非二进制LDPC解码器的校验节点和对应的方法与流程
本发明涉及一种用于控制解码器的校验节点的方法及对应的校验节点,该解码器用于对非二进制的LDPC码进行解码。
背景技术:
LDPC(低密度奇偶校验节点)码是已知的用于接近香农(Shannon)的理论传输极限的纠错码。由于其在抗扰性方面的性能,LDPC码并且具体地非二进制的LDPC码,开始应用于传输和存储数字数据的领域。
在非二进制的q阶的伽罗瓦域(Galois Field)中构造非二进制的LDPC码,q阶的伽罗瓦域通常写为GF(q)。GF(q)中的LDPC码由M x N维的稀疏奇偶矩阵H定义,在属于GF(q)的元素中,N是码字中的GF(q)元素的数量并且M是奇偶约束的数量。例如,对于由4个元素{0,α0,α1,α2}构成的伽罗瓦域GF(4),N=6并且M=3的奇偶矩阵如下:
该矩阵可以类似地由具有接收代码字的符号的N个变量节点和M个校验节点的二分图(坦纳(Tanner)图)示出。该奇偶矩阵中的每一列与变量节点相关联并且矩阵中的每一行与校验节点相关联。在规则的LDPC码的情况下,通过dc个分支将每个校验节点连接至变量节点的单个数dc。类似地,通过dv个分支将每个变量节点连接至校验节点的单个数dv。在规则的LDPC码的情况下,分支的数量dc或dv根据变量节点或校验节点而改变。
这些LDPC码的解码是迭代进行的并且在于经由这些分支交换消息,每个变量节点或校验节点对接收的消息进行处理,并且在处理之后,根据具体情况将其它消息递送至它们经由分支连接到的校验节点或变量节点。交换的消息表示代码符号的概率密度函数并且因此是以大小q的向量形式。这种解码描述于2007年4月出版的IEEE通信学报第4期第55卷中的633页至643页的D.Declercq和M.Fossorier的题为“Decoding Algorithms for Non binary LDPC Codes Over GF(q)”的文献中。
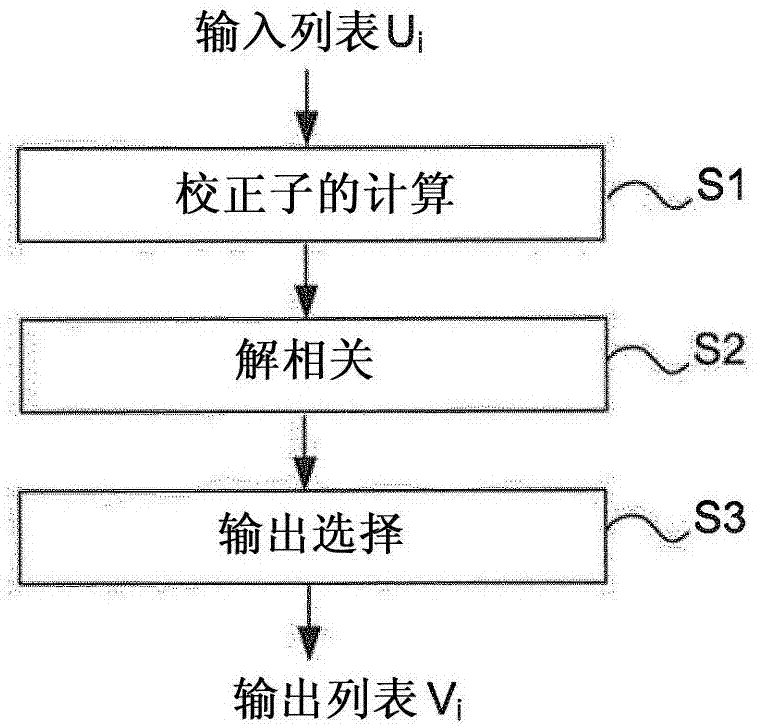
具体地,本发明涉及用于控制解码器的校验节点的方法。参照图1,每个校验节点CN接收多个传入消息Ui并且递送传出消息Vj,其中i,j∈[1...dc],使得,
在图1的实例中,校验节点接收dc=4条传入消息U1、U2、U3、U4并且递送4条传出消息V1、V2、V3、V4,诸如:
其中,“+”是伽罗瓦域GF(q)中的加法运算符。
每条传入和传出消息均是大小q的向量,该向量将概率密度与伽罗瓦域中的每一个元素相关联。每个校验节点对传入消息进行计算并且将传出消息递送至变量节点。
因此,在校验节点与变量节点之间交换密度概率函数,并且相反地,直至代码字被完全解码或已执行预定义的迭代次数。然后,参考“置信传播”算法或BP算法。
实现这种算法相对复杂并且需要校验节点中的大量的演算。利用该算法,复杂度随着GF(q)的大小而增加。BP算法的简单直接的实现方式具有O(q2)的复杂度。
为了降低该复杂度,已知的是在对数域进行工作,以便将乘法转换成加法。在节点之间交换的数据是对数似然比(LLR)。
为了计算传出消息的概率密度函数,用于降低所述复杂度的另一已知的解决方案在于仅考虑传入消息中的nm个最大概率密度函数,nm<q。在2005年9月比利时Louvain-la-Neuve,GRETSI的A.Voicila,D.Declercq,M.Fossorier以及F.Verdier的题为“Algorithmes simplifiés pour le décodage de codes LDPC non binaires”的文献中详细地描述了被称为EMS(扩展的最小总和)的这种算法。该解决方案可以与之前的解决方案进行组合,使得交换的数据是对数似然比。
根据该算法,对传入消息Ui进行过滤并且在由校验节点处理之前对其进行排序。因而,供应至校验节点的消息是仅包括nm个按降序排序的概率密度函数值或LLR的列表。每个概率密度函数或LLR值与伽罗瓦域GF(q)中的元素相关联。概率函数或LLR值的数量考虑了被减少的校验节点(nm<q),该算法的复杂度降低但仍保持高精度。
目前,EMS算法赋予了硬件复杂度与通信性能之间的最佳平衡。
