算术编码或算术解码的方法和设备与流程
技术领域
本发明涉及多媒体数据的算术编码和解码。
背景技术:
算术编码是一种数据无损压缩的方法。算术编码基于概率密度函数(PDF)。为了达到压缩效果,编码所基于的概率密度函数必须与数据实际遵循的实际概率密度函数相同或至少相似—越接近越好。
如果算术编码基于适当概率密度函数,则可以实现导致至少几乎最佳代码的显著压缩。因此,在编码和解码系数序列的音频、语音或视频编码中,算术编码是一种频繁使用技术,其中这些系数是用二进制表示的视频像素或音频或语音信号样本值的量化时频变换。
为了进一步提高压缩,算术编码可以基于一组概率密度函数,其中用于编码当前系数的概率密度函数取决于所述当前系数的背景。也就是说,取决于出现具有相同量化值的系数的背景,可以将不同概率密度函数用于编码所述相同量化值。系数的背景通过包含在与各自系数相邻的一个或多个相邻系数的邻域,例如,序列中相邻地在要编码或要解码的各自系数前面的一个或多个已编码或已解码系数的子序列中的系数的量化值来定义。邻域可能出现的每种不同可能定义每一种被映射成概率密度函数的不同可能背景。
事实上,只有当邻域足够大时所述压缩提高才变得明显。随之而来的是不同可能背景的数量的组合激增以及相应数量巨大的可能概率密度函数或相应复杂映射。
在如下文献中可以找到基于背景算术编码方案的一个例子:ISO/IEC JTC1/SC29/WG11 N10215,October 2008,Busan,Korea,提出统一语音和音频编码(USAC)的参考模型。按照该建议,将已经编码的4元组(4-tuples)考虑为背景。
在如下文献中可以找到基于USAC相关背景算术编码的另一个例子:ISO/IEC JTC1/SC29/WG11N10847,July 2009,London,UK。
为了降低高阶条件熵编码中的复杂性,美国专利5,298,896提出了限定码元(symbol)的非均匀量化。
技术实现要素:
与要处理的数量巨大背景相对应,存在需要存储,检索和处理的数量巨大概率密度函数或从背景到概率密度函数的至少相应复杂映射。这提高了编码/解码延迟和存储容量要求的至少一种。因此,在技术上需要一种允许在降低编码/解码延迟和存储容量要求的至少一种的同时,几乎一样好地实现压缩的可替代解决方案。
为了解决这种需要,根据实施例,本发明提出了用于使用前谱系数算术解码当前谱系数的设备和用于使用前谱系数算术编码当前谱系数的设备,如文中所述。
一种使用前谱系数算术解码当前谱系数的设备,所述前谱系数是已经解码的,其中所述前谱系数和所述当前谱系数被包含在对时频变换的视频、音频或语音信号样本值进行量化所得的一个或多个量化谱中,所迷设备包含:
-处理前谱系数的处理部件;
-从至少两个不同背景类别确定背景类别的第一部件,所述第一部件适用于将处理后前谱系数用于确定背景类别,
其中将前谱系数的量化绝对值之和用于背景类别的确定;
-确定概率密度函数的第二部件,所述第二部件适用于将所确定背景类别和从至少两个不同背景类别到至少两个不同概率密度函数的映射用于确定概率密度函数;
-根据所确定概率密度函数算术解码当前谱系数的算术解码器,
其中所述处理部件适用于非均匀地量化前谱系数的绝对值以便在背景类别的确定中使用;
其中所述第一部件适用于接收模式切换信号和复位信号的至少一个;并且其中所述第一部件适用于将至少一个所接收信号用于控制确定背景类别的步骤,
其中所述第二部件被配置为使用查找表或散列表实现所述映射。
