基于AR的脸谱互动教学方法与流程
本发明涉及多媒体教学技术领域,特别涉及基于ar的脸谱互动教学方法。
背景技术:
增强现实技术(augmentedreality,简称ar),是一种实时地计算摄影机影像的位置及角度并加上相应图像、视频、3d模型的技术,这种技术的目标是在屏幕上把虚拟世界套在现实世界并进行互动。目前,ar技术已经逐渐进入人们的生活中,在商业领域、军事领域、工业领域、医疗领域、历史文化领域、纸媒行业和娱乐等领域均有不同程度的应用。但是教育领域的应用还较少,尤其是儿童教育领域。
目前,在儿童教育领域,广泛采用的是视频教学,视频教学大部分是使用播放器直接播放视频来完成。视频以其形象直观的表现形式,能满足儿童教学的部分需求。
但是儿童的兴趣广泛,思维处于具体形象思维阶段,对比较抽象的事物还很难大量接受,促进具体形象思维的发展才是早期开发儿童学习潜力的途径。目前儿童的视频教学中,儿童故事浸入感不够,缺少人和机器的互动,而且趣味性不够,教学过程比较单调。
例如传统的脸谱绘画教学项目,儿童在纸上作画后,通常是直接展示或拍摄后传输到屏幕上进行显示,教学过程比较单调;儿童只是参与了作画,后续的点评、展示环节参与度低,趣味性差,教学效果不够好。
为此,需要一种基于ar的教学方法,在ar技术支持下使虚拟教学环境与现实教学环境相结合,以提高教学过程中的趣味性。
技术实现要素:
本发明的目的在于提供基于ar的脸谱互动教学方法,以提高教学过程中的趣味性。
为解决上述技术问题,本发明技术方案如下:
基于ar的脸谱互动教学方法,包括如下步骤:
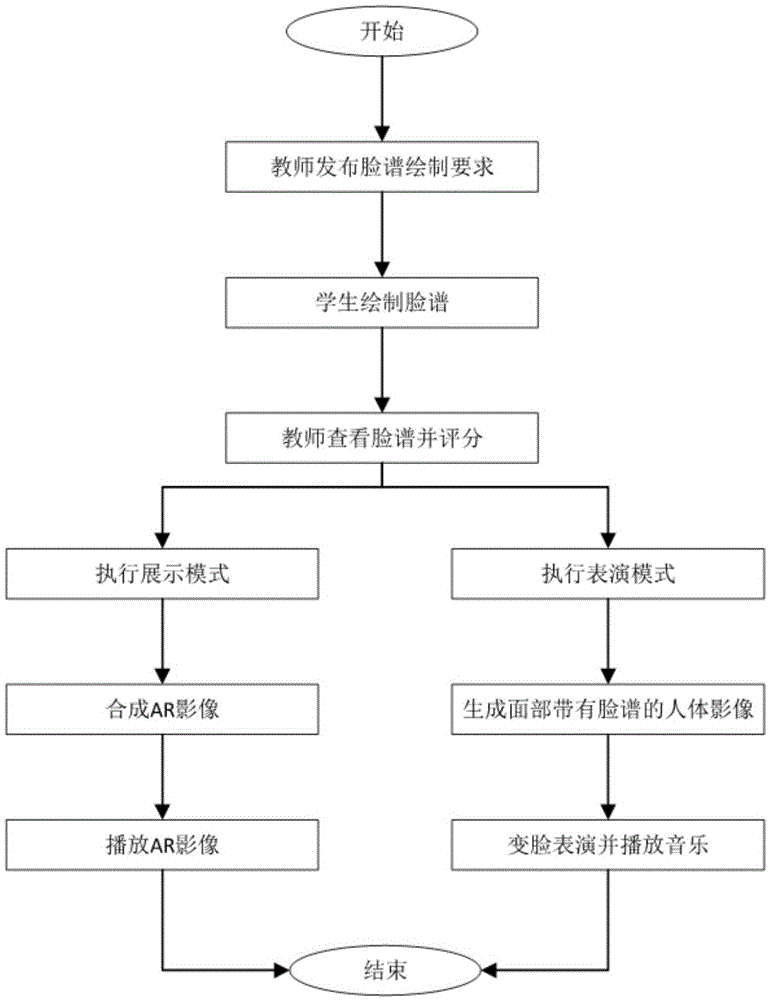
s1、教师向学生发布脸谱绘制指令;
s2、学生通过学生端绘制脸谱;
s3、教师通过教师端查看学生绘制的脸谱,通过教师端控制处理端执行展示模式;
s4、处理端基于脸谱和3d人物模型合成有脸谱的3d人物模型;处理端还获取实时图像,将有脸谱的3d人物模型和实时图像混合生成ar影像,将ar影像输出至播放端;
s5、播放端显示ar影像。
基础方案原理及有益效果如下:
当学生完成脸谱绘制后,自己绘制的脸谱会出现在3d人物模型上,并通过播放端展示;而且,播放端展示的是3d人物模型和实时图像混合生成的ar影像,仿佛3d人物模型就出现在现实中,对学生,尤其是幼儿来说,将呆板的抽象的二维脸谱图像转变为三维图像,能让学生有很强的故事浸入感,趣味性强。
进一步,还包括s6、处理模块从实时图像中提取人体影像,识别人体影像中的面部,将脸谱合成到面部,生成面部有脸谱的人体影像;将面部有脸谱的人体影像输出至播放端;
s7、播放端显示面部有脸谱的人体影像;
其中,所述s3中,教师还通过教师端控制处理端执行表演模式,并转跳到s6。
学生表演时,其人体影像被处理模块获取,然后处理模块将绘制的脸谱合成到面部,生成面部有脸谱的人体影像;其他观看的学生就可以通过播放端观看面部有脸谱的人体影像。互动性强。
