用于纹理译码的先进残余预测(ARP)的方法和设备与流程
技术领域
本发明涉及视频译码。
背景技术:
数字视频能力可并入到广泛范围的装置中,包含数字电视、数字直播系统、无线广播系统、个人数字助理(PDA)、膝上型或桌上型计算机、平板计算机、电子图书阅读器、数码相机、数字记录装置、数字媒体播放器、视频游戏装置、视频游戏控制台、蜂窝式或卫星无线电电话、所谓的“智能电话”、视频电话会议装置、视频串流装置等等。数字视频装置实施视频译码技术,例如由MPEG-2、MPEG-4、ITU-T H.263、ITU-T H.264/MPEG-4第10部分先进视频译码(AVC)所定义的标准、目前正在开发的高效视频译码(HEVC)标准及这些标准的扩展中所描述的视频译码技术。视频装置可通过实施此类视频译码技术而更有效率地发射、接收、编码、解码及/或存储数字视频信息。
视频译码技术包含空间(图片内)预测和/或时间(图片间)预测以减少或移除视频序列中固有的冗余。对于基于块的视频译码来说,视频切片(例如,视频帧或视频帧的一部分)可分割成视频块,视频块还可被称作树块、译码单元(CU)和/或译码节点。图片的经帧内编码(I)切片中的视频块是使用相对于同一图片中的相邻块中的参考样本的空间预测来编码。图片的经帧间编码(P或B)切片中的视频块可使用相对于同一图片中的相邻块中的参考样本的空间预测或相对于其它参考图片中的参考样本的时间预测。图片可被称作帧,且参考图片可被称为参考帧。
空间或时间预测产生用于待译码块的预测块。残余数据表示待译码原始块与预测块之间的像素差。经帧间译码块是根据指向形成预测块的参考样本块的运动向量及指示经译码块与预测块之间的差的残余数据编码的。经帧内译码块是根据帧内译码模式及残余数据编码的。为了进一步压缩,可将残余数据从像素域变换到变换域,从而导致残余变换系数,接着可对残余变换系数进行量化。可扫描最初用二维阵列布置的经量化变换系数,以便产生变换系数的一维向量,且可应用熵译码以实现更多的压缩。
技术实现要素:
大体来说,本发明描述用于纹理译码的准确先进残余预测(ARP)技术,其可提供相对于其它ARP技术的改进的准确性。更确切地说,本发明描述ARP技术,其包含识别从当前视图到参考视图的DMV,以及基于DMV的识别确定当前视频块的ARP的残余预测符块。
在一些实例中,DMV为当前视频块的DMV,且所述技术包含确定当前视频块的视图间ARP的视图间残余预测符块。DMV用于基于视图间参考视频块的当前视频块的视图间预测。视图间ARP的技术还可包含基于视图间参考视频块的时间运动向量(TMV)识别当前和参考视图中的时间参考视频块,以及基于时间参考视频块之间的差确定残余预测符块。在此些实例中,ARP不限于用于对经时间预测的视频块译码的时间ARP,而实际上可包含用于对经视图间预测的视频块译码的视图间ARP。
在一些实例中,当前视频块经时间预测,且针对当前视频块的时间ARP,当前视频块的参考视频块的DMV代替例如根据基于相邻块的视差向量导出(NBDV)而针对当前视频块导出的视差向量。在此些实例中,通常通过速率失真优化而选择的DMV可比所导出的视差向量更精确,这可导致当前视频块的更精确时间ARP。在一些实例中,当前视频块经时间预测,且针对当前视频块的时间ARP,经由当前视频块的时间参考视频块的协同定位深度块导出的视差向量代替例如根据基于相邻块的视差向量导出(NBDV)而针对当前视频块导出的视差向量。此些实例可在协同定位深度块在纹理译码期间可用时提供更精确时间ARP。
在一个实例中,用于解码视频数据的视图间先进残余预测的方法包括解码经编码视频位流,其编码视频数据以识别当前视频块的视差运动向量(DMV)和残余块。当前视频块在当前视图中,且DMV用于基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述方法进一步包括识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片;基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块;以及基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述方法进一步包括基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块。所述方法进一步包括将所述残余预测符块和从经编码视频位流识别的残余块施加到视图间参考视频块以重建当前视频块。
在另一实例中,一种用于编码视频数据的视图间先进残余预测的方法包括识别当前视频块的视差运动向量(DMV),其中当前视频块在当前视图中,且其中DMV用于基于参考视图以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述方法进一步包括识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片;基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块;以及基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述方法进一步包括基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块。所述方法进一步包括编码经编码视频位流,其编码视频数据以识别当前视频块的DMV和残余块。由经编码视频位流识别的残余块包括当前视频块的视图间参考视频块与残余预测符块之间的差。
在另一实例中,一种设备包括视频译码器,其经配置以执行视图间先进残余预测以用于对视频数据译码。视频译码器包括经配置以存储编码视频数据的经编码视频位流的存储器,和一或多个处理器。所述一或多个处理器经配置以识别当前视频块的视差运动向量(DMV),其中当前视频块在当前视图中,且其中DMV用于基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述一或多个处理器进一步经配置以识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片,基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块,且基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述一或多个处理器进一步经配置以基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块。所述一或多个处理器进一步经配置以对经编码视频位流译码以识别当前视频块的DMV和残余块。通过对经编码视频位流译码而识别的残余块包括当前视频块的视图间参考视频块与残余预测符块之间的差。
在另一实例中,一种计算机可读存储媒体具有存储在其上的指令,所述指令在执行时致使视频译码器的一或多个处理器识别当前视频块的视差运动向量(DMV),其中当前视频块在当前视图中,且其中DMV用于基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述指令进一步致使所述一或多个处理器识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片,基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块,且基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述指令进一步致使所述一或多个处理器基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块。所述指令进一步致使所述一或多个处理器对经编码视频位流译码以识别当前视频块的DMV和残余块。通过对经编码视频位流译码而识别的残余块包括当前视频块的视图间参考视频块与残余预测符块之间的差。
在其它实例中,用于编码视频数据的视图间先进残余预测的方法包括识别当前视频块的视差运动向量(DMV),其中当前视频块在当前视图中,且其中DMV用于基于参考视图以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述方法进一步包括识别时间运动向量(TMV)和相关联参考图片。在一些实例中,DMV可来自当前视频块的第一参考图片列表,且TMV和相关联参考图片可来自当前视频块的第二参考图片列表。在其它实例中,TMV和相关联参考图片是从当前视频块的空间或时间相邻块导出。在任一情况下,所述方法可进一步包括基于TMV识别参考视图中的时间参考视频块,以及基于所述TMV识别当前视图中的时间参考视频块。所述方法进一步包括基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块。所述方法进一步包括编码经编码视频位流,其编码视频数据以识别当前视频块的DMV和残余块。由经编码视频位流识别的残余块包括当前视频块的视图间参考视频块与残余预测符块之间的差。
在另一实例中,一种用于对视频数据译码的时间先进残余预测的方法包括识别当前视频块的时间运动向量(TMV),其中当前视频块在当前视图中,且其中TMV用于基于当前视图中以及与当前视频块不同的存取单元中的时间参考视频块的当前视频块的预测。所述方法进一步包括识别用于时间参考视频块的视图间预测的时间参考视频块的视差运动向量(DMV)。所述方法进一步包括基于所述DMV确定参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块或参考视图中以及不同存取单元中的时间参考视频块中的至少一者。所述方法进一步包括基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块与参考视图中以及不同存取单元中的时间参考视频块之间的差确定当前视频块的残余预测符块。所述方法进一步包括对经编码视频位流译码,所述经编码视频位流编码视频数据以识别当前视频块的TMV和残余块。由经编码视频位流识别的残余块包括当前视频块的时间参考视频块与残余预测符块之间的差。此方法的一些实例进一步包括将当前视频块的TMV缩放到目标存取单元中的目标参考图片以用于当前视频块的先进残余预测,其中所述经缩放TMV识别当前视图中的时间参考视频块。在此方法的一些实例中,由经缩放TMV识别的当前视图中的时间参考视频块包括第一时间参考视频块,且所述方法进一步包括确定由经缩放TMV识别的当前视图中的第一时间参考视频块并不与DMV相关联,以及基于所述TMV不在场缩放识别当前视图中的第二时间参考视频块。在此些实例中,识别DMV包括识别由TMV不在场缩放识别的当前视图中的第二时间参考视频块的DMV。在此方法的一些实例中,当前视图中以及与当前视频块不同的存取单元中的时间参考视频块包括多个预测单元,且识别时间参考视频块的DMV包括识别与所述多个PU中的含有时间参考视频块的中心位置的一者相关联的DMV。在此方法的一些实例中,识别DMV包括从除后向视频合成预测(BVSP)外的预测模式识别DMV。在此方法的一些实例中,视图间参考视频块含有对应于第一参考图片列表的第一运动信息集合和对应于第二参考图片列表的第二运动信息集合,且识别视图间参考视频块的TMV包括在第一运动信息集合包含TMV的情况下选择来自所述第一运动信息集合的TMV,以及在第一运动信息集合并不包含TMV的情况下选择来自所述第二运动信息集合的TMV。在此方法的一些实例中,第一参考图片列表包括RefPicList0。在此方法的一些实例中,用于考虑第一和第二运动信息集合的次序与第一和第二运动信息集合中的哪一者包含TMV无关。在此方法的一些实例中,对经编码视频位流译码包括用视频解码器解码经编码视频位流以识别当前视频块的TMV和残余块,以及将残余预测符块和从经编码视频位流识别的残余块施加到时间参考视频块以重建当前视频块。在此方法的一些实例中,对经编码视频位流译码包括用视频编码器编码经编码视频位流以向视频解码器指示当前视频块的TMV和残余块。
在另一实例中,一种用于对视频数据译码的时间先进残余预测的方法包括识别当前视频块的时间运动向量(TMV),其中当前视频块在当前视图中,且其中TMV用于基于当前视图中以及与当前视频块不同的存取单元中的时间参考视频块的当前视频块的预测。所述方法进一步包括经由时间参考视频块的协同定位深度块导出视差向量(DV)。所述方法进一步包括基于所述DV确定参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块或参考视图中以及不同存取单元中的时间参考视频块中的至少一者。所述方法进一步包括基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块与参考视图中以及不同存取单元中的时间参考视频块之间的差确定当前视频块的残余预测符块。所述方法进一步包括对经编码视频位流译码,所述经编码视频位流编码视频数据以识别当前视频块的TMV和残余块。由经编码视频位流识别的残余块包括当前视频块的时间参考视频块与残余预测符块之间的差。此方法的一些实例进一步包括将当前视频块的TMV缩放到目标存取单元中的目标参考图片以用于当前视频块的先进残余预测,其中所述经缩放TMV识别当前视图中的时间参考视频块。在此方法的一些实例中,由经缩放TMV识别的当前视图中的时间参考视频块包括第一时间参考视频块,且所述方法进一步包括确定由经缩放TMV识别的当前视图中的第一时间参考视频块并不与DMV相关联,以及基于所述TMV不在场缩放识别当前视图中的第二时间参考视频块。在此些实例中,识别DMV包括识别由TMV不在场缩放识别的当前视图中的第二时间参考视频块的DMV。在此方法的一些实例中,导出DV包括将协同定位深度块内的一个样本的深度值转换为DV。在一些实例中,所述一个样本相对于协同定位深度块的左上样本定位在(W/2,H/2),其中协同定位深度块的大小为WxH。在此方法的一些实例中,导出DV包括基于协同定位深度块内的多个样本的深度值确定代表性深度值,以及将所述代表性深度值转换为DV。在一些实例中,所述多个样本是四个隅角样本。在一些实例中,所述多个样本基于深度块的相邻样本而选择。在一些实例中,基于协同定位深度块内的多个样本的深度值确定代表性深度值包括基于协同定位深度块内的多个样本的所有深度值确定代表性深度值。在此方法的一些实例中,对经编码视频位流译码包括用视频解码器解码经编码视频位流以识别当前视频块的TMV和残余块,以及将残余预测符块和从经编码视频位流识别的残余块施加到时间参考视频块以重建当前视频块。在此方法的一些实例中,对经编码视频位流译码包括用视频编码器编码经编码视频位流以向视频解码器指示当前视频块的TMV和残余块。
在附图和下文描述中阐述本发明的一或多个实例的细节。其它特征、目标和优点将从所述描述、图式以及权利要求书显而易见。
附图说明
图1是说明可利用本发明中描述的技术的实例视频编码和解码系统的框图。
图2为说明实例多视图编码或解码次序的图形图。
图3为说明用于多视图视频译码的实例时间和视图间预测图案的概念图。
图4为说明用于预测当前块的运动信息的相邻块与所述当前块的实例关系的概念图。
图5为说明用于预测当前块的运动信息的经视图间预测的运动向量候选者和视图间视差运动向量候选者的导出的实例的概念图。
图6为说明相对于当前视频块的实例空间相邻块的概念图,可从所述实例空间相邻块使用基于相邻块的视差向量导出(NBDV)导出当前视频块的视差向量。
图7为说明来自参考视图的深度块的位置的实例以及使用参考视图中的所定位深度块用于后向视图合成预测(BVSP)的概念图。
图8为说明用于经时间预测视频块的时间先进残余预测(ARP)的实例预测结构的概念图。
图9为说明用于时间ARP的实例双向预测结构的概念图。
图10为根据本发明中描述的技术的用于经视图间预测视频块的视图间ARP的实例预测结构的概念图。
图11为根据本发明中描述的技术的用于使用视差运动向量(DMV)的经时间预测视频块的时间ARP的实例预测结构的概念图。
图12为说明根据本发明中描述的技术的用于识别视频块中或附近的时间运动向量(TMV)或DMV的实例技术的概念图。
图13A-13D是说明根据本发明的技术的用于识别TMV或DMV的实例扫描次序的概念图。
图14是说明可实施本发明中描述的技术的实例视频编码器的框图。
图15是说明可利用本发明中所描述的技术的实例视频解码器的框图。
图16为说明根据本发明中描述的技术的用于解码视频块的实例ARP方法的流程图。
图17为说明根据本发明中描述的技术的用于解码经视图间预测的视频块的实例视图间ARP方法的流程图。
图18为说明根据本发明中描述的技术的用于解码经时间预测视频块的实例时间ARP方法的流程图。
图19为说明根据本发明中描述的技术的用于编码视频块的实例ARP方法的流程图。
图20为说明根据本发明中描述的技术的用于编码经视图间预测的视频块的实例视图间ARP方法的流程图。
图21为说明根据本发明中描述的技术的用于编码经时间预测视频块的实例时间ARP方法的流程图。
图22为说明根据本发明中描述的技术的用于识别时间ARP的DMV的实例方法的流程图。
图23为说明根据本发明中描述的技术的用于识别ARP的TMV或DMV的实例方法的流程图。
具体实施方式
大体来说,本发明涉及多视图视频译码,其中经译码视频数据包含两个或两个以上视图。在一些实例中,多视图视频译码包含多视图加深度视频译码过程。在一些实例中,多视图译码可包含三维或3D视频的译码,且可被称作3D视频译码。一些所揭示的技术还可应用于除多视图或3D视频译码外的视频译码,例如可缩放视频译码或根据视频译码标准的基本规范的视频译码,例如其中视频数据并不包含多个视图或层。
本发明还涉及视频块的残余信号的预测,例如先进残余预测(ARP)。更确切地说,本发明描述用于非基础视图中多视图视频数据的纹理分量的更精确ARP的技术。用于更精确ARP的技术可包含识别从当前视频块的当前视图到参考视图的视差运动向量(DMV)。DMV为例如参考视图中的基于当前视频块或参考视频块的视频数据的用于当前视图中的视频数据的视图间预测的运动向量。所述技术可进一步包含使用所述经识别DMV来识别ARP的参考视频块,以及基于所述经识别参考视频块确定当前视频块的残余预测符块。经编码视频位流中识别的当前块的经译码残余块可为在基于经译码加权因子索引的潜在缩放之后正常残余块与残余预测符块之间的差,所述正常残余块为当前块与当前视频块的参考视频块之间的差。在本发明中,术语“当前”一般用于识别当前正译码的视图、图片或块。因此,相较于已经译码的视频块或相较于仍待译码的视频块,当前块通常表示正被译码的视频数据块。
在一些实例中,DMV可为当前视频块的DMV,在此情况下视频译码器可使用所述DMV来识别参考视图中的参考块。在此些实例中,所述技术可包含基于经识别DMV确定用于当前视频块的视图间ARP的视图间残余预测符块。在此些实例中,ARP不限于用于对经时间预测的视频块译码的时间ARP,而实际上可包含用于对经视图间预测的视频块译码的视图间ARP。视图间ARP可允许视频译码器更准确地计算不同存取单元中的视图间残余预测符以预测当前视频块的残余。
在一些实例中,当前视频块经时间预测,且DMV可为与当前视频块相同的视图中的时间参考块的DMV。在此些实例中,视频译码器可使用DMV而非针对当前视频块导出的视差向量(DV)来识别参考视图中的当前视频块的视图间参考块或用于当前视频块的时间ARP的参考视图中的时间参考块中的一或两者。视频译码器可使用基于DMV识别的块来更准确地计算时间残余预测符(参考视图中计算)以预测当前视频块的残余。在此些实例中,通常通过速率失真优化而选择的DMV可比所导出的视差向量更精确,这可导致当前视频块的更精确时间ARP。
