一种烟气成分的预测方法
本发明涉及石油化工及能源领域,更具体地,涉及一种烟气成分的预测方法。
背景技术:
乙烯裂解炉用于加工裂解气,是乙烯生产装置的核心设备,主要作用是把天然气、炼厂气、原油及石脑油等各类原材料加工成裂解气,并提供给其它乙烯装置,最终加工成乙烯、丙烯及各种副产品。在乙烯裂解炉工业过程中,裂解炉内的烟气主要成分包括氧气、一氧化碳、二氧化碳。这些烟气成分含量反映了裂解炉燃烧效率与状态,实时监测烟气主要成分浓度是实现裂解炉运行状态智能调控的重要前提。然而这些质量变量(主要为:氧气浓度、一氧化碳浓度和二氧化碳浓度)的测量通常是通过分析仪在尾气排放处测量的,存在测量滞后和测量间隔时间长问题,无法直接用于燃烧反馈控制。软测量本质上是数学模型,能够根据易于测量的过程变量(也叫作辅助变量),如烟气流量、炉内温度、炉内压力等,在线预测这些质量变量。软测量因其无延迟和便于维护等优点,在过程监控、闭环控制、过程优化等方面发挥着重要作用。
乙烯裂解炉工业过程呈现非线性、非高斯性、多模态等特性。这些特性增加了开发高精度软测量模型的难度。此外,通过硬件传感器获得的一些工业过程变量的测量值不可避免地存在观察误差、记录错误、测量干扰或数据缺失等问题,导致可用来进行统计分析的数据集被离群点污染。不幸的是,这些离群点很难被完全识别和移除。因此,混合student’st模型被提出并且应用到多模态工业过程的鲁棒软测量开发。混合student’st模型可以按概率组合一组student’st分布来近似任意复杂的非高斯分布,并通过对每个student’st分量赋予不同的重要性来构造局部模型,从而实现非线性、非高斯性和过程不确定性的建模。student’st分布相较于高斯分布具有重尾特性,能够对工业过程数据集中的离群点具有一定的鲁棒特性。然而,现有的混合student’st模型在软测量开发时都是针对单质量变量的,而忽略了多质量变量的预测问题,尤其是乙烯裂解炉烟气成分中多质量变量相互耦合下的预测问题。若考虑在单质量变量混合student’st模型的基础上,设计一种多质量变量的模型结构,以及多质量变量联合学习算法,可实现对多质量变量的乙烯裂解炉烟气成分的多质量变量联合鲁棒软测量建模,由此解决问题。因此,目前亟需一种能准确预测烟气成分的测量方法。
技术实现要素:
为了解决上述问题,本发明提供一种烟气成分的预测方法,该方法能准确预测烟气成分。
本发明采取的技术方案是:
一种烟气成分的预测方法,包括以下步骤:
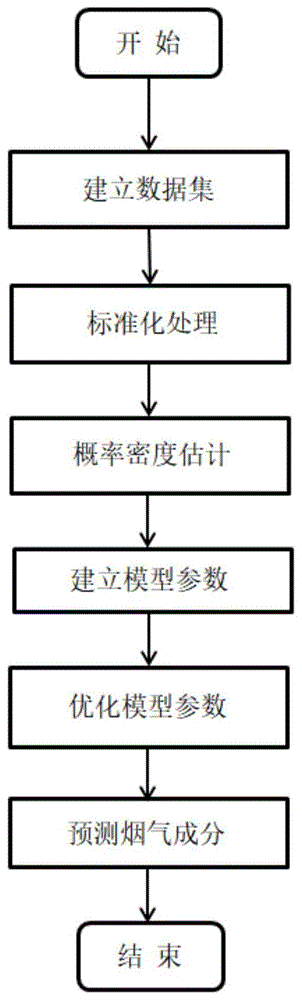
步骤s1:收集乙烯裂解炉工业过程的历史数据,建立训练集;
所述历史数据为用于反映裂解炉燃烧效率与状态的数据;
所述训练集包括辅助变量数据集和质量变量数据集;
步骤s2:对训练集进行标准化处理,获取标准化训练集;
所述标准化训练集为均值为0,方差为1的数据集;
步骤s3:根据标准化训练集初始化模型参数;
步骤s4:以迭代的方式优化模型参数;
步骤s5:根据优化后的模型参数获取质量变量的预测值。
具体地,首先,收集乙烯裂解炉工业过程的历史数据,历史数据用于反映裂解炉燃烧效率与状态,一般为烟气流量、炉内温度、炉内压力、各种气体浓度等,以此建立训练集。其中,烟气流量、炉内温度、炉内压力为辅助变量,由辅助变量数据集存储,各种气体浓度为质量变量,由质量变量数据集存储。然后,对训练集进行标准化处理,获取标准化训练集。之后,利用标准化训练集进行概率密度估计,确定组分,建立模型参数。所述组分指炉内烟气的各种成分,如氧气、一氧化碳和二氧化碳都为烟气的组分。最后,优化模型参数,以优化好的模型参数预测烟气成分。
