产生经修饰的仅有重链的抗体的转基因非人动物的制作方法
本申请包含序列表,该序列表已以ascii格式经由电子方式提交并且并据此以引用方式整体并入。所述ascii副本于2017年8月11日创建,被命名为tno-0001-wo_sl.txt,大小为26,401个字节。本发明涉及产生经修饰的仅有重链的抗体(hcab)的转基因非人动物。具体而言,本发明涉及产生聚集倾向降低的经修饰的人或嵌合hcab的转基因非人动物例如转基因大鼠或小鼠、这样制备的抗体及其制备和使用方法。
背景技术:
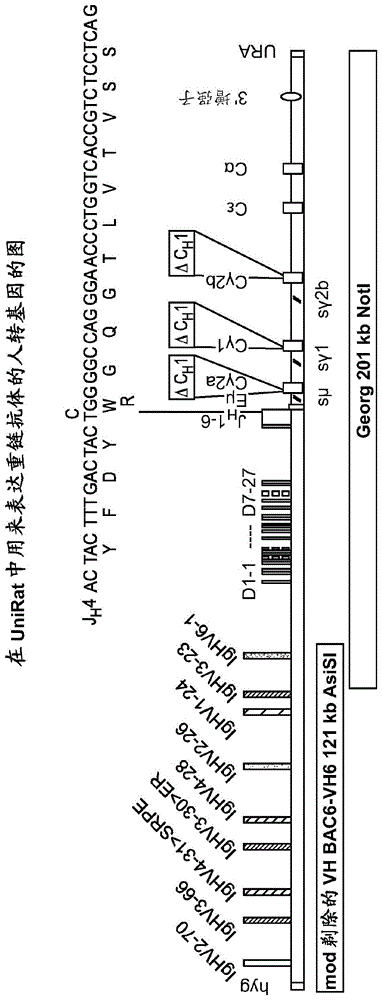
:仅有重链的抗体基本的四链抗体单元是由两条相同的轻(l)链和两条相同的重(h)链组成的异四聚体糖蛋白。就igg而言,4链单元通常为约150,000道尔顿。每条l链通过一个共价二硫键与h链连接,而两条h链根据h链同种型通过一个或多个二硫键彼此连接。每条h链和l链还具有规律间隔的链内二硫桥。每条h链在n-端具有可变结构域(vh),接着是α链和γ链各自的三个恒定结构域(ch),以及μ和ε同种型的四个ch结构域。每条l链在n-端具有可变结构域(vl),接着是在其另一端具有恒定结构域(cl)。vl与vh对齐并且cl与重链的第一恒定结构域(ch1)对齐。据信特定氨基酸残基会在轻链与重链可变结构域之间形成界面。vh和vl配对在一起形成单个抗原结合位点。igm抗体由5个基本异四聚体单元和称为j链的额外多肽组成,并因此含有10个抗原结合位点,而分泌的iga抗体可以聚合形成多价组装体,其包含2-5个基本4链单元以及j链。对于不同类别的抗体的结构和性质,参见例如basicandclinicalimmunology,第8版,danielp.stites,abbai.terr和tristramg.parslow(编),appleton&lange,norwalk,ct,1994年,第71页和第6章。在此类抗体中,vh和vl结构域的相互作用形成抗原结合区,但ch1结构域和部分cl结构域促进了结合。来自任何脊椎动物物种的l链可基于其恒定结构域的氨基酸序列而被分为两种截然不同的类型(称为κ和λ)中的一种。根据免疫球蛋白重链(ch)恒定结构域的氨基酸序列,可以将免疫球蛋白分为不同的类别或同种型。有五类免疫球蛋白:iga、igd、ige、igg和igm,其分别具有被命名为α、δ、ε、γ和μ的重链。基于ch序列和功能上相对小的差异,将γ和α的类别进一步分成亚类,例如,人表达以下亚类:igg1、igg2、igg3、igg4、iga1和iga2。在常规igg抗体中,重链和轻链的缔合部分是由于轻链恒定区和重链ch1恒定结构域之间的疏水相互作用。在重链框架2(fr2)区和框架4(fr4)区中存在另外的残基,所述残基也有助于重链和轻链之间的这种疏水相互作用。然而,已知骆驼科动物(包括骆驼、单峰骆驼和美洲驼的胼足亚目)的血清含有仅由成对的h链构成的主要类型的抗体(仅有重链的抗体或hcab)。骆驼科(camelidae)(单峰骆驼(camelusdromedarius)、双峰骆驼(camelusbactrianus)、大羊驼(lamaglama)、原驼(lamaguanaco)、羊驼(lamaalpaca)和小羊驼(lamavicugna))的hcab具有由单可变结构域(vhh)、铰链区和两个恒定结构域(ch2和ch3)组成的独特结构,所述两个恒定结构域与经典抗体的ch2和ch3结构域高度同源。这些hcab缺乏恒定区(ch1)的第一结构域,其存在于基因组中,但在mrna加工过程中被剪接掉。ch1结构域的缺乏解释了hcab中轻链的缺乏,因为该结构域是轻链恒定结构域的锚定场所。这些hcab天然进化以通过来自常规抗体或其片段的三个cdr来赋予抗原结合特异性和高亲和力(muyldermans,2001;jbiotechnol74:277-302;revets等人,2005;expertopinbiolther5:111-124)。软骨鱼类也进化出一种独特类型的免疫球蛋白,称为ignar,其缺乏轻多肽链并且完全由重链组成。20世纪60年代确定了无轻链、仅有重链的抗体结合抗原的能力(jaton等人(1968)biochemistry,7,4185-4195)。与轻链物理分离的重链免疫球蛋白相对于四聚体抗体保留了80%的抗原结合活性。sitia等人(1990)cell,60,781-790证明从重排的小鼠μ基因中去除ch1结构域导致在哺乳动物细胞培养物中产生无轻链、仅有重链的抗体。产生的抗体保留了vh结合特异性和效应子功能。骆驼科重链抗体的发现刺激了在人工系统(如噬菌体展示)中开发人单结构域抗体的兴趣。以这种方式鉴定的早期人结构域抗体易于聚集并且具有溶解性问题,这可能是由于框架区中暴露的疏水性补丁(hydrophobicpatch)通常埋在与轻链恒定区的界面中。阐明人vh结构域抗体的晶体结构的后续研究鉴定出人结构域抗体的表面暴露的残基。barthelemy等人(2008)j.biol.chem.,283,3639-3654报道了对有助于自主人vh结构域的稳定性和溶解性的因素的综合分析。经克隆且分离的vhh结构域是具有原始hcab的完全抗原结合能力的稳定多肽。纳米抗体(nanobody)是最小的可用完整抗原结合片段(约12-15kda),其具有已经进化的重链抗体的原始重链的完全抗原结合能力,所述重量抗体在没有轻链的情况下是完全有功能的。这些vhh结构域形成被称为纳米抗体的新一代治疗性抗体的基础,所述治疗性抗体适于静脉内、口服或局部施用,可以容易地制造成对一种或多种靶标表现出高效力和结合亲和力的单价或多价形式。单结构域vhh抗体,包括其制备方法,在例如wo2004062551中有描述。其中λ(lambda)轻链(l)链基因座和/或λ和κ(kappa)l链基因座已功能性沉默的小鼠和由此类小鼠产生的抗体在美国专利第7,541,513和8,367,888号中有描述。仅有重链的抗体在小鼠和大鼠中的重组产生,已经例如,在wo2006008548;美国申请公开第20100122358号;nguyen等人,2003,immunology;109(1),93-101;brüggemann等人,crit.rev.immunol.;2006,26(5):377-90;和zou等人,2007,jexpmed;204(13):3271-3283中进行了报道。在geurts等人,2009,science,325(5939):433中描述了通过锌指核酸酶的胚胎显微注射产生敲除大鼠。ménoret等人,2010,europeanjournalofimmunology,40:2932-2941报道了免疫球蛋白重链敲除大鼠的表征。美国专利第8,883,150号中描述了可溶性的仅有重链的抗体和包含产生此类抗体的异源重链基因座的转基因啮齿动物。包含单结构域抗体作为结合(靶向)结构域的car-t结构例如在iri-sofla等人,2011,experimentalcellresearch317:2630-2641和jamnani等人,2014,biochimbiophysacta,1840:378-386中进行了描述。尽管最近取得了进展,但仍需要用于产生具有较低聚集倾向并保持对其预期靶标的高亲和力的仅有重链的抗体的改进方法。技术实现要素:本发明至少部分基于以下发现:通过将仅有重链的抗体(hcab)的第四框架区(fr4)的第一位置处的天然氨基酸残基用能够破坏在所述位置处包含所述天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁的另一氨基酸残基,可以制备具有较低聚集倾向的hcab。此类疏水性补丁通常埋在与抗体轻链恒定区的界面中,但在hcab中变成是表面暴露的,并且至少部分地用于hcab的不希望的聚集和轻链缔合。一方面,本发明涉及一种分离的人的或嵌合的仅有重链的抗体(hcab),其包含含有互补决定区(cdr)和框架区(fr)的重链可变(vh)结构域,在不存在抗体轻链的情况下对靶抗原具有结合亲和力,其中在所述vh结构域中,所述hcab的第四框架区(fr4)的第一位置处的天然氨基酸残基被不同的氨基酸残基取代,所述不同的氨基酸残基能够破坏在所述位置处包含所述天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁。在一个实施方案中,hcab为人抗体。在另一个实施方案中,在hcab中,fr4的第一位置处的天然氨基酸残基被极性氨基酸残基取代。在另一个实施方案中,在hcab中,fr4的第一位置处的天然氨基酸残基被带正电荷的氨基酸残基诸如赖氨酸(k)、精氨酸(r)或组氨酸(h),优选精氨酸(r)取代。在一个特定实施方案中,hcab在第四框架(fr4)区中的第一氨基酸残基处包含色氨酸(w)到精氨酸(r)的取代。在所有实施方案中,hcab可以在一个或多个框架区中包含一个或多个其他突变。在所有实施方案中,hcab相对于在fr4中的第一氨基酸残基处包含天然氨基酸残基的对应抗体可具有降低的聚集倾向。在所有实施方案中,hcab可对其靶抗原具有约1pm至约1μm的结合亲和力。另一方面,本发明涉及一种分离的人的或嵌合的仅有重链的抗体(hcab),其在不存在抗体轻链的情况下对靶抗原具有结合亲和力,包含含有互补决定区(cdr)和框架区(fr)的重链可变(vh)结构域,其中所述hcab在天然人vh氨基酸序列的第四fr区(fr4)中的第一氨基酸位置处包含色氨酸(t)到精氨酸(r)的取代。在一个实施方案中,hcab还包含缺乏ch1区的重链恒定(ch)结构域,并且可以是igg抗体,例如igg1抗体。在另一个实施方案中,hcab在一个或多个fr区中包含一个或多个其他突变。在另一个实施方案中,hcab相对于在fr4中的第一氨基酸残基处包含天然氨基酸残基的对应抗体具有降低的聚集倾向。另一方面,本发明涉及嵌合抗原受体(car),其包含如本文所述的仅有重链的抗体。在一个实施方案中,car包含单一人vh结构域。另一方面,本发明涉及一种分离的自主人抗体重链可变(vh)结构域,其包含互补决定区(cdr)和框架区(fr),对靶抗原具有结合亲和力,包含不同氨基酸残基对于第四框架(fr4)区中的第一氨基酸残基处的天然氨基酸残基的取代,所述不同氨基酸残基能够破坏在所述位置处包含所述天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁。在一个实施方案中,在分离的自主人vh结构域中,fr4的第一位置处的天然氨基酸残基被极性氨基酸残基取代。在另一个实施方案中,fr4的第一位置处的天然氨基酸残基被带正电荷的氨基酸残基诸如赖氨酸(k)、精氨酸(r)或组氨酸(h)残基,优选精氨酸(r)残基取代。在另一个实施方案中,分离的自主人vh结构域在第四框架(fr4)区中的第一氨基酸残基处包含色氨酸(w)到精氨酸(r)的取代。在另一个实施方案中,分离的自主人vh结构域在一个或多个框架区中包含一个或多个其他突变。另一方面,本发明涉及一种多价结合蛋白,其含有多个抗原结合结构域,所述多个抗原结合结构域包括含有互补决定区(cdr)和框架区(fr)的至少一个人vh结构域,所述多价结合蛋白对靶抗原具有结合亲和力,其中在所述vh结构域中,所述多价结合蛋白的第四框架区(fr4)的第一位置处的天然氨基酸残基被不同的氨基酸残基取代,所述不同的氨基酸残基能够破坏在所述位置处包含所述天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁。在一个实施方案中,在多价结合蛋白中,fr4的第一位置处的天然氨基酸残基被极性氨基酸残基取代。在另一个实施方案中,在多价结合蛋白中,fr4的第一位置处的天然氨基酸残基被带正电荷的氨基酸残基诸如赖氨酸(k)、精氨酸(r)或组氨酸(h)残基,优选精氨酸(r)残基取代。在另一个实施方案中,多价结合蛋白在第四框架(fr4)区中的第一氨基酸残基处包含色氨酸(w)到精氨酸(r)的取代。在所有实施方案中,多价结合蛋白可以在一个或多个框架区中包含一个或多个其他突变。在另一个实施方案中,本发明涉及一种重组的仅有重链的免疫球蛋白(ig)基因座,其包含一个或多个人v基因区段、一个或多个人d基因区段和一个或多个人j基因区段,所述基因区段在非人动物的基因组中彼此重组时并且在亲和力成熟后编码包含互补决定区(cdr)和框架(fr)区的重链可变(vh)区,其中所述人j区段中的至少一个包含编码在第四框架区(fr4)的第一位置处的非天然氨基酸残基的密码子,所述非天然氨基酸残基能够破坏在所述位置处包含天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁。在一个实施方案中,重组的仅有重链的ig基因座还包含编码缺乏ch1功能的免疫球蛋白恒定效应区的恒定(c)区基因区段。在多个实施方案中,重组的仅有重链的ig基因座包含两个至40个d基因区段和/或两个至20个j基因区段。在另一个实施方案中,一个以上的人j区段包含编码在第四框架区(fr4)的第一位置处的非天然氨基酸残基的密码子,所述非天然氨基酸残基能够破坏在所述位置处包含天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁。在另一个实施方案中,在重组的仅有重链的ig基因座中,所有的人j区段包含编码在第四框架区(fr4)的第一位置处的非天然氨基酸残基的密码子,所述非天然氨基酸残基能够破坏在所述位置处包含天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁。在另一个实施方案中,在编码的重链vh区中,fr4的第一位置处的天然氨基酸残基被极性氨基酸残基,诸如赖氨酸(k)、精氨酸(r)或组氨酸(h),优选精氨酸(r)残基取代。在另一个实施方案中,编码的vh区在第四框架(fr4)区中的第一氨基酸残基处包含色氨酸(w)到精氨酸(r)的取代。在另一个实施方案中,重组的仅有重链的ig基因座包含j4基因区段,其中w的密码子被r的密码子置换。