以SNP为遗传标记物的亲缘关系鉴定方法与流程
本发明涉及亲缘关系鉴定方法
技术领域:
,具体为以snp为遗传标记物的亲缘关系鉴定方法。
背景技术:
:亲缘关系鉴定指依照遗传学基本原理,采用现代化dna分型检测技术综合评定样本之间是否存在亲缘关系,现代生物遗传理论指出,子代的基因组染色体dna各有一半来自亲生父母双方,以此为原则,目前已发展出多种亲缘鉴定方法,如血型亲缘鉴定和str基因分型技术等。基因分型技术也叫做dna指纹技术,是通过分析基因分型比较鉴定个体dna的分析技术,基本原理过程包括:样本dna的提取,特定限制性内切酶的长链切割,酶切片段凝胶电泳分离,双链dna的分离和转移,放射性dna探针与样本片断杂交,胶片显影,最终呈现出的dna片段条状图谱,就是dna指纹,该技术在20世纪80年代开始运用于法医,经过近三十年的发展,该技术不断改进,并广泛用于亲缘鉴定等场合,目前司法和商业用途中多使用str为遗传标记物的基因分型亲缘鉴定。str也被称为短串联序列重复,广泛存在于人类基因组中,每个str基因座由2-6对碱基构成一个核心序列,核心序列串联重复形成100~300bp长度左右的片段,即为一个str基因座。由于重复的数目不同,所以str基因座在长度上具有多态性。在人群中,同一个str基因座在不同的个体中可能重复次数不同,所以累加检测多个str基因座的分型结果,可以鉴定出两各个体的亲缘关系远近。str分型使用对应str试剂盒,经过常规规范的dna提取、pcr扩增、凝胶电泳等步骤,将得到检测样本的str片段。通过比较两各个体的str片段,最终确定片段是否相同和相同碱基的数量,在检测多个str基因座后,统计相同碱基数目并按照相应规定打分,以此判断样本亲缘关系,具体实施方法参照《生物学全同胞关系鉴定实施规范》。snp指在基因组水平上,由单个核苷酸变异导致的dna序列多态性,是人类可遗传变异中最常见的一种,占人类基因组多态性90%以上。snp的变异包括单个碱基的转换、颠换、插入和缺失,是一种丰富的遗传标记物。人类基因组中每1000个碱基中就有一个snp,由于其数量多、分布广泛,因此snp也成为了人类基因组计划应用的重要步骤,已有研究表明,很多肿瘤、免疫性疾病、遗传疾病等都与snp相关,snp的检测技术有ngs、基因芯片检测和pcr检测等。常用的str亲缘鉴定鉴别标准,其str序列的突变率为10-3-10-5,远高于人类基因组的平均突变,1.4×10-10,因此str的稳定性不高,使用str为遗传标记的亲缘检测分型结果易受到突变的影响;str多态性复杂,如同一长度中存在多个核心序列重复、核心序列非整倍重复等,增加亲缘检测中遗传标记物str的分型难度;str扩增时对样本的要求高,小浓度条件下,str片段不容易扩增出来,使得该亲缘鉴定方法使用环境受限;str检测成本较高,通量较低,增加了亲缘检测成本;亲缘鉴定使用的str序列所包含的遗传信息仅足够判定两个样本的父母-子女关系,但无法鉴别出更远的关系(祖孙、表亲等);str亲缘鉴定鉴别标准中易出现“无法判定关系”的结论,判定不直观,str基因座,即短串联序列重复基因座,其是目前较常用的亲缘鉴定遗传标记,但由于str基因座突变率高、多态性复杂且蕴含信息有限,这种检测鉴定技术也面对检测成本高、准确率有限、且结果易受主观环境影响等问题,为此我们提出以snp为遗传标记物的亲缘检测鉴定方法。技术实现要素:本发明提供了以snp为遗传标记物的亲缘关系鉴定方法,具备分型结果准确直观及采用程序化判定,操作简单方便的优点,解决了
背景技术:
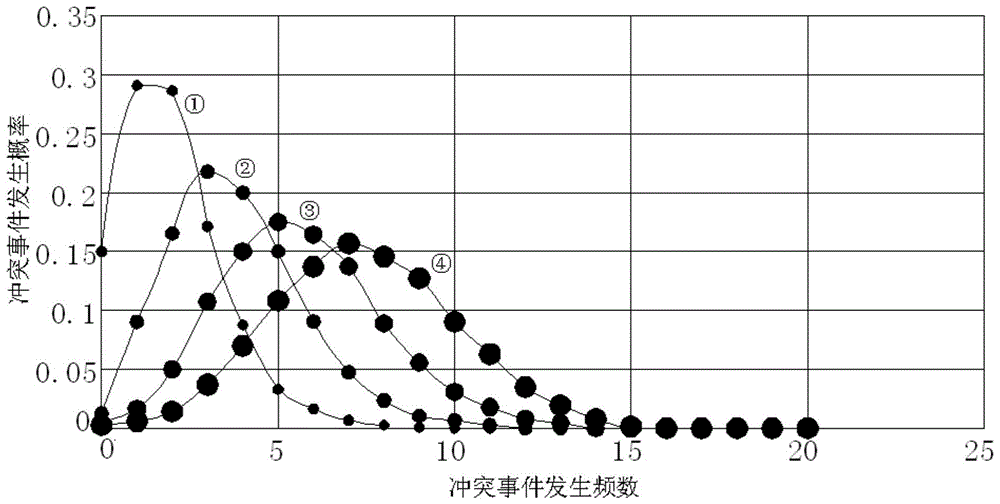
