方式,而这些服务方式都有着严格的时效要求,一旦超时,则需对客户进行赔偿,还将影响客户体验,因此,客户下单后,工作人员上门取件所需要的取货操作耗时也需要进行严格限定。
目前,取货操作耗时主要是通过有经验的工作人员进行人为预测,再根据预测结果调度取件人员前往取件,但是人为预测往往不尽人意,预测结果准确性低,而预测结果的不准确极可能会使得整个物流过程的时间分配出现不合理的情况,导致货物不能及时运输到客户手里,并且,人为预测还会加大人力消耗,加重公司负担。
技术实现要素:
本发明提供了一种物流取货操作耗时智能预测方法及系统,以解决现有物流运输行业中,人为预测操作耗时不准确的问题。
为了解决上述问题,本发明提供了一种物流取货操作耗时智能预测方法,包括:
接收当前订单信息,订单信息包括客户名、货物下单重量和货物下单件数;
获取数据库中客户名下所有历史订单,判断历史订单的数量是否超过预设阈值;
若是,则根据多元映射回归预测模型对货物下单重量和货物下单件数进行处理,得到预测操作耗时;多元映射回归预测模型根据历史订单特征属性数据构建;
若否,则从数据库中匹配出该客户名下与当前订单最近似的历史订单,将该历史订单的实际操作耗时作为当前订单的预测操作耗时。
作为本发明的进一步改进,历史订单特征属性数据包括每单下单件数、每单下单重量,以及每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的统计值,统计值包括平均值、中位数值、下四分位数值、上四分位数值中的至少一种。
作为本发明的进一步改进,多元映射回归预测模型根据历史订单特征属性数据构建的步骤,包括:
建立多元映射回归方程:y=at·x+b,其中y表示实际操作耗时,x表示由历史订单特征属性数据组成的矩阵,at、b为影响因子;
拟合历史订单特征属性数据,获得at、b的优选估计值;
根据所述at、b的优选估计值构建所述多元映射回归预测模型。
作为本发明的进一步改进,从数据库中匹配出该客户名下与当前订单最近似的历史订单的步骤,包括:
建立以每单货物件数、每单货物重量为维度的平面直角坐标系;
将历史订单数据、当前订单数据放入该平面直角坐标系中,形成相应的坐标点;
计算出与表示当前订单数据坐标点欧式距离最近的目标坐标点;
确认该目标坐标点表示的历史订单为与当前订单最近似的历史订单。
作为本发明的进一步改进,获取数据库中客户名对应的历史订单步骤之前,还包括:
对数据库中历史订单的每单实际耗时值进行数据清洗,确认出异常的实际耗时值;
从数据库中删除掉异常实际耗时值对应的历史订单。
为了解决上述问题,本发明还提供了一种物流取货操作耗时智能预测系统,包括:
接收模块,用于接收当前订单信息,订单信息包括客户名、货物下单重量和货物下单件数;
判断模块,用于获取数据库中客户名下所有历史订单,判断历史订单的数量是否超过预设阈值;
第一耗时预测模块,用于当历史订单数量超过预设阈值时,根据多元映射回归预测模型对货物下单重量和货物下单件数进行处理,得到预测操作耗时;多元映射回归预测模型根据历史订单特征属性数据构建;
第二耗时预测模块,用于当历史订单数量未超过预设阈值时,从数据库中匹配出该客户名下与当前订单最近似的历史订单,将该历史订单的实际操作耗时作为当前订单的预测操作耗时。
作为本发明的进一步改进,历史订单特征属性数据包括每单下单件数、每单下单重量,以及每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的统计值,统计值包括平均值、中位数值、下四分位数值、上四分位数值中的至少一种。
作为本发明的进一步改进,其还包括:
方程建立模块,用于建立多元映射回归方程:y=at·x+b,其中y表示实际操作耗时,x表示由历史订单特征属性数据组成的矩阵,at、b为影响因子;
拟合模块,用于拟合历史订单特征属性数据,获得at、b的优选估计值;
模型构建模块,根据at、b的优选估计值构建多元映射回归预测模型。
作为本发明的进一步改进,第二耗时预测模块包括:
坐标系建立单元,用于建立以每单货物件数、每单货物重量为维度的平面直角坐标系;
