一种慢性心力衰竭患者PRO预后风险模型及构建方法
一种慢性心力衰竭患者pro预后风险模型及构建方法
技术领域
1.本发明涉及机器学习和数据处理技术领域,具体为一种慢性心力衰竭患者pro预后风险模型及构建方法。
背景技术:
2.慢性心力衰竭是各种心血管疾病的终末阶段,尽管近年来心衰治疗取得很大的进展,但其再住院率、死亡率仍居高不下,这与疾病预后不良和院外管理“断崖式”下降密切相关。因此,建立科学的心衰患者院外评估体系/系统,实时评估患者病情,持续对患者进行全病程、全方位、多领域、多维度的预后评估,对于采取个性化的干预措施,改善患者预后具有重要意义。
3.目前,临床上多采用人口统计学数据、临床症状及体征、实验室化验、影像学检查及生物标志物等评估患者预后。此类资料虽可反映患者的状态,但预测效能有限,较少涉及患者心理、社会、治疗等领域的健康状态,且常忽略了患者自身对于疾病的感受和观点。而且现有类似的量表大多均来源于国外,缺乏跨文化调试,无法直接应用于我国国人的健康评估。因此,制定适用于我国国人的pro测量工具对于评估患者健康状况、了解患者健康期望、制定患者管理方案至关重要。
4.此外,临床虽已开发了多种类型的风险预测模型,用以捕获患者总体风险,量化患者生存前景,但多惯用传统的统计模型,该类方法设定简单、解释性好,但预测能力有限,当数据结构复杂,不满足这些模型条件假定时,效果并不理想。而随着人类对疾病研究的加深,各种不同类型的数据陆续出现,数据结构的复杂性,使线性预测模型不得不因其局限性逐渐退出,与此同时大数据时代的发展使机器学习技术受到广泛关注,尤其是集成机器学习技术对于模型的改善效果更加显著。
5.综上所述,本技术利用自行研制的慢性心衰pro测量工具(chf-prom),以量表的形式反映患者健康状况,同时,结合患者一般人口学资料构建慢性心衰预后风险模型,将其与慢性病患者的院外管理相联系,全面便捷地从“生物-心理-社会-环境”医学新模式角度出发,捕获患者疾病状态,合理指导患者院外管理。
技术实现要素:
6.针对现有测量工具以及风险预测模型在预后评估中存在的问题本发明提供了一种慢性心力衰竭患者报告结局(pro)预后风险模型及构建方法。
7.为了达到上述目的,本发明采用了下列技术方案:
8.本发明提供了一种慢性心力衰竭患者pro预后风险模型的构建方法,包括以下步骤:
9.s1:研制慢性心力衰竭患者pro测量工具,建立随访队列;
10.s2:数据预处理;包括异常值识别、缺失值填补、类别比例不均衡问题的处理和特征筛选;
11.s3:根据预处理后的数据构建预测模型,得到慢性心力衰竭患者pro预后风险模型。
12.进一步,所述步骤s1具体包括以下步骤:
13.s11、慢性心力衰竭患者pro测量工具研制
14.按照国际pro测量工具研制规范,从生理领域、心理领域、社会领域和治疗领域出发,查阅国内外相关问卷及文献,结合专家意见与患者访谈的形式,形成初量表框架;
15.根据严格的纳入排除标准,招募105名慢性心衰患者和50名健康人进行预调查,采用经典测量理论和项目反应理论,对条目进行初步筛选和调整,形成初量表;
16.在365例患者,100例健康人群中进行大规模调查,并修改,形成终量表,即慢性心力衰竭患者pro测量工具;
17.s12、随访队列构建
18.顺序纳入2年内,三所三级甲等医院符合纳入和排除标准的患者;
19.住院期间,收集患者的一般资料和pro信息,患者出院后1个月、3个月和之后每6个月通过电话进行随访,随访内容为患者终点事件及发生时间。
