一种多人命令语音识别方法、系统及存储介质与流程
本发明语音识别领域,尤其涉及一种多人命令语音识别方法、系统及存储介质。
背景技术
语音识别技术是指机器把音频输入转换为文字或命令的技术。在语音识别过程中,尤其是麦克风阵列具有远场识别功能时,音频信号采集的灵敏度会比较高。用户周围如果有其他不相干的人说话,麦克风会同时采集到多个人的声音,而且不相关部分的声音幅值也会高于语音识别门限,导致用户与设备的交互以及周围其他人之间的闲聊均被设备采集,使语音识别模块无法判断用户的意图,从而难以做出正确的响应。
传统的音频信号处理方法有麦克风降噪,回声消除,主要是用来去除环境中喇叭或者设备产生的噪声;还有自动增益控制技术,主要用来稳定音频信号。但对于嘈杂环境中多人讲话时,却无法提升语音识别效果。
随着社会与科学技术的高速发展,人机交互技术发展成为一门重要技术,应用于智能机器人及智能手机等智能设置的人机交互,需要语音识别技术做为人机交互的基础,而在现有的人机交互中,都是对智能设备进行单独命令,语音识别也是单人语音识别,识别的精度并不高,在智能设备上的响应也只能进行单人响应,一次响应完毕后再对语音进行识别,才能再次响应,无法针对多个用户同时命令做出连续的响应。
技术实现要素:
本发明的目的是针对上述现有技术存在的缺陷,提供一种多人命令语音识别方法、系统及存储介质。
本发明采用的技术方案是,提供一种多人命令语音识别方法,包括:
智能音箱通过采音设备获取至少一个用户语音指令;
根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在;
根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在;
将所述至少一个唤醒词与所述至少一个执行命令按用户声纹特征进行匹配,得到与至少一个用户对应的至少一个响应指令;
智能音箱对所述至少一个响应指令根据响应策略进行匹配响应。
优选的,在根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在之前,所述方法还包括:
智能音箱通过采音设备采集至少一个用户声纹特征;
将采集到的所述至少一个用户声纹特征配置为存储有至少一个用户声纹特征的声纹库,所述声纹库对应一个用户表;
所述声纹库分区配置,分别配置为存储所述至少一个用户的唤醒词声纹特征区与执行命令声纹特征区。
在使用用户声纹特征进行识别前,应对用户的声纹进行记录,以用于在识别时对用户的声纹进行匹配。
优选的,所述方法还包括:
在所述采集至少一个用户声纹特征、及所述获取至少一个用户语音指令时进行第一去噪处理;
在所述根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在、及在所述根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在时进行第二去噪处理。
采集或获取到的声音因环境的影响,会在用户的声音中参杂噪声,而在识别多用户的语音的情况下,噪声对于识别的结果影响更大,会造成识别精度下降甚至无法识别的情况。
优选的,所述方法在所述对所述至少一个响应指令根据响应策略进行匹配响应前还包括:
确定响应优先级;
根据所述确定响应优先级配置一用户权限表。
当存在多个用户语音命令时,不能实现同时响应,应当确定响应的优先级,按照优先级进行响应,才能在更好的完成响应,所述用户权限表记录用户的优先级情况。
优选的,所述对所述至少一个响应指令根据响应策略进行匹配响应的方法包括:
根据用户声纹特征将响应指令映射到用户表;