中提到的问题。为实现以上目的,本发明提供如下技术方案予以实现:以snp为遗传标记物的亲缘关系鉴定方法,包括亲缘关系判定模型的建立、snp位点的分型检测和根据分型结果和判定模型确认个体间亲缘关系三大步骤。第一步:亲缘关系判定模型的建立;该模型对于snp的选取有三个要求;要求一:位点上出现的两种碱基频率为0.5:0.5;要求二:选取的检测位点之间不存在连锁遗传现象;要求三:选取的位点位于人类基因组常染色体上,要求一保证了判定模型的准确性,最大限度减少了概率突变的误差,要求二是从遗传学的角度避免了位点之间的相互影响,要求三则保证每个位点都有等位基因,方便关系判定的计算,并减小可能出现的误差。人群中同一位点的两个碱基频率各为0.5,故人群中该位点的基因型分布符合aa,ab,bb~0.25,0.5,0.25,其中定义aa~bb为冲突事件,即亲代基因型为aa是,子代基因型不可能是bb,否则为冲突。因此对于同一位点直系亲属发生冲突事件的概率为0,陌生人之间发生冲突的概率为0.125,其余亲缘关系发生冲突的概率介于0~0.125之间。定义样本间亲兄弟关系为一级亲缘关系,样本间祖孙/外祖孙为耳机亲缘关系,叔侄、舅甥等为三级亲缘关系,计算三种亲缘关系在同一位点下发生冲突事件的概率分别为:一级亲缘关系为1/32,二级亲缘关系为2/32,三级亲缘关系为3/32。根据这三个亲缘关系的冲突概率,建立了样本容量为60的三个概率密度模型为标准参考模型,即选取60个snp位点分别建立概率密度模型。第二步:snp位点的分型检测;snp位点分型检测选用某公司针对亚洲人定制的asamd芯片,芯片可检测出66万个有效位点分型结果。第三步:根据分型结果和判定模型确认个体间亲缘关系。工作人员应每次从两个样本的可用位点中随机选出60个snp位点的分型结果,并计数每次出现冲突的频数,每60个位点计算一次冲突出现的频率;反复大量重复后,将得到的冲突出现的频率做均值处理最为最终频率,由于位点库中的位点多,且重复实验次数多,所以最大程度上避免了每次实验的偶然性,同时冲突频率也极度接近冲突出现的理论概率,最后将得到的结果与三个标准概率密度模型进行比较,即可得到两个样本间的亲缘关系。可选的,所述亲缘关系判定模型基本原理和计算可分为人群中任意两样本间的亲缘关系和直系亲属亲缘关系计算模型、一级亲缘关系计算模型、二级亲缘关系计算模型和三级亲缘关系计算模型。人群中任意两样本间的亲缘关系和直系亲属亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率分别为0.25、0.5、0.25,定义:两个体同一位点上分别出现aa、aa或gg、gg的基因型为纯合相同,出现ag、ag的基因型为杂合相同,出现aa、ag或gg、ag的基因型为不同,出现aa、gg的基因型为冲突。则:p(纯合相同)=0.125;p(杂合相同)=0.25;p(不同)=0.5;p(冲突)=0.125其中选取冲突事件作为判断两样本亲缘关系的标准,一级亲缘关系的两样本发生冲突事件的概率为0,任意两样本间发生冲突事件的概率为0.125,其余亲缘关系间发生冲突事件的的概率介于二者之间。若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突发生但不全冲突的概率,事件c为分型结果全都冲突的的概率,则:a(n)=(7/8)nb(n)=1-(7/8)n-(1/8)nc(n)=(1/8)n如果所有snp分型结果出现冲突事件的频率为0,则可认为两样本间为直系亲属关系;如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本是人群中任意两个体即陌生人关系。可选的,一级亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率为0.25、0.5、0.25。定义:两个体同一位点上分别出现aa、aa或bb、bb的基因型为纯合相同,出现ab、ab的基因型为杂合相同,出现aa、ab或bb、ab的基因型为不同,出现aa、bb的基因型为冲突。