20.进一步,所述步骤s2具体包括以下步骤:
21.s21、异常值识别:对原始数据集中的异常值进行识别,并与临床医师合作进行专业判断,进行删除或保留处理;
22.s22、缺失值填补:对缺失比例大于30%的分类变量进行删除,对缺失比例不大于30%的分类变量采用missforest函数进行填补;
23.s23、类别比例不均衡问题的处理:使用smote算法对数据不均衡问题进行处理;
24.s23、特征筛选:从患者的一般资料和pro信息两个角度进行特征变量的收集,由于pro测量工具部分的变量比较重要,且变量数目少,因此特征筛选工作仅对患者一般资料的变量进行;具体为,将患者一般资料的特征变量输入xgboost模型中,进行特征重要性排序,并结合临床专家建议,选择排序靠前的16个变量与pro测量工具中的4个变量作为最终的变量筛选结果,用于纳入最终的预测模型。
25.进一步,所述步骤s3预测模型构建的具体过程为:
26.将进行预处理后的数据输入logistic回归、随机森林模型(rf)、极限梯度增强学习机(xgboost)、轻梯度提升机(lightgbm)、朴素贝叶斯(nb)和多层感知学习机(mlp)模型中,通过以下3个阶段构建预测模型,
①
以患者一般资料为自变量构建预测模型;
②
以患者一般资料+慢性心力衰竭患者报告结局测量工具chf-prom四个领域为自变量构建模型;
③
通过学习曲线和网格搜索对
②
的参数进行调整,得到各机器学习算法的最优配置;所有模型构建采用python 3.7的各种软件包进行分析;
27.具体构建过程如下:
28.定义数据集d=(xi,yi),其中xi表示第i个样本的各特征变量,yi为第i个样本的预测变量;
29.构建决策树模型,定义函数fk代表第k棵数的权重;
30.定义目标函数为:式中l代表损失函数,用来衡量
与真实值(yi)之间的差距,ω是正则项,用于防止模型过拟合;
31.对目标函数进行二阶泰勒展开结果如下:
[0032][0033]
其中,gi和hi是第t棵残差树的参数,当目标函数值达到最小状态时,各参数取值为最优模型参数,其构建模型为当前最优的预测模型,const表示前面树的复杂度,即
[0034]
更进一步,所述步骤s11中的终量表即慢性心力衰竭患者pro测量工具包括4个领域共57个条目,其中生理领域(phd)16条,心理领域(psd)21条,社会领域(sod)8条,治疗领域(tre)12条,具体信息如下表:
[0035][0036]
所述步骤s12中纳入标准为:根据esc指南诊断为慢性心力衰竭,纽约心脏协会心功能ii-iv级的患者;排除标准为:排除两个月前发生急性心血管事件或因智力障碍无法完成问卷的患者。
[0037]
所述患者的一般资料包括年龄、性别、体重指数、职业、教育程度、医保类型、吸烟和饮酒史、家族史、血压、心率、nyha分级及合并症;其中合并症包括冠心病、心脏瓣膜病、高血压、糖尿病、房颤、慢性阻塞性肺疾病、慢性肾功能不全、肿瘤、中枢神经系统疾病;所述pro信息包括4个领域共57个条目,其中生理领域(phd)16条,心理领域(psd)21条,社会领域(sod)8条,治疗领域(tre)12条,具体信息如下表:
[0038]
[0039][0040]
本发明又提供了一种基于上述方法构建得到的慢性心力衰竭患者pro预后风险模型。
[0041]
本发明还提供了一种基于上述预后风险模型的慢性心力衰竭患者结局事件发生风险预测系统,所述系统是通过python软件将性能最优的慢性心力衰竭患者pro预后风险模型搭建于网络在线预测系统中形成的。