一种使用前谱系数算术编码当前谱系数的设备,所述前谱系数是已经编码的,其中所述前谱系数和所述当前谱系数被包含在对时频变换的视频、音频或语音信号样本值进行量化所得的一个或多个量化谱中,所述设备包含:
-处理前谱系数的处理部件;
-从至少两个不同背景类别确定背景类别的第一部件,所述第一部件适用于将处理后前谱系数用于确定背景类别,
其中将前谱系数的量化绝对值之和用于背景类别的确定;
-确定概率密度函数的第二部件,所述第二部件适用于将所确定背景类别和从至少两个不同背景类别到至少两个不同概率密度函数的映射用于确定概率密度函数;
-根据所确定概率密度函数算术编码当前谱系数的算术编码器,
其中所述处理部件适用于非均匀地量化前谱系数的绝对值以便在背景类别的确定中使用;
其中所述第一部件适用于插入模式切换信号和复位信号的至少一个;并且其中所述第一部件适用于将至少一个所插入信号用于控制确定背景类别的步骤,
其中所述第二部件被配置为使用查找表或散列表实现所述映射。
算术编码或解码的所述方法将前谱系数分别用于当前谱系数的算术编码或解码,其中所述前谱系数是已经分别编码或解码的。所述前谱系数和所述当前谱系数两者都被包含在视频、音频或语音信号样本值的量化时频变换所得的一个或多个量化谱中。所述方法进一步包含处理前谱系数,将处理后前谱系数用于确定作为至少两个不同背景类别之一的背景类别,将所确定背景类别和从至少两个不同背景类别到至少两个不同概率密度函数的映射用于确定概率密度函数,以及根据所确定概率密度函数算术分别编码或解码当前谱系数。该方法的一个特征是处理前谱系数包含非均匀地量化前谱系数的绝对值。
将背景类别替代背景用于确定概率密度函数便于将得出不同但非常相似概率密度函数的两个或更多个不同背景分组成映射到单个概率密度函数的单 个背景类别。该分组是通过将前谱系数的非均匀量化绝对值用于确定背景类别实现的。
例如,存在处理前谱系数包含确定前谱系数的量化绝对值之和以便用在确定背景类别中的实施例。类似地,存在算术编码设备的相应实施例,以及算术解码设备的相应实施例,其中的处理部件适用于确定前谱系数的量化绝对值之和以便用于确定背景类别。
在设备的进一步实施例中,所述处理部件适用于使处理前谱系数进一步包含按照第一量化方案量化前谱系数的绝对值的第一量化、确定按照第一量化方案量化的前谱系数的绝对值的方差的方差确定、将所确定方差用于选择至少两种不同非线性第二量化方案之一、和按照所选择非线性第二量化方案进一步量化按照第一量化方案量化的前谱系数的绝对值的第二量化。所述方法的进一步实施例包含相应步骤。所述方差确定可以包含确定按照第一量化方案量化的前谱系数的绝对值之和,并将所确定和值与至少一个阈值相比较。
在进一步实施例中,每种设备的所述处理部件可以适用于使处理导致第一后果或至少一个不同第二后果。然后,确定背景类别进一步包含确定对其处理导致第一后果的那些前谱系数的数量,并将所确定数量用于确定背景类别。
每种设备可以包含接收模式切换信号和复位信号的至少一种的部件,其中所述设备适用于将所接收信号的至少一种用于控制背景类别的确定。
所述至少两个不同概率密度函数可以通过将代表性数据集用于确定至少两个不同概率密度函数事先确定,所述映射可以使用查找表或散列表实现。
附图说明
本发明的示范性实施例例示在附图中,并在如下描述中得到更详细说明。这些示范性实施例只是为了阐明本发明,而不是限制定义在权利要求书中的本发明范围和精神而说明的。