则:人群中任意个体双亲的基因型组合及概率和各个组合下冲突事件发生的概率可计算结果;若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突但不全冲突的概率,事件c为分型结果全都冲突的概率,则:a(n)=(31/32)nb(n)=1-(31/32)n-(1/32)nc(n)=(1/32)n如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本间为一级亲缘关系。可选的,二级亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率为0.25、0.5、0.25。定义:两个体同一位点上分别出现aa、aa或bb、bb的基因型为纯合相同,出现ab、ab的基因型为杂合相同,出现aa、ab或bb、ab的基因型为不同,出现aa、bb的基因型为冲突。当个体的祖父(祖母、外祖父、外祖母)基因型为aa时,个体基因型为bb时发生冲突事件,计算该情况下冲突事件发生的概率为0.125;当个体的祖父(祖母、外祖父、外祖母)基因型为ab时,个体为任何基因型都不会发生冲突事件,计算该情况下冲突事件发生的概率为0;当个体的祖父(祖母、外祖父、外祖母)基因型为bb时,个体基因型为aa时发生冲突事件,计算该情况下冲突事件发生的概率为0.125。因此,计算一个snp位点上二级亲缘关系间发生冲突的概率为:0.25×0.125+0.5×0+0.25×0.125=0.0625若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突但不全冲突的概率,事件c为分型结果全都冲突的概率,则:a(n)=(15/16)nb(n)=1-(15/16)n-(1/16)nc(n)=(1/16)n如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本间为二级亲缘关系。可选的,三级亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率为0.25、0.5、0.25。定义:两个体同一位点上分别出现aa、aa或bb、bb的基因型为纯合相同,出现ab、ab的基因型为杂合相同,出现aa、ab或bb、ab的基因型为不同,出现aa、bb的基因型为冲突。当个体的叔叔/舅舅等基因型为aa时,个体基因型为bb时发生冲突事件,计算该情况下冲突事件发生的概率为3/16;当个体的叔叔/舅舅等基因型为ab时,个体为任何基因型都不会发生冲突事件,计算该情况下冲突事件发生的概率为0;当个体的叔叔/舅舅等基因型为bb时,个体基因型为aa时发生冲突事件,计算该情况下冲突事件发生的概率为3/16.因此,计算一个snp位点上三级亲缘关系间发生冲突的概率为:0.25×3/16+0.5×0+0.25×3/16=3/32若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突都不全冲突的概率,事件c为分型结果全都冲突的概率,则:a(n)=(29/32)nb(n)=1-(29/32)n-(3/32)nc(n)=(3/32)n如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本间为二级亲缘关系。可选的,亲缘关系判定模型如下:在所选用的snp位点不发生突变、没有连锁遗传现象、且在同一位点上出现两碱基的概率各位0.5的情况下,人群中任意两个体发生冲突事件的概率为1/8,一级亲缘关系间发生冲突事件的概率为1/32,二级亲缘关系间发生冲突事件的概率为1/16,三级亲缘关系间发生冲突事件的概率为3/32,直系亲属间发生冲突事件的概率为0。在符合要求的snp位点中每次选取60个位点,进行冲突事件概率统计,计算几种亲缘关系冲突事件发生的概率密度函数。