基于上下文的FAQ知识库的快速问答方法与流程
基于上下文的faq知识库的快速问答方法
技术领域
1.本发明涉及一种基于上下文的faq知识库的快速问答方法。
背景技术:
2.随着人工智能的发展和普及,智能客服机器人在各个行业的应用也越来越多了。对于所有领域的智能客服机器人来说,常见问答库是不可或缺的。常见问答库即给出了很多的问答对,如何根据真实的人工客服历史聊天记录的问答对,自动构建出基于知识库给出准确、有效答案的客服机器人,是智能客服机器人的研究热点和难点。
3.由于现有的faq机器人很多都是采用关键字等字面信息检索(如浏览器信息检索、电商商品检索等),或则规则模板式的检索对答案进行排序并返回。此种方式存在很大的语义鸿沟问题,很多时候检索出来的答案并不是用户需要的答案。现有faq机器人回复精度差、经常性的答非所问,而且没有上下文能力理解与推理能力,这些都是现有faq机器人的缺陷。
技术实现要素:
4.本发明提供了一种基于上下文的faq知识库的快速问答方法,采用如下的技术方案:
5.一种基于上下文的faq知识库的快速问答方法,包含以下步骤:
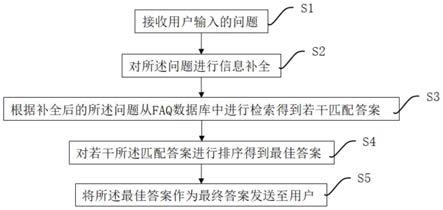
6.接收用户输入的问题;
7.对问题进行信息补全;
8.根据补全后的问题从faq数据库中进行检索得到若干匹配答案;
9.对若干匹配答案进行排序得到最佳答案;
10.将最佳答案作为最终答案发送至用户。
11.进一步地,对问题进行信息补全的具体方法为:
12.获取与该用户之前沟通的历史记录,历史记录包含该用户之前提出的所有问题以及对这些问题的回复;
13.根据历史记录对问题进行信息补全。
14.进一步地,对该用户分配一个用户id,根据用户id识别该用户的历史记录。
15.进一步地,通过缓存对该用户的历史记录进行保存;
16.当需要对问题进行信息补全时从缓存中调取历史记录。
17.进一步地,缓存为redis缓存。
18.进一步地,根据历史记录对问题进行信息补全的具体方法为:
19.对问题和历史记录进行语义分析;
20.根据语义分析结果自动从历史记录中获取补充信息对问题进行信息补全。
21.进一步地,语义分析包含句法分析、句子成分分析和指代消解。
22.进一步地,在将最佳答案作为最终答案发送至用户之前,基于上下文的faq知识库
的快速问答方法还包括:
23.通过意图识别模型识别补全后的问题的意图;
24.根据识别出的意图匹配预先设置的话术答案;
25.将最佳答案作为最终答案发送至用户的具体方法为:
26.根据预先设置的优先级配置从最佳答案和话术答案中选择一个作为最终答案发送至用户。
27.进一步地,优先级配置为:
28.当同时得到最佳答案和话术答案时,将话术答案作为最终答案发送至用户。
29.本发明的有益之处在于所提供的基于上下文的faq知识库的快速问答方法,具有上下文自动识别能力,能够对用户的提问进行自动补充,能够更好的识别用户的意图,从而更加准确的回答用户提出的问题。
附图说明
30.图1是本发明的基于上下文的faq知识库的快速问答方法的流程图。
具体实施方式
31.以下结合附图和具体实施例对本发明作具体的介绍。
32.如图1所示为本发明的一种基于上下文的faq(frequently asked questions,常见问题解答)知识库的快速问答方法,主要包含以下步骤:s1:接收用户输入的问题。s2:对问题进行信息补全。s3:根据补全后的问题从faq数据库中进行检索得到若干匹配答案。s4:对若干匹配答案进行排序得到最佳答案。s5:将最佳答案作为最终答案发送至用户。通过以上步骤,能够对用户的提问进行自动补充,能够更好的识别用户的意图,从而更加准确的回答用户提出的问题。以下具体介绍上述步骤。