在附图中:
图1示范性地描绘了本发明编码器的一个实施例;
图2示范性地描绘了本发明解码器的一个实施例;
图3示范性地描绘了确定背景类别的背景分类器的第一实施例;
图4示范性地描绘了确定背景类别的背景分类器的第二实施例;
图5a示范性地描绘了要在频域模式下编码或解码的当前谱区(bin)之前的前谱区的第一邻域;
图5b示范性地描绘了要在加权线性预测变换模式下编码或解码的当前谱区之前的前谱区的第二邻域;
图6a示范性地描绘了要在频域模式下编码或解码的当前最低频谱区之前的前谱区的第三邻域;
图6b示范性地描绘了要在频域模式下编码或解码的当前次最低频谱区之前的前谱区的第四邻域;
图7a示范性地描绘了要在加权线性预测变换模式下编码或解码的当前最低频谱区之前的前谱区的第五邻域;
图7b示范性地描绘了要在加权线性预测变换模式下编码或解码的当前次最低频谱区之前的前谱区的第六邻域;
图7c示范性地描绘了要在加权线性预测变换模式下编码或解码的当前第三最低频谱区之前的前谱区的第七邻域;
图7d示范性地描绘了要在加权线性预测变换模式下编码或解码的当前第四最低频谱区之前的前谱区的第八邻域;
图8示范性地描绘了要编码或解码的不同谱区的邻域,所述不同谱区包含在要在频域模式下开始编码/解码或出现复位信号之后编码或解码的第一频谱中;以及
图9示范性地描绘了要在加权线性预测变换模式下编码或解码的不同谱区的进一步邻域,所述不同谱区被包含在要在在加权线性预测变换模式下开始编码/解码或出现复位信号之后编码或解码的第二频谱中。
具体实施方式
本发明可以在包含相应适配的处理设备的任何电子设备上实现。例如,算术解码的设备可以在电视机、移动电话、个人计算机、mp3播放器、导航系统或汽车音响系统中实现。算术编码的设备可以在移动电话、个人计算机、有源汽车导航系统、数字照相机、数字摄像机或录音机等中实现。
下文描述的示范性实施例涉及量化多媒体样本的时频变换所得的量化谱区的编码或解码。
本发明基于将已经发射量化谱区,例如,序列中当前量化谱区BIN之前 的前量化谱区用于确定用于分别算术编码和解码当前量化谱区BIN的概率密度函数的方式。
算术编码或算术解码的方法和设备的所述示范性实施例分别包含用于非均匀量化的步骤或部件。所有步骤或部件一起提供最高编码效率,但每个步骤或部件已单独实现本发明的构思,并提供与编码/解码延迟和/或存储要求有关的好处。因此,详细的描述应该理解为描述只实现所述的步骤或部件之一的示范性实施例,以及描述实现所述的步骤或部件的两个或更多个步骤或部件的组合的示范性实施例。
可以但无需包括在本方法的示范性实施例中的第一步骤是决定应该使用哪种一般变换模式的切换步骤。例如,在USAC无噪编码方案中,一般变换模式可以是频域(FD)模式或加权线性预测变换(wLPT)模式。每种一般模式可以将已编码或解码谱区的不同邻域,即,不同的选择用于确定PDF。
此后,可以在模块背景生成COCL下确定当前谱区BIN的背景。根据确定的背景,通过分类背景确定背景类别,其中在分类之前,最好但未必通过背景的谱区的非均匀量化NUQ1处理背景。分类可以包含估计背景的方差VES并将方差与至少一个阈值相比较。或者,直接从背景中确定方差估计值。然后将方差估计值用于控制最好但未必非线性的进一步量化NUQ2。
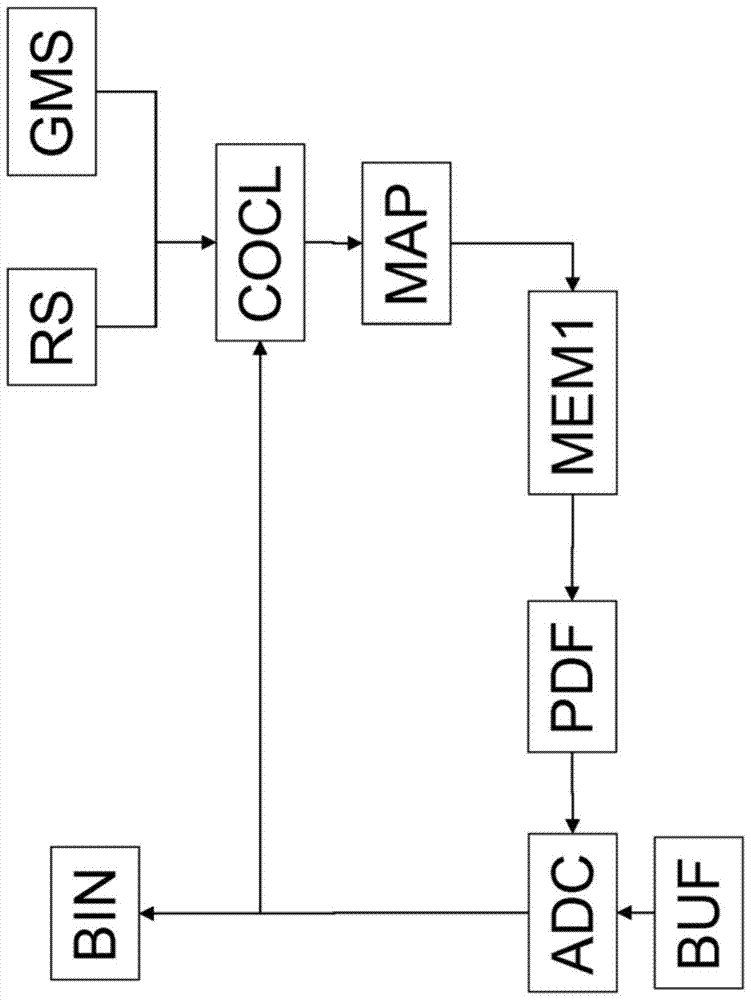
