一种人声起止时间检测方法及装置与流程
本发明涉及语音数据处理技术领域,尤其涉及一种人声起止时间检测方法及装置。
背景技术:
目前,语音通话功能、录音功能和音乐播放功能等是目前移动终端上的常用功能,由于在上述功能的运行过程中会在人声中间夹杂无声的片段、使得用户体验效果不佳。基于上述难题,现有技术的基于深度学习的方法通过利用带噪语音的频谱特征及其变种作为输入,得到该帧语音的标签。这种方法存在以下缺点:在有复杂噪声情况下的性能很差导致信噪比很低,在这种环境下不能准确的判断语音的vad(语音端点检测)标签,进而无法确定语音中人声的开始时间和结束时间,效果不佳且稳定性低。
技术实现要素:
针对上述所显示出来的问题,本方法基于预先训练降噪模型然后利用降噪模型对带噪的预设vad语音进行降噪的同时得到预测mask值,根据预测mask值训练vad模型然后利用训练后的vad模型提取带噪的当前vad标签进而确定带噪的当前vad语音中的人声开始时间和结束时间。
一种人声起止时间检测方法,包括以下步骤:
利用带噪的预设语音生成所述预设语音的第一倒谱特征,基于所述第一倒谱特征获得预测掩蔽值;
根据所述预测掩蔽值对第一预设神经网络进行训练进而生成训练后的第一神经网络;
利用所述训练后的第一神经网络得到带噪的预设vad语音的预测mask值;
根据所述预测mask值对第二预设神经网络进行训练进而生成训练后的第二神经网络;
获取带噪的当前vad语音,基于所述训练后的第一神经网络和所述训练后的第二神经网络获得所述带噪的当前vad语音的起止时间。
优选的,所述利用带噪的预设语音生成所述预设语音的第一倒谱特征,基于所述第一倒谱特征获得预测掩蔽值,包括:
获取多个带噪的预设语音;
利用下列公式提取所述第一倒谱特征:
cepstral=istft(log(stft(mixture)));
其中,所述stft()为短时傅里叶变换,所述istft为短时逆傅里叶变换,所述mixture为带噪的预设语音;
将所述第一倒谱特征输入到所述第一预设神经网络中以计算所述预测掩蔽值。
优选的,所述根据所述预测掩蔽值对第一预设神经网络进行训练进而生成训练后的第一神经网络,包括:
获取多个纯净的预设语音;所述多个纯净的预设语音与所述多个带噪的预设语音相对应;
利用下列公式计算实际掩蔽值:
其中,所述pure为纯净的预设语音,所述θ为相位,|xx|为幅度;
计算所述实际掩蔽值和所述预测掩蔽值的差值;
通过前馈算法和所述差值对所述第一预设神经网络进行训练进而生成所述训练后的第一神经网络。
优选的,所述利用所述训练后的第一神经网络得到带噪的预设vad语音的预测mask值,包括:
获取所述带噪的预设vad语音;
提取所述带噪的预设vad语音的第二倒谱特征;
将所述第二倒谱特征输入到所述训练后的第一神经网络中;
输出所述预测mask值;
所述根据所述预测mask值对第二预设神经网络进行训练进而生成训练后的第二神经网络,包括:
将所述预测mask值输入到所述第二预设神经网络中以计算预测vad标签;
根据实际vad标签和所述预设vad标签的差值对所述预设第二神经网络进行训练以生成所述训练后的第二神经网络。
优选的,所述获取带噪的当前vad语音,基于所述训练后的第一神经网络和所述训练后的第二神经网络获得所述带噪的当前vad语音的起止时间,包括:
提取所述带噪的当前vad语音的第三倒谱特征;
将所述第三倒谱特征输入到所述训练后的第一神经网络中以得到当前mask值;
将所述当前mask值输入到所述训练后的第二神经网络中以得到当前vad标签;
