一种基于非概率模型的垃圾网页降级方法与流程
本发明属于网页信息技术领域,特别是涉及一种基于非概率模型的垃圾网页降级方法。
背景技术:
垃圾网页指采用作弊手段来提高自身在搜索引擎搜索结果中排名的网页。垃圾网页的存在对普通搜索引擎用户和搜索引擎公司均带来了很大挑战。对普通用户而言,垃圾网页使得搜索结果中存在大量无用信息,增加了用户寻找有效信息的时间;对搜索引擎公司而言,垃圾网页需要额外的资源来对其进行存储、解析、索引,极大地浪费了存储资源和计算资源。
现有垃圾网页降级处理方法需要建立庞大且复杂的概率计算模型,从而依靠概率计算模型对垃圾网页进行降级处理;这种方法会极大浪费网络资源,并且识别垃圾网页的效率极低,无法快速且精确地实现垃圾网页降级处理。现有垃圾网页降级算法通常采用孤立近似原则,即正常网页极少有链接至垃圾网页,忽略了网页链接之间的传播性,大大降低了垃圾网页降级的处理精度。
技术实现要素:
为了解决上述问题,本发明提出了一种基于非概率模型的垃圾网页降级方法,实现垃圾网页降级处理,尽最大可能提升正常网页在搜索引擎中的排名,同时降低垃圾网页的排名,有效提高了垃圾网页降级的处理精度和速度。
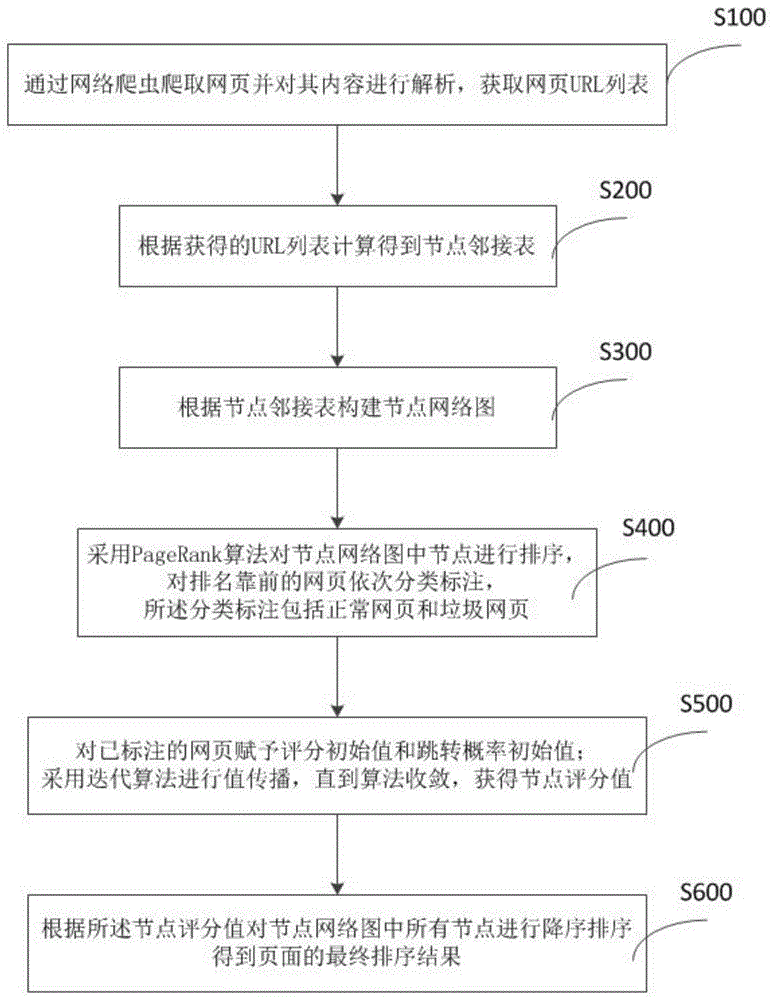
为达到上述目的,本发明采用的技术方案是:一种基于非概率模型的垃圾网页降级方法,包括步骤:
s100,通过网络爬虫爬取网页并对其内容进行解析,获取网页url列表;
s200,根据获得的url列表计算得到节点邻接表;
s300,根据节点邻接表构建节点网络图;
s400,采用pagerank算法对节点网络图中节点进行排序,对排名靠前的网页依次分类标注,所述分类标注包括正常网页和垃圾网页;
s500,对已标注的网页赋予评分初始值和跳转概率初始值;采用迭代算法进行值传播,直到算法收敛,获得节点评分值;
s600,根据所述节点评分值对节点网络图中所有节点进行降序排序,得到页面的最终排序结果。
进一步的是,将所获取网页的url链接和其链出的url链接以邻接表的形式存储在数据库中。
进一步的是,根据邻接表构建的节点网络图结构为g=(v,e),g为有向无权图;
其中,v为所有节点的集合,e为所有边的集合;
如果节点vi存在,且存在由节点vi指向节点vj的链接,则有<vi,vj>∈e;对于任意节点vi,指向自己的链接不包含在e中,即
进一步的是,在所述步骤s400中,对排名靠前的网页进行分类标注,包括步骤:
从排名最高的节点开始,依次进行标注,直到标注的正常网页和垃圾网页数量均不少于100个;标注后的正常网页集合为sn,垃圾网页集合为ss。
进一步的是,在所述步骤s500中,采用迭代算法进行值传播,直到算法收敛,获得节点评分值,包括步骤:
对每一个节点vi,记g(vi)表示其正向排序值,b(vi)表示其逆向排序值,in(vi)表示vi的父节点集合,out(vi)表示vi的子节点集合;
采用迭代算法计算每个节点的g(vi)和b(vi),计算公式为:
其中,
g(vi)和b(vi)的初始值由ig(vi)和ib(vi)计算;λ取值0.85;算法迭代次数为100次。
进一步的是,根据所述节点评分值对节点网络图中所有节点进行降序排序时,节点vi的g(vi)和b(vi)用来作为节点是正常网页和垃圾网页的非归一化概率近似值;若g(vi)越大,则节点vi是正常网页的可能性越大;若b(vi)越大,则节点vi是垃圾网页的可能性越大。
进一步的是,在所述传播过程中,源节点传播的值经过两次衰减,一次衰减使用源节点的信息,一次衰减使用目标节点的信息,计算过程为:
节点vi的不衰减传播值为:
节点vi为正常页面的概率为:
节点vj为正常页面的概率为:
若<vi,vj>∈e,则将p(vi)和p(vj)作为衰减因子得到节点vi传播给节点vj的值为:
其中,|out(vi)|为节点vi的子节点数。
采用本技术方案的有益效果:
