一种客观题目的自动解答方法和装置与流程
本发明涉及电子化教育领域,尤指一种客观题目的自动解答方法和装置。
背景技术:
随着人工智能技术的发展,使用机器来代替人工已成为各行各业的热点方向,教育领域对题目的自动解答也成为了研究热点。要做到自动解答,首先要对题目理解正确,理解题目要考查的关键信息,根据该关键信息再去思考答案。目前,机器对题意的理解还不够智能,一般还是通过人为标注来获取题目考查的关键信息。
技术实现要素:
本发明的目的是提供一种客观题目的自动解答方法和装置,让机器自动识别题目意图,实现自动答题,提高机器答题的智能化程度,从而有利于智能化教育服务的推广应用。
本发明提供的技术方案如下:
一种客观题目的自动解答方法,包括:输入待分析题目;将所述待分析题目输入预先构建的题目解析模型,得到对应的题目意图;根据所述题目意图和预先建立的知识库,确定所述待分析题目对应的答案。
进一步优选的,所述的得到对应的题目意图包括:当所述待分析题目为选择题时,所述待分析题目对应的题目意图包括题干意图、题干关键词和备选答案关键词。
进一步优选的,所述的根据所述题目意图和预先建立的知识库,确定所述待分析题目对应的答案包括:当所述待分析题目为选择题时,根据预先建立的知识库,选择与题干关键词的关系符合题干意图的备选答案关键词所对应的备选答案作为所述待分析题目对应的答案。
进一步优选的,预先构建所述题目解析模型包括:收集用于构建题目解析模型的题目,构建训练样本集;对所述训练样本集的每个样本的题目意图进行人工标注;基于人工标注好的训练样本集训练题目解析模型,其中,每个样本为所述题目解析模型的输入量,每个样本的题目意图为所述题目解析模型的输出量。
进一步优选的,所述基于人工标注好的训练样本集训练题目解析模型包括:从人工标注好的训练样本集中,选取一部分作为第一样本数据,剩余的作为第二样本数据;将所述第一样本数据用于模型训练,得到候选模型;将所述第二样本数据用于所述候选模型的测试,根据测试结果评估所述候选模型的合格性;当所述候选模型被评估合格时,将所述候选模型作为题目解析模型;当所述候选模型被评估不合格时,根据所述测试结果对所述候选模型进行补充训练。
本发明还提供一种客观题目的自动解答装置,包括:题目输入模块,用于输入待分析题目;题目解析模块,用于将所述待分析题目输入预先构建的题目解析模型,得到对应的题目意图;答案判定模块,用于根据所述题目意图和预先建立的知识库,确定所述待分析题目对应的答案。
进一步优选的,所述题目解析模块,进一步用于当所述待分析题目为选择题时,所述待分析题目对应的题目意图包括题干意图、题干关键词和备选答案关键词。
进一步优选的,所述答案判定模块,进一步用于当所述待分析题目为选择题时,根据预先建立的知识库,选择与题干关键词的关系符合题干意图的备选答案关键词所对应的备选答案作为所述待分析题目对应的答案。
进一步优选的,还包括:样本收集模块,用于收集用于构建题目解析模型的题目,构建训练样本集;样本预处理模块,用于对所述训练样本集的每个样本的题目意图进行人工标注;模型构建模块,用于基于人工标注好的训练样本集训练题目解析模型,其中,每个样本为所述题目解析模型的输入量,每个样本的题目意图为所述题目解析模型的输出量。
进一步优选的,所述模型构建模块,进一步用于从人工标注好的训练样本集中,选取一部分作为第一样本数据,剩余的作为第二样本数据;将所述第一样本数据用于模型训练,得到候选模型;将所述第二样本数据用于所述候选模型的测试,根据测试结果评估所述候选模型的合格性;当所述候选模型被评估合格时,将所述候选模型作为题目解析模型;当所述候选模型被评估不合格时,根据所述测试结果对所述候选模型进行补充训练。
通过本发明提供的一种客观题目的自动解答方法和装置,能够带来以下有益效果:
1、本发明通过让机器自动识别题目意图,实现自动答题,提高机器答题的智能化程度,从而有利于智能化教育服务的推广应用。