根据所述当前vad标签确定所述带噪的当前vad语音中人声的起止时间。
一种人声起止时间检测装置,该装置包括:
第一获取模块,用于利用带噪的预设语音生成所述预设语音的第一倒谱特征,基于所述第一倒谱特征获得预测掩蔽值;
第一训练模块,用于根据所述预测掩蔽值对第一预设神经网络进行训练进而生成训练后的第一神经网络;
生成模块,用于利用所述训练后的第一神经网络得到带噪的预设vad语音的预测mask值;
第二训练模块,用于根据所述预测mask值对第二预设神经网络进行训练进而生成训练后的第二神经网络;
第二获取模块,用于获取带噪的当前vad语音,基于所述训练后的第一神经网络和所述训练后的第二神经网络获得所述带噪的当前vad语音的起止时间。
优选的,所述第一获取模块,包括:
第一获取子模块,用于获取多个带噪的预设语音;
第一提取子模块,用于利用下列公式提取所述第一倒谱特征:
cepstral=istft(log(stft(mixture)));
其中,所述stft()为短时傅里叶变换,所述istft为短时逆傅里叶变换,所述mixture为带噪的预设语音;
第一计算子模块,用于将所述第一倒谱特征输入到所述第一预设神经网络中以计算所述预测掩蔽值。
优选的,所述第一训练模块,包括:
第二获取子模块,用于获取多个纯净的预设语音;所述多个纯净的预设语音与所述多个带噪的预设语音相对应;
第二计算子模块,用于利用下列公式计算实际掩蔽值:
其中,所述pure为纯净的预设语音,所述θ为相位,|xx|为幅度;
第三计算子模块,用于计算所述实际掩蔽值和所述预测掩蔽值的差值;
第一训练子模块,用于通过前馈算法和所述差值对所述第一预设神经网络进行训练进而生成所述训练后的第一神经网络。
优选的,所述生成模块,包括:
第三获取子模块,用于获取所述带噪的预设vad语音;
第二提取子模块,用于提取所述带噪的预设vad语音的第二倒谱特征;
输入子模块,用于将所述第二倒谱特征输入到所述训练后的第一神经网络中;
输出子模块,用于输出所述预测mask值;
所述第二训练模块,包括:
第四计算子模块,用于将所述预测mask值输入到所述第二预设神经网络中以计算预测vad标签;
第二训练子模块,用于根据实际vad标签和所述预设vad标签的差值对所述预设第二神经网络进行训练以生成所述训练后的第二神经网络。
优选的,所述第二获取模块,包括:
第三提取子模块,用于提取所述带噪的当前vad语音的第三倒谱特征;
第一获得子模块,用于将所述第三倒谱特征输入到所述训练后的第一神经网络中以得到当前mask值;
第二获得子模块,用于将所述当前mask值输入到所述训练后的第二神经网络中以得到当前vad标签;
确定子模块,用于根据所述当前vad标签确定所述带噪的当前vad语音中人声的起止时间。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明所提供的一种人声起止时间检测方法的工作流程图;
图2为本发明所提供的一种人声起止时间检测方法的另一工作流程图;
图3为本发明所提供的一种人声起止时间检测方法的工作流程截图;
图4为本发明所提供的一种人声起止时间检测装置的结构图;
图5为本发明所提供的一种人声起止时间检测装置的另一结构图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
