语音处理系统的自动增益控制方法及控制装置与流程
本发明涉及语音处理系统,尤其涉及一种语音处理系统的自动增益控制方法及控制装置,可以应用在语音压缩、录音或语音识别等系统的输入信号处理,能有效地提供达到电压位准(power level)目标范围的输入语音信号,以利语音处理系统的后续相关处理。
背景技术:
在语音压缩、录音或语音识别等语音处理系统中,其模拟语音输入信号的前置处理,是期望被处理的语音信号在进入模拟数字转换处理时,就能够达到应用所需的电压位准,然后提供后续语音处理单元进行应用处理。
就语音处理系统而言,语音的输入是透过麦克风及模拟电路作为前置电路,然后进入模拟数字转换器(Analog to Digital Converter,ADC)转换成数字语音数据。但是,麦克风输入的语音信号会受到许多原因的影响,而产生变动性的电压位准。分析影响语音输入产生不同电压位准或能量的原因,其包括:1)麦克风的灵敏度;2)语音输入源(人声)与麦克风的距离远近;3)语音输入源发出声音的能量大小;4)环境噪声声的能量位准等因素,这些都会影响输入语音的电压位准或能量。
然而,有些硬件处理方式是在麦克风及模拟电路的前置电路中,采用固定增益的方法来放大语音的电压位准。但是当语音输入源时而靠近、时而离远麦克风时,所获得的语音信号就会忽大忽小;或者语音输入源发出声音的能量产生大小变化时,亦会影响输入的电压位准。此外,在固定增益的电路处理下,环境噪声是会被同步放大的,进而影响后续语音处理的正确性。因此,为使后续语音处理单元能获得稳定且达到电压位准目标范围的输入语音信号,则需要能够依据输入语音信号自动调整增益的方法,来达到应用所需的目的。
另外,目前有许多语音活动检测(Voice Activity Detection,VAD)的方法,在时域中有使用输入语音音框的能量平均值、均方根值(Root Mean Square,RMS),或在频域中有使用语音音框的频谱峰值(Spectral Peak)等特征值,来进行是否有语音活动的判断。但是,应用前述的运算方法来检测语音活动,其属于较高的计算复杂度;尤其在采用频域的特征值时,需要将输入语音作频谱转换,亦会增加处理时间及计算复杂度。因此,这些语音活动检测方法虽能有效检测语音活动,但是并不适用在使用低阶的微处理器的应用上。
技术实现要素:
本发明的目的是提供一种语音处理系统的自动增益控制方法及控制装置,该控制方法及控制装置能在语音处理系统中动态调适地追踪语音输入信号,处理后有效地调整运算放大器的增益,使输入的语音信号能够有效达到电压位准目标范围。
为达上述目的,本发明采用的技术方案如下:
一种语音处理系统的自动增益控制方法,所述自动增益控制方法包括:
将麦克风的输出信号输入运算放大器放大;
将放大后的信号转换为数字信号;
对所述数字信号进行语音活动检测;以及
当检测到所述数字信号为语音信号时,比较当前运算窗框和前一运算窗框的语音信号参数,根据比较结果向所述运算放大器输出相应的增益调整数据。
在上述的语音处理系统的自动增益控制方法中,优选地,对所述数字信号进行语音活动检测的步骤包括:
按采样频率读取所述数字信号;