视频译码标准包含ITU-T H.261、ISO/IEC MPEG-1 Visual、ITU-T H.262或ISO/IEC MPEG-2 Visual、ITU-T H.263、ISO/IEC MPEG-4 Visual及ITU-T H.264(也被称为ISO/IEC MPEG-4 AVC),包含其可缩放视频译码(SVC)及多视图视频译码(MVC)扩展。MVC的最新联合草案描述于2010年3月的“用于通用视听服务的高级视频译码”(ITU-T建议H.264)中。
近来,新的视频译码标准(即高效率视频译码(HEVC))的设计已由ITU-T视频译码专家组(VCEG)和ISO/IEC动画专家组(MPEG)的视频译码联合合作小组(JCT-VC)定案。下文中被称作HEVC WD10的最新HEVC草案说明书可从http://phenix.int-evry.fr/jct/doc_end_user/documents/12_Geneva/wg11/JCTVC-L1003-v34.zip获得。HEVC WD10的完全引用文件为布洛斯(Bross)等人“高效视频译码(HEVC)文本说明书草案10(用于FDIS以及最后调用)”,JCTVC-L1003_v34,ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码联合合作小组(JCT-VC),第12次会议:瑞士日内瓦,2013年1月14-23日。HEVC WD10全文以引用的方式并入本文中。
HEVC的多视图扩展(即MV-HEVC)也正由JCT-3V开发。下文中被称作MV-HEVC WD3的最新MV-HEVC工作草案(WD)可从http://phenix.it-sudparis.eu/jct2/doc_end_user/documents/3_Geneva/wg11/JCT3V-C1004-v4.zip获得。MV-HEVC WD3的完全引用文件为泰克(Tech)等人“MV-HEVC草案文本3(ISO/IEC 23008-2:201x/PDAM2)”,JCT3V-C1004_d3,ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的3D视频译码扩展开发联合合作小组,第3次会议:瑞士,日内瓦,2013年1月17-23日。MV-HEVC WD3全文以引用的方式并入本文中。
被称为SHVC的对HEVC的可缩放扩展也正由JCT-VC开发。下文中被称作SHVC WD1的SHVC的新近工作草案(WD)可从http://phenix.int-evry.fr/jct/doc_end_user/documents/12_Geneva/wg11/JCTVC-L1008-v1.zip获得。SHVC WD1的完全引用文件为陈(Chen)等人“SHVC草案文本1”,JCTVC-L1008,ITU-T SG 16 WP 3和ISO/IEC JTC1/SC29/WG 11的视频译码联合合作小组(JCT-VC),第12次会议:瑞士,日内瓦,2013年1月14-23日。SHVC WD1全文以引用的方式并入本文中。
当前,VCEG及MPEG的3D视频译码联合合作小组(JCT-3C)正在开发基于HEVC的3DV标准,其中标准化努力的一部分包含MV-HEVC的标准化,且标准化努力的另一部分包含基于HEVC(3D-HEVC)的3D视频译码(3DV)的标准化。对于3D-HEVC,可包含且支持用于纹理及深度视图两者的新译码工具,包含在译码单元/预测单元层级中的那些工具。3D-HEVC的最近参考软件测试模型(3D HTM-7.0)可从以下链接下载:https://hevc.hhi.fraunhofer.de/svn/svn_3DVCSoftware/tags/HTM-7.0/。
3D-HEVC的最近参考软件描述以及工作草案的完全引用文件如下:泰克(Tech)等人“3D-HEVC测试模型4”,JCT3V-D1005_spec_v1,ITU-T SG 16 WP 3和ISO/IEC JTC1/SC29/WG 11的3D视频译码扩展开发联合合作小组,第4次会议:韩国,仁川,2013年4月20-26日。3D-HEVC的此参考软件描述和工作草案可从以下链接下载:http://phenix.it-sudparis.eu/jct2/doc_end_user/documents/4_Incheon/wg11/JCT3V-D1005-v1.zip。3D-HTM-7.0和3D-HEVC测试模型4的相应全文以引用的方式并入本文中。
先前参考中的每一者的相应全文以引用的方式并入本文中。本发明中描述的技术可由根据(例如)HEVC的MV-HEVC或3D-HEVC扩展或H.264的MVC延伸操作的视频译码器实施。然而,本发明中描述的技术不限于那些标准,且可延伸到本文中所描述的其它视频译码标准或本文未提及的其它视频译码标准,包含提供视频译码中的残余预测的标准。
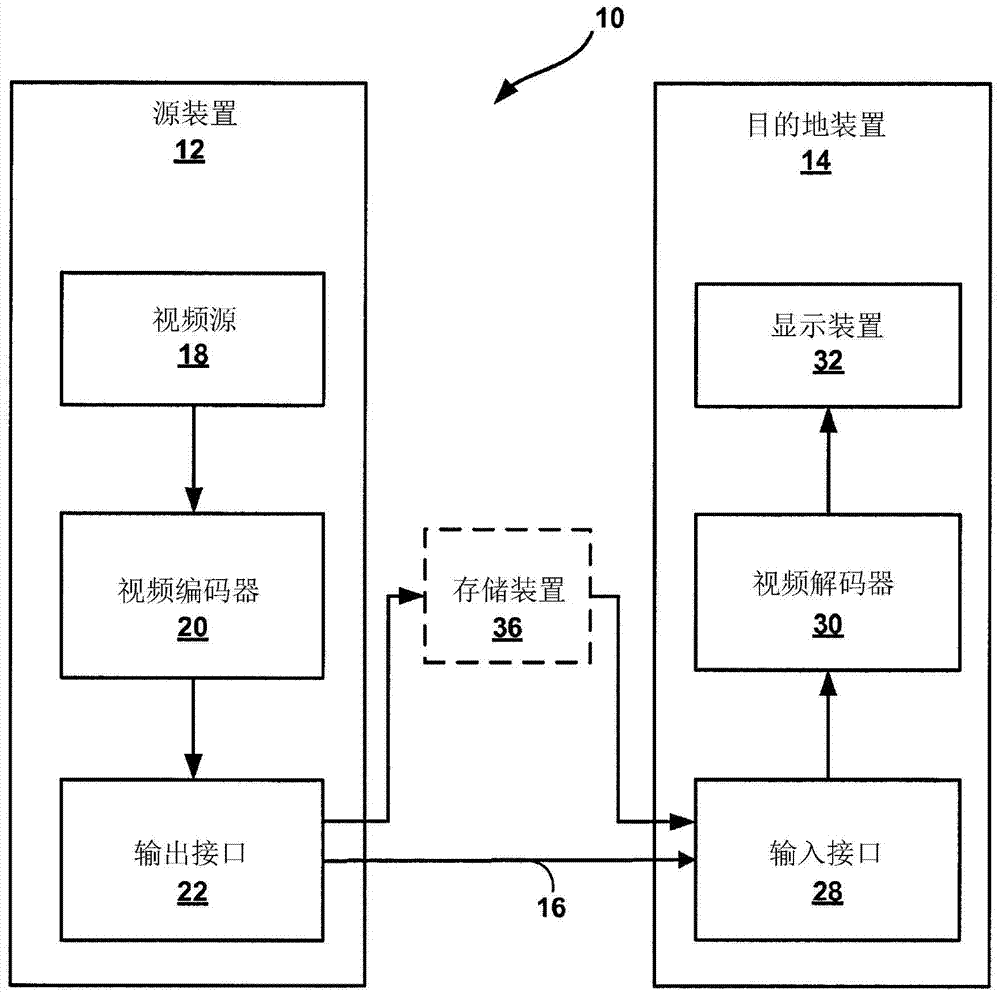
图1是说明根据本发明中所描述的一或多个实例的实例视频编码和解码系统的框图。举例来说,系统10包含源装置12及目的地装置14。源装置12和目的地装置14经配置以实施本发明中描述的技术。在一些实例中,系统10可经配置以支持经编码视频数据(例如,根据例如WD10中所描述的HEVC标准及其扩展(例如,MV-HEVC WD3、SHVC WD1、3D-HEVC测试模型4等中所描述的扩展)编码的视频数据)的编码、发射、存储、解码及/或呈现。然而,本发明中所描述的技术可适用于其它视频译码标准或其它扩展。
如图1中所展示,系统10包含源装置12,其产生稍后由目的地装置14解码的经编码视频数据。源装置12及目的地装置14可包括多种多样的装置中的任一者,包含台式计算机、笔记本(即,膝上型)计算机、平板计算机、机顶盒、电话手持机(例如所谓的“智能”电话)、所谓的“智能”平板计算机、电视机、相机、显示装置、数字媒体播放器、视频游戏控制台、视频串流装置或类似者。在一些情况下,源装置12及目的地装置14可经装备以用于无线通信。
目的地装置14可经由链路16接收待解码的经编码视频数据。链路16可包括能够将经编码视频数据从源装置12移动到目的地装置14的任何类型的媒体或装置。在一个实例中,链路16可包括使得源装置12能够实时地将经编码视频数据直接发射到目的地装置14的通信媒体。经编码视频数据可以根据通信标准(例如,无线通信协议)来调制,并且被发射到目的地装置14。通信媒体可包括任何无线或有线通信媒体,例如射频(RF)频谱或一或多个物理发射线路。通信媒体可形成基于包的网络(例如,局域网、广域网或例如因特网等全球网络)的部分。通信媒体可包含路由器、交换器、基站或任何其它可以用于促进从源装置12到目的地装置14的通信的设备。
在一些实例中,经编码数据可从输出接口22输出到存储装置36。类似地,可通过输入接口28从存储装置34存取经编码数据。存储装置36可包含多种分布式或本地存取的数据存储媒体中的任一者,例如硬盘驱动器、蓝光光盘、DVD、CD-ROM、快闪存储器、易失性或非易失性存储器或任何其它用于存储经编码视频数据的适当数字存储媒体。在另一实例中,存储装置36可对应于文件服务器或可保持由源装置12产生的经编码视频的另一中间存储装置。目的地装置14可经由串流或下载从存储装置36存取所存储的视频数据。文件服务器可以是能够存储经编码视频数据并且将所述经编码视频数据发射到目的地装置14的任何类型的服务器。实例文件服务器包含网络服务器(例如,用于网站)、FTP服务器、网络附接存储(NAS)装置或本地磁盘驱动器。目的地装置14可以经由任何标准数据连接(包含因特网连接)来存取经编码视频数据。此可包含适合于存取存储于文件服务器上的经编码的视频数据的无线信道(例如,Wi-Fi连接)、有线连接(例如,DSL、电缆调制解调器等)或两者的组合。经编码视频数据从存储装置36的发射可为串流发射、下载发射或两者的组合。
本发明的技术当然并不限于无线应用或设定。所述技术可应用于视频译码以支持多种多媒体应用中的任一者,例如空中电视广播、有线电视发射、卫星电视发射、串流视频发射(例如,经由因特网)、编码数字视频以存储于数据存储媒体上、解码存储于数据存储媒体上的数字视频,或其它应用。在一些实例中,系统10可经配置以支持单向或双向视频发射,以支持例如视频串流、视频重放、视频广播和/或视频电话等应用。
在图1的实例中,源装置12包含视频源18、视频编码器20和输出接口22。在一些情况下,输出接口22可包含调制器/解调器(调制解调器)和/或发射器。在源装置12中,视频源18可包含例如视频俘获装置(例如,摄像机)、含有先前俘获的视频的视频存档、用于从视频内容提供者接收视频的视频馈入接口及/或用于产生计算机图形数据作为源视频的计算机图形系统,或此类源的组合等源。作为一个实例,如果视频源18是摄像机,则源装置12与目的地装置14可形成所谓的相机电话或视频电话。然而,本发明中所描述的技术一般可适用于视频译码,且可应用于无线及/或有线应用。
可由视频编码器12来编码所俘获视频、经预先俘获的视频或计算机产生的视频。经编码视频数据可经由源装置12的输出接口22直接发射到目的地装置14。经编码视频数据还可(或替代地)存储到存储装置36上以供稍后由目的地装置14或其它装置存取以用于解码及/或重放。
目的地装置14包含输入接口28、视频解码器30和显示装置32。在一些情况下,输入接口28可包含接收器和/或调制解调器。目的地装置14的输入接口28经由链路16接收经编码视频数据。经由链路16传送或在存储装置36上提供的经编码视频数据可包含由视频编码器20所产生的多种语法元素以供由例如视频解码器30等视频解码器用于解码视频数据。此些语法元素可与在通信媒体上发射、存储在存储媒体上或存储在文件服务器中的经编码的视频数据包含在一起。
显示装置32可与目的地装置14一起集成或在目的地装置外部。在一些实例中,目的地装置14可包含集成式显示装置,并且还经配置以与外部显示装置介接。在其它实例中,目的地装置14可为显示装置。一般来说,显示装置32将经解码视频数据显示给用户,且可包括多种显示装置中的任一者,例如液晶显示器(LCD)、等离子体显示器、有机发光二极管(OLED)显示器或另一类型的显示装置。
视频编码器20和视频解码器30可根据视频压缩标准(例如当前开发下的HEVC标准以及HEVC标准的扩展(例如MV-HEVC、SHVC及3D-HEVC))操作。然而,本发明的技术不限于任何特定译码标准。
尽管图1中未展示,但在一些方面中,视频编码器20和视频解码器30可各自与音频编码器和解码器集成,且可包含适当的MUX-DEMUX单元或其它硬件和软件,以处置对共同数据流或单独数据流中的音频和视频两者的编码。在一些实例中,如果适用,那么MUX-DEMUX单元可符合ITU H.223多路复用器协议,或例如用户数据报协议(UDP)等其它协议。
视频编码器20和视频解码器30各自可实施为例如一或多个微处理器、数字信号处理器(DSP)、专用集成电路(ASIC)、现场可编程门阵列(FPGA)、离散逻辑、软件、硬件、固件或其任何组合等多种合适的编码器电路中的任一者。当部分地用软件实施所述技术时,装置可将用于所述软件的指令存储于合适的非暂时性计算机可读媒体中且使用一或多个处理器用硬件执行所述指令以执行本发明的技术。视频编码器20和视频解码器30中的每一者可包含在一或多个编码器或解码器中,所述编码器或解码器中的任一者可集成为相应装置中的组合编码器/解码器(CODEC)的一部分。
大体来说,视频编码器20和视频解码器30各自可遵照HEVC WD10、MV-HEVC WD3、SHVC WD1及/或3D-HEVC测试模型4(如上文所描述)而操作,或遵照本发明中所描述的技术在其中可有用的其它类似标准或扩展而操作。HEVC标准根据(例如)ITU-T H.264/AVC指定视频译码装置相对于现有装置的若干额外能力。举例来说,虽然H.264提供了九种帧内预测编码模式,但HEVC标准可提供多达三十三种帧内预测编码模式。
大体来说,视频帧或图片可划分成包含明度和色度样本两者的树块或最大译码单元(LCU)的序列。HEVC译码过程中的树块具有与H.264标准的宏块类似的目的。切片包含按译码次序的若干连续树块。视频帧或图片可被分割成一或多个切片。每一树块可根据四叉树而分裂成译码单元(CU)。举例来说,作为四叉树的根节点的树块可分裂成四个子节点,且每一子节点又可为父节点且分裂成另外四个子节点。最终的未分裂子节点(作为四叉树的叶节点)包括译码节点,即经译码视频块。与经译码位流相关联的语法数据可界定树块可分裂的最大次数,且还可界定译码节点的最小大小。
CU包含译码节点以及与所述译码节点相关联的预测单元(PU)和变换单元(TU)。CU的大小对应于译码节点的大小并且形状必须是正方形。CU的大小可从8x8像素到具有最大64x64像素或更大的树块的大小变动。每一CU可以含有一或多个PU和一或多个TU。举例来说,与CU相关联的语法数据可描述将CU分割成一或多个PU。分割模式可以在CU被跳过或经直接模式编码、经帧内预测模式编码或经帧间预测模式编码之间有区别。PU可分割成非正方形形状。举例来说,与CU相关联的语法数据还可描述根据四叉树将CU分割成一或多个TU。TU可为正方形或非正方形形状。
HEVC标准允许根据TU变换,TU可针对不同CU而有所不同。TU的大小通常是基于针对经分割的LCU定义的给定CU内的PU的大小来设置,但是情况可能并不总是如此。TU通常与PU大小相同或小于PU。在一些实例中,对应于CU的残余样本可以使用被称为“残余四叉树”(RQT)的四叉树结构细分成较小单元。RQT的叶节点可被称为变换单元(TU)。可以变换与TU相关联的像素差值以产生变换系数,所述变换系数可以经量化。
一般来说,PU包含与预测过程有关的数据。举例来说,当PU经帧内模式编码时,PU可包含描述PU的帧内预测模式的数据。作为另一实例,当PU经帧间模式编码时,PU可包含界定PU的运动向量的数据。定义PU的运动向量的数据可描述例如运动向量的水平分量、运动向量的垂直分量、运动向量的分辨率(例如,四分之一像素精度或八分之一像素精度)、运动向量所指向的参考图片及/或运动向量的参考图片列表(例如,RefPicList0(L0)或RefPicList1(L1))。
一般来说,TU用于变换和量化过程。具有一或多个PU的给定CU还可包含一或多个变换单元(TU)。在预测之后,视频编码器20可计算对应于PU的残余值。残余值包括像素差值,所述像素差值可变换成变换系数、经量化且使用TU进行扫描以产生串行化变换系数以用于熵译码。本发明通常使用术语“视频块”来指CU的译码节点。在一些特定情况下,本发明还可使用术语“视频块”来指包含译码节点以及PU及TU的树块,即,LCU或CU。
举例来说,对于根据HEVC标准的视频译码,视频帧可分割成译码单元(CU)、预测单元(PU)和变换单元(TU)。CU一般是指充当基本单元的图像区域,各种译码工具被应用于所述基本单元以实现视频压缩。CU通常具有正方形几何形状,且可以被认为类似于例如ITU-T H.264等其它视频译码标准下的所谓“宏块”。
为实现更好的译码效率,CU可取决于其含有的视频数据而具有可变大小。也就是说,CU可被分割或“分裂”成较小块或子CU,其中的每一者也可被称作CU。另外,分别出于CU的预测及变换的目的,未分裂成子CU的每一CU可进一步被分割成一或多个PU及TU。
PU可以被认为类似于例如H.264等其它视频译码标准下的块的所谓分割区。PU为执行块的预测以产生“残余”系数的基础。CU的残余系数表示CU的视频数据与使用CU的一或多个PU确定的CU的经预测数据之间的差。具体来说,所述一或多个PU指定出于预测的目的如何分割CU,及使用哪一预测模式来预测含于CU的每一分割区内的视频数据。
CU的一或多个TU指定CU的残余系数的块的分割区,基于此将变换应用于块以产生CU的残余变换系数的块。所述一或多个TU也可与所应用的变换的类型相关联。变换将残余系数从像素或空间域转换到例如频域等变换域。另外,所述一或多个TU可指定参数,基于所述参数将量化应用于残余变换系数的所得块以产生经量化残余变换系数的块。可量化残余变换系数以可能减小用以表示系数的数据的量。
CU通常包含表示为Y的一个明度分量及表示为U及V的两个色度分量。换句话说,未进一步分裂成子CU的给定CU可包含Y、U及V分量,出于CU的预测及变换的目的,其中的每一者可进一步被分割成一或多个PU及TU,如先前描述。举例来说,取决于视频取样格式,U及V分量的大小在样本的数目方面可与Y分量的大小相同或不同。因此,可对给定CU的Y、U及V分量中的每一者执行上文关于预测、变换及量化所描述的技术。
为了对CU进行编码,首先基于CU的一或多个PU导出CU的一或多个预测符。预测符为含有CU的经预测数据的参考块,且是基于CU的对应PU导出的,如先前描述。举例来说,PU指示将确定经预测数据的CU的分割区,及用以确定经预测数据的预测模式。可经由帧内(I)预测(即空间预测)或帧间(P或B)预测(即,时间预测)模式来导出预测符。因此,一些CU可使用相对于相同帧中的相邻参考块或CU的空间预测来进行帧内译码(I),而其它CU可相对于其它帧中的参考块或CU进行帧间译码(P或B)。
在基于CU的所述一或多个PU识别所述一或多个预测符后,即刻计算对应于所述一或多个PU的CU的原始视频数据与含于所述一或多个预测符中的CU的经预测数据之间的差。也被称作预测残余的此差包括残余系数,且指代由所述一或多个PU指定的CU的部分与所述一或多个预测符之间的像素差,如先前描述。残余系数通常布置成对应于CU的所述一或多个PU的二维(2-D)阵列。
为实现进一步压缩,通常例如使用离散余弦变换(DCT)、整数变换、卡忽南-拉维(K-L)变换或另一变换来变换预测残余。变换将空间域中的预测残余(即,残余系数)转换成变换域(例如频域)中的残余变换系数,也如先前所描述。变换系数通常还布置成对应于CU的所述一或多个TU的2-D阵列。为了进一步压缩,可量化残余变换系数以可能减小用以表示系数的数据的量,也如先前所描述。
为了实现更进一步压缩,熵译码器随后使用上下文自适应二进制算术译码(CABAC)、上下文自适应可变长度译码(CAVLC)、概率区间分割熵译码(PIPE)或另一熵译码方法对所得残余变换系数进行编码。熵译码可通过相对于其它CU减少或移除由系数表示的CU的视频数据中所固有的统计冗余而实现此进一步压缩。
视频序列通常包含一系列视频帧或图片。图片群组(GOP)一般包括一系列的视频图片中的一或多者。GOP可包含GOP的标头、图片中的一或多者的标头或其它地方中的语法数据,其描述GOP中包含的图片的数目。图片的每一切片可包含切片语法数据,其描述用于相应切片的编码模式。视频编码器20通常对个别视频切片内的视频块进行操作以便对视频数据进行编码。视频块可对应于CU内的译码节点。视频块可具有固定或变化的大小,并且可根据指定译码标准而有不同大小。
作为一实例,HEVC支持各种PU大小的预测。假设特定CU的大小为2Nx2N,那么HEVC支持2Nx2N或NxN的PU大小的帧内预测,及2Nx2N、2NxN、Nx2N或NxN的对称PU大小的帧间预测。HEVC还支持用于2NxnU、2NxnD、nLx2N和nRx2N的PU大小的帧间预测的不对称分割。在不对称分割中,不分割CU的一个方向,而另一方向分割成25%及75%。CU的对应于25%分割区的部分由“n”后面接着“上方”、“下方”、“左侧”或“右侧”的指示来指示。因此,例如,“2NxnU”是指水平地分割的2Nx2N CU,其中顶部为2Nx0.5N PU,而底部为2Nx1.5N PU。