目前,语音通话功能、录音功能和音乐播放功能等是目前移动终端上的常用功能,由于在上述功能的运行过程中会在人声中间夹杂无声的片段、使得用户体验效果不佳。基于上述难题,现有技术的基于深度学习的方法通过利用带噪语音的频谱特征及其变种作为输入,得到该帧语音的标签。这种方法存在以下缺点:在有复杂噪声情况下的性能很差导致信噪比很低,在这种环境下不能准确的判断语音的vad标签,进而无法确定语音中人声的开始时间和结束时间,效果不佳且稳定性低。为了解决上述问题,本实施例公开了一种基于预先训练降噪模型然后利用降噪模型对带噪的预设vad语音进行降噪的同时得到预测mask值,根据预测mask值训练vad模型然后利用训练后的vad模型提取带噪的当前vad标签进而确定带噪的当前vad语音中的人声开始时间和结束时间的方法。
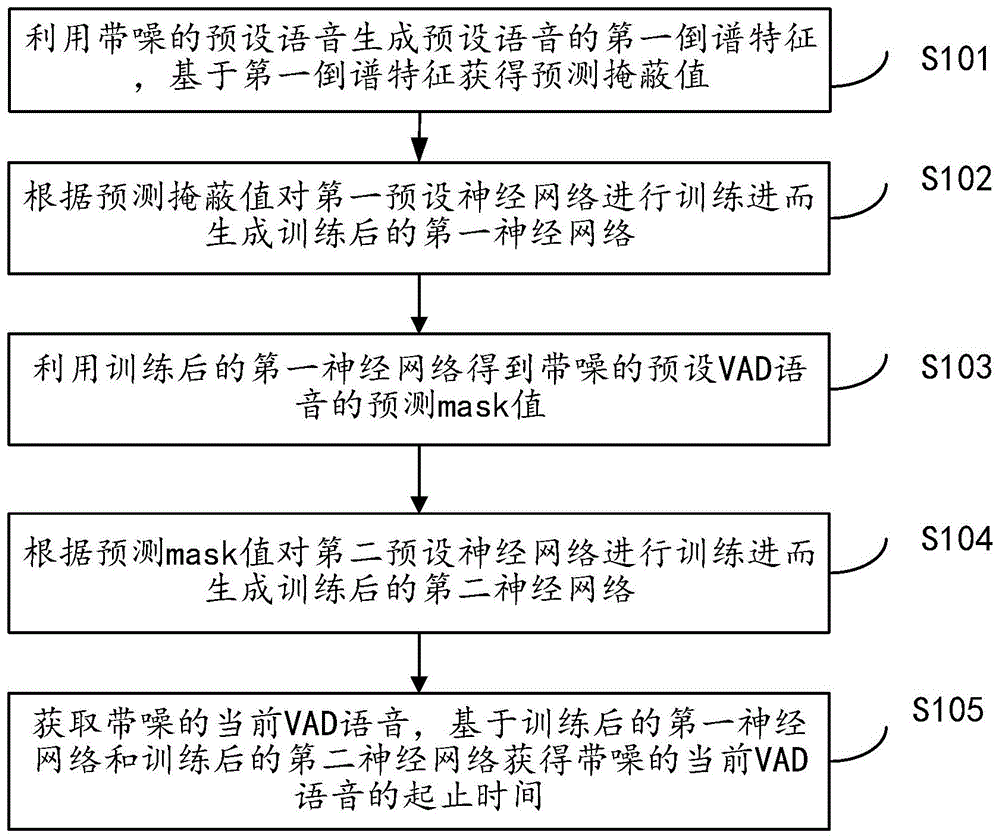
一种人声起止时间检测方法,如图1所示,包括以下步骤:
步骤s101、利用带噪的预设语音生成预设语音的第一倒谱特征,基于第一倒谱特征获得预测掩蔽值;
步骤s102、根据预测掩蔽值对第一预设神经网络进行训练进而生成训练后的第一神经网络;
步骤s103、利用训练后的第一神经网络得到带噪的预设vad语音的预测mask值;
步骤s104、根据预测mask值对第二预设神经网络进行训练进而生成训练后的第二神经网络;
步骤s105、获取带噪的当前vad语音,基于训练后的第一神经网络和训练后的第二神经网络获得带噪的当前vad语音的起止时间;
特别的,上述mask值指的是在语音中语音里每一帧为人声的概率,mask的值都在0到1之间,当某帧属于语音的时候,该帧的mask值会接近于1,相反的,当某帧属于噪音的时候,该帧的mask值会接近于0。
上述技术方案的工作原理为:提取带噪的预设语音的第一倒谱特征,基于第一倒谱特征获得预测掩蔽值,利用预测掩蔽值来对第一预设神经网络训练而生成训练后的第一神经网络,通过训练后的第一神经网络对带噪的预设vad语音进行降噪然后得到预测mask值,根据预测mask值对第二预设神经网络进行训练,生成训练后的第二神经网络,获取带噪的当前vad语音结合上述训练后的第一神经网络和训练后的第二神经网络来获得当前vad标签进而确定当前vad语音中人声的起止时间。
上述技术方案的有益效果为:本发明通过对带噪的vad语音进行加降噪处理然后获得vad标签进而确定上述vad标签里人声的起止时间,排除了语音中的噪音成分,解决了现有技术中由于信噪比低无法准确的根据vad标签获得语音中人声的起止时间的问题,从根本上提高了整个过程的稳定性和获取结果的准确性。
在一个实施例中,利用带噪的预设语音生成预设语音的第一倒谱特征,基于第一倒谱特征获得预测掩蔽值,包括:
获取多个带噪的预设语音;
利用下列公式提取第一倒谱特征:
cepstral=istft(log(stft(mixture)));
其中,stft()为短时傅里叶变换,istft为短时逆傅里叶变换,mixture为带噪的预设语音;
将第一倒谱特征输入到第一预设神经网络中以计算预测掩蔽值。
上述技术方案的有益效果为:获取多个带噪的预设语音来获取多种掩蔽值以应对不同的情况,进而根据多种掩蔽值来训练预设神经网络,使得训练模型更加完整,避免了由于当前带噪语音中含有预设神将网络无法识别的掩蔽值而无法对当前带噪语音有效降噪的问题。同时,获取倒谱特征来训练预设神经网络相比于基于深度学习技术的降噪方法所需要的其他特征所训练预设神经网络更加完美,降噪效果也更佳。
在一个实施例中,根据预测掩蔽值对第一预设神经网络进行训练进而生成训练后的第一神经网络,包括:
获取多个纯净的预设语音;多个纯净的预设语音与多个带噪的预设语音相对应;
