生物可获得的预测工具的制作方法
相关申请案的交叉参考
本申请案主张对2017年2月15日申请的第62/459,558号美国临时申请案的优先权,所述美国申请案以其全文应用方式并入本文中。
政府利益声明
本发明在美国政府的支持下依据由darpa授予的第hr0011-15-9-0014号协议进行。政府对本发明享有一定的权利。
本发明大体上涉及改进微生物的基因工程设计的方法,且特定来说,涉及通过在无需大量人工干预的情况下识别可在特定微生物中产生的分子集来改进微生物的基因工程设计借此促成例如宿主选择及途径工程设计的过程的方法。
背景技术:
化学家及材料科学家采用合成生物学修饰宿主生物(例如,细菌、酵母或真菌)的基因组以产生所期望化学品。然而,可产生哪些化学品作为微生物中的生物量的部分存在限制。一般来说,会面临确定在无需大量人工干预可通过基因组修饰生成的最大可能的化学品库的问题。此类化学品在本文应称为“生物可获得的”化学品、分子或代谢物。
最先进的生物化学生成技术可大致分为两类:
1)存在被充分理解的靶分子或代谢途径-化学品生产集中于此特定途径,且试图迫使此途径中的化学品可用。
2)尝试以计算方式预测可通过使用已知代谢反应的子集及通过所述子集进行简单跟踪来制造哪些分子。
这些方法容易出错,部分导致十分高的假阳性率。需要在给定一组约束的情况下更准确地预测宿主生物能够在生物学上生成的化学品的方法。
技术实现要素:
本发明提供一种用于以克服常规技术的缺点的方式预测可行靶分子的生物可获得的预测工具。特定来说,本发明的生物可获得的预测工具预测特定于指定宿主生物的可行靶分子。
本发明的实施例的生物可获得的预测工具获得指定宿主生物的开始代谢物的开始代谢物集。在实施例中,开始代谢物集指定核心代谢物,核心代谢物包含由至少一个数据库指示为由未经工程设计的宿主在指定条件下产生的代谢物。在实施例中,宿主尚未经受基因组修饰。
在实施例中,生物可获得的预测工具获得指定反应的开始反应集。在实施例中,工具将来自开始反应集的在至少一个数据库中指示为通过一或多个对应催化剂(例如,酶)催化的一或多个反应包含于经筛选反应集中,所述催化剂本身指示为可能可用于催化在宿主生物中可发生的一或多个反应。
如果生物可获得的预测工具从(例如)公共或专属数据库确定指示催化剂可通过将催化剂工程设计到宿主中(例如,通过修饰宿主基因组)或经由从宿主在其中生长的生长培养基摄取催化剂而引入到宿主中的信息,那么催化剂有可能“可用于催化”宿主生物中的反应。
更明确来说,当宿主生物的基因组被修饰(例如,经由插入、删除、替换)使得宿主生物产生催化剂(例如,酶蛋白)时,本发明将一部分(例如所述催化剂)称为“经工程设计”到宿主生物中。然而,如果所述部分本身包括基因材料(例如,用作酶的核酸序列),那么使那个部分“经工程设计”到宿主生物中是指修饰宿主基因组以体现那个部分本身。
如果生物可获得的预测工具确定指示一部分可经工程设计到宿主中的信息,那么所述部分有可能“可用于经工程设计”到宿主生物中。举例来说,根据实施例,如果由所述工具存取的公共或专属数据库指示(例如,经由注释)酶指示为对应于已知氨基酸序列,那么所述工具可确定指示酶有可能可用于经工程设计到宿主中的信息。如果氨基酸序列是已知的,那么技术人员可能能够导出用于编码氨基酸序列的对应基因序列及相应地修饰宿主基因组。
在此上下文中且在技术方案中,“有可能”意味着比不可能更有可能,即,具有大于50%的可能性。
在一或多个处理步骤中的每一处理步骤中,生物可获得的预测工具依照经筛选反应集的一或多个反应处理表示开始代谢物及在先前处理步骤中生成的代谢物的数据以生成表示一或多个可行靶分子的数据。所述工具将表示一或多个可行靶分子的数据提供为输出。
在实施例中,生物可获得的预测工具确定关于对应催化剂是否可用于在宿主生物中催化一或多个反应(例如,可用于经工程设计到宿主生物中以催化一或多个反应)的置信度。置信度可包含(例如)至少一第一置信度或高于第一置信度的第二置信度。所述工具可将来自开始反应集的在至少一个数据库中指示为通过一或多个对应催化剂催化的一或多个反应包含于经筛选反应集中,所述一或多个对应催化剂本身确定为在第二置信度下可用于在宿主生物中催化一或多个反应(例如,经确定为在第二置信度下可用于经工程设计到宿主生物中以催化一或多个反应)。
在本发明的实施例中,生物可获得的预测工具生成产生可行靶分子中的一或多者的难度的指示。所述难度指示可基于热力学性质、一或多个可行靶分子的反应途径长度或关于催化剂是否可用于催化沿到可行靶分子中的一或多者的一或多个第一反应途径的一或多个对应反应的置信度。
在本发明的实施例中,在于特定处理步骤中生成表示一或多个可行靶分子的数据之后且在下一处理步骤之前,生物可获得的预测工具从经筛选反应集移除与在特定处理步骤中生成表示一或多个可行靶分子的数据相关联的任何反应。
在实施例中,所述工具生成导向每一可行靶分子的一或多个反应途径(即,系谱)的记录。在实施例中,生成记录包括不将来自普遍存在的代谢物的反应途径包含于记录中。在实施例中,所述工具生成其中生成表示可行靶分子的数据的步骤的记录。在实施例中,所述工具生成从开始代谢物集到每一可行靶分子的最短反应途径的记录。
代替在给定单个宿主生物的情况下确定可行靶分子,可期望识别其中将产生给定可行靶分子的一或多个宿主生物。举例来说,客户可请求工具的用户确定多个宿主内的其中产生靶分子的最优宿主生物。在实施例中,生物可获得的预测工具针对多个宿主生物运行,且根据本文描述的方法中的任何者针对多个宿主生物中的每一宿主生物生成表示一或多个可行靶分子的数据。在此类实施例中,针对给定可行靶分子,所述工具确定多个宿主生物中满足至少一个准则的至少一者,所述准则例如由给定宿主生物产生的可行靶分子的给定经预测产量,或预测为在给定宿主生物中产生给定可行靶分子所必需的处理步骤的给定数目。所述工具将表示确定为满足至少一个准则的宿主生物的数据提供为输出。
如针对上述实施例描述,所述工具可生成导向由每一宿主生物产生的每一靶分子的一或多个反应途径(即,系谱)的记录,所述记录包含(例如)热力学性质。基于针对多个宿主生物运行工具的上述实施例,所述工具可将宿主生物、靶分子与系谱之间的关联存储于数据库中作为库,其可包含指定参数(例如产量、处理步骤的数目、催化剂在反应途径中催化反应的可用性等)的注释。
在实施例中,如果所述工具可存取此库,那么无需运行所述工具来识别其中产生给定可行靶分子的多个宿主生物。代替地,在此类实施例中,所述工具可使用来自库的系谱,其可包含关于宿主、靶分子与反应之中的关联的注释数据。所述工具可至少部分基于来自(例如)公共或专属数据库或来自库的经预测在引起在至少一个靶宿主生物中产生靶分子的至少一个反应途径中催化反应的所有催化剂很可能对催化所有此类反应有用的证据识别来自一或多个宿主生物之中的至少一个靶宿主生物。在实施例中,所述工具可基于靶宿主需要比经预测为产生靶分子所必需的反应途径内的反应步骤的阈值数目少的反应步骤来确定靶宿主。
