一种用于主动噪声均衡控制的临界频带幅值增益优化方法与流程
本发明涉及汽车噪声控制领域,尤其是涉及一种用于主动噪声均衡控制的临界频带幅值增益优化方法。
背景技术:
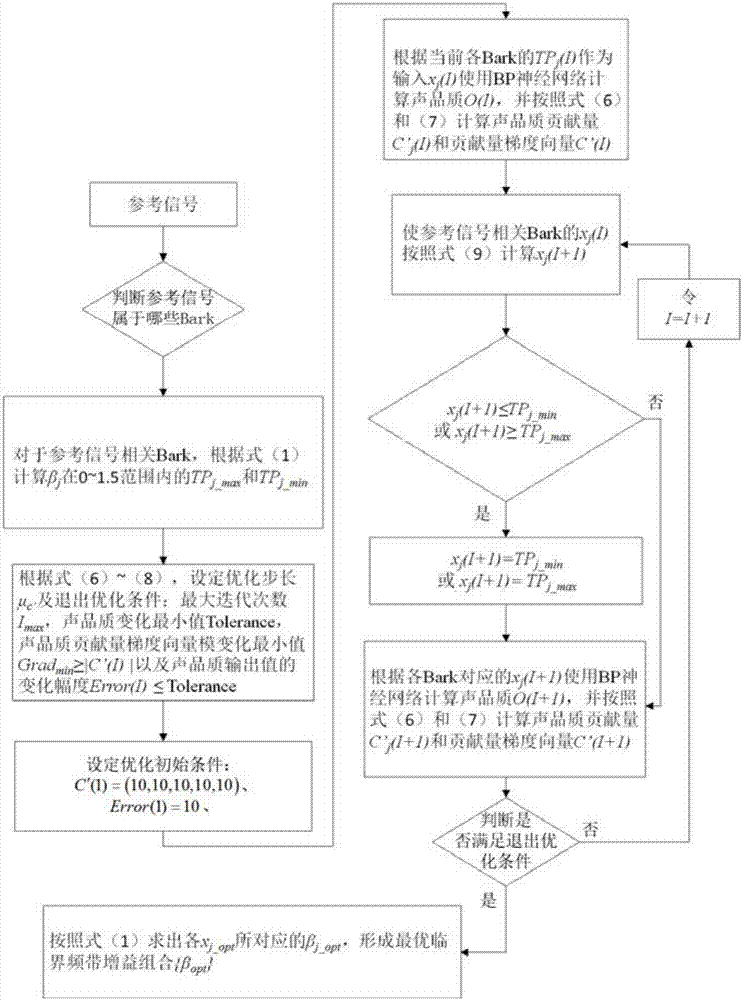
:汽车车内噪声的主动噪声控制(ANC)方法是依据声波干涉相消原理通过次级声源发声抵消原有噪声实现降噪,同时随着数字信号处理技术和集成电路广泛应用日渐兴起。主动噪声控制采用以声治声的方法对低频噪声有良好的抑制效果。在ANC基础上发展出的主动噪声均衡控制可以有选择性地控制特定频段(一般为临界频带)的噪声使之产生均衡效果从而改善声品质。在实施主动噪声均衡控制之前先要获得各控制临界频带下使声品质最佳的幅值增益组合,也就是临界频带幅值增益的优化问题。目前主要采用枚举法,将所有可能的幅值增益进行组合并计算所有声品质结果,选取出最佳组合,这类方法效率较低。技术实现要素:本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种用于主动噪声均衡控制的临界频带幅值增益优化方法。本发明的目的可以通过以下技术方案来实现:一种用于主动噪声均衡控制的临界频带幅值增益优化方法,该方法包括以下步骤:S1、通过参考信号识别模块识别噪声参考信号并判断参考信号的临界频带,确定BP神经网络声品质模型的临界频带总声压幅值输入值;S2、设置声品质贡献量梯度向量初始值C’(1)、声品质输出值的变化幅度初始值Error(1)和退出优化条件;S3、BP神经网络声品质模型根据当前临界频带总声压幅值输入值计算当前声品质O、当前声品质贡献量C’j和当前声品质贡献量梯度向量C’(I);S4、根据临界频带总声压幅值输入值和声品质贡献量C’j计算下一个临界频带总声压幅值输入值,并计算下一个输入值对应声品质、声品质贡献量C’j和声品质贡献量梯度向量C’(I+1),判断是否满足退出优化条件,若为否则迭代次数I加1继续重复步骤S4,若为是则得到声品质输出极值并进行步骤S5,;S5、利用声品质输出极值,根据声品质与临界频带总声压幅值之间的关系,获得声品质极大值对应的临界频带总声压幅值输入值xj_opt,再根据临界频带幅值增益与临界频带总声压幅值之间的关系,求出各个临界频带总声压幅值输入值xj_opt所对应的最优临界频带幅值增益βj_opt,形成最优临界频带幅值增益组合{βopt},送入FxLMS自适应控制器进行主动均衡控制。步骤S5中声品质与临界频带总声压幅值的关系为:式中,xj和O分别表示临界频带总声压幅值输入值和声品质输出值,ωij为输入节点j与隐节点i间的网络权值,θi是隐节点i的网络阈值,θk是输出点的网络阈值,f1()是隐含层的传递函数;Tki是隐节点i与输出点间的网络权值,f2()是输出层的传递函数。所述的退出优化条件为声品质贡献量梯度向量模|C'(I)|≤声品质贡献量梯度向量模变化最小值Gradmin,同时声品质输出值的变化幅度Error(I)≤声品质变化最小值Tolerance,并且达到最大迭代次数Imax,其中Error(I)=|O(I)-O(I-1)|。