基于长度约束和无重复路径的网络信息传播方法与流程
本发明属于计算机技术领域,更进一步涉及数据挖掘技术领域中的一种基于长度约束和无重复路径的网络信息传播方法。本发明可用于微博,社交和电商等复杂网络中传播不同节点间的文字,评价等信任信息。
背景技术:
社交、电商等网络是一个典型的复杂网络,在这种复杂网络中将每个人或个体抽象为一个网络节点,而人与人之间的关系抽象为网络中对应节点间的连边,各节点之间的关联程度可以抽象为网络中对应边的权重,由此构成了复杂网络模型,网络中相邻节点的信任信息可以用节点间的权重表示。复杂网络中信息传播模型不仅能够明确信任信息传播的过程,而且还能够预测信息的传播路径以及传播态势,从宏观以及微观上把握信息传播的特点,从而为信息传播的研究提供理论依据。目前复杂网络中的信任传播主要为基于矩阵幂的信任传播模型和基于节点间路径的信任传播模型。
重庆邮电大学在其申请的专利文献“面向社交网络的多信息和多维网络信息传播模型及方法”(专利申请号201711380291.1,申请公布号cn108230170a)中公开了一种面向社交网络的多信息和多维网络信息传播方法。该方法通过获取社交网络数据,对该社交网络数据进行预处理,构建多维空间网络,引入“影响因子”用以表示不同信息之间的相互作用及强度,用余弦相似度的方法明确多维空间网络的信息传播。该方法存在的不足之处是,由于该方法引入了额外的影响因子,增加了节点间关系的不确定性,不能准确描述节点间信任关系。
郑州大学在其申请的专利文献“基于传播路径隐私泄露风险的社交网络信任度计算方法”(专利申请号201810654835.7,申请公布号cn108900409a)中公开了一种基于传播路径隐私泄露风险的社交网络信任度计算方法。该方法对社交网络中的每个用户建立一个黑名单,限制黑名单中的用户与网络中的用户进行信息交互,通过对社交网络平台中随机性的删除局部网络连边,预测信息传播路径及隐私泄露风险概率来计算用户之间的信任度方法。该方法存在的不足之处是,由于该方法通过对社交网络平台中随机性的删除局部网络连边,较大程度的破坏了网络的拓扑结构,导致删除后的网络可用性低的问题。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于长度约束和无重复路径的网络信息传播方法,解决网络中的信息传播可靠性问题。
实现本发明目的的思路是,本发明首先使用信任网络图模型,在起始节点到终端节点的最优网络路径搜索过程中,既考虑了路径节点间权重值的影响,也保证了信任网络的结构属性不改变,利用路径代价估计值的方法确定路径的后继节点,并引入长度加倍操作,得到起始节点到终端节点间有长度约束的无重复路径总数,使用网络信息接受度判断节点间传播信息的真实性。
为了实现上述目的,本发明的具体步骤包括如下:
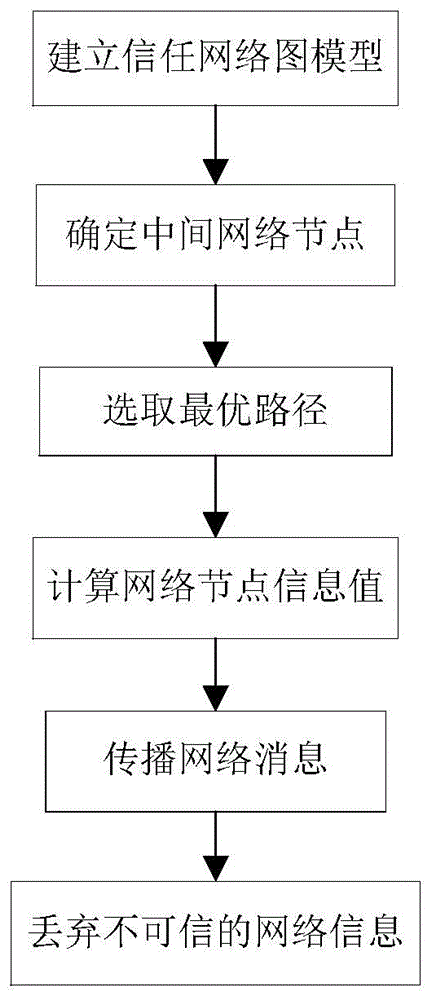
(1)建立信任网络图模型;
(1a)读入至少含有300个网络节点的数据集;
(1b)将所读入数据集的数据抽象为有向图;
(1c)采用网络邻接矩阵生成方法,生成与有向图对应的邻接矩阵;
(2)确定中间网络节点:
(2a)分别建立一个用于存储后继节点的空栈、用于存储终端节点的空集合、用于存储网络节点的交集;
(2b)从网络节点的数据集中随机选择一个未选过网络节点作为起始节点;
(2c)将与起始节点有连边、且从未访问过的所有网络节点作为后继节点存入栈中;
(2d)从栈中弹出一个后继节点;
(2e)判断当前起始节点到当前弹出的后继节点的路径上的边数是否小于等于长度约束值,若是,将当前弹出的后继节点作为终端节点存入集合中,执行本步骤的(2f),否则,将当前弹出的后继节点作为起始节点,执行本步骤的(2c);