一些反应酶可能不具有已知相关联的氨基酸序列或基因序列(“孤儿酶”)。在此类情形中,所述工具可生物勘探孤儿酶以预测其氨基酸序列,且最终,预测其基因序列,使得最新排序的酶可经工程设计到宿主生物中以催化一或多个反应。所述工具可包含对应于最新排序的酶的反应作为经筛选反应数据的成员。
在实施例中,生物可获得的预测工具将与导向可行靶分子的反应途径中的一或多个反应相关联的一或多个基因序列的指示提供到“工厂”(例如,基因制造系统)。在实施例中,基因制造系统将经指示基因序列体现到宿主的基因组中,借此产生用于制造靶分子的经工程设计的基因组。在实施例中,所述工具将用于工厂的一或多个催化剂的指示提供到工厂以将一或多个催化剂引入到宿主生物的生长培养基中以产生靶分子。
在实施例中,生物可获得的预测工具至少部分基于一或多个反应是否是自发的、至少部分基于其方向性、至少部分基于一或多个反应是否是传递反应或至少部分基于一或多个反应是否生成卤素化合物将来自开始反应集的反应包含于经筛选反应集中。
在本发明的实施例中,生物可获得的预测工具获得指定宿主生物的开始代谢物的开始代谢物集,且获得指定特定于宿主的反应的开始反应集。在本发明的实施例中,生物可获得的预测工具将在至少一个数据库中指示为自发的一或多个反应包含于经筛选反应集中。在一或多个处理步骤中的每一处理步骤中,所述工具依照经筛选反应集的一或多个反应处理表示开始代谢物及在先前处理步骤中生成的任何代谢物的数据以在每一步骤中生成表示一或多个可行靶分子的数据。在实施例中,所述工具将表示一或多个可行靶分子的数据提供为输出。
附图说明
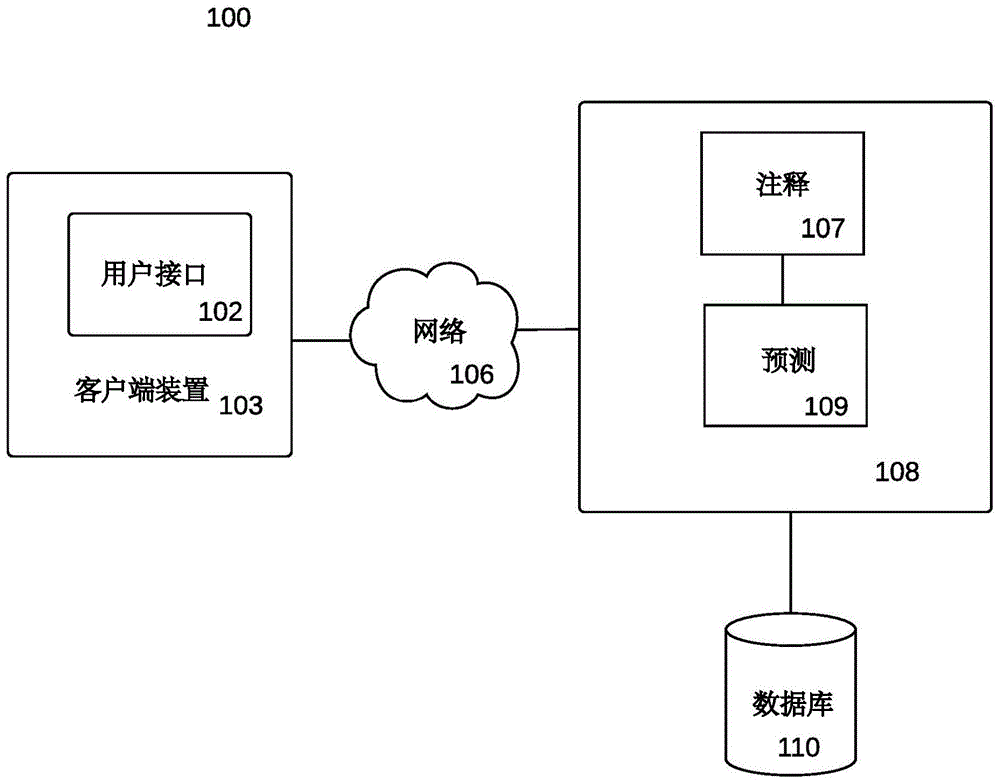
图1说明根据本发明的实施例的用于实施生物可获得的预测工具的系统。
图2是说明根据本发明的实施例的生物可获得的预测工具的操作的流程图。
图3说明根据本发明的实施例的用于实施严格及宽松的酶序列搜索的伪代码。
图4说明可由本发明的实施例的生物可获得的预测工具生成的报告的实例。
图5说明可由本发明的实施例的生物可获得的预测工具生成的反应系谱跟踪的报告的假想实例。
图6说明根据本发明的实施例的云计算环境。
图7说明根据本发明的实施例的可用于执行非暂时性计算机可读媒体(例如,存储器)中存储的指令的计算机系统的实例。
图8说明可由本发明的实施例的生物可获得的预测工具生成的类型的单个途径的实例。在此实例中,预测分子酪胺是可通过将单个酶促步骤添加到宿主生物获得的。已减少此途径以实践且已将此途径工程设计到宿主生物中以产生酪胺。此途径的评估分数附在反应图的末尾。
图9说明可由本发明的实施例的生物可获得的预测工具生成的类型的两个不同途径的实例。在此实例中,两个途径由生物可获得的预测工具识别为能够生成生物可获得的分子(s)-2,3,4,5-四氢吡啶二羧酸(tudp)。两个途径因其使用减少等效类型(nadh对nadph)而不同。已减少这些途径中的一者以实践且已将所述一者工程设计到宿主生物中以产生tudp。每一途径的评估分数附在反应图的末尾。
图10说明可由本发明的实施例的生物可获得的预测工具生成的类型的更复杂的多途径预测的实例。每一途径的评估分数附在反应图的末尾。
图11a及11b一起说明可由本发明的实施例的生物可获得的预测工具生成的评分细分的实例。(图11b附在图11a的底部。)在此案例中,所展示的评估数据在预测到分子(s)-2,3,4,5-四氢吡啶二羧酸(thdp)的途径的过程期间生成。
具体实施方式
参考其中展示各种实例实施例的附图进行本描述。然而,可使用许多不同实例实施例,且因此,所述描述不应理解为限于本文陈述的实例实施例。而是,提供这些实例实施例使得本发明将是详尽且完整的。所属领域的技术人员将容易地明白对示范性实施例的各种修改,且本文定义的通用原理可应用于其它实施例及应用而不会背离本发明的精神及范围。因此,本发明不希望限于展示的实施例,但应符合与本文揭示的原理及特征一致的最宽范围。
发明者已认识到,用于预测可行靶分子的常规方法会遭遇以下障碍:
1)缺乏生物部分。这是关于可在生物学上生成的化学品的假阳性预测的单个最大原因。一些常规方法采用现存反应数据库从原料(如葡萄糖)逐步完成所有已知代谢反应,且假设所有路径可经工程设计。然而,许多反应并不对应于可经工程设计到宿主生物中的通用部分。通常,反应通过酶催化。现存数据库中的反应可根据其催化酶良好地特性化,但那些酶中的许多者未将其氨基酸排序,意味着在酶与相关联的基因序列之间不存在经建立相关性。在无基因序列的情况下,宿主基因组不能经修饰以产生所需酶。实际上,大约25%到50%的良好特性化的酶促反应不具有已知相关联的基因序列,且因此那些酶不能用作用于工程设计目的的生物部分。整个生物数据库中的基因缺席反应的百分比很可能甚至更高,这是因为这些数据库包含未良好特性化的许多反应。发明者注意,在一些情形中,可采用除了酶之外的催化剂,例如酶纳米颗粒共轭。参见(例如)威特吉尔aa(vertgelaa)等人的《用于生物医学应用的酶纳米颗粒共轭(enzyme-nanoparticleconjugatesforbiomedicalapplications)》,《分子生物学方法》(methodsmol.bio.)2011;679:165-82;约翰逊pa(johnsonpa)等人的《酶纳米颗粒制造:磁性纳米颗粒合成及酶固定化(enzymenanoparticlefabrication:magneticnanoparticlesynthesisandenzymeimmobilization)》,《分子生物学方法》(methodsmol.biol.)2011;679:183-91,其都以全文引用的方式并入本文中。在那些案例中,将那些催化剂工程工程设计到宿主生物中所需的部分可能是已知的或可能不是已知的。
2)不正确的途径跟踪。许多经尝试的解决方案企图任意地跟踪分子之间的途径。此可导致不能正确地跟踪靶分子的碳骨架的创造。为了引用共同实例,可跟踪从谷氨酰胺到生成靶分子的反应中的路径,且接着可引用谷氨酰胺作为到创造那个靶分子路径的部分。然而,在多数情形中,谷氨酰胺标示氮基团且无碳,所以此跟踪在误导且不指示可制造靶分子(其它错误包含跟踪连接,尽管其它普遍存在的代谢物(例如atp)或无机分子(例如水))。这些类型的途径跟踪错误还导致大量不能再用的经预测途径(就好像映射应用允许通过旧金山(sanfrancisco)的所有可能街道路线,代替两到三条最直接且有用的路径)。
3)假设双向反应。另一重要的错误源是不能考虑反应的热力学/方向。热力学指示一些反应仅可在一个方向上运行。然而,仅使分子a降解到分子b的反应通常通过常规方法预测为在任一方向上运行,使得可不正确地预测分子a可由b合成。作为特定实例,一些细菌分解卤代化合物(例如有机氯),但不能反向运行以创造卤代化合物。因为许多生物反应仅在一个方向上显著有利地运行,所以不能考虑反应方向性也会造成假阳性预测。