声品质贡献量C’j计算方法为:其中,xj表示临界频带总声压幅值输入值,ωij为输入节点j与隐节点i间的网络权值,Sj为声品质输出对输入量的灵敏度,Tki是隐节点i与输出点间的网络权值。各临界频带的声品质贡献量C’j组成了声品质贡献量梯度向量C’。步骤S4中所述的计算下一个临界频带总声压幅值输入值具体为:xj(I+1)=xj(I)±μc′·Cj′(I)其中,xj(I+1)为下一个临界频带总声压幅值输入值,xj(I)为当前临界频带总声压幅值输入值,μc′为学习步长,Cj′(I)为当前声品质贡献量。步骤S2还包括设定学习步长μc′。步骤S2中声品质贡献量梯度向量初始值C’(1)和声品质输出值的变化幅度初始值Error(1)分别为C’(1)=(10,10,10,10,10)、Error(1)=10。步骤S1还包括:设定临界频带幅值增益的范围,计算该临界频带幅值增益的范围内最大和最小总声压幅值TPj_max和TPj_min。当步骤S4中临界频带总声压幅值输入值在[TPj_min,TPj_max]范围外,则取临界频带总声压幅值输入值为TPj_max或TPj_min。与现有技术相比,本发明具有以下优点:1、迭代次数远远降低:将声品质对输入量的灵敏度和输入量大小都列入了优化方法虑的范围,优先抑制对与声品质负贡献量大的频率成分,并且优化迭代次数远远小于枚举法;2、提升主动噪声均衡控制效果、效率高:利用BP神经网络声品质模型进行最优临界频带幅值增益组合,效率高,输入FxLMS自适应控制器,改善车内声品质。附图说明图1为临界频带幅值增益主动噪声均衡控制系统图;图2为用于主动噪声均衡控制的临界频带幅值增益优化方法流程图;图3为声品质“舒适度”值随优化迭代次数I的变化图;图4声品质输出值的变化幅度Error(I)随优化迭代次数I的变化;图5声品质贡献量梯度向量模|C'(I)|变化值Gradient随优化迭代次数I的变化。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。实施例本发明涉及一种用于主动噪声均衡控制的临界频带幅值增益优化方法。如图1所示,该方法应用于由参考信号识别模块、BP神经网络声品质模型、基于噪声误差反馈的FxLMS(Filter-xLeastMeanSquare滤波x最小均方误差)自适应均衡控制器以及次级声源所组成的噪声主动均衡控制系统。通过基于BP神经网络声品质模型推导出声品质对于神经网络输入(临界频带总声压幅值)的贡献量以及建立临界频带幅值增益与临界频带总声压幅值之间的关系,将优化目标由对临界频带幅值增益的枚举转变为声品质贡献量梯度向量,以声品质贡献量及其梯度向量作为优化时输入量的改变方向,将声品质对输入量的灵敏度和输入量大小都列入了优化方法虑的范围,优先抑制对与声品质负贡献量大的频率成分,提高优化效率。步骤如下:1.通过参考信号识别模块识别主动均衡控制的噪声参考信号并判断参考信号属于哪些临界频带j(BARK)。对于参考信号相关的临界频带,根据所建立的临界频带幅值增益与临界频带总声压幅值之间的关系(具体公式如式1)计算出在所选幅值增益βj范围内(如0~1.5)的最大及最小总声压幅值TPj_max和TPj_min。