坐标代入单元,用于将历史订单数据、当前订单数据放入该平面直角坐标系中,形成相应的坐标点;
计算单元,用于计算出与表示当前订单数据坐标点欧式距离最近的目标坐标点;
确认单元,用于确认该目标坐标点表示的历史订单为与当前订单最近似的历史订单。
作为本发明的进一步改进,其还包括:
清洗模块,用于对数据库中历史订单的每单实际耗时值进行数据清洗,确认出异常的实际耗时值;
删除模块,用于从数据库中删除掉异常实际耗时值对应的历史订单。
相比于现有技术,本发明通过根据历史订单特征属性数据构建多元映射回归预测模型,而当历史订单的数量较多时,根据该多元映射回归预测模型预测的结果更为准确,因此,在接收到客户的当前订单信息后,从数据库中获取该客户名下的所有历史订单,当历史订单的数量超过预设阈值时,则根据多元映射回归预测模型对当前订单的操作耗时进行预测,提高预测结果的准确率,而当历史订单的数量未超过预设阈值时,多元映射回归预测模型的预测准确率下降,此时,从所有历史订单中确认与当前订单最近似的历史订单,并将该最近似的历史订单的实际操作耗时作为当前订单的预测操作耗时,从而使得无论客户的历史订单的数量多或少,均能得到一个较好的预测结果,并且,本发明的预测过程不需要人为参与进行,降低了人力消耗,同时也避免了人为预测准确率低的问题。
附图说明
图1为本发明物流取货操作耗时智能预测方法第一个实施例的流程图;
图2为本发明物流取货操作耗时智能预测方法一个实施例的多元映射回归预测模型构建的流程图;
图3为本发明物流取货操作耗时智能预测方法第二个实施例的流程图;
图4为本发明物流取货操作耗时智能预测方法一个实施例的平面直接坐标系的框架示意图;
图5为本发明物流取货操作耗时智能预测方法预测结果的差值区间分布图;
图6为本发明物流取货操作耗时智能预测方法第三个实施例的流程图;
图7为本发明物流取货操作耗时智能预测系统第一个实施例的功能模块示意图;
图8为本发明物流取货操作耗时智能预测系统第二个实施例的功能模块示意图;
图9为本发明物流取货操作耗时智能预测系统第三个实施例的功能模块示意图;
图10为本发明物流取货操作耗时智能预测系统第四个实施例的功能模块示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用来限定本发明。
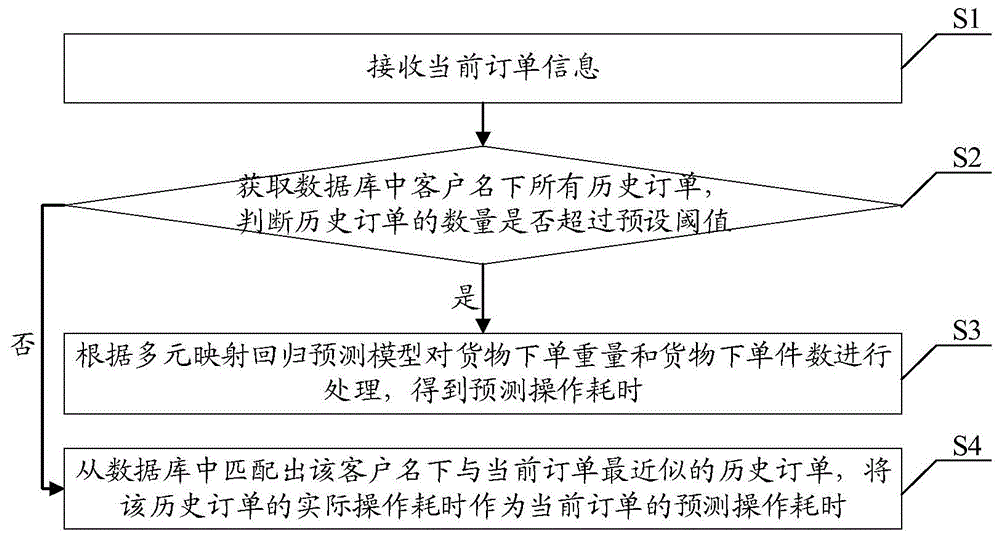
图1展示了本发明物流取货操作耗时智能预测方法的一个实施例。在本实施例中,如图1所示,该物流取货操作耗时智能预测方法包括:
步骤s1,接收当前订单信息。
需要说明的是,该订单信息包括客户名、货物下单重量和货物下单件数。
步骤s2,获取数据库中客户名下所有历史订单,判断历史订单的数量是否超过预设阈值。若历史订单的数量超过预设阈值,则执行步骤s3;若历史订单的数量未超过预设阈值,则执行步骤s4。
需要说明的是,该数据库用于存储所有客户名以及客户名下的历史订单数据,该预设阈值预先设置。
具体地,接收到当前订单信息之后,根据客户名从数据库中获取其对应的所有历史订单,从而得到历史订单的数量,再判断历史订单的数量是否超过预设阈值。该阈值根据预测准确性、应用覆盖面等方面综合考虑后设置,本实施例中该预设阈值为10单。
进一步地,在一些实施例中,考虑到数据的时效性,还可以是获取数据库中预设时间段内客户名下所有历史订单,该预设时间段预先设置,例如,1个月、2个月、半年等,则此时预设阈值可以为1个月10单、2个月10单、半年10单等。
步骤s3,根据多元映射回归预测模型对货物下单重量和货物下单件数进行处理,得到预测操作耗时。
需要说明的是,多元映射回归预测模型根据历史订单特征属性数据构建。在本实施例中,该历史订单特征属性数据包括每单下单件数、每单下单重量,以及每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的统计值,该统计值包括平均值、中位数值、下四分位数值、上四分位数值中的至少一种。