2、本发明通过对模型实施监督式学习,使模型学会像人一样去理解题目意图,从而改进机器对题目意图理解的准确度,提高机器答题的正确率。
3、本发明通过对题目解析模型的测试、补充训练,提高模型的泛化能力,从而进一步提高机器对题目意图理解的准确度,提高机器答题的正确率。
附图说明
下面将以明确易懂的方式,结合附图说明优选实施方式,对一种客观题目的自动解答方法和装置的上述特性、技术特征、优点及其实现方式予以进一步说明。
图1是本发明的一种客观题目的自动解答方法的一个实施例的流程图;
图2是本发明的一种客观题目的自动解答方法的另一个实施例的流程图;
图3是本发明的一种客观题目的自动解答方法的另一个实施例的流程图;
图4是本发明的一种客观题目的自动解答方法的另一个实施例的流程图;
图5是本发明的一种客观题目的自动解答方法的另一个实施例的流程图;
图6是本发明的一种客观题目的自动解答装置的一个实施例的结构示意图;
图7是本发明的一种客观题目的自动解答装置的另一个实施例的结构示意图。
附图标号说明:
100.样本收集模块,200.样本预处理模块,300.模型构建模块,400.题目输入模块,500.题目解析模块,600.答案判定模块。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对照附图说明本发明的具体实施方式。显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。
为使图面简洁,各图中只示意性地表示出了与本发明相关的部分,它们并不代表其作为产品的实际结构。另外,以使图面简洁便于理解,在有些图中具有相同结构或功能的部件,仅示意性地绘示了其中的一个,或仅标出了其中的一个。在本文中,“一个”不仅表示“仅此一个”,也可以表示“多于一个”的情形。
在本发明的一个实施例中,如图1所示,一种客观题目的自动解答方法,包括:
步骤s400输入待分析题目。
具体的,本发明针对的待分析题目为客观题目(有明确答案的题),如选择题、填空题等,非主观题(比如,看图写作文等)。待分析题目可以通过文本输入,得到题目文本;也可以通过图像或图片输入,通过识别图像中的题目内容,比如,通过光学字符识别(opticalcharacterrecognition,ocr)技术,将图像数据识别为文本数据,得到题目文本;也可以通过语音输入,将语音数据识别为文本数据,得到题目文本;本发明对此不做限定。
步骤s500将所述待分析题目输入预先构建的题目解析模型,得到对应的题目意图。
步骤s600根据所述题目意图和预先建立的知识库,确定所述待分析题目对应的答案。
具体的,将该待分析题目对应的题目文本输入预先建好的题目解析模型,该模型对题目文本进行分析,比如,该模型预先经过大量的填空题的训练,已学习到填空题的题目特征,以下面例子为例,题目特征为题干意图+关键信息+填空项,根据题目特征识别出关键信息是“儿童相见不相识”,题干意图为古诗词填空、填充关键信息的下一句,题干意图、关键信息构成了题目意图:
古诗词填空:儿童相见不相识,________________?
根据题目意图和预先建立的知识库,确定待分析题目对应的答案。继续以前述为例,到预先建立的知识库中搜索关键信息“儿童相见不相识”,获得该关键信息的知识点,根据这些知识点找到符合题干意图“填充关键信息的下一句”的知识点,即关键信息的下一句“笑问客从何处来”为题目对应的答案。
本实施例,通过构建题目解析模型让机器自动识别题目意图,实现自动答题,提高机器答题的智能化程度,从而有利于智能化教育服务的推广应用。
在本发明的另一个实施例中,如图2所示,一种客观题目的自动解答方法,包括:
步骤s410输入待分析题目,所述待分析题目为选择题;
步骤s510将所述待分析题目输入预先构建的题目解析模型,得到包括题干意图、题干关键词和备选答案关键词的题目意图;
步骤s610根据预先建立的知识库,遍历各个备选答案关键词,判断其与题干关键词之间的关系是否符合题干意图;