在本发明中,“N×N”与“N乘N”可互换使用来指代在垂直及水平尺寸方面的视频块的像素尺寸,例如,16×16像素或16乘16像素。一般来说,16x16块将在垂直方向上具有16个像素(y=16),且在水平方向上具有16个像素(x=16)。同样,NxN块总体上在垂直方向上具有N个像素,且在水平方向上具有N个像素,其中N表示非负整数值。一块中的像素可布置成行和列。此外,块未必需要在水平方向上具有与在垂直方向上相同数目个像素。举例来说,块可包括NxM像素,其中M未必等于N。
在使用CU的PU进行帧内预测性或帧间预测性译码之后,视频编码器20可以计算用于CU的TU的残余数据。PU可包括空间域(也被称作像素域)中的像素数据,且在将变换应用到残余视频数据之后,TU可包括变换域中的系数,所述变换例如离散余弦变换(DCT)、整数变换、小波变换或概念上类似的变换。残余数据可以对应于未经编码图片的像素与对应于PU的预测值之间的像素差。视频编码器20可形成包含用于CU的残余数据的TU,且接着变换TU以产生用于CU的变换系数。
在进行用于产生变换系数的任何变换之后,视频编码器20可执行变换系数的量化。量化通常是指将变换系数量化以可能减少用以表示系数的数据量从而提供进一步压缩的过程。量化过程可减小与变换系数中的一些或全部相关联的位深度。举例来说,n位值可在量化期间向下舍入到m位值,其中n大于m。
在一些实例中,视频编码器20可利用预定义扫描次序来扫描经量化的变换系数以产生可经熵编码的串行化向量。在其它实例中,视频编码器20可执行自适应扫描。在扫描经量化变换系数以形成一维向量之后,视频编码器20可例如根据上下文自适应可变长度译码(CAVLC)、上下文自适应二进制算术译码(CABAC)、基于语法的上下文自适应二进制算术译码(SBAC)、概率区间分割熵(PIPE)译码或另一熵编码方法对所述一维向量进行熵编码。视频编码器20还可对与经编码视频数据相关联的语法元素进行熵编码以供视频解码器30在解码视频数据时使用。
为了执行CABAC,视频编码器20可以向待发射的符号指派上下文模型内的上下文。举例来说,所述上下文可以涉及符号的相邻值是否为非零。为了执行CAVLC,视频编码器20可选择用于待发射的符号的可变长度码。VLC中的码字可经构造而使得相对较短的代码对应于更有可能的符号,而较长的代码对应于不太可能的符号。以此方式,使用VLC可与例如对待发射的每一符号使用等长码字相比实现位节省。概率确定可基于指派到符号的上下文。
视频编码器20可例如在帧标头、块标头、切片标头或GOP标头中进一步将例如基于块的语法数据、基于帧的语法数据和基于GOP的语法数据等语法数据发送到视频解码器30。GOP语法数据可描述相应GOP中的帧的数目,且帧语法数据可指示用以编码对应帧的编码/预测模式。
此外,视频编码器20可例如通过逆量化和逆变换残余数据而解码或重建经编码图片,且将残余数据与预测数据组合。以此方式,视频编码器20可模拟由视频解码器30执行的解码过程。视频编码器20和视频解码器30两者因此将能够存取实质上相同经解码或经重建图片以供用于图片间预测。
一般来说,视频解码器30可执行与由视频编码器执行的编码过程相反的解码过程。举例来说,视频解码器30可使用由视频编码器用于对经量化视频数据进行熵编码的熵编码技术的相反过程来执行熵解码。视频解码器30可进一步使用由视频编码器20采用的量化技术的相反过程来逆量化所述视频数据,且可执行由视频编码器20用于产生经量化的变换系数的变换的相反过程。视频解码器30可随后将所得的残余块应用于邻近的参考块(帧内预测)或来自另一图片(帧间预测)的参考块以产生用于最终显示的视频块。视频解码器30可经配置、经指令控制或经引导以基于由视频编码器20提供的语法元素与由视频解码器30接收的位流中的经编码视频数据来执行由视频编码器20执行的各种过程的相反过程。如本文所使用,术语“视频译码器”可指代例如视频编码器20等视频编码器或例如视频解码器30等视频解码器。此外,术语“视频译码”或“译码”可指代例如由视频编码器进行的编码或例如由视频解码器进行的解码中的任一者或两者。
在一些实例中,视频编码器20和视频解码器30(图1)可使用用于多视图视频译码(例如包含两个或两个以上视图的视频数据的译码)的技术。在此些实例中,视频编码器20可编码包含两个或两个以上视图的经编码视频数据的位流,且视频解码器30可解码所述经编码视频数据以将所述两个或两个以上视图提供(例如)到显示装置32。在一些实例中,视频解码器30可提供视频数据的多个视图以使显示装置32能够显示3D视频。在一些实例中,视频编码器20和视频解码器30可符合HEVC标准的3D-HEVC扩展,例如其中使用多视图译码或多视图加深度译码过程。多视图或3D视频译码可涉及两个或两个以上纹理视图和/或包含纹理和深度分量的视图的译码。在一些实例中,由视频编码器20编码且由视频解码器30解码的视频数据包含任何给定时间例项(即,“存取单元”内)的两个或两个以上图片,或可从其导出任何给定时间例项的两个或两个以上图片的数据。
在一些实例中,装置(例如视频源18)可通过例如使用两个或两个以上空间偏移相机或其它视频俘获装置来俘获共同场景而产生所述两个或两个以上图片。自稍微不同的水平位置同时或几乎同时俘获的相同场景的两个图片可用以产生三维效果。在一些实例中,视频源18(或源装置12的另一组件)可使用深度信息或视差信息从在给定时间例项处的第一视图的第一图片产生在所述给定时间例项处的第二(或其它额外)视图的第二(或其它额外)图片。在此状况下,存取单元内的视图可包含对应于第一视图的纹理分量及可与所述纹理分量一起使用以产生第二视图的深度分量。深度或视差信息可由俘获第一视图的视频俘获装置例如基于相机参数或关于视频俘获装置的配置及第一视图的视频数据的俘获的其它已知信息来确定。深度或视差信息可另外地或可替代地例如由视频源18或源装置12的另一组件从相机参数及/或第一视图中的视频数据进行计算。
为呈现3D视频,显示装置32可同时或几乎同时显示与共同场景的不同视图相关联的两个图片,其是同时或几乎同时俘获的。在一些实例中,目的地装置14的用户可戴上主动式眼镜以快速地及替代性地遮挡左及右镜片,且显示装置32可快速在左视图与右视图之间与主动式眼镜同步地切换。在其它实例中,显示装置32可同时显示两个视图,且用户可佩戴被动式眼镜(例如,具有偏光镜片),其对视图进行过滤,从而致使恰当视图进入到用户的眼睛。在其它实例中,显示装置32可包括裸眼式立体显示器,其并不需要让用户感知到3D效果的眼镜。
多视图视频译码指代对多个视图进行译码的方式。在3D视频译码的状况下,所述多个视图可例如对应于左眼视图及右眼视图。所述多个视图中的每一视图包含多个图片。检视者对3D场景的感知归因于不同视图的图片中的对象之间的水平视差。
当前图片的当前块的视差向量(DV)是指向在与当前图片不同的视图中的对应图片中的对应块的向量。因此,使用DV,视频译码器可在对应图片中定位对应于当前图片的当前块的块。在此情况下,对应图片是与当前图片为相同的时间例项但在不同视图中的图片。对应图片中的对应块和当前图片中的当前块可包含相似视频内容;然而,当前图片中的当前块的位置与对应图片中的对应块的位置之间存在至少水平视差。当前块的DV提供对应图片中的块与当前图片中的当前块之间的此水平视差的量度。
在一些情况下,还可存在对应图片内的块的位置与当前图片内的当前块的位置之间的垂直视差。当前块的DV还可提供对应图片中的块与当前图片中的当前块之间的此垂直视差的量度。DV含有两个分量(x分量和y分量),但在许多情况下垂直分量将等于零。当前视图的当前图片和不同视图的对应图片所显示的时间可为相同的,也就是说当前图片和对应图片是同一时间例项的图片。
在视频译码中,通常存在两种类型的预测,通常被称为帧内预测和帧间预测。在帧内预测中,视频译码器基于相同图片中的已经译码块预测图片中的视频块。在帧间预测中,视频译码器基于不同图片(即参考图片)的已经译码块预测图片中的视频块。如本发明中所使用,参考图片通常指代含有可用于按解码次序的后续图片的解码过程中的帧间预测的样本的任何图片。当例如根据3D-HEVC相对于当前图片对多视图内容译码时,参考图片可属于相同时间例项但在不同视图中或可在相同视图中但属于不同时间例项。在例如3D-HEVC中的多视图译码的情况下,图片间预测可包含从时间上不同图片中的另一视频块(即,从与当前图片不同的存取单元)预测当前视频块(例如CU的当前译码节点),以及从与当前图片相同的存取单元中的但同与当前图片不同的视图相关联的不同图片预测。
在帧间预测的后一种情况下,其可被称作视图间译码或视图间预测。在多视图译码中,在相同存取单元(即,具有相同时间例项)的不同视图中俘获的图片当中执行视图间预测以移除视图之间的相关。在对例如相依视图等非基础视图的图片译码时,来自相同存取单元但不同视图(例如来自参考视图,例如基础视图)的图片可添加到参考图片列表。视图间参考图片可放置到参考图片列表的任何位置中,正如任何帧间预测(例如,时间或视图间)参考图片的情况。
用于预测当前图片的块的参考图片的块由运动向量识别。在多视图译码中,存在至少两个种类的运动向量。时间运动向量(TMV)为指向在与正被译码的块相同的视图中但与正被译码的块不同的时间例项或存取单元的时间参考图片中的块的运动向量,且对应帧间预测被称作经运动补偿的预测(MCP)。另一类型的运动向量为视差运动向量(DMV),其指向与当前图片相同的存取单元中的但属于不同视图的图片中的块。利用DMV,对应帧间预测被称作经视差补偿的预测(DCP)或视图间预测。
图2为说明实例多视图编码或解码次序的图形图。图2中所说明的解码次序布置可被称作时间优先译码。大体来说,对于每一存取单元(即,具有相同时间例项),多视图或3D视频序列可分别包含两个或两个以上视图中的每一者的两个或两个以上图片。在图2中,S0到S7各自是指多视图视频的不同视图。T0到T8各自表示一个输出时间例项。存取单元可包含针对一个输出时间例项的所有视图的经译码图片。举例来说,第一存取单元包含用于时间实例T0的所有视图S0到S7(即,图片0到7),第二存取单元包含用于时间实例T1的所有视图S0到S7(即,图片8到15),等等。在此实例中,图片0到7是在相同时间例项(即,时间例项T0),且图片8到15是在相同时间例项(即,时间例项T1)。通常同时显示具有相同时间例项的图片,且相同时间例项的图片内的对象之间的水平视差及可能一些垂直视差致使检视者感知到包含3D体积的图像。
在图2中,所述视图中的每一者包含图片集合。举例来说,视图S0包含图片集合0、8、16、24、32、40、48、56和64,视图S1包含图片集合1、9、17、25、33、41、49、57和65等等。每一集合包含两个图片:一个图片称为纹理视图分量,且另一图片称为深度视图分量。视图的一图片集合内的纹理视图分量及深度视图分量可被视为对应于彼此。举例来说,视图的一图片集合内的纹理视图分量可被视为对应于视图的所述图片集合内的深度视图分量,且反之亦然(即,深度视图分量对应于所述集合中的其纹理视图分量,且反之亦然)。如本发明中所使用,相对应的纹理视图分量及深度视图分量可被视为单一存取单元的相同视图的一部分。
纹理视图分量包含所显示的实际图像内容。举例来说,纹理视图分量可包含明度(Y)和色度(Cb和Cr)分量。深度视图分量可指示其对应纹理视图分量中的像素的相对深度。作为一个实例,所述深度视图分量可类似于仅包含明度值的灰度图像。换句话说,深度视图分量可不传达任何图像内容,而是提供纹理视图分量中的像素的相对深度的量度。
举例来说,对应于深度视图分量中的纯白色像素的像素值可指示其在对应的纹理视图分量中的对应像素从检视者的角度来看更靠近,且对应于深度视图分量中的纯黑色像素的像素值可指示其在对应的纹理视图分量中的对应像素从检视者的角度来看更远离。对应于黑色与白色之间的各种灰阴影的像素值指示不同的深度水平。举例来说,深度视图分量中的深灰色像素指示其在纹理视图分量中的对应像素比深度视图分量中的浅灰色像素更远。因为仅需要类似于灰度的一个像素值来识别像素深度,所以深度视图分量可仅包含一个像素值。因此,不需要类似于色度分量的值。
深度视图分量仅使用明度值(例如,强度值)来识别深度是出于说明的目的而提供,且不应被视为限制性的。在其它实例中,可利用任何技术来指示纹理视图分量中的像素的相对深度。
根据多视图译码,从相同视图中的纹理视图分量或从一或多个不同视图中的纹理视图分量对纹理视图分量进行帧间预测。纹理视图分量可在视频数据块中经译码,视频数据块被称作“视频块”且通常在H.264上下文中称为宏块,或在HEVC上下文中称为树块或译码单元(CU)。
任何类似时间例项的图片可包含类似内容。然而,类似时间例项中的不同图片的视频内容可在水平方向上相对于彼此稍许移位。举例来说,如果一块位于视图S0的图片0中的(x,y)处,那么位于视图S1的图片1中的(x+x',y)处的块包含与位于视图S0的图片0中的(x,y)处的块类似的视频内容。在此实例中,位于视图S0的图片0中的(x,y)处的块及位于视图S1的图片1中的(x+x',y)处的块被视为对应块。在一些实例中,位于视图S1的图片1中的(x+x',y)处的块的DV涉及其对应块的位置。举例来说,位于(x+x',y)的块的DV为(-x',0)。
在一些实例中,视频编码器20或视频解码器30可利用第一视图的图片中的块的DV以识别第二视图的图片中的对应块。视频编码器20和视频解码器20可(例如)在执行视图间预测时利用DV。视频编码器20和视频解码器30可(例如)通过使用当前块的DV确定的参考视图中的参考图片的参考块的信息执行视图间预测。
图3为说明用于多视图视频译码的实例时间和视图间预测图案的概念图。类似于图2的实例,在图3的实例中,说明了八个视图(具有视图ID“S0”到“S7”),且对于每一视图说明了十二个时间位置或存取单元(“T0”到“T11”)。即,图3中的每一行对应于一视图,而每一列指示时间位置或存取单元。对象(其可为图片或不同图片中的实例视频块)在图3中的每一行与每一列的相交处指示。具有MVC扩展的H.264/AVC标准可使用术语帧来表示视频的一部分,而HEVC标准可使用术语图片来表示视频的一部分。本发明可互换地使用术语图片与帧。
在图3中,视图S0可被视为基础视图,且视图S1到S7可被视为相依视图。基础视图包含未被视图间预测的图片。可相对于相同视图中的其它图片对基础视图中的图片进行帧间预测。举例来说,视图S0中并无图片可相对于视图S1到S7中的任一者中的图片被帧间预测,但视图S0中的图片中的一些可相对于视图S0中的其它图片被帧间预测。
另外,存取单元T0和T8是图3的实例预测结构的视频序列的随机存取单元或随机存取点。如图3的实例预测结构中标记为“I”的块所说明,在每一随机存取点(T0和T8)处,基础视图图片(S0)的视频块经图片内预测。随机存取点中的其它非基础视图图片或非随机存取点中的基础和非基础视图图片的视频块可经由时间帧间预测或视图间预测而经图片间预测,如图3的实例预测结构中标记为“I”、“B”、“P”或“b”的各种块所说明。图3的实例预测结构中的预测由箭头指示,其中箭头指向的图片使用箭头出发的图片用于预测参考。。
相依视图包含被视图间预测的图片。举例来说,视图S1到S7中的每一者包含相对于另一视图中的图片被帧间预测的至少一个图片。相依视图中的图片可相对于基础视图中的图片被帧间预测,或可相对于其它相依视图中的图片被帧间预测。在图3的实例中,大写的“B”及小写的“b”用于指示图片之间的不同阶层关系,而非不同译码方法。大体来说,大写的“B”图片在预测层次上比小写的“b”帧相对高。
包含基础视图及一或多个相依视图两者的视频流可为可由不同类型的视频解码器进行解码的。举例来说,一个基本类型的视频解码器可经配置以仅解码基础视图。另外,另一类型的视频解码器可经配置以解码视图S0到S7中的每一者。经配置以对基础视图及相依视图两者进行解码的解码器可被称作支持多视图译码的解码器。
使用包含字母的阴影块说明图3中的图片(或其它对象),所述字母指明对应图片是经帧内译码(也就是说,I图片),在一个方向上经帧间译码(也就是说,作为P图片)还是在多个方向上经帧间译码(也就是说,作为B图片)。一般来说,预测通过箭头来指示,其中箭头指向的图片使用箭头出发的图片用于预测参考。举例来说,时间位置T0处的视图S2的P图片是从时间位置T0处的视图S0的I图片预测的。
如同单视图视频编码,多视图视频译码视频序列的图片可相对于不同时间位置处的图片预测性地编码。举例来说,时间位置T1处的视图S0的B图片具有从时间位置T0处的视图S0的I图片指向其的箭头,从而指示所述b图片是从所述I图片预测的。然而,另外,在多视图视频编码的上下文中,图片可经视图间预测。也就是说,视图分量(例如,纹理视图分量)可出于参考目的使用其它视图中的视图分量。举例来说,在多视图译码中,实现了视图间预测,好像另一视图中的视图分量为帧间预测参考。潜在视图间参考可用信号发出,且可由参考图片列表建构过程来修改,这使得能够灵活排序帧间预测或视图间预测参考。
图3提供视图间预测的各种实例。在图3的实例中,视图S1的图片说明为是从视图S1的不同时间位置处的图片预测,以及是从相同时间位置处的视图S0和S2的图片经视图间预测。举例来说,时间位置Tl处的视图S1的B图片是从时间位置T0及T2处的视图S1的B图片中的每一者以及时间位置T1处的视图S0及S2的B图片预测。
图3还说明使用不同阴影等级的预测阶层的变化,其中较大阴影量(即,相对较暗)的帧在预测阶层上高于具有较少阴影(即,相对较浅)的那些帧。举例来说,图3中的所有I图片说明为具有完全阴影,而P图片具有稍浅的阴影,且B图片(及小写的b图片)具有相对于彼此的各种阴影水平,但始终比P图片及I图片的阴影浅。
一般来说,预测阶层可与视图次序索引相关,因为预测阶层相对较高的图片应在解码阶层相对较低的图片之前解码。阶层相对较高的那些图片在对阶层相对较低的图片进行解码期间可以用作参考图片。视图次序索引为指示存取单元中的视图分量的解码次序的索引。视图分量的解码可遵循视图次序索引的升序。如果呈现所有视图,则视图次序索引集合可包括从零到视图的全部数目少1的连续有序集合。
对于处于阶层的相等层级处的某些图片,相对于彼此的解码次序可能无关紧要。举例来说,时间位置T0处的视图S0的I图片可被用作时间位置T0处的视图S2的P图片的参考图片,所述P图片又可被用作时间位置T0处的视图S4的P图片的参考图片。因此,时间位置T0处的视图S0的I图片应在时间位置T0处的视图S2的P图片之前解码,所述P图片又应在时间位置T0处的视图S4的P图片之前解码。然而,在视图S1与S3之间,解码次序无关紧要,因为对于预测,视图S1及S3并不依赖于彼此。替代地,仅从预测阶层较高的其它视图预测视图S1及S3。此外,视图S1可在视图S4之前解码,只要视图S1在视图S0及S2之后解码即可。
如上文所描述,在3D-HEVC中,视频编码器20及视频解码器30可参考第二视图的参考图片内的参考块对第一视图的当前图片内的当前块进行帧间预测。此帧间预测被称作视图间预测。当前图片及参考图片的时间例项在相应视图中可为相同的。在此些实例中,视频编码器20或视频解码器30执行跨相同存取单元中的图片的视图间预测,其中相同存取单元中的图片在相同时间例项处。
为了对当前块执行视图间预测,视频编码器20或视频解码器30建构参考图片列表,其识别可用于帧间预测的参考图片,包含可用于视图间预测的图片。帧间预测是指相对于参考图片中的参考块预测当前图片中的当前块。视图间预测为帧间预测的子集,因为在视图间预测中,参考图片在不同于当前图片的视图的视图中。因此,对于视图间预测,视频编码器20及视频解码器30将另一视图中的参考图片添加于经建构参考图片列表中的一者或两者中。可在经建构参考图片列表内的任何位置处识别另一视图中的参考图片。如本发明中所使用,当视频编码器20正对块执行帧间预测(例如,帧间预测)时,视频编码器20可被认为是对块进行帧间预测编码。当视频解码器30正对块执行帧间预测(例如,帧间预测)时,视频解码器30可被视为对块进行帧间预测解码。在视图间预测中,当前视频块的DMV识别视图中的参考图片中的块的位置(其中所述图片包含待用作用于对当前块进行帧间预测的参考块的待预测的视频块的视图除外),且到经建构参考图片列表中的一或两者中的参考索引识别另一视图中的参考图片。