本发明提供了以snp为遗传标记物的亲缘关系鉴定方法,具备以下有益效果:1、该以snp为遗传标记物的亲缘关系鉴定方法,检测方式上采用snp代替str作为遗传标记物,充分避免了使用str为遗传标记检测时稳定性差、分型难度高、对样本质量要求高、成本高的缺点;通过新模型算法可直接判定出两样本间直系、一级亲缘关系、二级亲缘关系、三级亲缘关系和陌生人;引入概率密度模型,充分避免各种误差带来的影响;采用程序化判定,操作简单方便。2、该以snp为遗传标记物的亲缘关系鉴定方法,采用snp分型检测技术,使分型结果准确直观;算法使用的snp位点多、重复次数多,结果更加准确;判定模型在概率的基础上引入概率密度模型,最大程度避免误差出现,结论更准确。附图说明图1为本发明亲缘关系判定概率密度模型示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。实施例1,请参阅图1,以snp为遗传标记物的亲缘关系鉴定方法,包括亲缘关系判定模型的建立、snp位点的分型检测和根据分型结果和判定模型确认个体间亲缘关系三大步骤,snp多位于基因的非编码区,突变率远低于str基因座,所以使用snp作为遗传标记物更加稳定;单个snp仅1kb,而一个str长15kb同时含有多个等位基因,因此snp在分型难度上远小于str;str为遗传标记的亲缘鉴定,检测成本相对较高,使用snp检测将大大降低鉴定成本,鉴定上我们建立了概率密度判断模型,相较于当前str鉴定容易受主观因素影响的状况,新方法更加直观准确。第一步:亲缘关系判定模型的建立;该模型对于snp的选取有三个要求;要求一:位点上出现的两种碱基频率为0.5:0.5;要求二:选取的检测位点之间不存在连锁遗传现象;要求三:选取的位点位于人类基因组常染色体上,要求一保证了判定模型的准确性,最大限度减少了概率突变的误差,要求二是从遗传学的角度避免了位点之间的相互影响,要求三则保证每个位点都有等位基因,方便关系判定的计算,并减小可能出现的误差。人群中同一位点的两个碱基频率各为0.5,故人群中该位点的基因型分布符合aa,ab,bb~0.25,0.5,0.25,其中定义aa~bb为冲突事件,即亲代基因型为aa是,子代基因型不可能是bb,否则为冲突。因此对于同一位点直系亲属发生冲突事件的概率为0,陌生人之间发生冲突的概率为0.125,其余亲缘关系发生冲突的概率介于0~0.125之间。定义样本间亲兄弟(姐妹、兄妹、姐弟,不包含同卵双胞胎情况)关系为一级亲缘关系,样本间祖孙/外祖孙为耳机亲缘关系,叔侄、舅甥等为三级亲缘关系,计算三种亲缘关系在同一位点下发生冲突事件的概率分别为:一级亲缘关系为1/32,二级亲缘关系为2/32,三级亲缘关系为3/32。根据这三个亲缘关系的冲突概率,建立了样本容量为60的三个概率密度模型为标准参考模型,即选取60个snp位点分别建立概率密度模型。第二步:snp位点的分型检测;snp位点分型检测选用某公司针对亚洲人定制的asamd芯片,该公司拥有遗传变异和生物学功能分析领域的优秀的产品、技术和服务,芯片可检测出66万个有效位点分型结果。第三步:根据分型结果和判定模型确认个体间亲缘关系,检测方式上采用snp代替str作为遗传标记物,充分避免了使用str为遗传标记检测时稳定性差、分型难度高、对样本质量要求高、成本高的缺点。工作人员应每次从两个样本的可用位点中随机选出60个snp位点(和建立模型算去的位点数量保持一致)的分型结果,并计数每次出现冲突的频数,每60个位点计算一次冲突出现的频率;反复大量重复后,将得到的冲突出现的频率做均值处理最为最终频率,由于位点库中的位点多,且重复实验次数多,所以最大程度上避免了每次实验的偶然性,同时冲突频率也极度接近冲突出现的理论概率,最后将得到的结果与三个标准概率密度模型进行比较,即可得到两个样本间的亲缘关系。