本实施例中,每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的统计值,可以为每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的平均值;在一些实施例中,还可以为每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的平均值和中位数值;在一些实施例中,还可以为每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的平均值、中位数值和下四分位数值;在一些实施例中,还可以为每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的平均值、中位数值、下四分位数值和上四分位数值。
其中,每单下单件数是指每个历史订单下单时输入的货物件数,每单下单重量是指每个历史订单下单时输入的货物重量,每单货物真实件数是指每个历史订单的货物实际件数,每单货物真实重量是指每个历史订单的货物实际重量,每单实际耗时是指每个历史订单的实际操作耗时,每单单件货物件均耗时是指每个历史订单单件货物的平均操作耗时。每单货物真实件数、每单货物真实重量、每单实际耗时均在订单完成之后存储至数据库,因此,可从数据库中直接获取,而每单单件货物件均耗时可根据每单真实件数和每单实际耗时计算获得。
其中,四分位数也称四分位点,是指在统计学中把所有数值由小到大排列并分成四等份,处于三个分割点位置的数值。它是一组数据排序后处于25%和75%位置上的值。四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据,中间的四分位数就是中位数,处在25%位置上的数值称为下四分位数,处在75%位置上的数值称为上四分位数。
进一步的,如图2所示,多元映射回归预测模型根据历史订单特征属性数据构建的步骤包括:
步骤s10,建立多元映射回归方程:y=at·x+b。
需要说明的是,y表示每个历史订单的实际操作耗时,即历史订单中每单实际耗时,x表示由历史订单特征属性数据组成的矩阵,本实施例中,历史订单特征属性数据包括,
(1)每单下单件数、每单下单重量;
(2)每单货物真实件数的平均值、中位数值、下四分位数值和上四分位数值;
(3)每单货物真实重量的平均值、中位数值、下四分位数值和上四分位数值;
(4)每单实际耗时的平均值、中位数值、下四分位数值和上四分位数值;
(5)每单单件货物件均耗时的平均值、中位数值、下四分位数值和上四分位数值。
at、b为影响因子。
具体地,在确认客户名下所有历史订单之后,获取历史订单特征属性数据,再根据历史订单特征属性数据和每单实际耗时构建多元映射回归方程。
步骤s11,拟合历史订单特征属性数据,获得at、b的优选估计值。
具体地,根据历史订单的历史订单特征属性数据和每单实际耗时进行拟合,得到多组at、b估计值,然后根据拟合优度系数r2对每组at、b估计值进行评估,拟合优度系数r2越接近1,代表拟合优度越高,从而选取出at、b的优选估计值。
其中,拟合优度系数r2根据如下公式计算:
其中,ssr代表回归平方和,sse为残差平方和,sst为总离差平方和,fi为通过多元映射回归方程得到的预测操作耗时,yi为该历史订单的实际耗时,
步骤s12,根据at、b的优选估计值构建多元映射回归预测模型。
本实施例在构建多元映射回归方程之后,根据客户名下的所有历史订单的历史订单特征属性数据进行拟合,并通过拟合优度系数确认at、b的优选估计值,并根据该at、b的优选估计值构建多元映射回归预测模型,从而保证该多元映射回归预测模型对该客户的订单的操作耗时的预测更为准确。
在构建好多元映射回归方程后,将当前订单信息中的货物下单重量和下单件数代入该多元映射回归方程,从而得到预测操作耗时。
例如,客户a的历史订单数目达到50个,属于经常下单的客户(其历史订单的数量超过预设阈值10),根据该50个历史订单即可获得该客户的历史订单特征属性数据组成矩阵x,该历史订单特征属性具体请参考上述实施例中所述,此处不再赘述。
表1客户a多元映射回归方程的at、b的优选估计值