式中,TPj为临界频带总声压幅值,βj为临界频带总声压幅值增益,xj为临界频带总声压幅值输入值,fj_max和fj_min分别为临界频带j的上下限频率;Pr(f)为临界频带内的所有参考信号对应频率范围内的幅值谱分量(参考信号分量),Pn(f)为临界频带内剩余频率范围内的幅值谱分量(非参考信号分量),f为声压幅值谱的频率,Δf为声压幅值谱的频率分辨率;W(f)为权值,当f为临界频带的上限频率或下限频率,W(f)=0.5,当f介于临界频带的上限频率和下限频率之间,W(f)=1。2.基于BP神经网络声品质模型建立声品质与神经网络输入(临界频带总声压幅值)之间关系的表达式:式中,xj和O分别表示临界频带总声压幅值输入值和声品质输出值。ωij为输入节点j与隐节点i间的网络权值,θi是隐节点i的网络阈值,f1()是隐含层的传递函数;Tki是隐节点i与输出点间的网络权值,θk是输出点的网络阈值,f2()是输出层的传递函数。声品质输出对输入量的灵敏度Sj公式为:其中,O声品质输出值,xj表示临界频带总声压幅值输入值,ωij为输入节点j与隐节点i间的网络权值,Tki是隐节点i与输出点间的网络权值,θi是隐节点i的网络阈值。声品质贡献量C’j定义为:各临界频带的声品质贡献量组成了贡献量梯度向量C’C'=(C'1,C'2,…,C'n)(7)以声品质贡献量C’j(I)及其梯度向量C’(I)为优化目标进行优化。设定优化步长μc’及退出优化条件:最大迭代次数Imax,声品质变化最小值Tolerance,声品质贡献量梯度向量模|C'(I)|变化最小值Gradmin以及声品质输出值的变化幅度Error(I)。设定初始条件C’(1),Error(1)。Error(I)=|O(I)-O(I-1)|≤Tolerance(8)O(I)为当前声品质输出值;O(I-1)为前一个临界频带总声压幅值输入值对应的声品质输出值。3.使用BP神经网络模型计算声品质,同时计算参考信号相关的临界频带下的声品质贡献量C’j(I)及其梯度向量C’(I)。BP神经网络模型的输入量xj(I)沿着声品质贡献量梯度方向变化迭代求出下一个输入量xj(I+1)。4.各个输入量xj的变化按照式(9)向当前次迭代的声品质贡献量梯度的正、负两个方向一直进行。在满足优化退出条件后,迭代结束,就会找到在[TPj_max,TPj_min]范围内的两个声品质输出极值,取较大的极大值对应的各个输入量xj_opt,再根据式(1)求出各个xj_opt所对应的最优临界频带幅值增益βj_opt,形成最优临界频带幅值增益组合{βopt}送入FxLMS自适应控制器进行主动均衡控制。xj(I+1)=xj(I)±μc′·Cj′(I)(9)xj(I+1)为下一个临界频带总声压幅值输入值;xj(I)为当前临界频带总声压幅值输入值;μc′为学习步长;Cj′(I)为当前临界频带总声压幅值输入值对应的声品质贡献量。如图2,本发明的具体实施步骤如下:1、识别出参考信号属于几个临界频带j(Bark),确定输入xj的个数n。设定临界频带幅值增益βj的范围,并根据式(1)计算TPj_max和TPj_min。