4)其它错误。并非每个宿主都可经工程设计以产生每个靶分子,或经工程设计以使用一组相同修饰或以相同成功可能性产生每个靶分子,这是因为并非所有宿主都维持一组相同代谢途径。
本发明的实施例的生物可获得的预测工具(bpt)克服常规方法的限制。本发明的实施例的bpt可以靶不可知的方式描述有可能可在生物上生成的每个化学品(给定一组开始约束,(例如,特定宿主生物、反应步骤的数目、是否仅允许使用基因经排序的酶的反应)。此创建“生物可获得的列表”,即,可行靶化学品的列表。这些靶化学品及其相关联的结构可提供给专业化学家,专业化学家可审阅分子的化学效用而无须考虑创造所述分子所需的生物。在选择特定生物可获得的靶化学品之后,可将其化学式及反应途径提供到基因制造系统以修饰宿主生物的基因序列以产生所选择的靶分子。
系统设计
图1说明本发明的实施例的分布式系统100。用户接口102包含客户端侧接口,例如文本编辑器或图形用户接口(gui)。用户接口102可驻留在客户端侧计算装置103处,例如膝上型或桌上型计算机。客户端侧计算装置103通过网络106(例如因特网)耦合到一或多个服务器108。
服务器108在本地或远程地耦合到一或多个数据库110,数据库110可包含一或多个集合的分子、反应及序列数据。反应数据可表示一组所有已知的代谢反应。在实施例中,反应数据是通用的,即,并非宿主特定的。
分子数据包含关于代谢物的数据,所述代谢物—反应数据中所含的反应中涉及的反应物,其作为底物或产物。在实施例中,关于代谢物的数据包含关于所属领域中已知的将在特定宿主微生物中产生的宿主特定代谢物的数据,例如核心代谢物。在一些实施例中,通过由发明者收集的经验证据确定一些核心代谢物是由特定宿主产生。这些宿主特定代谢物集通过各种方法(例如宿主生物的代谢组学分析)或通过识别在某些生长条件下是必需的酶编码基因及推断存在由通过那些基因编码的酶产生的代谢物来识别。分子数据可用表示许多特征的注释标记,所述特征例如宿主生物、生长培养基特性及分子是核心代谢物、是前体、是普遍存在的还是无机的。
数据库110(例如,uniprot)还可包含关于催化剂是否可经由从宿主在其中生长的生长培养基摄取催化剂而被引入到宿主生物中的数据。
序列数据可包含用于反应注释引擎107的数据,所述数据用于关于反应是否有可能已知为对应于用于将反应工程设计到宿主生物中的序列(例如,酶或基因序列)来注释反应数据集中的反应。举例来说,序列数据可包含用于关于反应是否由酶催化来注释反应数据中的反应的数据,对于所述酶来说氨基酸序列有可能是已知的。如果是这样的话,那么通过所属领域中已知的方法,可确定用于编码酶的基因序列。在实施例中,出于确定生物可获得的靶分子的目的,反应注释引擎107无需知道序列数据本身,而是仅知道序列是否有可能已知为针对催化剂存在。下文描述的反应注释引擎107可编译来自数据库(例如uniprot)的序列数据,所述数据库包含催化指示为具有相关联的编码序列的反应的酶的序列数据。
在实施例中,服务器108包含反应注释引擎107及生物可获得的预测引擎109,其一起形成本发明的实施例的生物可获得的预测工具。替代地,用于注释引擎107、预测引擎109或两者的软件及相关联的硬件可在本地驻留在客户端103处而非驻留在服务器108处,或分布于客户端103与服务器108两者之间。数据库110可包含公共数据库,例如uniprot、pdb、brenda、bkmr及mnxref,以及由用户或其他人生成的定制数据库,例如包含经由由用户或第三方贡献者执行的合成生物学实验生成的分子及反应的数据库。数据库110可在本地或相对于客户端103在远程处或既在本地分布又远程分布。在一些实施例中,注释引擎107可运行为基于云的服务,且预测引擎109可在本地在客户端装置103上运行。在实施例中,供任何本地驻留引擎使用的数据可存储于客户端装置103上的存储器中。
系统操作
获得开始代谢物列表及开始反应数据集
到生物可获得的预测过程的输入包含信息(例如开始代谢物列表、开始反应列表、宿主生物及基线条件(例如宿主(例如,基本或丰富的生长培养基)的燃料液面))及环境条件(例如温度)。注释引擎107可连同来自数据库110的相关联的注释一起组装代谢物及反应数据。
通过用户接口102,用户可指定从其获得开始代谢物及反应列表的信息的数据库110。举例来说,反应及宿主特定代谢物可从公共数据库(例如kegg、uniprot、bkmr及mnxref)获得。(所属领域的技术人员应从论述的上下文认识到,此说明书中对“代谢物”、“反应”及类似物的参考及对“代谢物”、“反应”及类似物的主张实际上在许多例子中可能是指表示那些物理对象或过程的数据而非物理对象或过程本身。)
开始代谢物列表
参考图2,在实施例中,反应注释引擎107从数据库110获得或本身聚合宿主特定开始代谢物文件,所述文件包括期望在宿主生物在给定生长条件下在特定时间或在特定时间间隔期间的生长期间存在的化学化合物(开始、中间及最终产物)的列表(202)。默认生长条件可为基本生长培养基,这是因为此是用于选择开始代谢物的最保守方法。在实施例中,反应注释引擎107可将代谢物文件作为开始代谢物列表提供到预测引擎109。
在实施例中,反应注释引擎107可基于宿主生物或类似生物的生长数据确定或模板化(从类似微生物)开始代谢物。此方法类似于用于注释系统(例如rast系统)中的微生物的基因组或预测biocyc数据库集合中的代谢途径的方法。此方法使用给定宿主生物的基因组注释以进行在何处存在代谢途径的最佳推测,且接着,假设在那些途径中存在所有组成反应及其代谢物。在biocyc数据库的案例中,现存基因组注释用于识别个别酶(且因此其反应)的推定存在。接着,基于规则的系统用于基于其取代反应(的部分)的存在推断全部代谢途径的存在。
具有特定于宿主生物的开始代谢物列表是本发明的实施例的区别性开始点。然而,其它常规方法进行关于可制造的靶的基因预测,本发明的实施例的此可定制步骤避免由于宿主生物的生物学差异而做出关于可制造哪些靶分子(或可如何制造所述靶分子)的不正确预测的问题。
在实施例中,用户可指示反应注释引擎107基于查询具有参数(例如宿主生物及生长培养基)的现存数据库或数据集(例如mnxref、kegg或bkmr)且在一些实施例中经由交叉索引那些数据库与相关模型生物数据库或特定代谢物的存在的其它指示从所述数据库或数据集检索开始代谢物。到目前为止,针对特定工业宿主,受让人已创建关于大约200到300种代谢物的典型的开始代谢物文件。如上所述,表示公共数据库及由注释引擎107形成的列表中的代谢物的数据对象可包含注释,包含元数据,例如宿主生物、生长培养基类型及代谢物是否是核心代谢物、前体、无机的或普遍存在的。
