一种通过人声分析检测呼吸道的方法与流程
本发明属于人声语音分析技术领域,特别涉及一种通过人声分析检测呼吸道的方法。
背景技术:
声纹是近年蓬勃发展的生物识别技术,可以有效辨别人的身份。每个人的声音之所以具有独特性是因为每个人的声腔构造再加上说话时嘴型的变化而造成。为了要辨别声纹,个体需要发出声音才能让机器进行识别。
目前的声纹辩别技术是透过识别每个人独一无二的声谱图进行分析,人的声纹会受到多种特征的影响,包含:
(1)与人类发音机制的解剖学结构有关的声学特征(如频谱、倒频谱、共振峰、基音、泛音、反射系数等等)、鼻音、呼吸音、沙哑音、笑声等;
(2)受到后天环境,如社会状况、出生地等影响了语义、修辞、发音、言语习惯等;
(3)个人特点或父母的影响,像是说话时的韵律、节奏、速度、语调、音量等语音特征。
除此之外,在数学方法建模计算时,声纹自动识别的模型目前可以使用的特征包括:
(1)声学特征(倒频谱),包含音量(volume)、音高(pitch)、音色(timbre)所组成;
(2)词法特征,包含说话人所使用的词汇特征、音素特征;
(3)韵律特征;
(4)语种、方言和口音信息;
(5)信道信息(声音使用何种媒介传输)等。
而当呼吸道出现异常时,主要的表征有:声音沙哑、变低沉、语句产生变化(如断句次数变多)。因此会影响人声的响度、音调、以及说话的断句方式发生改变。实际上,通过分析人声是可能对人的呼吸道进行检测的。
技术实现要素:
本发明提供了一种通过人声分析检测呼吸道的方法。
一种通过人声分析检测呼吸道的方法,包括以下步骤:
步骤一,通过麦克风收集人声的声音数据,形成可供声纹辨识的声谱图;
步骤二,采用声谱图分析仪,根据声音的振幅与仪器的全幅范围,区辨出所需要的人声讯号与背景噪声,分析出说话者的语音震幅、频率、音高、谐波信息,当同一说话者的声谱图采集达到常态分布时,透过声音数据发现说话者的声纹特色;
步骤三,收集人生病时的声谱图,提取音频、振幅、音波断裂位置,以及所有身体变化可能会造成声音产生差异的物理特征,透过大数据,比较分析每日的声音频谱图的变化,得知人生病时的声音变化趋势。
本发明对于麦克风所录取之人声进行声纹采集,并对于所采集到的声纹进行分析,以获取到人体的喉咙、鼻腔等呼吸道相关器官的健康信息,进而判断个体是否处于生病状态。本发明包含的技术为透过语音采集的大数据分析,获取健康与非健康的声音物理特征模式,将其带入个体的声音健康状况判别。在进行个体的声音健康状况判别前会先取得个体的声音物理特征的常态状况分布,以求取得更精确的“非健康”状况分析。本发明基于声音采集的个体独特唯一性,以及影响声音的因素,透过人生判断的健康状况仅包含呼吸道的健康状况,并不对其他身体部位的健康状况进行判读分析。
附图说明
图1是本发明的实现流程图。
图2是应用本发明进行健康判断的方法示意图。
具体实施方式
本发明透过数字方式的语音采集(麦克风),经过特殊的语音消息处理(透过算法进行声音频谱图的分析),比较分析每日的声音频谱图的变化,判断个体的身体状况是否产生变化,整个分析过程分为三阶段,如图1所示。图1中的Phase是阶段的意思。
第一阶段首先收集用户的声谱图数据,透过麦克风采集声音数据时,随着采样方使用的设备与编程方式不同,采样频率、采样深度、声道数都可能不同,然而这并不影响声纹辨识的声谱图。