本发明描述用于执行ARP的技术,其包含识别当前视频块或参考视频块的DMV,以及基于经识别DMV确定用于当前视频块的残余预测符块。当前视频块或与当前视频块相同的视图中的参考视频块的DMV可视为从当前视频块的当前视图到用于基于参考视图中的视频数据对当前视图中的视频数据进行视图间预测的参考视图的DMV。本发明的技术可由视频编码器20及视频解码器30中的一者或两者来实施。这些技术可例如与基于HEVC的多视图视频译码和/或基于HEVC的3D视频译码结合使用。
如上文所论述,界定视频数据块的TMV或DMV的数据可包含向量的水平分量和垂直分量以及所述向量的分辨率。视频块的运动信息可包含运动向量,以及预测方向和参考图片索引值。另外,当前视频块的运动信息可从也可被称作参考视频块的相邻视频块的运动信息预测。参考视频块可为同一图片内的空间相邻者、相同视图的不同图片内但不同存取单元内的时间相邻者,或不同视图的不同图片内但相同存取单元内的视频块。在来自不同视图中的参考块的运动信息的情况下,运动向量可为从视图间参考图片(即,与当前图片相同的存取单元中但来自不同视图的参考图片)中的参考块导出的TMV或从DV导出的DMV。
通常,对于运动信息预测,以经界定方式形成来自各种参考块的候选运动信息的列表,例如使得来自各种参考块的运动信息考虑以经界定次序包含在列表中。在形成候选者列表之后,视频编码器20可评估每一候选者以确定哪一者提供与经选定用于编码视频的给定速率和失真简档最佳匹配的最佳速率和失真特性。视频编码器20可相对于候选者中的每一者执行速率失真优化(RDO)程序,从而选择运动信息候选者中的具有最佳RDO结果的一者。或者,视频编码器20可选择最佳近似经确定用于当前视频块的运动信息的存储在列表中的候选者中的一者。
在任何情况下,视频编码器20可使用识别运动信息的候选者列表中的候选者中的选定一者的索引指定所述选定的候选者。视频编码器20可信令经编码位流中的此索引以供由视频解码器30使用。为了译码效率,候选者可在列表中排序使得最可能经选定用于对当前视频块译码的候选运动信息首先或以其它方式与最低量值索引值相关联。
用于运动信息预测的技术可包含合并模式、跳过模式和高级运动向量预测(AMVP)模式。大体来说,根据合并模式和/或跳过模式,当前视频块继承来自例如同一图片中的空间上相邻块或时间或视图间参考图片中的块等另一先前经译码相邻块的例如运动向量、预测方向和参考图片索引等运动信息。当实施合并/跳过模式时,视频编码器20经界定方式建构作为参考块的运动信息的合并候选者的列表,选择所述合并候选者中的一者,且在位流中向视频解码器30信令识别所述选定合并候选者的候选者列表索引。
视频解码器30在实施合并/跳过模式时接收此候选者列表索引,根据经界定方式重建合并候选者列表,且选择候选者列表中的合并候选者中的由索引指示的一者。视频解码器30可随后将合并候选者中的所述选定一者实体化为处于与合并候选者中的所述选定一者的运动向量相同的分辨率且指向与合并候选者中的所述选定一者的运动向量相同的参考图片的当前PU的运动向量。因此,在解码器侧,一旦候选者列表索引经解码,就可继承选定的候选者的对应块的所有运动信息,例如运动向量、预测方向和参考图片索引。合并模式和跳过模式通过允许视频编码器20信令到合并候选者列表中的索引而非用于当前视频块的帧间预测的所有运动信息而促进位流效率。
当实施AMVP时,视频编码器20以经界定方式建构候选运动向量预测符(MVP)的列表,选择所述候选者MVP中的一者,且在位流中向视频解码器30信令识别所述选定MVP的候选者列表索引。类似于合并模式,当实施AMVP时,视频解码器30以经界定方式重建候选者MVP的列表,解码来自编码器的候选者列表索引,且基于候选者列表索引选择和实体化MVP中的一者。
然而,与合并/跳过模式相反,当实施AMVP时,视频编码器20还信令参考图片索引和预测方向,因此指定候选者列表索引指定的MVP指向的参考图片。此外,视频编码器20确定当前块的运动向量差(MVD),其中MVD为MVP与原本将用于当前块的实际运动向量之间的差。对于AMVP,除参考图片索引、参考图片方向和候选者列表索引之外,视频编码器20还在位流中信令当前块的MVD。归因于给定块的参考图片索引和预测向量差的信令,AMVP可不如合并/跳过模式有效,但可提供经译码视频数据的改进的保真度。
图4展示来自另一图片但在与当前图片相同的视图中的当前视频块47、五个空间相邻块(41、42、43、44和45)和时间参考块46的实例。时间参考块46可(例如)为不同时间例项的图片中但在与当前视频块47相同的视图中的协同定位块。在一些实例中,当前视频块47和参考视频块41-46可如当前开发中的HEVC标准中通常所界定。参考视频块41-46根据当前开发中的HEVC标准标记为A0、A1、B0、B1、B2和T。视频编码器20及视频解码器30可根据例如合并/跳过模式或AMVP模式等运动信息预测模式基于参考视频块41-46的运动信息预测当前视频块47的运动信息(包含TMV)。如下文更详细地描述,视频块的TMV可与DMV一起使用以实现根据本发明的技术的先进残余预测。
如图4中所说明,视频块42、44、43、41和45可分别相对于当前视频块47在左侧、上方、右上方、左下方和左上方。然而,相邻块41-45相对于图4中说明的当前视频块47的数目和位置仅是实例。在其它位置中,不同数目的相邻块和/或不同位置处的块的运动信息可考虑包含在当前视频块47的运动信息预测候选者列表中。
空间相邻块42、44、43、41和45中的每一者与当前视频块47的空间关系可描述如下。明度位置(xP,yP)用以指定相对于当前图片的左上样本的当前块的左上明度样本;变量nPSW和nPSH指代针对明度的当前块的宽度和高度。空间上相邻块42的左上明度样本为xP-1,yP+nPSH-1。空间上相邻块44的左上明度样本为xP+nPSW-1,yP-1。空间上相邻块43的左上明度样本为xP+nPSW,yP-1。空间上相邻块41的左上明度样本为xP-1,yP+nPSH。空间上相邻块45的左上明度样本为xP-1,yP-1。尽管相对于明度位置描述,当前和参考块可包含色度分量。
空间相邻块41-45中的每一者可提供用于预测当前视频块47的运动信息(例如TMV)的空间运动信息候选者。例如视频编码器20(图1)或视频解码器30(图1)等视频译码器可以预定次序(例如扫描次序)考虑空间上相邻参考块的运动信息。举例来说,在3D-HEVC的情况下,视频解码器可考虑参考块的运动信息以以下次序包含在合并模式的合并候选者列表中:42、44、43、41和45。在所说明的实例中,空间相邻块41-45在当前视频块47左侧和/或上方。此布置为典型的,因为大多数视频译码器以光栅扫描次序从图片的左上方对视频块译码。因此,在此些实例中,空间相邻块41-45将通常在当前视频块47之前经译码。然而,在其它实例中,例如当视频译码器以不同次序对视频块译码时,空间相邻块41-45可位于当前视频块47的右侧和/或下方。
时间参考块46位于在当前视频块47的当前图片之前(但不必在译码次序中紧邻在其之前)经译码的时间参考图片内。另外,块46的参考图片并不一定按显示次序在当前视频块47的图片之前。参考视频块46可通常相对于当前图片中当前视频块47的位置协同定位在参考图片中。在一些实例中,参考视频块46位于当前图片中当前视频块47的位置右侧和下方,或覆盖当前图片中当前视频块47的中心位置。
图5为说明例如根据合并/跳过模式或AMVP模式导出经视图间预测的运动向量候选者(IPMVC)和视图间视差运动向量候选者(IDMVC)用于预测当前视频块50的运动信息的实例的概念图。当视图间预测经启用时,视频编码器20和/或视频解码器30可将新的运动向量候选者IPMVC或IDMVC添加到当前视频块50的运动信息候选者列表。IPMVC可预测当前视频块50的TMV,根据本发明的技术,视频编码器20和/或视频解码器30可将其用于当前视频块50或另一视频块的ARP,如下文更详细描述。IDMVC可预测当前视频块50的DMV,根据本发明的技术,视频编码器20和/或视频解码器30可将其用于当前视频块50或另一视频块的ARP,如下文更详细描述。
在图5的实例中,当前块50处于当前视图Vm中。视频编码器20和/或视频解码器30可使用视差向量(DV)51将对应或参考块52定位在参考视图V0中。视频译码器可基于相机参数或根据本文中所描述的技术中的任一者确定DV 51。举例来说,视频译码器可基于相邻块的DV例如使用基于相邻块的视差向量导出(NBDV)而确定当前视频块50的DV 51。
如果参考块52并不经帧内译码且不经视图间预测,且其参考图片(例如参考图片58或参考图片60)具有等于当前视频块50的相同参考图片列表中的一个条目的图片次序计数(POC)值的POC值,那么视频编码器20和/或视频解码器30可在将基于POC的参考索引转换为用于当前视频块50的IPMVC之后导出其运动信息(预测方向、参考图片和运动向量)。在图5的实例中,参考视频块52与第一参考图片列表(RefPicList0)中指定的指向参考视图V0中的第一参考图片58的TMV 54和第二参考图片列表(RefPicList1)中指定的指向参考视图V0中的第二图片60的TMV 56相关联。当前视频块50继承TMV 54和56由图5中的虚线箭头说明。基于参考视频块52的运动信息,视频译码器将当前视频块50的IPMVC导出为第一参考图片列表(RefPicList0)中指定的指向当前视图Vm中的第一参考图片66的TMV 62(例如具有第一参考图片列表中的与参考图片58相同的POC)和第二参考图片列表(RefPicList1)中指定的指向当前视图Vm中的第二图片68的TMV 64(例如具有与参考图片60相同的POC)中的至少一者。视频编码器20和/或视频解码器30可根据本发明的技术将TMV 62和/或TMV 64用于当前视频块50或另一视频块的ARP,如下文更详细描述。
视频编码器20和/或视频解码器30还可将DV 51转换为当前视频块50的IDMVC,且将IDMVC添加到当前视频块50的运动信息候选者列表在与IPMVC不同的位置中。IPMVC或IDMVC中的每一者可在此上下文中被称为“视图间候选者”。在合并/跳过模式中,视频译码器将所有空间和时间合并候选者之前的IPMVC(如果可用)插入到合并候选者列表。在合并/跳过模式中,视频译码器插入从A0导出的空间合并候选者之前的IDMVC(图4的块41)。DV 51到IDMVC的转换可视为DV 51到当前视频块50的DMV的转换。视频编码器20和/或视频解码器30可根据本发明的技术将DMV用于当前视频块50或另一视频块的ARP,如下文更详细描述。
在一些情形中,视频译码器可导出当前视频块的DV。举例来说,如上文参看图5所描述,视频编码器20和/或视频解码器30可导出用于当前视频块50的DV 51。在一些实例中,视频译码器可使用基于相邻块的视差向量(NBDV)导出来导出用于当前视频块的DV。
针对3D-HEVC的提议针对所有视图使用纹理优先译码次序。换句话说,对于位流中所述多个视图中的每一者,纹理分量在视图的任何深度分量之前经译码,例如经编码或经解码。在一些情况下,例如对于视图间预测,需要DV来对特定存取单元中的视图的纹理分量中的视频块译码。然而,在纹理优先译码中,当前视频块的对应深度分量并不可用于确定当前视频块的DV。NBDV可由视频译码器采用,且经提议用于3D-HEVC,以在此些情形中导出用于当前视频块的DV。在当前3D-HEVC设计中,从NBDV导出的DV可通过从由来自NBDV过程的DV指向的参考视图的深度图检索深度数据而进一步改善。
DV用于两个视图之间的移位的估计量。因为相邻块共享视频译码中的几乎相同运动/视差信息,所以当前视频块可使用相邻块中的运动向量信息作为其运动/视差信息的良好预测符。遵循此想法,NBDV使用相邻视差信息用于估计不同视图中的DV。
根据NBDV,视频译码器识别若干空间和时间相邻块。利用两组相邻块。一组来自空间相邻块且另一组来自时间相邻块。视频译码器随后以由当前块与候选(相邻)块之间的相关的优先权所确定的预定义次序检查空间和时间相邻块中的每一者。当视频译码器识别候选者的运动信息中的DMV(即,从相邻候选块指向视图间参考图片(相同存取单元中,但不同视图中)的运动向量)时,视频译码器将DMV转换为DV,且传回相关联视图次序索引。举例来说,视频译码器可将当前块的DV的水平分量设定为等于DMV的水平分量,且可将DV的垂直分量设定为0。
3D-HEVC首先采纳张(Zhang)等人“3D-CE5.h:视差向量产生结果”(ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码扩展开发联合合作小组第1次会议:瑞典斯德哥尔摩,2012年7月16-20日,文献JCT3V-A0097(MPEG编号m26052,下文中称为“JCT3V-A0097”))中所提议的NBDV方法。JCT3V-A0097可从以下链路接下载:
http://phenix.int-evry.fr/jct2/doc_end_user/current_document.php?id=89。JCT3V-A0097的全部内容以引用的方式并入本文中。
在3D-HEVC的一些设计中,当视频译码器执行NBDV过程时,视频译码器按次序检查时间相邻块中的视差运动向量、空间相邻块中的视差运动向量且随后检查隐式视差向量(IDV)。IDV可为使用视图间预测译码的空间上或时间上相邻PU的视差向量。IDV也可被称作经导出视差向量。IDV可在PU采用视图间预测时产生,即,用于AMVP或合并模式的候选者借助于视差向量从另一视图中的参考块导出。此视差向量称为IDV。IDV可出于DV导出的目的存储到PU。举例来说,尽管块利用运动预测译码,但块的所导出DV出于对以下视频块译码的目的而并不丢弃。因此,当视频译码器识别DMV或IDV时,视频译码器可传回经识别的DMV或IDV。
在桑(Sung)等人的“3D-CE5.h:基于HEVC的3D视频译码的视差向量导出的简化”(ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码扩展开发联合合作小组第1次会议:瑞典斯德哥尔摩,2012年7月16-20日,文献JCT3V-A0126(MPEG编号m26079,下文为“JCT3V-A0126”))中的简化NBDV包含隐式视差向量(IDV)。JCT3V-A0126可从以下链路接下载:
http://phenix.int-evry.fr/jct2/doc_end_user/current_document.php?id=142。JCT3V-A0126的全部内容以引用的方式并入本文中。
在康(Kang)等人的“3D-CE5.h:用于视差向量导出的改进”(ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码扩展开发联合合作小组第2次会议:中国上海,2012年10月13-19日,文献JCT3V-B0047(MPEG编号m26736,下文为“JCT3V-B0047”))中发生针对3D-HEVC的NBDV的进一步开发。JCT3V-B0047可从以下链路接下载:
http://phenix.it-sudparis.eu/jct2/doc_end_user/current_document.php?id=236。JCT3V-B0047的全部内容以引用的方式并入本文中。在JCT3V-B0047中,通过移除存储在经解码图片缓冲器中的IDV而进一步简化用于3D-HEVC的NBDV,但也随着随机存取点(RAP)图片选择而改进译码增益。视频译码器可将传回的视差运动向量或IDV转换为视差向量且可使用所述视差向量用于视图间运动预测和视图间残余预测。随机存取指代从不是位流中的第一经译码图片的经译码图片开始的位流的解码。随机存取图片或随机存取点以规则的间隔插入到位流中可实现随机存取。随机存取图片的实例类型包含即时解码器刷新(IDR)图片、清洁随机存取(CRA)图片和断链存取(BLA)图片。因此,IDR图片、CRA图片和BLA图片统称为RAP图片。在一些实例中,RAP图片可具有NAL单元类型等于BLA_W_LP、BLA_W_RADL、BLA_N_LP、IDR_W_RADL、IDR_N_LP、RSV_IRAP_VCL22、RSV_IRAP_VCL23或CRA_NUT。
在康(Kang)等人的“CE2.h:D-HEVC中基于CU的视差向量导出”(ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码扩展开发联合合作小组第4次会议:韩国仁川,2013年4月20-26日,文献JCT3V-D0181(MPEG编号m29012,下文为“JCT3V-D0181”))中提议用于针对3D-HEVC的基于CU的DV导出的技术。JCT3V-D0181可从以下链路接下载:
http://phenix.it-sudparis.eu/jct3v/doc_end_user/current_document.php?id=866。JCT3V-D0181的全部内容以引用的方式并入本文中。
当视频译码器识别DMV或IDV时,视频译码器可终止检查过程。因此,一旦视频译码器找到当前块的DV,视频译码器便可终止NBDV过程。当视频译码器不能够通过执行NBDV过程确定当前块的DV时(即,当不存在NBDV过程期间发现的DMV或IDV时),NBDV标记为不可供使用的。换句话说,可认为NBDV过程传回不可用视差向量。
如果视频译码器不能够通过执行NBDV过程导出当前块的DV(即,如果未发现视差向量),那么视频译码器可使用0DV为当前PU的DV。0DV为具有等于0的水平分量和垂直分量两者的DV。因此,即使当NBDV过程传回不可供使用的结果时,视频译码器的需要DV的其它译码过程也可将0视差向量用于当前块。在一些实例中,如果视频译码器不能够通过执行NBDV过程导出当前块的DV,那么视频译码器可停用当前块的视图间残余预测。然而,不管视频译码器是否能够通过执行NBDV过程导出当前块的DV,视频译码器都可针对当前块使用视图间预测。也就是说,如果在检查所有预定义相邻块之后未发现DV,那么0视差向量可用于视图间预测,同时可针对对应CU停用视图间残余预测。
图6为说明相对于当前视频块90的可使用NBDV从其导出当前视频块的DV的实例空间相邻块的概念图。图6中说明的五个空间相邻块是相对于当前视频块的左下块96、左侧块95、右上块92、上方块93和左上块94。空间相邻块可位覆盖当前视频块的CU的左下、左侧、右上、上方和左上块。应注意,NBDV的这些空间相邻块可与由视频译码器例如根据HEVC中的合并(MERGE)/AMVP模式用于当前视频块的运动信息预测的空间相邻块相同。在此些情况下,可不需要由视频译码器针对NBDV的额外存储器存取,因为空间相邻块的运动信息已经考虑用于当前视频块的运动信息预测。
为了检查时间相邻块,视频译码器建构候选图片列表。在一些实例中,视频译码器可处理来自当前视图的多达两个参考图片,即,与当前视频块相同的视图,作为候选图片。视频译码器可首先将协同定位的参考图片插入到候选图片列表中,接着按参考图片索引的升序插入候选图片的其余部分。当具有两个参考图片列表中相同参考索引的参考图片可用时,视频译码器可将与协同定位图片相同的参考图片列表中的一者插入在来自另一参考图片列表的另一参考图片之前。在一些实例中,视频译码器可识别三个候选区,用于从候选图片列表中的候选图片中的每一者导出时间相邻块。所述三个候选区可如下界定:
●CPU:当前PU或当前CU的协同定位的区。
●CLCU:覆盖当前块的所述协同定位的区的最大译码单元(LCU)。
