一种车载语音交互方法、智能座舱系统及车载设备与流程
本说明书涉及智能座舱,尤其涉及一种车载语音交互方法、智能座舱系统及车载设备。
背景技术:
1、近年来,人们对于智能汽车的车载语音交互需求越来越高,但由于智能汽车语音识别的影响因素众多,例如车外复杂的噪音环境,车内多个说话人同一时间说话产生的语音相互干扰等等,使得智能汽车的车载语音识别效果大打折扣。
2、为了提高车载语音识别效果,特别是识别车载空间的多个说话人在同一时间说话形成的混合音频,现有语音识别技术将混合音频按照事先构建的音区进行语音分离,从而有效分离出混合音频中的不同说话人语音。但是,由于现有语音识别技术极度依赖于音区划分的准确性,因此需要保证说话人所处实际位置和所划分的音区一一对应,一旦说话人在说话时偏离其所在位置,则很可能会被识别成其他音区的语音,造成其他音区的误识别。可见,现有语音识别技术的应用存在一定局限性。
技术实现思路
1、本说明书提供了一种车载语音交互方法、智能座舱系统及车载设备,以解决或者部分解决车载空间内的说话人偏离其所在位置发出语音时造成的误识别问题。
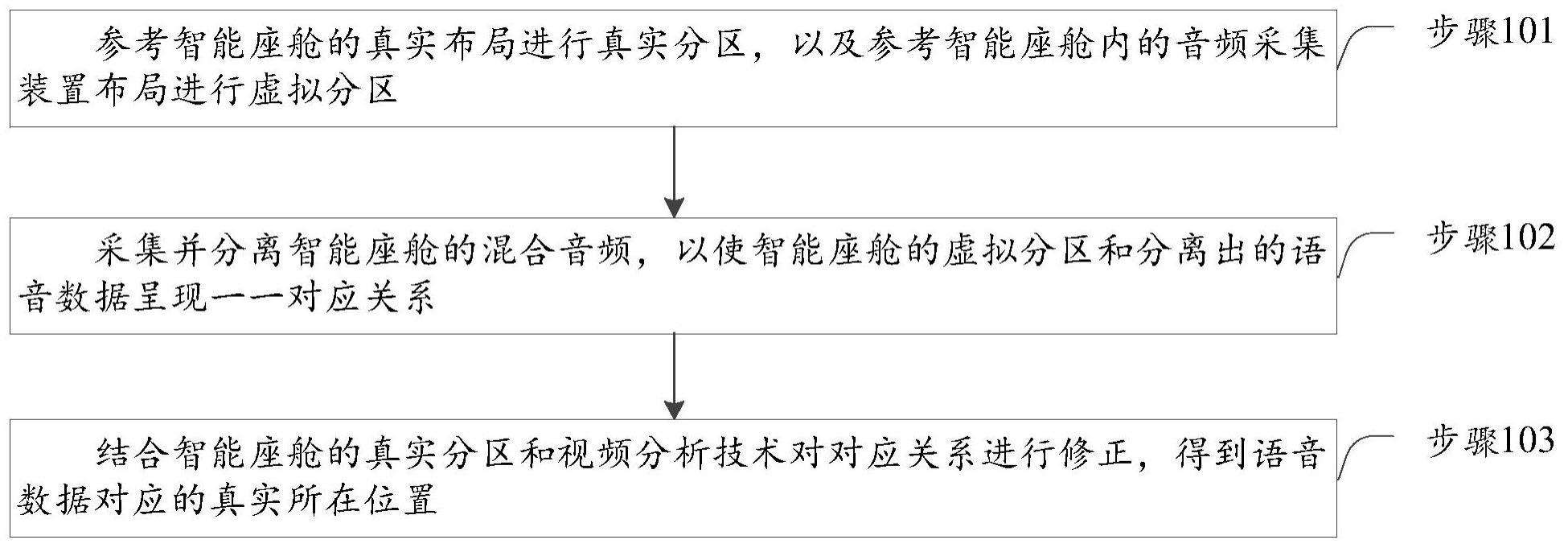
2、本说明书的第一方面,公开了一种车载语音交互方法,所述方法包括:
3、参考智能座舱的真实布局进行真实分区,以及参考所述智能座舱内的音频采集装置布局进行虚拟分区;
4、采集并分离所述智能座舱的混合音频,以使所述智能座舱的虚拟分区和分离出的语音数据呈现一一对应关系;
5、结合所述智能座舱的真实分区和视频分析技术对所述对应关系进行修正,得到所述语音数据对应的真实所在位置。
6、可选的,所述采集并分离所述智能座舱的混合音频之前,所述方法还包括:
7、采用深度学习技术构建噪声抑制模型,利用所述噪声抑制模型对所述混合音频中的非平稳噪声进行降噪处理。
8、可选的,所述结合所述智能座舱的真实分区和视频分析技术对所述对应关系进行修正,得到所述语音数据对应的真实所在位置,具体包括:
9、基于产生所述语音数据的产生时刻,利用所述视频分析技术锁定在所述产生时刻具有语言输出的目标说话人及其在所述智能座舱中的真实分区;
10、利用所述目标说话人所在真实分区修正所述语音数据对应的虚拟分区,得到所述语音数据对应的真实所在位置。
11、可选的,所述结合所述智能座舱的真实分区和视频分析技术对所述对应关系进行修正,得到所述语音数据对应的真实所在位置,具体包括:
12、若所述智能座舱的同一虚拟分区在同一时段具有两路以上语音数据,利用所述视频分析技术锁定在所述同一时段具有语言输出的两个以上目标说话人及其在所述智能座舱中的真实分区;
13、利用唇读识别技术识别所述两路以上语音数据各自对应的目标说话人;
14、基于所述两路以上语音数据各自对应的目标说话人所在真实分区修正对应语音数据的虚拟分区,得到所述两路以上语音数据各自对应的真实所在位置。