33.对于步骤s1:接收用户输入的问题。
34.具体的,用户通过智能终端向智能机器人发送问题。
35.对于步骤s2:对问题进行信息补全。
36.对问题进行信息补全的具体方法为:获取与该用户之前沟通的历史记录,历史记录包含该用户之前提出的所有问题以及对这些问题的回复。根据历史记录对问题进行信息补全。
37.具体的,每个用户均被分配一个用户id,根据用户id识别该用户的历史记录。当用户与智能机器人进行沟通时,通过缓存对用户的历史记录进行保存。当需要对问题进行信息补全时从缓存中调取历史记录。在本发明中,缓存为redis缓存。
38.其中,根据历史记录对问题进行信息补全的具体方法为:对问题和历史记录进行语义分析。根据语义分析结果自动从历史记录中获取补充信息对问题进行信息补全。其中,语义分析包含句法分析、句子成分分析和指代消解等。
39.对于智能机器人的上下文能力评估,需要抽取出大量包含省略句、指代句的对话数据,以对话的形式评测其上下文信息处理与推理能力。以对话数据为单位,统计出智能机器人能够正确处理的上下文的对话数作为精度值,即机器人的上下文处理能力。
40.对于步骤s3:根据补全后的问题从faq数据库中进行检索得到若干匹配答案。
41.具体的,将收集到的所有faq数据写信息检索工具库,如es(elasticsearch)等,通过es字面检索、模糊查询等方式召回若干与问题相关性大的faq数据,即若干匹配答案。
42.对于步骤s4:对若干匹配答案进行排序得到最佳答案。
43.在步骤s3的基础上,再通过如孪生网络siamese network、基于交互矩阵的match pyramid等深度语义匹配方式打分,还可以加上词移距离相似度得分、编辑距离得分、关键词得分等各种得分进行结果归并和重排序,最后得到得分最高的最佳答案。
44.在本发明中,对于检索结果的评价,可以采用平行语料的方式给予评价。平行语料构建方法如下:对于知识库里的每一条知识的问题,构建n条相似问句,从n条相同语义的问句中随机挑选一条作为用户的问题,其他的数据作为faq知识库的内容,这样对于每一个问题即可计算出基于信息检索与语义重排序的答案的top精度与top n精度值。可以以计算出的top精度与top n精度值作为评价标准。
45.对于步骤s5:将最佳答案作为最终答案发送至用户。
46.将步骤s4中得到的最佳答案发送至用户。
47.作为一种可选的实施方式,在将最佳答案作为最终答案发送至用户之前,基于上下文的faq知识库的快速问答方法还包括:通过意图识别模型识别补全后的问题的意图。根据识别出的意图匹配预先设置的话术答案。具体而言,将所有的faq数据进行特征抽取、语义聚类等抽取出faq数据中的头部经常询问的问题,并归纳出一些头部问题对应的意图和对应的代表性数据,以此构造出一个训练集训练意图识别模型。为了提高意图识别模型的效果,增加人工数据清洗、打标工作。对于头部的高频问题,可以通过意图识别的方案在每个意图下配置一个高质量的话术作为答案,以增加用户使用体感。意图识别模型即为一个多分类器,可以采用分类常用的指标准确率、召回率、f1值等指标作为评估标准。
48.此时,步骤s5的将最佳答案作为最终答案发送至用户的具体方法为:根据预先设置的优先级配置从最佳答案和话术答案中选择一个作为最终答案发送至用户。
49.作为一种优选的实施方式,优先级配置为:当同时得到最佳答案和话术答案时,将话术答案作为最终答案发送至用户。
50.以上显示和描述了本发明的基本原理、主要特征和优点。本行业的技术人员应该了解,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1