进一步地,所述训练集为d=[x;y],d∈r(d+m)×n;所述训练集采集的样本数为n,每个样本包含一个辅助变量样本和一个质量变量样本;所述r为实数集;所述辅助变量数据集为x={x1,x2,…,xn}∈rd×n,用于存储辅助变量样本;所述辅助变量样本为维度为d的多维数组,每个辅助变量样本包含至少一种辅助变量,即d≥1;所述辅助变量为用于预测质量变量的量;所述质量变量数据集为y={y1,y2,…,yn}∈rm×n,用于存储质量变量样本;所述质量变量样本为维度为m的多维数组,每个质量变量样本包含至少一种质量变量,即m≥1;所述质量变量为用于反映裂解炉燃烧效率与状态的量;所述标准化训练集为
具体地,虽然质量变量可以反映裂解炉燃烧效率与状态,但是一般只能在尾气排放时测量,存在测量滞后和测量间隔时间过长的问题,无法直接用于燃烧反馈控制。因此,一般的做法是先采集易于测量的辅助变量,然后通过辅助变量预测质量变量,再通过预测出来的质量变量反映裂解炉燃烧效率与状态。训练集采集的样本为n,样本数与辅助变量样本数、质量变量样本数对应,相应的采集到的辅助变量样本的数量也为n,n个辅助变量样本预估出来的质量变量样本数量也为n。
进一步地,所述标准化后的辅助变量样本的概率密度函数为:
所述标准化后的质量变量样本的概率密度函数为:
所述
进一步地,所述模型参数为:
进一步地,所述步骤s4中迭代的方式为重复执行期望最大化算法。
具体地,期望最大化算法(expectationmaximization)简称em算法,是一类算法的总称。em算法分为e-step和m-step两步。em算法的应用范围很广,一般用于基本机器学习中迭代优化参数模型。e-step:e的全称是expectation,即期望的意思。e-step也是获取期望的过程。即根据现有的模型,计算各个观测数据输入到模型中的计算结果。这个过程称为期望值计算过程,即e过程。m-step:m的全称是maximization,即最大化的意思。m-step也是期望最大化的过程。得到一轮期望值以后,重新计算模型参数,以最大化期望值。这个过程为最大化过程,即m过程。最大化的意思是我们在使用这个模型时希望我们定义的函数能使得到的结果最大化,而结果越大越接近我们希望得到的结果。我们优化的目标也就是这些能得到最大值的函数。
进一步地,所述期望最大化算法包括:
e-step:
根据模型参数计算样本对应的类别隐变量的后验分布:
所述样本的类别隐变量z=(z1,z2,…,zn);所述
根据样本对应的类别隐变量的后验分布,获取样本由组分解释的后验概率的数学期望:
为了后续推导的简洁性,其中第n个样本由第k个组分解释的后验概率的数学期望
对样本引入对应的中间隐变量;所述中间隐变量的后验分布的数学期望为:
所述中间隐变量为η=(η1,η2,…,ηn);所述ηnk为第n个样本对应的中间隐变量;所述ψ(·)为digamma函数。
具体地,首先,根据模型参数计算第n个样本对应的类别隐变量的后验分布为:
换算后为
然后,根据第n个样本对应的类别隐变量的后验分布获取第n个样本由第k个组分解释的后验概率的数学期望。
最后,由于student’st分布不属于指数家族分布,因此对student’st分布进行最大似然估计往往很难得到解析解。通过对第k个组分的第n个辅助变量样本
进一步地,在e-step之后,所述期望最大化算法还包括:
m-step:
根据e-step获取的数学期望,计算训练集的对数似然函数的数学期望:
其中,
执行最大化似然估计更新模型参数:
所述更新的υk通过求解非线性方程获取,非线性方程如下:
根据更新后的模型参数计算训练集的对数似然函数的数学期望
具体地,根据e-step求解得到的数学期望,计算训练集的对数似然函数的数学期望,然后执行最大化似然估计获取模型参数的更新公式。假设所有数据样本服从独立同分布假设,可得到上述训练集的对数似然函数的数学期望。最后通过训练集的对数似然函数的数学期望计算