但是,为了实现当今的应用所需的吞吐量,在软件中执行算法是不充分的。专用硬件架构变为强制性的。EMS算法中的最大复杂度是校验节点(CN)的演算,当前技术的架构应用了所谓的前向-后向(FWBW)方案处理校验节点。该架构公开于2004年6月第2卷IEEE国际通信会议的772页至776页中的H.Wymeersch,H.Steendam以及M.Moeneclaey,Proc.的“Log-domain decoding of LDPC codes over GF(q)”。
执行一系列计算,以减少硬件成本并且允许在演算期间重复使用中间结果。然而,这种方案引入了高延迟性并且降低了吞吐量。当GF(q)的大小增加时,这种效果显著增加。
本发明的目的是提供一种允许减少这些缺陷的方案。
技术实现要素:
根据本发明,提出了一种用于控制NB-LDPC(非二进制的低密度奇偶校验)解码器内的校验节点的新方法,以允许提高的校验节点演算的并行机制。由校验节点应用的处理被称为基于校正子(SYN)的校验节点(CN)处理。在比当前技术的硬件认知解码算法略微更好地实现了通信性能的同时,SYN CN处理具有更低的复杂度并且校验节点演算的提高的并行机制使能够允许低延迟性和高吞吐量解码器架构。
本发明涉及一种用于控制解码器的校验节点的方法,解码器用于对非二进制的LDPC码进行解码,所述校验节点接收nm个元素的dc个输入列表Ui并且递送n'm个元素的dc个输出列表Vi,其中i∈[1...dc],其中dc>2,输入或输出列表中的每个元素分别被称为输入元素和输出元素,输入元素和输出元素包括与伽罗瓦域GF(q)的符号相关联的可靠性值,其中q>nm并且q>n'm,分别在所述输入列表和输出列表中根据可靠性值对输入元素和输出元素进行大致排序,所述方法的特征在于该方法包括下列步骤:
-将输入列表Ui中的dc输入元素相加,以生成被称为校正子的多个总和,所述输入元素中的每一个属于dc个输入列表Ui之中的截然不同的输入列表,并且每个校正子包括作为所述输入元素的可靠性值的总和的可靠性值和作为伽罗瓦域中的所述输入元素的符号的总和的伽罗瓦域的符号;
-对于每个输出列表Vi,通过从校正子中减去输入列表Ui中的输入元素而对校正子应用解相关,以生成解相关的校正子;并且
-对于每个输出列表Vi,选择具有最高可靠性值并且针对所述输出列表Vi生成的n'm个解相关的校正子作为所述输出列表Vi中的输出元素。
特别是对于解相关运算,该方法允许进行大量的并行实现方式,从而导致高吞吐量和低延迟处理。
优选地,从LLR(对数似然比)值导出可靠性值。通过最低LLR值给出最高可靠性值,并且相反地,通过最高LLR值给出最低可靠性值。
在一种具体的实施方式中,在相加步骤中,基于与具有所述最高可靠性值(LLR=0)的输入元素不同的至多k个输入元素来生成每个校正子,其中k<dc。
在本实施方式中,仅使用具有最高可靠性值的校正子生成输出列表Vi,从而导致所有其他校正子的演算多余。仅生成具有较少偏离的校正子(利用不具有最高可靠性值(LLR=0)的少量输入元素)。这导致所生成的校正子的数量显著减少。
在一种具体的实施方式中,在相加步骤中,基于与具有最高可靠性值的输入元素的被称为可靠性距离的距离低于最大可靠性距离的输入元素,生成每个校正子。不使用具有最低可靠性值的输入元素生成校正子。这也有助于减少所生成的校正子的数量。
在一种具体的实施方式中,最大可靠性距离取决于k。最大可靠性距离与校正子的偏离数链接。有利地,校正子的偏离数越高,最大可靠性距离越低。
在一种具体的实施方式中,通过根据可靠性值将针对输出列表Vi生成的解相关的校正子进行排序并且通过选择具有最高可靠性值(最低LLR值)的n'm个解相关的校正子,来选择输出列表Vi中的输出元素。在本实施方式中,对解相关的校正子进行排序运算,以便生成输出列表Vi。
在另一具体的实施方式中,对于待生成的输出列表Vi,对从输入列表Ui中的具有最高可靠性值(LLR=0)的输入元素生成的校正子应用解相关。在本实施方式中,仅考虑使用输入列表Ui中的最可靠的元素(LLR=0)的校正子,以用于生成输出列表Vi。不使用所有其他的校正子。在本实施方式的情况下,不需要LLR减法运算。