进一步,所述s6中,处理端还用于识别人体影像的动作,当检测到人体影像的变脸动作时,切换人体影像面部的脸谱。
切换人体影像面部的脸谱,就可以实现川剧变脸的表演,学生的参与度高,互动性强。
进一步,所述s7中,播放端还播放表演音乐,其中,表演音乐包括展示音乐和变脸音乐;未变脸时播放端播放展示音乐,变脸动作时,播放端播放变脸音乐。
通过播放不同的音乐,能增强表演的趣味性。
进一步,所述s6中,变脸动作为手掌、胳膊或衣服遮挡面部,然后手掌、胳膊或衣服移开面部。
设置变脸动作,便于识别。
进一步,所述s2中,绘制脸谱的方式包括对带有轮廓的脸谱进行上色或自行绘制轮廓并上色。
可以根据学生的年龄安排不同的绘制方式,例如刚入学的幼儿,就可以安排对带有轮廓的脸谱进行上色的绘制方式,这种方式相比于自行绘制轮廓并上色难度更低,便于幼儿上手。
进一步,所述s3中,教师还通过教师端对学生绘制的脸谱进行评分,将评分发送至学生端。
通过评分便于学生了解自己绘制脸谱的优劣。
进一步,所述s2中,学生通过带有触控显示屏的学生端绘制脸谱。
通过触控显示屏绘制脸谱,操作方便。
附图说明
图1为基于ar的脸谱互动教学方法实施例一的流程图。
具体实施方式
下面通过具体实施方式进一步详细说明:
实施例一
如图1所示,基于ar的脸谱互动教学方法,包括如下步骤:
s1、教师向学生发布脸谱绘制指令。
s2、学生通过带有触控显示屏的学生端绘制脸谱;绘制脸谱的方式包括对带有轮廓的脸谱进行上色或自行绘制轮廓并上色。
s3、教师通过教师端查看学生绘制的脸谱,对学生绘制的脸谱进行评分,将评分发送至学生端。教师还通过教师端控制处理端执行展示模式,并转跳至s4;教师要求任一学生进行变脸表演并通过教师端控制处理端执行表演模式,并转跳到s6。
s4、处理端基于脸谱和3d人物模型合成带有脸谱的3d人物模型;处理端还获取实时图像,将有脸谱的3d人物模型和实时图像混合生成ar影像,将ar影像输出至播放端。
s5、播放端显示ar影像。
s6、处理模块从实时图像中提取表演学生的人体影像,识别人体影像中的面部,将脸谱合成到面部,生成面部有脸谱的人体影像;将面部有脸谱的人体影像输出至播放端;当检测到人体影像的变脸动作时,切换人体影像面部的脸谱。其中,变脸动作为手掌、胳膊或衣服遮挡面部,然后手掌、胳膊或衣服移开面部。
s7、播放端显示面部有脸谱的人体影像、播放表演音乐,其中,表演音乐包括展示音乐和变脸音乐;未变脸时播放端播放展示音乐,变脸动作时,播放端播放变脸音乐。
为实现基于ar的脸谱互动教学方法,本实施例还提供基于ar的脸谱互动教学系统,包括,学生端、播放端、教师端和处理端。