[0042]
与现有技术相比本发明具有以下优点:
[0043]
1.本发明采用自行研制设计的慢性心力衰竭患者pro测量工具,从生理领域、心理领域、社会领域和治疗领域多个维度进行综合评估,而且对测量工具进行信度、效度和可行性分析,表明所研制的测量工具真实可靠,可作为评估慢性心力衰竭临床治疗和临床试验的有效工具。
[0044]
2.本发明将自行研制的pro测量工具与一般资料结合使用,构建了机器学习的pro预后风险模型,经过对比实验分析表明构建的模型可保证良好的预测精度。
[0045]
3.本发明pro预后风险模型可搭建在网络在线预测系统中形成具有以下优点的风险预测系统,
[0046]
(1)所需信息易于获得,可大大提高患者依从性。不同于其它已开发的预测系统(严重依赖实验室检测指标),本发明风险系统仅通过询问患者一般情况类资料和pro测量工具评估信息,可对患者不同结局事件发生的风险进行实时个性化预测。
[0047]
(2)简单,普适性高。本系统操作界面简单,输出窗口表达简洁明了,对于大多数使用者来说,都可独立完成任务。
附图说明
[0048]
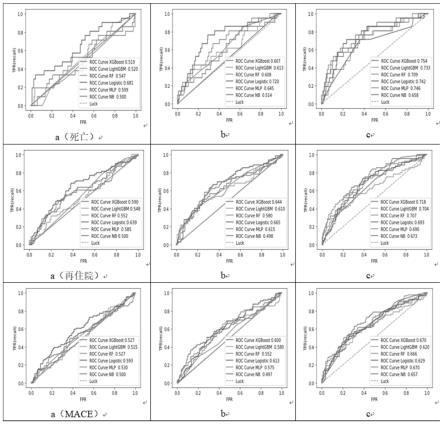
图1为实施例1中6种机器学习方法的roc曲线比较。图中第一行为患者死亡预测,第二行为再住院预测,第三行为mace预测,每一行中a、b、c分别代表模型1、模型2和模型3。
[0049]
图2为本发明可视化风险预测系统。
具体实施方式
[0050]
下面结合本发明实施例和附图,对本发明的技术方案进行具体、详细的说明。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干变型和改进,这些也应视为属于本发明的保护范围。
[0051]
一种慢性心力衰竭患者pro预后风险模型的构建方法,包括以下步骤:
[0052]
s1:研制慢性心力衰竭患者pro测量工具,建立随访队列;
[0053]
s2:数据预处理;包括异常值识别、缺失值填补、类别比例不均衡问题的处理和特征筛选;
[0054]
s3:根据预处理后的数据构建预测模型,得到慢性心力衰竭患者pro预后风险模型。
[0055]
所述步骤s1具体包括以下步骤:
[0056]
s11、慢性心力衰竭患者pro测量工具研制
[0057]
按照国际pro测量工具研制规范,从生理领域、心理领域、社会领域和治疗领域出发,查阅国内外相关问卷及文献,结合专家意见与患者访谈的形式,形成初量表框架;
[0058]
根据严格的纳入排除标准,招募105名慢性心衰患者和50名健康人进行预调查,采用经典测量理论和项目反应理论,对条目进行初步筛选和调整,形成初量表;
[0059]
在365例患者,100例健康人群中进行大规模调查,并修改,形成终量表,即慢性心力衰竭患者pro测量工具;测量工具包括4个领域共57个条目,其中生理领域(phd)16条,心理领域(psd)21条,社会领域(sod)8条,治疗领域(tre)12条,具体信息如下表:
[0060][0061]
s12、随访队列构建
[0062]
顺序纳入2年内,三所三级甲等医院符合纳入和排除标准的患者;纳入标准为:根据esc指南诊断为慢性心力衰竭,纽约心脏协会心功能ii-iv级的患者;排除标准为:排除两个月前发生急性心血管事件或因智力障碍无法完成问卷的患者。
[0063]
住院期间,收集患者的一般资料和pro信息,患者出院后1个月、3个月和之后每6个月通过电话进行随访,随访内容为患者终点事件及发生时间.