检测用户的响应优先级;
按用户的响应优先级进行输出。
通过用户声纹特征将响应指令映射到用户表,为所述用户表临时赋予一个响应指令,在判断优先级后,可调用用户表的响应指令直接进行输出。
还提供一种多人命令语音识别系统,包括:
输入模块,用于获取至少一个用户语音指令;
语音识别模块,用于根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个唤醒词的存在;还用于根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在;
指令生成模块,用于将所述至少一个唤醒词与所述至少一个执行命令按用户声纹特征进行匹配,得到与至少一个用户对应的至少一个响应指令;
检测模块,用于检测用户优先级;
响应模块,用于对所述至少一个响应指令根据响应策略进行匹配响应。
优选的,所述输入模块还用于采集至少一个用户声纹特征,所述系统还包括:
存储子模块,用于将采集到的所述至少一个用户声纹特征配置为存储有至少一个用户声纹特征的声纹库,所述声纹库对应一个用户表;
所述存储子模块设置有第一存储区用于配置为存储所述至少一个用户的唤醒词声纹特征区,以及第二存储区用于配置为存储所述执行命令声纹特征区。
所述唤醒词声纹特征区与所述执行命令声纹特征区分开设置,在对唤醒词进行识别时,只需要调用所述唤醒词声纹特征区的识别程序,在对执行命令进行识别时,只需要调用所述执行命令声纹特征区的识别程序,缩小的识别的范围。
优选的,所述输入模块内设置有第一去噪子模块,用于在所述采集至少一个用户声纹特征、及所述获取至少一个用户语音指令时进行第一去噪处理;
所述语音识别模块内设置有第二去噪子模块,用于在所述根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在、及所述根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在前进行第二去噪处理。
采集或获取到的声音因环境的影响,会在用户的声音中参杂噪声,而在识别多用户的语音的情况下,噪声对于识别的结果影响更大,会造成识别精度下降甚至无法识别的情况。所述第一去噪子模块对所述输入模块进行第一去噪处理,所述第二去噪子模块对所述语音识别模块进行第二去噪处理,进一步的减少环境噪声带来的对用户语音的影响,提高了语音识别的精度。
优选的,所述系统还包括指令输出子模块,用于向用户输出响应指令。
所述存储子模块内还包括:一映射表用于根据用户声纹特征将响应指令映射到用户表,以及一用户权限表用于确定响应优先级。
当存在多个用户语音命令时,所述响应模块不能实现同时响应,应当确定响应的优先级,所述响应模块按照优先级进行响应,才能在更好的完成响应,所述用户权限表记录用户的优先级情况,通过用户声纹特征将响应指令映射到用户表,为所述用户表临时赋予一个响应指令,在判断优先级后,可调用用户表的响应指令直接进行输出。
还提供一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或所述指令集由所述处理器加载并执行以实现如前述的多人命令语音识别方法。
与现有技术相比,本发明至少具有以下有益效果:本发明通过用户的声纹特征分别识别多个用户的唤醒词与执行命令,并按照响应策略进行响应,唤醒词与执行命令分开识别,提高了语音识别精度,按响应策略执行用户的语音命令,还可使语音命令清晰的得到执行,不会混乱。
附图说明
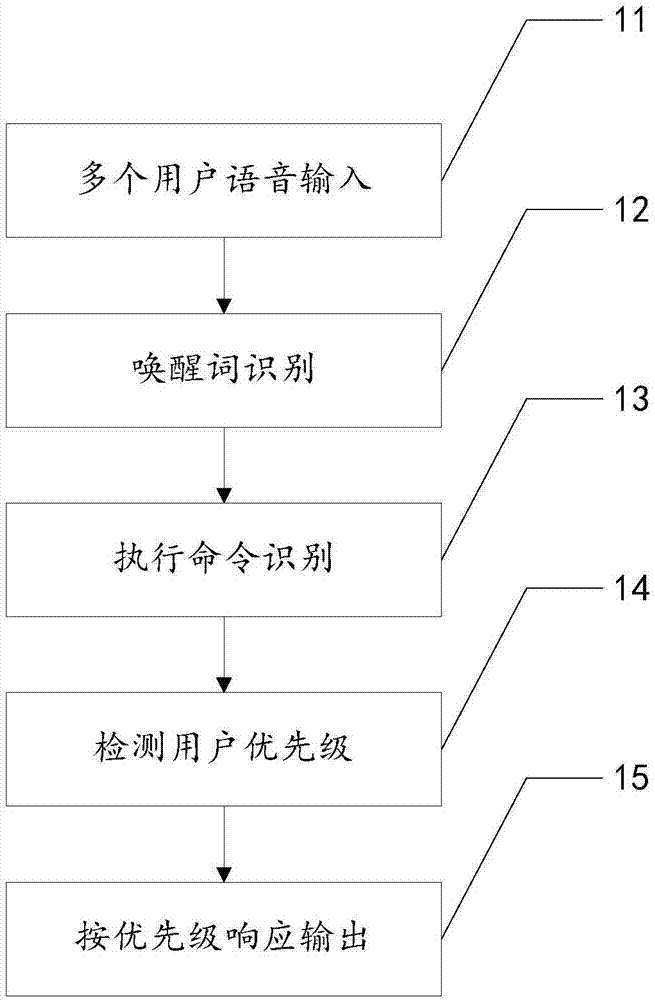