在所有实施方案中,重组的仅有重链的ig基因座编码vh区,所述vh区在一个或多个框架区中包含一个或多个其他突变。在另一个实施方案中,重组的仅有重链的ig基因座编码包含如上所述的vh区的人的或人源化的仅有重链的抗体。另一方面,本发明涉及包含如上所述的重组的仅有重链的ig基因座的转基因非人动物。在多个实施方案中,转基因非人动物是非人哺乳动物,如非人脊椎动物、啮齿动物、小鼠或大鼠,例如unirattm。另一方面,本发明涉及一种转基因非人动物,其不表达任何功能性免疫球蛋白轻链基因并且包含异源的仅有重链的ig基因座,所述异源的仅有重链的ig基因座包含一个或多个v基因区段、一个或多个d基因区段和一个或多个j基因区段,所述基因片段在彼此重组时并且在亲和力成熟后编码包含互补决定区(cdr)和构架区(fr)的vh结构域,其中所述vh结构域的第四框架区(fr4)的第一位置处的天然氨基酸残基被不同的氨基酸残基取代,所述不同的氨基酸残基能够破坏在所述位置处包含所述天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁,所述异源的仅有重链的ig基因座还包含一个或多个恒定效应区基因区段,每个恒定效应区基因区段编码包括ch1功能的抗体恒定效应区,其中所述基因区段排列成使得v、d和j基因区段和恒定区基因区段重组产生编码仅有重链的抗体(hcab)的重排的亲和力成熟的仅有重链的基因座。在一个实施方案中,在所述转基因非人动物的vh结构域中,fr4的第一位置处的天然氨基酸残基被极性氨基酸残基或带正电荷的氨基酸残,诸如赖氨酸(k)、精氨酸(r)或组氨酸(h)残基基,优选精氨酸(r)残基取代。在另一个实施方案中,在转基因非人动物中,vh结构域在第四框架(fr4)区中的第一氨基酸残基处包含色氨酸(w)到精氨酸(r)的取代。在另一个实施方案中,在转基因非人动物中,异源的仅有重链的基因座包含其中w的密码子被r的密码子置换的j4区段。在所有实施方案中,编码的仅有重链的抗体在一个或多个框架区中包含一个或多个其他突变。在另一个实施方案中,转基因非人动物为哺乳动物、脊椎动物、啮齿动物、小鼠或大鼠,例如unirattm。在所有方面,在某些实施方案中,本文的仅有重链的抗体在其他框架区(包括fr1、fr2和fr3区)中不含突变。在所有方面,在某些实施方案中,本文的仅有重链的抗体不含有通常存在于骆驼科动物(例如骆驼、美洲驼、单峰骆驼、羊驼或原驼)中的额外的框架突变。在所有方面,在某些实施方案中,本文的仅有重链的抗体可以在一个或多个框架区(包括fr1、fr2、fr3和/或fr4区),例如在fr2区或fr2和fr4区中包含一个或多个其他突变。在所有方面和实施方案中,本发明的hcab对其具有结合亲和力的靶抗原包括但不限于细胞表面受体和肿瘤抗原,例如egfr、erbb2(her2)、erbb3(her3)、erbb4(her4)、ctla-4/cd152、rankl、tnf-α、cd20、il-12/il-23、il1-β、il-17a、il-17f、cd38、ngf、igf-1、il-12、cd20、cd30、cd39、cd73、cd40、pd-1、pdl-1、pd-l2、bcma、btla、胸腺基质淋巴细胞生成素(tsp)、卵泡刺激激素受体(fshr)、前列腺特异性膜抗原(psma)、前列腺干细胞抗原(psca)、cd137、ox-40和il-33。在所有方面和实施方案中,hcab结合结构域可以是多特异性结合蛋白的一部分,所述结合结构域结合同一靶抗原的多个不同表位或一种以上靶抗原上的多个不同表位。具体地包括多特异性,例如双特异性hcab,包括例如具有以下结合亲和力的双特异性hcab结构:上皮细胞粘附分子(epcam)×cd3;cd19×cd3;epcam×cd3;tnf-αxil-17;il-1α×il-1β;cd30×cd16a;人表皮生长因子受体2(her2)×her3;il-4×il-13;血管生成素2(ang-2)×血管内皮生长因子a(vegf-a);因子ixa×因子x;表皮生长因子受体(egfr)×her3;il-17a×il-17f;her2×her3;癌胚抗原×cd3;cd20×cd3;cd123×cd3;bcma×cd3、psma×psca×cd3,psma×cd3,psca×cd3,cd19×cd22×cd3,cd22×cd3,cd38×pd1、cd38×pd-l1,cd38×cd73,cd38×cd39、pd1×cd39×cd73和pd1×cd73。附图说明图1是如实施例中所述,在unirattm中表达仅有重链的抗体的人转基因的图,所述人转基因的j4基因区段(seqidno:40)在位置101处表达r(seqidno:41)。图2是如实施例中所述,在unirattm中表达仅有重链的抗体的人转基因的图,所述人转基因的所有j区段(按照出现的顺序,分别为seqidno42-47)在位置101处均表达r。图3显示unirattm和omniflictm中的j基因使用,其中omniflictm是具有与unirattm相同的人v基因簇但表达固定κ轻链的转基因大鼠。图4说明仅有重链的人抗体中第四框架区(fr4)的第一氨基酸残基处的w→r突变抑制与λ轻链的缔合。图5是游离λ蛋白与相同cdr3族中的重链抗体的缔合。该图显示了来自相同cdr3族中的重链抗体的11个vh序列(按照出现的顺序,分别为seqidno48-58)的多序列比对。所有这些序列在位置101处均含有w。图6说明使用人vh胞外结合结构域的嵌合抗原受体的两种结构,使用本发明的仅有重链的人抗体比较scfvcar-t结构(图块a)和car-t结构(图块b)。图7显示了包含人vh结合结构域的多种多特异性hcab构建体。具体实施方式除非另有说明,否则本发明的实践将采用本领域技术范围内的分子生物学(包括重组技术)、微生物学、细胞生物学、生物化学和免疫学的常规技术。此类技术在文献中有全面解释,例如“molecularcloning:alaboratorymanual”,第二版(sambrook等人,1989);“oligonucleotidesynthesis”(m.j.gait编辑,1984);“animalcellculture”(r.i.freshney编辑,1987);“methodsinenzymology”(academicpress,inc.);“currentprotocolsinmolecularbiology”(f.m.ausubel等人编辑,1987,及定期更新);“pcr:thepolymerasechainreaction”,(mullis等人编辑,1994);“apracticalguidetomolecularcloning”(perbalbernardv.,1988);“phagedisplay:alaboratorymanual”(barbas等人,2001)。本文引用的所有参考文献,包括专利申请和出版物,均通过引用整体并入。i.定义如本文所用,如本文所定义的“转基因非人动物”是能够产生人的或人源化的仅有重链的抗体的非人动物,其中第四框架区(fr4)的第一位置处的氨基酸残基被另一种能够破坏包含此类残基或与其缔合的表面暴露的疏水补片的残基取代。在一个实施方案中,天然氨基酸残基被带电荷的氨基酸残基,例如带正电荷的氨基酸残基取代。转基因非人动物优选为哺乳动物,包括但不限于大鼠、小鼠、牛、猴、猪、绵羊、山羊、兔、狗、猫、豚鼠、仓鼠等。优选地,转基因非人动物为啮齿动物,优选大鼠或小鼠,最优选unirattm。转基因动物的选择仅受限于产生具有本文所述fr4突变的人的或嵌合的仅有重链的人或嵌合抗体的能力。如本文所用,“遗传修饰”是非人动物基因序列的一个或多个改变。非限制性实例是将转基因插入转基因动物的基因组中。如本文所用,术语“转基因”是指含有启动子、报告基因、多腺苷酸化信号和其他增强表达的元件(隔离子、内含子)的外源dna。该外源dna整合到单细胞胚胎的基因组中,由该胚胎发育转基因动物,并且转基因留在成熟动物中的基因组中。整合的转基因dna可以出现在卵或小鼠基因组中的单个或多个位置,并且转基因的单个至多个(数百个)串联拷贝可以整合在每个基因组位置。“常规抗体”通常为由两条相同的轻(l)链和两条相同的重(h)链组成约150,000道尔顿的异四聚体糖蛋白。每条轻链通过一个共价二硫键与重链连接,而二硫连键的数量在不同免疫球蛋白同种型的重链之间不同。每条重链和轻链还具有规律间隔的链内二硫桥。每条重链在一端具有可变结构域(vh),接着是许多恒定结构域。每条轻链在一端具有可变结构域(vl),并且在另一端具有恒定结构域;轻链的恒定结构域与重链的第一恒定结构域对齐,并且轻链可变结构域与重链的可变结构域对齐。据信特定氨基酸残基会在轻链与重链可变结构域之间形成界面。本文的抗体残基根据kabat编号系统编号(例如,kabat等人,sequencesofimmunologicalinterest.第5版publichealthservice,nationalinstitutesofhealth,bethesda,md.(1991))。根据该编号,fr4区的第一氨基酸残基位于氨基酸位置101处。术语“可变”是指可变结构域的某些部分在抗体之间的序列差异很大,并且用于每种特定抗体对其特定抗原的结合和特异性。然而,变异性不是均匀地分布在抗体的可变结构域中。其集中在轻链和重链可变结构域中称为互补决定区(cdr)或高变区的三个区段中。可变结构域更高度保守的部分称为框架(fr)。天然重链和轻链的可变结构域各自包含四个fr区,主要采用β-折叠构型,通过三个cdr连接,这三个cdr形成连接并且在一些情况下形成β-折叠结构的一部分的环。每条链中的cdr通过fr区紧密靠近在一起,并与来自另一条链的cdr一起促成抗体的抗原结合位点的形成(参见kabat等人,nihpubl.第91-3242期,第1卷,第647-669页(1991))。恒定结构域不直接参与抗体与抗原的结合,但表现出各种效应子功能,例如抗体参与抗体依赖性细胞毒性。如本文所用,术语“单克隆抗体”是指从基本上同源的抗体群获得的抗体,即除了可能少量存在的可能天然存在的突变之外,构成该群的单个抗体是相同的。单克隆抗体针对单个抗原位点具高度特异性。此外,与通常包括针对不同决定簇(表位)的不同抗体的常规(多克隆)抗体制剂相反,每种单克隆抗体针对抗原上的单个决定簇。术语“仅有重链的抗体”、“重链抗体”和“hcab”可互换使用,并且在最广泛的意义上是指缺乏常规抗体的轻链的抗体。因为同源二聚体hcab缺乏轻链并因此缺乏vl结构域,因此抗原被单个结构域识别,即重链抗体重链的可变结构域(当指的是骆驼重链可变结构域时,是vh或vhh)。该术语具体包括但不限于包含vhh抗原结合结构域及ch2和ch3恒定结构域的同型二聚体抗体或不存在ch1结构域的骆驼抗体;此类抗体的功能性(抗原结合)变体、可溶性vh变体,包含一个可变结构域(v-nar)和五个c样恒定结构域(c-nar)的同型二聚体的ig-nar及其功能片段;和可溶性单结构域抗体(sdab)或纳米抗体。本发明的仅有重链的抗体包含至少一个重链可变(vh)结构域,其中fr4的第一位置处的氨基酸残基(根据kabat编号为氨基酸残基101)被另一个能够破坏包含此类残基或与其缔合的表面暴露的疏水性补丁的残基取代。在一个实施方案中,天然氨基酸残基被带电荷的氨基酸残基,例如带正电荷的氨基酸残基取代。本发明的仅有重链的抗体优选为人或嵌合抗体,优选在氨基酸位置101处包含trp(w)到arg(r)的突变(w101r突变)。在一个实施方案中,本文的仅有重链的抗体用作嵌合抗原受体(car)的结合(靶向)结构域。在最广泛的意义上,术语“可溶性单结构域抗体(sdab)”用于指在不存在恒定结构域的情况下包含重链抗体或常规igg的重链可变结构域的多肽。sdab基本结构通常由被三个互补决定区(cdr1-cdr3)中断的四个框架区(fr1-fr4)组成。因此,sdab可用以下结构表示:fr1-cdr1-fr2-cdr2-fr3-cdr3-fr4。关于进一步的综述,参见,holt等人,″domainantibodies:proteinsfortherapy″trendsinbiotechnology(2003):第21卷,第11期:484-490。本发明的抗体包括多特异性抗体。多特异性抗体具有一种以上的结合特异性。术语“多特异性”具体包括“双特异性”和“三特异性,”以及更高级别的独立特异性结合亲和力,例如更高级的多表位特异性,以及四价抗体和抗体片段。术语“多特异性抗体”、“仅有单链的多特异性抗体”和“多特异性hcab”在本文中在最广义上使用,并涵盖具有一种以上结合特异性的所有抗体。如本文所用的术语“价”是指抗体分子中指定的结合位点数量。“多价”抗体具有两个或更多个结合位点。因此,术语“二价”、“三价”和“四价”分别指存在两个结合位点、三个结合位点和四个结合位点。根据本发明的双特异性抗体至少是二价的并且可以是三价的、四价的或其他多价的。本发明的多特异性的仅有单链的抗体,例如双特异性抗体,包括多价的仅有单链的抗体。术语“嵌合抗原受体”或“car”在本文中在最广义上使用,是指工程化受体,其将所需的结合特异性(例如单克隆抗体或其他配体的抗原结合区)移植至跨膜结构域和胞内信号传导结构域。通常,该受体用于将单克隆抗体的特异性移植到t细胞上以产生jnatlcancerinst,2015;108(7):dvj439;和jackson等人,naturereviewsclinicaloncology,2016;13:370-383。包含人vh胞外结合结构域的代表性car-t构建体示于图6中。所谓“重组免疫球蛋白(ig)基因座”意指缺乏一部分内源ig基因座和/或包含不是受试哺乳动物ig基因座内源的至少一个片段的ig基因座。此类片段可以是人或非人的,并且可以包括任何ig基因区段或其部分,或者可以构成整个ig基因座。