学生端包括带有显示屏的智能桌,显示屏带有触控功能。本实施例中,显示屏可分割为四个独立的小屏幕,用以显示不同的内容。智能桌可以是c型卡通智能桌、m型卡通智能桌、传统国学智能桌、魔方外形智能桌等;本实施例中采用魔方外形智能桌。显示屏用于学生绘制脸谱。绘制脸谱的方式包括对带有轮廓的脸谱进行上色或自行绘制轮廓并上色。
播放端包括摄像头和带有显示屏的播放设备;摄像头用于采集教室的实时图像。摄像头为体感摄像头,本实施例中具体采用微软kinect体感摄像头。播放设备可以是壁挂机、投影仪等,本实施例中采用壁挂机。
处理端包括处理模块和存储模块;存储模块用于存储实时图像和学生绘制的脸谱,存储模块中预存有3d人物模型和若干表演音乐;其中,表演音乐包括展示音乐和变脸音乐,展示音乐和变脸音乐为不同的音乐。
教师端可以是pc或平板电脑,本实施例中,采用平板电脑。教师端用于向学生端发送脸谱绘制要求,从存储模块中获取脸谱进行查看;教师端还用于对绘制的脸谱进行评分,将评分发送至学生端。
其中,教师端用于控制处理模块执行展示模式;处理模块基于脸谱和3d人物模型合成有脸谱的3d人物模型;具体合成方式为,对二维的脸谱进行三维化,将三维化的脸谱贴合至3d人物模型的面部。对二维的脸谱进行三维化的具体技术手段在《基于小波插值的人脸建模方法》(许然汪亚明黄文清石信增浙江理工大学2011年9月《计算机仿真》第28卷第9期)中已经公开,属于现有技术,这里不再赘述。处理模块还获取实时图像,将有脸谱的3d人物模型和实时图像混合生成ar影像,将ar影像输出至播放设备。
教师端还用于控制处理模块执行表演模式;处理模块从实时图像中提取人体影像,识别人体影像中的面部,将脸谱合成到面部,生成面部有脸谱的人体影像;将面部有脸谱的人体影像输出至显示屏。
在表演模式中,处理模块还用于识别人体影像的动作,当检测到人体影像的变脸动作时,切换人体影像面部的脸谱。其中变脸动作为手掌、胳膊或衣服遮挡面部,然后手掌、胳膊或衣服移开面部。处理模块切换人体影像面部的脸谱具体方式为从存储模块中获取学生绘制的脸谱,具体可以是表演学生自己绘制的其他脸谱或者其他学生绘制的脸谱。对变脸动作的识别在《基于3d卷积神经网络的人体动作识别算法》(张瑞李其申储珺南昌航空大学信息工程学院江西省图像处理与模式识别重点实验室《计算机工程》2019-01-15第45卷第1期)中已经公开,属于现有技术,这里不再赘述。
处理模块向播放设备发送展示音乐;当处理模块检测到人体影像的变脸动作时,向播放设备发送变脸音乐。
实施例二
为了实现学生在表演模式下,脸谱与表演学生的面部快速的匹配,减少面部识别时间,本实施例与实施例一的区别在于,本实施例中智能桌上还设有摄像头、音响模块和处理器。摄像头安装在智能桌的桌面,摄像头用于采集智能桌前的区域图像;将区域图像发送至处理器;本实施例中,摄像头包括彩色摄像头模组和tof3d摄像头模组。