在链接到之前实施方式的具体实施方式中,在解相关步骤之前,根据所述校正子的可靠性值对校正子进行排序,使得在解相关步骤之后,根据可靠性值将针对输出列表Vi生成的解相关的校正子进行排序,并且输出列表Vi中的元素是具有最高可靠性值的n'm个解相关的校正子。在本实施方式中,排序运算可以在解相关步骤之前完成。这允许将排序器的数量从dc显著减少至1。
在另一具体的实施方式中,在校正子生成之前或之后或同时,该方法进一步包括下列步骤:
-在输入列表Ui中预选择被称为探针的输入元素,每个探针具有代表包括所述探针的一组p个相邻输入元素的可靠性值;
-评估所述预选择的探针,以便选择预定数量的预选择的探针并且对其进行排序,根据可靠性值对被称为最终探针的所述探针进行排序;并且
-基于所述最终探针选择生成的校正子,按最终探针的顺序对所述校正子进行排序。
在本实施方式的情况下,根据可靠性值不能对输出列表Vi中的输出元素进行精确排序,但对于接收这些输出列表的变量节点不是强制性的。在本实施方式中,仅使用数量减少的被称为探针的输入元素选择待解相关的校正子。
在变形中,在校正子生成之前,该方法进一步包括下列步骤:
-在输入列表Ui中预选择被称为探针的输入元素,每个探针具有代表包括所述探针的一组p个相邻输入元素的可靠性值;并且
-评估所述预选择的探针,以便选择预定数量的预选择的探针并且对其进行排序,根据可靠性值对被称为最终探针的所述探针进行排序;
并且其中,在校正子生成步骤中,基于所述最终探针生成校正子,按最终探针的顺序对所述校正子进行排序。
在该变形中,仅基于最终探针生成校正子。因此,计算数量更加减少的校正子。
在具体实施方式中,在每个输入列表Ui中均等地分配探针。
对于具有高的q值(大于64)的GF(q),不均等分配是可能的。
在一个具体实施方式中,探针是在包括所述探针的一组p个相邻输入元素中的具有最高可靠性值的输入元素,并且探针的可靠性值是所述最高可靠性值。
在另一实施方式中,探针的可靠性值是p个相邻输入元素的可靠性值的组合。例如,探针的可靠性值是p个相邻输入元素的可靠性值的平均值。
本发明还涉及一种用于对非二进制的LDPC码进行解码的解码器的校验节点,该校验节点包括:
-dc个输入端,dc个输入端用于接收被称为输入元素的nm个元素的dc个输入列表Ui,其中i∈[1...dc]、nm>1并且dc>2,每个输入元素包括与伽罗瓦域GF(q)中的符号相关联的可靠性值,其中q>nm,在所述输入列表中根据可靠性值对输入元素进行大致排序;
-dc个输出端,dc个输出端用于递送被称为输出元素的n'm个元素的dc个输出列表Vi,其中q>n'm,每个输出元素包括与伽罗瓦域GF(q)的符号相关联的可靠性值,在所述输出列表中根据可靠性值对输出元素进行大致排序;
-校正子计算器,校正子计算器用于将输入列表Ui中的dc个输入元素相加,以生成被称为校正子的多个总和,所述输入元素中的每一个属于dc个输入列表Ui之中的截然不同的输入列表,并且每个校正子包括作为所述输入元素的可靠性值的总和的可靠性值和作为伽罗瓦域中的所述输入元素的符号的总和的伽罗瓦域的符号;
-dc个解相关器,用于对于每个输出列表Vi,通过从校正子中减去输入列表Ui中的输入元素而对校正子应用解相关,以生成解相关的校正子;以及
-装置,用于对于每个输出列表Vi,选择具有最高可靠性值并且针对所述输出列表Vi生成的n'm个解相关的校正子作为所述输出列表Vi的输出元素。
在一个具体实施方式中,校验节点包括用于根据可靠性值对解相关的校正子进行排序的dc个排序器,所述排序器中的每一个专用于将针对专用输出列表Vi生成的解相关的校正子进行排序。
在一个具体实施方式中,校验节点包括用于根据可靠性值对由校正子计算器生成的校正子进行排序的一个排序器,对于待生成的输出列表Vi,对从输入列表Ui中的具有最高可靠性值的输入元素生成的校正子应用解相关。
在一个具体实施方式中,校验节点进一步包括:
-探针选择器,用于在输入列表Ui中选择被称为探针的输入元素,每个探针具有代表包括所述探针的一组p个相邻输入元素的可靠性值;
-探针排序器,用于根据可靠性值对探针进行排序;以及
-校正子选择器,基于所述排序的探针选择生成的校正子,按排序的探针的顺序对所述校正子进行排序。