[0064]
所述患者的一般资料包括年龄、性别、体重指数、职业、教育程度、医保类型、吸烟和饮酒史、家族史、血压、心率、nyha分级及合并症;其中合并症包括冠心病、心脏瓣膜病、高血压、糖尿病、房颤、慢性阻塞性肺疾病、慢性肾功能不全、肿瘤、中枢神经系统疾病。
[0065]
所述步骤s2具体包括以下步骤:
[0066]
s21、异常值识别:对原始数据集中的异常值进行识别,并与临床医师合作进行专业判断,进行删除或保留处理;
[0067]
s22、缺失值填补:对缺失比例大于30%的分类变量进行删除,对缺失比例不大于30%的分类变量采用missforest函数进行填补;
[0068]
s23、类别比例不均衡问题的处理:使用smote算法对数据不均衡问题进行处理;
[0069]
s23、特征筛选:从患者的一般资料和pro信息两个角度进行特征变量的收集,由于pro测量工具部分的变量比较重要,且变量数目少,因此特征筛选工作仅对患者一般资料的
变量进行;具体为,将患者一般资料的特征变量输入xgboost模型中,进行特征重要性排序,并结合临床专家建议,选择排序靠前的16个变量与pro测量工具中的4个变量作为最终的变量筛选结果,用于纳入最终的预测模型。
[0070]
所述步骤s3预测模型构建的具体过程为:
[0071]
将进行预处理后的数据输入logistic回归、随机森林模型rf、极限梯度增强学习机xgboost、轻梯度提升机lightgbm、朴素贝叶斯nb和多层感知学习机mlp模型中,通过以下3个阶段构建预测模型,
①
以患者一般资料为自变量构建预测模型;
②
以患者一般信息+慢性心力衰竭患者报告结局测量工具chf-prom四个领域为自变量构建模型;
③
通过学习曲线和网格搜索对
②
的参数进行调整,得到各机器学习算法的最优配置;所有模型构建采用python 3.7的各种软件包进行分析;
[0072]
具体构建过程如下:
[0073]
定义数据集d=(xi,yi),其中xi表示第i个样本的各特征变量,yi为第i个样本的预测变量;
[0074]
构建决策树模型,定义函数fk代表第k棵数的权重;
[0075]
定义目标函数为:式中l代表损失函数,用来衡量预测值与真实值之间的差距,ω是正则项,用于防止模型过拟合;
[0076]
对目标函数进行二阶泰勒展开结果如下:
[0077][0078]
其中,gi和hi是第t棵残差树的参数,当目标函数值达到最小状态时,各参数取值为最优模型参数,其构建模型为当前最优的预测模型,const表示前面树的复杂度,即
[0079]
实施例1
[0080]
一种慢性心力衰竭患者pro预后风险模型的构建
[0081]
步骤1:慢性心力衰竭患者pro测量工具研制,并建立随访队列。
[0082]
步骤1-1:慢性心力衰竭患者pro测量工具研制
[0083]
按照国际pro测量工具研制规范,从生理领域、心理领域、社会领域和治疗领域出发,查阅大量国内外相关问卷及文献,结合专家意见与患者访谈的形式,形成初量表框架。根据严格的纳入排除标准,在八所医院招募了105名慢性心衰患者和50名健康人进行预调查,采用经典测量理论和项目反应理论,对条目进行初步筛选和调整,形成初量表。在365例患者,100例健康人群中进行大规模调查,并修改,形成终量表,即慢性心力衰竭患者pro测量工具(chf-prom)。终量表包括4个领域共57个条目,其中生理领域16条,心理领域21条,社会领域8条,治疗领域12条。具体信息如下表1所示:
[0084]
表1chf-prom结构
[0085][0086]
对终量表,即测量工具进行信度、效度和可行性分析,表明所研制的测量工具真实可靠。
[0087]
(1)信度分析:克朗巴赫系数是目前最常用的信度系数,一般认为该指标应该达到0.7以上,数值越高表明一致性程度越高,该测量工具信度分析结果见下表2。
[0088]
表2信度分析结果(克朗巴赫系数)
[0089][0090][0091]
(2)效度分析:包括内容效度、结构效度、维度相关性、区分度
[0092]
内容效度:本项目pro测量工具编制过程中,结合文献查询法、专家咨询法和患者访谈法进行条目的构建/筛选/修正,可保证测量工具的内容效度。
[0093]
结构效度:采用验证性因子方法(cfa)对测量工具结构效度进行分析,测量结果显示(表3):近似误差均方根(rmsea)、均方根残差(rmr)、规范拟合指数(nfi)、不规范拟合指数(nnfi)、比较拟合指数(cfi)和增值拟合指数(ifi)等模型拟合指标都达到了参考标准中相应的要求,该测量工具的结构效度较高。
[0094]
表3结构效度分析(验证性因子方法)