核心代谢物是在给定基线条件(例如生长培养基的丰富度)下在基因方面未经修饰的微生物中天然发现的开始(例如,底物)、中间及最终代谢物培养基。微生物(如大肠杆菌)的生物量中的每一核心代谢物(例如,氨基酸)可在细胞的核心代谢物中从十一种前体代谢物中的一者生成,且在根本上可从提供到在基因方面未经修饰的生物的无论什么碳输入生成。在实施例中,用户可选择从数据库(例如mnxref、kegg、chebit、reactome或其它)选择用其前体相依性标记的核心化合物的开始代谢物集。
顾名思义,无机代谢物(例如铵)不包含碳,且因此不能向新陈代谢的新产物贡献碳原子。因此,反应注释引擎107可从开始代谢物集排除无机代谢物。
一些代谢物是普遍存在的,即,其发现于许多反应中。其包含分子,如atp及nadp。通常,普遍存在的分子不会向靶产物贡献碳,且因此不是到靶的任何代谢途径的部分。因此,反应注释引擎107可从开始代谢物集排除普遍存在的代谢物。可基于专家评估在注释中手动指定普遍存在的分子,或通过确定哪些分子参与超过特定阈值数目的反应来识别普遍存在的分子。一种启发法以大于典型的核心代谢物输入的大小的数字(例如,300)标记反应集中出现的所有分子。举例来说,在一个数据集中,atp在大约31,000反应的2,415个反应中出现,nadh在2,000个反应中出现,且nadph在3,107个反应中出现,这使其超过核心代谢物计数且将其全都标记为“是普遍存在的”。
开始反应数据集
反应注释引擎107获得开始反应数据集作为用于预测可行靶分子的基础(204)。用户可指定如何构建开始反应数据集,或用户可指示注释引擎107直接从公共数据库110或专属数据库110(例如由用户或其他人先前创建的定制数据库)获得数据。在一个实施例中,注释引擎107可从mnxref的metanetx反应命名空间(mnx)导入完整反应集(大约30,000个反应)。在其它实施例中,注释引擎107可从metacyc及kegg或其它公共或私有数据库导入且合并反应集(总共大约22,000个反应)。
在实施例中,反应注释引擎107可通过选择性地聚合从数据库110获得的信息构建开始反应数据集。举例来说,bkmr提供反应是否是自发的信息。注释引擎107可使用已知映射将bkmr反应id映射到对应反应的mnxref中的id。在其它实例中,可代替bkmr及其id而采用kegg或metacyc及其id。接着,使用此关联,反应注释引擎107可使用来自mnxref(例如,核心、普遍存在)的现存注释以及来自bkmr的对应自发反应标签在数据库110中创建定制反应列表。类似地,通过映射对应id,注释引擎107可使mnxref中的反应与uniprot中的注释相关联以获得反应是否是传递反应或反应底物或产物是否含有卤素的标签,且针对数据库110中的定制反应列表中的反应将那些标签并入到注释中。(识别卤代化合物是一种用于识别在错误方向上运行的反应的启发法,这是因为多数卤素相关反应涉及分解化学品。)
沿着这些线,反应注释引擎107可使用跨数据库相关联的id以聚合来自数据库的数据以用定制注释构建存储开始反应集的数据库110,例如反应是否是自发的、是否由于热力学而在仅一个方向上运行、是否含有卤素(与确定方向性相关)、是否含有普遍存在的代谢物、是否是传递反应、是否是不平衡的(即,化学反应的两边不能维持元素平衡,表明反应被不正确地写入于源数据库中且应被忽略)、在可用数据库中是否被不完全特性化、是否与酶相关联(所述酶用与已知氨基酸序列或编码酶的基因序列相关联的指示符标记)、或是否通过有可能具有跨膜区的源酶催化以及其它标签。举例来说,通过注释引擎107,用户可因此将注释指派到mnxref数据库中的全部大约30,000个反应。如下文描述,接着,用户可针对每一注释特征或其任何组合配置准则以将此主文件筛选到个别列表中。
生物可获得的分子预测
参考图2的流程图,下文描述本发明的实施例的预测引擎109的操作的实例。预测引擎109预测哪些化学品可经由(例如)基因工程在任意选择的宿主生物中创造出来。预测引擎109可将输入当作开始代谢物文件、开始反应数据集及序列数据库。序列数据库可存储催化化合物(例如酶)的氨基酸序列或编码催化化合物的基因序列。在实施例中,本发明的实施例的bpt使用序列数据库确定存在或缺少用于每一反应的氨基酸序列或基因序列。在此类实施例中,序列数据库无需包含序列本身,只要催化剂被标记为具有酶或可用通用部分或不具有酶或可用通用部分。与生物可获得分子的列表一起,预测引擎109产生引起从开始代谢物(例如,在一些实施例中,宿主的核心代谢物)产生每一可获得的靶分子的反应的指定宿主生物“系谱”(反应途径)。
特定来说,预测可基于若干参数进行调谐,例如催化剂催化反应的可能可用性(例如,经工程设计到宿主生物中的通用部分的可能可用性或催化剂经由从宿主生物在其中生长的生长培养基的摄取被引入到宿主生物中的可能可用性)、允许的反应步骤的最大数目(从开始代谢物开始)、将被允许的部分或化学反应的类型及其它可选择的特征。预测引擎109还帮助通过预测从核心代谢物到每一靶分子的潜在路径预测设计靶分子的方法及难度。
经筛选反应数据集
在实施例中,预测引擎109创建经筛选且经验证反应数据集(rds)。使用通过反应注释引擎107特性化的反应,预测引擎109可将反应筛选到所期望的验证级别,例如反应酶的编码序列存在的置信度(206)。这是精细调谐预测的准确度中的且用于控制假阳性预测的主要源的步骤。在上文提及的实例中,发明者通过从mnxref的metanetx反应命名空间(mnx)导入及注释完整反应集(大约30,000个反应)生成用于一个生物可获得的列表的rds。类似方法可应用于其它公共可用的反应数据库,例如kegg、reactome及metacyc。
基于发明者的经验,最流行的公共数据库中的25%到50%的反应可能不具有任何已知的相关联的生物部分。举例来说,用于催化反应的酶的氨基酸序列或其伴随的基因序列可能是未知的。在无酶序列信息的情况下,生物反应器将不能执行采用那些酶的反应,因此使反应信息对工程设计目的无用。即使途径内的仅一个酶缺少已知基因序列,整个途径也不能被工程设计到宿主中。
为了处理此缺乏,预测引擎109可通过使用公共可用或定制酶数据的一系列验证测试筛选反应。一个公共数据库是uniprot,其是大的、开放存取的且被可靠地组织。其它者包含pcsb蛋白质数据库(pdb)及genbank。在一些公共数据库中,例如mnxref、uniprot、brenda或pdb,反应可用酶学委员会(ec)编号标记,其是基于其催化的反应的酶的数值分类。一些数据库,例如uniprot或pdb仅存储针对其编码催化酶的基因序列是已知的反应的ec数字标签。其它数据库,例如kegg及metacyc,包含针对其基因序列是未知的酶的ec编号。