在一个具体的实施方式中,校验节点进一步包括:
-探针选择器,用于在输入列表Ui中选择被称为探针的输入元素,每个探针具有代表包括所述探针的一组p个相邻输入元素的可靠性值;
-探针排序器,用于根据可靠性值对探针进行排序;
并且其中,驱动校正子计算器以基于所述排序的探针生成校正子,按排序的探针的顺序对所述校正子进行排序。
附图说明
可参考下面的描述和附图来更好地理解本发明,下面的描述和附图以示例的方式给出而非限制保护的范围,并且在附图中:
-图1是校验节点的示意性表示;
-图2是示出根据本发明的基于校正子的方法的流程图;
-图3是实现图2中的基于校正子的方法的校验节点的示意性表示;
-图4是校正子的示意性表示;
-图5是示出不同偏离集合中的校正子的平均LLR值的图;
-图6是示出根据本发明的基于校正子的方法中的第一变量的步骤的流程图;
-图7是实现图6中的基于校正子的方法的校验节点的示意性表示;
-图8是图7所示的校验的解相关器的示意性表示;
-图9是用于对偏离集合D1和D2中的校正子进行排序的排序器的示意性表示;
-图10是图9中的排序器的一部分的示意性表示;
-图11是示出探针的分配的示意图;
-图12是示出根据使用探针的本发明的基于校正子的方法中的第二变量的步骤的流程图;
-图13是示出图12中的方法的结果的曲线;
-图14是实现图12中的基于校正子的方法的校验节点的示意性表示;
-图15是图14中的校验节点的探针评估器的示意性表示;
-图16是图14中的校验节点的校正子计算器的示意性表示;
-图17是图14中的校验节点的校正子选择器的示意性表示;
-图18是图14中的校验的变量的示意性表示;以及
-图19是示出由图18中的校验节点实现的基于校正子的方法的步骤的流程图。
具体实施方式
在下面的描述中,校验节点被视为接收按降序或升序排序的nm个元素的列表作为输入并且递送同样按降序或升序排序的n'm=nm个元素的列表作为输出。同样,认为该校验节点在对数域中工作,因而,在节点之间交换的数据是LLR值。当然,n'm可以不同于nm。
更具体地,在下文中,将参考校验节点描述本发明,该校验节点接收dc个输入Ui作为传入消息并且递送dc个输出Vi作为传出消息,其中i∈[1...dc]。每个输入Ui和输出Vi是各自与GF(q)的符号相关联的nm个LLR值的元组(定序列表),其中nm<q,根据其LLR值的升序或降序对元组元素进行排序。元组的nm个符号是如在当前技术的EMS算法中定义的nm个最可靠的符号(具有最低LLR值的符号)。具有最高可靠性值的符号(或伽罗瓦域元素)具有LLR=0。
在下文中,Ui[j]表示输入列表Ui中的第j个元素并且Vi[j]表示输出列表Vi中的第j个元素,其中j∈[0…nm-1]。
在详细描述本发明的对于具有dc个输入端和dc个输出端的校验节点的方法之前,将简要描述具有如图1所示的校验节点的发明方法的原理,该校验节点具有四个输入U1、U2、U3、U4和四个输出V1、V2、V3、V4。
如上所述,四个输出如下:
其可以重写为如下:
其中,-是伽罗瓦域GF(q)中的减法运算符并且用于LLR值。
本发明的基本原理是在完成适当的减法(解相关)之前首先计算对所有输出V1、V2、V3、V4通用的被称为校正子的总和U1+U2+U3+U4,以获得4个输出V1、V2、V3、V4。这允许并行进行大量的运算。
图2表示本发明的方法的基本流程图并且图3表示用于实现所述方法的基本架构。
根据图2,该方法包括下列步骤:
-步骤S1:将输入列表Ui中的dc个输入元素相加,以便生成被称为校正子的多个总和,已相加的输入元素中的每一个属于dc个输入列表之中的截然不同的输入列表Ui;每个校正子包括作为所述输入元素的可靠性值的总和的可靠性值和也作为伽罗瓦域中的输入元素的符号的总和的伽罗瓦域的符号;可靠性值是LLR值。
-步骤S2:对于每个输出列表Vi,通过从校正子中减去输入列表Ui中的输入元素而对校正子应用解相关,以生成解相关的校正子;以及
-步骤S3:对于每个输出列表Vi,选择具有最高可靠性值并且针对所述输出列表Vi生成的nm个解相关的校正子作为所述输出列表Vi中的输出元素。