在示范性地描绘在图1中的编码过程中,确定适当概率密度函数(PDF)来编码当前量化谱区BIN。为此,只能使用在解码器方也已知的信息。也就是说,只能使用前编码或解码量化谱区。这是在背景分类器块COCL中完成的。在那里,所选前谱区定义用于确定实际背景类别的邻域NBH。背景类别可以通过背景类别号表示。背景类别号用于经由映射MAP,例如,经由查找表或散列表从PDF存储器MEM1中检索相应PDF。背景类别的确定可能取决于允许视所选模式而定使用不同邻域的一般模式开关GMS。如上所述,对于USAC,可能存在两种一般模式(FD模式和wLPT模式)。如果一般模式开关GMS是在编码器方实现的,则模式改变信号或当前一般信号必须被包含在位流中,以便解码器也知道它。例如,在ISO/IEC JTC1/SC29/WG11 N10847,2009年7月,英国伦敦,提出的统一语音和音频编码(USAC)的参考模型中,存在为发送一般模式而提出的表格4.4core_mode和表格4.5core_mode0/1。
在确定了适合算术编码器AEC编码当前量化谱区BIN的PDF之后,将 当前量化谱区BIN馈入邻域存储器MEM2中,即,当前谱区BIN变成前谱区。包含在邻域存储器MEM2中的前谱区可以被块COCL用于编码下一个谱区BIN。在存储当前谱区BIN期间,之前或之后,通过算术编码器AEC算术编码所述当前谱区BIN。将算术编码器AEC的输出存储在位缓冲器BUF中或直接写入位流中。
可以经由,例如,电缆或卫星发送或广播位流或缓冲器BUF的内容。或者,可以将算术编码谱区写在像DVD、硬盘、蓝光盘等那样的存储媒体上。PDF存储器MEM1和邻域存储器MEM2可以在单个物理存储器中实现。
复位开关RS可以便于不用知道前谱地在可以开始编码和解码的专用帧上不时重新开始编码或解码,专用帧被称为解码入口点。如果复位开关RS是在编码器方实现的,则复位信号必须被包含在位流中,以便解码器也知道它。例如,在ISO/IEC JTC1/SC29/WG11 N10847,2009年7月,英国伦敦,提出的统一语音和音频编码(USAC)的参考模型中,在WD表格4.10和表格4.14中存在arith_reset_flag。
在图2中示范性地描绘基于相应邻域的解码方案。它包含与编码方案相似的块。要用于算术解码的PDF的确定与编码方案相同,以保证在编码器和解码器两者中,确定的PDF相同。算术解码从位缓冲器BUF中或直接从位流中获取位,并使用确定的PDF解码当前量化谱区BIN。之后,解码的量化谱区馈入背景类别号确定块COCL的邻域存储器MEM2中,并可以用于解码下一个谱区。
图3更详细地示范性描绘了确定背景类别的背景分类器COCL的第一实施例。
在将当前量化谱区BIN存储在谱存储器MEM2中之前,可以在块NUQ1中对其进行非均匀量化。这具有两方面好处:其一,使通常是16位带码元整数值的量化谱区的存储更有效,其二,减少了每个量化谱区具有的值的数量。这使得在块CLASS中的背景类别确定过程中极大地减少了可能背景类别。更进一步,由于在背景类别确定中,可能舍弃了量化谱区的码元,所以可以在非均匀量化块NUQ1中包括绝对值计算。在表1中,示出了如块NUQ1可以进行的示范性非均匀量化。在本例中,在非均匀量化之后,每个谱区可能有三个不同值。但是,一般说来,非均匀量化的唯一约束是减少一个谱区可能采用的值的数量。
表1包括绝对值计算的示范性非均匀量化步骤