重组ig基因座优选是能够进行基因重排并在转基因动物中产生免疫球蛋白库的功能基因座。重组ig基因座包括重组ig轻链基因座和重组ig重链基因座。一旦并入宿主的基因组中,人工ig基因座就可被称为重组ig基因座。所谓“转基因抗体”意指由重组ig基因座编码并且由包含根据本发明的重组ig基因座的转基因非人哺乳动物产生或以其他方式源自所述转基因非人哺乳动物的抗体。源自受试转基因哺乳动物的转基因抗体包括使用从受试转基因动物获得的分离的细胞或核酸,或使用源自从受试转基因动物获得的分离的细胞或核酸的细胞或核酸所产生的转基因抗体。在优选的实施方案中,转基因抗体包含由整合的供体多核苷酸或其部分编码的氨基酸序列。如本文所用的术语“ig基因区段”是指编码ig分子的不同部分的dna区段,其存在于非人类动物和人的种系中,并且在b细胞中聚集在一起以形成重排的ig基因。因此,如本文所用的“ig基因区段”可指v基因区段、d基因区段。j基因区段和c区基因,及其部分。如本文所用的术语“人ig基因区段”包括人ig基因区段的天然存在序列,人ig基因区段的天然存在序列的简并形式,以及编码与人ig基因区段的天然存在序列所编码的多肽基本上相同的多肽序列的合成序列。所谓“基本上”意指氨基酸序列同一性程度为至少约85%-95%。优选地,氨基酸序列同一性程度高于90%,更优选高于95%。如本文所定义的术语“仅有重链的基因座”是指编码vh结构域的基因座,其中抗体fr4区的第一氨基酸残基带正电荷,所述基因座包含一个或多个v基因区段、一个或多个d基因区段和一个或多个j基因区段,任选与一个或多个重链效应区基因区段连接,每个区段编码缺乏ch1结构域功能的抗体恒定效应区。优选地,仅有重链的基因座包含约五个至约二十个v基因片段,约两个至约40个d基因片段,和约两个至约二十个j基因片段,其中v/d/j片段优选是人来源的。术语“d基因区段”和“j基因区段”在其范围内还包括其衍生物、同源物和片段,只要所得区段可以与本文所述的重链抗体基因座的其余组分重组产生仅有重链的抗体。d和j基因区段可以源自天然存在的来源,或者它们可以使用本领域技术人员熟悉的和本文描述的方法合成。在一个实施方案中,在j4基因区段中,w的密码子(tgg)被r的密码子(cgg)置换,以在fr4的第一氨基酸位置处(按照kabat编号,仅有重链的抗体的位置101)编码r而不是w。d和j基因区段可以并入限定的附加氨基酸残基或限定的氨基酸取代或缺失的密码子以增加cdr3多样性。术语“v基因区段”涵盖源自非人动物,例如非人哺乳动物(例如啮齿动物),经工程改造以在fr4区的第一个残基处引入带正电荷的氨基酸残基的天然存在的v基因区段。“v基因区段”必须能够与d基因区段、j基因区段和重链恒定区重组,将ch1外显子排除在外,以在表达核酸时产生本文的仅有重链的抗体。所谓“人独特型”意指存在于人抗体上的免疫球蛋白重链和/或轻链可变区中的多肽序列表位。如本文所用的术语“人独特型”包括天然存在的人抗体序列,以及与天然存在的人抗体中发现的多肽基本相同的合成序列。所谓“基本上”意指氨基酸序列同一性程度为至少约85%-95%。优选地,氨基酸序列同一性程度高于90%,更优选高于95%。所谓“嵌合抗体”或“嵌合免疫球蛋白”意指包含来自至少两个不同ig基因座的氨基酸序列的免疫球蛋白分子,例如包含由人ig基因座编码的部分和由大鼠ig基因座编码的部分的转基因抗体。嵌合抗体包括具有非人fc区或人工fc区和人独特型的转基因抗体。此类免疫球蛋白可以从已经工程改造为产生此类嵌合抗体的本发明的动物中分离。“结合亲和力”是指分子(例如,抗体)的单个结合位点与其结合伴侣(例如,抗原)之间非共价相互作用的总和强度。除非另有说明,否则如本文所用,“结合亲和力”是指内在结合亲和力,其反映结合对成员(例如,抗体和抗原)之间的1∶1相互作用。分子x对其伴侣y的亲和力通常可用解离常数(kd)表示。本发明的hcab的kd通常在约1pm至约1μm之间例如,kd可为约200nm、150nm、100nm、60nm、50nm、40nm、30nm、20nm、10nm、8nm、6nm、4nm、2nm、1nm或更强。亲和力可以通过本领域已知的常用方法测量。低亲和力抗体通常缓慢地结合抗原并且倾向于容易解离,而高亲和力抗体通常更快地结合抗原并且倾向于保持。如本文所用,“kd”或“kd值”是指通过使用表面等离子体共振测定测量的解离常数,例如,使用biacoretm-2000或biacoretm-3000(biacore,inc.,piscataway,n.j.)在25℃下用固定的抗原cm5芯片以约10个反应单位(ru)进行测量。有关详细信息,请参见例如,chen等人,j.mol.biol.293:865-881(1999)。“表位”是抗原分子表面上与单个抗体分子结合的位点。通常,抗原具有几个或许多个不同的表位并与许多不同的抗体反应。该术语具体包括线性表位和构象表位。“多表位特异性”是指特异性结合相同或不同靶标上的两个或更多个不同表位的能力。当两种抗体识别相同的或空间上重叠的表位时,抗体与参考抗体结合“基本上相同的表位”。使用最广泛且快速的用于确定两个表位是否与相同的或空间上重叠的表位结合的方法是竞争测定,竞争测定可以使用标记抗原或标记抗体以所有数量的不同形式配置。通常,将抗原固定在96孔板上,并使用放射性或酶标记来测量未标记抗体阻断标记抗体结合的能力。“表位作图”是鉴定抗体在其靶抗原上的结合位点或表位的过程。抗体表位可以是线性表位或构象表位。线性表位由蛋白质中连续的氨基酸序列形成。构象表位由蛋白质序列中不连续的,但在将蛋白质折叠成其三维结构时聚集在一起的氨基酸形成。如本文中所用的“肿瘤”是指所有肿瘤细胞生长和增殖,无论恶性还是良性,以及所有癌前和癌性细胞和组织。术语“肿瘤”包括实体瘤和血液癌症。术语“癌症”和“癌”是指或描述通常特征在于细胞生长不受调控的哺乳动物的生理状况。癌症的实例包括但不限于癌、淋巴瘤、母细胞瘤、肉瘤和白血病。更具体的癌症实例包括乳腺癌、胃癌、鳞状细胞癌、成胶质细胞瘤、宫颈癌、卵巢癌、肝脏癌、膀胱癌、肝细胞瘤、结肠癌、结直肠癌、子宫内膜癌、唾液腺癌、肾脏癌、肾癌、前列腺癌、外阴癌、甲状腺癌、肝癌、头颈癌、直肠癌、结直肠癌、肺癌(包括小细胞肺癌、非小细胞肺癌、肺腺癌和肺鳞癌)、鳞状细胞癌(例如上皮鳞状细胞癌)、前列腺癌、腹膜癌、肝细胞癌、胃癌或胃部癌(包括胃肠癌)、胰腺癌、成胶质细胞瘤、视网膜母细胞瘤、星形细胞瘤、泡膜细胞瘤、卵巢男性母细胞瘤、肝细胞瘤、恶性血液病(包括非霍奇金淋巴瘤(non-hodgkinslymphoma,nhl)、多发性骨髓瘤和急性恶性血液病)、子宫内膜癌或子宫癌、子宫内膜异位、纤维肉瘤、绒毛膜癌、唾液腺癌、外阴癌、甲状腺癌、食管癌、肝癌、肛门癌、阴茎癌、鼻咽癌、喉癌、卡波西肉瘤(kaposi′ssarcoma)、黑素瘤、皮肤癌、许旺氏细胞瘤(schwannoma)、少突神经胶质瘤、神经母细胞瘤、横纹肌肉瘤、骨源性肉瘤、平滑肌肉瘤、泌尿道癌、甲状腺癌、维尔姆斯瘤(wilm′stumor)以及b细胞淋巴瘤(包括低级/滤泡性非霍奇金淋巴瘤(nhl);小淋巴细胞性(sl)nhl;中级/滤泡性nhl;中级弥漫性nhl;高级免疫母细胞性nhl;高级淋巴细胞性nhl;高级小型非核裂细胞nhl;巨大肿块性nhl;套细胞淋巴瘤;aids相关淋巴瘤;和华氏巨球蛋白血症(waldenstrom′smacroglobulinemia));慢性淋巴细胞性白血病(cll);急性淋巴细胞性白血病(all);毛细胞白血病;慢性成髓细胞白血病;和移植后淋巴组织增生性病症(ptld),以及与斑痣性错构瘤病(phakomatoses)和麦格综合征(meigs′syndrome)相关的异常血管增生。ii.详述本发明的hcab是人的或嵌合的,其在fr4区的第一位置(根据kabat编号系统为氨基酸位置101)处的天然氨基酸残基被能够破坏在所述位置处包含所述天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁的另一氨基酸残基取代。此类疏水性补丁通常埋在与抗体轻链恒定区的界面中,但在hcab中变成是表面暴露的,并且至少部分地用于hcab的不希望的聚集和轻链缔合。取代的氨基酸残基优选带电荷,更优选带正电荷。所得hcab优选在生理条件下在没有聚集的情况下具有高抗原结合亲和力和溶解度。具体包括缺乏骆驼科vhh框架和突变及其功能性vh区的仅有重链的抗体。此类仅有重链的抗体可以,例如,在转基因大鼠或小鼠中产生,所述转基因大鼠或小鼠包含例如wo2006/008548中所述的仅有重链的全人基因座,但也可以使用其他转基因哺乳动物,例如兔、豚鼠、大鼠,优选大鼠和小鼠。也可以通过重组dna技术,通过在合适的真核或原核宿主(包括大肠杆菌(e.coli)或酵母)中表达编码核酸,产生仅有重链的抗体,包括其vhh或vh功能片段。仅有重链的抗体的结构域结合了抗体和小分子药物的优点:可为单价的或多价的;具有低毒性;并且可成本有效地制造。由于其尺寸小,这些结构域易于施用,包括口服或局部施用,其特征在于稳定性高,包括胃肠稳定性;并且其半衰期可以根据所需的用途或指示进行定制。另外,hcab的vh和vhh结构域可以以成本有效的方式制造。在一个实施方案中,hcab的结构域是如上文所定义的纳米抗体。在一个实施方案中,hcab结合结构域可以是多特异性结合蛋白的一部分,所述结合结构域结合同一靶抗原的多个不同表位或一种以上靶抗原上的多个不同表位。在一个实施方案中,抗体为双特异性抗体。图7中说明了包含人vh结合结构域的多种多特异性结构。本发明的多特异性或双特异性hcab可以例如结合相同可溶性靶标上的两个或更多个位点,或同一细胞表面(受体)靶标(例如肿瘤抗原)上的两个或更多个位点,或一种或多种可溶性靶标和一种或多种细胞表面受体靶标。在某些实施方案中,本文的双特异性hcab结构具有以下结合亲和力:上皮细胞粘附分子(epcam)×cd3;cd19×cd3;epcam×cd3;tnf-αxil-17;il-1α×il-1β;cd30×cd16a;人表皮生长因子受体2(her2)×her3;il-4×il-13;血管生成素2(ang-2)×血管内皮生长因子a(vegf-a);因子ixa×因子x;表皮生长因子受体(egfr)×her3;il-17a×il-17f;her2×her3;癌胚抗原×cd3;cd20×cd3;cd123×cd3;bcma×cd3、psma×psca×cd3,psma×cd3,psca×cd3,cd19×cd22×cd3,cd22×cd3,cd38×pd1、cd38×pd-l1,cd38×cd73,cd38×cd39、pd1×cd39×cd73和pd1×cd73。在一个优选的实施方案中,本文的hcab由转基因动物产生,包括转基因小鼠和大鼠,优选大鼠,其中内源免疫球蛋白基因被敲除或禁用。在一个优选的实施方案中,本文的hcab在unirattm中生产。unirattm使其内源性免疫球蛋白基因沉默,并使用人免疫球蛋白重链转基因座(translocus)来表达多样化的、经天然优化的全人hcab库。虽然大鼠中的内源性免疫球蛋白基因座可以使用多种技术来敲除或使其沉默,但在unirattm中,使用锌指(内切)核酸酶(znf)技术来使内源性大鼠重链j基因座、轻链cκ基因座和轻链cλ基因座失活。用于显微注射到卵母细胞中的znf构建体可产生igh和igl敲除(ko)品系。有关详细信息,请参见geurts等人,2009,science325:433ig重链敲除大鼠的表征已由menoret等人,2010,eur.j.immunol.40:2932-2941进行了报道。znf技术的优点是非同源末端接合以通过多达几kb的缺失使基因或基因座沉默也可以提供用于同源整合的靶位点(cui等人,2011,natbiotechnol29:64-67。unirattmhcab结合不能用常规抗体攻击的表位。它们的高特异性、亲和力和小尺寸使其对于单特异性和多特异性应用而言很理想。在本发明的仅有重链的抗体中,第四框架区(fr4)的第一位置处的天然氨基酸残基被不同的氨基酸残基取代,所述不同的氨基酸残基能够破坏在所述位置处包含所述天然氨基酸残基或与所述天然氨基酸残基缔合的表面暴露的疏水性补丁。在一个实施方案中,取代的氨基酸残基是带电荷的。在另一个实施方案中,取代的氨基酸残基带正电荷,例如赖氨酸(lys,k)、精氨酸(arg,r)或组氨酸(his,h),优选精氨酸(r)。如图5的比对中所示,来自相同cdr3族中的重链抗体的vh序列在位置101处全部含有trp(w),因此在优选的实施方案中,源自本发明的转基因动物的仅有重链的抗体在位置101处含有trp到arg的突变。本发明的人的或嵌合的仅有重链的抗体可以针对任何预期靶抗原产生并且具有用于多种临床应用的巨大潜力。用于治疗应用的靶抗原包括但不限于egfr、erbb2(her2)、erbb3(her3)、erbb4(her4)、ctla-4/cd152、rankl、tnf-α、cd20、il-12/il-23、il1-β、il-17a、il-17f、cd38、ngf、igf-1、il-12、cd20、cd30、cd39、cd73、cd40、pd-1、pdl-1、pd-l2、bcma、btla、胸腺基质淋巴细胞生成素(tsp)、卵泡刺激激素受体(fshr)、前列腺特异性膜抗原(psma)、前列腺干细胞抗原(psca)、cd137、ox-40和il-33。治疗适应症包括但不限于治疗实体瘤、血液肿瘤、炎性疾病(例如类风湿性关节炎)、银屑病、克罗恩病(crohn’sdisease)、溃疡性结肠炎、代谢紊乱、心血管疾病、呼吸疾病、皮肤病、中枢神经系统疾病、血液疾病、眼/耳疾病、肝脏疾病。