(2f)判断栈是否为空,若是,则得到一个网络集合,执行本步骤的(2g),否则,执行本步骤的(2d);
(2g)判断是否得到两个集合,若是,执行本步骤的(2h),否则,执行本步骤的(2a);
(2h)判断两个集合中是否存在结构相同的网络节点,若是,执行本步骤的(2i),否则,将长度约束值加1后执行本步骤的(2a);
(2i)将所有结构相同的网络节点对应的任意一个集合中的所有网络节点放入交集,从交集中随机选取一个网络节点,作为中间网络节点;
(2j)将当前起始节点作为目标节点;
(3)选取最优路径:
(3a)从交集中选择未选过的网络节点作为最优路径的起始节点,目标节点作为最优路径的终端结点;
(3b)建立一个用于存储候选后继节点的空集合,建立一个用于存储最优路径节点的链表,建立一个用于存储路径的集合;
(3c)将与最优路径的起始节点有连边、且从未访问过的网络节点作为候选后继节点,存入集合中;
(3d)从集合中选取一个未选取过的候选后继节点;
(3e)利用总权重值计算公式,计算路径从起始节点到所选后继节点的总权重值;
(3f)按照下式,计算最优路径的经由所选后继节点到最优路径的终端节点的代价估计值:
f=g(·)+h(·)
其中,f表示最优路径的起始节点经由所选后继节点到最优路径的终端节点的代价估计值,g(·)表示从最优路径的起始节点到所选后继节点的代价值,h(·)表示当前所选后继节点到最优路径的终端节点的最优路径代价估计值;
(3g)判断候选节点集合中的节点是否都被选取过,若是,执行本步骤的(3g),否则,执行本步骤的(3d);
(3h)从集合中选取起始节点到终端节点代价估计值中的最小值,将该最小值对应的后继节点作为最优路径中间节点存入链表中;
(3i)判断存入链表中的最优路径中间节点是否为终端节点,若是,则将该链表放入存储路径的集合后执行本步骤的(3j),否则,将当前候选后继节点作为最优路径的起始节点后执行本步骤的(3c);
(3j)判断交集中是否存在未被选过的节点,若是,执行本步骤的(3a),否则,得到一个存储路径的集合,执行步骤(4);
(4)计算网络节点信息值:
(4a)按照下式,计算最优路径起始节点到终端节点的网络信息接受度:
其中,γ表示最优路径起始节点到终端节点的网络信息接受度,α表示网络信息传播可信度参数,zn表示存储路径集合中所有路径长度为n的路径总数,∑表示求和操作,s表示路径节点集合的一个子集合,
(4b)按照下式,计算最优路径起始节点的连接状态比值:
其中,u表示最优路径起始节点的连接状态比值,t表示最优路径的起始节点,vn表示有向图中的第n个节点,∈表示属于符号,v表示存储候选后继节点的集合,
(4c)判断网络信息接受度是否大于等于连接状态比值,若是,执行步骤(5),否则,执行步骤(6);
(5)传播网络消息:
将最优路径的起始节点到终端节点的网络信息判定为可信度高信息,可以进行新一轮的信息传播;
(6)丢弃不可信的网络信息:
将起始节点到终端节点传递的网络信息判定为不可靠,丢弃该网络信息并终止信息传播。
本发明与现有技术相比具有如下优点:
第一,由于本发明使用信任网络图模型,选取起始节点到终端节点的最优路径,克服了现有技术中对社交网络随机性的删除局部网络连边,较大程度的破坏网络的拓扑结构,导致删除后的网络可用性低的问题。使得本发明在选取最优路径的同时,有效保证了网络的结构属性,提高了社交网络的可用性。
第二,由于本发明使用最优路径起始节点到终端节点的所有路径长度为2n的无重复路径总数,计算起始节点到终端节点的网络信息接受度,克服了现有技术中引入额外的影响因子,增加了节点间关系的不确定性,不能准确描述节点间信任关系的问题。使得本发明在保证信任网络的完整度的同时,有效的提高了节点间网络信息的可靠性。
附图说明
图1为本发明的流程图;
图2为本发明的仿真实验结果图。