其中,所述亲缘关系判定模型基本原理和计算可分为人群中任意两样本间的亲缘关系和直系亲属亲缘关系计算模型、一级亲缘关系计算模型、二级亲缘关系计算模型和三级亲缘关系计算模型。人群中任意两样本间的亲缘关系和直系亲属亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率分别为0.25、0.5、0.25,定义:两个体同一位点上分别出现aa、aa或gg、gg的基因型为纯合相同,出现ag、ag的基因型为杂合相同,出现aa、ag或gg、ag的基因型为不同,出现aa、gg的基因型为冲突。则:p(纯合相同)=0.125;p(杂合相同)=0.25;p(不同)=0.5;p(冲突)=0.125;计算方法如下表:基因型paaabbbf频率0.250.50.25aa0.250.06250.1250.0625ab0.50.1250.250.125bb0.250.06250.1250.0625其中选取冲突事件作为判断两样本亲缘关系的标准,一级亲缘关系的两样本发生冲突事件的概率为0,任意两样本间发生冲突事件的概率为0.125,其余亲缘关系间发生冲突事件的的概率介于二者之间。若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突发生但不全冲突的概率,事件c为分型结果全都冲突的的概率,则:a(n)=(7/8)nb(n)=1-(7/8)n-(1/8)nc(n)=(1/8)n如果所有snp分型结果出现冲突事件的频率为0,则可认为两样本间为直系亲属关系;如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本是人群中任意两个体即陌生人关系。其中,一级亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率为0.25、0.5、0.25。定义:两个体同一位点上分别出现aa、aa或bb、bb的基因型为纯合相同,出现ab、ab的基因型为杂合相同,出现aa、ab或bb、ab的基因型为不同,出现aa、bb的基因型为冲突。则:人群中任意个体双亲的基因型组合及概率和各个组合下冲突事件发生的概率可计算结果,计算结果如下表:表格1.双亲基因型组合及概率基因型♂aaabbb♀概率0.250.50.25aa0.250.06250.1250.0625ab0.50.1250.250.125bb0.250.06250.1250.0625表格2.双亲基因型及子代为一级亲缘关系时发生冲突事件的概率由以上两表格可计算出两样本为一级亲缘关系时冲突事件发生的概率为:p(冲突)=0.0625×0+0.25×0+0.25×0.125+0.625×0+0.125×0=0.3125若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突但不全冲突的概率,事件c为分型结果全都冲突的概率,则:a(n)=(31/32)nb(n)=1-(31/32)n-(1/32)nc(n)=(1/32)n如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本间为一级亲缘关系。其中,二级亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率为0.25、0.5、0.25。定义:两个体同一位点上分别出现aa、aa或bb、bb的基因型为纯合相同,出现ab、ab的基因型为杂合相同,出现aa、ab或bb、ab的基因型为不同,出现aa、bb的基因型为冲突。当个体的祖父(祖母、外祖父、外祖母)基因型为aa时,个体基因型为bb时发生冲突事件,计算该情况下冲突事件发生的概率为0.125;当个体的祖父(祖母、外祖父、外祖母)基因型为ab时,个体为任何基因型都不会发生冲突事件,计算该情况下冲突事件发生的概率为0;当个体的祖父(祖母、外祖父、外祖母)基因型为bb时,个体基因型为aa时发生冲突事件,计算该情况下冲突事件发生的概率为0.125。