进一步地,所述步骤s5包括:
步骤s5.1:计算待测样本对应的类别隐变量的后验概率:
为了后续推导的简洁性,其中待测样本对应的类别隐变量的后验概率
步骤s5.2:根据待测样本对应的类别隐变量的后验概率,计算待测样本的质量变量样本关于辅助变量样本的条件概率分布:
所述待测样本的质量变量样本为
步骤s5.3:根据待测样本的质量变量样本关于辅助变量样本的条件概率分布,计算待测样本的质量变量样本的预测值:
进一步地,所述辅助变量样本包括:炉膛温度、炉管外壁温度、引风机转速、烧嘴燃料量、进风量中的一种或多种。
进一步地,所述质量变量样本包括:氧气浓度、一氧化碳浓度和二氧化碳浓度中的一种或多种。
与现有技术相比,本发明的有益效果为:
(1)设计多质量变量的模型及多质量变量联合学习算法,实现对具有多质量变量的乙烯裂解炉的鲁棒软测量。
(2)可以有效处理数据缺失、质量差等情形,能够实现乙烯裂解炉烟气成分的实时多变量预测。
附图说明
图1为本发明的流程图。
具体实施方式
本发明附图仅用于示例性说明,不能理解为对本发明的限制。为了更好说明以下实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
实施例
本实施例提供一种烟气成分的预测方法,图1为本发明的流程图,如图所示,包括以下步骤:
步骤s1:收集乙烯裂解炉工业过程的历史数据,建立训练集;
所述历史数据为用于反映裂解炉燃烧效率与状态的数据;
所述训练集包括辅助变量数据集和质量变量数据集;
步骤s2:对训练集进行标准化处理,获取标准化训练集;
所述标准化训练集为均值为0,方差为1的数据集;
步骤s3:根据标准化训练集初始化模型参数;
步骤s4:以迭代的方式优化模型参数;
步骤s5:根据优化后的模型参数获取质量变量的预测值。
具体地,首先,收集乙烯裂解炉工业过程的历史数据,历史数据用于反映裂解炉燃烧效率与状态,一般为烟气流量、炉内温度、炉内压力、各种气体浓度等,以此建立训练集。其中,烟气流量、炉内温度、炉内压力为辅助变量,由辅助变量数据集存储,各种气体浓度为质量变量,由质量变量数据集存储。然后,对训练集进行标准化处理,获取标准化训练集。之后,利用标准化训练集进行概率密度估计,确定组分,建立模型参数。所述组分指炉内烟气的各种成分,如氧气、一氧化碳和二氧化碳都为烟气的组分。最后,优化模型参数,以优化好的模型参数预测烟气成分。
进一步地,所述训练集为d=[x;y],d∈r(d+m)×n;所述训练集采集的样本数为n,每个样本包含一个辅助变量样本和一个质量变量样本;所述r为实数集;所述辅助变量数据集为x={x1,x2,…,xn}∈rd×n,用于存储辅助变量样本;所述辅助变量样本为维度为d的多维数组,每个辅助变量样本包含至少一种辅助变量,即d≥1;所述辅助变量为用于预测质量变量的量;所述质量变量数据集为y={y1,y2,…,yn}∈rm×n,用于存储质量变量样本;所述质量变量样本为维度为m的多维数组,每个质量变量样本包含至少一种质量变量,即m≥1;所述质量变量为用于反映裂解炉燃烧效率与状态的量;所述标准化训练集为
具体地,虽然质量变量可以反映裂解炉燃烧效率与状态,但是一般只能在尾气排放时测量,存在测量滞后和测量间隔时间过长的问题,无法直接用于燃烧反馈控制。因此,一般的做法是先采集易于测量的辅助变量,然后通过辅助变量预测质量变量,再通过预测出来的质量变量反映裂解炉燃烧效率与状态。训练集采集的样本为n,样本数与辅助变量样本数、质量变量样本数对应,相应的采集到的辅助变量样本的数量也为n,n个辅助变量样本预估出来的质量变量样本数量也为n。