靶肿瘤包括例如乳腺癌、胃癌、鳞状细胞癌、成胶质细胞瘤、宫颈癌、卵巢癌、肝脏癌、膀胱癌、肝细胞瘤、结肠癌、结直肠癌、子宫内膜癌、唾液腺癌、肾脏癌、肾癌、前列腺癌、外阴癌、甲状腺癌、肝癌、头颈癌、直肠癌、结直肠癌、肺癌(包括小细胞肺癌、非小细胞肺癌、肺腺癌和肺鳞癌)、鳞状细胞癌(例如上皮鳞状细胞癌)、前列腺癌、腹膜癌、肝细胞癌、胃癌或胃部癌(包括胃肠癌)、胰腺癌、成胶质细胞瘤、视网膜母细胞瘤、星形细胞瘤、泡膜细胞瘤、卵巢男性母细胞瘤、肝细胞瘤、恶性血液病(包括非霍奇金淋巴瘤(nhl)、多发性骨髓瘤(mm)和急性恶性血液病)、子宫内膜癌或子宫癌、子宫内膜异位、纤维肉瘤、绒毛膜癌、唾液腺癌、外阴癌、甲状腺癌、食管癌、肝癌、肛门癌、阴茎癌、鼻咽癌、喉癌、卡波西肉瘤、黑素瘤、皮肤癌、许旺氏细胞瘤、少突神经胶质瘤、神经母细胞瘤、横纹肌肉瘤、骨源性肉瘤、平滑肌肉瘤、泌尿道癌、甲状腺癌、维尔姆斯瘤以及b细胞淋巴瘤(包括低级/滤泡性非霍奇金淋巴瘤(nhl);小淋巴细胞性(sl)nhl;中级/滤泡性nhl;中级弥漫性nhl;高级免疫母细胞性nhl;高级淋巴细胞性nhl;高级小型非核裂细胞nhl;巨大肿块性nhl;套细胞淋巴瘤;aids相关淋巴瘤;和华氏巨球蛋白血症);慢性淋巴细胞性白血病(cll);急性淋巴细胞性白血病(all);毛细胞白血病;慢性成髓细胞白血病;和移植后淋巴组织增生性病症(ptld),以及与斑痣性错构瘤病和麦格综合征相关的异常血管增生。通过以下非限制性实施例来说明本发明的进一步的详细内容,实施例使用以下缩写:bac细菌人工染色体yac酵母人工染色体zfn锌指核酸酶h重链c恒定区v可变区d多样性区段j接合区段实施例实施例1:表达仅有重链的抗体(hcab)的基因工程改造的大鼠的产生此前已鉴定、表征和部分修饰的bac和yac适应人重链可变区基因和大鼠恒定区基因(osborn等人,2013,j.immunol.190:1481-1490;ma等人,2013,j.immunol.methods400-401:78-86)。为了实现重链抗体表达,通过cμ的去除及所有cγ中ch1外显子的缺失来修饰大鼠恒定区bac。然后通过内源性重链和轻链(κ和λ)基因座的沉默来强制执行仅有重链的表达。yac和bac上经修饰的人igh基因座的构建。“人-大鼠”igh分若干部分进行构建和组装。这涉及对大鼠c区基因进行修饰并将其接合在人jh的下游,然后在上游添加人vh6-d区段区。然后将具有独立人vh基因簇的两种bac[bac6和bac3]与被称为georg的bac共同注射,被称为georg的bac编码包含人vh6-全部d-全部jh-大鼠cγ2a/1/2b(δch1)的经组装和修饰的区。为了在dna序列的精确位置引入修饰并同时接合多个大的dna区,开发了将酿酒酵母(s.cerevisiae)中具有重叠末端的序列组装为环状yac(cyac),随后将此类cyac转化为bac的技术。yac的优点包括其保留大的dna插入物的能力,在酵母宿主中易于同源改变以及尤其在高度重复区(例如转换区、增强子)中维持序列稳定性。另一方面,在大肠杆菌中增殖的bac提供了易于制备和高产量的优点。另外,与yac相比,可通过bac更好地实现详细的限制性内切酶谱和序列分析。构建两种自我复制型酿酒酵母/大肠杆菌穿梭载体,即pbelo-cen-ura和pcau。简言之,将酿酒酵母cen4从pyac-rc切割为avrii片段(marchuk和collins,1988;nucleicacidsres.16(15):7743)并连接到spei线性化pap599(ma等人,molmicrobiol.2007;66(1):14-25)。所得质粒含有在ura3下游克隆的cen4。由此,切下apali-bamhiura3-cen4片段,并连接到apali和bamhi消化的pbacbelo11(newenglandbiolabs)上,得到pbelo-cen-ura。合成酿酒酵母自主复制序列ars209并克隆到pbelo-cen-ura中的独特sexai位点以得到pcau。为了促进人jh4、大鼠cμ和cγ1区的修饰,从bac构建体annabel上切下从人jh上游~2.2kb跨越至大鼠cγ1编码区下游~5.5kb的~37kbsacii-片段(osbom等人,2013;j.immunol.190:1481-1490)并克隆到pbelo-cen-ura[pbelo+sacii,37kb]中的独特sacii位点。另外,为了修饰大鼠cγ2b区,将来自annabel的从γ2b转换区上游~6.9kb跨越到cγ2b编码区下游~2.0kb的~19kbsacii-swai片段克隆到sacii和hpai双重消化的pbelo-cen-ura[pbelo+sacii-swai,19kb]中。两种质粒均用作扩增各种人和大鼠基因组区的模板并用于建立所需的限制性片段。从人jh上游~3.1kb跨越并且包括具有一些3′区的大鼠cμ的dna区经修饰并作为16.7kbsnabi-fspi片段组装在pcau中。经修饰区包括所有真实人jh,不同的是将t→c点突变引入jh4(导致w→r氨基酸变化),接着是从jh直至μch1的大鼠基因间区,该基因间区与cμ编码区的其余部分一起缺失,并且被缺乏ch1的大鼠cγ2a序列精确取代(从紧邻铰链上游的内含子开始到膜外显子的3′端)。该构建体通过将酵母中的以下5个重叠片段组装为cyac而获得,然后转化成bac:使用引物hc27-1和-2扩增的覆盖人jh上游区到突变的jh4(用表示的通过后一种引物引入的点突变)的~4.3kb片段;使用引物hc27-3和-4扩增的从突变的jh4(用表示)跨越到μ转换区上游的~3.4kb片段;涵盖μ转换区和从pbelo+sacii37kb切下的旁侧序列的~5.2kbaflii片段;使用长引物hc27-5和-6扩增的缺乏与大鼠cμ旁侧序列融合的ch1的大鼠cγ2a;以及使用引物hc27-7和-8扩增的pcau载体。这样产生pcau+huj-ratcγ2a(-ch1)。通过测序检查所有经修饰区以确认准确性。通过pcr分别产生缺乏ch1的大鼠cγi和缺乏ch1的cγ2b。使用引物hc27-9和-10扩增紧邻位于cγ1编码区上游的~1.7kb片段,其3′尾与ch1和铰链之间的内含子的5′端匹配。使用引物hc27-11和-12将cγ1扩增为从ch1和铰链之间的内含子到编码区3′端的~3.9kb片段。随后,将~1.7kb和~3.9kb片段均进行凝胶纯化并使用引物hc27-9和-12通过重叠pcr接合以得到~5.6kb片段。类似地,对于无ch1的cγ2b,使用引物hc27-13和-14扩增cγ2b编码区上游的~0.3kb片段,并使用引物hc27-15和-16扩增跨越从ch1和铰链之间的内含子到编码区的3’端的区域的~5.4kb片段,随后使用引物hc27-13和-16通过重叠pcr接合这两个片段以得到~5.7kb片段。将pcau+大鼠cγ1,2b(-ch1)构建为含有以下各项:与大鼠cμ的3’端匹配的100bp同源区,接着是基因组构型中的cγ1和cγ2b,不同的是两者的ch1缺失。使用六个重叠片段构建pcau+大鼠cγ1,2b(-ch1):跨越3’cμ同源区,接着是从pbelo+sacii(37kb)切下的γ1转换区的~10.2kbspei-nari片段;含有如上所述无ch1的cγ1的~5.6kbpcr片段;使用引物hc27-17和-18扩增的覆盖cγ1和cγ2b之间的基因间区的~7.4kb片段;涵盖从pbelo+sacii-swai19kb切下的大鼠cγ2b转换区的~11.3kbxhoi片段;含有无ch1的cγ2b的~5.7kbpcr片段;及使用引物hc27-19和-20扩增的pcau载体。可以将pcau+大鼠cγ1,2b(-ch1)中的大鼠基因组区切下作为单个~40kbfspi片段。最后,使用以下四个重叠片段组装编码具有所有修饰的人vh6-d-jh-大鼠c区的bac(georg):涵盖从bac10(ctd-3216m13,invitrogen)切下的人vh6-d区的纯化~78.2kbfspai-mlui片段,从如上所述的pcau+huj-大鼠cγ2a(-ch1)上切下的16.7kbsnabi-fspi片段,从pcau+大鼠cγ1,2b(-ch1)切下的~40kbfspi片段,和从构建体annabel上切下的纯化~77.2kbswai-sacii片段,构建体annabel包括cγ2b和cε之间的基因间区,接着是cε、cα、3′增强子区、pbelo-cen-ura载体和人vh6上游的5′区。通过限制性内切酶谱和部分测序来深入检查该最终构建体。(人vh6-d-jh-大鼠c)区可以切下并纯化作为~201kbnoti片段。bac6含有从vh4-39至vh3-23的人基因组区,而bac3含有从vh3-11至vh6-1的下游区(最靠近d的vh基因)。为了在bac6和bac3之间提供重叠,将bac3中位于人vh基因座5’端处的10.6kb片段如先前所述那样整合到bac6中vh3-23的下游(osborn等人2013年,同上)。将bac6中的人vh基因切下作为~182-kbasisi-asci片段。bac3未经修饰,并且将该bac中的人vh基因切下作为~173kbnoti片段。寡核苷酸:hc27-1:hc27-2:hc27-3:hc27-4:hc27-5:hc27-6:hc27-7:hc27-8:hc27-9:hc27-10:hc27-11:hc27-12:hc27-13:hc27-14:hc27-15:hc27-16:hc27-17:hc27-18:hc27-19:hc27-20:georgii的构建“人-大鼠”igh分若干部分进行构建和组装。这涉及对大鼠c区基因进行修饰并将其接合在各含有编码w→r的点突变突变的人jh1-jh6的下游,然后在上游添加人vh6-1-d区段区。该bac被命名为georgii。首先,在2.3kbscai片段中合成突变的人jh1-jh6(thermofisherscientific,见下文)。然后,将突变的人jh1-jh6与人jh上游的~3.1kbdna区和从紧邻jh下游的大鼠序列跨越到大鼠cμ的~11.4kb区接合,大鼠cμ的编码区已被大鼠cγ2a编码区取代,但在称为pcau+huj(w-r)-大鼠cγ2a(-ch1)的bac中缺乏ch1。该bac中的整个经修饰区可以切下作为16.7kbsnabi-fspi片段。该bac通过将酵母中的以下4个重叠片段组装为cyac而获得,然后转化成bac:使用引物hc32-1和-2扩增的覆盖人jh上游区的~2.7kb片段;2.3kb突变的人jh1-jh6-scai片段;使用引物hc32-3和-4扩增的覆盖紧邻jh下游的大鼠区的~2.1kb片段;和从pcau+huj-大鼠cγ2a(-ch1)上切下的~18.4kbmlui-hpai片段(含有大鼠cμ基因座,其编码区被缺乏ch1和pcau载体的大鼠cγ2a编码区取代,如‘hc27构建方法’中所述)。通过测序检查所有经修饰区以确认准确性。最后,使用以下4个重叠片段组装编码人vh6-1-d-突变jh-经修饰的大鼠c区的georgii:涵盖从bac10(ctd-3216m13,invitrogen)切下的人vh6-1-d区的纯化~78.2kbfspai-mlui片段,从如上所述的pcau+huj(w-r)-大鼠cγ2a(-ch1)上切下的16.7kbsnabi-fspi片段,从pcau+大鼠cγ1,2b(-ch1)切下的~40kbfspi片段(如‘hc27构建方法’中所述),和从构建体annabel上切下的纯化~77.2kbswai-sacii片段,构建体annabel包括cγ2b和cε之间的基因间区,接着是cε、cα、3′增强子区、pbelo-cen-ura载体和人vh6-1上游的5′区。通过限制性内切酶谱和部分测序来深入检查该最终构建体。(人vh6-1-d-突变jh-经修饰的大鼠c)区可以切下并纯化作为~201kbnoti片段。显微注射以产生hc32和hc33转基因大鼠bac6含有从vh4-39至vh3-23的人基因组区,而bac3含有从vh3-11至vh6-1的下游区(最靠近d的vh基因)。为了在bac6和bac3之间提供重叠,将bac3中位于人vh基因座5’端处的10.6kb片段如先前所述那样整合到bac6中vh3-23的下游(osborn等人2013,j.immunol.190:1481-1490)。将bac6中的人vh基因切下作为~182-kbasisi-asci片段。bac3未经修饰,并且将该bac中的人vh基因切下作为~173kbnoti片段。将两个片段纯化并与来自georgii的~201kbnoti片段共同注射到大鼠胚胎中以构建hc32。bac9含有从vh3-74至vh3-53的人基因组区。bac(14+5)含有从vh3-53至vh3-13的下游区,并将紧邻vh6-1上游的6.1kb区添加至其3′以提供与georgii的重叠。将bac9中的人vh区切下作为~185kbnoti片段,并将来自bac(14+5)的人vh区切下作为~209kbbsiwi片段。将两个片段纯化并与来自georgii的~201kbnoti片段共同注射到大鼠胚胎中以构建hc33。dna纯化使用elutraptm(schleicher和schuell)(gu等人,j.biochem.biophysmethods.,1992,24:45-50)从切割自常规操作的0.8%琼脂糖凝胶或得自脉冲场凝胶电泳(pfge)的条带进行电洗脱来纯化消化后的线性yac、环状yac和bac片段。dna浓度通常为~100μl的体积中若干ng/μl。对于高达~200kb的片段,使dna沉淀并重新溶解于显微注射缓冲液(10mmtris-hclph7.5,100mmedtaph8和100mmnacl,但不含精胺/亚精胺)达到所需浓度。使用nucleobondax硅胶基阴离子交换树脂(macherey-nagel,germany)纯化来自酵母的环状yac。简言之,使用藤黄节杆菌酶或溶细胞酶制备原生质球并使其沉淀(davies等人,1996,humanantibodyrepertoiresintransgenicmice:manipulationoftransferofyacs.inantibodyengineering:apracticalapproach.j.mccafferty,h.r.hoogenboom和d.j.chiswell编辑,irl,oxford,u.k.,第59-76页)。