因此,取决于数据库,ec编号可指示或可不指示存在已知酶基因序列。近似地,具有ec编号的20%到25%的反应不具有相关联的酶编码序列。在一些案例中,ec编号用于注释多个特定化学转变(在ec编号与化学反应之间存在一对多关系),使得存在与ec编号相关联的酶序列并不意味着与那个ec相关联的每个反应都具有有效相关联的序列。因此,存在关于酶活性的ec标签不是存在那个酶的基因序列的可靠的通用指示符,但其可应用于某些数据库以确定是否有可能合理地存在那个酶的序列。一些数据库还具有将特定化学反应明确描述为已知由给定氨基酸序列(因此具有用于编码酶催化剂的已知基因序列)明确催化的特定化学反应的单独字段(例如,uniprot中的“催化活性”字段)。此类反应在本文称为注释为“明确排序”。
预测引擎109可确定关于催化剂是否可用于在宿主生物中催化反应(例如,可用于被工程设计到宿主生物中以催化反应)的置信度。举例来说,基于酶编码序列是已知的确定性中的差异,预测引擎109可在一些实施例中针对反应数据集中的注释执行对酶编码序列的“严格”搜索或“宽松”搜索。对于严格搜索,预测引擎109可仅选择(例如)注释为被明确排序的反应。
对于宽松搜索,预测引擎109可从自数据库(例如metacyc)导出的注释选择(例如)注释为具有与已知酶编码序列相关联的ec编号的反应或在序列数据库中注释为“被明确排序”的(布尔非排他性或)反应。预测引擎109针对任一置信度记录是否发现用于反应的任何基因或氨基酸序列。举例来说,预测引擎109可用指示其满足宽松搜索而非严格搜索的标签注释反应。
图3说明根据本发明的实施例的用于对数据库(例如mnxref及uniprot)实施严格及宽松酶序列搜索的示范性伪代码。伪代码描述由启发法使用的用于确定酶的序列是否存在的逻辑。此实施例提供四种置信度。代码展示首先确定反应数据集注释是否包含至少一个ec编号。如果是这样的话,那么代码要求针对ec编号搜索序列数据库。如果进行了严格搜索,那么代码要求针对被明确排序的反应搜索序列数据库。如果进行了宽松搜索,那么代码将具有相关联的ec编号的反应的宽松注释标签设置为真。
如果初始步骤确定反应数据集注释(a)不包含ec编号或(b)(如上文提及)ec序列搜索发现序列数据库中的ec编号且进行了严格搜索,那么代码要求针对被明确排序的反应的序列搜索数据库。如果那个搜索发现如被明确排序的反应,那么代码将那个反应的严格及宽松注释两者设置为真。如果不是这样的话,那么代码将那个反应的那些注释设置为假。
总而言之,此启发法的输出是每一反应的两个注释标签:严格及宽松。此启发法提供四种置信度,如下文描述:
严格=真→序列存在的置信度非常高
严格=假→序列不存在的置信度中等(预期一些假阴性)
宽松=真→序列存在的置信度中等(预期一些假阳性)
宽松=假→序列不存在的置信度非常高
发明者已发现,运行宽松搜索导致小于20%的假阳性率,而针对uniprot中的催化活性字段运行严格搜索导致显著假阴性率。因此,在宽松搜索方面稍微犯错可为较佳的。“宽松”及“严格”标签仅是处理基于序列的筛选的两种潜在方法。bpt适合任何基于序列的标记(且因此筛选)方法,包含:更宽容的方法,例如识别存在具有用于靶活力的适当基序的序列;或更严格的方法,例如需要在精心组织的数据库(例如metacyc)中存在直接支持文献的活性序列链接。
作为基于序列的筛选的替代或除了基于序列的筛选之外,预测引擎109可基于上文关于注释引擎107论述的注释的任何组合来筛选(即,选择或不选择)反应,例如反应方向性或反应是否是自发反应、传递反应或是否含有卤素。预测引擎109可基于用户配置通过用户接口102或默认设置执行筛选。在实施例中,预测引擎109可沿模拟代谢途径在不同反应步骤中应用不同筛选器。作为默认设置的实例,其可为:反应具有基于宽松准则的序列;排除所有传递反应;如果反应具有序列,那么仅包含含有卤素的反应;包含所有自发反应,不论上述属性为何。
如果反应是自发的,反应将自动发生,而无需工程设计宿主基因组以产生酶来催化自发反应。因为已知反应在针对给定宿主的给定条件下发生,所以预测引擎109可预测将产生自发反应产物。
如上所述,无机分子不会贡献碳,且普遍存在的分子不可能将碳贡献到目标代谢物。因此,从用作开始代谢物的那些分子消除普遍存在且无机的分子启发式地提供在预测可行靶分子时预测引擎109将依循有效代谢途径的较高置信度。因此,预测引擎109不将普遍存在的分子或无机分子视为在反应中受限制。也就是说,假设其始终可用于其参与的反应。
代谢物预测
参考图2,给定根据经筛选rds中的反应处理的输入代谢物的底物,预测引擎109可执行逐步模拟以预测将形成哪些代谢物(208)。(化学反应在输入“底物”(例如,一组分子)上操作以产生化学产物。)本发明的实施例的预测引擎109的操作可如下描述:
步骤0:最初,仅核心代谢物存在于模拟宿主生物中。其在下一步骤中形成用于反应的当前底物。
步骤1:预测引擎109确定来自步骤0的核心代谢物是否匹配经筛选反应集(rds)内的化学方程式中的任何者的一边,以及反应是否可在给定方向上发生(基于方向/热力学注释)以借此确定会发生哪种反应以在反应方程式的另一边上产生化学品(208)。预测引擎109确定发生的反应是否产生任何新的代谢物(210)。
如果预测引擎109确定已预测到无新的代谢物(210),那么预测引擎109结束预测过程且报告结果(212)。
相反地,如果预测引擎确定会形成新的代谢物(210),那么预测引擎109将新的代谢物添加到底物池(214)。更新的底物池现包含核心代谢物及来自步骤1的最新预测的代谢物。
预测引擎109记录每一步骤中的代谢物及发生的反应,且还从经筛选rds移除发生的反应(步骤216)。此移除防止在后续步骤中发生相同反应,以借此避免反应及其所得代谢物被识别为存在于后续步骤中。贯穿过程的所有步骤,仅模拟每一反应一次。此与工程设计通常集中于到达代谢物的最短路径(最少数目个步骤)的最佳实践一致-到相同代谢物的较长途径通常是次优的。与每一步骤内的代谢物及反应一起,预测引擎109记录在其中制造代谢物(即,预测为将制造)的步骤。那个步骤表示生成代谢物的代谢路径长度。注意,如果代谢物经由不同反应创造,那么其可作为产物出现在多个步骤中。此事实允许预测引擎有用地识别不同途径,其中相同代谢物通过不同反应获得。
步骤2:接着,预测引擎109返回到步骤208,使用代谢物的现在经更新的底物池作为输出以针对经筛选rds(其中现已移除发生的反应)运行以预测是否会发生任何反应以产生新的代谢物。
在多次迭代之后,代谢物池生长而可用反应池缩减。最终,过程可运行到饱和,这是因为没有留下可引发保留在经筛选rds中的反应的更多代谢物。在由发明者进行的实验中,大约10,000个经筛选反应可在所有迭代之后导致数千种代谢物。替代地,预测引擎109可经配置以在停止预测及报告结果之前指定允许的反应步骤数目(212)。关于反应步骤数目的限制反映真实世界工程设计,其通常会限制循环的数目。
