基于多复杂度减速器装配场景的N-Back次任务脑电试验方法
基于多复杂度减速器装配场景的n-back次任务脑电试验方法
技术领域
1.本发明涉及认知负荷的分类评估技术领域,具体涉及一种基于多复杂度减速器装配场景的n-back次任务脑电试验方法。
背景技术:
2.目前,国内外学者对认知负荷评估方法进行了深度研究,常用方法主要有:主观评定法、任务绩效测量法、生理测量法。主观评定法是操作者对任务过程中个体负荷的事后评测,主要包括:nasa-tlx量表、swat法、pass自我评定量表、wp量表等。
3.nasa-tlx量表,如文献[1]:李乃梁,陆勇,李开伟.无人机操作主观心理负荷测评与心率数据比较[j].中国安全生产科学技术,2021,17(4):35-41.和文献[2]:hirachan n,mathews a,romero j,et al.measuring cognitive workload using multimodal sensors[j].arxiv preprint arxiv:2205.04235,2022.记载。
[0004]
swat法如文献[3]:晋良海,李宬.高处作业人员心理负荷的swat量表主观评定方法研究[j].安全与环境工程,2015,22(3):70-74,82.记载。
[0005]
wp量表如文献[4]:李文斌,刘志胜,谢小萍,等.5种量表在测量飞行活动主观脑力负荷中的适用性比较[j].航天医学与医学工程,2020,33(3):221-227记载。
[0006]
然而,由于个体感知差异,评定结果的准确性与可靠性不高。任务绩效测量法是通过主、次任务的完成情况评价操作者的认知负荷,虽然该方法评价结果相对准确,但不同的次任务对主任务的影响不同,试验设计要求相对较高。生理测量法根据其采用的生理指标可分为:脑电(electroencephalogram,eeg)、心电(electrocardio-gram,ecg)、皮电(galvanic skin response,gsr)、眼动、呼吸等特征指标。其中,脑电具有高时间分辨率、非入侵式、信号精度高等优点,是现阶段认知负荷研究的主要方式。如文献[5]:baig m z,kavakli m.analyzing novice and expert user’s cognitive load in using a multi-modal interface system[c]//2018 26th international conference on systems engineering(icseng).ieee,2018:1-7.中记载。
[0007]
文献[6]:hogervorst m a,anne-marie b,van e.combining and comparing eeg,peripheral physiology and eye-related measures for the assessment of mental workload[j].frontiers in neuroscience,2014,8(322):322.中hogervorst等分别采用脑电、心电、皮电与眼动4种测量方式对不同程度的n-back任务进行认知负荷测量,证明脑电信号与认知负荷之间的关系最显著;傅嘉豪等研究不同任务组合状态下脑电负荷变化情况,证明计算难度与次任务对脑力负荷均有影响,且脑电节律会随脑力负荷变化而变化。
[0008]
文献[7]:zhang d,zhao h,bai w,et al.functional connectivity among multi-channel eegs when working memory load reaches the capacity[j].brain research,2016,1631:101-112.中zhang d等采用6级视觉工作记忆任务与节律频谱分析对负荷进行研究,结果表明,节律最强的连接强度分布在额叶中线区域,且脑电波之间的功能
连接性会随着认知过载而变弱。
[0009]
文献[8]:dai z,pr
í
ncipe j c,bezerianos a,et al.cognitive workload discrimination in flight simulation task using a generalized measure of association[c]//international conference on neural information processing.springer,cham,2015:692-699.中dai等研究表明,使用与认知负荷无关的脑区信号会对认知负荷评估结果产生干扰。
[0010]
近些年,随着机器学习、深度学习等方法的发展,认知负荷分类评估模型成为该领域的研究热点。