细胞然后进行碱裂解,与ax100柱结合并洗脱,如用于低拷贝质粒的nucleobond方法中所述。使用质粒-safetmatp依赖性脱氧核糖核酸酶(epicenterbiotechnologies)来水解污染性酵母染色体dna,然后使用sureclean(bioline)进行最终的清洗步骤。然后用环状yac转化dh10电感受态细胞(invitrogen)的等分试样以获得bac克隆。为了将用于显微注射的插入dna(150-200kb)与从bac载体dna(~10kb)分离,使用sepharose4b-cl进行过滤步骤(yang等人,1997,nat.biotechnol.1997,15;859-865)。凝胶分析通过在常规0.7%琼脂糖凝胶上进行限制性内切酶消化和分离来分析纯化的yac和bacdna(sambrook和russell,2001)。在8℃下,通过pfge(bioradchefmappertm),使用0.5%tbe中的0.8%pfc琼脂糖,保持2-20秒转换时间16小时(6v/cm、10ma),以分离较大的片段(50-200kb)。纯化允许对所得片段与从序列分析获得的预测大小进行直接比较。通过pcr和测序来分析改变。显微注射将远系杂交的sd/hsd系动物根据实验动物评估和认可管理委员会(aaalac)认可的动物设施中的获批动物护理方案圈养在标准微型隔离笼中。将大鼠维持在14-10小时光/暗循环中,随意进食和饮水。在与远系杂交的sd/hsd雄性配种之前,对4至5周龄sd/hsd雌性大鼠注射20-25iupmsg(sigma-aldrich),48小时后注射20-25iuhcg(sigma-aldrich)。收集受精的1细胞期胚胎用于随后的显微注射。将操纵的胚胎转移到假孕sd/hsd雌性大鼠中以进行分娩。将编码重组免疫球蛋白基因座的纯化dna重悬于含有10mm精胺和10mm亚精胺的显微注射缓冲液中。将dna以0.5至3ng/μl的各种浓度注射到受精的卵母细胞中。将编码对大鼠免疫球蛋白基因具有特异性的zfn的质粒dna或mrna以0.5至10ng/ul的各种浓度注射到受精的卵母细胞中。锌指核酸酶(zfn)产生了对大鼠免疫球蛋白基因具有特异性的zfn。对大鼠cκ具有特异性的zfn具有以下结合位点:atgagcagcaccctctcgttgaccaaggctgactatgaa(seqidno:22)对大鼠j基因座序列具有特异性的zfn具有以下结合位点:caggtgtgcccatccagctgagttaaggtggag(seqidno:23)和caggaccaggacacctgcagcagctggcaggaagcaggt(seqidno:24)对大鼠cγ基因座序列具有特异性的zfn具有以下结合位点:aacagccatttgcagaccaaagggaaggaaaga(seqidno:25)和ttctaccctggtgttatgacagtggtctggaaggcagatggt(seqidno:26)具有转基因座的大鼠产生携带呈未重排构型的人工重链免疫球蛋白基因座的转基因大鼠。对转基因大鼠的rt-pcr和血清分析(elisa)揭示了转基因免疫球蛋白基因座的有效重排和各同种型的仅有重链的抗体在血清中的表达。转基因大鼠的免疫导致产生高亲和力抗原特异性的仅有重链的抗体。新型锌指核酸酶敲除技术为了进一步优化转基因大鼠中仅有重链的抗体的产生,产生含有失活内源性大鼠免疫球蛋白基因座的敲除大鼠。为了使大鼠重链免疫球蛋白重链表达和大鼠λ轻链表达失活,将zfn显微注射到单细胞大鼠胚胎中。随后,将胚胎转移到假孕雌性大鼠中并进行分娩。通过pcr鉴定具有突变的重链和轻链基因座的动物。对此类动物的分析证明突变动物中大鼠免疫球蛋白重链和轻链表达的失活。实施例2:大鼠中抗原特异性的仅有重链的抗体(hcab)的产生为了在大鼠中产生抗原特异性的仅有重链的抗体,以各种方式对表达仅有重链的抗体的基因工程改造的大鼠,例如实施例1中描述的那些大鼠进行免疫。用灭活病毒免疫由immunologyandpathogenesisbranch,influenzadivision,cdc,atlanta,ga提供具有多种不同血凝素和神经氨酸酶基因的流感病毒。使病毒原液在10日龄含胚鸡蛋的尿囊腔中增殖,并通过10%-50%蔗糖梯度以超速离心的方式进行纯化。将病毒重悬于磷酸盐缓冲盐水中,并在4℃下通过用0.05%福尔马林处理2周来灭活。将灭活的病毒和alumn溶液(pierce)以3∶1的比率混合,并在免疫前于室温下孵育1小时。用全灭活物对表达仅有重链的抗体的基因工程改造的大鼠进行免疫。用蛋白质或肽免疫通常将免疫原(蛋白质或肽,如人免疫球蛋白κ轻链、人igm或igg重链、人血清白蛋白、蛋白质-肽缀合物)用无菌盐水稀释至0.05-0.15ml,并用佐剂合并至0.1-0.3ml的最终体积。可获得许多适当的佐剂(即热灭活的百日咳博德特氏菌(bordetellapertussis)、氢氧化铝凝胶、quila或皂苷、细菌脂多糖或抗cd40),但都没有完全弗氏佐剂(cfa)和弗氏不完全佐剂(ifa)的活性。在最终制剂中,可溶性免疫原如蛋白质和肽的浓度可在5μg至5mg之间变化。用cfa中的免疫原进行的第一次免疫(初免)经腹膜内和/或皮下和/或肌肉内施用。如果使用完整细胞作为免疫原,则最好是经腹膜内和/或静脉内注射。将细胞稀释于盐水中,每次注射施用100至2000万个细胞。在大鼠体内存活的细胞将产生最佳免疫结果。用cfa中的免疫原进行第一次免疫后,通常在4周后递送在ifa中的第二次免疫(加强)。该顺序导致形成产生高亲和力抗体的b细胞。如果免疫原较弱,则每2周施用加强免疫,直至实现强体液反应。加强免疫中的免疫原浓度可以较低,并且可以使用静脉内途径。每2周收集大鼠血清以测定体液反应。如上所述用脂质ii五肽、青霉素结合蛋白、β-内酰胺酶、转肽酶(sortases)和原核生物的其他膜蛋白进行免疫。用脂质、糖脂和碳水化合物聚合物免疫用聚-n-乙酰基-β-(1-6)-葡萄糖胺(pnag)和其他碳水化合物聚合物进行免疫纯化的dpnag、pnag或其他碳水化合物聚合物通过还原胺化反应与白喉毒素、白蛋白或其他载体蛋白缀合。首先通过用戊二醛处理将醛基基团引入载体蛋白的表面上。随后,在还原剂nacnbh3钠存在下,使活化载体蛋白与dpnag(或其他碳水化合物聚合物)通过其游离氨基进行反应。第0天用pnag和dpnag-dt缀合物经皮下或足垫对动物进行免疫,并在随后几周用0.15-100-μg剂量的完全弗氏佐剂或其他佐剂中的缀合pnag或dpnag加强。加强免疫优选在弗氏不完全佐剂中进行。每周抽血,通过elisa测定特异性抗体滴度。从引流淋巴结或脾脏和使用标准方法产生的杂交瘤中回收b细胞。可替代地,使用酵母细胞来选择抗原结合抗体或片段。用脂质ii进行免疫将具有c55或更短脂质尾的纯化脂质ii与titermax、脂质体、ribi佐剂或其他佐剂混合。另外,将诸如klh或卵清蛋白的蛋白质和诸如脂质a或完全弗氏佐剂的免疫刺激化合物添加到混合物中。第0天在足垫中或在皮下用0.1-1mg脂质ii进行初次免疫,并在随后几周用0.15-100-μg剂量的完全弗氏佐剂或其他佐剂中的缀合pnag或dpnag加强。加强免疫优选在弗氏不完全佐剂中进行。每周抽血,通过elisa测定特异性抗体滴度。从引流淋巴结或脾脏和使用标准方法产生的杂交瘤中回收b细胞。可替代地,使用酵母细胞来选择抗原结合抗体或片段。使用脂质a进行免疫根据bogard等人,1987,infectionandimmunity,55:4,899-908的方法制备核-脂质a。将鲍曼不动杆菌(acinetobacterbaumannii)atcc19606或其他革兰氏阴性菌在luria肉汤中培养,通过离心收集,悬浮在冷冻干燥培养基中达到细胞密度为109cfu/ml,然后置于预称重安瓿或玻璃小瓶中,填充不超过1/3的体积。将无菌棉或玻璃棉插入安瓿颈部,或将塞子插入小瓶中。将样品在超低温冰箱中缓慢冷冻,然后施加真空过夜以进行初步干燥。通过将温度升高至20℃持续数小时来进行二次干燥。将冻干样品储存在4℃下。将10mg冻干细胞悬浮于400μl异丁酸和1m氢氧化铵(5∶3,v/v)中,并在100℃下在带有搅棒的螺旋盖试管中孵育2小时。将样品在冰水中冷却并以2000xg离心15分钟。将上清液转移到新管中,用等份水稀释并冻干。将样品用400μl甲醇洗涤两次,并以2000xg离心15分钟,保存底部有机层及其界面并在氮气流下干燥。然后将五毫克脂质a悬浮在5ml的0.5%(重量/体积)三乙胺中。(sigma,st.louis,mo.),之后添加5mg经酸处理的细菌。将混合物在室温下缓慢搅拌30分钟,并用speedvac离心机真空干燥。使用脂质a包被的细胞经腹膜内或足垫对动物进行免疫。与弗氏不完全佐剂(difco)呈1∶1混合物使用,每次注射50μl剂量的核lps包被的细胞悬液(dekievit&lam,journalofbacteriology,dec.1994,第7129-7139页)。第0、4、9、14和28天对动物进行免疫。通过酶联免疫吸附测定(elisa)和从不同来源纯化的lps(avantipolarlipids,alabaster,ala)来针对抗lps抗体的产生对杂交瘤细胞系进行筛选。还将上清液在热灭活的或有活力的革兰氏阴性细菌诸如克雷伯氏菌(klebsiella)、大肠杆菌、铜绿假单胞菌(pseudomonasaeruginosa)、鲍曼不动杆菌和沙门氏菌(salmonella)上进行了试验。选择广泛反应性抗体并进行与多粘菌素b(polymyxinb)的竞争测定。hcab的最小抑制浓度(mic)可以使用多种实验室方法来测量细菌对抗微生物剂的体外易感性。可以使用肉汤或琼脂稀释方法来定量测量抗微生物剂针对给定细菌分离物的体外活性。为了进行试验,用向其中添加了多种浓度的抗微生物剂的肉汤或琼脂培养基制备一系列管或板。然后用试验生物的标准化悬液对这些管或板进行接种。在35±2℃下孵育过夜后,检查试验并测定最小抑制浓度(mic)。最终结果受到方法的显著影响,如果要实现可重复的结果(实验室内和实验室间),必须小心控制方法。使用稀释试验获得的mic给出了抑制感染生物所需的抗微生物剂的浓度。然而,mic并不代表绝对值。“真”mic介于抑制生物生长的最低试验浓度(即mic读数)和下一个较低试验浓度之间的某个浓度。例如,如果使用两倍稀释并且mic为16μg/ml,则“真”mic将介于16和8μg/ml之间。即使在最佳控制条件下,稀释试验也可能不会在每次进行时产生相同的终点。通常,试验的可接受重复性在实际终点的一个两倍稀释范围内。根据标准clsi方法,通过肉汤微量稀释mic测定(brothmicrodilutionmicassay)测试抗体或其片段和比较物抗生素(万古霉素(vancomycin)、多粘菌素、头孢菌素(cephalosporin)或其他β-内酰胺)的体外活性(临床与实验室标准研究所(clinicalandlaboratorystandardsinstitute.)2003.需氧菌抗菌药物稀释法敏感性试验方法(methodsfordilutionantimicrobialsusceptibilitytestsforbacteriathatgrowaerobically).批准标准m7-a7)。针对金黄色葡萄球菌(staphylococcusaureus)atcc29213、革兰氏阳性和革兰氏阴性细菌测试抗体或其片段的活性。mic测定如下:1.细菌接种物制备。从新平板(小于1周时长)挑选每个菌株的单个菌落,并转移到5ml阳离子调节的muller-hinton肉汤(camhb)中。在37℃振荡器中孵育过夜。2.第二天早上,对过夜培养物进行1∶100稀释(将50ul稀释成5ml)。在37℃振荡器中孵育2-4小时。3.2-4小时后(在600nm下吸光度为约0.3-0.5)将细菌离心(5000rpm,5分钟),重悬于pbs中,将培养物调节至macfarland0.5并将50ul经调节的培养物转移到9950ulcamhb中,进行涡旋混合。4.2-4小时后(在600nm下吸光度为约0.3-0.5)将细菌离心(5000rpm,5分钟),重悬于pbs中,将培养物调节至macfarland0.5并将50ul经调节的培养物转移到9950ul的1.1xcamhb(阳离子调节的muller-hinton肉汤)中,进行涡旋混合。5.母板制备[10个子板有一个母板,每个菌株一个子板]:(在细菌生长的同时制备,步骤5):向深孔板的第一个孔添加200ul化合物原液并向所有其他孔添加100uldmso。在孔2-11中进行化合物的2倍连续稀释(从1转移100ul到2,通过移液混合4次,从2转移100ul到3,混合,以此类推,从孔11弃去100ul)。孔12是仅有dmso的对照。向每个孔添加900ul灭菌蒸馏水,通过移液混合。6.mic板制备:从母板的每个孔转移10ul到子板的相应孔中。每孔添加90ul细菌接种物,通过移液混合。7.在37℃下孵育24小时并对生长进行评分。出现孔浑浊、有明显沉淀或孔中存在>3个细菌定点中的任一者都认为是在生长。将未显示出生长的最低化合物浓度评为mic。使用标准肉汤微量稀释mic测定测得,对于金黄色葡萄球菌的万古霉素mic在0.1ug/ml和10ug/ml之间变化。完整hcab对金黄色葡萄球菌的mic在0.025ug/ml和25ug/ml之间变化。如果使用可变区片段或纳米抗体,则对金黄色葡萄球菌的mic在0.008ug/ml和8ug/ml之间变化。(金黄色葡萄球菌的万古霉素mic:0.25-4ug/ml,mrsa的万古霉素mic:1-138ug/ml,万古霉素分子量为1450道尔顿,hcab的分子量重量为80,000道尔顿,hcab比万古霉素重~50x,万古霉素对脂质ii的亲和力为50nm,hcab的亲和力将介于0.5至10nm。