获取每个采样音框内数字信号的最大峰值;
比较所述最大峰值,获取运算窗框内信号的最大振幅;以及
将所述最大振幅与设定的阀值比较,判断所述数字信号是否为语音信号。
在上述的语音处理系统的自动增益控制方法中,优选地,每一运算窗框包括四个采样音框,每一采样音框的时间长度为20~40ms。
在上述的语音处理系统的自动增益控制方法中,优选地,增益调整数据符合渐进调整所述运算放大器增益的原则。
在上述的语音处理系统的自动增益控制方法中,优选地,所述的语音信号参数为语音信号的最大振幅。
在上述的语音处理系统的自动增益控制方法中,优选地,所述自动增益控制方法还包括:在启动时或判断不是语音信号时,将所述运算放大器的增益调整为初始值。
在上述的语音处理系统的自动增益控制方法中,优选地,在所述的根据比较结果向所述运算放大器输出相应的增益调整数据的步骤中,当语音能量连续小于设定下限时,快速降低所述运算放大器的增益。
一种语音处理系统的自动增益控制装置,所述自动增益控制装置包括从输入端到输出端顺次连接的运算放大器、模拟数字转换器和微控制器,所述运算放大器的增益调整端与所述微控制器连接,所述微控制器用于:采样所述模拟数字转换器输出的数字信号;对所述数字信号进行语音活动检测;以及当检测到语音信号时,比较当前运算窗框和前一运算窗框的语音信号参数,根据比较结果向所述运算放大器输出相应的增益调整数据。
在上述的语音处理系统的自动增益控制装置中,优选地,所述运算放大器的输入端和麦克风之间设置有抗混迭滤波器。
在上述的语音处理系统的自动增益控制装置中,优选地,所述微控制器配置为:依据渐进调整原则生成所述增益调整数据,且当语音能量连续小于设定下限时快速调降所述运算放大器的增益。
与现有技术相比,本发明至少具有以下有益效果:
能使语音输入信号达到所设定的电压位准目标范围,提供稳定的语音数字采样数据给语音处理单元,进行语音处理相关应用的运算。
直接使用麦克风输入语音信号进行自动增益控制,无须对麦克风输入电压位准进行校准程序。
能对麦克风输入信号进行语音活动检测,以利正确进行语音增益调整。
附图说明
图1为典型实施例自动增益控制方法的流程图;
图2为其中语音活动检测方法的流程图;
图3为采样音框及运算窗框的定义示意图;
图4为典型实施例自动增益控制装置的原理框图。
具体实施方式
下面结合附图和实施例对本发明做进一步说明。
参照图1,典型实施例语音处理系统的自动增益控制方法包括:
步骤S100、将麦克风的输出信号输入运算放大器放大;
步骤S200、将放大后的信号转换为数字信号;
步骤S300、对所述数字信号进行语音活动检测;以及
步骤S400、当检测到所述数字信号为语音信号时,比较当前运算窗框和前一运算窗框的语音信号参数,根据比较结果向所述运算放大器输出相应的增益调整数据。
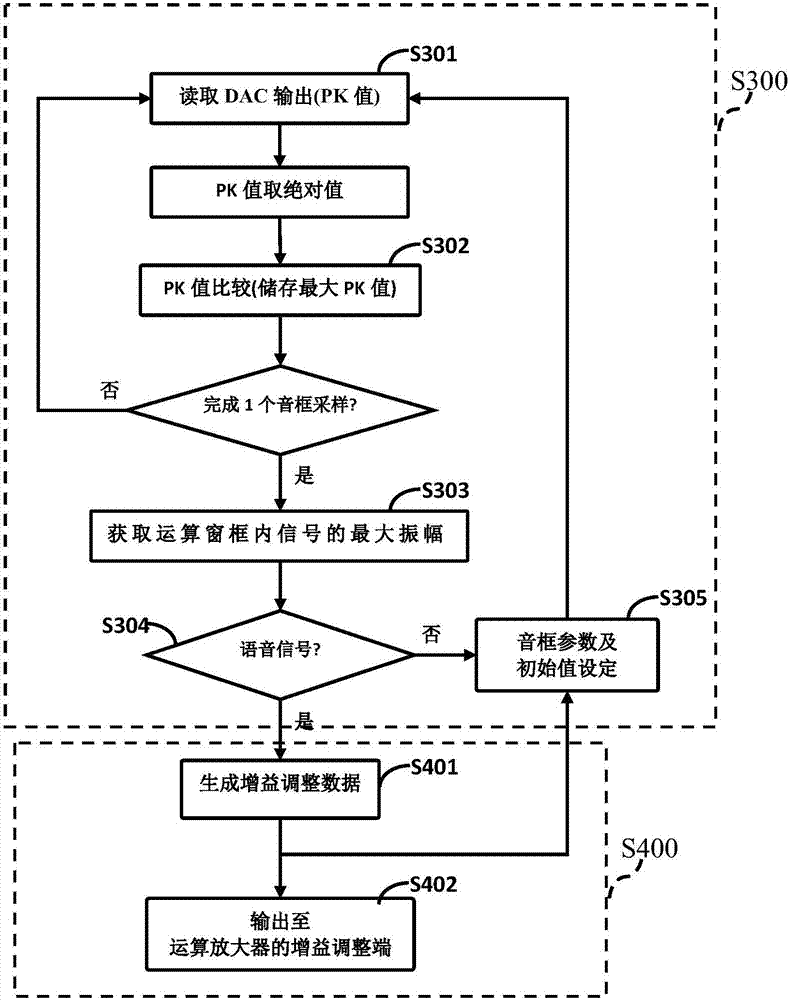
参照图2,对所述数字信号进行语音活动检测的方法,即步骤S300包括:
步骤S301、按采样频率读取所述数字信号。
更具体地说包括:读取模拟数字转换器(DAC)的输出值,该数值表示为PK(Peak value)。
