一种基于视觉位姿感知和深度强化学习的机器人抓取方法与流程
本发明涉及一种根据视觉传感器的输入进行位姿感知和机器人智能抓取的方法,特别是一种基于深度学习和深度强化学习的机器人感知和控制方法,属于机器人控制领域、深度学习和深度强化学习领域,主要应用在机器人自动化进行物体的码放、搬运、分类的任务场景。
背景技术:
机械臂物体抓取是被研究得最广泛的机器人操纵领域问题,而智能的感知和抓取一直是机械臂物体抓取研究的主要热点方向,如何让机器人学会像人一样抓取是研究的终极目标。随着深度强化学习的蓬勃发展,这一技术在直观上非常契合机械臂物体智能抓取这一目的,让机械臂从零开始,像人类一样,在一次次抓取尝试中学会如何抓取。然而,深度强化学习还有相当大的局限性,即深度强化学习的训练难度十分巨大。当下,深度强化学习在游戏领域取得了举世瞩目的成就,一个重要的原因就是游戏环境的进程能够使用软件进行加速,游戏的帧率能够随着硬件水平的提高不断地上升,这就意味着从游戏环境中可以得到相当丰富的经验数据,从而降低了学习的难度。如果在真实的机械臂上,每一次的经验数据需要一次机械臂的抓取执行,而一次抓取执行往往需要数十秒钟的时间,那么在机械臂上训练一个有效深度强化学习智能体所需要的时间就不可估量。因此,当下的深度强化学习方法并不直接适用于机械臂抓取。
通常,深度强化学习算法都将感知和控制融合在一起,通过卷积神经网络,对图像进行处理,并在后端接入全连接神经网络,输出动作向量,完成从感知到控制的端到端模型。但是,这样端到端的模型有相当严重的局限性,深度强化学习不同于监督学习,它没有直接的训练数据,而是通过与环境进行交互产生反馈,来训练神经网络的参数,而与环境交互产生的反馈可能非常稀疏,或者存在严重的滞后性,非常不利于网络参数的更新,而感知与控制的端到端模型非常复杂,网络参数庞大,使得训练十分困难。在现有的研究中,研究人员通过14台机器人分布式地与环境进行交互,产生足够多的经验数据,在超过两个月的时间里,终于训练得到了一个学会抓取新物体的深度强化学习智能体。由此可见,目前深度强化学习算法仍很难胜任机器人抓取任务,所需的硬件条件过于苛刻,其训练效率也十分低下。自mnih等人发表深度强化学习划时代的方法dqn之后,相当多的学者都在为提高深度强化学习算法的训练效率而努力,hado等人提出了double-dqn方法,着重解决了dqn中对于q值的过度估计,导致收敛困难的问题,在提升了训练速度的同时,也实现了更好的效果。tom等人对dqn所使用的经验回放(experiencereplay)技术进行改进,使得更有利于网络更新的经验得到更多的重视和使用,提出了优先经验回放,将智能体所经历的经验按其有效性赋予优先级,并根据优先级来更好地训练网络。实验表明,优先经验回放能够更快地训练网络,并且在雅达利游戏上比原始dqn得分更高。wang等人提出了对抗式的网络结构,令网络在输出q(st,at)的同时输出v(st)值,实验证明,该网络结构更加适用于现代的深度强化学习方法,提升了dqn的训练速度,并在雅达利游戏环境上得分比原始dqn更高。mnih等人提出了异步训练的模式,利用多个智能体同时体验游戏获得经验,并更新共享的网络参数,理论上使得网络的训练速度成倍的增长。