[0095][0096]
维度相关性:生理领域、心理领域、社会领域和治疗领域中各条目相关性分析结果显示相关系数r均在0.50以上,即各条目与其所属领域间存在较强相关性。
[0097]
区分度:在本次调查中,患者和对照组在量表各维度的得分及量表总得分差异均有统计学意义(表4)。说明该测量工具的区分度较高,可以区分不同生存质量的人群。
[0098]
表4区分度分析结果
[0099][0100]
(3)可行性分析:该测量工具在大规模临床调查中,回收率为98.94%,有效回收率为98.92%,每份调查表在十五分钟左右完成。说明本测量工具有很好的可行性。
[0101]
步骤1-2:随访队列构建
[0102]
顺序纳入2017年7月1日至2019年6月30日,三所三级甲等医院符合纳入和排除标准的患者。纳入标准为:根据esc指南诊断为慢性心力衰竭,纽约心脏协会(nyha)心功能ii-iv级的患者。并排除两个月前发生急性心血管事件或因智力障碍无法完成问卷的患者。所有受试者均签署知情同意书。本研究按照《赫尔辛基宣言》进行,并经山西医科大学审查委员会(irb)批准。
[0103]
住院期间,收集患者的一般资料和患者报告结局(pro)信息。患者出院后1个月、3个月和之后每6个月通过电话进行随访,随访内容为患者终点事件及发生时间。为保证收集到的数据质量,所有的问卷都由经过专业培训的人员收集。
[0104]
一般资料包括年龄、性别、体重指数(bmi)、职业、教育程度、医保类型、吸烟和饮酒史、家族史、血压、心率、nyha分级及合并症。其中合并症包括冠心病、心脏瓣膜病、高血压、
糖尿病、房颤、慢性阻塞性肺疾病、慢性肾功能不全、肿瘤、中枢神经系统性疾病。
[0105]
步骤2:数据预处理
[0106]
步骤2-1:异常值识别。对原始数据集中的异常值进行识别,为保证异常值识别的准确性,对于各变量两个标准差范围外的样本分布,均由临床医师进行专业判断,再进行处理(删除/保留)。
[0107]
步骤2-2:缺失值填补。为确保填补数据尽可能保持原始数据的分布结构,对缺失比例过大(大于30%)的变量进行删除。测量工具数据分类变量较多,常规变量填补方法无法识别分类变量,因此对于缺失比例较小的变量采用missforest进行填补。此外,为防止信息泄露,对内部训练数据与外部验证数据的特征集进行分开填补,以外部验证数据为例:
[0108]
假设我们的数据为n*p的特征矩阵x=(x1,x2,...,xs,...,x
p
),假设表示缺失变量(xs)的观测值;表示xs的缺失值;表示xs以外的观测变量值;表示xs的缺失值以外的其余观测值,构建过程:
[0109]
构建的随机森林模型;
[0110]
通过已构建的随机森林模型,用预测进行填补;
[0111]
对于连续变量,当最小时,或分类变量最小时,停止迭代,即最新一次的填补结果与上一次的一致,即为缺失变量最终的填补结果。
[0112]
步骤2-3:类别比例不均衡问题的处理(以死亡预测系统为例,13:1)
[0113]
在慢性疾病风险预测模型的构建中,类别比例严重失衡的现象非常普遍,若不处理,很可能导致预测结果偏向类别较多的一类,对于少数类样本的预测能力就非常有限。为此本技术通过smote算法,对各结局预测系统中的少数类样本进行重采样,使发生结局事件的样本比例与未发生结局事件的样本比例达到1:1,具体构建如下:
[0114]
对于发生死亡事件的每一个样本x,计算其与死亡事件集中每一个样本的欧氏距离,作为其k近临结果。
[0115]
根据原始数据中结局事件类别分布比例,设置死亡预测模型中的采样倍率n为13,再住院采样倍率为3,mace采样倍率为2,从其k近邻中随机选择若干个样本,假设选择的近邻集为xn。
[0116]
选定其中一个k近邻,生成0到1间的随机数rand(0,1),通过以下公式生成新的少数类样本,并重复该步骤,直至达到采样倍率。
[0117][0118]
步骤2-4:特征筛选。
[0119]
本实施例特征变量从两个角度进行收集,角度1:患者一般资料变量,包括年龄、性别、体重指数(bmi)、职业、教育程度、医保类型、吸烟和饮酒史、家族史、血压、心率、nyha分级及合并症。其中合并症包括冠心病、心脏瓣膜病、高血压、糖尿病、房颤、慢性阻塞性肺疾病、慢性肾功能不全、肿瘤、中枢神经系统疾病。角度2:pro测量工具信息,从患者的生理领域、心理领域、社会领域和治疗领域对患者信息进行综合评估,并将各领域条目得分相加,
得到各领域总得分,最终整理成4个变量进入模型。因pro测量工具部分的变量比较重要,且变量数目少,特征筛选工作仅对角度1的变量进行。
[0120]