由于模拟数字转换器的输出值即为波形取样值,当为语音信号时在转换过程中会产生有符号数值,所以在音框采样数值比对前,进一步还包括将PK值取绝对值,该绝对值表示为PKCUR=|PK|。
步骤S302、获取每个采样音框内数字信号的最大峰值。
更具体地说包括:连续比对在同一音框内采样数值,并储存比对后的最大值,当完成1个音框的采样数及数值比较,即获得该采样音框的PK最大值(即,数字信号的最大峰值),其表示为
PKMAXFn,n=0,1,2,3
其中,Fn,n=0,1,2,3为4个连续的采样音框PK最大值。在增益控制算法中储存采样音框PK最大值的缓存器是循环使用的,即在进行下一个采样音框处理前,就会调整储存下一个采样音框PK最大值的缓存器位置参数,即步骤S305,(n+1)mod 4。
步骤S303、比较所述最大峰值(即上述PK最大值),获取运算窗框内信号的最大振幅。
在典型实施例中,运算窗框由连续的四个采样音框组成,通过比较连续的四个采样音框的PK最大值,选出最大值
PKMAX=max(PKMAXFn),n=0,1,2,3,
作为运算窗框内信号的最大振幅,然后使用PKMAX进行语音信号判断。
步骤S304、将所述最大振幅与设定的阀值比较,判断所述数字信号是否为语音信号。
使用PKMAX进行语音信号判断的判断式如下:
if PKMAX≥PKTHD,then VA=1(判断该窗框信号是语音信号),
if PKMAX<PKTHD,then VA=0(判断该窗框信号不是语音信号);
其中,PKTHD是设定的阀值。
若判断结果不是语音信号,则执行步骤S305、调整采样音框的参数及相关初始值设定,进入下一音框的采样数值读取和数值比较。
若判断结果是语音信号,则执行步骤S400进行增益调整,具体包括:步骤S401、生成增益调整数据;以及步骤S402、将增益调整数据输出至前述的运算放大器的增益调整端。
步骤S401中,生成增益调整数据的方法包括:当检测到为语音信号时,比较当前运算窗框和前一运算窗框的语音信号参数,根据比较结果生成相应的增益调整数据,使运算放大器的增益调大或调小。其中,所述语音信号参数采用运算窗框内语音信号的最大振幅,即上述PKMAX。可见,增益调整的依据是当前运算窗框的PKMAX与前一次运算窗框的PKMAXPRE。
进一步,采取渐进式的增加/减少模式调整增益,使输入语音信号的电压位准能稳定地增加/减少,达到设定的电压位准目标区。
生成增益调整数据的方法进一步还包括,在启动时或判断不是语音信号时,将所述运算放大器的增益调整为初始值。该初始值是语音处理系统获得的实验值。
由于语音输入的能量在进入系统时,通常是由小变大的变化;但是当语音输入结束时,则是快速地由有声音变成无声音的状态。因此,生成增益调整数据的方法进一步还包括,当语音能量连续小于设定下限时,快速降低所述运算放大器的增益。以避免环境噪声在高增益数值下仍持续放大,造成语音活动检测中对语音输入的误判。
典型实施例中,每一运算窗框包括四个采样音框,每一采样音框的时间长度为20ms。图3中示出了采样音框及运算窗框的定义。参照图3,依时间轴线处理输入语音信号,每一采样音框会产出一个语音峰值(Peak value,简称PK值);连续4个采样音框构成1个增益调整的运算窗框,使用窗框内的语音峰值进行运算,判断是否语音信号,以及生成增益调整数据。