表1中列出了根据历史订单特征属性数据组成的矩阵x信息作为示例。经过拟合计算,并通过拟合优度系数r2进行评估,得到如表1所示的at、b的优选估计值。
在构建完成多元映射回归方程后,若客户a再次下了一个订单,该订单的货物下单件数为30件,货物下单重量为100kg,则将货物下单件数和货物下单重量代入至多元映射回归方程:y=at·x+b,从而计算得到预测操作耗时,计算过程示例如下:
y=30*0.2186+100*0.1082+2.76*(-0.016)+6.54*(-0.08)+8.51*0.0516+1.96*(-0.008)+11.68*0.0642+……+1*3.2137=22.59;
则根据多元映射回归方程的计算,得到客户a本次订单的预测操作耗时为22.59分钟。
进一步地,在一些实施例中,在根据历史订单特征属性数据构建多元映射回归预测模型的步骤之前,还包括:
判断客户名下的历史订单的数量是否超过预设阈值;若客户名下的历史订单的数量未超过预设阈值,则不创建该客户的多元映射回归预测模型。
应当理解的是,本实施例中的预设阈值和上述实施例中的预设阈值为同一阈值。
同样地,考虑到数据的有效性,该客户名下的历史订单的数量同样为预设时间段内的历史订单的数量,该预设时间段预设设置,如1个月、2个月、半年等,则此时预设阈值可以为1个月10单、2个月10单、半年10单等。
本实施例通过根据客户的历史订单的数量确认是否创建多元映射回归预测模型,从而不需要对下单量过少的客户构建模型,减少了数据处理需要消耗的资源。
应当理解的是,多元映射回归预测模型的构建是基于历史订单特征属性数据的基础,因此,历史订单越多,构建的多元映射回归预测模型,其预测的结果更准确,因此,本实施例中,当历史订单的数量超过预设阈值时,说明当前客户的下单较为频繁,其历史订单较多,此时,采用多元映射回归预测模型根据当前订单的货物下单重量和货物下单件数进行处理,得到预测操作耗时。
当历史订单数量较少,未超过预设阈值时,则执行步骤s4。
步骤s4,从数据库中匹配出该客户名下与当前订单最近似的历史订单,将该历史订单的实际操作耗时作为当前订单的预测操作耗时。
具体地,当历史订单的数量未超过预设阈值时,说明该当前客户的历史订单较少,此时,根据其历史订单构建的多元映射回归预测模型预测的结果反而不够准确,因此,考虑到为同一客户下单,可以从其历史订单中获取与当前订单比较近似的历史订单,参考该历史订单的实际操作耗时来进行预测。
具体地,本实施例中,通过从数据库中匹配出该客户名下与当前订单最近似的历史订单,将该历史订单的实际操作耗时作为当前订单的预测操作耗时。需要理解的是,本实施例中所述的与当前订单最近似的历史订单,可以将当前订单的货物下单重量和货物下单件数与历史订单的实际重量和实际件数进行比较,从而确认最近似的历史订单。
进一步的,如图3所示,步骤s4包括:
步骤s20,建立以每单货物件数、每单货物重量为维度的平面直角坐标系。
步骤s21,将历史订单数据、当前订单数据放入该平面直角坐标系中,形成相应的坐标点。
具体地,为了统一量纲,对客户历史订单的每单货物件数、每单货物重量均进行离差标准化处理,使得两个维度的数据值落到[0,1]区间内,从而得到每个历史订单的坐标点,并将坐标点放入平面直角坐标系中,同样地,针对于当前订单数据,即当前订单的货物下单重量和货物先件数也进行离差标准化处理,得到当前订单对应的坐标点,并将坐标点放入该平面直角坐标系中。
步骤s22,计算出与表示当前订单数据坐标点欧式距离最近的目标坐标点。
步骤s23,确认该目标坐标点表示的历史订单为与当前订单最近似的历史订单。
步骤s24,将该历史订单的实际操作耗时作为当前订单的预测操作耗时。
具体地,计算当前订单数据坐标点与每一个历史订单数据坐标点之间的欧式距离,从而确认出最接近当前订单数据坐标点的历史订单数据坐标点为目标坐标点,并确认该目标坐标点对应的历史订单,并将该历史订单的是实际操作耗时作为当前订单的预测操作耗时。