具体实施方式
下面结合附图对本发明做进一步的描述。
参照图1,对本发明实现的具体步骤做进一步的详细描述。
步骤1,建立信任网络图模型。
读入至少含有300个网络节点的数据集。
将所读入数据集的数据抽象为有向图。
所述的有向图为g1=(v,e),其中,v表示有向图g1中所有网络节点的集合,每个网络节点表示网络中的一个用户,e表示有向图g1中网络节点的边的集合,每条边表示网络中任意两个网络节点间的连线关系。
采用网络邻接矩阵生成方法,生成与有向图对应的邻接矩阵。
所述网络邻接矩阵生成方法的步骤如下:
第1步,生成一个元素均为0的n行n列的邻接矩阵,n表示网络中的网络节点的总数,按照网络节点的读取次序依次对其编号。
第2步,从有向图中任意选取未选过的两个网络节点,判断所选两个网络节点之间是否存在连接边,若是,则将邻接矩阵中与所选节点对应位置的元素置为1,否则,置为0。
第3步,判断是否选完有向图中的所有节点,若是,则邻接矩阵完成,否则,执行第二步。
步骤2,确定中间网络节点。
(2.1)分别建立一个用于存储后继节点的空栈、用于存储终端节点的空集合、用于存储网络节点的交集。
所述的交集是指,两个集合中是否存在结构相同的网络节点,若是,将结构相同的所有网络节点对应的任意一个集合中的所有网络节点放入一个空集合中,将该集合称为交集。
(2.2)从网络节点的数据集中随机选择一个未选过网络节点作为起始节点。
(2.3)将与起始节点有连边、且从未访问过的所有网络节点作为后继节点存入栈中。
(2.4)从栈中弹出一个后继节点。
(2.5)判断当前起始节点到当前弹出的后继节点的路径上的边数是否小于等于长度约束值,若是,将当前弹出的后继节点作为终端节点存入集合中,执行本步骤的(2.6),否则,将当前弹出的后继节点作为起始节点,执行本步骤的(2.3)。
所述的长度约束值是由下式计算得到的:
其中,∑表示求和操作,v1表示当前起始节点,v2表示当前弹出的后继节点,∈表示属于符号,v表示有向图g1中所有网络节点的集合,
(2.6)判断栈是否为空,若是,则得到一个网络集合,执行本步骤的(2.7),否则,执行本步骤的(2.4)。
(2.7)判断是否得到两个集合,若是,执行本步骤的(2.8),否则,执行本步骤的(2.1)。
(2.8)判断两个集合中是否存在结构相同的网络节点,若是,执行本步骤的(2.9),否则,将长度约束值加1后执行本步骤的(2.1)。
(2.9)将所有结构相同的网络节点对应的任意一个集合中的所有网络节点放入交集,从交集中随机选取一个网络节点,作为中间网络节点。
(2.10)将当前起始节点作为目标节点。
步骤3,选取最优路径。
(3.1)从交集中选择未选过的网络节点作为最优路径的起始节点,目标节点作为最优路径的终端结点。
(3.2)建立一个用于存储候选后继节点的空集合,建立一个用于存储最优路径节点的链表,建立一个用于存储路径的集合。
(3.3)将与最优路径的起始节点有连边、且从未访问过的网络节点作为候选后继节点,存入集合中。
(3.4)从集合中选取一个未选取过的候选后继节点。
所述的总权重值计算公式如下:
其中,t表示最优路径上的总权重值,∑表示求和操作,vm,vn分别表示集合中第m个候选后继节点和第n个候选后继节点,∈表示属于符号,v表示存储候选后继节点的集合,
(3.5)利用总权重值计算公式,计算路径从起始节点到所选后继节点的总权重值。
(3.6)按照下式,计算最优路径的经由所选后继节点到最优路径的终端节点的代价估计值:
f=g(·)+h(·)
其中,f表示最优路径的起始节点经由所选后继节点到最优路径的终端节点的代价估计值,g(·)表示从最优路径的起始节点到所选后继节点的代价值,h(·)表示当前所选后继节点到最优路径的终端节点的最优路径代价估计值。