[0011]
文献[9]:fernandez rojas r,debie e,fidock j,et al.electroencephalographic workload indicators during teleoperation of an unmanned aerial vehicle shepherding a swarm of unmanned ground vehicles in contested environments[j].frontiers in neuroscience,2020,14:40.中fernandez等研究在遥控操作任务中多维特征对操作者认知负荷的影响,并采用性能良好且计算成本较低的lda算法对无人机操控员的4个负荷水平进行分类,最终获得较好的分类结果。
[0012]
文献[10]:so w,wong s,mak j n,et al.an evaluation of mental workload with frontal eeg[j].plos one,2017,12(4):e0174949.中so等通过4项认知任务证明额叶节律可用于评估认知负荷的动态变化,并采用svm模型对认知负荷进行分类。
[0013]
文献[11]:li j,zhang j.mental workload classification based on semi-supervised extreme learning machine[c]//international conference on artificial neural networks.springer,cham,2017:297-304.中li等采用多种方法对生理信号进行特征提取,引入ss-elm算法实现认知负荷分类,并证明了该方法的有效性。上述研究大多模拟汽车或飞机驾驶环境,提取生理信号,运用现有的分类算法,完成认知负荷分类研究。
[0014]
然而,复杂装配系统中操作员的认知负荷对企业生产安全也十分重要,但目前研究较少。另外,针对认知负荷分类问题,多数学者通过增加分类特征提高分类性能,鲜有学者针对认知负荷数据特征对算法进行改进。
技术实现要素:
[0015]
为解决上述技术问题,本发明提供一种基于多复杂度减速器装配场景的n-back次任务脑电试验方法,通过收集脑电信号与装配数据,结合主观评定数据,研究基于特征融合的装配系统操作员认知负荷分类评估模型,分析数据特征,构建基于互信息量的随机森林模型以提高认知负荷分类准确率,为开发以人为本的复杂装配系统和安全生产系统奠定理论基础。
[0016]
本发明采取的技术方案为:
[0017]
基于多复杂度减速器装配场景的n-back次任务脑电试验方法,包括以下步骤:
[0018]
步骤一:受试者佩戴脑电仪,用于减速器装配试验数据采集;
[0019]
步骤二:为了解不同难度装配任务对受试者的影响,受试者按照简单装配任务、一般装配任务、复杂装配任务的顺序,依次完成3种不同复杂度的装配任务;
[0020]
步骤三:为了进一步模拟真实的减速器装配试验场景,并对受试者认知负荷进行
分类,引入n-back听觉反馈试验,作为减速器装配任务的次任务,依照0-back,1-back,2-back的顺序将次任务分为3级,依次对应低级认知负荷、中级认知负荷、高级认知负荷;
[0021]
步骤四:每位受试者完成装配任务后,填写nasa_tlx量表;随机选择下一位受试者完成试验,直至所有受试者均完成减速器装配试验;
[0022]
步骤五:采集并获取减速器装配试验数据指标,包括主观评价指标(the subjective feature,tsf)、脑电特征指标(eeg)、装配任务指标(workshopassembly,wa),并对指标进行数据处理;
[0023]
步骤六:构建基于互信息量的随机森林模型,实现了受试者认知负荷的分类评估。
[0024]
所述步骤一中,按脑电仪规定位置,将电极安置于受试者头部相应位置,并紧贴头皮以保证信号平稳传输,受试者端坐于装配试验台前,按照指定顺序完成减速器装配动作;脑电仪采集的信号能够通过无线蓝牙传输至计算机,完成数据采集工作。
[0025]
所述步骤三中,n-back听觉反馈试验具体操作步骤为:在受试者装配减速器过程中,每隔一段时间会听到一组语音播报,每组语音播报包括字母“a-i”中的一个随机字母,直至减速器装配任务结束,语音播报停止播放;
[0026]
当次任务难度为0-back时,受试者在听到两组相同字母时回答“正确”;
[0027]
当次任务难度为1-back时,受试者在听到两组相隔一组语音播报的两个字母相同时回答“正确”;
[0028]
当次任务难度为2-back时,受试者在听到两组相隔两组语音播报的两个字母相同时回答“正确”。
[0029]
所述步骤五中,对指标进行数据处理包括:
[0030]