将非均匀量化/映射谱区存储在谱存储器MEM2中。按照所选一般模式选择GMS,对于要编码的每个谱区的背景类别确定CLASS,选择谱区的所选邻域NBH。
图5a示范性地描绘了要编码或解码的谱区的第一示范性邻域NBH。
在这个例子中,只将实际或当前频谱(帧)的谱区和一个前频谱(帧)的谱区定义成邻域NBH。当然,可以将不止一个前频谱的谱区用作邻域的一部分,这样会变得更加复杂,但最终也可能提供更高编码效率。注意,相对于实际频谱,只有已经发送的谱区才可以用于定义邻域NBH,因为在解码器上也必须可访问它们。这里,以及在下面的例子中,假设谱区的发送顺序从低频到高频。
然后,将所选邻域NBH用作背景类别确定块COCL的输入。在下文中,在描述特定实现之前,首先说明背景类别确定以及简化形式后面的总体思路。
背景类别确定后面的总体思路是使要编码的谱区的方差得到可靠估计。这个预测方差可以再次用于获取要编码的谱区的PDF的估计值。对于方差估计,没有必要评估邻域中的谱区的码元。因此,在存储在谱存储器MEM2中之前的量化步骤中已经可以舍弃码元。极简单背景类别确定看起来可能像如下那样:谱区BIN的邻域NBH看起来可能像图5a中那样,由7个谱区组成。如果使用在表1中所示的示范性非均匀量化,每个谱区可以具有3个值。这导致37=2187个可能背景类别。
为了进一步减少这种可能背景类别的数量,可以舍弃邻域NBH中的每个谱区的相对位置。因此,只计数分别具有0,1或2值的谱区的数量,其中0谱区的数量、1谱区的数量和2谱区的数量之和当然等于邻域中谱区的总数量。在包含每一个可以呈现三个不同值当中的一个的n个谱区的邻域NBH中,存在0.5*(n2+3*n+2)种背景类别。例如,在7个谱区的邻域中,存在36个可能背景类别,而在6个谱区的邻域中,存在28个可能背景类别。
更复杂但仍然相当简单背景类别确定考虑到有研究表明前谱相同频率的谱区特别重要(在图5a,5b,6a,6b,7a,7b,7c,8和9中用带点圆圈描绘的谱区)。对于邻域中的其它谱区,即,在各自图形中描绘成带横线圆圈的那些谱区,相关位置较不相关。因此,将前谱中相同频率的谱区显性地用于背景类别确定,而对于其它6个谱区,只计数0谱区的数量、1谱区的数量和2谱区的数量。这导致了3×28=84个可能背景类别。实验表明,这样的背景分类对于FD模式非常有效。
背景类别确定可以通过控制第二非均匀量化NUQ2的方差估计VES扩展。这使背景类别生成COCL更好地适用于要编码的谱区的预测方差的更高动态范围。在图4中示范性地示出扩展背景类别确定的相应框图。
在图4中所示的例子中,将非均匀量化分成两个步骤,其中前一个步骤提供较细量化(块NUQ1),后一步骤提供较粗量化(块NUQ2)。这便于该量化适用于,例如,邻域的方差。邻域的方差是在方差估计块VES中估计的,其中该方差估计基于块NUQ1中邻域NBH中的谱区的所述前较细量化。方差的估计无需精确,而是可以非常粗略。例如,将USAC应用于确定所述较细量化之后邻域NBH中的谱区的绝对值是否达到或超过方差阈值就足够了,也就是说,在高低方差之间切换就足够了。
2步非均匀量化看起来可能像表2那样。在这个例子中,低方差模式对应于在表2中所示的1步量化。
表2描绘了示范性2步非均匀量化;第二或随后步骤依赖于方差被估计成高还是低地不同地量化
块CLASS中的最终背景类别确定与图3的简化版本中相同。可以按照方差模式使用不同背景类别确定。也可以使用不止两种方差模式,当然这导致背景类别的数量增加和复杂性的增加。