●BR:CPU的右下4x4块。
如果覆盖候选区的PU指定DMV,那么视频译码器可基于PU的视差运动向量确定当前视频单元的DV。
如上文所论述,除从空间及时间相邻块导出的DMV外,视频译码器还可检查IDV。在3D-HTM 7.0的所提议的NBDV过程中,视频译码器依次检查时间相邻块中的DMV,随后是空间相邻块中的DMV,且随后是IDV。一旦发现DMV或IDV,过程就终止。
当视频译码器检查相邻PU(即,空间或时间相邻PU)时,视频译码器可首先检查相邻PU是否具有视差运动向量。如果相邻PU均不具有视差运动向量,那么视频译码器可确定空间相邻PU中的任一者是否具有IDV。如果空间相邻PU中的一者具有IDV且所述IDV是作为合并/跳过模式而经译码,那么视频译码器可终止检查过程且可使用所述IDV作为当前PU的最终视差向量。
如上文所指出,视频译码器可应用NBDV过程以导出当前块(例如,CU、PU等)的DV。当前块的视差向量可指示参考视图中的参考图片(即,参考分量)中的位置。在一些3D-HEVC设计中,允许视频译码器存取参考视图的深度信息。在一些此些3D-HEVC设计中,当视频译码器使用NBDV过程导出当前块的DV时,视频译码器可应用改善过程以进一步改善当前块的视差向量。视频译码器可基于参考图片的深度图改善当前块的DV。视频译码器可使用类似改善过程来改善DMV用于后向视图合成预测。以此方式,深度可用于改善DV或DMV以用于后向视图合成预测。此改善过程可在本文中被称作NBDV改善(“NBDV-R”)、NBDV改善过程或深度定向的NBDV(Do-NBDV)。
当NBDV过程传回可用的视差向量时(例如,当NBDV过程传回指示NBDV过程能够基于相邻块的视差运动向量或IDV导出当前块的视差向量的变数时),视频译码器可进一步通过检索来自参考图片的深度图的深度数据而改善视差向量。在一些实例中,改善过程包含以下两个步骤:
1)在例如基础视图等经先前译码参考深度视图中通过所导出的DV定位对应深度块;对应深度块的大小与当前PU的大小相同。
2)从对应深度块的四个隅角像素选择一个深度值且将其转换为经改善DV的水平分量。DV的垂直分量不变。
经改善DV可用于当前视频块的视图间预测,而未经改善DV可用于当前视频块的视图间残余预测。此外,经改善DV存储为一个PU的运动向量(如果其利用后向视图合成预测(BVSP)模式译码),其在下文更详细地描述。在3D-HTM 7.0的所提议的NBDV过程中,基础视图的深度视图分量将始终被存取,而不管从NBDV过程导出的视图次序索引的值如何。
田(Tian)等人“CE1.h:使用相邻块的视图合成预测”(ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码扩展开发联合合作小组第3次会议:瑞士日内瓦,2013年1月23日,文献JCT3V-C0152(MPEG编号m27909,下文中称为“JCT3V-C0152”))中提议后向视图合成预测(BVSP)方法。JCT3V-C0152可从以下链路接下载:
http://phenix.int-evry.fr/jct3v/doc_end_user/current_document.php?id=594。JCT3V-C0152的全部内容以引用的方式并入本文中。
JCT3V-C0152在第3次JCT-3V会议中采纳。此BSVP的基本想法与3D-AVC中的基于块的VSP相同。这两个技术均使用后向扭曲和基于块的VSP以避免发射运动向量差且使用更精确的运动向量。实施方案细节由于不同平台而不同。在以下段落中,我们还使用术语BVSP来指示3D-HEVC中的后向扭曲VSP方法所述3D-AVC中的基于块的VSP中的一或两者。
在3D-HTM中,在共同测试条件中应用纹理优先译码。因此,当对一个非基础纹理视图进行解码时对应非基础深度视图不可用。因此,估计深度信息且其用以执行BVSP。
大体来说当视频译码器执行BVSP以合成参考纹理图片时,视频译码器处理相依纹理图片中的块(例如,视频单元)。相依纹理图片和经合成纹理图片在相同存取单元中,但不同视图中。当视频译码器处理相依纹理图片的块(即,当前块)时,视频译码器可执行NBDV过程以识别当前块的DV。也就是说,为了估计块的深度信息,视频译码器可首先从相邻块导出DV。
此外,当视频译码器执行BVSP以合成参考纹理图片时,视频译码器可使用当前块的DV以识别参考深度图片中的参考块。换句话说,视频译码器可随后使用导出的DV以获得来自参考视图的深度块。举例来说,由NBDV过程识别的DV可表示为(dvx,dvy),且当前块位置可表示为(blockx,blocky)。此外,在此实例中,视频译码器可在参考视图的深度图像中(blockx+dvx,blocky+dvy)处提取深度块。在此实例中,所获取的深度块具有当前PU的相同大小。相依纹理图片和参考深度图片在相同存取单元中,但不同视图中。视频译码器可随后执行后向扭曲过程以基于当前块的样本值和参考图片的经识别参考块的样本值确定经合成图片的样本值。换句话说,在此实例中,视频译码器可使用所提取的深度块执行当前PU的后向扭曲。
如上文所指出,当视频译码器执行BVSP时,视频译码器可执行NBDV过程以识别当前块的DV。此外,当视频译码器执行BVSP时,视频译码器可使用类似于本发明中其它地方描述的改善过程的改善过程来改善使用NBDV过程导出的DMV。当视频译码器执行DV改善过程时,视频译码器可基于参考视图中的深度图中的深度值改善DV。换句话说,深度可用于改善DV或DMV以用于BVSP。如果经改善DV利用BVSP模式译码,那么所述经改善DV可存储为一个PU的运动向量。
在3D-HEVC的一些版本中,应用纹理优先译码。在纹理优先译码中,视频译码器对纹理视图分量译码(例如,编码或解码),随后对对应的深度视图分量(即,具有与纹理视图分量相同的POC值和视图识别符的深度视图分量)译码。因此,非基础视图深度视图分量不可用于对对应的非基础视图纹理视图分量译码。换句话说,当视频译码器对非基础纹理视图分量译码时,对应的非基础深度视图分量不可供使用。因此,可估计深度信息且将其用以执行BVSP。
图7为说明从参考视图进行深度块导出以执行BVSP预测的概念图。在图7的实例中,视频译码器正对当前纹理图片70译码。当前纹理图片70标记为“相依纹理图片”,因为当前纹理图片70依附于经合成参考纹理图片72。换句话说,视频译码器可需要合成参考纹理图片72以便解码当前纹理图片70。参考纹理图片72和当前纹理图片70在相同存取单元中但不同视图中。
为了合成参考纹理图片72,视频译码器可处理当前纹理图片70的块(即,视频单元)。在图7的实例中,视频译码器正处理当前块74。当视频译码器处理当前块74时,视频译码器可执行NBDV过程以导出当前块74的DV。举例来说,在图7的实例中,视频译码器识别与当前视频块74相邻的块78的DV 76。DV 76的识别展示为图7的步骤1。此外,在图7的实例中,视频译码器基于DV 76确定当前块74的DV 78。举例来说,DV 78可为DV 76的副本。复制DV 76展示为图7的步骤2。
视频译码器可基于当前块74的DV 78识别参考深度图片82中的参考视频块80。参考深度图片82、当前纹理图片70和参考纹理图片72可各自在相同存取单元中。参考深度图片82和参考纹理图片72可在相同视图中。视频译码器可基于当前块74的纹理样本值和参考深度块80的深度样本值确定参考纹理图片72的纹理样本值。确定纹理样本值的过程可被称为后向扭曲。后向扭曲展示为图7的步骤3。以此方式,图7说明如何定位来自参考视图的深度块且随后用于BVSP预测的三个步骤。
引入的BVSP模式视为特殊经帧间译码模式,且针对每一PU应维持指示BVSP模式的使用的旗标。代替于在位流中信令所述旗标,将合并模式的新合并候选者(BVSP合并候选者)添加到合并候选者列表,且所述旗标依附于经解码合并候选者索引是否对应于BVSP合并候选者。BVSP合并候选者被定义为如下:
1.每一参考图片列表的参考图片索引:-1
2.每一参考图片列表的运动向量:经改善视差向量
BVSP合并候选者的插入位置依附于空间相邻块:
1.如果五个空间相邻块的任一者利用BVSP模式译码,即,相邻块的所维持的旗标等于1,那么视频译码器将BVSP合并候选者视为对应的空间合并候选者,切将BVSP候选者插入到合并候选者列表中。在某一实例中,视频译码器将BVSP合并候选者插入到合并候选者列表中仅一次。
2.否则(五个空间相邻块均未利用BVSP模式译码),视频译码器可将BVSP合并候选者插入(单板)到合并候选者列表中刚好在时间合并候选者之前。
在一些实例中,在组合双向预测合并候选者导出过程期间,视频译码器应检查额外条件以避免包含BVSP合并候选者。
对于大小由NxM表示的每一经BVSP译码的PU,视频译码器可进一步将PU分割为具有等于KxK(其中K可等于4)的大小的若干子区。对于每一子区,视频译码器可导出单独DMV,且可从视图间参考图片中由所导出DMV定位的一个块预测每一子区。换句话说,用于经BVSP译码PU的运动补偿单元的大小可设定成KxK。在共同测试条件中,K设定成4。
对于以BVSP模式译码的一个PU内的每一子区(4×4块),视频译码器可在具有上述经改善DV的情况下将对应的4×4深度块定位在参考深度视图中。视频译码器可选择对应深度块中的十六个深度像素的最大值。视频译码器可将最大值转换为DMV的水平分量,且可将DMV的垂直分量设定成0。
图8为说明用于经时间预测视频块的时间先进残余预测(ARP)的当前提议的实例预测结构的概念图。如张(Zhang)等人“CE4:用于多视图译码的先进残余预测”(ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码扩展开发联合合作小组第4次会议:韩国仁川,2013年4月20-26日,文献JCT3V-D0177(MPEG编号m29008,下文中称为“JCT3V-D0177”))中所提议,在第4次JCT3V会议中采纳施加到具有等于Part_2Nx2N的分割模式的CU的ARP。JCT3V-D0177可从以下链路接下载:
http://phenix.it-sudparis.eu/jct3v/doc_end_user/current_document.php?id=862。JCT3V-D0177的全部内容以引用的方式并入本文中。
如图8中所展示,视频译码器在当前(例如相依)视图Vm的当前图片102中的当前视频块100的残余的预测中调用或识别以下块。
1.当前视频块100(视图Vm中):Curr
2.参考/基础视图(图8中的V0)的视图间参考图片108中的视图间参考视频块106:Base。视频译码器基于当前视频块100的DV 104导出视图间参考视频块106(Curr)。视频译码器可使用NBDV确定DV 104,如上文所描述。
3.与当前视频块100(Curr)相同的视图(Vm)中的时间参考图片114中的时间参考视频块112:CurrTRef。视频译码器基于当前视频块100的TMV 110导出时间参考视频块112。视频译码器可使用本文中所描述的技术中的任一者确定TMV 100。
4.参考视图(即,与视图间参考视频块106(Base)相同的视图)中的时间参考图片118中的时间参考视频块116:BaseTRef。视频译码器使用当前视频块100(Curr)的TMV 110导出参考视图中的时间参考视频块116。TMV+DV的向量120可相对于当前视频块100(Curr)识别时间参考视频块116(BaseTRef)。
当视频编码器基于视频译码器使用TMV 110识别的时间参考视频块112对当前视频块100进行时间帧间预测时,视频编码器将当前视频块100与时间参考视频块112之间的逐像素差异确定为残余块。无ARP的情况下,视频译码器将对残余块进行变换、量化和熵编码。视频解码器将对经编码视频位流进行熵解码,执行逆量化和变换以导出残余块,且将残余块应用到参考视频块112的重建以重建当前视频块100。
使用ARP的情况下,视频译码器确定预测残余块的值(即,预测当前视频块100(Curr)与时间参考视频块112(CurrTRef)之间的差)的残余预测符块。视频编码器可随后仅需要编码残余块与残余预测符块之间的差,从而减少用于编码当前视频块100的经编码视频位流中包含的信息量。在图8的时间ARP实例中,基于参考/基础视图(V0)中的对应于当前视频块100(Curr)和时间参考视频块112(CurrTRef)且由DV 104识别的块确定当前视频块100的残余的预测符。参考视图中的这些对应块之间的差可为残余的良好预测符,即当前视频块100(Curr)与时间参考视频块112(CurrTRef)之间的差。特定来说,视频译码器识别参考视图中的视图间参考视频块106(Base)和时间参考视频块116(BaseTRef),且基于视图间参考视频块106与时间参考视频块116之间的差(BaseTRef-Base)确定残余预测符块,其中减法运算应用到所表示的像素阵列的每一像素。在一些实例中,视频译码器可将加权因子w应用到残余预测符。在此些实例中,当前块的最终预测符,即参考块与残余预测符块求和,可表示为:CurrTRef+w*(BaseTRef-Base)。
图9为说明当前视图(Vm)中的当前视频块120的时间ARP的实例双向预测结构的概念图。上文描述和图8说明单向预测。当将ARP扩展到双向预测的情况时,视频译码器可将上文技术应用到参考图片列表中的一或两者以便识别当前视频块120的残余预测符块。特定来说,视频译码器可检查当前视频块100的参考列表中的一或两者以确定其中的一者是否含有可用于时间ARP的TMV。在由图9说明的实例中,当前视频块120与指向第一参考图片列表(RefPicList0)中的第一时间参考图片134的TMV 130相关联,且指向第二时间参考图片136的TMV 132为第二参考图片列表(RefPicList1)。
在一些实例中,视频译码器将根据检查次序检查参考图片列表以确定其中的一者是否包含可用于时间ARP的TMV,且如果第一列表包含此TMV,则不必根据所述检查次序检查第二列表。在一些实例中,视频译码器将检查两个参考图片列表,并且如果两个列表均包含TMV,那么例如基于使用所述TMV产生的所产生残余预测符相对于当前视频块的残余的比较而确定使用哪一TMV。值得注意的是,根据针对ARP的当前提议,当当前块针对一个参考图片列表使用视图间参考图片(不同视图中)时,停用残余预测过程。
如图9中所说明,视频译码器可使用例如根据NBDV针对当前视频块120识别的DV 124以识别与当前图片122不同的参考视图(V0)中但相同存取单元中的视图间参考图片128中的对应的视图间参考视频块126(Base)。视频译码器还可针对当前视频块120使用TMV 130和132以识别两个参考图片列表(例如RefPicList0和RefPicList1)中的参考视图的各个时间参考图片中的视图间参考视频块126(Base)的时间参考块(BaseTRef)。在图9的实例中,视频译码器基于当前视频块120的TMV 130和132识别第一参考图片列表(例如RefPicList0)中的时间参考图片142中的时间参考视频块(BaseTRef)140和第二参考图片列表(例如RefPicList1)中的时间参考图片146中的时间参考视频块(BaseTRef)144。
参考视图中的当前视频块120的TMV 130和132的使用由图9中的虚线箭头说明。在图9中,参考视图中的时间参考视频块140和144归因于其基于TMV 130和132的识别而被称作经运动补偿的参考块。视频译码器可基于时间参考视频块140与视图间参考视频块126之间的差或基于时间参考视频块144与视图间参考视频块126之间的差确定当前视频块120的残余预测符块。
解码器侧的所提议的时间ARP的主程序可描述(参看图9)如下:
1.视频解码器例如使用指向目标参考视图(V0)的NBDV获得如当前3D-HEVC中指定的DV 124。随后,在相同存取单元内的参考视图的图片128中,视频解码器通过DV 124识别对应的视图间参考视频块126(Base)。
2.视频解码器再使用当前视频块120的运动信息(例如,TMV 130、132)以导出对应的视图间参考视频块126的运动信息。视频解码器可基于当前视频块120的TMV 130、132和参考视频块126的参考视图中的所导出的参考图片142、146应用对应的视图间参考视频块126的运动补偿以识别经运动补偿的时间参考视频块140、144(BaseTRef)以及通过确定BaseTRef-Base确定残余预测符块。当前块、对应块(Base)和运动补偿块(BaseTRef)之间的关系在图8和9中展示。在一些实例中,参考视图(V0)中具有与当前视图(Vm)的参考图片相同的POC(图片次序计数)值的参考图片选定为对应块的参考图片。
3.视频解码器可将加权因子w应用到残余预测符块以获得经加权残余预测符块,且将经加权残余块的值相加到经预测样本以重建当前视频块100。
在针对ARP的提议中,可使用三个加权因子,即0、0.5和1。产生当前CU的最小速率失真成本的一个选定为最终加权因子,且对应加权因子索引(0、1和2,其分别对应于加权因子0、1和0.5)在CU层级处的位流中发射。一个CU中的所有PU预测共享相同加权因子。当加权因子等于0时,ARP并不用于当前CU。
在张(Zhang)等人“3D-CE4:用于多视图译码的先进残余预测”(ITU-T SG 16 WP 3和ISO/IEC JTC1/SC 29/WG 11的视频译码扩展开发联合合作小组第3次会议:瑞士日内瓦,2013年1月17-23日,文献JCT3V-C0049(MPEG编号m27784,下文中称为“JCT3V-C0049”))中描述3D-HEVC的ARP的方面。JCT3V-C0049可从以下链路接下载:
http://phenix.int-evry.fr/jct3v/doc_end_user/current_document.php?id=487。JCT3V-C0049的全部内容以引用的方式并入本文中。
在JCT3V-C0049中,以非零加权因子译码的不同PU的参考图片可在不同PU(或当前视频块)间不同。因此,来自参考视图的不同图片可需要被存取以产生参考视图(Base)中的对应视图间参考视频块(例如图8和9中的视图间参考视频块106和126)的经运动补偿的块(BaseTRef),例如图8和9中的时间参考视频块116、140和144。
JCT3V-D0177中提议通过经由运动向量缩放进行参考图片选择而进一步简化ARP。举例来说,提议当加权因子不等于0时,视频译码器在执行针对残余产生过程的运动补偿之前朝向固定图片缩放当前PU的运动向量。在JCT3V-D0177中,固定图片被定义为每一参考图片列表(如果其来自相同视图)的第一参考图片。当经解码运动向量并不指向固定图片时,其首先由视频译码器缩放,且随后由视频译码器使用以识别当前视频块的CurrTRef和BaseTRef。用于ARP的此参考图片可被称为目标ARP参考图片。可存在分别对应于RefPicList0和RefPicList1的两个目标ARP参考图片,其可分别表示为L0目标ARP参考图片和L1目标ARP参考图片。
根据JCT3V-C0049,视频译码器在对应块(Base)及其预测块(BaseTRef)的内插过程期间应用双线性滤波器,但针对当前视频块(Curr)(例如PU)和当前视频块的预测块(CurrTRef)的内插过程应用常规8/4抽头滤波器。JCT3V-D0177中提议视频译码器始终针对此些内插处理采用双线性滤波器,而不管当施加ARP时所述块处于基础视图还是非基础视图中。