(1):主观评价指标与装配任务指标数据处理:
[0031]
对nasa_tlx量表各维度评分结果进行归一化处理,再对各维度处理后的数据进行算术平均,最后将得到的平均值作为主观评价结果;计算公式如下所示:
[0032][0033][0034]
式中:x
i-nasa_tlx量表的第i个维度评分;
[0035]
x
ij-第i个维度的第j行数据;
[0036]yij-x
ij
归一化处理后的数据;
[0037]
z-处理后的主观评分。
[0038]
(2):脑电特征指标数据处理:
[0039]
采用脑电数据预处理工具eeglab,依次完成通道定位与删除、信号滤波、基线校正、重参考与降采样、剔除坏段5个步骤,并筛选出0.5~50hz之间的信号波段,利用式(3)~式(6)分别计算出各组脑电信号的均值、标准差、偏度、峰度;再采用7层小波包分解重构,得到α,β,θ波段信号,依据式(7)求出各频率波段的平均功率;(θ-α/β)的变化规律对认知负荷分类有较好的区分度,因此,将其定为认知负荷脑电特征指标之一;
[0040][0041][0042][0043][0044][0045]
式中:a
cd-第d个脑电通道的第c行数据;
[0046]
n-脑电数据总量;
[0047]
μ
d-第d个脑电通道数据的均值;
[0048]
σ
d-第d个脑电通道数据的标准差;
[0049]ad-第d个脑电通道数据;
[0050]
e—数学期望;
[0051]
γ
1d-第d个脑电通道的偏度;
[0052]
γ
2d-第d个脑电通道的峰度;
[0053]
p
e-某波段信号的平均功率,其中,e可选取的范围包括α,β,θ三种节律;
[0054]
a,b-各频段的频率上限和频率下限;
[0055]
p(f)-各节律的功率谱密度。
[0056]
采用wilcoxon非参数检验对脑电特征数据进行显著性检验。
[0057]
(3):对上述所有指标进行数据标准化处理,计算公式如下所示:
[0058][0059]
式中:r
o-标准化后的特征数据;
[0060]
x
o-各特征的原始数据;
[0061]-各特征的均值;
[0062]
s-各特征的样本标准差。
[0063]
所述步骤六包括如下步骤:
[0064]
s6.1:构建基础随机森林模型;
[0065]
s6.2:构建决策树相关性度量矩阵,以此判断两决策树之间的相关性,该矩阵由特征集相关性度量矩阵和样本相关性度量矩阵两部分组成,通过对两者进行均值计算,从而获得决策树相关性度量矩阵;
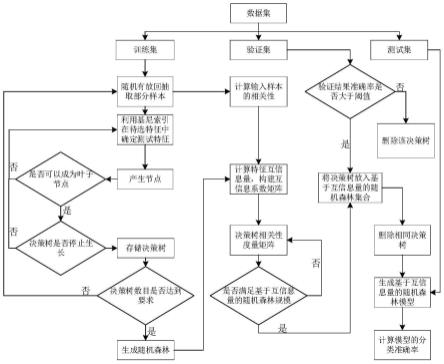
[0066]
s6.2.1:构建特征集互信息系数矩阵:
[0067]
首先,计算两特征之间的互信息量,互信息量是指一个随机变量中包含另一随机变量的信息量,可以有效度量两个随机变量之间的相关性,因此,采用互信息量建立特征集互信息矩阵。随机选择两特征,分别对两特征建立散点图,再对散点图区域进行网格划分,划分为等面积的225个小区域,分别计算出两特征在每个小区域内出现的概率,记为p(x)和p(y),另将两特征数据分别作为横纵坐标轴,建立联合散点图,用同样的方法画分区域,计算出各区域数据出现的概率,记为p(x,y),通过式(9),特征x和特征y之间的互信息量为:
[0068][0069]
其次,计算两特征之间的互信息系数。为进一步提高特征相关性度量准确性,对两特征的互信息量进行正则化处理,即可获得两特征之间的互信息系数。计算公式如下:
[0070][0071]
式中:——特征x与特征y之间的互信息系数;
[0072]
m——特征x或特征y方向上划分的网格数。
[0073]
s6.2.2:构建样本相关性度量矩阵:
[0074]
对已构建的基础随机森林模型中决策树d
p
和dq的样本进行相关性计算。输入样本相关性主要考虑两决策树训练子集中相同样本所占比率,即样本相关性可表示为相同样本与总样本的比值,计算公式如下所示:
[0075][0076][0077]
式中:s(df,dq)——决策树df,dq的样本相关性;
[0078]
g(df,dq)——决策树df,dq的样本判别函数。
[0079]
s6.2.3:构建决策树相关性度量矩阵:
[0080]
在决策树d
p
建立过程中,将某节点与上一节点所选特征的互信息系数作为该节点的特征相关性,再将该决策树的所有节点特征相关性的均值作为该决策树的特征相关性,两决策树之间的特征相关性定义为这两棵决策树特征相关性的算术平均值。对已构建的基础随机森林模型中的所有决策树均进行上述计算,即可建立特征集相关性度量矩阵。将特征集相关性度量矩阵与样本相关性度量矩阵进行均值计算,获得决策树相关性度量矩阵。
[0081]
[0082][0083][0084]
dtc=(fc+sc)/2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0085]