步骤s620选择与题干关键词之间的关系符合题干意图的备选答案关键词对应的备选答案为所述待分析题目对应的答案。
具体的,待分析题目为选择题,选择题包括题干区域和至少一个备选答案区域,若选择题有多个备选方案,则对应有多个备选答案区域。填空题只有题干区域,没有备选答案区域。所以根据题目的外部形式特征就能区分选择题和填空题。
将待分析题目对应的题目文本输入预先建好的题目解析模型,该模型对题目文本进行分析,比如,该模型预先经过大量的选择题的训练,已学习到选择题的题目特征,以下面例子为例,选择题的外部特征为题干区域+备选答案区域,从题干区域获取题干意图和题干关键词,识别出题干意图为“近义词”、题干关键词为“高兴”;从备选答案区域获取备选答案关键词(备选答案1关键词:喜悦;备选答案2关键词:悲伤;备选答案3关键词:哭泣),上述题干意图、题干关键词和各个备选答案关键词构成了本题的题目意图:
以下哪组词语是高兴的近义词:
a喜悦b悲伤c哭泣
根据预先建立的知识库,遍历各个备选答案关键词,判断其与题干关键词之间的关系是否符合题干意图。以前述为例,根据预先建立的知识库中的知识点,判断备选答案1关键词(喜悦)与题干关键词(高兴)之间的关系是否符合题干意图(近义词),符合,所以备选答案1关键词所对应的备选答案1为本题的一个答案;继续判断备选答案2关键词(悲伤)与题干关键词(高兴)之间的关系是否符合题干意图(近义词),不符合,所以备选答案2关键词所对应的备选答案2不为本题的答案;继续判断备选答案3关键词(哭泣)与题干关键词(高兴)之间的关系是否符合题干意图(近义词),不符合,所以备选答案3关键词所对应的备选答案3不为本题的答案。综合以上分析,备选答案1为本题的答案。
本实施例描述了选择题的自动解答过程。
在本发明的另一个实施例中,如图3所示,一种客观题目的自动解答方法,包括:
步骤s420输入待分析题目,所述待分析题目为填空题;
步骤s520将所述待分析题目输入预先构建的题目解析模型,得到包括题干意图、题干关键词的题目意图;
步骤s630在预先建立的知识库中搜索题干关键词,获得题干关键词的知识点;
步骤s640根据与题干关键词之间的关系符合题干意图的知识点进行填空,作为所述待分析题目对应的答案。
具体的,待分析题目为填空题,填空题只有题干区域。
将待分析题目对应的题目文本输入预先建好的题目解析模型,该模型对题目文本进行分析,比如,该模型预先经过大量的填空题的训练,已学习到填空题的题目特征,以下面例子为例,多个空格实质上对应多个问题,每个空格可以按一个填空题处理,从题干区域获取题干意图和题干关键词,以第一个空格为例,识别出题干意图为“注音”、题干关键词为“恶人”,第二个空格,题干意图为“注音”、题干关键词为“可恶”:
给多音字注音:这个恶()人真可恶()。
以第一个空格为例,在预先建立的知识库中搜索题干关键词“恶人”,获得题干关键词“恶人”的知识点,比如有拼音、含义解释、用该词造句等;根据题干意图“注音”,选择拼音的知识点进行填空,拼音è作为答案。
以第二个空格为例,在预先建立的知识库中搜索题干关键词“可恶”,获得题干关键词“可恶”的知识点,比如有拼音、含义解释、用该词造句等;根据题干意图“注音”,选择拼音的知识点进行填空,拼音wù作为答案。
本实施例描述了填空题的自动解答过程。
在本发明的另一个实施例中,如图4所示,一种客观题目的自动解答方法,包括:
步骤s100收集用于构建题目解析模型的题目,构建训练样本集;
步骤s200对所述训练样本集的每个样本的题目意图进行人工标注;
步骤s300基于人工标注好的训练样本集训练题目解析模型,其中,每个样本为所述题目解析模型的输入量,每个样本的题目意图为所述题目解析模型的输出量。
具体的,可以从试题库中获取用于构建题目解析模型的题目,用作训练样本。比如,针对小学语文选择题的题目解析模型,从试题库中选择小学生的语文选择题作为训练样本。