因此,计算一个snp位点上二级亲缘关系间发生冲突的概率为:0.25×0.125+0.5×0+0.25×0.125=0.0625若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突但不全冲突的概率,事件c为分型结果全都冲突的概率,则:a(n)=(15/16)nb(n)=1-(15/16)n-(1/16)nc(n)=(1/16)n如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本间为二级亲缘关系。其中,三级亲缘关系计算模型如下:假设:一个snp位点上分型出现的两个碱基a、b的频率各为50%,则:人群中基因型为aa、ab、bb的概率为0.25、0.5、0.25。定义:两个体同一位点上分别出现aa、aa或bb、bb的基因型为纯合相同,出现ab、ab的基因型为杂合相同,出现aa、ab或bb、ab的基因型为不同,出现aa、bb的基因型为冲突。当个体的叔叔/舅舅等基因型为aa时,个体基因型为bb时发生冲突事件,计算该情况下冲突事件发生的概率为3/16;当个体的叔叔/舅舅等基因型为ab时,个体为任何基因型都不会发生冲突事件,计算该情况下冲突事件发生的概率为0;当个体的叔叔/舅舅等基因型为bb时,个体基因型为aa时发生冲突事件,计算该情况下冲突事件发生的概率为3/16.因此,计算一个snp位点上三级亲缘关系间发生冲突的概率为:0.25×3/16+0.5×0+0.25×3/16=3/32若有n个snp位点,定义事件a为两样本所有snp位点分型结果都不冲突的概率,事件b为分型结果有冲突都不全冲突的概率,事件c为分型结果全都冲突的概率,则:a(n)=(29/32)nb(n)=1-(29/32)n-(3/32)nc(n)=(3/32)n如果所有snp分型结果出现冲突事件的频率无限接近c(n),则可认为两个样本间为二级亲缘关系。其中,亲缘关系判定模型如下:在所选用的snp位点不发生突变、没有连锁遗传现象、且在同一位点上出现两碱基的概率各位0.5的情况下,人群中任意两个体发生冲突事件的概率为1/8,一级亲缘关系间发生冲突事件的概率为1/32,二级亲缘关系间发生冲突事件的概率为1/16,三级亲缘关系间发生冲突事件的概率为3/32,直系亲属间发生冲突事件的概率为0;通过新模型算法可直接判定出两样本间直系、一级亲缘关系、二级亲缘关系、三级亲缘关系和陌生人;引入概率密度模型,充分避免各种误差带来的影响;采用程序化判定,操作简单方便。在符合要求的snp位点中每次选取60个位点,采用snp分型检测技术,使分型结果准确直观;算法使用的snp位点多、重复次数多,结果更加准确;判定模型在概率的基础上引入概率密度模型,最大程度避免误差出现,结论更准确,进行冲突事件概率统计,计算几种亲缘关系冲突事件发生的概率密度函数,参考说明书附图1,其图中①代表一级亲缘关系、②代表二级亲缘关系、③代表三级亲缘关系和④代表陌生人,根据说明书附图1的标准概率分布模型,通过统计实际情况下两样本的冲突事件发生的频率,我们可判定出两样本的亲缘关系。实施例2,与实施例1不同的是:snp检测时使用的芯片检测,可被替换为ngs测序、pcr扩增或者wes测序等;实施例3,与实施例1及2不同的是:概率模型中我们选用60个位点进行检测,可被替换为其他位点数,同时对应的概率密度标准模型发生改变;实施例4,与实施例1、2和3不同的是:位点的选取是基于本公司样本数据库和千人计划等基因组测序数据库,可以被替换。需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1