hcab将具有的mic介于0.025至25ug/ml)。(j.clin.microbiol.2006,44(11):3883.doi:a.brucknerguiqingwang,janetf.hindler,kevinw.wardanddavid.increasedvancomycinmicsforstaphylococcusaureusclinicalisolatesfromauniversityhospitalduringa5-yearperiod)hcab在免疫球蛋白、补体和吞噬细胞存在下的mic如美国专利第8,410,249号所述,进行调理作用吞噬测定(opa)。opa测量在抗体、补体和吞噬细胞存在下对细菌的杀伤。通常使用补体和人类细胞。hcab或片段以0.01ug/ml至10μg/ml的浓度进行试验。通过在与所有组分一起孵育之前和之后测定菌落形成单位来测量对细菌的杀伤。调理作用也在显微镜下目测观察。将人多形核白细胞(pmn)或分化的hl60早幼粒细胞白血病(hl60)细胞用作效应细胞。将人血清或幼兔血清中的补体用作补体来源。简言之,将hcab或其他样本在96孔微量滴定板中用hanks平衡盐溶液以两倍稀释步骤连续稀释,然后与细菌(每孔~2,000个cfu)和补体一起在37℃下于定轨振荡器上孵育30分钟。确定每个细菌菌株的最佳振荡速度,以使非特异性杀伤或过度生长最小化。将新鲜分离的人pmn或分化的hl60细胞(效应细胞)以400∶1的比率添加到细菌(靶标)-补体-血清混合物中,并将混合物在37℃下孵育45分钟。opa滴度是这样的血清稀释度,其导致与来自含有除hcab或其片段之外的所有试剂的对照孔的cfu相比,cfu减少(杀伤)50%。hcab在10ng/ml和10μg/ml之间杀伤细菌。用细胞免疫用细胞免疫的方法是本领域熟知的。例如,为了表达抗cd3e抗体,使人jurkat细胞在组织培养物中生长。通过将jurkat细胞与单克隆抗体okt3一起孵育来分析所需人抗体的表达。随后,通过洗涤细胞去除未结合的okt3,并利用与荧光素缀合的抗小鼠igg以及流式细胞术分析来检测结合的okt3。如所述,通过电穿孔用编码人cd3的真核表达质粒转染大鼠t细胞杂交瘤细胞(transy等人,1989,eurjimmunol19(5):947-50)。表达人cd3的转染子通过facs富集并在组织培养中增殖。通过腹膜内注射30x10(6)个jurkat细胞来免疫表达仅有重链(hco)的抗体的基因工程改造的大鼠。在初次免疫后4周和8周,用表达人cd3的大鼠t细胞免疫大鼠。使用表达抗人cd3e仅有重链抗体的动物用来分离单克隆的仅有重链的抗cd3e抗体基于dna的免疫方案基因疫苗或使用编码抗原的dna免疫代表了一种在大鼠中形成强抗体反应的替代方法。dna接种途径通常是通过皮肤、肌肉及支持抗原转染和表达的任何其他途径。使用设计用于表达抗原,诸如流感病毒血凝素糖蛋白或其他人或病毒抗原的纯化质粒dna。dna接种途径包括:静脉内(尾静脉)、腹膜内;肌肉内(双侧股四头肌)、鼻内、皮内(诸如足垫)和皮下(诸如颈背部)。通常,每个接种部位以100μl盐水施用10-100μg的dna,或用适当的媒介物诸如金颗粒或促进细胞吸收和转染的某些制剂(http://www.incellart.com/index.php?page=genetic-immunization&menu=3.3)施用dna。免疫方案类似于上述方案;进行初次免疫,接着进行加强免疫。仅有重链的抗体的纯化为了纯化抗体,从免疫大鼠收集血液并通过离心获得血清或血浆,离心将凝结的细胞沉淀与含有血清抗体的顶部液相分离。通过标准程序纯化来自血浆血清的抗体。此类程序包括沉淀、离子交换色谱法和/或亲和色谱法。为了纯化igg,可以使用蛋白质a或蛋白质g(brüggemann等人,ji,142,3145,1989)。实施例3:从大鼠中分离表达抗体的b细胞。从脾脏、淋巴结或外周血中分离b细胞由免疫大鼠的脾脏或淋巴结制备单细胞悬液。在去除红细胞后或在分离b细胞、记忆b细胞、抗原特异性b细胞或浆细胞后,可以使用细胞而无需进一步富集。富集可以产生更好的结果,因此建议至少去除红细胞。通过消耗不需要的细胞和随后的阳性选择来分离记忆b细胞。使用针对cd2、cd14、cd16、cd23、cd36、cd43和cd235a(血型糖蛋白a)的抗体混合物消耗不需要的细胞,例如t细胞、nk细胞、单核细胞、树突细胞、粒细胞、血小板和红细胞系细胞。用对igg或cd19具有特异性的抗体进行阳性选择产生高度富集的b细胞(50%-95%)。通过将细胞暴露于用荧光标志物和/或磁珠标记的抗原而获得抗原特异性b细胞。随后,使用(流式细胞术或荧光激活细胞分选仪[facs])facs分选仪和/或磁体分离用荧光染料和/或磁珠标记的细胞。由于浆细胞可以表达很少的表面ig,因此可以应用细胞内染色。通过荧光激活细胞分选来分离b细胞使用基于facs的方法,根据细胞各自的特性对其进行分离。重要的是细胞处于单细胞悬液中。将由免疫大鼠的外周血、脾脏或其他免疫器官制备的单细胞悬液与对b细胞标志物诸如cd19、cd138、cd27或igg具有特异性的荧光染料标记的抗体混合。可替代地,将细胞与荧光染料标记的抗原一起孵育。在适当的缓冲液诸如pbs中,细胞浓度为100-2000万个细胞/ml。例如,可以通过选择对cd27呈阳性而对cd45r呈阴性的细胞来分离记忆b细胞。可以通过选择对cd138呈阳性而对cd45r呈阴性的细胞来分离浆细胞。将细胞装载到facs机上,并且将分类细胞沉积到含有培养基的96孔板或管中。如有必要,在实验中使用每种荧光染料的阳性对照,这允许本底扣除以计算补偿。从骨髓分离b细胞如所述,从免疫动物中分离骨髓浆细胞(bmpc)(reddy等人,2010,naturebiotechnology28,965-969)。从收获的胫骨和股骨中去除肌肉和脂肪组织。用外科手术剪刀修剪胫骨和股骨的端部并用26号胰岛素注射器(bectondickinson,bd)冲洗出骨髓。将骨髓收集在经过无菌过滤的1号缓冲液(pbs、0.1%bsa、2mmedta)中。经机械破碎,通过细胞滤网(bd)过滤收集骨髓细胞,并用20mlpbs洗涤并收集在50ml管(falcon,bd)中。将骨髓细胞在4℃下以335g离心10分钟。轻轻倒出上清液,将细胞沉淀重悬于3ml红细胞裂解缓冲液(ebioscience)中,并在25℃下轻轻振荡5分钟。用20mlpbs稀释细胞悬液,并在4℃下以335g离心10分钟。轻轻倒出上清液并将细胞沉淀重悬于1ml的1号缓冲液中。将骨髓细胞悬液与生物素化的抗cd45r和抗cd49b抗体一起孵育。然后将细胞悬液在4℃下旋转20分钟。然后在4℃下以930g离心6分钟,去除上清液并将细胞沉淀重悬于1.5ml的1号缓冲液中。根据制造商的方案洗涤并重悬链霉亲和素缀合的m28磁珠(invitrogen)。向每种细胞悬液中添加磁珠(50ul),并将混合物在4℃下旋转20分钟。然后将细胞悬液置于dynabead磁体(invitrogen)上,收集上清液(阴性成分,未与珠粒缀合的细胞),弃去与珠粒结合的细胞。将预洗涤的链霉亲和素m280磁珠在4℃下与生物素化的抗cd138一起孵育30分钟,每25ul磁珠混合物有0.75ug抗体。然后根据制造商的方案洗涤珠粒并重悬于1号缓冲液中。将如上收集的阴性细胞成分(耗尽了cd45r+和cd49b+细胞)与50ul的cd138缀合磁珠一起孵育,并将悬液在4℃下旋转30分钟。通过磁体分离具有cd138+结合细胞的珠粒,用1号缓冲液洗涤3次,弃去未结合珠粒的阴性(cd138-)细胞。收集阳性cd138+珠粒结合细胞并储存在4℃下直至进一步处理。可替代地,可以使用ouisse等人,bmcbiotechnology,2017,17:3,1-17中描述的方法。实施例4:杂交瘤的产生如所述,通过与骨髓瘤细胞诸如x63或yb2/0细胞融合而使分离的b细胞永生化(和milstein,nature,256,495,1975)。在选择性培养基中培养杂交瘤细胞,并通过有限稀释或单细胞分选而产生生成抗体的杂交瘤细胞。实施例5:编码仅有重链的抗体的cdna的分离由分离的细胞产生cdna序列将分离的细胞在4℃下以930g离心5分钟。用tri试剂裂解细胞,并根据制造商的方案在ribopurerna分离试剂盒(ambion)中分离总rna。根据制造商的方案,用寡聚dt树脂和poly(a)purist试剂盒(ambion)从总rna中分离mrna。用nd-1000分光光度计(nanodrop)测量mrna浓度。通过用maloney鼠白血病病毒逆转录酶(mmlv-rt,ambion)进行逆转录,将分离的mrna用于第一链cdna合成。根据retroscript(ambion)制造商的方案,使用50ng的mrna模板和寡聚dt引物通过rt-pcr引发进行cdna合成。cdna构建后,进行pcr扩增以扩增仅有重链的抗体。引物清单如表1所示:表1:按照出现的顺序分别公开seqidno27-39人vh基因寡核苷酸序列vh基因匹配vh1atggactggacctggaggatcc1-02,1-03,1-08,7-04.1vh1-24atggactgcacctggaggatcc1-24vh2tccacgctcctgctgctgac2-05vh2-26gctacacactcctgctgctgacc2-26vh3atggagtttgggctgagctgg3-11,3-23,3-30,3-33vh3-07atggaattggggctgagctg3-07vh3-09atggagttgggactgagctgga3-09vh3-35atggaatttggcctgagctgg3-35vh3-38atgcagtttgtgctgagctgg3-38vh4tgaaacacctgtggttcttcc4-04,4-28,4-31,4-34vh4-39tgaagcacctgtggttcttcc4-39vh6tcatcttcctgcccgtgctgg6-01大鼠igmch2gctttcagtgatggtcagtgtgcttatgac50μlpcr反应物由0.2mm正向和反向引物混合物、5ul的thermopol缓冲液(neb)、2ul未纯化的cdna、1ul的taqdna聚合酶(neb)和39ul重蒸馏h2o组成。pcr热循环程序为92℃持续3分钟;4个循环(92℃持续1分钟,50℃持续1分钟,72℃持续1分钟);4个循环(92℃持续1分钟,55℃持续1分钟,72℃持续1分钟),20个循环(92℃持续1分钟,63℃持续1分钟,72℃持续1分钟);72℃持续7分钟,4℃储存。pcr基因产物经凝胶纯化和dna测序。实施例6:重组的仅有重链的抗体的克隆和表达将pcr产物亚克隆到质粒载体中。为了在真核细胞中表达,如所述,将编码仅有重链的抗体的cdna克隆到表达载体中(tiller等人,2008;329(1-2):112-124)。可替代地,如所述,将编码仅有重链的抗体的基因克隆到产生微环的质粒中(kay等人,2010;naturebiotechnology28.12(2010):1287-1289)。可替代地,使用改进的热力学平衡内面向外成核pcr(gao等人,2003;nucleicacidsresearch.;31(22):e143)由重叠的寡核苷酸合成编码仅有重链的抗体的基因并克隆到真核表达载体中。可替代地,合成编码仅有重链的抗体的基因并将其克隆到质粒中。为了在人工染色体中组装多个编码仅有重链的抗体的多个表达盒,将多个表达盒彼此连接,随后克隆到bac载体中,使载体在细菌中增殖。为了转染,使用来自invitrogen的electromaxtmdh10btm细胞(http://tools.invitrogen.com/content/sfs/manuals/18290015.pdf)。可替代地,将连接的表达盒进一步与酵母人工染色体臂连接,使其在酵母细胞中增殖(davies等人,1996,同上)。质粒纯化使用来自sigma-aldrich的genelutetm质粒小量提取试剂盒从~5ml(或更多)过夜细菌培养物中分离质粒(http://www.sigmaaldrich.com/life-science/molecular-biology/dna-and-rna-purification/plasmid-miniprep-kit.html)。这涉及通过离心,接着进行碱裂解来收获细菌细胞。然后使dna与柱结合,洗涤并洗脱,准备用于消化或测序。bac纯化来自clontech的nucleobondrbac100是设计用于bac纯化的试剂盒(http://www.clontech.com/products/detail.asp?tabno=2&product_id=186802)。为此,从200ml培养物中收获细菌,并使用改进的碱/sds工序进行裂解。将细菌裂解物通过过滤澄清并装载到平衡柱上,其中质粒dna与阴离子交换树脂结合。在随后的洗涤步骤后,将纯化的质粒dna在高盐缓冲液中洗脱并用异丙醇使其沉淀。将质粒dna复溶于te缓冲液中以供进一步使用。yac纯化使用elutraptm(schleicher和schuell)(gu等人,1992,同上)从切割自常规操作的0.8%琼脂糖凝胶或得自脉冲场凝胶电泳(pfge)的条带进行电洗脱来纯化消化后的线性yac、环状yac和bac片段。将纯化的dna沉淀并重新溶解在缓冲液中至所需浓度。使用nucleobondax硅胶基阴离子交换树脂(macherey-nagel,germany)纯化来自酵母的环状yac。简言之,使用藤黄节杆菌酶或溶细胞酶制备原生质球并使其沉淀(davies等人,1996,同上)。细胞然后进行碱裂解,与ax100柱结合并洗脱,如用于低拷贝质粒的nucleobond方法中所述。