式中:fc——特征集相关性度量矩阵;
[0086]fc(d,e)
——决策树d和决策树e之间的特征相关性;
[0087]
——决策树d在第k
t
节点的特征相关性;
[0088]kt
——决策树的节点数,k
t
=1,2,3,...,k
t
;
[0089]
sc——样本集相关性。
[0090]
所述步骤六中,基于互信息量的随机森林模型算法,具体如下:
[0091]
首先,将原始数据采用六折交叉验证方法划分为训练集、测试集与验证集;
[0092]
其次,对训练集样本进行随机采样,建立样本子集与特征子集并构建基础随机森林模型,再对基础随机森林模型中的训练子集与决策树进行相关性计算,构建决策树相关性度量矩阵,利用验证集对每棵决策树进行准确率验证,选出准确率大于70%的决策树,并将其存储记为另选出决策树相关性度量矩阵数据中小于0.5的数据,并将其对应的决策树记为合并和两个集合,并判断其规模是否满足基于互信息量的随机森林模型所需决策树规模,若未达到数量要求,则继续在决策树相关性度量矩阵中选择,直至满足决策树规模。
[0093]
然后,将已选决策树集合中的相同决策树剔除,剩余决策树则构成基于互信息量的随机森林模型;
[0094]
最后,利用测试集对基于互信息量的随机森林模型准确性进行验证。
[0095]
所述步骤六中,采用随机森林模型、knn算法、支持向量机及组合分类模型4种算法作为基于互信息量的随机森林模型的对比算法,引入总体分类精度ac与kappa系数两个评估指标对算法分类结果进行分析:
[0096][0097][0098]
式中:t
l
——第l类分类正确的个数;
[0099]nl
——第l类样本的总量;
[0100]
h——样本总量
[0101]fl
——测试样本为第l类分类样本,但预测错误的个数;
[0102]ft
——预测结果为第t类,但样本不为第t类的样本数;
[0103]
g——类别总数。
[0104]
本发明一种基于多复杂度减速器装配场景的n-back次任务脑电试验方法,技术效果如下:
[0105]
1)本发明在分类模型构建时考虑互信息量模型,设计出基于互信息量的随机森林模型,采用knn、svm、ga-svm、随机森林模型4种分类算法作为对比算法,研究了不同特征输入下的认知负荷分类效果,并采用总体分类精度ac与kappa系数两个评估指标对算法分类结果进行分析。研究结果表明,基于互信息量的随机森林模型稳定性好,分类效果最佳;组合特征输入的分类效果明显优于单一特征输入的分类效果,且随着输入特征的增加,算法抗欠拟合能力增强,分类效果显著提升。
[0106]
2)通过试验数据分析,本发明方法中主观评分和装配任务指标均对次任务难度和任务复杂度有显著影响,p<0.05;且二者均随着次任务难度增加而增加;脑电特征数据中,除均值与偏度特征外,其他特征数据在不同次任务难度下均存在显著影响,p<0.05;n-back次任务脑电试验设计合理。
[0107]
3)本发明方法中,各特征因素对操作员认知负荷均有显著影响,且随认知负荷增加呈现规律性变化,认知负荷试验设计合理;基于互信息量的随机森林模型分类效果显著优于其他分类模型,多维特征可有效降低算法欠拟合能力,提高分类精度。
附图说明
[0108]
图1为改进后n-back听觉反馈实验示意图。
[0109]
图2为本发明试验流程图。
[0110]
图3(a)为在3种认知负荷分类标签下的α节律平均功率曲线图;
[0111]
图3(b)为在3种认知负荷分类标签下的β节律平均功率曲线图。
[0112]
图4为基于互信息量的随机森林模型算法流程图。
[0113]
图5(a)各算法在总体分类精度ac下的箱线图;
[0114]
图5(b)各算法在kappa系数下的箱线图。
[0115]
图6(a)为特征x散点图;
[0116]
图6(b)为特征x散点图;
[0117]
图6(c)为特征x和特征y的联合散点图。
具体实施方式
[0118]
基于多复杂度减速器装配场景的n-back次任务脑电试验方法,具体如下:
[0119]
(一)试验设计:
[0120]
1.1:受试者
[0121]
本发明基于多种复杂度的减速器装配场景,设计三层认知负荷的n-back次任务脑电试验。依据某工厂的男女比例,随机招募10名20~24岁的在校大学生。其中,男性被试者8名,女性被试者2名。被试者均身体健康,身体协调能力正常,右利手,在试验前均未服用过任何可能影响中枢神经系统的药物或食物,且在此之前都曾参加过减速器拆装任务实训,熟悉减速器装配流程。
[0122]
1.2:试验仪器:
[0123]
采用emotiv epoc x无线便携式脑电仪作为脑电信号采集装置,采集的信号可通过无线蓝牙传输至计算机,完成数据采集工作。按脑电仪规定位置,将电极安置于被试者(受试者)头部相应位置,并紧贴头皮以保证信号平稳传输,采样频率为128hz,受试者需端坐于装配试验台前,按照指定顺序完成减速器装配动作。