对于频谱中的第一谱区,像在图5a或5b中所示那样的邻域是不可应用的,因为对于第一谱区,根本不存在或不是存在所有较低频的谱区。对于这些特殊情况的每一种,可以定义自身邻域。在进一步的实施例中,将预定值填入不存在谱区中。对于在图5a中给出的示范性邻域,频谱中要发送的第一谱区的定义邻域像在图6a和图6b中所示那样。其思路是将邻域扩展到较高频谱区,以便于将相同背景类别确定功能用于频谱的其余部分。这也意味着相同的背景类别,并且至少可以使用相同PDF。如果仅仅减小邻域的尺寸(当然这也是一种选择),则这是不可能的。
复位通常发生在编码新谱之前。如上所述,有必要将专用起点用于解码。例如,如果解码过程从某个帧/谱开始,实际上解码过程必须从最后复位的点开始,以便相继解码前帧直到所希望的开始谱。这意味着,复位发生得越多,解码退出的入口点就越多。但是,在复位后的频谱中编码效率更低。
在发生复位之后,没有前谱可用于邻域定义。这意味着只有实际频谱的前谱区才可以用在邻域中。但是,一般过程可能没有发生变化,并且可以使用相同“工具”。并且,必须与前节已经所述不同地对待第一谱区。
在图8中,示出了示范性复位邻域定义。这种定义可以用于在USAC的FD模式下复位的情况下。
如图8的例子所示的附加背景类别的数量(如果使用量化步骤1之后的值,使用最终具有3个可能量化值或6个值的表格的量化)如下:对第1谱区的处理增加1个背景类别,对第2谱区的处理增加6个背景类别(使用量化步骤1之后的值),对第3谱区的处理增加6个背景类别,并且对第4谱区的处理增加10个背景类别。如果另外考虑两种(高低)方差模式,则这种背景类别的数量几乎加倍(只有对于没有信息可用的第一谱区、和使用量化步骤1之后的谱区的值的第二谱区没有加倍)。
对于复位的处理,在本例中导致了1+6+2×6+2×10=39个附加背景类别。
映射块MAP采用块COCL确定的背景分类,例如,确定的背景类别号, 并从PDF存储器MEM1中选择相应PDF。在这个步骤中,通过将单个PDF用于不止一个背景类别,可以进一步减小必要存储容量。也就是说,具有相似PDF的背景类别可以使用联合PDF。这些PDF可以在训练阶段使用足够大代表性数据集预定。这种训练可以包括识别与相似PDF相对应的背景类别并合并相应PDF的优化阶段。取决于数据统计,这可以导致必须存储在存储器中的数量相当少PDF。在USAC的示范性实验形式中,成功地应用了从822个背景类别到64个PDF的映射。
如果背景类别的数量不太大,这种映射功能MAP的实现可以是简单的查找表。如果数量越来越大,则由于效率原因,可以应用散列表搜索。
如上所述,一般模式开关GMS允许在频域模式(FD)与加权线性预测变换模式(wLPT)之间切换。依赖于模式,可以使用不同邻域。实验表明在图5a,图6a和6b和图8中描绘的示范性邻域对于FD模式来说足够大。但对于wLPT模式,发现如示范性地在图5b,图7a,7b和7c和图9中描绘的较大邻域是有利的。
也就是说,在图9中描绘了wLPT模式下的示范性复位处理。在图7a,7b,7c和7d中分别描述了频谱中最低、次最低、第三最低和第四最低谱区在wLPT模式下的示范性邻域。并且,在图5b中描绘了频谱中所有谱区在wLPT模式下的示范性邻域。