使用质粒-safetmatp依赖性脱氧核糖核酸酶(epicentrebiotechnologies)来水解污染性酵母染色体dna,然后使用sureclean(bioline)进行最终的清洗步骤。然后用环状yac转化dh10电感受态细胞(invitrogen)的等分试样以获得bac克隆(见上文)。为了插入dna(150-200kb)与bac载体dna(~10kb)分离,使用sepharose4b-cl进行过滤步骤(yang等人,同上)。用质粒或bacdna转染细胞为了表达重组的仅有重链的抗体,如所述,转染真核细胞(andreason和evans,1989,anal.biochem.180(2):269-75;baker和cotten,1997,nucleicacidres.,25(10):1950-6;http://www.millipore.com/cellbiology/cb3/mammaliancell)。使用多种选择方法来分离表达仅有重链的抗体的细胞。使用有限稀释或细胞分选来分离单细胞。分析克隆物的仅有重链的抗体的表达。实施例7:unirattm和omniflictm中的j基因使用图1显示了如前述实施例中所述,在unirattm中用来表达仅有重链的抗体的人转基因。omniflictm使用与unirat相同的人v基因簇,但表达固定的κ轻链。图2显示如前述实施例中所述,在unirattm中用来表达仅有重链的抗体的人转基因,其中所有j基因在位置101处均表达精氨酸。通过对从来自免疫动物的淋巴结来源的b细胞分离的mrna的完整vh区的下一代测序来确定unirattm和omniflictm的表达抗体库。将来自表达的抗体的完整vh序列与人ighv和ighj种系序列进行比对。从至少6只独立的unirattm和omniflictm动物计算j基因使用频率。图3显示unirattm使用含w101r突变的ighj4的频率高于具有野生型ighj4序列的omniflictm。omniflictm使用ighj6的频率也远高于unirattm。实施例8:w101突变抑制λ缔合通过标准elisa来测量λ与大量的1058个重链抗体的缔合。在总共1058个重链抗体中,859个在位置101处含有r,199个在位置101处位含有w。图4显示仅有2.7%的r101重链抗体表现出与游离λ蛋白显著缔合,确定为elisa信号为本底信号的10倍或更高。相比之下,使用相同标准,31.2%的w101重链抗体表现出与游离λ蛋白显著缔合。这些结果表明,w101r突变对λ缔合具有高度保护作用,并且w101重链抗体与λ缔合的可能性比r101高得多。实施例9:游离λ蛋白与相同cdr3族中仅有重链的抗体缔合图5显示了来自相同cdr3族中的重链抗体的11个vh序列的多序列比对。所有这些序列在位置101处均含有w。比对中的前7个序列对于通过elisa测量的λ缔合均呈阳性。比对的后4个序列对于同样通过elisa测量的λ缔合均呈阴性。该vh序列族在位置a和b处显示出将λ阳性和阴性序列区分开的附加突变。位置a或b处的ser或glu消除了λ缔合。然而,其他cdr3族中这些位置的ser或glu与λ结合不具有相同的关联。来自该族的结果表明,w101vh序列中存在阻止λ缔合的补偿性突变,但这些补偿性突变对cdr3族具有特异性。实施例10:当使用ighj6时,unirattm和omniflictm之间的d-j接合多样性不同。如实施例6中所示,在omniflictm中使用ighj6的频率为unirattm中的3倍。此外,如图3所示,在unirattm中使用ighj6时,在种系ighj6序列中看到的5个tyr残基的延伸段最经常地缩短为1个tyr。相比之下,当使用ighj6时,4个tyr残基的延伸段是omniflictm中最常见的长度。这表明当使用ighj6时,对于缩短含有w101的重链抗体中的种系ighj6序列中存在的5个tyr残基的延伸段而言存在选择压力。实施例11:使用人vh胞外结合结构域的嵌合抗原受体在原代t细胞上表达嵌合抗原受体需要表达含有胞外抗原结合结构域和胞内信号传导结构域的单一嵌合蛋白。单链fv片段通常用作抗原结合结构域。scfv嵌合抗原受体的一个实例如图6的图块a所示。可替代地,单一人vh结合结构域用作胞外结合结构域(图块b或图6)。使用单一人vh具有待表达的蛋白质较小且较不复杂的优点并且免疫原性较低。虽然本文已经显示和描述了本发明的优选实施方案,但是对于本领域技术人员显而易见的是,此类实施方案仅以举例的方式提供。在不脱离本发明的情况下,现在本领域技术人员将设想出许多变型、改变和替代形式。应该理解的是,本文所述的本发明的实施方案的各种替代方案可用于实施本发明。以下权利要求旨在限定本发明的范围,并且由此覆盖了这些权利要求及其等同内容范围内的方法和结构。序列表<110>teneobio,inc.<120>产生经修饰的仅有重链的抗体的转基因非人动物<130>tno-0001-wo<140><141><150>62/379,075<151>2016-08-24<160>58<170>patentin3.5版<210>1<211>27<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>1gtattacacacaaaatgggaaaagctg27<210>2<211>32<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>2ccggtagtcaaagtagtcacattgtgggaggc32<210>3<211>64<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>3ccttaatggggcctcccacaatgtgactactttgactaccggggccagggaaccctggtc60accg64<210>4<211>27<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>4gaatcctaggattgccttcttagcctg27<210>5<211>176<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多核苷酸”<400>5ccatagaccaaacttacctactatctagtcctgccaaccttaagagcagcaacatggaga60cagcagagtgtagagagatctcctgactggcaggaggcaagaagatggattcttactcgt120ccatttctcttttatccctctctggtcctagagaacaaccaggggatgaggggctc176<210>6<211>208<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多核苷酸”<400>6gcacaagtggacaaagtctttggccagtctagaaagaagcccgtctcagagatcaaagct60ggagggcaacacaggaaagatgtgggaataagtttactagtcatacaggcaggaacccca120ggcccagaggtagtgtccctgtgggagggtctcttgctctctgatgtccttccatgctga180gagttagggcccttgtccaatcatgttc208<210>7<211>71<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>7gaattttgcccaagttttttcagcttttcccattttgtgtgtaatacgtacacaccgcag60ggtaataactg71<210>8<211>74<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>8gacgggcttctttctagactggccaaagactttgtccacttgtgcgcagttatctatgct60gtctcaccatagag74<210>9<211>26<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>9ggaggtctaggctggagctgatccag26<210>10<211>51<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>10cctcgtcccctggttgttctctcaagaaaaagtatgcgtgatcattttgtc51<210>11<211>22<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>11agagaacaaccaggggacgagg22<210>12<211>27<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>12gtccacatagtcctccagagagagaag27<210>13<211>27<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>13gacccaagtccagttcccaacaaccac27<210>14<211>50<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>14cctcgtcccctggttgtcctctcaagagaggagggagtgtgagcttttcc50<210>15<400>15000<210>16<211>27<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>16agaggacaaccaggggacgaggggctc27<210>17<211>27<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>17gcatggggaaggggcattgtatgtagg27<210>18<211>26<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>18cagatcacactgtctgctcacttcac26<210>19<211>27<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>19aaggcagcaggatggaagctgatgtcg27<210>20<211>124<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多核苷酸”<400>20gctggagggcaacacaggaaagatgtgggaataagtttactagtcatacaggcaggaacc60ccaggcccagaggtagtgtccctgtgggagggtctcttgcgcacacaccgcagggtaata120actg124<210>21<211>91<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>21gatttaaatgtcaattggtgagtcttctggggcttcctacatacaatgccccttccccat60gcgcagttatctatgctgtctcaccatagag91<210>22<211>39<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>22atgagcagcaccctctcgttgaccaaggctgactatgaa39<210>23<211>33<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>23caggtgtgcccatccagctgagttaaggtggag33<210>24<211>39<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>24caggaccaggacacctgcagcagctggcaggaagcaggt39<210>25<211>33<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>25aacagccatttgcagaccaaagggaaggaaaga33<210>26<211>42<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>26ttctaccctggtgttatgacagtggtctggaaggcagatggt42<210>27<211>22<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>27atggactggacctggaggatcc22<210>28<211>22<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>28atggactgcacctggaggatcc22<210>29<211>20<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>29tccacgctcctgctgctgac20<210>30<211>23<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>30gctacacactcctgctgctgacc23<210>31<211>21<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>31atggagtttgggctgagctgg21<210>32<211>20<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