另外,根据针对ARP的现有提议,ARP的参考视图由从NBDV过程传回的视图次序索引识别。如上文所描述,视频译码器可使用NBDV过程确定用于识别对应视图间参考视频块(Base)(例如,图8和9中的视图间参考视频块106和126)的DV,例如DV 104或124。根据针对ARP的现有提议,当一个参考图片列表中的一个视频块(PU)的参考图片来自与ARP的目标参考视图不同的视图(如从NBDV过程传回的视图次序索引所识别)时,针对此参考图片列表停用ARP。
可存在与3D-HEVC中的针对ARP的现有提议相关联的问题。举例来说,根据现有提议,当当前视频块的当前运动向量指代相同视图中的参考图片时,ARP仅预测从时间预测产生的残余。因此,当当前视频块的当前运动向量指代视图间参考图片时,ARP并不可适用,但仍发射关于ARP的语法元素。
作为另一实例,所导出的DV(例如,如根据NBDV过程导出)可相比于显式DMV不够准确,显式DMV通常通过速率失真优化(RDO)选择。另外,作为解码过程、运动预测(包含视图间预测)在DV产生之后发生,且ARP在运动预测之后发生。因此,当ARP由视频译码器执行时,可用于识别当前ARP中未考虑的不同块的更精确TMV或DMV可用。尽管如此,如上文参看图8和9所描述,时间ARP的现有提议使用经由NBDV导出的DV以识别对应的视图间参考视频块。
本发明提供可解决与针对ARP的现有提议相关联的问题(包含上文所论述的那些问题)且可借此改进ARP的译码效率的技术。举例来说,实施本发明的技术以使用ARP对当前视频块译码的视频译码器(例如视频编码器20和/或视频解码器30)可识别从当前视频块的当前视图到参考视图的DMV,且基于DMV的识别确定当前视频块的残余预测符块。在一些实例中,DMV为用于当前视频块的视图间预测的DMV,且视频译码器可执行视图间ARP用于编码当前视频块。在其它实例中,DMV为与当前视频块相同的视图中的时间参考视频块的DMV。在此些实例中,DMV可用于当前视频块的时间ARP中,代替由NBDV针对当前视频块导出的DV。
图10为根据本发明中描述的技术的用于经视图间预测视频块的视图间ARP的实例预测结构的概念图。根据图10中说明的实例技术,视频译码器(例如视频编码器20和/或视频解码器30)可使用不同存取单元中计算的视图间残余来预测经视图间预测的当前块的残余。与其中在当前块的运动向量为DMV时不执行ARP且仅在当前视频块的运动向量为TMV时执行ARP的针对ARP的提议相比,图10的实例技术使用DMV来执行ARP。
特定来说,图10的实例技术可由视频译码器(例如视频编码器20或视频解码器30)在当前图片152中的当前视频块150(Curr)的运动向量为DMV 154时执行,且参考视图(V0)中的视图间参考图片158中的视图间参考视频块156(Base)含有至少一个TMV 160。在一些实例中,DMV 154可为DV,其转换为DMV以充当IDMVC用于当前视频块150的运动信息预测。
视频译码器使用当前视频块150的DMV 154识别视图间参考图片158中的视图间参考视频块156(Base)。视频译码器使用视图间参考视频块156的TMV 160和相关联参考图片(例如,参考视图(V0)中的时间参考图片164)连同DMV一起以识别参考视图(V0)中的时间参考图片164中的时间参考视频块162(BaseTRef)。基于TMV 160和DMV 154识别时间参考视频块162(BaseTRef)由虚线向量170(TMV+DMV)表示。视频译码器还使用TMV 160以识别当前视图(Vm)中的时间参考图片168中的时间参考块166(CurrTRef)。参考视图(V0)中的时间参考视频块162(BaseTRef)和当前视图(Vm)中的时间参考视频块166(CurrTRef)可在相同存取单元内,即参考视图(V0)中的时间参考图片164和当前视图(Vm)中的时间参考图片168可在相同存取单元中。
视频译码器(例如视频编码器20和/或视频解码器30)可随后基于这后两个块之间的逐像素差(即,当前视图中的时间参考视频块166与参考视图中的时间参考视频块164之间的差,或CurrTRef-BaseTRef)计算来自当前视频块150的不同存取单元中的视图间残余预测符块。差信号(表示为视图间残余预测符)可用于预测当前视频块150的残余。当前视频块150的预测信号可为视图间预测符(即,视图间参考视频块156(Base))与基于当前视图中的时间参考视频块166与参考视图中的时间参考视频块164之间的差而确定的不同存取单元中的经预测视图间残余的总和。在一些实例中,加权因子w施加到不同存取单元中的经预测视图间残余。在此些实例中,当前视频块150的预测信号可为:Base+w*(CurrTRef-BaseTRef)。
在一些实例中,视频译码器可确定用于视图间ARP的目标存取单元中的目标参考图片,例如类似于用于时间ARP的目标参考图片的确定,如上文所论述。在一些实例中,如上文参看JCT3V-D0177所论述,每一参考图片列表的目标参考图片为参考图片列表中的第一参考图片。在其它实例中,一个或两个参考图片列表的目标参考图片(例如目标POC)可例如以PU、CU、切片、图片或其它为基础从视频编码器20信令到视频解码器30。在其它实例中,每一参考图片列表的目标参考图片为与当前块相比具有最小POC差和较小参考图片索引的参考图片列表中的时间参考图片。在其它实例中,两个参考图片列表的目标参考图片相同。
如果含有TMV 160所指示的参考视图中的时间参考视频块的图片在与目标ARP参考图片不同的存取单元(时间例项)中,那么视频译码器可将TMV 160缩放到目标参考图片(例如目标参考图片164)以识别用于视图间ARP的参考视图中的时间参考视频块162(BaseTRef)。在此些实例中,视频译码器将时间参考视频块162定位在含有目标ARP参考图片的存取单元中。视频译码器可通过POC缩放来缩放TMV 160。此外,经缩放TMV用于识别定位于目标ARP参考图片中的当前视图中的时间参考视频块(CurrTRef)166。
在一些实例中,视频译码器将TMV 160缩放到LX(X为0或1)目标参考图片,其中LX对应于包含TMV的PU的所述RefPicListX。在一些实例中,视频译码器可将来自RefPicList0或RefPicList1中的任一者或两者的TMV分别缩放到L0或L1目标参考图片。在一些实例中,视频译码器将TMV 160缩放到LX目标参考图片,其中X满足当前视频块150(例如当前PU)的DMV 154对应于RefPicListX的条件。
类似地,在一些实例中,视频译码器在识别目标参考视图中的参考图片158中的视图间参考视频块156之前将DMV 154缩放到ARP的目标参考视图。视频译码器可通过视图次序差缩放而缩放DMV 154。目标参考视图可由视频编码器20及视频解码器30预定和已知,或可例如以PU、CU、切片、图片或其它为基础从视频编码器20信令到视频解码器30。
在视图间ARP的一些实例中,视频译码器(例如视频编码器20和/或视频解码器30)可使用图10中说明的相同预测结构以及经识别参考视频块156、164和168导出当前块150的预测信号,但基于参考视图中的参考块156与162而非不同存取单元中的参考块162与166之间的差确定残余预测符块。在此些实例中,视频译码器可将加权因子应用到其它样本阵列(例如,参考视图中的参考块156与162之间的差),且相应地导出当前视频块150的预测信号如下:CurrTRef+w*(Base-BaseTRef)。在视图间ARP的一些实例中,视频译码器可使用各种内插滤波器(包含双线性滤波器)在其与分数像素位置对准的情况下导出参考视频块156、162和166。
尽管图10说明其中使用视图间参考视频块的TMV和相关联参考图片识别当前和参考视图中的时间参考视频块的视图间ARP实例,但在其它实例中,其它TMV和相关联参考图片可用于识别当前和参考视图中的时间参考视频块。举例来说,如果当前视频块的DMV来自当前视频块的第一参考图片列表(例如,RefPicList0或RefPicList1),那么视频译码器可使用来自当前视频块的第二参考图片列表(例如,RefPicList0或RefPicList1中的另一者)的TMV和相关联参考图片。在此些实例中,视频译码器可识别与TMV相关联的参考图片中的当前视图中的时间参考视频块,或将TMV缩放到ARP的目标存取单元和目标参考图片以识别当前视图中的时间参考视频块。在此些实例中,视频译码器可识别与其中定位当前视图中的时间参考视频块的参考图片相同的存取单元中的参考图片中的参考视图中的时间参考视频块。在其它实例中,代替于视图间参考视频块的TMV或当前视频块的另一参考图片列表的TMV,视频译码器可类似地使用从当前视频块的空间或时间相邻视频块的运动信息导出的TMV和相关联参考图片以识别ARP的当前和参考视图中的时间参考视频块。
图10说明根据本发明的视图间ARP的实例。如上文所论述,根据针对时间ARP的现有提议,例如由NBDV导出的当前视频块的DV用于识别参考视图中的视图间参考视频块。根据本发明的技术,可通过用当前视图(CurrTRef)(如果其含有至少一个DMV)中的时间参考块的DMV替代所述DV而增加时间ARP的参考视图中计算的时间残余预测符的准确性。
图11为根据本发明中描述的技术使用当前视图(CurrTRef)中的时间参考块的DMV190的当前图片182中的经时间预测的当前视频块180的时间ARP的实例预测结构的概念图。根据图11的实例,视频译码器(例如视频编码器20和/或视频解码器30)使用识别时间参考图片188中的时间参考视频块186的TMV 184对当前视频块180进行时间预测。视频译码器确定时间参考视频块186是否含有用于对时间参考视频块186进行视图间预测的至少一个DMV,例如DMV 190。在一些实例中,DMV 190可为用于时间参考视频块186的运动信息预测的IDMVC。
视频译码器可使用DMV 190代替当前视频块180的DV用于识别以下中的任何一者或两者:参考视图(V0)中的参考图片198内的视图间参考视频块196(Base),或参考视图(V0)中的时间参考图片194中的时间参考视频块194(BaseTRef)。基于TMV 184和DMV 190识别时间参考视频块194由向量200说明,向量200标记为TMV+DMV。在一些实例中,当视频译码器使用DMV来替换来自时间ARP的NBDV的DV时,视频译码器还可用与选定DMV相关联的视图次序索引替换从NBDV过程传回的视图次序索引。另外,在一些实例中,如果使用BVSP模式导出的DMV将替换来自NBDV的DV,那么视频译码器可不选择与当前视频块180的时间ARP的时间参考视频块186相关联的DMV。视频译码器可使用经识别的参考视频块186、192和196确定当前视频块180的时间残余预测符块,如上文参看图8中的块106、112和116所描述。
在一些实例中,如果当前视频块180的经解码TMV 184指向与目标ARP参考图片不同的存取单元(时间例项)中的参考图片,那么视频译码器可将TMV 184缩放到目标ARP参考图片188,且通过经缩放TMV 184例如使用POC缩放将时间参考视频块186(CurrTRef)定位在目标ARP参考图片中。在此些实例中,视频译码器可导出如经缩放TMV 184识别的时间参考视频块186(CurrTRef)中的DMV 190。在一些实例中,当视频译码器缩放TMV 184以识别属于与目标ARP图片的存取单元相同的存取单元的图片188中的时间参考视频块186(CurrTRef)时,可识别由TMV 184在不缩放的情况下识别的另一时间参考视频块,即CurrTempRef。在此些实例中,视频译码器可使用来自此时间参考视频块(CurrTempRef)的DMV(如果可用)以替换当前视频块180的时间ARP的DV。在一些实例中,视频译码器仅在不存在与时间参考视频块186(CurrTRef)相关联的DMV时识别和使用CurrTempRef。在一些实例中,经译码块的其它DMV可用于替换来自NBDV的DV。
图12为说明根据本发明中描述的技术用于识别视频块中或附近的TMV或DMV的实例技术的概念图。如上文相对于图10和11所论述,视频译码器(例如视频编码器20和/或视频解码器30)根据本发明中描述的技术识别TMV和DMV以实施视图间ARP和时间ARP。在一些实例中,视频译码器识别当前视频块或视图间或时间参考视频块中或附近的TMV和DMV,所述视图间或时间参考视频块可为参考图片内的具有与当前视频块(例如当前PU)相同的宽度x高度大小的区。
图12说明宽度x高度的块210。块210可为当前视频块或视图间或时间参考视频块,其可为参考图片内的具有与当前视频块相同的大小的区。图12还说明邻近或包含块210的中心位置的块212,和邻近或包含块210的右下位置的块214。
在一些实例中,对于时间或视图间ARP,视频译码器考虑(例如仅考虑)运动向量(例如,TMV或DMV)和与含有块的中心位置的PU或其它块(例如块210内的块212)相关联的相关联参考索引。在一些实例中,视频译码器考虑(例如仅考虑)含有块210的右下(具有相对于(宽度,高度)的左上角像素的协调)和中心(具有相对于(宽度/2,高度/2)的左上角的协调)像素的两个块的运动信息(包含运动向量和参考索引)。参看图12,块214和212分别可为含有块210的右下和中心像素的块的实例。块212和214可为N×N,其可为可含有多达对应于每一参考图片列表的一个运动向量的最大块粒度,例如N×N可为4×4。可检查块212和214以按任何次序寻找ARP的DMV或TMV。
在一些实例中,假定当前视频块(例如当前PU)具有坐标(x,y)且用于识别参考视频块(v[0],v[1])的向量来自运动向量(TMV或DMV),那么视频译码器可将DMV转换为v[i]=(mv[i]+2)>>2,其中ⅰ分别等于0或1,或v[i]=mv[i]>>2。在此些实例中,视频译码器可将块212和214分别识别为覆盖具有协调(x+v[0]+宽度/2,y+v[1]+高度/2)的像素的块(例如,4×4块)和覆盖具有协调(x+v[0]+宽度,y+v[1]+高度)的像素的块。在一些实例中,视频译码器可通过经移位(-1,-1)的协调而识别中心块212和右下块214中的一或两者,其分别对应于(x+v[0]+宽度/2-1,y+v[1]+高度/2-1)和(x+v[0]+宽度-1,y+v[1]+高度-1)。
在一些实例中,视频译码器可根据检查次序检查块212和214以寻找可用TMV或DMV。在一些实例中,视频译码器可首先检查中心块212,且使用与ARP的中心块相关联的DMV或TMV(如果此运动向量可用)。在此些实例中,如果此运动向量不可从中心块212获得,那么视频译码器可检查右下块214以寻找ARP的TMV或DMV。
在一些实例中,视频译码器可以检查次序针对ARP的适当运动向量检查参考图片列表以寻找块212、214。举例来说,视频译码器可检查RefPicList0,和使用与RefPicList0相关联的DMV或TMV(如果此运动向量可用)。在此些实例中,如果此运动向量不可从RefPicList0获得,那么视频译码器可检查RefPicList1以寻找用于ARP的TMV或DMV。
在一些实例中,视频译码器可考虑(例如仅考虑)与含有块的中心和四个隅角位置中的一或多者的PU相关联的运动向量。视频译码器可基于优先权考虑次序中的PU,且一旦发现运动向量,就可不考虑其它PU。这些不同位置的优先权可在一个实例中被定义为:块的中心、左上、右上、左下和右下。
在一些实例中,视频译码器可经配置以考虑与块相关联的所有运动信息。在一些实例中,一旦发现块210内的用于ARP的TMV或DMV,视频译码器就可不检查额外运动向量。用于检查运动向量的块210内的PU的优先权可为(例如)光栅扫描次序或螺旋形扫描。图13A-13D中描绘用于扫描运动向量的块(例如,4x4块)的螺旋形扫描次序的实例。
在一些实例中,当检查块210以寻找用于ARP的TMV时,视频译码器可仅考虑指向与目标ARP参考图片相同的存取单元中的参考图片的TMV。在一些实例中,当检查参考块210以寻找用于ARP的DMV时,视频译码器可仅考虑指向与当前视频块的DMV或DV所指示的视图相同的视图中的视图间参考图片的DMV。在一些实例中,视频译码器首先将块210扩展到与PU相关联的块,且寻找经扩展块内的将成为用于ARP的TMV或DMV的TMV或DMV。在一些实例中,如果在块210中未发现TMV或DMV,那么视频译码器使用0运动向量执行ARP,或并不执行ARP。在一些实例中,当视频译码器使用0运动向量以识别当前和参考视图中的两个时间参考视频块时,视频译码器可使用RefPicListX的目标参考图片,其中X可为0或1且指示调用哪一列表用于视图间预测,例如哪一列表包含所述DMV。
如上文例如参看图12所论述,视频译码器可识别仅含有高达两组运动信息的给定块(例如,块210内的4×4块)中的TMV或DMV。一组运动信息对应于给定块的第一参考图片列表,例如参考图片列表0(RefPicList0),且另一组对应于所述给定块的第二参考图片列表,例如参考图片列表1(RefPicList1)。每一组运动信息包含运动向量和参考索引。
在一些实例中,视频译码器仅考虑对应于RefPicList0的运动信息用于识别当前视频块的ARP的TMV或DMV。在其它实例中,视频译码器仅考虑对应于RefPicList1的运动信息用于识别当前视频块的ARP的TMV或DMV。在其它实例中,视频译码器首先考虑对应于RefPicListX的运动信息。如果对应于RefPicListX的运动信息并不包含用于ARP的合适的TMV或DMV,那么视频译码器考虑对应于RefPicListY的运动信息(其中Y等于1-X)。
在一些实例中,X等于0。在一些实例中,X等于1。在一些实例中,X等于Z,其中Z对应于其中包含当前视频块的运动向量(TMV或DMV)的参考图片列表。举例来说,如果属于当前视频块(例如当前PU)的运动向量对应于RefPicList0,那么Z为0。如果属于当前视频块(例如当前PU)的运动向量对应于RefPicList1,那么Z为1。在一些实例中,视频译码器仅对应于RefPicListZ的运动信息。
用于通过替代当前视频块的DV改进时间ARP的准确性(例如参考视图中计算的时间残余的准确性)的另一实例技术包含用经由当前块(CurrTRef)的时间参考块的协同定位深度块导出的DV替代例如由NBDV导出的DV。视频译码器(例如视频编码器20和/或视频解码器30)可使用与用于导出BVSP的当前视频块的DV的技术类似或相同的技术(如上文相对于图7所描述)经由当前块(CurrTRef)的时间参考块的协同定位深度块导出DV。
视频译码器可使用经由当前块(CurrTRef)的时间参考块的协同定位深度块导出的DV代替例如由NBDV导出的当前的DV,用于导出用于ARP的参考视图中的参考块中的任何一者或两者。举例来说,视频译码器可使用经由当前块(CurrTRef)的时间参考块的协同定位深度块导出的DV以识别参考视图(Base)中的当前块的视图间参考块或参考视图(BaseTRef)中的时间参考块中的一者或两者。视频译码器可通过将当前块的TMV相加到经由当前块(CurrTRef)的时间参考块的协同定位深度块导出的DV而识别参考视图(BaseTRef)中的时间参考块。
如上文所论述,在一些实例中,如果当前块的经解码TMV指向与目标ARP参考图片不同的存取单元(时间例项)中的参考图片,那么视频译码器可将TMV缩放到目标ARP参考图片,且通过经缩放TMV定位CurrTRef。在此些实例中,视频译码器从如经缩放TMV识别的当前块(CurrTRef)的时间参考块的协同定位深度块导出DV。另外,如上文所论述,在一些实例中,当TMV经缩放以识别属于与目标ARP图片相同的存取单元的图片中的CurrTRef时,视频译码器可识别由TMV在无缩放的情况下识别的另一时间参考块(即,可识别CurrTempRef),且从CurrTempRef的协同定位深度块导出的DV(如果可用)可用于替换DV。在一些实例中,视频译码器仅需要在不能够经由当前块(CurrTRef)的时间参考块的协同定位深度块导出时识别和使用CurrTempRef。