图1为本发明实施例的方法流程图;
图2为本发明实施例的声纹库配置方法流程图;
图3为本发明实施例的用户权限表配置方法流程图;
图4为本发明实施例的响应策略方法流程图;
图5为本发明实施例的系统模块示意图。
具体实施方式
下面结合附图和实施例对本发明做进一步说明。
如图1所示,本发明提出了一种多人命令语音识别方法,设定所述方法的实施环境,所述实施环境包括:响应终端,所述响应终端为智能设备包括并不限于:智能音箱、智能手机、平板电脑、智能机器人等,所述终端安装有语音交互类应用,并内置有麦克风,并设置有能根据语音识别出的指令进行响应的执行机构,所述执行机构在智能手机与平板电脑上体现为语音打开应用等,在智能机器人上体现为语音命令机器人做出相应动作。
在本发明实施例中,所述环境优选为智能音箱,所述智能音箱内设置可以采集语音的麦克风及显示屏,在智能音箱中,还设置有语音识别功能模块,当然,做为一种可能的实施环境,所述智能音箱可以与提供语音识别服务的语音平台进行网络信号连接。
所述方法包括步骤:
11、多个用户语音输入,获取至少一个用户语音指令;通过所述终端上的麦克风对用户的语音进行采集输入,将采集到的信号为电流模拟信号,所述电流信号可以通过模数转换器将电流模拟信号转化为数字音频信号,所述数字音频信号便于进行存储与分析。
进一步的,为了降低语音指令识别的压力,可在对语音指令进行识别之前,先通过声纹特征对用户进行识别,挑选出有权限的用户的语音指令再进行识别。在对用户进行识别的过程中,获取识别用户的信息,所述信息可以包括:用户权限信息、用户数量信息、用户位置信息等。所述用户权限信息可以是预先设置在所述智能音箱中的权限信息,所述用户数量信息可以通过声纹特征进行获取,所述用户位置信息可以通过检测声源位置进行获取。
做为一种可能的实施例,为增加用户语音指令识别的效率,在对用户语音进行采集时,可以根据所述用户位置信息对用户进行顺序编号,在对用户进行识别时,通过声纹特征对不同位置的用户的语音频段进行拾取并关联到用户的顺序编号,剔除无权用户的编号,根据用户位置信息按由近到远对用户语音指令进行逐一识别。
做为另一种可能的实施例,为增加用户语音指令识别的效率,在对用户语音进行采集时,可以根据用户语音指令输入的顺序进行顺序编号,在对用户进行识别时,通过声纹特征对不同时间发出语音指令的用户的语音频段进行拾取并关联到用户顺序编号,剔除无权用户的编号,按用户语音指令输入的时间顺序对用户语音指令进行逐一识别。
做为又一种可能的实施例,为增加用户语音指令识别的效率,在对用户语音进行采集时,可以根据用户信息进行编号,在对用户进行识别时,通过声纹特征对不同用户的语音频段进行拾取并关联到用户编号,剔除无权用户的编号,将带有用户编号的语音频段按编号分别发送到多个语音识别装置中同时进行识别。
12、唤醒词识别,根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在;所述用户语音指令应遵循语音的输入策略,应当包括唤醒词及执行命令,所述唤醒词为激活终端语音响应的关键词,可避免在不需要响应时进行响应造成麻烦的情况。同时有多个用户语音指令时,通过声纹进行识别,声纹(voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。声纹不仅具有特定性,而且有相对稳定性的特点。成年以后,人的声音可保持长期相对稳定不变。无论讲话者是故意模仿他人声音和语气,还是耳语轻声讲话,即使模仿得惟妙惟肖,其声纹却始终不相同。借助声纹特性,可使语音识别平台更容易捕捉用户的语音波段,从而提高语音识别的精度。所述唤醒词为特定的词,每个用户在使用所述唤醒词时,其声纹特征也为特定的波段,便于识别的同时,还能进一步提高对唤醒词识别的精度。