>32atggaattggggctgagctg20<210>33<211>22<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>33atggagttgggactgagctgga22<210>34<211>21<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>34atggaatttggcctgagctgg21<210>35<211>21<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>35atgcagtttgtgctgagctgg21<210>36<211>21<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>36tgaaacacctgtggttcttcc21<210>37<211>21<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>37tgaagcacctgtggttcttcc21<210>38<211>21<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>38tcatcttcctgcccgtgctgg21<210>39<211>30<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成引物”<400>39gctttcagtgatggtcagtgtgcttatgac30<210>40<211>48<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>40actactttgactacyggggccagggaaccctggtcaccgtctcctcag48<210>41<211>15<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成肽”<220><221>variant<222>(5)..(5)<223>/置换="arg"<220><221>其它特征<222>(5)..(5)<223>/注="序列中给定的残基相对于所述位置批注的残基不具有偏好"<400>41tyrpheasptyrtrpglyglnglythrleuvalthrvalserser151015<210>42<211>52<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>42gctgaatacttccagcaccggggccagggcaccctggtcaccgtctcctcag52<210>43<211>53<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>43ctactggtacttcgatctccggggccgtggcaccctggtcactgtctcctcag53<210>44<211>50<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>44tgatgcttttgatatccggggccaagggacaatggtcaccgtctcttcag50<210>45<211>48<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>45actactttgactaccggggccagggaaccctggtcaccgtctcctcag48<210>46<211>51<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>46acaactggttcgacccccggggccagggaaccctggtcaccgtctcctcag51<210>47<211>63<212>dna<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成寡核苷酸”<400>47attactactactactactacatggacgtccggggcaaagggaccacggtcaccgtctcct60cag63<210>48<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>48gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045serthrvalserglythrglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleutyr65707580leuglnmetasnserleuargalagluaspthralavaltyrtyrcys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>49<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>49gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045seralaileserglyserglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnargleutyr65707580leuglnmetasnserleuargalagluaspthralavaltyrtyrcys859095alalysaspargpheglyserglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>50<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>50gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045serthrvalserglyserglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleutyr65707580leuglnmetasnserleuargalagluaspthralavaltyrtyrcys859095alalysasplystrpglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>51<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>51gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045serthrvalserglythrglyglyserthrtyrtyralaaspserval505560glnglyargphethrileserargaspasnserlysasnthrleutyr65707580leuglnmetasnserleuargalagluaspthralavaltyrtyrcys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>52<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>52gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045seralaileserglyserglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleuser65707580leuglnmetasnserleuargalagluaspthralavaltyrphecys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>53<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>53gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrpheserasntyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045seralavalserglyserglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleuser65707580leuglnmetasnserleuargalagluaspthralavaltyrphecys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>54<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>54gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrpheserasntyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045serthrvalserglythrglyglyserthrtyrtyralaaspserval505560glnglyargphethrileserargaspasnserlysasnthrleutyr65707580leuglnmetasnserleuargalagluaspthralailetyrtyrcys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>55<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>55gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametasntrpvalargglnalaproglylysglyleuglutrpval354045seralaileserglyserglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleutyr65707580leuglnmetasnserleuargalagluaspthralavaltyrsercys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>56<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>56gluvalglnleuleugluserglyglyglyleuvalglnproglyglu151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametsertrpvalargtrpalaproglythrglyleuglutrpval354045serthrvalserglyserglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleutyr65707580leuglnmetasnserleuargalagluaspthralaglutyrtyrcys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>57<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>57gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglypheasnphesersertyr202530alametsertrpvalargglnalaproglylysglyleuglutrpval354045seralaileserglyserglyglyargthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleuser65707580leuglnmetasnserleuargalagluaspthralavaltyrsercys859095alalysaspargpheglythrglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120<210>58<211>120<212>prt<213>人工序列<220><221>来源<223>/注=“人工序列的描述:合成多肽”<400>58gluvalglnleuleugluserglyglyglyleuvalglnproglygly151015serleuargleusercysalaalaserglyphethrphesersertyr202530alametsertrpvalargleualaproglylysglyleuglutrpval354045serthrvalserglythrglyglyserthrtyrtyralaaspserval505560lysglyargphethrileserargaspasnserlysasnthrleutyr65707580leuglnmetasnserleuargalagluaspthralavaltyrsercys859095alalysaspargpheglyserglythrasnpheasptyrtrpglygln100105110glythrleuvalthrvalserser115120当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1