图4及5说明可通过本发明的实施例的生物可获得的预测工具生成的报告的实例。图4展示针对每一处理步骤生成的代谢物(生物可获得的命名)、其化学式、代谢物类型(例如,通过反应产生的核心、前体、候选生物可获得)、由唯一反应id(例如众所周知的数据库中使用的id)标示的代谢物的反应系谱(其还展示反应的左(“l”)或右(“r”)边是否发生)、从最近的核心代谢物产生候选生物可获得的分子所需的反应步骤数目及每一候选生物可获得的分子的最近核心代谢物的命名。注意,步骤0中仅有的分子是来自开始代谢物列表(例如,核心、前体)。
图5说明反应系谱跟踪的假想实例。逐步反应如下:
步骤1:a+b←→c+d
步骤2:c+b←→e+f
步骤3:d+e←→g+h
此实例中的属性包含:所述步骤中生成的代谢物是否是核心;在其中发现代谢物的步骤;到所生成的代谢物的最近核心代谢物,如按以步骤数目计的距离测量;及标示经发生产生代谢物的化学反应的反应系谱。代谢物a是核心代谢物,且b是在步骤0处在宿主的生物量中存在的前体代谢物。因此,其不具有反应系谱。
c及d展示为在步骤1中通过反应系谱(source_reaction)中的反应a+b产生。到c及d两者的最近核心是a。c及d与核心a及b一起添加到底物。
e及f展示为在步骤2中通过反应c+b产生。到e及f两者的最近核心是a。e及f与核心a及b及生物可获得的产物c及d一起添加到底物。
g及h展示为在步骤3中通过反应d+e产生。到g及h两者的最近核心是a。
工具还可如下输出每一代谢物的途径(还被认为是反应的“系谱”序列):
c:a+b→
d:a+b→
e:a+b→;c+b→
f:a+b→;c+b→
g:a+b→;c+b→;d+e→
h:a+b→;c+b→;d+e→
途径筛选。在实施例中,给定宿主生物、靶分子及导向给定靶分子的途径的反应系谱,预测引擎109可基于给定参数(例如路径长度(例如,从开始代谢物到靶分子的反应处理步骤的数目))选择性地筛选途径以识别途径。预测引擎109可将表示经识别反应途径的数据提供为输出。
宿主生物选择。代替确定可行靶分子,给定单个宿主生物,可期望识别其中产生给定可行靶分子的一或多个宿主生物。在实施例中,预测引擎109根据上文描述的方法中的任何者生成表示可行靶分子的数据,不仅仅是针对一个宿主生物而是针对多个宿主生物。在此类实施例中,针对给定可行靶分子,预测引擎109确定满足至少一个准则的多个宿主生物中的至少一者。举例来说,使用反应系谱数据,预测引擎109可基于预测为在那个宿主生物中产生给定可行靶分子所必需的处理步骤的数目选择宿主生物。作为另一实例,预测引擎109可基于由宿主生物产生的可行靶分子的经预测产量选择那个宿主生物。经预测产量可基于每一潜在宿主的单独模型、简单元素产量建模及基于前体的百分比产率估计以数种方式导出,包含通量平衡分析(fba)。预测引擎109将表示确定为满足至少一个准则的宿主生物的数据提供为输出。
如针对上述实施例描述,预测引擎109可生成导向由每一宿主生物产生的每一靶分子的一或多个反应途径(即,系谱)的记录。基于针对多个宿主生物运行工具的上述实施例,反应注释引擎107可将宿主生物、靶分子与系谱之间的关联作为库存储在数据库中,所述库可包含指定参数的注释,所述参数例如产量、处理步骤的数目、催化剂在反应途径中催化反应的可用性等。替代地,所述库可从第三方获得。
在实施例中,如果预测引擎109已存取此库,那么无需运行池以识别其中产生给定可行靶分子的多个宿主生物。代替地,在此类实施例中,预测引擎109可使用来自库的系谱,所述库可包含关于宿主、靶分子与反应之中的关联的注释数据。预测引擎109可至少部分基于来自(例如)库或公共或专属数据库的经预测为在引起在至少一个靶宿主生物中产生靶分子的至少一个反应途径中催化反应的所有催化剂有可能在至少一个反应途径中可用于催化所有此类反应的证据从一或多个宿主生物之中识别至少一个靶宿主生物。在实施例中,预测引擎109可基于靶宿主需要比预测为产生靶分子所必需的反应路径内的反应步骤的阈值数目更少的反应步骤确定靶宿主。
生物勘探。一些反应酶可具有ec编号且被良好特性化(其反应物及产物是已知的),但不具有已知相关联的氨基酸序列或基因序列(“孤儿酶”)。在此类案例中,预测引擎109可生物勘探孤儿酶以预测其氨基酸序列,且最终预测其基因序列,使得最新排序的酶可被工程设计到宿主生物中以催化一或多个反应。接着,预测引擎109可将对应于最新排序的酶的反应指定为经筛选反应数据的成员。在实施例中,预测引擎109使用所属领域中已知的技术生物勘探孤儿酶。举例来说,一个团队通过应用基于质谱测定法的分析及计算方法(包含序列相似性网络及操纵子上下文分析)识别序列确定少量孤儿酶的氨基酸序列。接着,所述团队使用最新确定的序列以更准确地预测多得多的先前未经特性化的或错误注释的蛋白质的催化功能。拉基松kr(ramkissoonkr)等人(2013)的《快速识别孤儿酶的序列以激励正确的蛋白质注释(rapididentificationofsequencesfororphanenzymestopoweraccurateproteinannotation)》,《公共科学图书馆》(plosone)8(12):e84508.doi:10.1371/期刊.pone.0084508;还参见希勒ag(shearerag)等人(2014)的《找到超过270个孤儿酶的序列(findingsequencesforover270orphanenzymes)》,《公共科学图书馆》9(5):e97250.doi:10.1371/期刊.pone.0097250;山田t(yamadat)等人的《使用基因组及元基因组邻近基因组及元基因组邻近位点预测及识别孤儿酶的序列编码(predictionandidentificationofsequencescodingfororphanenzymesusinggenomicandmetagenomicneighboursgenomicandmetagenomicneighbours)》,《分子系统生物学》(molecularsystemsbiology)8:581,所述全部三者以全文引用的方式并入本文中。