[0124]
1.3:试验任务
[0125]
该试验主要研究减速器装配任务,受试者按照装配说明将工作台上的零件依次安装,安装完成后由试验员检查是否全部安装并安装正确。同时,为了解不同难度装配任务对受试者的影响,要求受试者按照简单装配任务、一般装配任务、复杂装配任务的顺序,依次完成3种不同复杂度的装配任务。
[0126]
为了进一步模拟真实的装配场景,并对操作者(受试者)认知负荷进行分类,引入n-back听觉反馈任务作为减速器装配任务的次任务,依照0-back,1-back,2-back的顺序将次任务分为3级,依次对应低级认知负荷、中级认知负荷与高级认知负荷。
[0127]
本发明中,改进n-back听觉反馈试验具体操作步骤为:在操作者(受试者)装配减速器过程中,每隔3s会听到一组语音播报,每组语音播报包括a-i中的一个随机字母,直至减速器装配任务结束,语音播报停止播放。当次任务难度为0-back时,操作者(受试者)需在听到两组相同字母时回答“正确”;当次任务难度为1-back时,操作者(受试者)需在听到两组相隔一组语音播报的两个字母相同时回答“正确”;当次任务难度为2-back时,操作者(受试者)需在听到两组相隔两组语音播报的两个字母相同时回答“正确”。改进后的n-back听觉反馈试验示意图如图1所示,即当听到目标点字母时回答“正确”。
[0128]
1.4:试验流程
[0129]
当10位被试人员(受试者)到达人因工程实验室后,首先需了解并接受知情承诺书;然后随机选择一位受试者对3种减速器进行一次拆装,完成练习任务;随后,受试者调整座椅位置,端坐于实验台前,将减速器各部件摆放到规定位置,佩戴脑电仪器并调整电极位置,保证信号接收完整。此后,进入正式试验阶段,受试者依次在次任务难度为0-back,1-back,2-back状态下完成3种难度的减速器装配任务,即每位受试者完成9次装配任务,每次完成装配任务后,休息5min并填写nasa_tlx量表。最后,按照上述试验流程,随机选择下一位受试者完成试验,直至所有受试者均完成试验,试验结束。试验流程如图2所示。
[0130]
(二)数据处理与分析:
[0131]
本发明所需数据通过脑电仪器采集、受试者填写、试验获取等方式获取,具体数据指标可分为三类:主观评价指标(the subjective feature,tsf)、脑电特征指标(eeg)、装配任务指标(workshopassembly,wa)。具体指标如表1所示。
[0132]
表1认知负荷装配试验数据指标信息
[0133][0134]
2.1:主观评价指标与装配任务指标
[0135]
选取使用最为广泛的nasa_tlx量表作为主观评价量表,该量表由6个维度指标构成,即:脑力需求、身体负担、时间需求、任务绩效、努力程度、挫败感。由于该量表的评分结果过于主观,无法直接作为认知负荷的评价指标,因此,对该量表各维度评分结果进行归一化处理,再对各维度处理后的数据进行算术平均,最后将得到的平均值作为主观评价结果。计算公式如下所示:
[0136][0137][0138]
式中:xi——nasa_tlx量表的第i个维度评分;
[0139]
x
ij
——第i个维度的第j行数据;
[0140]yij
——x
ij
归一化处理后的数据;
[0141]
z——处理后的主观评分。
[0142]
主观评价指标与装配任务指标的描述性统计表如表2所示。
[0143]
表2主观评价指标与装配任务指标的描述性统计表(均值
±
标准差)
[0144][0145]
在(0-2)-back次任务状态下,随着任务复杂度提高,nasa_tlx主观评价指标结果也随之增加。通过单因素方差分析,在显著性水平为95%的情况下,(0-2)-back次任务状态下的f统计量结果分别为:f
0-back
=86.71>f(0.05),f
1-back
=42.71>f(0.05),f
2-back
=47.21>f(0.05),且p均小于0.05,另对样本进行t检验,p均小于0.05,结果表明,任务复杂度对nasa_tlx主观评价结果有显著影响;
[0146]
通过横向对比,分别在不同任务复杂度情况下对3种次任务进行单因素方差检验,f统计量结果分别为:f(简单)=441.70>f(0.05),f(一般)=580.74>f(0.05),f(复杂)=1015.85>f(0.05),且p均小于0.05,另对样本进行t检验,p均小于0.05,结果表明,次任务难度对nasa_tlx主观评价结果有显著影响。因此,受试者主观认知负荷会随着装配任务复杂度的增加而增加,也会随着次任务难度的提高而增加,且受试者在装配过程中对二者的变化有明显感觉。
[0147]