2、基于BP神经网络声品质模型(确定隐节点i的数量为m),根据式(6)~(8),设定优化步长即学习步长μc’及退出优化条件:最大迭代次数Imax,声品质变化最小值Tolerance,声品质贡献量梯度向量模|C'(I)|变化值Gradient的最小值Gradmin以及声品质输出值的变化幅度Error(I)。设定初始条件C’(1),Error(1)。3、BP神经网络声品质模型按照当前各输入量xj(I)计算当前声品质O(I),并根据式(6)和(7)计算C’j(I)及C’(I)。根据式(9)迭代求出下一个输入量xj(I+1)。4、判断xj(I+1)≤TPj_min或xj(I+1)≥TPj_max?若是则xj(I+1)=TPj_min或xj(I+1)=TPj_max,若否则转至下一步5、按照输入量xj(I+1)计算声品质O(I+1),并根据式(6)和(7)计算C’j(I+1)及C’(I+1)。6、判断是否满足退出优化条件,若是则转至下一步,若否则令I=I+1,重复步骤3~5。7、根据式(1)求出各个xj_opt所对应的最优临界频带幅值增益βj_opt,形成最优临界频带幅值增益组合{βopt}。将本发明的优化方法用于多稳态工况下车内声品质“舒适度”的主动噪声均衡控制中。例中临界频带j的个数n=5,也就是输入量xj为5个;βj的范围设定为0~1.5;隐节点i的数量为m=7;,是隐含层传递函数f1()采用tansig传递函数,输出层传递函数f2()采用purelin传递函数;设定优化初始条件C′(1)=(10,10,10,10,10)和Error(1)=10,学习步长μc′=0.01,退出优化的条件Imax=1000、Gradmin=0.01和Tolerance=0.01。图3、图4和图5为实例中N档1750rpm工况下声品质“舒适度”值O(I)、Error(I)以及Gradient随优化迭代次数I的变化,声品质“舒适度”值O(I)随迭代次数增加逐渐提升,优化迭代是由于满足了Error(I)≤Tolerance的条件而停止的,而Gradient也随优化迭代次数I增多呈现陡降趋势。其他工况的优化过程也与此类似。表1列出了本方法与枚举法对比情况,可见,相比于现有技术的枚举法,本方法大大缩减了优化迭代次数,并且优化后的“舒适度”与枚举法相当,表2列出了本方法优化后的最优临界频带幅值增益组合{βopt}。表1两种优化方法对比表2本方法优化后的最优临界频带幅值增益组合{βopt}工况最优增益组合{βopt}N档1250rpm(0.98,0.0,1.5,1.0,1.0)N档1500rpm(0.90,0.0,1.5,0.0,1.0)N档1750rpm(1.5,0.0,1.5,0.0,1.0)N档2000rpm(0.0,0.28,1.5,0.0,0.0)N档2000rpm(0.0,0.11,1.5,1.5,1.0)4档1500rpm(0.72,0.0,1.5,0.0,1.0)4档2000rpm(1.5,1.5,1.5,1.0,0.0)5档2200rpm(0.0,0.0,0.0,1.0,1.0)怠速800rpm(0.56,0.0,1.0,1.0,1.0)以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1