(3.7)判断候选节点集合中的节点是否都被选取过,若是,执行本步骤的(3.7),否则,执行本步骤的(3.4)。
(3.8)从集合中选取起始节点到终端节点代价估计值中的最小值,将该最小值对应的后继节点作为最优路径中间节点存入链表中。
(3.9)判断存入链表中的最优路径中间节点是否为终端节点,若是,则将该链表放入存储路径的集合后执行本步骤的(3.10),否则,将当前候选后继节点作为最优路径的起始节点后执行本步骤的(3.3)。
(3.10)判断交集中是否存在未被选过的节点,若是,执行本步骤的(3.1),否则,得到一个存储路径的集合,执行步骤4。
步骤4,计算网络节点信息值。
按照下式,计算最优路径起始节点到终端节点的网络信息接受度:
其中,γ表示最优路径起始节点到终端节点的网络信息接受度,α表示网络信息传播可信度参数,zn表示存储路径集合中所有路径长度为n的路径总数,∑表示求和操作,s表示路径节点集合的一个子集合,
所述的路径节点集合是指,在存储路径的集合中,由所有路径的节点组成的集合。
按照下式,计算最优路径起始节点的连接状态比值:
其中,u表示最优路径起始节点的连接状态比值,t表示最优路径的起始节点,vn表示有向图中的第n个节点,∈表示属于符号,v表示存储候选后继节点的集合,
判断网络信息接受度是否大于等于连接状态比值,若是,执行步骤5,否则,执行步骤6。
步骤5,传播网络消息。
将最优路径的起始节点到终端节点的网络信息判定为可信度高信息,可以进行新一轮的信息传播。
步骤6,丢弃不可信的网络信息。
将起始节点到终端节点传递的网络信息判定为不可靠,丢弃该网络信息并终止信息传播。
本发明的效果可以通过以下仿真实验进一步说明:
1.仿真条件:
本发明的硬件测试平台是:处理器为intel(r)core(tm)i5-3470cpu@3.20ghz,内存为4.0gb,硬盘为500g;软件平台为:microsoftwindows7操作系统和python3.5。
2.仿真内容与仿真结果分析:
本发明的仿真实验是采用本发明的方法与现有技术的算法,分别在epinions网络上,从网络中随机的选择一部分节点连边,计算网络信息接受度,把起始节点的连接状态比值作为阈值,统计低于阈值的预测连边总数作为预测错误总数,将预测错误总数和选择的节点连边总数的比值作为预测错误率,用预测错误率作为实验结果,分别进行30次独立实验,取30次实验结果的平均值作为实验的仿真结果。
所述的现有技术为n.chen,j.wu等人发表的论文“去换路径算法及应用”(《硕博士论文》,2017,pages9–12)。
本发明的仿真实验的参数设置如下,epinions数据集包括50000个节点和487183个连边,每个连边都标记为信任或不信任。将信任解释为实际值1,并且将不信任解释为实际值0。在随机选择的过程中选择1500条边,网络信息传播可信度参数0.3,实验结果如图2所示。
图2中的横坐标表示路径长度约束的取值,纵坐标表示预测错误率,其中以十字标示的曲线表示采用本发明的方法的仿真结果曲线,以星星标示的曲线表示采用现有技术矩阵幂方法的仿真结果曲线。由图2可见,当横坐标的路径约束取值增大的过程中,本方法相较对比方法有了明显的提升。
综上所述,本发明采用基于长度约束和无重复路径的网络信息传播方法,使用信任网络图模型,在起始节点到终端节点的最优网络路径搜索过程中,既考虑了路径节点间权重值的影响,也保证了信任网络的结构属性不改变,利用路径代价估计值的方法确定路径的后继节点,并引入长度加倍操作,得到起始节点到终端节点间有长度约束的无重复路径总数,使用网络信息接受度判断节点间传播信息的真实性。本发明维护了网络结构的完整性,去除了节点间的循环路径,错误率有了明显的下降。
- 还没有人留言评论。精彩留言会获得点赞!