15、可选的,若所述两路以上语音数据中包含用于唤醒车载设备的预设唤醒词;所述利用所述视频分析技术锁定在所述同一时段具有语言输出的两个以上目标说话人及其在所述智能座舱中的真实分区之后,所述方法还包括:
16、在产出所述两路语音数据后的预设时间段,利用所述视频分析技术确定未发出语音的目标说话人及其在所述智能座舱中的真实分区;
17、利用所述未发出语音的目标说话人所在真实分区修正所述预设唤醒词对应的虚拟分区,得到所述预设唤醒词对应的真实所在位置。
18、可选的,所述得到所述语音数据对应的真实所在位置之后,所述方法还包括:
19、若所述语音数据包含预设唤醒词,识别与所述预设唤醒词隶属于同一虚拟分区且在所述预设唤醒词之后产出的目标语音数据。
20、可选的,在识别与所述预设唤醒词隶属于同一虚拟分区且在所述预设唤醒词之后产出的目标语音数据之前,所述方法还包括:对所述目标语音数据对应的干扰项数据进行抑制,得到待识别语音数据;
21、所述识别与所述预设唤醒词隶属于同一虚拟分区且在所述预设唤醒词之后产出的目标语音数据,具体包括:识别所述待识别语音数据。
22、可选的,所述对所述目标语音数据对应的干扰项数据进行抑制,具体包括下述一种或多种方式:
23、采集所述目标语音数据对应的说话人动态视频;其中,所述说话人动态视频用于展示输出所述目标语音数据时的说话人嘴型动作,每帧视频帧中映射有语音帧数据,所述语音帧数据通过以帧为单位划分所述目标语音数据得到;
24、结合所述目标语音数据对应的说话人动态视频逐帧检测,若检测到目标视频帧中处于所述目标语音数据所属虚拟区域中的目标说话人未开口,则将所述目标视频帧对应的语音帧数据作为干扰项数据进行抑制;
25、按照声音响度确定谐波基频,查找与所述谐波基频呈非倍数的语音帧数据作为干扰项数据进行抑制;
26、分析所述目标语音数据对应的响度,将响度处于设定阈值之下的语音帧数据作为干扰项数据进行抑制。
27、本说明书的第二方面,公开了一种智能座舱系统,包括:
28、控制模块,用于参考智能座舱的真实布局进行真实分区,以及参考所述智能座舱内的音频采集装置布局进行虚拟分区;
29、分区模块,用于采集并分离所述智能座舱的混合音频,以使所述智能座舱的虚拟分区和分离出的语音数据呈现一一对应关系;
30、修正模块,用于结合所述智能座舱的真实分区和视频分析技术对所述对应关系进行修正,得到所述语音数据对应的真实所在位置。
31、可选的,所述系统还包括:
32、噪声抑制模块,用于在采集并分离所述智能座舱的混合音频之前,采用深度学习技术构建噪声抑制模型,利用所述噪声抑制模型对所述混合音频中的非平稳噪声进行降噪处理。
33、可选的,所述修正模块,具体用于:
34、基于产生所述语音数据的产生时刻,利用所述视频分析技术锁定在所述产生时刻具有语言输出的目标说话人及其在所述智能座舱中的真实分区;
35、利用所述目标说话人所在真实分区修正所述语音数据对应的虚拟分区,得到所述语音数据对应的真实所在位置。
36、可选的,所述修正模块,具体用于:
37、若所述智能座舱的同一虚拟分区在同一时段具有两路以上语音数据,利用所述视频分析技术锁定在所述同一时段具有语言输出的两个以上目标说话人及其在所述智能座舱中的真实分区;
38、利用唇读识别技术识别所述两路以上语音数据各自对应的目标说话人;
39、基于所述两路以上语音数据各自对应的目标说话人所在真实分区修正对应语音数据的虚拟分区,得到所述两路以上语音数据各自对应的真实所在位置。
40、可选的,若所述两路以上语音数据中包含用于唤醒车载设备的预设唤醒词;所述修正模块,具体还用于:
41、在产出所述两路语音数据后的预设时间段,利用所述视频分析技术确定未发出语音的目标说话人及其在所述智能座舱中的真实分区;
42、利用所述未发出语音的目标说话人所在真实分区修正所述预设唤醒词对应的虚拟分区,得到所述预设唤醒词对应的真实所在位置。
43、可选的,所述系统还包括:
44、识别模块,用于在得到所述语音数据对应的真实所在位置之后,若所述语音数据包含预设唤醒词,识别与所述预设唤醒词隶属于同一虚拟分区且在所述预设唤醒词之后产出的目标语音数据。
45、可选的,所述系统还包括:干扰抑制模块,用于对所述目标语音数据对应的干扰项数据进行抑制,得到待识别语音数据;
46、所述识别模块,具体还用于识别所述待识别语音数据。
47、可选的,所述干扰抑制模块,具体用于执行下述一种或多种方式:
48、采集所述目标语音数据对应的说话人动态视频;其中,所述说话人动态视频用于展示输出所述目标语音数据时的说话人嘴型动作,每帧视频帧中映射有语音帧数据,所述语音帧数据通过以帧为单位划分所述目标语音数据得到;
49、结合所述目标语音数据对应的说话人动态视频逐帧检测,若检测到目标视频帧中处于所述目标语音数据所属虚拟区域中的目标说话人未开口,则将所述目标视频帧对应的语音帧数据作为干扰项数据进行抑制;
50、按照声音响度确定谐波基频,查找与所述谐波基频呈非倍数的语音帧数据作为干扰项数据进行抑制;
51、分析所述目标语音数据对应的响度,将响度处于设定阈值之下的语音帧数据作为干扰项数据进行抑制。
52、本说明书的第二方面,公开了一种车载设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现上述方法的步骤。
53、通过本说明书的一个或者多个实施例,本说明书具有以下有益效果或者优点:
54、本说明书中的方案,参考智能座舱中按照真实布局和音频采集装置布局分别进行了分区,并采集智能座舱中产生的混合音频进行分离。在确定出智能座舱的虚拟分区和混合音频中各语音数据的对应关系之后,即便因说话人偏离其所在位置导致其产出的语音数据被分离到其他虚拟分区,也可以结合智能座舱的真实分区和视频分析技术进行修正,从而得到语音数据对应的真实所在位置,以避免误识别。
55、上述说明仅是本说明书技术方案的概述,为了能够更清楚了解本说明书的技术手段,而可依照说明书的内容予以实施,并且为了让本说明书的上述和其它目的、特征和优点能够更明显易懂,以下特举本说明书的具体实施方式。
- 还没有人留言评论。精彩留言会获得点赞!