在图5b中描绘的示范性邻域引起的背景类别的数量是3×91=273个背景类别。因子3是由在与当前要编码或当前要解码的一个谱区相同的频率上对一个谱区的特殊处理引起的。按照上面给出的公式,对于邻域中的其余12个谱区,存在0.5*((12*12)+3*12+2)=91种具有值2,1或0的谱区的号码的组合。在依赖于邻域的方差是否达到或超过阈值区分背景类别的实施例中,将273个背景类别加倍。
如图9所示的示范性复位处理也可以增加背景类别的数量。
在在实验中产生良好结果的示范性测试实验中,存在以下表1中分解的822个可能背景类别。
表1MPEG USAC CE建议的分解可能背景类别
在示范性测试实施例中,将这822个可能背景类别映射成64个PDF。如上所述,该映射在训练阶段确定。所得64个PDF必须存储在ROM表中,例如,对于定点算术编码器,以16位精度存储。这里,揭露了所提方案的另一个优点:在在背景技术部分提到的USAC标准化的当前工作草案中,利用单个码字共同编码四元组(quadruple)(包含4个谱区的矢量)。即使矢量中的每个分量的动态范围极小,这也导致极大的码簿(例如,每个分量可能具有值[-4,...,3]→84=4096个可能不同矢量)。但是,标量的编码使得即使每个谱区的动态范围很大码簿也极小。在示范性测试实施例中使用的码簿具有提供从-15到+15的谱区动态范围和转义码字(Esc-codeword)(对于该情况,谱区的值在这个范围之外)的32个项目。这意味着只有64×32个16位值必须存储在ROM表中。
上面描述了使用前谱系数算术编码当前谱系数的方法,其中所述前谱系数是已经编码的,并且所述前谱系数和当前谱系数两者都被包含在视频、音频或语音信号样本值的量化时频变换所得的一个或多个量化谱中。在一个实施例中,所述方法包含处理前谱系数,将处理后前谱系数用于确定作为至少两个不同背景类别之一的背景类别,将所确定背景类别和从至少两个不同背景类别到至少两个不同概率密度函数的映射用于确定概率密度函数,以及根据所确定概率密度函数算术编码当前谱系数,其中处理前谱系数包含非均匀地量化前谱系数。
在另一个示范性实施例中,使用已经编码的前谱系数算术编码当前谱系数的设备包含处理部件、确定背景类别的第一部件、存储至少两个不同概率密度函数的存储器、检索概率密度的第二部件、和算术编码器。
然后,所述处理部件适用于通过非均匀量化处理已经编码的前谱系数,并且所述第一部件适用于将处理结果用于确定作为至少两个不同背景类别之一的背景类别。所述存储器存储至少两个不同概率密度函数、和便于检索与所确定背景类别相对应的概率密度函数的从至少两个不同背景类别到至少两个不同概率密度函数的映射。所述第二部件适用于从所述存储器中检索与所确定背景类别相对应的概率密度函数,并且所述算术编码器适用于根据检索 的概率密度函数算术编码当前谱系数。
存在使用已经编码的前谱系数算术解码当前谱系数的设备的对应另一个示范性实施例,该设备包含处理部件、确定背景类别的第一部件、存储至少两个不同概率密度函数的存储器、检索概率密度的第二部件、和算术解码器。
然后,所述处理部件适用于通过非均匀量化处理已经编码的前谱系数,并且所述第一部件适用于将处理结果用于确定作为至少两个不同背景类别之一的背景类别。所述存储器存储至少两个不同概率密度函数、和便于检索与所确定背景类别相对应的概率密度函数的从至少两个不同背景类别到至少两个不同概率密度函数的映射。所述第二部件适用于从所述存储器中检索与所确定背景类别相对应的概率密度函数,并且所述算术解码器适用于根据检索的概率密度函数算术解码当前谱系数。
- 还没有人留言评论。精彩留言会获得点赞!