一种基于图像识别的无人车停车方法、系统及存储介质与流程
本发明涉及无人驾驶汽车技术视觉引导领域,更具体地说,涉及一种基于图像识别的无人车停车方法、系统及存储介质。
背景技术:
随着社会经济的发展与科学技术的不断进步,智能交通系统逐渐成为未来人类交通系统发展的趋势,而无人驾驶技术在其中扮演着十分重要的角色。工业园区、校园、旅游景点、港口码头等园区是无人车目前应用较多的场所。
目前,无人车在相关园区内的巡航和停车,大多数都通过程序设定识别处理一些停车指令,如根据手势指令停车或根据交通标识信息停车,但同时遇到人和交通标识或其他一些复杂环境时容易产生混乱。
中国专利申请,申请号cn201810979341.6,公开日2020年3月3日,公开了一种交警手势识别方法、装置、整车控制器及存储介质,其方法包括:实时获取车辆前方的路况图像;当从所述路况图像中检测到交警目标时,根据预先建立的骨骼关键点检测模型,获取所述交警目标的骨骼关键点及所述骨骼关键点在预设坐标系的坐标位置;根据所述骨骼关键点的坐标位置,获取所述交警目标的身体朝向;当所述交警目标的身体朝向为面向所述车辆的车道方向时,根据所述骨骼关键点以及预先建立的交警指挥动作识别模型,识别所述交警目标的指挥手势类型;该发明实现自动识别道路交警指挥动作含义的功能,提升驾驶智能化水平,其不足之处在于,该发明只能对交警的手势进行识别,不能识别交通标识。
技术实现要素:
1.要解决的技术问题
针对目前园区内无人车停车方案空缺和现有技术中存在的交通标识与手势共存时的识别效果不佳的问题,本发明提供了一种基于图像识别的无人车停车方法、系统及存储介质,它可以同时对交通标识与手势进行识别,并根据优先级进行处理,解决了交通标识与手势共存的识别问题,提高了识别准确率。
2.技术方案
本发明的目的通过以下技术方案实现。
一种基于图像识别的无人车停车方法,包括以下步骤:
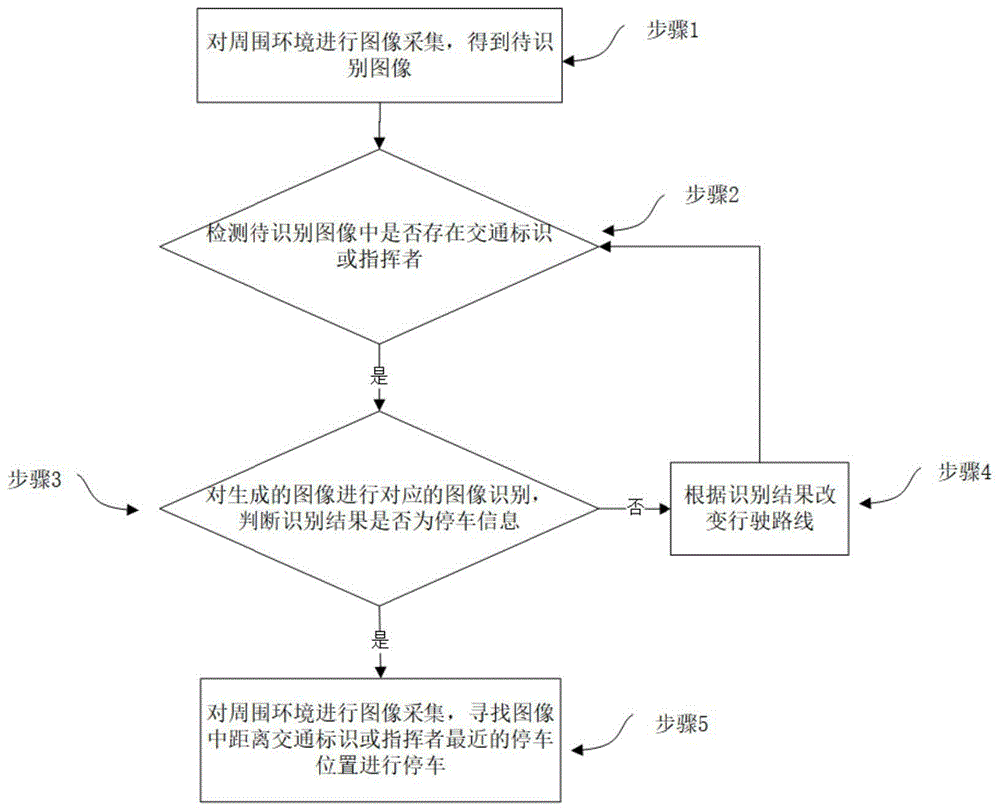
步骤1、对周围环境进行图像采集,得到待识别图像;
步骤2、检测待识别图像中是否存在交通标识或指挥者,若存在,则生成对应的图像,进入步骤3,否则继续按照预设路线行进;
步骤3、对生成的图像进行对应的图像识别,判断识别结果是否为停车信息,如果不是,进入步骤4,否则进入步骤5;
步骤4、根据识别结果改变行驶路线,返回步骤1;
步骤5、对周围环境进行图像采集,寻找图像中距离交通标识或指挥者最近的停车位置进行停车。
进一步的,步骤2中检测待识别图像中是否存在交通标识或指挥者,具体包括以下步骤:
步骤2.1、建立标识检测模型,并对其进行训练;
步骤2.2、运用训练好的标识检测模型对待识别图像进行目标检测,判断待识别图像中是否有交通标识或指挥者,如果有,则获取交通标识或指挥者所在区域,并生成对应的交通标识图案或人像图案。
更进一步的,步骤2.3中运用训练好的标识检测模型对待识别图像进行目标检测,判断待识别图像中是否有交通标识或指挥者,具体包括以下步骤:
利用主干特征提取网络convlayers提取待识别图像的featuremaps;
将featuremaps传入prn区域建议网络,并生成建议框anchors,通过softmax层对建议框分类得到包含目标图像的positiveanchors,利用boundingboxregression边框回归来修正建议框,获取更加精准的proposals;