同理,分别在(0-2)-back次任务状态对装配任务指标进行单因素方差检验,在显著性水平为95%的情况下,(0-2)-back次任务状态下的f统计量结果除零件选错次数小于f(0.05),且p大于0.05外,其他统计结果均大于f(0.05),且p均小于0.05,可认定任务复杂度对除零件选错次数指标无显著影响,而对其他5项装配任务指标结果具有显著影响,再对样本进行t检验,除零件选错次数指标和0-back状态下次任务完成率中的简单装配任务与复杂装配任务无显著影响外(p=0.26),其他结果均表明任务复杂度对装配任务指标结果具有显著影响;另对样本进行横向对比,在显著性水平为95%的情况下,不同任务复杂度情况下3种次任务单因素方差检验f统计量结果均大于f(0.05),且p均小于0.05,可认定次任务难度对6项装配任务指标结果具有显著影响,通过t检验,p均小于0.05。因此,次任务难度对主观评价指标与装配任务指标均具有显著影响,该试验设计的次任务难度较为合理,且任
务复杂度与操作者(受试者)认知负荷有一定关联性。
[0148]
2.2:脑电特征指标
[0149]
脑电信号的高时间分辨率、非侵入式等优点使其成为认知负荷测量的有效工具,但外部环境与受试者自身会对脑电信号产生一定影响,因此需对脑电信号进行预处理。为方便信号处理,仅选取对认知负荷影响最大的脑区信号作为脑电信号指标的原始信号,即选取位于额叶、颞叶、枕叶、顶叶的8个脑电测量通道信号。
[0150]
文献[12]:伏云发,丁鹏,苏磊,等.国内外脑电分析处理软件现状分析及发展趋势[j].昆明理工大学学报自然科学版,2021,46(1):54-67.中的eeglab是最常用的脑电数据预处理工具,采用该工具可依次完成通道定位与删除、信号滤波、基线校正、重参考与降采样、剔除坏段5个步骤,并筛选出0.5~50hz之间的信号波段,利用式(3)~式(6)分别计算出各组脑电信号的均值、标准差、偏度、峰度,再采用7层小波包分解重构,得到α,β,θ波段信号,依据式(7)求出各频率波段的平均功率。
[0151]
有学者指出,(θ-α/β)的变化规律对认知负荷分类有较好的区分度,如文献[13]:喻浩文.基于脑电的飞行模拟训练认知负荷初步研究[d].南京:南京航空航天大学,2019.中记载。因此,将其定为认知负荷脑电特征指标之一。
[0152][0153][0154][0155][0156][0157]
式中:a
cd
——第d个脑电通道的第c行数据;
[0158]
n——脑电数据总量;
[0159]
μd——第d个脑电通道数据的均值;
[0160]
σd——第d个脑电通道数据的标准差;
[0161]ad
——第d个脑电通道数据;
[0162]
e——数学期望;
[0163]
γ
1d
——第d个脑电通道的偏度;
[0164]
γ
2d
——第d个脑电通道的峰度;
[0165]
pe——某波段信号的平均功率,其中,e可选取的范围包括α,β,θ三种节律;
[0166]
a,b——各频段的频率上限和频率下限;
[0167]
p(f)——各节律的功率谱密度。
[0168]
为选择合适的显著性检验方法,确保检验结果准确,对脑电特征数据进行正态性检验。经k-s检验与s-w检验,除1-back状态下的偏度特征数据为正态分布,其他特征数据均为非正态分布,因此,采用wilcoxon非参数检验对脑电特征数据进行显著性检验,分别检验0-back与1-back、1-back与2-back、0-back与2-back次任务状态下各脑电特征有无显著性差异,检验结果如表3所示。
[0169]
表3 3种次任务状态下各脑电特征描述统计与显著性检验表(均值
±
标准差)
[0170][0171][0172]
由表3可知,脑电特征中的均值与标准差在0-back与1-back任务状态下无明显变化,随着任务难度增加均呈现增加趋势,且在wilcoxon非参数检验结果中显示,1-back与2-back、0-back与2-back状态下的标准差均有显著差异(p<0.05),该现象表明脑电数据均值与脑电数据标准差对中低难度的认知负荷规律不敏感,而对高难度的认知负荷规律敏感。脑电数据偏度特征随着次任务难度增加呈现先减小后增大的趋势,但在1-back与2-back、0-back与2-back状态下无显著差异(p=0.387,p=0.145);脑电数据峰度特征随着次任务难度增加呈现先增大后减小的趋势,且在3种次任务状态下均有显著影响。α节律平均功率随着次任务难度增加呈现减小趋势,如图3(a)所示。
[0173]
而β节律平均功率如图3(b)所示、θ节律平均功率与θ-α/β的变化规律均随次任务难度增加而增加,且这4种节律特征在三种次任务状态下均有显著影响,与文献[14]:mahajan r,majmudar c a,khatun s,et al.neuromonitor ambulatory eeg device:comparative analysis andits application for cognitive load assessment[c]//2014ieee healthcare innovation conference(hic).ieee,2014:133-136.中maha jan等记载的研究结论十分相近。