视频译码器(例如视频编码器20和/或视频解码器30)可以多种方式中的任一者从当前块(CurrTRef)的时间参考块的协同定位深度块导出DV。在一些实例中,视频译码器直接使用协同定位深度块内的仅一个样本,且将相关联深度值转换为用于时间ARP的DV。在一些实例中,用于导出时间ARP的DV的协同定位深度块的单一样本为位于协同定位深度块的中心的像素,例如相对于具有大小WxH的一个深度块的左上样本位于(W/2,H/2)处。
在一些实例中,视频译码器使用协同定位深度块内的若干选择性样本以例如经由数学函数确定一个代表性深度值。在一个实例中,视频译码器选择四个隅角深度样本。在另一实例中,视频译码器基于深度块的相邻深度样本选择协同定位深度块内的深度样本。举例来说,当相邻深度样本展示水平边缘时,视频译码器可选择仅第一行处的两个隅角像素。在一些实例中,协同定位深度块内的所有深度样本可用于经由数学函数确定一个代表性深度值。在一些实例中,视频译码器可通过(例如)确定选定深度值的最大值、平均值或中值或将某一其它函数施加到所述选定深度值而基于来自协同定位深度块的选定(或所有)深度值确定代表性深度值。
在一些实例中,视频译码器可应用上文所描述的时间ARP技术,涉及在不需要独立于相关联深度视图的纹理视图的解码时经由当前块(CurrTRef)的时间参考块的协同定位深度块导出的DV。当需要独立于相关联深度视图的纹理视图的解码时,视频译码器可应用本文中所描述的其它ARP技术,例如相对于图10和11描述的技术。
当启用时间和视图间ARP两者时,用于ARP的加权因子信令条件可从检查所有参考图片是否为视图间参考图片改变为简单地检查当前图片是否为随机存取图片(IRAP,具有15到22(包含15和22)的NAL单元类型:即BLA_W_LP、BLA_W_RADL、BLA_N_LP、IDR_W_RADL、IDR_N_LP或CRA_NUT)。因此,在一些实例中,所述当前CU为并不属于IRAP图片的经帧间译码CU,那么视频编码器(例如视频编码器20)信令加权因子。在此些实例中,当图片为随机存取图片时,视频编码器绝不发射加权因子。在其它实例中,如果其参考图片中的至少一者(其可仅为视图间参考图片)具有其参考图片列表中的任一者中的视图间参考图片,那么视频编码器20另外信令所述加权因子是针对属于IRAP图片的经帧间译码CU。在此些实例中,视频译码器可针对存取单元内的图片执行视图间残余预测的ARP。
对于其中在当前CU为并不属于IRAP图片的经帧间译码CU的情况下视频编码器(例如视频编码器20)信令加权因子的实例中,coding_unit的语法表改变,如下文突出显示。相对于3D-HEVC测试模型4的添加是带下划线的,且删除以文本展示。
此外,移除变数TempRefPicInListsFlag和TempRefPicInListsFlag的相关导出过程,如下文所示:
H.8.3.7用于合并模式中的TMVP的替代目标参考索引的导出过程
●在当前切片为P或B切片时调用此过程。
●变量AltRefIdxL0和AltRefIdxL1设定成等于-1;且以下对于0到1(包含0和1)范围内的X适用:
○当X等于0或当前切片为B切片时,以下适用:
■zeroIdxLtFlag=RefPicListX[0]为短期参考图片?0:1
■对于(i=1;i<=num_ref_idx_lX_active_minus1&&AltRefIdxLX==-1;i++)
●如果((zeroIdxLtFlag&&RefPicListX[i]为短期参考图片)||
○(!zeroIdxLtFlag&&RefPicListX[i]为长期参考图片))
○AltRefIdxLX=i
■
针对时间ARP的现有提议在NBDV并不传回当前视频块的可用DV时停用ARP。然而,如上文所论述,本发明提供并不依赖于由NBDV导出的DV的用于ARP的技术。因此,在根据本发明的一些实例中,代替于在NBDV并不传回可用DV时始终停用ARP,视频译码器可在其中NBDV并不传回可用DV的至少一些情形中启用ARP。举例来说,视频译码器(例如视频编码器20和/或视频解码器30)可在时间参考视频块(CurrTRef)覆盖至少一个DMV的情况下启用时间ARP。作为另一实例,视频译码器可在时间参考视频块(CurrTRef)覆盖至少一个DMV且对应块并不以BVSP模式译码的情况下启用时间ARP。在此些实例中,视频译码器可使用DMV替换DV来应用时间ARP,例如如上文相对于图11所描述。作为另一实例,视频译码器可在当前参考图片为视图间参考图片的情况下启用视图间ARP,例如如上文相对于图10所描述。可在视频解码器处给定一或多个约束使得当NBDV并不传回可用DV且上述条件中的一或多者并非真时,用于ARP的加权因子w将被设定成0。
图14是说明可实施本发明中描述的技术的实例视频编码器20的框图。视频编码器20可以对视频切片内的视频块执行帧内和帧间译码。帧内译码依赖于空间预测来减少或移除给定视频帧或图片内的视频中的空间冗余。帧间译码依赖于时间或视图间预测来减少或移除视频序列的邻近帧或图片内的视频中的冗余。帧内模式(I模式)可指代若干基于空间的压缩模式中的任一者。例如单向预测(P模式)或双向预测(B模式)的帧间模式可包含若干基于时间的压缩模式中的任一者。
在图14的实例中,视频编码器20包含分割单元235、预测处理单元241、参考图片存储器264、求和器250、变换处理单元252、量化处理单元254和熵编码单元256。预测处理单元241包含运动估计单元242、运动补偿单元244、先进残余预测(ARP)单元254和帧内预测处理单元246。为了视频块重建,视频编码器20还包含逆量化处理单元258、逆变换处理单元260,和求和器262。还可包含解块滤波器(图14中未展示)以对块边界进行滤波以从重建的视频移除成块假影。需要时,解块滤波器通常将对求和器262的输出进行滤波。除了解块滤波器之外,还可使用额外环路过滤器(环路内或环路后)。
在各种实例中,可给视频编码器20的单元分派任务以执行本发明的技术。并且,在一些实例中,本发明的技术可在视频编码器20的单元中的一或多者当中划分。举例来说,ARP单元245可独自或结合视频编码器的其它单元(例如运动估计单元242和运动补偿单元244)执行本发明的技术。
如图14中所展示,视频编码器20接收视频数据,且分割单元235将数据分割成视频块。此分割还可包含分割成切片、瓦片或其它较大单元,以及例如根据LCU及CU的四叉树结构的视频块分割。视频编码器20总体上说明编码待编码的视频切片内的视频块的组件。所述切片可划分成多个视频块(且可能划分成被称作瓦片的视频块集合)。
预测处理单元241可基于错误结果(例如,译码速率及失真等级)针对当前视频块选择多种可能译码模式中的一者,例如,多种帧内译码模式中的一者或多种帧间译码模式中的一者。预测处理单元241可将所得的经帧内译码或经帧间译码块提供到求和器250以产生残余块数据,且提供到求和器262以重建经编码块以用作参考图片。
预测处理单元241内的帧内预测单元246相对于与待译码当前块在相同的帧或切片中的一或多个相邻块执行当前视频块的帧内预测性译码,以提供空间压缩。预测处理单元241内的运动估计单元242及运动补偿单元244相对于一或多个参考图片中的一或多个预测性块执行当前视频块的帧间预测性译码以例如提供时间压缩。
运动估计单元242可经配置以根据用于视频序列的预定模式为视频切片确定帧间预测模式。运动估计单元242与运动补偿单元244可高度集成,但出于概念目的单独地加以说明。由运动估计单元242执行的运动估计是产生运动向量的过程,所述运动向量估计视频块的运动。举例来说,运动向量可指示当前视频帧或图片内的视频块的PU相对于参考图片内的预测性块的移位。
预测性块为发现在像素差方面紧密匹配待译码视频块的PU的块,像素差可由绝对差总和(SAD)、平方差总和(SSD)或其它差度量来确定。在一些实例中,视频编码器20可计算存储于参考图片存储器264中的参考图片的子整数像素位置的值。举例来说,视频编码器20可内插四分之一像素位置、八分之一像素位置或参考图片的其它分数像素位置的值。因此,运动估计单元242可相对于全像素位置及分数像素位置执行运动搜索并且输出具有分数像素精度的运动向量。
运动估计单元242通过比较经帧间译码切片中的视频块的PU的位置与参考图片的预测性块的位置来计算PU的运动向量。参考图片可选自第一参考图片列表(列表0或RefPicList0)或第二参考图片列表(列表1或RefPicList1),其中的每一者识别存储在参考图片存储器264中的一或多个参考图片。运动估计单元242可将计算的运动向量发送到熵编码单元256和运动补偿单元246。
通过运动补偿单元244执行的运动补偿可以涉及基于通过运动估计(可能执行子像素精度的内插)确定的运动向量提取或产生预测性块。在接收到当前视频块的PU的运动向量后,运动补偿单元244可以即刻在参考图片列表中的一者中定位所述运动向量指向的预测性块。视频编码器20通过从正被译码的当前视频块的像素值减去预测性块的像素值从而形成像素差值来形成残余视频块。像素差值形成用于所述块的残余数据,且可包含明度和色度差分量两者。求和器250表示执行此减法运算的一或多个组件。运动补偿单元244还可产生与视频块及视频切片相关联的语法元素以供视频解码器30在解码视频切片的视频块时使用。
作为如上文所描述由运动估计单元242和运动补偿单元244执行的帧间预测的替代方案,帧内预测单元246可以对当前块进行帧内预测。明确地说,帧内预测处理单元246可以确定用来对当前块进行编码的帧内预测模式。在一些实例中,帧内预测处理单元246可以例如在单独的编码遍次期间使用各种帧内预测模式编码当前视频块,并且帧内预测模块246(或在一些实例中为预测处理单元241)可以从测试模式中选择适当帧内预测模式来使用。举例来说,帧内预测处理单元246可以使用速率失真分析计算用于各种经测试帧内预测模式的速率失真值,并且从所述经测试模式当中选择具有最佳速率失真特性的帧内预测模式。速率失真分析总体上确定经编码块与经编码以产生所述经编码块的原始未经编码块之间的失真(或误差)的量,以及用于产生经编码块的位速率(即,位数目)。帧内预测处理单元246可根据用于各种经编码块的失真和速率计算比率,以确定哪个帧内预测模式对于所述块展现最佳速率-失真值。
在任何状况下,在选择用于块的帧内预测模式之后,帧内预测处理单元246可将指示块的选定帧内预测模式的信息提供到熵编码单元256。熵编码单元256可根据本发明的技术对指示所选帧内预测模式的信息进行编码。视频编码器20在所发射的位流中可包含配置数据,其可包含多个帧内预测模式索引表和多个经修改的帧内预测模式索引表(也称为码字映射表),对用于各种块的上下文进行编码的定义,以及对最可能帧内预测模式、帧内预测模式索引表和经修改的帧内预测模式索引表的指示以用于所述上下文中的每一者。
在预测处理单元241经由帧间预测或帧内预测产生当前视频块的预测块之后,视频编码器20通过从当前视频块减去预测性块而形成残余视频块。残余块中的残余视频数据可包含在一或多个TU中并应用于变换处理单元252。变换处理单元252使用例如离散余弦变换(DCT)或概念上类似变换的变换将残余视频数据变换成残余变换系数。变换处理单元252可将残余视频数据从像素域转换到变换域,例如频域。
变换处理单元252可将所得变换系数发送到量化处理单元254。量化处理单元254量化变换系数以进一步减小位速率。量化过程可减少与变换系数中的一些或全部相关联的位深度。可通过调整量化参数来修改量化程度。在一些实例中,量化处理单元254可接着执行对包含经量化变换系数的矩阵的扫描。替代地,熵编码单元256可执行所述扫描。
在量化之后,熵编码单元256对经量化的变换系数进行熵编码。举例来说,熵编码单元256可执行上下文自适应可变长度译码(CAVLC)、上下文自适应二进制算术译码(CABAC)、基于语法的上下文自适应二进制算术译码(SBAC)、概率区间分割熵(PIPE)译码或另一熵编码方法或技术。在熵编码单元256进行的熵编码之后,可将经编码视频位流发射到视频解码器30,或将经编码位流存档以供稍后发射或由视频解码器30检索。熵编码单元256还可对正经译码当前视频切片的运动向量和其它语法元素进行熵编码。
逆量化处理单元258和逆变换处理单元260分别应用逆量化和逆变换以在像素域中重建残余块,例如以供稍后用作参考图片的参考块。运动补偿单元244可以通过将残余块相加到参考图片列表中的一者内的参考图片中的一者的预测性块来计算参考块。运动补偿单元244还可将一或多个内插滤波器应用于经重建的残余块以计算子整数像素值用于运动估计。求和器262将经重建的残余块相加到由运动补偿单元244产生的运动补偿预测块以产生参考块用于存储在参考图片存储器264中。参考块可由运动估计单元242和运动补偿单元244用作参考块以对后续视频帧或图片中的块进行帧间预测。
视频编码器20(例如,视频编码器20的ARP单元245)可执行ARP技术中的任一者,例如本文中所描述的视图间或时间ARP技术。举例来说,如果预测处理单元241和/或运动估计单元242对当前视频块进行视图间预测(例如基于来自与使用DMV的当前视频块不同的参考视图中的参考图片的参考块预测当前视频块),那么ARP单元245可识别与当前视频块相关联的DMV用于当前视频块的视图间预测。在一些实例中,DMV可为转换为IDMVC以用于当前视频块的运动信息预测的DV。
基于DMV,ARP单元245独自或结合运动补偿单元244还可识别视图间参考视频块(Base)和视图间参考视频块的TMV,所述TMV可能先前已经由运动估计单元242在视图间参考视频块(Base)的预测期间确定。基于TMV,ARP单元245独自或结合运动补偿单元244可识别参考视图(BaseTRef)中的时间参考视频块和当前视图(CurrTRef)中的时间参考视频块。ARP单元245可基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差(CurrTRef-BaseTRef)确定当前视频块的视图间残余预测符。ARP单元245可将加权因子w应用到所述差(CurrTRef-BaseTRef),且可将当前视频块的视图间预测符块确定为Base+w*(CurrTRef-BaseTRef),如本文例如相对于图10所描述。
作为另一实例,如果预测处理单元241和/或运动估计单元242对当前视频块进行时间预测(例如基于来自与使用TMV的当前视频块不同的存取单元但相同的视图中的参考图片的参考块预测当前视频块),那么ARP单元245可识别TMV。基于TMV,ARP单元245独自或结合运动补偿单元244还可识别时间参考视频块(CurrTRef)和时间参考视频块的DMV,所述DMV可能先前已经由运动估计单元242在时间参考视频块(CurrTRef)的预测期间确定。基于DMV,ARP单元245独自或结合运动补偿单元244可识别参考视图(BaseTRef)中的时间参考视频块和参考视图(Base)中的视图间参考视频块。ARP单元245可基于参考视图中的参考视频块之间的差(Base-BaseTRef)确定当前视频块的时间残余预测符。ARP单元245可将加权因子w应用到所述差(Base-BaseTRef),且可将当前视频块的时间预测符块确定为CurrTRef+w*(Base-BaseTRef),如本文例如相对于图11所描述。
在以上实例的任一者中,ARP单元245、运动补偿单元244和/或预测处理单元241或视频编码器20的任何组件可将视图间预测符块提供到求和器250,求和器250确定当前视频块的经编码视频位流中待编码的残余。另外,ARP单元245可缩放TMV和DMV,或根据本发明的技术针对ARP执行本文中所描述的函数中的任一者。
以此方式,视频编码器20可经配置以实施本发明的实例ARP技术来编码视频块。举例来说,视频编码器20可为经配置以执行用于编码视频数据的视图间先进残余预测的方法的视频编码器的实例,所述方法包括识别当前视频块的DMV,其中当前视频块在当前视图中,且其中所述DMV用于基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述方法进一步包括识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片;基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块;以及基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述方法进一步包括:基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块;以及编码经编码视频位流,所述经编码视频位流编码视频数据以识别当前视频块的DMV和残余块,其中由经编码视频位流识别的残余块包括当前视频块的视图间参考视频块与残余预测符块之间的差。
视频编码器20还可为包括经配置以存储编码视频数据的经编码视频位流的存储器和一或多个处理器的视频译码器的实例。视频译码器(例如视频编码器20)的所述一或多个处理器可经配置以识别当前视频块的DMV,其中当前视频块在当前视图中,且其中所述DMV用于基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述一或多个处理器进一步经配置以识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片,基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块,且基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述一或多个处理器进一步经配置以:基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块;且对经编码视频位流进行译码以识别当前视频块的DMV和残余块,其中通过对经编码视频位流进行译码而识别的残余块包括当前视频块的视图间参考视频块与残余预测符块之间的差。
图15是说明可实施本发明中描述的技术的实例视频解码器30的框图。在图15的实例中,视频解码器30包含熵解码单元280、预测处理单元281、逆量化处理单元286、逆变换单元288、求和器290和参考图片存储器292。预测处理单元281包含运动补偿单元282、ARP单元283和帧内预测单元284。在一些实例中,视频解码器30可执行一般与相对于图14的视频编码器20描述的编码遍次互逆的解码遍次。
在各种实例中,可给视频解码器30的单元分派任务以执行本发明的技术。并且,在一些实例中,本发明的技术可在视频解码器30的单元中的一或多者当中划分。举例来说,ARP单元283可独自或结合视频编码器的其它单元(例如运动补偿单元282)执行本发明的技术。
在解码过程期间,视频解码器30从视频编码器20接收表示经编码视频切片的视频块和相关联语法元素的经编码视频位流。视频解码器30的熵解码单元280对位流进行熵解码以产生经量化系数、运动向量和其它语法元素。熵解码单元280将运动向量及其它语法元素转发到预测处理单元281。视频解码器30可接收视频切片层级和/或视频块层级的语法元素。
当视频切片经译码为经帧内译码(I)切片时,预测处理单元281的帧内预测单元284可以基于所信令的帧内预测模式和来自当前帧或图片的先前经解码块的数据产生用于当前视频切片的视频块的预测数据。当视频帧经译码为经帧间译码(即,B或P)切片时,预测处理单元281的运动补偿单元282基于从熵解码单元280接收到的运动向量和其它语法元素产生用于当前视频切片的视频块的预测性块。预测性块可以从参考图片列表中的一者内的参考图片中的一者产生。视频解码器30可使用默认构造技术或基于存储于参考图片存储器292中的参考图片的任何其它技术来构造参考帧列表RefPicList0及RefPicList1。