13、执行命令识别,根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在;语音指令中的执行命令是终端如何进行响应的依据,根据用户的声纹特征进行识别,可提高语音识别的精度,在语音指令中,执行命令做为一特定的关键词或关键语句被语音识别系统进行识别,比如,用户需要智能机器人做“挥手”动作,输入语音为“小x,来挥手一下”,这段语音指令中,“小x”做为唤醒词被识别,可唤醒机器人对“来挥手一下”的识别,在对“来挥手一下”的识别中,“挥手”做为执行命令被获取,并被输入到执行机构中使智能机器人做出挥手动作。
当然,在智能机器人挥手的实例中,“一下”也可做为一个执行命令关键词与“挥手”进行组合,通过识别“一下”中的数量对“挥手”做循环指令,识别到的“下”或“次”等为循环条件关键词,在“下”或“次”等关键词前的量词被识别为循环次数关键词。
在多用户同时对终端进行语音控制时,需要对多个用户的语音指令进行识别,识别语音指令的用户以及识别语音指令的待响应内容。所述语音识别可以是与终端信号连接的语音识别平台,也可以内置在终端内的语音识别系统。
将所述至少一个唤醒词与所述至少一个执行命令按用户声纹特征进行匹配,得到与至少一个用户对应的至少一个响应指令;所述唤醒词识别在先,所述执行命令识别在后,需要按照声纹特征进行匹配,可得到完整的包含唤醒词及执行命令的响应指令,当所述响应指令同时包含唤醒词及执行命令时才是一个有效响应指令,有效响应指令才能被终端响应执行。通过声纹特征识别用户,并将有效指令映射到用户。
14、检测用户优先级,对所述至少一个响应指令根据响应策略进行匹配;所述响应策略主要是响应的优先级顺序,在多个用户同时输入语音指令时,存在多个待响应的有效指令,当然,所述的多个用户中都为拥有基础响应权限的用户,对没有拥有基础响应权限的用户可以不响应。
对于没有拥有基础响应权限的用户,在对唤醒词进行声纹识别时,可识别出这部分用户,便可不再进行下一步的识别。当然,对于没有基础响应权限的用户,也可以由最高权限者配置临时用户表,对临时用户授予临时权限,便可以进行临时响应。
15、按优先级响应输出,输出响应。在多个用户都拥有基础权限的情况下,检测用户优先级,也就是检测用户中谁的权限更高,比如,在一个家庭中的智能机器人,女主人拥有最高权限,小主人拥有第二级权限,男主人拥有第三级权限,在三个人同时对智能机器人输入语音指令时,智能机器人优先响应拥有最高权限的女主人的指令,其次响应第二级权限的小主人的指令,最后响应拥有第三级权限的男主人,在有客人来访时,女证人可对客人开放临时权限,智能机器人对于客人的指令响应在男主人之后,同时存在多个客人,拥有相同的临时权限,在识别临时用户语音指令并对临时用户做出识别后,响应的顺序为按唤醒词获取的先后顺序进行响应,或者按语音指令完成的先后顺序进行响应。
如图2所示,在根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在之前,所述方法还包括步骤:
21、采集用户声纹,采集至少一个用户声纹特征;通过所述终端上的麦克风对有权限的用户的语音进行采集输入,将采集到的信号为电流模拟信号,再通过模数转换器将电流模拟信号转化为数字音频信号,所述数字音频信号便于进行存储与分析。对用户的数字音频信号进行区分,区分出用户的声纹特征并进行数字化的存储。