将前两步得到的featuremaps和proposals送入rolpooling层计算出proposalsfeaturemaps,将proposalsfeaturemaps送入后续网络;
通过全连接层和softmax计算每个目标检测框proposal的种类,并再次利用boundingboxregression边框回归对目标检测框的位置进行修正;
当识别出目标时,根据目标的种类将检测框的位置向量[x,y,h,w]送入对应的识别模型进行识别,其中x和y分别为检测框中心点横纵坐标,h和w分别为检测框的长度和宽度。
更进一步的,步骤3中对生成的图像进行对应的图像识别,具体包括以下步骤:
步骤3.1、根据图像的种类选择对应的图像识别模型,如果识别结果存在人像图案,则进入步骤3.2,否则进入步骤3.3;
步骤3.2、对人像图案进行手势识别,得到对应的识别结果;
步骤3.3、对交通标识进行交通标识识别,得到对应的识别结果。
更进一步的,步骤3中对交通标识进行交通标识识别的模型为超分辨率重建卷积神经网络模型,对人像图案进行手势识别的模型为3d卷积神经网络模型。
一种基于图像识别的无人车停车系统,包括:
图像采集单元,用于对周围环境进行图像采集,得到待识别图像;
标识检测单元,用于检测待识别图像中是否存在交通标识或指挥者,若存在,则生成对应的图像,进入图像分类单元,否则继续按照预设路线行进;
图像分类识别单元,用于对待识别图像进行图像识别,判断识别结果是否为停车信息,如果不是,进入路线变更单元,否则进入停车单元;
路线变更单元,用于根据识别结果改变行驶路线,返回图像采集单元;
停车单元,用于对周围环境进行图像采集,寻找图像中距离交通标识或指挥者最近的停车位置进行停车。
进一步的,标识检测单元包括:
模型训练模块,用于建立标识检测模型,并对其进行训练;
图像检测模块,用于运用训练好的标识检测模型对待识别图像进行目标检测,判断待识别图像中是否有交通标识或指挥者,如果有,则获取交通标识或指挥者所在区域,并生成对应的交通标识图案或人像图案。
更进一步的,图像分类识别单元包括:
模型选择模块,用于根据图像的种类选择对应的图像识别模型,如果识别结果存在人像图案,则进入手势识别模块,否则进入交通标识识别模块;
手势识别模块,用于对人像图案进行手势识别,得到对应的识别结果;
交通标识识别模块,用于对对交通标识进行交通标识识别,得到对应的识别结果。
一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述停车方法的步骤。
3.有益效果
相比于现有技术,本发明的优点在于:
本发明通过在无人车上设置有第一识别摄像头和第二识别摄像头,通过第一识别摄像头对停车标识的检测,同时配合第二识别摄像头对地面车位线识别定位,使得无人车能够精准地停在预设位置;首先对第一识别摄像头获取的图像进行检测,在对交通标识或指挥者手势进行检测和识别的过程中,将识别框架分为基于目标检测和精细分类两个阶段,保证更高的召回率和准确率;目标检测用于检测图像中是否存在交通标识或指挥者,如果存在,则对图像进行处理,并对其进一步的精细分类识别,根据图像中存在的是交通标识还是指挥者,进而选择对应的识别模型,分类模块分别为手势和交通标识的识别配置独立的精细分类网络3dcnn和srcnn,不仅能够保留手势指令图像在时间维度上的相关特征信息,将多种因素导致拍摄结果较低分辨率的交通标识转化为高分辨率图像,提高识别的准确率,并且这种独立设计的方式便于多人同时研发,缩短研发周期。