对每个训练样本的题目意图进行人工标注,假设选择题的题目意图包括题干意图、题干关键词和备选答案关键词,针对以下例子,将该选择题的题干中的“高兴”标注为题干关键词,“近义词”标注为题干意图,“喜悦”标注为备选答案1的关键词,“悲伤”标注为备选答案2的关键词,“哭泣”标注为备选答案3的关键词:
以下哪组词语是高兴的近义词:
a喜悦b悲伤c哭泣。
用人工标注好的训练样本集训练题目解析模型,使模型学习到人工标注中隐含的标注规则,像人一样理解题目意图。模型采用机器学习类算法,比如bp(backpropagation)神经网络。bp神经网络是一种按误差逆传播算法训练的多层前馈网络,能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
每个训练样本为题目解析模型的输入量,对应的题目意图为题目解析模型的输出量。通过调整神经网络的权值和阈值(即题目解析模型的权值和阈值),使题目解析模型针对每个训练样本的输出量与对应的人工标注的题目意图之间的误差在预设范围内,即模型训练好了。比如,针对选择题的题目解析模型,当模型已能从各个训练题目中正确的提取出题干意图、题干关键词、各个选项关键词(与人工标注的一致)时,则模型训练好了。
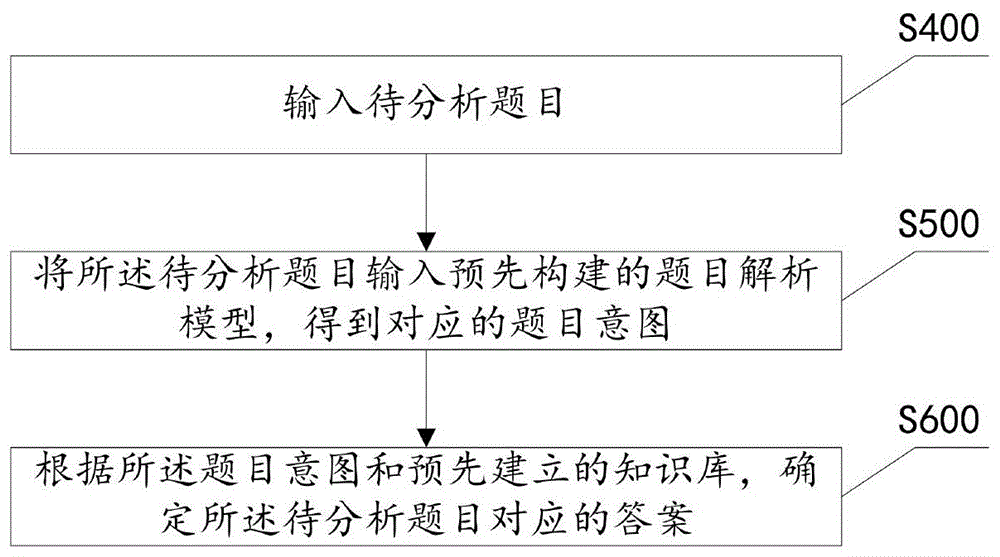
步骤s400输入待分析题目;
步骤s500将所述待分析题目输入预先构建的题目解析模型,得到对应的题目意图;
步骤s600根据所述题目意图和预先建立的知识库,确定所述待分析题目对应的答案。
具体的,预先构建的题目解析模型为训练好的模型。将待分析题目输入该训练好的模型,该训练好的模型对该待分析题目进行题意解析,得到对应的题目意图。根据该题目意图和预先建立的知识库,确定该待分析题目对应的答案,即完成了该待分析题目的自动解答。
本实施例介绍了题目解析模型的构建过程,通过对模型实施监督式学习,使模型学会像人一样去理解题目意图,从而改进机器对题目意图理解的准确度,提高机器答题的正确率。
在本发明的另一个实施例中,如图5所示,一种客观题目的自动解答方法,包括:
步骤s100收集用于构建题目解析模型的题目,构建训练样本集;
步骤s200对所述训练样本集的每个样本的题目意图进行人工标注;
步骤s310从人工标注好的训练样本集中,选取一部分作为第一样本数据,剩余的作为第二样本数据;
步骤s320将所述第一样本数据用于模型训练,得到候选模型,其中,所述第一样本数据的每个样本为所述候选模型的输入量,每个样本的题目意图为所述题目解析模型的输出量;
步骤s330将所述第二样本数据用于所述候选模型的测试,根据测试结果评估所述候选模型的合格性;
步骤s340当所述候选模型被评估合格时,将所述候选模型作为题目解析模型;
步骤s350当所述候选模型被评估不合格时,根据所述测试结果对所述候选模型进行补充训练。
具体的,从人工标注好的训练样本集中,选取一部分作为第一样本数据,剩余的作为第二样本数据,比如,70%作为第一样本数据,30%作为第二样本数据;可以随机选取,也可以按某个规则选取。将第一样本数据用于模型训练,得到候选模型(即该候选模型中的权值和阈值被确定);将第二样本数据用于对该候选模型进行测试,根据测试结果评估模型的合格性,比如,统计第二样本数据中该候选模型的输出不正确(即该候选模型的输出与人工标注的结果不一致)的比例,如果该比例低于95%则认为模型不合格。如果模型达不到预期效果,即不合格,则需要补充训练样本对模型进行训练,从而矫正模型,尤其需要补充与被错误解析的测试样本具有相同或近似特征的训练样本。如果模型达到预期效果,即合格,则将该候选模型作为题目解析模型。
步骤s410输入待分析题目,所述待分析题目为选择题;
步骤s510将所述待分析题目输入预先构建的题目解析模型,得到包括题干意图、题干关键词和备选答案关键词的题目意图;
步骤s610根据预先建立的知识库,遍历各个备选答案关键词,判断其与题干关键词之间的关系是否符合题干意图;