22、配置用户声纹库,将采集到的所述至少一个用户声纹特征配置为存储有至少一个用户声纹特征的声纹库,所述声纹库对应一个用户表;所述用户表与所述声纹库为映射关系,所述声纹库内的用户声纹特征能够通过一有映射表映射到所述用户表中对应的用户上,所述映射关系为声纹库中用户声纹对应到用户表中对应用户。
23、声纹库分区,所述声纹库分区配置,分别配置为存储所述至少一个用户的唤醒词声纹特征区与执行命令声纹特征区。具体的,所述唤醒词声纹特征区配置的存储容量要比执行命令声纹特征区配置的存储容量小,所述唤醒词为固定的一个或少许几个特定的指令,不必设置太多,如果太多,不仅会对语音识别造成影响,拖慢识别的速度,同时,还会出现不小心唤醒的情况。如同人的名字,如果一个人的名字太多,有可能别人随口一叫另外一人,他就会以为是在叫他,进而发生响应,非常不方便。
在使用用户声纹特征进行识别前,应对用户的声纹进行记录,以用于在识别时对用户的声纹进行匹配。
在本发明实施例中,所述方法还包括:
在所述采集至少一个用户声纹特征、及所述获取至少一个用户语音指令时进行第一去噪处理;所述第一去噪处理为滤波去噪,具体采集到的语音中会包含环境的噪声,对环境噪声进行去噪,先要进行对环境噪声的采集,得到环境噪声的波段,通过滤波去噪去掉这部分噪声的波段,在进行多人语音识别时,减少环境噪声的影响,可以提高语音识别的精度。
在所述根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在、及所述根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在时进行第二去噪处理。所述第二去噪处理为非关键词去噪,去掉非关键词对唤醒词及执行命令形成指令的影响,增加了响应的速度。
采集或获取到的声音因环境的影响,会在用户的声音中参杂噪声,而在识别多用户的语音的情况下,噪声对于识别的结果影响更大,会造成识别精度下降甚至无法识别的情况。
如图3所示,所述方法在所述对所述至少一个响应指令根据响应策略进行匹配响应前还包括:
31、确定优先级,确定用户的响应优先级;对多用户的优先级进行确定,最优先级用户对终端拥有最高权限,最高权限应属于终端的拥有者,可转让最高权限。
32、配置用户权限表,根据所述确定响应优先级配置一用户权限表。所述用户权限表用以确定用户的响应优先级,同时,所述用户权限表还用于在权限更改后对新用户权限进行更改,并为用户添加临时权限。
当存在多个用户语音命令时,不能实现同时响应,应当确定响应的优先级,按照优先级进行响应,才能在更好的完成响应,所述用户权限表记录用户的优先级情况。
如图4所示,所述对所述至少一个响应指令根据响应策略进行匹配响应的方法包括步骤:
41、赋予用户表指令,根据用户声纹特征将响应指令映射到用户表;所述响应指令为包括唤醒词与执行命令组成的有效响应指令,并映射在用户表上形成一个可临时调用的指令。
42、检测用户优先级,检测用户的响应优先级;通过用户权限表检测输入语音指令的用户的权限情况,并按权限情况配置响应顺序,并将响应顺序临时赋予到用户表上。
43、输出用户指令,按用户的响应优先级进行输出。调用用户表中的临时指令对终端进行控制,终端按用户表中临时赋予的响应顺序和响应指令进行响应,响应完毕后,清空用户表中的临时数据。
通过用户声纹特征将响应指令映射到用户表,为所述用户表临时赋予一个响应指令,在判断优先级后,可调用用户表的响应指令直接进行输出。