在步骤S1中,计算多个校正子。校正子的集合被称为S。通过针对总和选定的元素来区分各个校正子。通过图3中描述的校正子计算器10实现该步骤。
如果xi表示输入列表Ui中的一个元素Ui[j],其中j∈[0...nm]并且i∈[1...dc],则从输入元素(x1...xdc)生成的校正子被称为SYN(x1...xdc),如下:
其中
包括所有可能的校正子的校正子集合S包括个校正子并且定义如下:
并且
在步骤S2中,对于已生成的每个输出列表Vi,通过从校正子中减去输入列表Ui中的输入元素而对校正子应用解相关,以生成解相关的校正子。通过图3中描述的解相关器11实现该步骤。该步骤的技术效果是从校验节点的输入中将校验节点的输出解相关。
该步骤在于针对每个输出Vi生成专用的校正子集合Si,输出Vi与输入Ui不相关:并且
其中
并且
每个集合Si包括个校正子。
一经演算出集合Si,则在步骤S3中根据由LLR值表示的它们的校正子可靠性对在集合Si内的解相关的校正子进行排序。通过图3中描述的排序器12进行排序步骤。然后,每个输出列表Vi由集合Si中的nm个最可靠的解相关的校正子构成。
该处理方法是当前技术的校验节点处理的替代方案。其是高阶伽罗瓦域解码的第一种解决方案,允许进行大量的并行实现方式并且由此允许高吞吐量和低延迟。一经计算出校正子集合S,则可以对每个输出Vi并行运行解相关步骤和排序步骤。还可以并行完成校正子计算。这允许具有低延迟的处理。
然而,在没有特殊处理的情况下,校正子集合S的计算和Si的排序引入了高复杂度。必须降低复杂度,以使算法适用于硬件的实现方式。出于此目的,下文中提出了不同的改进。更具体地,提出了在维持通信性能的同时用于简化校正子集合生成和排序的不同解决方案。
根据第一有利的实施方式,减少了集合S中的校正子的数量。对于输出演算,仅使用S中的最可靠的值,从而使得所有其他校正子的演算多余。因此,S的基数(表示为|S|)的大大减小可以明显减小算法的整体复杂度,而不牺牲通信性能。
用于减小|S|的第一步骤是分离具有高可靠性的校正子与具有低可靠性的校正子。校正子集合S可以被限定为dc+1个子集Dk(也被称为偏离集合)的并集,其中k∈[0...dc],使得:
每个子集Dk仅包含与最可靠元素精确偏离k个元素的校正子。图4以图形方式表示了两个示例性的校正子,一个具有两个偏离(填充圆圈)并且一个具有三个偏离(开放式圆圈)。偏离表示用于生成校正子并且不具有等于零的LLR值(最高可靠性值)的输入元素。子集D0仅包含一个校正子,即,来自全部输入中的最可靠的元素的总和。子集D1包含dc·nm个校正子。更通常地,子集Dk包含个校正子。
图5示出了在排序的偏离集合Dk中的校正子的平均LLR值。我们可以观察到,可靠LLR的分配取决于由Eb/No表示的信噪比(SNR)。然而,具有多于两个偏离(例如,Dk,k>2)的校正子具有这样的低可靠性(高LLR值)使得它们很少贡献于输出Vi的生成。因此,有利地,我们可以将子集Dk的计算局限于具有低偏离量的那些。图5示出了考虑具有一个和两个偏离的校正子对于GF(64)运行良好。
因此,根据有利的实施方式,集合S局限于D0、D1、以及D2的并集:
用于降低|S|的另一参数是对于偏离集合Dk有贡献的元素的最大允许可靠性距离dk。可靠性距离描述了输入列表中的元素相对于最可靠元素(LLR=0)的位置。在图4中,最可靠的元素具有索引零。较不可靠的元素具有描述其在LLR的排序列表中的等级的更高索引。
对于Dk的计算,仅考虑具有小于或等于dk的索引的元素。可以基于元素的LLR值动态地设置特定偏离的最大允许可靠性距离或固定最大允许可靠性距离作为预定义的参数。对于每个偏离,可以设置不同的最大可靠性距离,例如,允许的偏离数量越高,偏离的最大可靠性距离越低,d1≥d2≥…≥ddc。在图4中,将d2固定至8并且将d3固定至2。该图中未示出最大可靠性距离d1,但是最大可靠性距离d1等于nm-1。
使用该方案明确地保持了每个Dk中的最佳校正子并且移除较不可靠的校正子。子集Di的基数可以计算如下:
两种所提技术的组合确实降低了S的基数并且由此降低演算的复杂度。计算最可靠的校正子并且仅移除不可靠的校正子。偏离数量的参数化及其最大可靠性距离是算法中的关键步骤。例如,仅使用具有固定可靠性距离d0=0;d1=nm-1;d2=2;dc=4并且nm=13的D0、D1以及D2,将|S|从28561缩小至73。对于GF(64)中的代码,这是复杂度与通信性能之间的非常好的平衡。
降低复杂度的另一种方式是简化排序步骤。上面呈现的处理的一个大的缺陷在于必须对每个校正子集合Si进行单独排序,以输出nm个最可靠的解相关的校正子。这就是由于之前应用的解相关步骤的情况。为了避免对解相关的校正子集合Si进行排序,可以选定简单并且有效的解决方案。代替对每个值进行解相关,仅考虑来自当前处理的输出边缘i的使用最可靠元素(LLR=0)的校正子。所有其他校正子不用于当前输出Vi。通过这种解决方案,不会通过解相关步骤改变校正子的顺序并且足以对一个集合S、而非dc个集合Si进行排序。此外,对于输出Vi中的每一个元素,在解相关步骤中未对LLR值进行修改,从而省去了实值减法。最后,仅必须对最可靠的输入元素而非完整的输入集合进行排序,以进行解相关。
如图6和图7中示出的,这种简化的解相关还允许在解相关步骤之前应用排序步骤。这将排序器的数量从dc降至1。图6示出了本实施方式的流程图并且图7是本实施方式的实现方式。
在图6中,在解相关步骤S3之前,在此运行在图2中的输出生成步骤S3中执行的排序运算。对集合S中的校正子应用排序运算(以S10表示)。在图7中,校验节点包括用于生成校正子的集合S的校正子计算器200、用于根据其LLR值对S的校正子进行排序的排序器220、以及用于对排序的集合Si应用解相关的dc个解相关器210。
图8示出了图7中的一个解相关器的示意性操作。在图8中,以附加信息SRC表示每个校正子,与附加信息SRC相关的输入边缘致使校正子产生偏离。图8中的SRC对产生偏离的输入边缘进行排序并且ADDRi表示当前输出边缘。对校正子计算中是否涉及来自当前边缘的偏离并且由此校正子是否对于当前边缘有效进行简单的比较评估。只有当前边缘不产生偏离时,才将解相关的校正子标记为有效并且用于输出Vi。
必须注意,由于每个输入对应于坦纳图中的一个边缘,所以表达式“边缘”在此处与术语输入交替地使用。
即使已将排序降低至校正子集合S,仍存在进行简化的更大可能性。可以将排序S划分成对偏离集合Di进行排序并且对其合并。尤其对于Di,可以进一步对排序进行简化。由于之前我们获得输入数据的认知而实现了此操作。我们明确地获知,列表Ui根据其LLR而进行排序。因此,D1的排序可以不局限于对dc个排序的集合进行合并。对于高阶偏离Di,其中i≥2,由于排序的输入列表,因此也可以对排序进行简化。图9中示出了用于对D1和D2的校正子进行排序的电路的实例,其中dc=4。部分P1用于对D1的校正子进行排序并且部分P2用于对D2的校正子进行排序,其中d2=2。
如从图9中可以看出并且如上所述,由于已经根据其LLR对列表Ui进行排序,所以简化了D1的校正子的排序,并且校正子的LLR是不具有等于零的LLR的输入元素的LLR。
对于D2的校正子(图9中的部分P2),首先通过生成分阶输入元素的子集的六个电路SCp生成排序的子列表,一个电路CS1用于生成输入元素U1[1]、U1[2]、U2[1]以及U2[2]的排序子列表,一个电路CS2用于生成输入元素U1[1]、U1[2]、U3[1]以及U3[2]的排序子列表,一个电路CS3用于生成输入元素U1[1]、U1[2]、U4[1]以及U4[2]的排序子列表,一个电路CS4用于生成输入元素U2[1]、U2[2]、U3[1]以及U3[2]的排序子列表,一个电路CS5用于生成输入元素U2[1]、U2[2]、U4[1]以及U4[2]的排序子列表,并且一个电路CS6用于生成输入元素U3[1]、U3[2]、U4[1]以及U4[2]的排序子列表。
图10示出了用于生成输入元素U1[1]、U1[2]、U2[1]以及U2[2]的排序子列表的电路CS1。图10中的电路可以容易地扩展至其他的偏离与可靠性距离。一旦对子列表进行排序,则通过如图9所示依次对其进行合并而生成输出。
鉴于上述声明,从根据本发明的方法中获得三个明显的益处:
●|S|的明显降低。
●没有LLR减法并且无需在解相关步骤中存储Ui。