步骤s620选择与题干关键词之间的关系符合题干意图的备选答案关键词对应的备选答案为所述待分析题目对应的答案。
具体的,本实施例介绍了另一种题目解析模型的构建过程,通过测试样本发现模型存在的问题,通过补充有针对性的补充训练,提高模型的泛化能力,从而进一步提高机器对题目意图理解的准确度,提高机器答题的正确率。
在本发明的另一个实施例中,如图6所示,一种客观题目的自动解答装置,包括:
题目输入模块400,用于输入待分析题目。
具体的,本发明针对的待分析题目为客观题目(有明确答案的题),如选择题、填空题等,非主观题(比如,看图写作文等)。待分析题目可以通过文本输入,得到题目文本;也可以通过图像或图片输入,通过识别图像中的题目内容,比如,通过光学字符识别(opticalcharacterrecognition,ocr)技术,将图像数据识别为文本数据,得到题目文本;也可以通过语音输入,将语音数据识别为文本数据,得到题目文本;本发明对此不做限定。
题目解析模块500,用于将所述待分析题目输入预先构建的题目解析模型,得到对应的题目意图。
答案判定模块600,用于根据所述题目意图和预先建立的知识库,确定所述待分析题目对应的答案。
具体的,将该待分析题目对应的题目文本输入预先建好的题目解析模型,该模型对题目文本进行分析,比如,该模型预先经过大量的填空题的训练,已学习到填空题的题目特征,以下面例子为例,题目特征为题干意图+关键信息+填空项,根据题目特征识别出关键信息是“儿童相见不相识”,题干意图为古诗词填空、填充关键信息的下一句,题干意图、关键信息构成了题目意图:
古诗词填空:儿童相见不相识,________________?
根据题目意图和预先建立的知识库,确定待分析题目对应的答案。继续以前述为例,到预先建立的知识库中搜索关键信息“儿童相见不相识”,获得该关键信息的知识点,根据这些知识点找到符合题干意图“填充关键信息的下一句”的知识点,即关键信息的下一句“笑问客从何处来”为题目对应的答案。
本实施例,通过构建题目解析模型让机器自动识别题目意图,实现自动答题,提高机器答题的智能化程度,从而有利于智能化教育服务的推广应用。
在本发明的另一个实施例中,如图6所示,一种客观题目的自动解答装置,包括:
题目输入模块400,用于输入待分析题目,所述待分析题目为选择题;
题目解析模块500,用于将所述待分析题目输入预先构建的题目解析模型,得到包括题干意图、题干关键词和备选答案关键词的题目意图;
答案判定模块600,用于根据预先建立的知识库,遍历各个备选答案关键词,判断其与题干关键词之间的关系是否符合题干意图;以及,选择与题干关键词之间的关系符合题干意图的备选答案关键词对应的备选答案为所述待分析题目对应的答案。
具体的,待分析题目可以通过文本输入,得到题目文本;也可以通过图像或图片输入,通过识别图像中的题目内容,比如,通过光学字符识别(opticalcharacterrecognition,ocr)技术,将图像数据识别为文本数据,得到题目文本;也可以通过语音输入,将语音数据识别为文本数据,得到题目文本;本发明对此不做限定。
待分析题目为选择题,选择题包括题干区域和至少一个备选答案区域,若选择题有多个备选方案,则对应有多个备选答案区域。填空题只有题干区域,没有备选答案区域。所以根据题目的外部形式特征就能区分选择题和填空题。
将待分析题目对应的题目文本输入预先建好的题目解析模型,该模型对题目文本进行分析,比如,该模型预先经过大量的选择题的训练,已学习到选择题的题目特征,以下面例子为例,选择题的外部特征为题干区域+备选答案区域,从题干区域获取题干意图和题干关键词,识别出题干意图为“近义词”、题干关键词为“高兴”;从备选答案区域获取备选答案关键词(备选答案1关键词:喜悦;备选答案2关键词:悲伤;备选答案3关键词:哭泣),上述题干意图、题干关键词和各个备选答案关键词构成了本题的题目意图:
以下哪组词语是高兴的近义词:
a喜悦b悲伤c哭泣
根据预先建立的知识库,遍历各个备选答案关键词,判断其与题干关键词之间的关系是否符合题干意图。以前述为例,根据预先建立的知识库中的知识点,判断备选答案1关键词(喜悦)与题干关键词(高兴)之间的关系是否符合题干意图(近义词),符合,所以备选答案1关键词所对应的备选答案1为本题的一个答案;继续判断备选答案2关键词(悲伤)与题干关键词(高兴)之间的关系是否符合题干意图(近义词),不符合,所以备选答案2关键词所对应的备选答案2不为本题的答案;继续判断备选答案3关键词(哭泣)与题干关键词(高兴)之间的关系是否符合题干意图(近义词),不符合,所以备选答案3关键词所对应的备选答案3不为本题的答案。综合以上分析,备选答案1为本题的答案。
本实施例描述了选择题的自动解答过程。
在本发明的另一个实施例中,如图6所示,一种客观题目的自动解答装置,包括:
题目输入模块400,用于输入待分析题目,所述待分析题目为填空题;
题目解析模块500,用于将所述待分析题目输入预先构建的题目解析模型,得到包括题干意图、题干关键词的题目意图;
答案判定模块600,用于在预先建立的知识库中搜索题干关键词,获得题干关键词的知识点;以及,根据与题干关键词之间的关系符合题干意图的知识点进行填空,作为所述待分析题目对应的答案。
具体的,待分析题目可以通过文本输入,得到题目文本;也可以通过图像或图片输入,通过识别图像中的题目内容,比如,通过光学字符识别(opticalcharacterrecognition,ocr)技术,将图像数据识别为文本数据,得到题目文本;也可以通过语音输入,将语音数据识别为文本数据,得到题目文本;本发明对此不做限定。
待分析题目为填空题,填空题只有题干区域。
将待分析题目对应的题目文本输入预先建好的题目解析模型,该模型对题目文本进行分析,比如,该模型预先经过大量的填空题的训练,已学习到填空题的题目特征,以下面例子为例,多个空格实质上对应多个问题,每个空格可以按一个填空题处理,从题干区域获取题干意图和题干关键词,以第一个空格为例,识别出题干意图为“注音”、题干关键词为“恶人”,第二个空格,题干意图为“注音”、题干关键词为“可恶”:
给多音字注音:这个恶()人真可恶()。
以第一个空格为例,在预先建立的知识库中搜索题干关键词“恶人”,获得题干关键词“恶人”的知识点,比如有拼音、含义解释、用该词造句等;根据题干意图“注音”,选择拼音的知识点进行填空,拼音è作为答案。
以第二个空格为例,在预先建立的知识库中搜索题干关键词“可恶”,获得题干关键词“可恶”的知识点,比如有拼音、含义解释、用该词造句等;根据题干意图“注音”,选择拼音的知识点进行填空,拼音wù作为答案。
本实施例描述了填空题的自动解答过程。
在本发明的另一个实施例中,如图7所示,一种客观题目的自动解答装置,包括:
样本收集模块100,用于收集用于构建题目解析模型的题目,构建训练样本集;
样本预处理模块200,用于对所述训练样本集的每个样本的题目意图进行人工标注;
模型构建模块300,用于基于人工标注好的训练样本集训练题目解析模型,其中,每个样本为所述题目解析模型的输入量,每个样本的题目意图为所述题目解析模型的输出量。
具体的,可以从试题库中获取用于构建题目解析模型的题目,用作训练样本。比如,针对小学语文选择题的题目解析模型,从试题库中选择小学生的语文选择题作为训练样本。
对每个训练样本的题目意图进行人工标注,假设选择题的题目意图包括题干意图、题干关键词和备选答案关键词,针对以下例子,将该选择题的题干中的“高兴”标注为题干关键词,“近义词”标注为题干意图,“喜悦”标注为备选答案1的关键词,“悲伤”标注为备选答案2的关键词,“哭泣”标注为备选答案3的关键词:
以下哪组词语是高兴的近义词:
a喜悦b悲伤c哭泣。