将患者一般资料中的24个变量输入xgboost模型中,进行特征重要性排序,并结合临床专家建议,选择排序靠前的16个变量与pro测量工具中的4个变量作为最终的变量筛选结果,并纳入最终的预测模型。
[0121]
步骤3-1:预测模型构建。
[0122]
将经过数据预处理和类别不平衡处理的内部验证数据,进行变量特征选择后输入logistic回归、随机森林模型(rf)、极限梯度增强学习机(xgboost)、轻梯度提升机(lightgbm)、朴素贝叶斯(nb)和多层感知学习机(mlp)模型中,通过3个阶段构建预测模型:
①
模型1:以患者一般资料为自变量构建预测模型;
②
模型2:以患者一般资料+chf-prom四个领域为自变量构建模型;
③
模型3:通过学习曲线和网格搜索对模型2的参数进行调整,得到各机器学习算法的最优配置。所有模型构建采用python 3.7的各种软件包进行分析。各软件包及调整各机器学习算法的关键变量如表5所示。具体构建如下:
[0123]
定义数据集d=(xi,yi),其中xi表示第i个样本的各特征变量,yi为第i个样本的预测变量;
[0124]
构建决策树模型,定义函数fk代表第k棵数的权重;
[0125]
定义目标函数为:式中l代表损失函数,用来衡量预测值与真实值之间的差距,ω是正则项,用于防止模型过拟合;
[0126]
对目标函数进行二阶泰勒展开结果如下:
[0127][0128]
其中,gi和hi是第t棵残差树的参数,当目标函数值达到最小状态时,各参数取值为最优模型参数,其构建模型为当前最优风险预测模型,const表示前面树的复杂度,即
[0129]
表5机器学习方法的参数调整
[0130]
[0131][0132]
评估机器学习模型(以死亡预测系统为例)。
[0133]
遍历每个机器学习算法的所有参数组合,然后使用10倍交叉验证确定预测效果。将本实施例构建的预测模型应用于心血管病医院患者,通过采用曲线下面积(area under curve,auc)评估预测模型的识别能力,brier score评估模型概率的准确性,对比各模型预测结果,择优搭建与在线预测系统(患者死亡预测系统、再住院预测系统、mace预测系统)中。
[0134]
模型比较结果如表6所示。结果表明,在一般资料中加入chf-prom后,所有模型的准确性和分辨力均显著提高。表明调整参数进一步改善了模型的性能。
[0135]
表6:cox比例风险模型中3种结果的风险比
[0136][0137]
6种机器学习方法中,xgboost对3种结局的预测性能均最高,其次为随机森林模型。xgboost模型的平均auc为死亡0.754(95%ci:0.737-0.761),心衰再住院0.718(95%ci:0.717-0.721),maces 0.670(95%ci:0.595-0.710)。模型比较的roc如图1所示。
[0138]
综合表明:用xgboost模型构建的患者死亡预测系统、再住院预测系统、mace预测系统的效果均为最高。
[0139]
实施例2
[0140]
搭建风险预测系统。
[0141]
为了便于实施例1的预测模型在临床实践中的应用,本实施例通过python软件,进一步将实施例1中性能最优的慢性心力衰竭患者pro预后风险模型搭建于网络在线预测系统中,即形成风险预测系统。
[0142]
如将死亡预测模型、再住院预测模型、mace事件预测模型搭建于网络在线预测系统中能分别形成患者死亡预测系统、再住院预测系统、mace预测系统。
[0143]
在预测系统中,患者的连续变量通过拖拽进行分配,分类变量通过下拉进行选择。以图2中的病人为例,该预测系统预测61岁,女性,已婚,初中文化程度,农民,中等收入,新农合,无家族史,bmi 27kg/m2,心率113次/分,血压130/98mmhg,心功能iii级,合并房颤、冠心病、糖尿病及中枢神经系统疾病,无高血压、肾功能不全、慢性阻塞性肺疾病、癌症及心脏瓣膜病,生理领域30分,心理领域57分,社会领域32分,治疗领域33分。患者2年病死率为20.16%,心衰再住院率为94.81%,主要心血管不良事件发生率为55.22%。可以看到该系统不同于其他已开发的预测系统,不需要严重依赖实验室检测指标,仅通过询问患者的一般资料和pro测量工具评估信息,就可以对不同结局事件发生的风险进行实时个性化预测。而且其操作界面简单,输出窗口表达简洁明了。
[0144]
虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技
术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1