本发明中的方法可以被进一步简化。将NB-LDPC解码器视为整体,可以观察到,无需对校验节点输出进行精确的排序。当变量节点将经验性的概率(APP)消息计算为信道值的总和并且计算来自校验节点的消息时,无论如何都必须对其重新排序。因此,粗略排序的校验节点输出是充分的并且不影响解码器的通信性能。因此,下文中提出了一种新的方法,即针对粗略排序的校验节点输出使用稳健性而进一步降低算法的复杂度。
为了允许进行这种粗略的排序,从输入列表Ui的元素之中选定所谓的探针并且根据其LLR进行排序。每个探针的LLR均被视为代表包括所述探针的一组p个相邻元素的LLR。图11示出了探针在D1所使用的输入列表U1内的分配。在该实例中,探针均等地分配在已调查配置运行良好的输入列表中。所考虑的探针是索引为1、4、7以及10的元素。然而,对于其他参数dc和nm,可以使用其他分配。
在该图中,探针是具有包括探针的一组p个相邻输入元素中的最低可靠性值的输入元素,并且探针的可靠性值是该组中的元素的最低可靠性值。在图11的实例中,将探针1(=U1[3])的LLR值视为包括元素U1[1]、U1[2]、以及U1[3]的组probe1_group中的全部元素的LLR值的代表。当然,探针的LLR值也可以是组中的元素的LLR值的组合,例如,组中的元素的LLR值的平均值。
在本实施方式中,一旦选择探针,则对其进行评估,以便选择数量减少的排序探针,并且然后,基于这些排序探针选择集合S中的校正子(例如,D0∪D1∪D2,其中d2=2),按排序的探针的顺序对选择的校正子进行排序。
图12中示出了这种实施方式的流程图。方法包括下列步骤:
-步骤S200:如上所述,在输入列表Ui中预选择探针;,该预选择可以是如图11中描述的预定义的一个;在该图中,预选择元素Ui[j],其中i=1;2;3;4并且j=3;6;9;12;因此,预选择16个探针。
-步骤S210:计算校正子,以生成校正子S的集合;
-步骤S220:评估预选择的探针,以便选择减少预定数量的预选择的探针并且对其进行排序,根据可靠性值对被称为最终探针的所述探针进行排序;步骤S220可以在步骤S210之前或之后或同时执行。
-步骤S230:基于最终探针从集合S中选择校正子;按最终探针的顺序对选择的校正子进行排序;以及
-步骤S240:对排序的校正子应用解相关,以生成输出列表Vi。
这种方案导致在从步骤S230发布的校正子集合中的一定的不确定性,但是足够接近精确的解决方案而不降低解码器的通信性能。
图13示出了用于CN输出计算的粗略排序的校正子的LLR值。这种粗略对于低LLR(高可靠性)运行良好,并且与最佳排序结果相比较,仅对于较不可靠的输出存在差异。
在下文中,给出了利用探针的本发明解决方案的硬件实现方式。该架构独立于实际使用的NB-LDPC码,仅给出了参数dc=4、q=64并且nm=13。
图14示出了校验节点硬件的概况。为了实现低延迟和高吞吐量,对于最可靠的元素(LLR=0),选定校验节点的输入并行机制为六GF(q)、LLR元组、以及附加的GF(q)输入。因此,可以在两个时钟循环内读取全部输入元素Ui[j]。可以与校正子集合S的实际计算并行地处理对探针的评估。在该实例中,校正子集合S被减少至D0∪D1∪D2,其中d2=2。D0包括1个校正子,D1包括48个校正子,并且D2包括24个校正子。
校验节点包括:
-探针评估器PE1,用于确定用于选择D1中的校正子的数量减少的探针;
-探针评估器PE2,用于确定用于选择D2中的校正子的数量减少的探针;
-校正子计算器SC,用于计算D0、D1、以及D2中的校正子。
-校正子选择器SS1,用于从由校正子计算器SC生成的D1中的校正子之中选择6个校正子;
-校正子选择器SS2,用于从由校正子计算器SC生成的D2中的校正子之中选择3个校正子;以及
dc个解相关器,接收D0中的校正子以及由校正子选择器SS1和SS2选择的D1和D2中的校正子。
在本实施方式中,一旦计算出S=D0∪D1∪D2并且对探针进行排序,则使用通由校正子选择器SS1和SS2选择的最可靠的子集进行解相关。处理校正子的并行机制对整体吞吐量具有显著影响。已经选定为三个校正子的三倍。在每个时钟循环中,处理来自D1的相邻校正子的两个集合和来自D2的一个集合的全部九个校正子。因此,在最多四个时钟循环之后,利用nm个有效消息填充全部输出边缘。CN的输出并行机制被选定为与六个GF(q)、LLR元组、以及D0的一个GF(q)消息的输入对称。