对指挥者的手势和交通标识指令信息进行综合识别,可以随时改变无人车的停车地点,使无人车的停车地停车方式更灵活、地点更多样;本发明通过提前对不同识别对象和命令信息优先级的设定,能够在人和标识同时存在等较复杂环境下更高效地完成无人车停车动作。相对于基于穿戴设备和基于人工提取特征的识别技术进行手势识别停车更具有机动性、通用性和高效性等特点。
附图说明
图1为本发明实施例中的无人车停车方法流程图;
图2为本发明实施例中的识别手势示意图;
图3为本发明实施例中的识别标识示意图;
图4为本发明实施例中的无人车停车系统框图。
具体实施方式
下面结合说明书附图和具体的实施例,对本发明作详细描述。
如图1所示,本发明的一个实施例提供了一种基于图像识别的无人车停车方法,包括以下步骤:
步骤1、车辆按照预设线路行进,对周围环境进行图像采集,得到待识别图像。
具体的,本实施例中,所述预设线路为预先根据出发地和目的地设定好的最优路径,所述车辆为园区中的无人车,无人车上预先安装有两个识别摄像头,其中第一识别摄像头安装在无人车前方顶部并稍稍上倾,用于对周围环境进行图像采集;第二识别摄像头为广角摄像头,安装在无人车安装在无人车正前方且倾斜朝下,用于寻找停车线的位置。
车辆在进入园区后,第一识别摄像头会对无人车四周环境进行实时采集,得到视频图像,并从所述视频影像中逐帧提取获得图像帧,即待识别图像,用于后续的图像识别。
步骤2、检测待识别图像中是否存在交通标识或指挥者,若存在,则生成对应的图像,进入步骤3,否则返回步骤1,按照预设路线继续行进。
具体的,检测待识别图像中是否存在交通标识或指挥者,具体包括以下步骤:
步骤2.1、建立标识检测模型,并对其进行训练;
具体的,本实施例中,使用fasterrcnn网络模型作为标识检测模型,fasterrcnn网络模型具有识别精度高、速度快的优点,可以高效快速地对指挥者和交通标识进行识别,通过大量的人像图案和交通标识图案对标识检测模型进行训练,得到能够快速识别交通标识图案和人像图案的检测模型,所述人像图案和交通标识图案的类型如图2和图3所示。
步骤2.2、运用训练好的标识检测模型对待识别图像进行目标检测,判断待识别图像中是否有交通标识或指挥者,如果有,则获取交通标识或指挥者所在区域,并生成对应的交通标识图案或人像图案。
具体的,本实施例中,标识检测模型用于识别待识别图像中是否存在交通标识或者指挥者,从而根据识别结果选择对应的识别模型,当识别到有交通标识或者指挥者时,获取交通标识或指挥者所在区域,并生成对应的待识别的交通标识图案或指挥者的人像图案。
步骤2.2中运用训练好的标识检测模型对待识别图像进行目标检测,判断待识别图像中是否有交通标识或指挥者,具体包括以下步骤:
(1)利用主干特征提取网络convlayers提取视频图像的featuremaps;