处理器用于检测区域图像中是否有人脸,并检测人脸是否完整;当区域图像中有一张完整的人脸时,处理器根据人脸生成3d面部模型,将3d面部模型存储至存储模块。当被采集3d面部模型的学生完成一张脸谱时,处理模块基于3d面部模型和脸谱生成与3d面部模型贴合的3d脸谱。如果该学生进行变脸表演,处理模块直接调用该学生的3d脸谱,将3d脸谱合成到该学生的面部。
当区域图像中有一张不完全的人脸时,处理器控制音响模块播放吸引语音,以提醒学生将人脸对准摄像头,便于采集完整的人脸。具体的吸引语音可以是:小朋友,请看一看摄像头;小朋友,请将脸对准摄像头等。当播放吸引语音后仍然没有检测到完整的人脸时,在t1时间后,再次播放吸引语音,并将吸引语音的音量提高10%。t1的范围为5s-60s;本实施例中,t1为10s。再次播放吸引语音以防止学生未听见上一次的吸引语音。
当区域图像中有两张完整的人脸时,处理模块控制音响模块播放提醒语音,具体提醒语音可以是,请小朋友回到自己的座位。
当区域图像中没有人脸时,处理器控制音响模块播放吸引语音,以提醒学生将人脸对准摄像头,便于采集完整的人脸。当播放吸引语音后仍然没有检测到完整的人脸时,在t2时间后,处理器获取相邻智能桌的摄像头采集的区域图像,判断区域图像中是否包含两张人脸且一张人脸为完整人脸,一张人脸为不完整人脸;
如果包含,处理器基于本智能桌与相邻智能桌的位置,判断不完整人脸的相对位置为靠近本智能桌或远离本智能桌,如果为靠近本智能桌,处理器控制音响模块播放吸引语音;如果为远离本智能桌,处理器向相邻智能桌的处理器发送信号,相邻智能桌的处理器控制相邻智能桌的音响模块播放提醒语音。相邻智能桌可以是本智能桌左侧、右侧、前侧、左前侧和/或右前侧的智能桌。
如果不包括,处理器向教师端发送报警信息。本实施例中,报警信息为:智能桌无法检测到人脸。t2的范围为10s-120s,本实施例中,t2为30s。
由于幼儿比较好动,在实际采集人脸的过程中难以准确的人脸进行采集。在本实施中,当幼儿在位置上而人脸没有完全对准摄像头时,音响模块播放吸引语音,可以吸引幼儿将脸对准摄像头,实现对幼儿人脸的采集。当两个幼儿在同一个位置上时,音响模块播放提醒语音,以提醒其中一个幼儿回到自己的位置上。
当幼儿的人脸没有在区域图像中出现时,首先通过吸引语音,吸引幼儿将脸对准摄像头;如果幼儿仍然没有将脸对准摄像头,可能幼儿正在和相邻智能桌的幼儿聊天,玩耍;再通过相邻智能桌的区域图像判断幼儿是否在相邻智能桌,或者将脸转到相邻智能桌;如果判断结果为是,通过相邻智能桌播放提醒语音,提醒幼儿回到自己的智能桌,如果幼儿只是将脸转到相邻智能桌,通过本智能桌播放吸引语音,提醒幼儿将脸对准摄像头,以便完成人脸的采集。
当幼儿的人脸没有出现在相邻的智能桌时,向教师端发送报警信息,以便提醒教师幼儿未在自己的智能桌的情况。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 还没有人留言评论。精彩留言会获得点赞!