在本实施例中,根据历史订单数据和当前订单数据构建平面直角坐标系,再根据历史订单数据坐标点与当前订单数据坐标点之间的欧式距离确认出与当前订单最近似的历史订单,从而根据该最近似的历史订单的实际操作耗时对当前订单进行预测,得到预测操作耗时,相比于其他预测方式,在历史订单的数量较少的情况下,本实施例中的预测操作耗时是根据客户的历史订单预测的,其预测结果更为准确。
例如,如图4所示,以八组历史订单数据为例,将该八组历史订单数据进行离差标准化处理之后,得到八个历史订单数据坐标点,并代入至平面直角坐标系中(图中三角形所示坐标点),并将当前订单数据同样经离差标准化处理之后,得到当前订单数据坐标点,并代入至平面直角坐标系中(图中圆形所示坐标点),再分别计算当前订单数据坐标点与每个历史订单数据坐标点之间的欧式距离,从而确认与当前订单最近似的历史订单(如图中虚线区域内所示为当前订单数据坐标点和与当前订单数据坐标点最近似的历史订单数据坐标点),并将该历史订单的实际操作耗时作为当前订单的预测操作耗时。
具体地,例如,下表2展示了一组订单的操作耗时预测结果,该批订单对应的客户名下的历史订单的数量超过预设阈值,其中,回归预测模型预测耗时是指根据多元映射回归预测模型对货物下单重量和货物下单件数进行处理,得到的预测操作耗时;历史数据匹配预测耗时是指从数据库中匹配出该客户名下与当前订单最近似的历史订单,将该历史订单的实际操作耗时作为当前订单的预测操作耗时。
表2操作耗时预测结果
根据上表2即可得出如图5所示的差值区间分布图,图中横坐标代表预测操作耗时与实际操作耗时之间的差值。由图5可以看出,针对同一组订单,采用历史数据匹配进行预测,预测结果中预测操作耗时与实际操作耗时之间差值在[0,10)区间范围的,占其所有预测结果的42.55%;而采用回归预测模型进行预测,预测结果中预测操作耗时与实际操作耗时之间差值在[0,10)区间范围的,占其所有预测结果的51.98%,可以看出,预测结果中差值在[0,10)区间范围的占比,采用回归预测模型比采用历史数据匹配预测要高9.43%;差值在[10,40)区间范围的,采用历史数据匹配预测,占其预测结果的40.88%;而采用回归预测模型预测,占其预测结果的39.88%,两者相近;差值在[40,∞)区间范围的,采用历史数据匹配预测,占其预测结果的16.58%;而采用回归预测模型预测,占其预测结果的8.14%,可以看出,预测结果中差值在[40,∞)区间范围的占比,采用回归预测模型比采用历史数据匹配预测减少了8.44%。通过对比可看出,根据回归模型预测耗时,整体上所得预测结果与实际操作耗时之间差值较小,预测操作耗时更接近实际操作耗时,因此,当客户名下的历史订单的数量超过预设阈值时,则采用回归模型预测耗时的方案可以得到很好的预测效果。
但是,当客户名下累计的历史订单的数量未超过预设阈值时,由于缺乏可供回归模型学习的参考数据,此时采用历史数据匹配预测耗时的方案得到的预测效果更好。
本实施例通过根据历史订单特征属性数据构建多元映射回归预测模型,当历史订单的数量较多时,根据该多元映射回归预测模型预测的结果更为准确,因此,在接收到客户的当前订单信息后,从数据库中获取该客户名下的所有历史订单,当历史订单的数量超过预设阈值时,则根据多元映射回归预测模型对当前订单的操作耗时进行预测,提高预测结果的准确率,而当历史订单的数量未超过预设阈值时,多元映射回归预测模型的预测准确率下降,此时,从所有历史订单中确认与当前订单最近似的历史订单,并将该最近似的历史订单的实际操作耗时作为当前订单的预测操作耗时,从而使得无论客户的历史订单的数量多或少,均能得到一个较好的预测结果,并且,本发明的预测过程不需要人为参与进行,降低了人力消耗,同时也避免了人为预测准确率低的问题。
进一步地,为了提高预测的准确率,上述实施例的基础上,其他实施例中,如图6所示,在步骤s2之前,还包括:
步骤s30,对数据库中历史订单的每单实际耗时值进行数据清洗,确认出异常的实际耗时值。
步骤s31,从数据库中删除掉异常实际耗时值对应的历史订单。