[0174]
因此,对脑电特征分析表明,脑电数据标准差、脑电数据峰度、α节律平均功率、β节律平均功率、θ节律平均功率和θ-α/β的变化规律与装配认知负荷有较明显的关联性,且在不同难度次任务状态下均有规律性变化,可将其作为操作员认知负荷评价的有效指标。
[0175]
由表2、表3可知,主观评价指标、装配任务指标、脑电特征指标的量纲各不相同,为防止数据量纲差异过大对认知负荷分类预测准确性造成影响,并消除奇异样本数据产生的不良影响,对上述所有指标进行数据标准化处理。计算公式如下所示:
[0176]
[0177]
式中:ro——标准化后的特征数据;
[0178]
xo——各特征的原始数据;
[0179]
——各特征的均值;
[0180]
s——各特征的样本标准差。
[0181]
(三):认知负荷分类算法
[0182]
为避免小样本训练的模型陷入过拟合及对目标任务的欠拟合状态,确保模型有效提取到小样本中的重要信息,采用smote算法对认知负荷数据进行扩充,共获得363组数据,13种特征集合。另外,由于认知负荷数据具有数据量小、维度多、线性相关性强等特点,考虑到随机森林算法在处理小数据、高维数据分类问题中具有良好表现,且抗过拟合能力较强,因此,选用该算法为认知负荷分类问题的主算法,为解决数据线性相关性强的问题,对随机森林算法进行改进,建立基于互信息量的随机森林模型(random forest based on mutual information,mi-rf)。
[0183]
3.1:基础随机森林分类模型
[0184]
首先,构建基础随机森林模型。为准确评价算法性能,采用六折交叉运算建立训练集与测试集,再对训练集进行h次随机有放回取样,获得h组训练子集,在特征集中随机选择m种特征作为特征子集,对h组训练子集与特征子集构建cart决策树,重复k次,得到k棵不同的决策树,共同组成基础随机森林模型。具体构建流程如下:
[0185]
输入:原始训练集s;
[0186]
输出:分类准确率ac;
[0187]
(1)将原始训练集样本s均分为6份,并对每一份进行编号;
[0188]
(2)for ia=1,2,3,...,6
[0189]
(3)选择第ia份样本作为测试集t,其余样本作为新训练集
[0190]
(4)for k=1,2,3,...,k
[0191]
(5)对训练集进行n次随机有放回取样,获得h组训练子集;
[0192]
(6)在特征集中随机选择m种特征作为特征子集;
[0193]
(7)用id3算法对上述训练子集构建决策树d;
[0194]
(8)用测试集t对决策树d的分类性能进行验证,获得分类结果;
[0195]
(9)end
[0196]
(10)重复k次,得到k棵不同的决策树,共同组成基础随机森林模型,并将所有决策树分类结果的众数作为最终分类,计算分类精度a
c1
并存储;
[0197]
(11)end
[0198]
(12)计算六折交叉验证的总体分类精度ac=a
c1
/6。
[0199]
3.2:降低随机森林模型相关性
[0200]
为提高算法分类性能,避免因数据特征相关性强而导致分类错误率高的问题,设计基于互信息量的随机森林模型。该模型通过构建决策树相关性度量矩阵,以此判断两决策树之间的相关性。该矩阵由特征集相关性度量矩阵和样本相关性度量矩阵两部分组成,通过对两者进行均值计算,从而获得决策树相关性度量矩阵。
[0201]
3.2.1:构建特征集互信息系数矩阵
[0202]
首先,计算两特征之间的互信息量。互信息量是指一个随机变量中包含另一随机变量的信息量,可以有效度量两个随机变量之间的相关性,因此,采用互信息量建立特征集互信息矩阵。随机选择两特征,分别对两特征建立散点图,再对散点图区域进行网格划分,划分为等面积的225个小区域,如图6(a)、图6(b)所示。分别计算出两特征在每个小区域内出现的概率,记为p(x)和p(y),另将两特征数据分别作为横纵坐标轴,建立联合散点图,如图6(c)所示,用同样的方法画分区域,计算出各区域数据出现的概率,记为p(x,y),通过式(9),特征x和特征y之间的互信息量为:
[0203][0204]
其次,计算两特征之间的互信息系数。为进一步提高特征相关性度量准确性,对两特征的互信息量进行正则化处理,即可获得两特征之间的互信息系数。计算公式如下:
[0205][0206]
式中:——特征x与特征y之间的互信息系数;
[0207]
m——特征x或特征y方向上划分的网格数。
[0208]
3.2.2:构建样本相关性度量矩阵
[0209]
对已构建的基础随机森林模型中决策树d
p