利用下列公式计算实际掩蔽值:
其中,pure为纯净的预设语音,θ为相位,|xx|为幅度;
计算实际掩蔽值和预测掩蔽值的差值;
通过前馈算法和差值对第一预设神经网络进行训练进而生成训练后的第一神经网络。
上述技术方案的有益效果为:通过对同一种带噪语音和纯净语音的预测掩蔽值和实际掩蔽值进行差值计算进而通过前馈算法优化预设神经网络,使得预设神经网络用以包含更多的掩蔽值,并且训练后的神经网络也更加的完美,以使当前带噪语音可以实现更好的降噪效果。
在一个实施例中,如图2所示,利用训练后的第一神经网络得到带噪的预设vad语音的预测mask值,包括:
获取带噪的预设vad语音;
提取带噪的预设vad语音的第二倒谱特征;
将第二倒谱特征输入到训练后的第一神经网络中;
输出预测mask值;
根据预测mask值对第二预设神经网络进行训练进而生成训练后的第二神经网络,包括:
将预测mask值输入到第二预设神经网络中以计算预测vad标签;
根据实际vad标签和预设vad标签的差值对预设第二神经网络进行训练以生成训练后的第二神经网络。
上述技术方案的有益效果为:通过将带噪的预设vad语音输入到训练后的第一神经网络中来进行降噪,除去语音中的噪音部分,避免噪音对后续获取的vad模型产生干扰和变异的同时也使的信噪比更高,使整个工作流程会更加的高效。
在一个实施例中,获取带噪的当前vad语音,基于训练后的第一神经网络和训练后的第二神经网络获得带噪的当前vad语音的起止时间,包括:
步骤s201、提取带噪的当前vad语音的第三倒谱特征;
步骤s202、将第三倒谱特征输入到训练后的第一神经网络中以得到当前mask值;
步骤s203、将当前mask值输入到训练后的第二神经网络中以得到当前vad标签;
步骤s204、根据当前vad标签确定带噪的当前vad语音中人声的起止时间。
上述技术方案的有益效果为:确保获得的当前vad是纯净无噪的,避免发生误把噪音当成人声进而生成错误vad模型的问题,进一步地提高了稳定性和准确性,对于用户来说提高了体验感。
在一个实施例中,如图3所示,包括:
1、提取带噪语音mixture的倒谱特征,公式如下
cepstral=istft(log(|stft(mixture)|));
stft和istft分别为短时傅里叶变换和其逆变换,|·|表示幅度。
2、计算mixture与对应纯净语音pure之间的psm(phasesensitivemask),公式如下
|·|表示幅度,θ表示相位;
3、通过前馈算法,利用mse(meansquareerror)作为损失函数训练神经网络,并保存训练好的网络;
4、将用大量带噪语音训练好的模型保存,将需要做vad的带噪语音输入到模型中,得到该句语音每个时频点所对应的是语音的概率值,即mask值;
5、将得到的带噪语音的mask值输入到vad模型中进行训练,训练过程中根据当前语音帧的实际vad标签和模型输出之间的差异来修改模型的参数,直到模型收敛并保存训练好的模型备用;
6、将带噪的需要vad预测的语句输入到降噪模型,然后将得到的mask输入到vad预测模型,得到该语音每帧的vad标签,并进行后处理得到语音段的起止时间。