尽管已有的深度强化学习算法相比于最初的算法在提高训练效率、降低训练代价上都取得了相当引人瞩目的成果,但仍然无法攻克深度强化学习在机器人抓取任务上的应用问题。面向抓取任务来说,感知和控制的端到端设计模式为深度强化学习的训练添加了不必要的难度,将感知和控制分离才是解决深度强化学习在抓取任务上应用的关键。lange等人首先进行了感知和控制分离的工作,利用自编码器将图像进行降维,利用自编码器的重构损失来对视觉感知模块进行训练,将训练好的自编码器对环境进行感知,再将感知的结果输入到深度强化学习算法中得到控制策略,实现了移动小车的自动控制。finn等人首先将该思想应用到了机器人操作研究上,但只能实现单一物体的推、翻转等简单的机器人操作。
技术实现要素:
本发明的技术解决问题:克服现有技术的不足,提供一种基于视觉位姿感知和深度强化学习的机器人抓取方法,分离了感知和控制,使得深度强化学习的训练代价大大降低,同时能够实现鲁棒的物体抓取。
本发明提出一种基于视觉位姿感知和深度强化学习的机器人抓取方法,利用深度学习方法对物体进行识别和定位,利用深度强化学习对机器人进行控制并执行对物体的抓取;机器人执行抓取的环境为:在工作平面内放置多个待抓取物体,视觉传感器固定在物体正上方,机器人位于工作平面侧方;该方法包括如下步骤:
第一步,根据视觉传感器获得的图像,利用基于区域的掩码卷积神经网络(maskrcnn)算法在图像上生成所有物体的掩码,得到所有物体掩码所包含的像素点集;
第二步,求取第一步中所得的每一个掩码的像素中心,并利用主成分分析(pca)算法对每一个掩码求取第一主成分方向,得到每一个物体在图像中的像素位置(xk-pixel,yk-pixel)和朝向θk;
第三步,将第二步所得的每一个物体的像素位置和朝向通过坐标变换得到每一个物体在工作平面内的物理位置(xk,yk)和朝向θk;
第四步,获取当前机器人的物理位置和朝向,指定一物体作为目标物体,联合第三步获得的该目标物体的物理位置和朝向,作为深度强化学习算法近端策略优化算法(ppo)的输入,近端策略优化算法(ppo)输出对机器人的控制指令;
第五步,机器人接收到第四步所得到的控制指令并执行,执行结束后计算当前机器人位置与目标物体位置的欧式距离,若小于一定阈值,则执行抓取物体动作,完成对物体的抓取。
进一步的,分离感知和控制部分,环境的感知由maskrcnn算法和pca算法实现,机器人的控制由深度强化学习ppo算法实现,ppo不直接使用视觉传感器的数据而是利用maskrcnn算法和pca算法的结果,降低ppo算法的训练代价。
进一步的,所述第一步中,得到某一物体掩码所包含的像素点集的方法为:
对一个特定类别的物体,maskrcnn的输出中包含目标物体的覆盖矩形,以及矩形内的每个像素点是否为物体上一点的标志信号;首先初始化一个空的目标点集合,遍历覆盖矩形中的每一个像素点,若该像素点是物体上的一点,则将其加入目标点集合中,直到完成矩形内的所有像素点的遍历,得到该物体掩码所包含的所有像素点集。
进一步的,所述第二步中,得到每一个物体在图像中的像素位置和朝向的方法为:
对第一步中所得到的物体掩码所包含的像素点集求平均值,即得到该物体的像素位置,记为(xk-pixel,yk-pixel);利用pca算法对第一步所得到的物体掩码求取第一主成分,所得到的是一条直线上的像素点集合,求该直线和水平方向的夹角,作为目标物体的朝向θk。
进一步的,所述第三步中,将像素位置朝向变换到物理位置和朝向的方法为:
由于视觉传感器在工作平面的正上方,其视角与工作平面垂直,位置关系是确定的;通过测量视觉传感器视野的左上角、右下角两个角点坐标(x1,y1),(x2,y2),根据公式:
求得物体在工作平面内的物理位置(x,y),式中rx,ry为视觉传感器的分辨率,θk与第二步中求得的物体像素朝向θk一致。
进一步的,所述第四步中,ppo算法具体如下:
串联机器人物理位置、朝向和目标物体的物理位置、朝向组成一个六维向量作为输入,经过一层包含512个神经元的全连接神经网络,得到一个512维的隐含层变量,将该隐含层变量分别输入两个包含512个神经元的全连接神经网络,得到两个512维的向量,分别是动作向量(actionvector)和价值向量(valuevector);价值向量最后经过一个包含1个神经元的全连接神经网络,得到一个标量,称为环境状态价值(environmentstatevalue);动作向量经过一个包含6个神经元的全连接神经网络,得到一个6维的向量,其中前3维表示动作均值μ,后3维表示动作方差σ;根据动作均值和动作方差构建一个正态分布,并从正态分布中采样得到动作,并作为控制指令发送给机器人;
ppo算法使用如下奖励函数对神经网络进行训练:
其中d是当前机器人位置和朝向与目标物体的位置和朝向的欧氏距离,其中朝向θk是[0,π]的弧度制,在求取d时除以权重π,以缩放到与距离同一尺度,rt是深度强化学习ppo的奖励函数,下标t是某一时间步,ppo输出的动作每一次执行即每一个时间步都会获得一个奖励,直到整个任务完成。
本发明与现有技术相比的优势在于:
(1)本发明分离了感知和控制,摒弃了端到端的训练模式,先使用maskrcnn对视觉传感器的图像进行处理,得到目标物体的位置信息后,再基于物体位置信息进行深度强化学习的训练,大大降低了深度强化学习的训练代价,加速了其学习速度,使得深度强化学习能够在有限的时间内学会物体抓取的技能;
(2)本发明提出的机器人抓取方法泛化能力强,由于深度强化学习的训练不基于图像信息,而是基于位置等物理量信息,与待抓物体的纹理、色彩无关,因此能够很容易地对新的物体进行抓取;
(3)本发明提出的机器人抓取方法可以适用于多种场景的应用,特别能够完成对移动物体的追踪和抓取,深度强化学习进行物体抓取技能学习的同时也学会了视觉伺服的技能,与现有技术相比,其能力更加强大。
附图说明
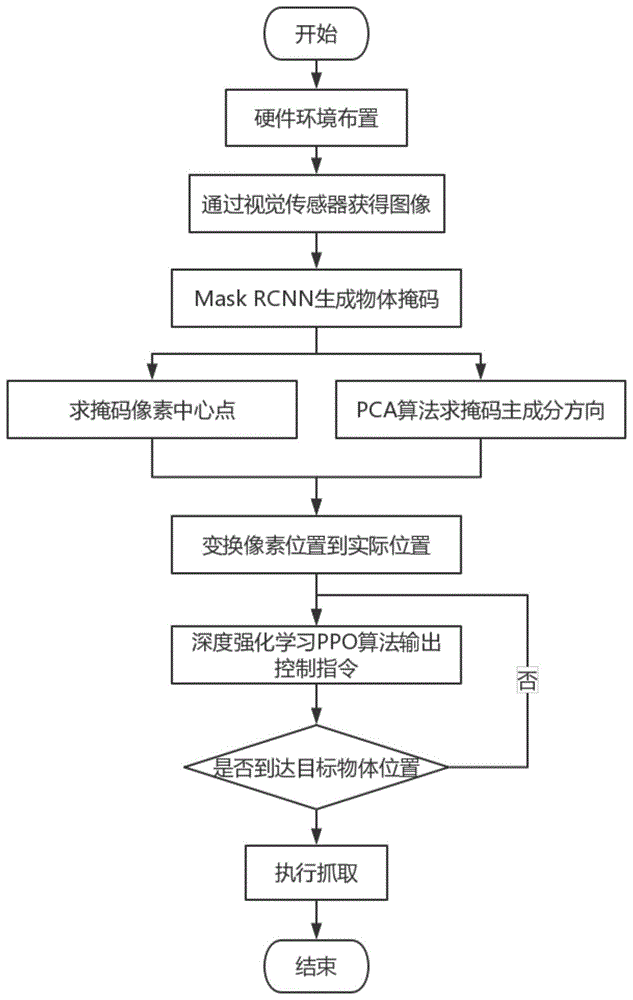
图1为本发明的方法执行机器人抓取的流程图;
图2为本发明物体像素位置信息计算的结果示意图,其中黑色阴影表示物体的掩码点集,灰色圆点表示物体的中心位置,灰色直线表示物体的朝向;
图3为本发明进行物体抓取时的物理环境示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅为本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域的普通技术人员在不付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
如图1所示,本发明提出一种基于视觉位姿感知和深度强化学习的机器人抓取方法,包含物体感知和机器人控制,具体如下:
1.待抓取物体放置在1m*1m的工作平面内,视觉传感器固定在物体正上方,视野范围覆盖整个工作平面,机器人位于工作平面侧面,其工作空间覆盖整个工作平面;