运动补偿单元282通过解析运动向量和其它语法元素确定用于当前视频切片的视频块的预测信息,并且使用所述预测信息产生用于正解码的当前视频块的预测性块。举例来说,运动补偿单元282使用所接收语法元素中的一些语法元素确定用于对视频切片的视频块进行译码的预测模式(例如,帧内预测或帧间预测)、帧间预测切片类型(例如,B切片或P切片)、切片的参考图片列表中的一或多者的构造信息、切片的每一经帧间编码的视频块的运动向量、切片的每一经帧间译码的视频块的帧间预测状态,及用以解码当前视频切片中的视频块的其它信息。
运动补偿单元282还可基于内插滤波器执行内插。运动补偿单元282可使用由视频编码器20在视频块的编码期间使用的内插滤波器来计算参考块的子整数像素的内插值。在这种情况下,运动补偿单元282可根据所接收的语法信息元素而确定由视频编码器20使用的内插滤波器且使用所述内插滤波器来产生预测性块。
逆量化处理单元286对位流中提供的且由熵解码单元280解码的经量化变换系数进行逆量化,即解量化。逆量化过程可包含使用由视频编码器20针对视频切片中的每一视频块计算的量化参数以确定应应用的量化程度及同样确定应应用的逆量化程度。逆变换处理单元288对变换系数应用逆变换,例如逆DCT、逆整数变换或概念上类似的逆变换过程,以便产生像素域中的残余块。
在运动补偿单元282基于运动向量和其它语法元素产生当前视频块的预测性块之后,视频解码器30通过将来自逆变换处理单元288的残余块与运动补偿单元282产生的对应预测性块求和来形成经解码视频块。求和器290表示可执行此求和运算的一或多个组件。视需要,解块滤波器还可应用于对经解码块进行滤波以便移除成块假影。其它环路过滤器(在译码环路中或在译码环路之后)也可用于使像素转变变平滑或者以其它方式改进视频质量。接着将给定帧或图片中的经解码视频块存储在参考图片存储器292中,参考图片存储器292存储参考图片用于后续运动补偿。参考图片存储器292还存储经解码视频用于稍后在显示装置(例如图1的显示装置32)上呈现。
视频解码器30(例如视频解码器30的ARP单元283)可执行ARP技术中的任一者,例如本文中所描述的视图间或时间ARP技术。举例来说,如果基于由熵解码单元280从经编码视频位流恢复的语法元素,预测处理单元281和/或运动补偿单元282使用DMV对当前视频块进行视图间预测,那么ARP单元283可识别与当前视频块相关联的DMV用于当前视频块的视图间预测。在一些实例中,DMV可为转换为IDMVC以用于当前视频块的运动信息预测的DV。
基于DMV,ARP单元283独自或结合运动补偿单元282还可识别视图间参考视频块(Base)和视图间参考视频块的TMV,所述TMV可能先前已经由运动估计单元282在视图间参考视频块(Base)的预测期间确定。基于TMV,ARP单元283独自或结合运动补偿单元282可识别参考视图(BaseTRef)中的时间参考视频块和当前视图(CurrTRef)中的时间参考视频块。ARP单元283可基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差(CurrTRef-BaseTRef)确定当前视频块的视图间残余预测符。ARP单元283可将加权因子w应用到所述差(CurrTRef-BaseTRef),且可将当前视频块的视图间预测符块确定为Base+w*(CurrTRef-BaseTRef),如本文例如相对于图10所描述。
作为另一实例,如果基于由熵解码单元280从经编码视频位流恢复的语法元素,预测处理单元281和/或运动补偿单元282使用TMV对当前视频块进行时间预测,那么ARP单元283可识别TMV。基于TMV,ARP单元283独自或结合运动补偿单元282还可识别时间参考视频块(CurrTRef)和时间参考视频块的DMV,所述DMV可能先前已经由运动估计单元282在时间参考视频块(CurrTRef)的预测期间确定。基于DMV,ARP单元283独自或结合运动补偿单元282可识别参考视图(BaseTRef)中的时间参考视频块和参考视图(Base)中的视图间参考视频块。ARP单元283可基于参考视图中的参考视频块之间的差(Base-BaseTRef)确定当前视频块的时间残余预测符。ARP单元283可将加权因子w应用到所述差(Base-BaseTRef),且可将当前视频块的时间预测符块确定为CurrTRef+w*(Base-BaseTRef),如本文例如相对于图11所描述。
在上述实例的任一者中,ARP单元283、运动补偿单元282和/或预测处理单元281或视频解码器30的任何组件可将视图间预测符块提供到求和器290,求和器290将视图间预测符块与从逆变换处理单元288接收的经解码残余求和以重建当前视频块。另外,ARP单元283可缩放TMV和DMV,或根据本发明的技术针对ARP执行本文中所描述的函数中的任一者。
以此方式,视频解码器30可经配置以实施本发明的实例ARP技术来解码视频块。举例来说,视频解码器30可为经配置以执行用于解码视频数据的视图间先进残余预测的方法的视频解码器的实例,所述方法包括解码经编码视频位流,所述经编码视频位流编码视频数据以识别当前视频块的视差运动向量(DMV)和残余块,其中当前视频块在当前视图中,且其中所述DMV用于基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述方法进一步包括识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片;基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块;以及基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述方法进一步包括:基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块;以及将残余预测符块和从经编码视频位流识别的残余块施加到视图间参考视频块以重建当前视频块。
视频解码器30还可为包括经配置以存储编码视频数据的经编码视频位流的存储器和一或多个处理器的视频译码器的实例。视频译码器(例如视频解码器30)的所述一或多个处理器可经配置以识别当前视频块的DMV,其中当前视频块在当前视图中,且其中所述DMV用于基于参考视图中以及与当前视频块相同的存取单元中的视图间参考视频块的当前视频块的视图间预测。所述一或多个处理器进一步经配置以识别视图间参考视频块的时间运动向量(TMV)和相关联参考图片,基于视图间参考视频块的TMV识别参考视图中的相关联参考图片中的时间参考视频块,且基于参考视图中的视图间参考视频块的TMV识别当前视图中的时间参考视频块。当前视图中的时间参考视频块和参考视图中的时间参考视频块定位于相同存取单元中。所述一或多个处理器进一步经配置以:基于当前视图中的时间参考视频块与参考视图中的时间参考视频块之间的差确定当前视频块的残余预测符块;且对经编码视频位流进行译码以识别当前视频块的DMV和残余块,其中通过对经编码视频位流进行译码而识别的残余块包括当前视频块的视图间参考视频块与残余预测符块之间的差。
图16为说明根据本发明中描述的技术的用于解码视频块的实例ARP方法的流程图。图16的实例方法可由视频解码器(例如视频解码器30)执行,视频解码器30可包含ARP单元283。
根据图16的实例方法,视频解码器30解码经编码视频位流以识别当前视频块的参考视频块和残余块(300)。举例来说,运动补偿单元282可基于由熵解码单元280解码的语法所指示的运动向量识别参考视频块,且逆变换处理单元288可将经解码残余块提供到求和器290。视频解码器30(例如ARP单元283)识别从当前视频块的当前视图到参考视图的DMV(302)。
视频解码器30(例如ARP单元283)可随后基于所述DMV确定用于解码当前视频块的残余预测符块(304)。举例来说,如果当前视频块经视图间预测,那么视频解码器30可使用例如如相对于图10所描述的视图间ARP技术基于当前视频块的DMV确定视图间残余预测符块。如果当前视频块经时间预测,那么视频解码器30可使用例如如相对于图11所描述的时间ARP技术基于时间参考视频块的DMV确定时间残余预测符块。视频解码器30(例如ARP单元283和/或求和器290)可将残余预测符块和经解码残余块应用到参考视频块以重建当前视频块(306)。
图17为说明根据本发明中描述的技术的用于解码经视图间预测的视频块的实例视图间ARP方法的流程图。图17的实例方法可由视频解码器(例如视频解码器30)执行,视频解码器30可包含ARP单元283。
根据图17的实例方法,视频解码器30解码经编码视频位流以识别用于当前视频块的视图间预测的DMV和残余块(310)。视频解码器30(例如ARP单元283)基于所述DMV识别视图间参考视频块(Base)(312)。视频解码器30(例如ARP单元283)还识别视图间参考视频块(Base)的TMV和相关联参考图片(314)。
视频解码器30(例如ARP单元283)可随后例如使用上文相对于图10描述的技术基于TMV识别当前和参考视图(分别CurrTRef和BaseTRef)中的时间参考视频块(316)。视频解码器30(例如ARP单元283)可随后基于这些时间参考视频块(CurrTRef-BaseTRef)之间的差确定当前视频块的视图间残余预测符块(318)。视频解码器(例如ARP单元283和/或求和器290)可将视图间残余预测符块和经解码残余块应用到视图间参考视频块(Base)以重建当前视频块(Curr)(320)。
图18为说明根据本发明中描述的技术的用于解码经时间预测视频块的实例时间ARP方法的流程图。图18的实例方法可由视频解码器(例如视频解码器30)执行,视频解码器30可包含ARP单元283。
根据图18的实例方法,视频解码器30解码经编码视频位流以识别当前视图中的时间参考视频块(CurrTRef)和残余块用于重建当前视频块(330)。视频解码器30(例如运动补偿单元282)可使用如从经解码视频位流确定的与当前视频块相关联的TMV识别当前视图中的时间参考视频块(CurrTRef)。视频解码器30(例如ARP单元283)可识别时间参考视频块(CurrTRef)的DMV,其又可识别参考视图(BaseTRef)中的时间参考视频块(332)。
视频解码器30(例如ARP单元283)还可基于当前视图中的时间参考视频块(CurrTRef)的DMV识别参考视图(Base)中的视图间参考视频块(334)。视频解码器30(例如ARP单元283)可随后基于参考视图中的这些参考视频块之间的差(Base-BaseTRef)确定当前视频块的时间残余预测符块(336)。视频解码器(例如ARP单元283和/或求和器290)可将时间残余预测符块和经解码残余块应用到时间参考视频块(CurrTRef)以重建当前视频块(Curr)(338)。
图19为说明根据本发明中描述的技术的用于编码视频块的实例ARP方法的流程图。图19的实例方法可由视频编码器(例如视频编码器20)执行,视频编码器20可包含ARP单元245。
根据图19的实例方法,视频编码器20(例如ARP单元245)识别当前视频块的当前视图到参考视图的DMV(340)。视频编码器20(例如ARP单元245)可随后基于DMV确定用于编码当前视频块的残余预测符块(342)。举例来说,如果当前视频块经视图间预测,那么视频编码器20可使用例如如相对于图10所描述的视图间ARP技术基于当前视图的DMV确定视图间残余预测符块。如果当前视频块经时间预测,那么视频编码器20可使用例如如相对于图11所描述的时间ARP技术基于当前视图中的时间参考视频块的DMV确定时间残余预测符块。在任一情况中,视频编码器20(例如ARP单元245和求和器250)可基于当前视频块与当前视频块的预测符块之间的差确定当前视频块的残余块,其可为当前视频块的参考视频块和残余预测符块的总和(344)。视频编码器20可编码视频位流以识别此残余块和参考视频块(346)。
图20为说明根据本发明中描述的技术的用于编码经视图间预测的视频块的实例视图间ARP方法的流程图。图20的实例方法可由视频编码器(例如视频编码器20)执行,视频编码器20可包含ARP单元245。
根据图20的实例方法,视频编码器20(例如ARP单元245)识别当前视频块(Curr)到视图间参考视频块(Base)的DMV(350)。视频编码器20(例如ARP单元245)还识别视图间参考视频块的TMV和相关联参考图片(Base)(352)。视频编码器20(例如ARP单元245)可随后例如使用上文相对于图10描述的技术基于TMV识别当前和参考视图(分别CurrTRef和BaseTRef)中的时间参考视频块(354)。
视频编码器30(例如ARP单元245)可随后基于这些时间参考视频块之间的差(CurrTRef-BaseTRef)确定当前视频块的视图间残余预测符块(318)。视频编码器20(例如ARP单元245和求和器250)可基于当前视频块与当前视频块的预测符块之间的差确定当前视频块的残余块,其可为当前视频块的视图间参考视频块(Base)和残余预测符块的总和(358)。视频编码器20可编码视频位流以识别此残余块和视图间参考视频块(360)。
图21为说明根据本发明中描述的技术的用于编码经时间预测视频块的实例时间ARP方法的流程图。图21的实例方法可由视频编码器(例如视频编码器20)执行,视频编码器20可包含ARP单元245。
根据图21的实例方法,视频编码器20(例如ARP单元245)例如使用与当前视频块相关联的TMV识别当前视图中的时间参考视频块(CurrTRef)。视频编码器20(例如ARP单元245)可随后识别时间参考视频块(CurrTRef)的DMV,其又可识别参考视图(BaseTRef)中的时间参考视频块(370)。基于当前视图中的时间参考视频块(CurrTRef)的DMV,视频编码器20(例如ARP单元245)还可识别参考视图(Base)中的视图间参考视频块(372)。
视频编码器20(例如ARP单元245)可随后基于参考视图中的这些参考视频块之间的差(Base-BaseTRef)确定当前视频块的时间残余预测符块(374)。视频编码器20(例如ARP单元245和求和器250)可基于当前视频块与当前视频块的预测符块之间的差确定当前视频块的残余块,其可为当前视频块的时间参考视频块(CurrTRef)和残余预测符块的总和(376)。视频编码器20可编码视频位流以识别此残余块和视图间参考视频块(378)。
图22为说明根据本发明中描述的技术的用于识别时间ARP的DMV的实例方法的流程图。图22的实例方法可由视频译码器(例如视频编码器20和/或视频解码器30)执行,所述视频编码器20和/或视频解码器30可包含ARP单元245、283。
根据图22的实例方法,视频译码器基于经缩放TMV识别当前视图(CurrTRef)中的时间参考视频块(380)。视频译码器随后确定所识别时间参考视频块是否与DMV相关联(382)。如果时间参考视频块与DMV相关联,那么视频译码器基于DMV识别视图间参考视频块(388)。如果时间参考视频块并不与DMV相关联,那么视频译码器在无缩放的情况下基于TMV识别当前视图中的另一时间参考视频块(384),且基于在无缩放的情况下基于TMV识别的当前视图中的时间参考视频块的DMV识别视图间参考视频块(388)。
图23为说明根据本发明中描述的技术的用于识别ARP的DMV或TMV的实例方法的流程图。图23的实例方法可由视频译码器(例如视频编码器20和/或视频解码器30)执行,所述视频编码器20和/或视频解码器30可包含ARP单元245、283。
根据图23的实例方法,视频译码器首先检查用于ARP所需要的DMV或TMV的RefPicList0(390)。如果RefPicList0包含DMV或TMV,那么视频译码器基于DMV或TMV识别参考视频块(396)。如果RefPicList0并不包含DMV或TMV,那么视频译码器检查用于DMV或TMV的RefPicList1(394),且可基于来自RefPicList1的DMV或TMV识别参考视频块(396)。如果参考图片列表既不包含DMV也不包含TMV,那么视频译码器可使用0运动向量或不执行ARP,作为实例。在其中视频译码器使用用于ARP的0运动向量的一些实例中,视频译码器可将0运动向量应用到针对使用DMV的视图间预测调用的参考图片列表(方向)。
在一些实例中,本发明中描述的技术的一或多个方面可由例如具有媒体知识的网络元件(MANE)、流调适处理器、剪接处理器或编辑处理器等中间网络装置执行。举例来说,此中间装置可经配置以产生或接收如本发明中描述的多种信令中的任一者。
在一或多个实例中,所描述的功能可用硬件、软件、固件或其任何组合来实施。如果以软件实施,那么功能可作为一或多个指令或代码存储在计算机可读媒体上或在计算机可读媒体上发射,并由基于硬件的处理单元执行。计算机可读媒体可包含计算机可读存储媒体,其对应于例如数据存储媒体等有形媒体,或包含任何促进将计算机程序从一处传送到另一处的媒体(例如,根据一种通信协议)的通信媒体。以此方式,计算机可读媒体大体上可以对应于(1)非暂时性的有形计算机可读存储媒体,或(2)通信媒体,例如信号或载波。数据存储媒体可以是可由一或多个计算机或一或多个处理器存取以检索用于实施本发明中描述的技术的指令、代码和/或数据结构的任何可用媒体。计算机程序产品可包含计算机可读媒体。
举例来说(且并非限制),此些计算机可读存储媒体可包括RAM、ROM、EEPROM、CD-ROM或其它光盘存储装置、磁盘存储装置或其它磁性存储装置,或可用于存储呈指令或数据结构的形式的所要程序代码且可由计算机存取的任何其它媒体。而且,任何连接被恰当地称为计算机可读媒体。举例来说,如果使用同轴缆线、光纤缆线、双绞线、数字订户线(DSL)或例如红外线、无线电和微波等无线技术从网站、服务器或其它远程源发射指令,那么同轴缆线、光纤缆线、双绞线、DSL或例如红外线、无线电和微波等无线技术包含在媒体的定义中。然而,应理解,计算机可读存储媒体及数据存储媒体并不包含连接、载波、信号或其它暂时性媒体,而是实际上针对于非暂时性的有形存储媒体。如本文所使用,磁盘和光盘包含压缩光盘(CD)、激光光盘、光学光盘、数字多功能光盘(DVD)、软性磁盘和蓝光光盘,其中磁盘通常以磁性方式再现数据,而光盘用激光以光学方式再现数据。上述各者的组合也应包含在计算机可读媒体的范围内。
指令可以由一或多个处理器执行,所述一或多个处理器例如是一或多个数字信号处理器(DSP)、通用微处理器、专用集成电路(ASIC)、现场可编程逻辑阵列(FPGA)或其它等效的集成或离散逻辑电路。因此,如本文中所使用的术语“处理器”可指上述结构或适合于实施本文中所描述的技术的任一其它结构中的任一者。此外,在一些方面中,本文中所描述的功能性可在经配置用于编码及解码的专用硬件及/或软件模块内提供,或并入在组合编解码器中。并且,可将所述技术完全实施于一或多个电路或逻辑元件中。
本发明的技术可在广泛多种装置或设备中实施,包括无线手持机、集成电路(IC)或一组IC(例如,芯片组)。本发明中描述各种组件、模块或单元是为了强调经配置以执行所揭示的技术的装置的功能方面,但未必需要由不同硬件单元实现。实际上,如上文所描述,各种单元可以结合合适的软件及/或固件而组合在编解码器硬件单元中,或者由互操作硬件单元的集合来提供,所述硬件单元包含如上文所描述的一或多个处理器。
已经描述各种实例。这些和其它实例在所附权利要求书的范围内。
- 还没有人留言评论。精彩留言会获得点赞!