本发明使用网络节点间的链接结构来计算节点评分值,根据节点评分值对网页排序,通过评分值的传播指向特性,实现垃圾网页降级处理,尽最大可能提升正常网页在搜索引擎中的排名,同时降低垃圾网页的排名,有效提高了垃圾网页降级的处理精度和速度;
本发明方法无需建立复杂且庞大的概率模型,节约了网络存储资源和计算资源,大大提高了垃圾网页降级的处理速度和精度。
附图说明
图1为本发明的一种基于非概率模型的垃圾网页降级方法流程示意图;
图2为本发明实施例中节点网络图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面结合附图对本发明作进一步阐述。
在本实施例中,参见图1所示,本发明提出了一种基于非概率模型的垃圾网页降级方法,包括步骤:
s100,通过网络爬虫爬取网页并对其内容进行解析,获取网页url列表;
s200,根据获得的url列表计算得到节点邻接表;
s300,根据节点邻接表构建节点网络图;
s400,采用pagerank算法对节点网络图中节点进行排序,对排名靠前的网页依次分类标注,所述分类标注包括正常网页和垃圾网页;
s500,对已标注的网页赋予评分初始值和跳转概率初始值;采用迭代算法进行值传播,直到算法收敛,获得节点评分值;
s600,根据所述节点评分值对节点网络图中所有节点进行降序排序,得到页面的最终排序结果。
作为上述实施例的优化方案,将所获取网页的url链接和其链出的url链接以邻接表的形式存储在数据库中。
作为上述实施例的优化方案,根据邻接表构建的节点网络图结构为g=(v,e),g为有向无权图;
其中,v为所有节点的集合,e为所有边的集合;
如果节点vi存在,且存在由节点vi指向节点vj的链接,则有<vi,vj>∈e;对于任意节点vi,指向自己的链接不包含在e中,即
作为上述实施例的优化方案,在所述步骤s400中,对排名靠前的网页进行分类标注,包括步骤:
从排名最高的节点开始,依次进行标注,直到标注的正常网页和垃圾网页数量均不少于100个;标注后的正常网页集合为sn,垃圾网页集合为ss。
作为上述实施例的优化方案,在所述步骤s500中,采用迭代算法进行值传播,直到算法收敛,获得节点评分值,包括步骤:
对每一个节点vi,记g(vi)表示其正向排序值,b(vi)表示其逆向排序值,in(vi)表示vi的父节点集合,out(vi)表示vi的子节点集合;
采用迭代算法计算每个节点的g(vi)和b(vi),计算公式为:
其中,
g(vi)和b(vi)的初始值由ig(vi)和ib(vi)计算;λ取值0.85;算法迭代次数为100次。
根据所述节点评分值对节点网络图中所有节点进行降序排序时,节点vi的g(vi)和b(vi)用来作为节点是正常网页和垃圾网页的非归一化概率近似值;若g(vi)越大,则节点vi是正常网页的可能性越大;若b(vi)越大,则节点vi是垃圾网页的可能性越大。
在所述传播过程中,源节点传播的值经过两次衰减,一次衰减使用源节点的信息,一次衰减使用目标节点的信息,计算过程为:
节点vi的不衰减传播值为:
节点vi为正常页面的概率为:
节点vj为正常页面的概率为:
若<vi,vj>∈e,则将p(vi)和p(vj)作为衰减因子得到节点vi传播给节点vj的值为:
其中,|out(vi)|为节点vi的子节点数。
如图2中的节点网络图实例中:
out(v1)={v2,v3,v4},|out(v1)|=3
v1的不衰减传播值为:
v1为正常页面的概率为:
v2为正常页面的概率为:
将p(v1)和p(v2)作为衰减因子得到节点v1传播给节点v2的值为:
本发明提供的基于非概率模型的节点重要性算法能够有效降低在基于pagerank排序算法的搜索引擎中垃圾网页的排名。在公开的数据集webspam-uk2006和webspam-uk2007上本发明提供的算法均取得了比经典算法trustrank、pagerank、anti-trustrank等更好的效果。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!