2.假设视野范围内共有n个物体,根据视觉传感器获得的图像,利用maskrcnn算法在图像上生成所有物体的覆盖矩形以及每个覆盖矩形内的每个像素点是否为物体上一点的标志信号。初始化n个空的目标点集合,对每一个目标物体的覆盖矩形遍历其中所有的像素点,若该像素点是目标物体上的一点,则将其加入到相应的目标点集合中去。完成所有覆盖矩形的遍历后,得到n个物体的掩码像素点集。
3.利用公式
4.由于视觉传感器在工作平面的正上方,其视角与工作平面垂直,位置关系是确定的。通过测量视觉传感器视野的左上角、右下角两个角点坐标(x1,y1),(x2,y2),根据公式
求得每一个物体在工作平面内的物理位置xk,yk,k=1,2,…,n,其中rx,ry是视觉传感器的分辨率,θ与物体像素朝向一致;至此求得视野内所有物体的真实坐标xk,yk,θk。
5.通过tcp/ip协议读取当前机器人的状态,根据机器人出厂的通信协议解析机器人当前的位置信息,并取得其中的(xr,yr,θr)三维信息,分别代表机器人末端的x,y轴位置坐标和z轴朝向。在某一时刻,机器人仅对n个物体中的1个进行抓取,取得该物体的真实坐标(xk,yk,θk),与机器人当前位置串联,得到六维的状态向量(xr,yr,θr,xk,yk,θk),经过一层包含512个神经元的全连接神经网络,得到一个512维的隐含层变量,将该隐含层变量分别输入两个包含512个神经元的全连接神经网络,得到两个512维的向量,分别是动作向量(actionvector)和价值向量(valuevector)。价值向量最后经过一个包含1个神经元的全连接神经网络,得到一个标量,称为环境状态价值(environmentstatevalue)。动作向量经过一个包含6个神经元的全连接神经网络,得到一个6维的向量,其中前3维表示动作均值μ,后3维表示动作方差σ。根据动作均值和动作方差构建一个正态分布,并从正态分布中采样得到三维的动作向量,分别表示机器人在x,y方向的移动和z方向的旋转。通过tcp/ip协议将动作向量发送给机器人,控制机器人执行相应的动作。在每次动作执行完成后,计算当前机器人位置和朝向与目标物体的位置和朝向的欧式距离d,构建奖励函数如下:
据此奖励函数计算ppo算法的代价函数,利用梯度下降法最小化ppo算法的代价来对神经网络进行参数更新。
6.在每次动作执行结束时,将进行抓取动作的判定,即计算当前机器人位置与目标位置的欧式距离,若该距离小于一定阈值,则执行抓取动作。抓取动作可以分解成以下动作:(1)令机器人z方向上向下移动到目标物体上方10mm;(2)闭合夹爪;(3)令机器人在z方向上向上移动到初始位置;(4)判断夹爪是否完全闭合,若完全闭合则抓取失败,若不完全闭合则抓取成功。
本发明分离了感知和控制,与传统的感知和控制端到端训练的模式相比,本发明先使用监督学习的方法训练感知模型,再使用深度强化学习训练控制模型,使得深度强化学习发挥其控制长处的同时大大降低了深度强化学习的训练代价,因而能够处理机器人抓取任务。如图3所示,是验证抓取方法的硬件环境布置,整个系统仅使用视觉传感器对环境进行感知,并利用本发明提出的方法对机器人智能抓取进行实现。如图2所示,是环境感知的结果示意图,其中黑色阴影表示物体的掩码点集,灰色圆点表示物体的中心位置,灰色直线表示物体的朝向,而中心位置和物体朝向将作为控制变量提供给深度强化学习算法ppo,最终得到相应的控制指令。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,且应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!