对于语音处理的音框采样时间长度,根据语音采样的相关研究中采样音框的时间长度通常在20~40ms间,是较适当的采样时间。因此,在典型实施例中采样音框的时间长度是依采样频率调整,使采样音框的时间长度约在20ms左右;若采样频率为8KHz,则采样音框内的采样点数为160点时,采样音框的时间长度等于20ms。另外,语音活动检测的运算窗框时间长度,则等于4个采样音框的时间长度。每次增益调整运算窗框内的采样数据有75%是交迭(overlap)的,这样的设计是为使增益调整算法中,不会因单一音框中噪声信号的变动影响,进而大幅度地调整增益数值;适当长度的运算窗框,可以获得较为稳定的增益调整数值。
参照图4,典型实施例自动增益控制装置100包括:从输入端到输出端顺次连接的运算放大器101、模拟数字转换器103和微控制器102,所述运算放大器101的增益调整端与所述微控制器102连接,所述微控制器102用于:采样所述模拟数字转换器103输出的数字信号;对所述数字信号进行语音活动检测;以及当检测到语音信号时,比较当前运算窗框和前一运算窗框的语音信号参数,根据比较结果向所述运算放大器101输出相应的增益调整数据。
进一步在所述运算放大器101的输入端和麦克风200之间设置有抗混迭滤波器(Anti-Aliasing Filter,AAF)300。通过该滤波器能够滤除超出语音处理范围的信号,且增加输入信号对噪声的抗干扰能力。进一步,滤波后采用共模拒斥比(Common-Mode Rejection Ratio,CMRR)模式输入至运算放大器101。
进一步,所述微控制器102配置为:依据渐进调整原则生成所述增益调整数据,且当语音能量连续小于设定下限时快速调降所述运算放大器101的增益。
进一步,所述微控制器102配置为:每一运算窗框包括四个采样音框,每一采样音框的时间长度为20~40ms。
可见,所述微控制器102内融合了语音活动检测和渐进式增益调整模型。语音输入经过麦克风200进行拾音后,产生的声音弦波信号经过抗混迭滤波器300滤波后进入自动增益控制装置100处理,在自动增益控制装置100中,输入的语音信号电压位准经过运算放大器101的放大处理后,透过模拟数字转换器103转换为数字语音数据,然后经由微控制器102处理,得到下一个音框语音输入的增益调整数据,并反馈(Feedback)该增益调整数据到运算放大器101,提供下一个音框语音输入的增益,使语音输入的能量大小得以自动调整到电压位准目标区。
在完成前述处理后的数字语音数据,则提供给数字语音处理单元400进行所需的处理或演算,例如,数字滤波、语音识别、数据压缩储存等,达到语音处理系统的应用需求。
上述通过具体实施例对本发明进行了详细的说明,这些详细的说明仅仅限于帮助本领域技术人员理解本发明的内容,并不能理解为对本发明保护范围的限制。本领域技术人员在本发明构思下对上述方案进行的各种润饰、等效变换等均应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!