上述技术方案的工作原理和有益效果为:提取带噪的预设语音的第一倒谱特征,基于第一倒谱特征获得预测掩蔽值,利用预测掩蔽值来对第一预设神经网络训练而生成训练后的第一神经网络,通过训练后的第一神经网络对带噪的预设vad语音进行降噪然后得到预测mask值,根据预测mask值对第二预设神经网络进行训练,生成训练后的第二神经网络,获取带噪的当前vad语音结合上述训练后的第一神经网络和训练后的第二神经网络来获得当前vad标签进而确定当前vad语音中人声的起止时间。通过大量数据训练的降噪模型得到每个频点的mask值,mask的值都在0到1之间,表示该频点是语音的概率,当该帧属于语音的时候,部分频点的mask值会接近于1,而当该帧属于噪声的时候,每个频点的mask值会接近于0,模型根据每个频点是语音与否给出概率值,直接在mask上进行vad训练和预测降低了算法对语音能量的依赖,即噪声的mask比语音的mask小,且与语音实际能量无关,提高了模型在低信噪比环境下的vad预测准确率。
本实施例还公开了一种人声起止时间检测装置,如图4所示,该装置包括:
第一获取模块401,用于利用带噪的预设语音生成预设语音的第一倒谱特征,基于第一倒谱特征获得预测掩蔽值;
第一训练模块402,用于根据预测掩蔽值对第一预设神经网络进行训练进而生成训练后的第一神经网络;
生成模块403,用于利用训练后的第一神经网络得到带噪的预设vad语音的预测mask值;
第二训练模块404,用于根据预测mask值对第二预设神经网络进行训练进而生成训练后的第二神经网络;
第二获取模块405,用于获取带噪的当前vad语音,基于训练后的第一神经网络和训练后的第二神经网络获得带噪的当前vad语音的起止时间。
在一个实施例中,第一获取模块,包括:
第一获取子模块,用于获取多个带噪的预设语音;
第一提取子模块,用于利用下列公式提取第一倒谱特征:
cepstral=istft(log(stft(mixture)));
其中,stft()为短时傅里叶变换,istft为短时逆傅里叶变换,mixture为带噪的预设语音;
第一计算子模块,用于将第一倒谱特征输入到第一预设神经网络中以计算预测掩蔽值。
在一个实施例中,第一训练模块,包括:
第二获取子模块,用于获取多个纯净的预设语音;多个纯净的预设语音与多个带噪的预设语音相对应;
第二计算子模块,用于利用下列公式计算实际掩蔽值:
其中,pure为纯净的预设语音,θ为相位,|xx|为幅度;
第三计算子模块,用于计算实际掩蔽值和预测掩蔽值的差值;
第一训练子模块,用于通过前馈算法和差值对所述第一预设神经网络进行训练进而生成训练后的第一神经网络。
在一个实施例中,生成模块,包括:
第三获取子模块,用于获取带噪的预设vad语音;
第二提取子模块,用于提取带噪的预设vad语音的第二倒谱特征;
输入子模块,用于将第二倒谱特征输入到训练后的第一神经网络中;
输出子模块,用于输出预测mask值;
第二训练模块,包括:
第四计算子模块,用于将预测mask值输入到第二预设神经网络中以计算预测vad标签;
第二训练子模块,用于根据实际vad标签和预设vad标签的差值对预设第二神经网络进行训练以生成训练后的第二神经网络。
在一个实施例中,如图5所示,第二获取模块,包括:
第三提取子模块4051,用于提取带噪的当前vad语音的第三倒谱特征;
第一获得子模块4052,用于将第三倒谱特征输入到训练后的第一神经网络中以得到当前mask值;
第二获得子模块4053,用于将当前mask值输入到训练后的第二神经网络中以得到当前vad标签;
确定子模块4054,用于根据当前vad标签确定带噪的当前vad语音中人声的起止时间。
本领域技术人员应当理解的是,本发明中的第一、第二指的是不同应用阶段而已。
本领域技术用户员在考虑说明书及实践这里公开的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!