基因组工程设计。生物可获得的预测工具可向化学家、材料科学家或其他人(其可为第三方,例如客户)提供生物可获得的候选分子(可行靶分子)的列表。基于其对靶分子的选定,用户可指示工具将酶或用于在导向每一所选择的靶分子的反应途径中催化反应的其它催化剂的基因序列的指示提供到基因制造系统。接着,基因制造系统可将经指示基因序列体现(通过(例如)插入、替换、删除)到宿主的基因组中,借此产生经工程设计基因组以制造可行靶分子。在实施例中,基因制造系统可使用通过所属领域中已知的系统及技术或通过工厂210实施,所述工厂210描述于2016年4月27日申请的标题为“用于经工程设计核苷酸序列的经改进大规模产生的菌株设计系统及方法(microbialstraindesignsystemandmethodsforimprovedlargescaleproductionofengineerednucleotidesequences)”的序列号为15/140,296的待决美国专利申请案中,所述美国专利申请案以全文引用方式并入本文中。在实施例中,预测引擎109向工厂提供一或多个催化剂的指示以使工厂将一或多个催化剂引入到宿主生物的生长培养基中以产生靶分子。
途径预测实例
根据本发明的实施例,预测引擎109可预测采用有可能可用于被催化或经工程设计以获得靶分子的催化剂的每个反应途径。预测引擎109还可用于从经预测途径之中选择以企图基于定性信息或定量信息(例如可通过预测引擎109生成的分数)制造分子。
反应标记及类别
反应集可如此专利中的别处描述那样被筛选及标记。举例来说,反应可标记为“宽松的序列”以指示其有可能具有可用基因序列,或其可被标记为“经特性化孤儿”以指示本质上存在基因,但需要用实验方法特性化。反应可类似地被标记以反映其质量及能量平衡或其它性状。
另外,bpt可基于热力学数据计算反应有可能在哪个方向上操作。
在生成靶分子的反应的处理期间,反应注释引擎107可标示通过反应产生靶分子是在热力学有利的方向上发生还是在热力学不利的方向上发生。
接着,这些热力学结果及全部其它反应标记可由反应注释引擎107使用以标记通过bpt的给定运行产生的分子及系谱。举例来说,含有一个热力学不利的反应及缺少产生酶以催化反应的已知基因的两个反应的五步系谱可标记为:
路径长度:5
不利的反应:1
缺少基因的反应:2
接着,这些标记可由预测引擎109使用以对每一反应评分。其还可用于对输出子区段分类及操作,且其提供对给定宿主的给定分子的可工程设计性的直接了解。
在下文详述的实例中,bpt用于识别生物可获得的靶分子及显示可用于到达那些靶分子的经预测途径。
并入到途径产生及评估的热力学数据使用基团贡献方法生成,但也可从任何数目个代谢数据库导出。
预测引擎108可将使用本文描述的评分方法创建的相关联的分数指派到每一潜在途径。这些分数可用于通知关于哪些途径变化尝试进行工程设计以制造靶分子的决策。
在实施例中,预测引擎109可以100分的最优分数开始且减去增加设计故障难度或风险的途径特征的分。举例来说,路径长度与设计风险相关,且总分数可随着路径长度增加而减小,例如,预测引擎109可针对路径长度中的每一额外步骤从所述分数减去一分或更多分。
酪胺
图8说明根据本发明的实施例的由预测引擎109识别的产生酪胺的途径。在酪胺的案例中,预测由一个反应步骤(r1)组成的单个途径。所展示的途径取决于基于热力学数据计算为可逆的反应,意味着所述反应可在生成酪胺所需的方向上操作。
在途径图中,黑色箭头表示那个反应在途径中产生所要分子(在此处,酪胺)所需的反应方向。白色箭头表示反应的经计算热力学方向。当所需反应方向与经计算反应方向匹配时,途径看似合理。
此单个途径按别处描述的度量得分100分。
(s)-2,3,4,5-四氢吡啶二羧酸(thdp)
如图9中展示,根据本发明的实施例,bpt预测生成thdp的两个可能两步途径。两个途径在这些实施例中实现相同分数97分。
途径共享相同第一反应(r1)且在第二反应(r2或r3)处不同。在此案例中,这些反应不同之处在于其使用了哪一形式的还原辅因子,例如,nadh对nadph。尽管途径得分相同,但此辅因子差异出于工程设计目的是相关的,且因此在bpt的此实施例中显示以帮助指导设计决策。通常,一个辅因子(nadh或nadph)更丰富得多地存在于每一给定宿主生物中。因此,在实施例中,所属领域的技术人员可选择采用更丰富的辅因子产生thdp的途径。在其它实施例中,预测引擎109可从数据库检索且考虑关于辅因子对可工程设计性的影响的信息以计算靶分子分数,借此消除对人类审查途径辅因子的需要。
假想分子“f”的实例经预测途径
在另一实例中,针对生物可获得的分子“f”,bpt预测了三个潜在途径,如图10中说明。
第一途径是两个步骤长且包含低置信度孤儿反应(r2),得到58分的分数。低置信度孤儿反应是通过孤儿酶催化的反应,针对所述孤儿酶,对应dna序列不可能在无需大量特定研究工作的情况下容易地得到。因此,扣除孤儿酶的许多分。
第二途径是三个步骤长且包含仅具有可用真核基因的一个反应(r4),得到92分的分数。因为总途径长度且由于在为r4供应基因中的限制,扣除分数。
第三途径也是三个步骤长且具有与其它三步反应一样的两个反应(r3及r4)。其还具有仅具有可用真核基因的一个反应(r4)及需要经工程设计酶的另一反应(r5),得到82分的分数。另外,此途径具有对途径分数无影响的一组替代开始核心代谢物(k+l而非a+b),但为在决定哪一途径最适于特定宿主及应用时的考虑。
在此实例中,从bpt的预测引擎109输出的评分提供超出简单的路径长度的关键工程设计信息。尽管直觉上最短途径(#1)可为最佳的,但由注释引擎107收集的关于每一反应的信息及通过bpt在筛选或处理期间收集到的信息展示较长途径(#2及#3)对工程设计可为更可行的。举例来说,反应注释引擎107可确定用于一些反应的催化剂仅可用于高风险类别中(例如,低置信度孤儿、经工程设计酶),且预测引擎109可确定较短途径取决于这些高风险类别,而较长途径不取决于这些高风险类别,这可展示较长途径对工程设计更可行。
四氢吡啶二羧酸评分表
根据本发明的实施例,预测引擎109使用其生成的信息以对产生靶分子的难度评分。(相反地,可将分数视为指示产生分子的容易程度。)此分数在本文可互换地称为“分子分数”、“靶分子分数”或“总途径分数”。
作为实例,图11a及11b一起提供一表,其说明预测引擎109可如何对四氢吡啶二羧酸(tfidp)的产生评分。在实施例中,整个途径评分过程可通过成分分解,例如途径分数、部分分数及产物分数,加权(例如)为30%、60%、10%,如所述表中展示。所展示的评估数据在预测到分子(s)-2,3,4,5-四氢吡啶二羧酸(tudp)的途径的过程期间生成。
途径成分分数表示途径的相对工程设计可行性。在实施例中,其包括两个元素:
路径长度-途径中的反应步骤数目。根据本发明的实施例,此被记录为由预测引擎109进行的生物可获得的预测的固有部分。
基因计数-经预测的途径所需的基因数目。此通过查询数据库作为由反应注释引擎107进行的反应筛选的部分来识别。
因为反应及酶并非总是呈1:1关系(例如,单个反应有时通过需要两个基因的两部分酶催化),所以预测引擎109可将两个元素都纳入工程设计途径的经预测难度中。