进一步地,所述标准化后的辅助变量样本的概率密度函数为:
所述标准化后的质量变量样本的概率密度函数为:
所述
进一步地,所述模型参数为:
进一步地,所述步骤s4中迭代的方式为重复执行期望最大化算法。
具体地,期望最大化算法(expectationmaximization)简称em算法,是一类算法的总称。em算法分为e-step和m-step两步。em算法的应用范围很广,一般用于基本机器学习中迭代优化参数模型。e-step:e的全称是expectation,即期望的意思。e-step也是获取期望的过程。即根据现有的模型,计算各个观测数据输入到模型中的计算结果。这个过程称为期望值计算过程,即e过程。m-step:m的全称是maximization,即最大化的意思。m-step也是期望最大化的过程。得到一轮期望值以后,重新计算模型参数,以最大化期望值。这个过程为最大化过程,即m过程。最大化的意思是我们在使用这个模型时希望我们定义的函数能使得到的结果最大化,而结果越大越接近我们希望得到的结果。我们优化的目标也就是这些能得到最大值的函数。
进一步地,所述期望最大化算法包括:
e-step:
根据模型参数计算样本对应的类别隐变量的后验分布:
所述样本的类别隐变量z=(z1,z2,…,zn);所述
根据样本对应的类别隐变量的后验分布,获取样本由组分解释的后验概率的数学期望:
为了后续推导的简洁性,其中第n个样本由第k个组分解释的后验概率的数学期望
对样本引入对应的中间隐变量;所述中间隐变量的后验分布的数学期望为:
所述中间隐变量为η=(η1,η2,…,ηn);所述ηnk为第n个样本对应的中间隐变量;所述ψ(·)为digamma函数。
具体地,首先,根据模型参数计算第n个样本对应的类别隐变量的后验分布为:
换算后为
然后,根据第n个样本对应的类别隐变量的后验分布获取第n个样本由第k个组分解释的后验概率的数学期望。
最后,由于student’st分布不属于指数家族分布,因此对student’st分布进行最大似然估计往往很难得到解析解。通过对第k个组分的第n个辅助变量样本
进一步地,在e-step之后,所述期望最大化算法还包括:
m-step:
根据e-step获取的数学期望,计算训练集的对数似然函数的数学期望:
其中,
执行最大化似然估计更新模型参数:
所述更新的υk通过求解非线性方程获取,非线性方程如下:
根据更新后的模型参数计算训练集的对数似然函数的数学期望
具体地,根据e-step求解得到的数学期望,计算训练集的对数似然函数的数学期望,然后执行最大化似然估计获取模型参数的更新公式。假设所有数据样本服从独立同分布假设,可得到上述训练集的对数似然函数的数学期望。最后通过训练集的对数似然函数的数学期望计算
进一步地,所述步骤s5包括:
步骤s5.1:计算待测样本对应的类别隐变量的后验概率:
为了后续推导的简洁性,其中待测样本对应的类别隐变量的后验概率
步骤s5.2:根据待测样本对应的类别隐变量的后验概率,计算待测样本的质量变量样本关于辅助变量样本的条件概率分布:
所述待测样本的质量变量样本为
步骤s5.3:根据待测样本的质量变量样本关于辅助变量样本的条件概率分布,计算待测样本的质量变量样本的预测值:
进一步地,所述辅助变量样本包括:炉膛温度、炉管外壁温度、引风机转速、烧嘴燃料量、进风量中的一种或多种。
进一步地,所述质量变量样本包括:氧气浓度、一氧化碳浓度和二氧化碳浓度中的一种或多种。
显然,本发明的上述实施例仅仅是为清楚地说明本发明技术方案所作的举例,而并非是对本发明的具体实施方式的限定。凡在本发明权利要求书的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!