和dq的样本进行相关性计算。输入样本相关性主要考虑两决策树训练子集中相同样本所占比率,即样本相关性可表示为相同样本与总样本的比值,计算公式如下所示:
[0210][0211][0212]
式中:s(df,dq)——决策树df,dq的样本相关性;
[0213]
g(df,dq)——决策树df,dq的样本判别函数。
[0214]
3.2.3:构建决策树相关性度量矩阵
[0215]
在决策树d
p
建立过程中,将某节点与上一节点所选特征的互信息系数作为该节点的特征相关性,再将该决策树的所有节点特征相关性的均值作为该决策树的特征相关性,两决策树之间的特征相关性定义为这两棵决策树特征相关性的算术平均值。对已构建的基础随机森林模型中的所有决策树均进行上述计算,即可建立特征集相关性度量矩阵。将特征集相关性度量矩阵与样本相关性度量矩阵进行均值计算,获得决策树相关性度量矩阵。
[0216][0217]
[0218][0219]
dtc=(fc+sc)/2
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(16)
[0220]
式中:fc——特征集相关性度量矩阵;
[0221]fc(d,e)
——决策树d和决策树e之间的特征相关性;
[0222]
——决策树d在第k
t
节点的特征相关性;
[0223]kt
——决策树的节点数,k
t
=1,2,3,...,k
t
;
[0224]
sc——样本集相关性。
[0225]
3.3:基于互信息量的随机森林模型算法描述:
[0226]
基于互信息量的随机森林模型算法流程如图4所示。首先将原始数据采用六折交叉验证方法划分为训练集、测试集与验证集。其次,对训练集样本进行随机采样,建立样本子集与特征子集并构建基础随机森林模型,再对基础随机森林模型中的训练子集与决策树进行相关性计算,构建决策树相关性度量矩阵,利用验证集对每棵决策树进行准确率验证,选出准确率大于70%的决策树,并将其存储记为另选出决策树相关性度量矩阵数据中小于0.5的数据,并将其对应的决策树记为合并和两个集合,并判断其规模是否满足基于互信息量的随机森林模型所需决策树规模,若未达到数量要求,则继续在决策树相关性度量矩阵中选择,直至满足决策树规模。然后,将已选决策树集合中的相同决策树剔除,剩余决策树则构成基于互信息量的随机森林模型。最后,利用测试集对基于互信息量的随机森林模型准确性进行验证。
[0227]
3.4:模型评价与分析
[0228]
在认知负荷分类研究中,随机森林模型、knn算法、支持向量机及组合分类模型是最常用且分类性能最好的4种模型。因此,本发明中采用上述4种算法作为基于互信息量的随机森林模型的对比算法。为高效评估算法准确性,引入总体分类精度ac与kappa系数两个评估指标对算法分类结果进行分析:
[0229][0230][0231]
式中:t
l
——第l类分类正确的个数;
[0232]nl
——第l类样本的总量;
[0233]
h——样本总量
[0234]fl
——测试样本为第l类分类样本,但预测错误的个数;
[0235]ft
——预测结果为第t类,但样本不为第t类的样本数;
[0236]
g——类别总数。
[0237]
表4 5种算法分类结果对比
[0238][0239]
表4分别列出了以不同特征作为输入时5种算法的总体分类精度ac与kappa系数。结果表明,在4种不同特征输入情况下,随机森林系列模型均具有较好的总体分类精度ac和kappa系数,支持向量机系列模型分类结果相对较差,而knn模型表现最差,最高分类精度仅为60.61%,kappa系数仅为0.4091,预测结果与真实值一致性效果较为一般。此外,5种算法中基于互信息量的随机森林模型分类效果最优,证明基于互信息量的随机森林模型的有效性,且降低决策树之间的相关性可以有效提高算法分类精度和泛化能力。
[0240]
从表4中可以看出,单独以脑电特征作为输入时,各算法的分类效果均为最差,当脑电特征与其他特征组合时,各算法分类效果明显提高,而以全部特征作为输入时,各算法分类效果均达到最佳效果,说明脑电特征的变化不仅受到认知负荷的影响,还受到外部环境、受试者情绪变化等各种因素的影响。因此,将仅脑电特征作为输入不能准确评估受试者的认知负荷水平,随着其他特征的加入,输入样本的数据量也随之增加,有效避免了各算法欠拟合现象的发生,进一步提高了算法性能。
[0241]
图5(a)、图5(b)分别是5种算法在总体分类精度c与kappa系数下的箱线图。由图5(a)、图5(b)可以看出,基于互信息量的随机森林模型分类效果最佳。另外,改进后的随机森林模型在4种输入状态下均无异常值,且与其他算法相比箱体更扁平,证明基于互信息量的随机森林模型分类结果波动程度小,算法稳定性好。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1