具体地,可采用箱线图法来识别历史订单的数据中,异常的实际耗时值。箱线图通过绘制连续变量的最小值、下四分位数q1(第25百分位数)、中位数q2(第50百分位数)、上四分位数q3(第75百分位数)以及最大值,描述了连续型变量的分布。如果箱线图是竖直的,那么箱线图中的盒子的上下边分别代表q1和q3,盒子的长度等于上下四分位数之差,称为四分位间距或四分位极差(iqr)。通常地,在1.5倍iqr范围外的点,箱线图都识别为异常值,箱线图不需要假设数据满足某种分布,且具有很好的鲁棒性,不受异常值的影响。
本实施例中,以历史订单的每单实际耗时值为连续变量绘制箱线图,并规定[q1-3*iqr,q3+3*iqr]区间范围之外的值为异常值,从而确认出异常的实际耗时值,再将该异常的实际耗时值对应的历史订单从数据库中删除。
本实施例通过对数据库中客户名下的历史订单进行清洗,从而清除掉异常的历史订单,避免异常的历史订单对预测结果造成影响,提高了预测的准确率。
图7展示了本发明物流取货操作耗时智能预测系统的一个实施例。在本实施例中,如图7所示,该物流取货操作耗时智能预测系统包括接收模块10、判断模块11、第一耗时预测模块12和第二耗时预测模块13。
其中,接收模块10,用于接收当前订单信息,订单信息包括客户名、货物下单重量和货物下单件数;判断模块11,用于获取数据库中客户名下所有历史订单,判断历史订单的数量是否超过预设阈值;第一耗时预测模块12,用于当历史订单数量超过预设阈值时,根据多元映射回归预测模型对货物下单重量和货物下单件数进行处理,得到预测操作耗时;多元映射回归预测模型根据历史订单特征属性数据构建;第二耗时预测模块13,用于当历史订单数量未超过预设阈值时,从数据库中匹配出该客户名下与当前订单最近似的历史订单,将该历史订单的实际操作耗时作为当前订单的预测操作耗时。
上述实施例的基础上,其他实施例中,历史订单特征属性数据包括每单下单件数、每单下单重量,以及每单货物真实件数、每单货物真实重量、每单实际耗时、每单单件货物件均耗时的统计值,统计值包括平均值、中位数值、下四分位数值、上四分位数值中的至少一种。
上述实施例的基础上,其他实施例中,如图8所示,该物流取货操作耗时智能预测系统还包括方程建立模块20、拟合模块21和模型构建模块22。
其中,方程建立模块20,用于建立多元映射回归方程:y=at·x+b,其中y表示实际操作耗时,x表示由历史订单特征属性数据组成的矩阵,at、b为影响因子;拟合模块21,用于拟合历史订单特征属性数据,获得at、b的优选估计值;模型构建模块22,根据at、b的优选估计值构建多元映射回归预测模型。
上述实施例的基础上,其他实施例中,如图9所示,第二耗时预测模块13包括坐标系建立单元130、坐标代入单元131、计算单元132和确认单元133。
其中,坐标系建立单元130,用于建立以每单货物件数、每单货物重量为维度的平面直角坐标系;坐标代入单元131,用于将历史订单数据、当前订单数据放入该平面直角坐标系中,形成相应的坐标点;计算单元132,用于计算出与表示当前订单数据坐标点欧式距离最近的目标坐标点;确认单元133,用于确认该目标坐标点表示的历史订单为与当前订单最近似的历史订单。
上述实施例的基础上,其他实施例中,如图10所示,该物流取货操作耗时智能预测系统还包括清洗模块30和删除模块31。
其中,清洗模块30,用于对数据库中历史订单的每单实际耗时值进行数据清洗,确认出异常的实际耗时值;删除模块31,用于从数据库中删除掉异常实际耗时值对应的历史订单。
关于上述五个实施例物流取货操作耗时智能预测系统中各模块实现技术方案的其他细节,可参见上述实施例中的物流取货操作耗时智能预测方法中的描述,此处不再赘述。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于系统类实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上对发明的具体实施方式进行了详细说明,但其只作为范例,本发明并不限制于以上描述的具体实施方式。对于本领域的技术人员而言,任何对该发明进行的等同修改或替代也都在本发明的范畴之中,因此,在不脱离本发明的精神和原则范围下所作的均等变换和修改、改进等,都应涵盖在本发明的范围内。
- 还没有人留言评论。精彩留言会获得点赞!