如图5所示,还提供一种多人命令语音识别系统,所述系统搭载于一响应终端,响应终端,所述响应终端为智能设备包括并不限于:智能手机、平板电脑、智能机器人等,所述终端安装有语音交互类应用,并内置有麦克风,并设置有能根据语音识别出的指令进行响应的执行机构,所述执行机构在智能手机与平板电脑上体现为语音打开应用等,在智能机器人上体现为语音命令机器人做出相应动作。
所述系统包括:
输入模块51,用于获取至少一个用户语音指令;所述输入模块为终端内置的麦克风,通过所述终端上的麦克风对用户的语音进行采集输入,将采集到的信号为电流模拟信号,再通过模数转换器将电流模拟信号转化为数字音频信号,所述数字音频信号便于进行存储、分析及处理。
语音识别模块52,所述语音识别模块由语音识别芯片及电路组成,所述语音识别模块52包括唤醒词识别子模块,所述唤醒词识别子模块用于根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个唤醒词的存在;以及执行命令识别子模块,用于根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在;所述唤醒识别子模块识别特定的词为唤醒词,每个用户在使用所述唤醒词时,其声纹特征也为特定的波段,便于识别的同时,还能进一步提高对唤醒词识别的精度。同样的,所述执行命令识别子模块也识别特定的词为执行命令,同样通过声纹进行识别,同样能进一步提高对执行命令识别的精度。
指令生成模块53,用于将所述至少一个唤醒词与所述至少一个执行命令按用户声纹特征进行匹配,通过所述指令生成模块53生成与至少一个用户对应的至少一个响应指令;所述唤醒词识别在先,所述执行命令识别在后,需要按照声纹特征进行匹配,可得到完整的包含唤醒词及执行命令的响应指令,当所述响应指令同时包含唤醒词及执行命令时才是一个有效响应指令,有效响应指令才能被终端响应执行。通过声纹特征识别用户,并将有效指令映射到用户。
检测模块54,用于检测用户的优先级;在多个用户同时通过所述输入模块51输入语音指令时,通过所述语音识别模块52识别后,并通过所述指令生成模块53生成多个待响应的有效指令,对所述有效指令进行响应。
响应模块55,所述响应模块55用于对所述至少一个响应指令根据响应策略进行匹配响应。所述响应策略主要是所述响应模块55对用户响应的优先级顺序,在多个用户同时通过所述输入模块51输入语音指令时,通过所述语音识别模块52识别后,并通过所述指令生成模块53生成多个待响应的有效指令,对所述有效指令进行响应。当然,所述的多个用户中都为拥有基础响应权限的用户,对没有拥有基础响应权限的用户可以不响应。
对于没有拥有基础响应权限的用户,在对唤醒词进行声纹识别时,可识别出这部分用户,便可不再进行下一步的识别。当然,对于没有基础响应权限的用户,也可以由最高权限者配置临时用户表,对临时用户授予临时权限,在通过所述检测模块54检测用户优先级后,便可以通过所述响应模块55进行临时响应。
在本发明实施例中,所述输入模块还用于采集至少一个用户声纹特征,所述系统还包括:
存储子模块,用于将采集到的所述至少一个用户声纹特征配置为存储有至少一个用户声纹特征的声纹库,所述声纹库对应一个用户表;所述用户表与所述声纹库为映射关系,所述声纹库内的用户声纹特征能够通过一有映射表映射到所述用户表中对应的用户上。所述映射关系为声纹库中用户声纹对应到用户表中对应用户。
所述存储子模块设置有第一存储区用于配置为存储所述至少一个用户的唤醒词声纹特征区,以及第二存储区用于配置为存储所述执行命令声纹特征区。具体的,所述第一存储区的存储容量要小所述第二存储区的存储容量,即所述唤醒词声纹特征区配置的存储容量要比执行命令声纹特征区配置的存储容量小,所述唤醒词为固定的一个或少许几个特定的指令,不必设置太多,如果太多,不仅会对语音识别造成影响,拖慢识别的速度,同时,还会出现不小心唤醒进而发生响应的情况。