(2)将featuremaps传入prn区域建议网络,并生成建议框anchor,通过softmax层对建议框分类得到包含目标图像的positiveanchors,利用boundingboxregression边框回归来修正建议框,获取更加精准的proposals;
(3)将前两步得到的featuremaps和proposals送入rolpooling层计算出proposalsfeaturemaps,并将featuremaps送入后续网络,所述后续网络为全连接层;
(4)通过全连接层和softmax计算每个目标检测框proposal的种类,并再次利用boundingboxregression边框回归对目标检测框的位置进行修正;
(5)当识别出目标时,根据目标的种类将检测框的位置向量[x,y,h,w]送入对应的识别模型进行识别,其中x和y分别为检测框中心点横纵坐标,h和w分别为检测框的长度和宽度,对应得识别模型为步骤3中的超分辨率重建卷积神经网络模型或3d卷积神经网络模型。
步骤3、对生成的图像进行对应的图像识别,判断识别结果是否为停车信息,如果不是,进入步骤4,否则进入步骤5。
具体的,对生成的图像进行对应的图像识别,具体包括以下步骤:
步骤3.1、根据图像的种类选择对应的图像识别模型,如果识别结果存在人像图案,则进入步骤3.2,否则进入步骤3.3。
具体的,在步骤2中,标识检测模型对待识别图像进行了标识检测,生成了交通标识或人像图案,在对图像进行对应的图像识别之前,需要确定对应的图像识别模型。由于现实中可能会有交通标识和指挥者同时存在,如交通管制时,此时如果不进行对应的处理,会出现识别混乱的情况,因此,本方法预先设定好指令的优先级,本实施例中设置指挥者手势图像的优先级高于交通标识,当图像中存在指挥者时,直接选择指挥者图像对应的手势识别模型进行识别,不对交通标识进行处理,一方面解决了交通标识与指挥者共存时的识别混乱问题,另一方面减少了所需算力,提高了识别速度。
对于交通标识的识别,本实施例采用了超分辨率重建卷积神经网络(srcnn)模型,针对交通标识识别采取基于srcnn的方法,可以将车辆行驶速度较快、光线较暗等原因导致拍摄分辨率低的标识图像还原为高分辨率图像,可以有效改善对低分辨率图像对识别准确率的影响;对于指挥者的手势图像识别,本实施例采用了3d卷积神经网络(3dcnn)模型,2d卷积神经网络在进行视频识别时容易丢失目标在时间维度上的相关特征信息,导致识别准确率降低,因此使用基于3d卷积神经网络模型的手势识别方法。这种独立设计的方式便于多人同时研发,缩短研发周期。
步骤3.2、对人像图案进行手势识别,得到对应的识别结果。
具体的,本实施例中,对人像图案进行手势识别,包括以下步骤:
(1)将接受到的视频图像进行归一化处理,用于统一帧数和各帧的宽度高度,得到32帧的rgb输入视频;
(2)从rgb视频中利用idt算法提取光流特征,生成32帧光流视频;
(3)将32帧的rgb视频和光流视频分别通过c3d模型提取特征;
(4)将得到的rgb特征和光流特征拼接融合。
(5)将融合得到的高维特征输入到svm分类器进行分类,得到分类结果。
步骤3.3、对交通标识进行交通标识识别,得到对应的识别结果。
具体的,本实施例中,对交通标识进行交通标识识别,包括以下步骤:
(1)通过srcnn算法对交通标识图像进行超分辨率重建,得到重建后的图像;