在由bpt预测的两个系谱中,如图9中展示,thdp在所期望的宿主生物中需要两步途径。此基于2步对1步途径的难度的适度增加产生适当分数扣除。
在此案例中,每途径反应步骤基因数目(可经由确定反应根本是否有可能具有基因的相同评估过程识别)还产生适度处罚。
部分成分分数
部分分数表示个别途径部分的相对工程设计可行性。在实施例中,其是基于找到针对被评估的途径中的反应将催化剂工程设计到宿主中所需的部分(例如,基因)的经预测难度。
在实施例中,可影响找到部分的能力的可能特征包含:
>100个已知酶序列-针对反应在反应筛选步骤期间发现的100个或100个以上序列(例如,对应于用于催化反应的酶的至少一个数据库中指示的100个或100个以上氨基酸序列)
<100个已知酶序列-发现酶序列,但在反应筛选步骤期间识别少于100个酶序列
高置信度孤儿/低置信度孤儿-在反应筛选步骤期间在公共数据库中未发现酶序列,但发现指示那些序列将相对容易(高置信度)或较难(低置信度)识别的相关联的证据
经工程设计酶-仅在反应筛选步骤期间连结到此反应的酶经工程设计以实施反应(此数据可发现于数据库搜索中)。此通常指代经突变以催化不同于其自然催化的反应的反应的自然酶。这些经工程设计酶可能难以用于新颖途径中,这是因为其可限于来自有限供体生物范围的一个或几个序列。此类经工程设计酶可发现于公共数据库(例如breda)中
基因分类供应-也在反应筛选步骤期间识别(假设发现了酶序列);此成分在所述生物可获得的分子的经预测途径中的反应之中按“最差情形”(最大处罚)分类那个生物可获得的分子;处罚是基于迄今为止关于在工业平台生物中表达来自经指示源的酶的难度的经验数据
当个别反应未知时路径的基因可用性-在一些情形中,途径使用数据集中的替代反应来定义,且这些反应可以编程方式连结到个别基因簇或生物;其中个别反应是未知的途径代表工程设计风险及难度的显著增加,且因此指派较大处罚
这些特征元素全都由反应注释引擎107识别,这是因为积累了关于催化每一反应的酶的序列数据的存在、缺乏及丰富度的信息。
在thdp的案例中,基因针对两个途径反应丰富地存在,从而不产生处罚。如果代替地,例如,如果反应中的一者通过低置信度孤儿催化,那么thdp会产生重大处罚。
产物成分分数
在本发明的实施例中,产物分数是靶分子分数的最小的总贡献者。产物分数表示影响维持细胞中的产物、将其从细胞导出及在培养基中维持其的难度的因子。在实施例中,其代表分子的预期毒性、导出及稳定性的评估。此实施例中描述的特定特征包含:
毒性-可预期分子对一或多个宿主生物有毒的程度。此信息可从查询抗菌数据库(或收集关于一般类别的宿主生物的毒性信息的其它数据库)导出。
导出-通过查询化学数据库的分配系数数据或通过查询内部实验数据来预测。
稳定性-稳定性问题通过查询化学数据库识别。
分数总结
表的底部总结总分数及类别分数。其还强调任何旗标-需要用于途径工程设计的特定风险化解的区域。thdp碰巧不具有旗标。实例旗标将为路径是否缺乏用于其反应步骤的一或多个基因(例如,高置信度或低置信度孤儿)。
计算机系统实施方案
图6说明根据本发明的实施例的云计算环境604。在本发明的实施例中,图1的反应注释引擎107及预测引擎109的软件610可实施于云计算系统602中以使多个用户能够根据本发明的实施例注释反应及预测生物可获得的分子。客户端计算机606(例如图7中说明的客户端计算机)经由网络608(例如因特网)存取系统。所述系统可采用图7中说明的类型的使用一或多个处理器的一或多个计算系统。云计算系统本身包含网络接口612以经由网络608将生物可获得的预测工具软件610介接到客户端计算机606。网络接口612可包含应用程序编程接口(api)以使客户端计算机606处的客户端应用程序能够存取系统软件610。特定来说,通过api,客户端计算机606可存取注释引擎107及预测引擎109。
软件即服务(saas)软件模块614将bpt系统软件610作为服务提供到客户端计算机606。云管理模块616管理通过客户端计算机606对系统610的存取。云管理模块616可使采用多组织应用、虚拟化的云架构或所属领域中已知的其它架构能够服务多个用户。
图7说明根据本发明的实施例的可用于执行非暂时性计算机可读媒体(例如,存储器)中存储的程序代码的计算机系统800的实例。所述计算机系统包含输入/输出子系统802,其可用于取决于应用与人类用户及/或其它计算机系统介接。i/o子系统802可包含(例如)键盘、鼠标、图形用户接口、触摸屏或其它输入接口,及(例如)led或其它平板显示器或其它输出接口,包含应用程序接口(api)。本发明的实施例的其它元件,例如注释引擎107及预测引擎109,可用计算机系统实施,如计算机系统800。
程序代码可存储于非暂时性媒体中,例如辅助存储器810或主存储器808或两者中的永久存储装置。主存储器808可包含易失性存储器,例如随机存取存储器(ram)或非易失性存储器,例如只读存储器(rom),以及用于更快速地存取指令及数据的不同级别的高速缓冲存储器。辅助存储器可包含永久存储装置,例如固态驱动、硬盘驱动或光盘。一或多个处理器804从一或多个非暂时性媒体读取程序代码且执行所述代码以使计算机系统能够完成由本文的实施例执行的方法。所属领域的技术人员应理解,处理器可摄取源代码,且将源代码解译或编译成在处理器804的硬件门级下可理解的机器代码。处理器804可包含用于处置计算密集型任务的图形处理单元(gpu)。
处理器804可经由一或多个通信接口807(例如网络接口卡、wifi收发器等)与外部网络通信。总线805通信地耦合i/o子系统802、处理器804、外围装置806、通信接口807、存储器808及永久存储装置810。本发明的实施例不限于此代表性架构。替代实施例可采用不同布置及类型的组件,例如,用于输入-输出组件及存储器子系统的单独总线。
所属领域的技术人员应理解,本发明的实施例的部分或全部元件及其伴随操作可完全或部分由包含一或多个处理器及一或多个存储器系统的一或多个计算机系统实施,如计算机系统800。特定来说,生物可获得的预测工具的元件及本文描述的任何其它自动化系统或装置可为计算机实施的。举例来说,一些元件及功能性可在本地实施,且其它者可以分布式方式跨网络通过不同服务器实施,例如,以客户端-服务器方式。特定来说,可使服务器侧操作可以软件即服务(saas)方式用于多个客户端,如图6中展示。
尽管本发明可能未明确揭示本文描述的一些实施例或特征可与本文描述的其它实施例或特征组合,但应阅读本发明以描述可由所属领域的一般技术人员实践的任何此类组合。
所属领域的技术人员应认识到,在一些实施例中,本文描述的部分操作可由人类实施方案执行或通过自动化与人工手段的组合执行。当操作并非是完全自动化时,生物可获得的预测工具的适当组件可(例如)接收人类执行操作的结果而非通过其自身操作生成结果。
- 还没有人留言评论。精彩留言会获得点赞!