图15中示出了探针评估器PE1的实例。在每个时钟循环中,该探针评估器在每个输入边缘处理两个探针。对于dc=4,必须对全部八个LLR进行排序,排序通过延迟优化排序网络执行。对于已经明确进行排序的每两个探针,由于属于同一输入列表,可以应用网络上的某些简化。
探针评估器PE1在第一循环中接收探针U1[1]、U1[4]、U2[1]、U2[4]、U3[1]、U3[4]、U4[1]、U4[4]并且在第二循环中接收探针U1[7]、U1[10]、U2[7]、U2[10]、U3[7]、U3[10]、U4[7]、U4[10]。通过排序网络处理这些探针。排序的结果不是LLR的排序列表而是排序输入的位置。在寄存器中对其进行排序并且在下一时钟循环中针对第二个一半的输入LLR第二次执行同一任务。从第二个时钟循环开始,每下一个时钟循环输出两个最小探针的位置。为了执行该任务,利用附加排序器从寄存器中选择两个最小的探针。一旦使用探针进行输出生成,则通过相应地移位寄存器内容而进行移除。由于仅考虑四个输入,所以D2的探针评估器PE2是D1的探针评估器的简化版本。而且,每个时钟循环仅需要生成一个输出。使用探针评估器的输出作为校正子选择器部件的控制信号。
图16部分描述了校正子计算器SC的实例。全部并行执行校正子计算。由于对偏离可靠性距离的限制(d0=0、d1=nm-1、d2=2),严格限制所需的硬件。用于计算的精密方案允许进一步降低硬件成本。代替计算每个校正子作为dc个输入的总和,使用中间结果将明确计算的次数最小化。D0的计算涉及dc-1次GF(q)加法,对于D1,需要总共dc·nm次GF(q)加法。因此,对于D0和D1,仅需要计算GF(q)。对于D2,容易扩展D1的处理方案,并且除GF(q)运算之外,每个校正子仅需要一次实值加法。与当前技术的处理相比,这明显降低了演算复杂度。校正子计算器的输出是用作校正子选择器的输入的一组排序子集。
图17部分描述了对于D1的校正子选择器的实例。校正子选择器从探针评估器PE1接收最可靠的校正子集合的地址并且从校正子计算器接收按照子集排序的校正子Di。完整的硬件包含从子集中选定一组三个最可靠的校正子的多路复用器树。为了实现来自D1的六条消息,在该单元中对图17中的多路复用器树进行复制。对于D2,D2的六个子集之间的单个树选定就足够。
对于校验节点的每个输出边缘,单独执行解相关。解相关器的输出并行机制是每个时钟循环六条消息。每个时钟循环处理两倍于来自D1的三个校正子和来自D2的三个校正子。通过构建,消息集合始终具有相同边缘上的偏离。因此,足以检查消息集合中的一条消息是否有效,这由有效标记表示。如果仅接收的集合中的一部分有效,则由多路复用器通过仅使用有效的消息进行输出的方式对其进行重新布置。在最佳情况下,在一个时钟循环中接收的全部校正子都是有效的。由于输出并行机制仅为六个,所以在附加寄存器中对多余的校正子进行排序并且在下一时钟循环中重新使用多余的校正子。在将消息发送至变量节点之前,应用实际的解相关,即,当前输入边缘的最可靠GF(q)值的减法。
在图14的硬件实现方式中,通过校正子计算器SC生成D1和D2的全部校正子并且通过校正子选择器SS1和SS2仅选择其中的九个。
在图18和图19示出的变量中,提出了仅生成待解相关的校正子。在该变量中,将由探针评估器生成的控制信号ctrl传输至校正子计算器SC,使得后者仅生成待解相关的D0中的校正子以及D1和D2中的九个校正子。移除校正子选择器SS1和SS2。
通过该变量中的校验节点执行的方法总结为图19中描述的下列步骤:
-步骤S300:如上所述,在输入列表Ui中预选择探针;
-步骤S310:评估探针,以便选择预定数量的预选择的探针并且对其进行排序,根据可靠性值对被称为最终探针的所述探针进行排序;
-步骤S320:基于最终探针计算数量减少的校正子;以及
-步骤S340:对排序的校正子应用解相关,以生成输出列表Vi。
- 还没有人留言评论。精彩留言会获得点赞!