(2)对lenet-5卷积神经网络进行训练,得到lenet-5卷积神经网络模型;
(3)通过训练好的卷积神经网络模型,对重建后的图像进行识别,得到识别结果。
步骤4、根据识别结果改变行驶路线,返回步骤2;
具体的,本实施例中,根据步骤3中得到的识别结果改变形式路线,识别结果包括交通标识指令信号和手势指令信号。
交通标识包括:(1)直行信号,无人车响应结果为继续直行;(2)左转信号,无人车响应结果为向左转;(3)右转信号,无人车响应结果为向右转(4)停车信号,无人车进行停车。
手势指令信号:(1)跟随信号,无人车响应结果为跟随人的位置继续行驶;(2)停止跟随信号,无人车响应结果为停止跟随,等待下一步指令;(3)转向信号,无人车响应结果为按照指令进行转向,转向完成后直行;(4)停车信号,无人车进行停车。
步骤5、对周围环境进行图像采集,寻找图像中距离交通标识或指挥者最近的停车位置进行停车。
具体的,当步骤3的识别结果为停车信息时,无人车上的第二识别摄像头对周围环境进行图像采集,本实施例中使用现有的自动泊车系统的控制算法进行停车。
如图4所示,本发明的又一个实施例提供了一种基于图像识别的无人车停车系统,用于实现上述无人车停车方法,所述停车系统包括:
图像采集单元,用于对周围环境进行图像采集,得到待识别图像;
标识检测单元,用于检测待识别图像中是否存在交通标识或指挥者,若存在,则生成对应的图像,进入图像分类单元,否则继续按照预设路线行进;
图像分类识别单元,用于对待识别图像进行图像识别,判断识别结果是否为停车信息,如果不是,进入路线变更单元,否则进入停车单元;
路线变更单元,用于根据识别结果改变行驶路线,返回图像采集单元;
停车单元,用于对周围环境进行图像采集,寻找图像中距离交通标识或指挥者最近的停车位置进行停车。
具体的,上述标识检测单元包括:
模型训练模块,用于建立标识检测模型,并对其进行训练;
图像检测模块,用于运用训练好的标识检测模型对待识别图像进行目标检测,判断待识别图像中是否有交通标识或指挥者,如果有,则获取交通标识或指挥者所在区域,并生成对应的交通标识图案或人像图案。
具体的,上述图像分类识别单元包括:
模型选择模块,用于根据图像的种类选择对应的图像识别模型,如果识别结果存在人像图案,则进入手势识别模块,否则进入交通标识识别模块;
手势识别模块,用于对人像图案进行手势识别,得到对应的识别结果;
交通标识识别模块,用于对对交通标识进行交通标识识别,得到对应的识别结果。
本实施例中的系统通过使用无人车停车方法实现无人车的交通标识和手势识别,从而控制无人车在园区行驶过程中的自动转向和停车
本申请的实施例也可以被实现为计算机可读存储介质,根据本申请实施例的计算机可读存储介质上存储有计算机可读指令,当所述计算机可读指令由处理器运行时,可以执行参照以上附图描述的根据本申请实施例的方法。所述计算机可读存储介质包括但不限于例如易失性存储器和/或非易失性存储器,所述易失性存储器例如可以包括随机存取存储器(ram)和/或高速缓冲存储器(cache)等,所述非易失性存储器例如可以包括只读存储器(rom)、硬盘、闪存等。
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
- 还没有人留言评论。精彩留言会获得点赞!