第二阶段为声谱图采集与基础分析,声谱图分析仪会根据声音的振幅与仪器的全幅范围进行测量,区辨出所需要的人声讯号与背景噪声,在分析主要的人声电子讯号时,主要的决定因素为频率、强度、扭曲率、谐波、带宽以及其他与声波相关的元素。尽管一个人在说话时会有语意内容与语调起伏的不同,但在声谱图分析过程中,还是可以清楚辨别说话者的身份,因其最后的波形具有相同的模式(pattern)。透过大量的采集模式,可以分析出说话者的语音震幅、频率、音高、谐波等固定信息,当同一说话者的声谱图采集达到常态分布时,可以透过数据发现说话者的声纹特色,此为唯一固定模式。
第三阶段为透过声谱图判断说话者的健康状况,也是本发明的主要着重点。在声谱图采集到的数据中,与健康状况有关的声音元素包含震幅(强度)、音频(音高)、断句位置、非人声信号采集。当声音变得虚弱时,声音的振幅产生变化;当原本清亮的声音变得低沈,意即声音的频率产生变化,由高频变成低频、当原本运气流畅的声音变得运气短促,换气频率变高时,意即断句的频率增加,音波的中断频率变高。在此阶段必须要判断生病与健康状况良好时的音频比较,首先需要透过大数据分析,大量采集生病时的声谱图,透过大数据分析所获得的结果,可以得知多数人生病时的声音变化趋势。在大数据的采集过程中,需要收集音频、振幅、音波断裂位置等,所有身体变化可能会造成声音产生差异的物理特征。在采集到足够的数据量后,进行健康与不健康的数据比对,透过建立演算法的方式,建立健康与不健康的声音物理特征值的回归算法,借此得到原本健康的声音物理特征值在有呼吸道疾病时分布范围为何。往后只要将新得到的声音物理特征值套入算法即可获得在不健康的状况下的范围值,以此判断发出声音的个体是否处于健康状态,算法如下:
y=ax+b-------(1)健康与不健康的声音物理特征值的回归算法
透过既有的数据分析,将健康的声音值代入x,不健康的声音值代入y,得到a和b。接着将健康声音值x,a,b带入算法,计算所得到的y与实际上的不健康声音值的差值,对此差值进行统计处理,计算估计值与实际值的误差区间。往后收集到用户长期的声音特征值后(收集到之数据必须让特征值呈现正态分布),将特征值带入x,计算得到不健康之特征值y,若用户的声音特征值落在y±误差区间,则判断用户为生病状态。
透过大数据的采集、获得与分析结果,可以得到在生病时声音的震幅、音频、断句位置产生的变化程度,因此当机器输入这些数值,判断说话者的声音产生的变化程度已经到达多数人生病时所产生变化的幅度后,即可对其健康状况的改变产生评断。
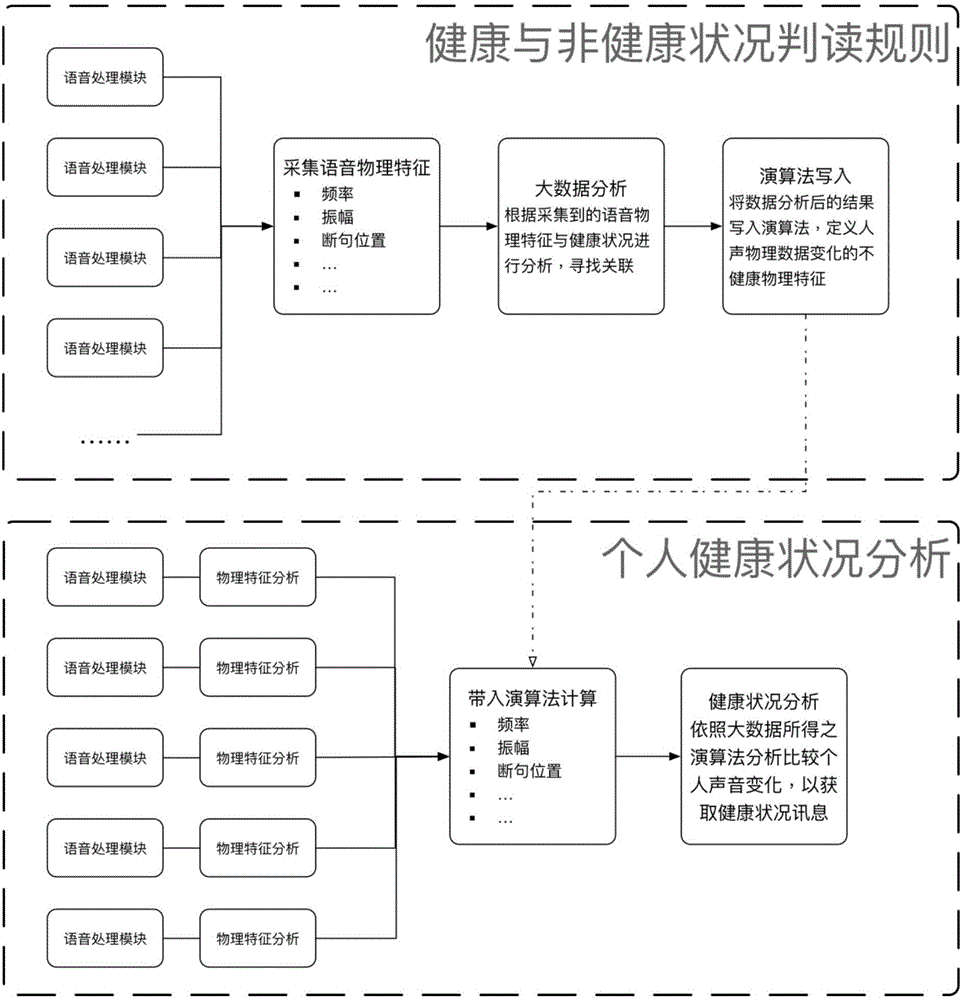
本发明透过语音判读呼吸道健康状况的方式发明,此方式主要分为两个功能模块,第一为建立出健康与非健康状况的系统判读规则,第二为进行个人健康状况分析。如图2所示。
在第一阶段的健康与非健康状况判读规则,需要透过大量的语音数据采集,分析语音物理特征,包含但不仅止于声音的频率、震幅、断句位置等,透过分析病人的语音物理特征,寻找出病人与健康的语音物理特征差异,归纳并整理算法的编写,提供往后新收录的声音进行健康状况检测。
在第二阶段的个人健康状况分析中,同样需要采集大量的个人语音消息,当个人的语音消息物理特征具备声音的唯一性(可透过声纹等声音特征辨识身份时),即可使用该个体的语音物理特征进行健康状况的判读。详细使用方式为,在建立出个人语音物理特征的常态模型后,只要新录入的声音都可以采撷其物理特征进行分析,将新录入的声音物理特征与常态分布数据带入阶段一的算法进行计算后,即可了解本次采集的声音数据及物理特征属于健康的人声或非健康的人声,若经判读为非健康的人生即可对个体提出警示,建议去医院或诊所进行检查,或是加强日常生活的健康照护。
- 还没有人留言评论。精彩留言会获得点赞!