用人工标注好的训练样本集训练题目解析模型,使模型学习到人工标注中隐含的标注规则,像人一样理解题目意图。模型采用机器学习类算法,比如bp(backpropagation)神经网络。bp神经网络是一种按误差逆传播算法训练的多层前馈网络,能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
每个训练样本为题目解析模型的输入量,对应的题目意图为题目解析模型的输出量。通过调整神经网络的权值和阈值(即题目解析模型的权值和阈值),使题目解析模型针对每个训练样本的输出量与对应的人工标注的题目意图之间的误差在预设范围内,即模型训练好了。比如,针对选择题的题目解析模型,当模型已能从各个训练题目中正确的提取出题干意图、题干关键词、各个选项关键词(与人工标注的一致)时,则模型训练好了。
题目输入模块400,用于输入待分析题目;
题目解析模块500,用于将所述待分析题目输入预先构建的题目解析模型,得到对应的题目意图;
答案判定模块600,用于根据所述题目意图和预先建立的知识库,确定所述待分析题目对应的答案。
具体的,预先构建的题目解析模型为训练好的模型。将待分析题目输入该训练好的模型,该训练好的模型对该待分析题目进行题意解析,得到对应的题目意图。根据该题目意图和预先建立的知识库,确定该待分析题目对应的答案,即完成了该待分析题目的自动解答。
本实施例介绍了题目解析模型的构建过程,通过对模型实施监督式学习,使模型学会像人一样去理解题目意图,从而改进机器对题目意图理解的准确度,提高机器答题的正确率。
在本发明的另一个实施例中,如图7所示,一种客观题目的自动解答装置,包括:
样本收集模块100,用于收集用于构建题目解析模型的题目,构建训练样本集;
样本预处理模块200,用于对所述训练样本集的每个样本的题目意图进行人工标注;
模型构建模块300,用于从人工标注好的训练样本集中,选取一部分作为第一样本数据,剩余的作为第二样本数据;将所述第一样本数据用于模型训练,得到候选模型,其中,所述第一样本数据的每个样本为所述候选模型的输入量,每个样本的题目意图为所述题目解析模型的输出量;将所述第二样本数据用于所述候选模型的测试,根据测试结果评估所述候选模型的合格性;当所述候选模型被评估合格时,将所述候选模型作为题目解析模型;当所述候选模型被评估不合格时,根据所述测试结果对所述候选模型进行补充训练。
具体的,从人工标注好的训练样本集中,选取一部分作为第一样本数据,剩余的作为第二样本数据,比如,70%作为第一样本数据,30%作为第二样本数据;可以随机选取,也可以按某个规则选取。将第一样本数据用于模型训练,得到候选模型(即该候选模型中的权值和阈值被确定);将第二样本数据用于对该候选模型进行测试,根据测试结果评估模型的合格性,比如,统计第二样本数据中该候选模型的输出不正确(即该候选模型的输出与人工标注的结果不一致)的比例,如果该比例低于95%则认为模型不合格。如果模型达不到预期效果,即不合格,则需要补充训练样本对模型进行训练,从而矫正模型,尤其需要补充与被错误解析的测试样本具有相同或近似特征的训练样本。如果模型达到预期效果,即合格,则将该候选模型作为题目解析模型。
题目输入模块400,用于输入待分析题目,所述待分析题目为选择题;
题目解析模块500,用于将所述待分析题目输入预先构建的题目解析模型,得到包括题干意图、题干关键词和备选答案关键词的题目意图;
答案判定模块600,用于根据预先建立的知识库,遍历各个备选答案关键词,判断其与题干关键词之间的关系是否符合题干意图;选择与题干关键词之间的关系符合题干意图的备选答案关键词对应的备选答案为所述待分析题目对应的答案。
具体的,本实施例介绍了另一种题目解析模型的构建过程,通过测试样本发现模型存在的问题,通过补充有针对性的补充训练,提高模型的泛化能力,从而进一步提高机器对题目意图理解的准确度,提高机器答题的正确率。
应当说明的是,上述实施例均可根据需要自由组合。以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!