所述唤醒词声纹特征区与所述执行命令声纹特征区分开设置,在对唤醒词进行识别时,只需要调用所述唤醒词声纹特征区的识别程序,在对执行命令进行识别时,只需要调用所述执行命令声纹特征区的识别程序,缩小了的识别的范围,不仅提高了识别的精度,还提高了响应的速度。
在本发明实施例中,所述输入模块内设置有第一去噪子模块,用于在所述采集至少一个用户声纹特征、及所述获取至少一个用户语音指令时进行第一去噪处理;所述第一去噪处理为滤波去噪装置,具体采集到的语音中会包含环境的噪声,对环境噪声进行去噪,先要进行对环境噪声的采集,得到环境噪声的波段,通过滤波去噪装置去掉这部分噪声的波段,在进行多人语音识别时,减少环境噪声的影响,可以提高语音识别的精度。
所述语音识别模块内设置有第二去噪子模块,用于在所述根据用户声纹特征识别检测所述至少一个用户语音指令中至少一个唤醒词的存在、及所述根据用户声纹特征识别检测所述至少一个用户语音指令中的至少一个执行命令的存在时进行第二去噪处理。所述第二去噪处理为非关键词去噪,去掉非关键词对唤醒词及执行命令形成指令的影响,增加了响应的速度。所述第二去噪子模块为数字去噪装置,通过数字去噪装置,可对数字化的语音指令进行去噪,去除与唤醒词及执行命令无关的其他信号。
采集或获取到的声音因环境的影响,会在用户的声音中参杂噪声,而在识别多用户的语音的情况下,噪声对于识别的结果影响更大,会造成识别精度下降甚至无法识别的情况。所述第一去噪子模块对所述输入模块进行第一去噪处理,所述第二去噪子模块对所述语音识别模块进行第二去噪处理,进一步的减少环境噪声带来的对用户语音的影响,提高了语音识别的精度。
在本发明实施例中,所述系统还包括指令输出子模块,用于向用户表输出响应指令。所述响应指令为包括唤醒词与执行命令组成的有效响应指令,所述指令输出子模块输出所述有效响应指令到用户表上形成一个可临时调用的指令。
所述存储子模块内还包括:一映射表用于根据用户声纹特征将响应指令映射到用户表,以及一用户权限表用于确定响应优先级。所述用户权限表用以确定用户的响应优先级,同时,所述用户权限表还用于在权限更改后对新用户权限进行更改,并为用户添加临时权限。
具体的,通过检测模块检测54输入语音指令的用户的权限情况,并按权限情况配置响应顺序,并将响应顺序临时赋予到用户表上。调用用户表中的临时指令对终端进行控制,响应模块55按用户表中临时赋予的响应顺序和响应指令进行响应,响应完毕后,清空用户表中的临时数据。
当存在多个用户语音命令时,所述响应模块不能实现同时响应,应当确定响应的优先级,所述响应模块按照优先级进行响应,才能在更好的完成响应,所述用户权限表记录用户的优先级情况,通过用户声纹特征将响应指令映射到用户表,为所述用户表临时赋予一个响应指令,在判断优先级后,可调用用户表的响应指令直接进行输出。
还提供一种计算机可读存储介质,所述存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述至少一条指令、所述至少一段程序、所述代码集或所述指令集由所述处理器加载并执行以实现前述的多人命令语音识别方法。
上述实施例仅用于说明本发明的具体实施方式。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和变化,这些变形和变化都应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!