补身醇合酶及生产补身醇的方法与流程
技术领域:
涉及生产补身醇(drimenol)的方法,所述方法包含使至少一种多肽接触法呢基焦磷酸酯(FPP)。具体地,所述方法可以在体外或体内进行以生产补身醇,补身醇在香料领域是一种非常有用的化合物。本文还提供在本文提供的方法中有用的多肽的氨基酸序列。本文还提供编码本文实施方式的多肽的核酸以及含有所述核酸的表达载体。本文进一步提供经转化以在所述生产补身醇的方法中使用的非人宿主生物体或细胞。
背景技术:
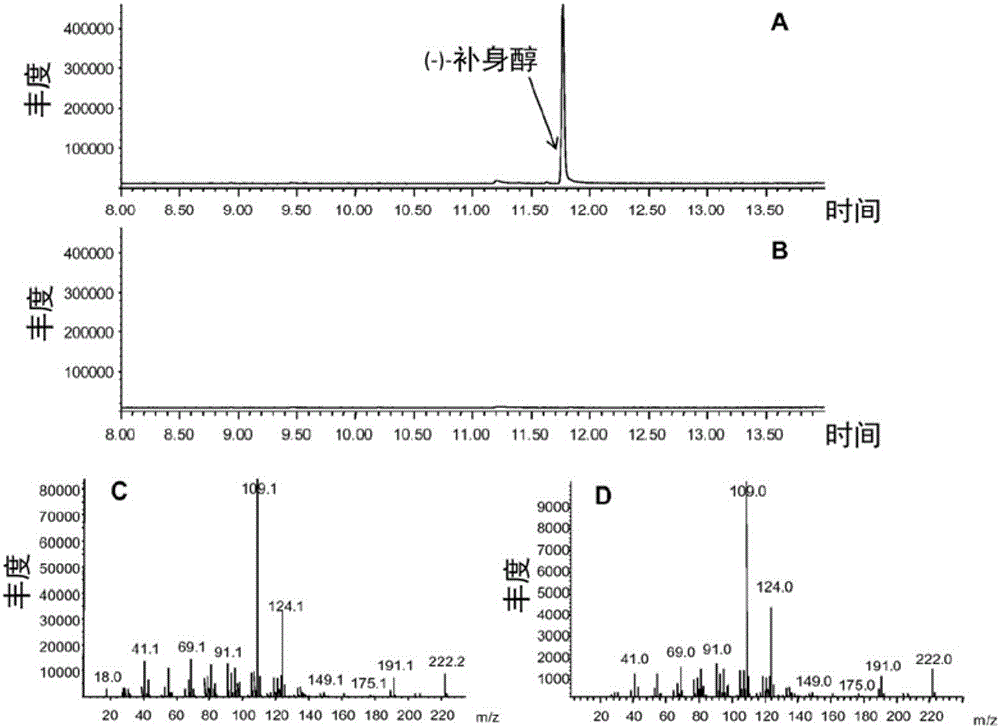
:在大多数生物体(微生物、动物和植物)中发现了萜烯。这些化合物由称为异戊二烯单元的五碳单元构成并且通过存在于它们结构中的这些单元的数目进行归类。因此,单萜、倍半萜和二萜是分别含有10、15和20个碳原子的萜烯。例如,在植物界广泛地发现了倍半萜。许多倍半萜分子因为它们的风味和香味特性以及它们的美容、医药和抗菌效果而公知。已经鉴定出许多倍半萜烃类和倍半萜类。萜烯的生物合成生产涉及称为萜合酶的酶。实际上,在植物界存在无数的倍半萜合酶,它们均使用相同的底物(法呢基焦磷酸酯,FPP),但是具有不同的产物概况。已经克隆了编码倍半萜合酶的基因和cDNA并且表征了相应的重组酶。当前,补身醇的主要来源是天然含有补身醇的植物,并且补身醇在这些天然来源中的含量较低。已经开发了化学合成途径,但仍然较复杂且不具成本效益。技术实现要素:本文提供一种生产补身醇的方法,包含:i)使无环萜烯焦磷酸酯接触具有补身醇合酶活性并且与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少或至少约70%序列同一性的多肽,以生产补身醇;和ii)可选地分离所述补身醇。本文进一步提供一种具有补身醇活性的分离的多肽,其包含与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列的氨基酸序列具有至少或至少约70%或更高同一性的氨基酸序列。本文还提供一种分离的核酸分子,其编码与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少或至少约70%序列同一性的多肽。附图说明图1.胡椒莓(Drimyslanceolata)和辛酸八角木(Drimyswinteri)的叶子的GCMS分析。图2.在体外测定中由重组体DlTps589生产的倍半萜的GCMS分析。A.使用FPP培育重组体DlTps589的倍半萜概况的总离子色谱图。B.使用空质粒转化的大肠杆菌细胞在相同条件下进行的阴性对照。C.11.76min处的峰的质谱。D.(-)-补身醇真实标准的质谱。图3.在工程细菌细胞中通过重组体DlTps589体内生产的倍半萜的GCMS分析。A.总离子色谱图。B.11.49min处的峰的质谱。C.(-)-补身醇真实标准的质谱。在10.98min洗脱出的化合物是DlTps589酶生产的法尼醇或由大肠杆菌细胞生产的过量FPP的水解产生的法尼醇。图4.由重组体DlTps589合酶生产的(-)-补身醇的结构。图5.由重组体酶生产的(-)-补身醇(上)、由化学法获得的外消旋补身醇(中)和真实(-)-补身醇(下)的手性GC\FID色谱图。图6.由重组蛋白SCH51-3228-9(A)、SCH51-998-28(B)或SCH52-13163-6(C)在体外测定中生产的倍半萜的GCMS分析的总离子色谱图。图7.由表达不同重组蛋白SCH51-3228-9(A)、SCH51-998-28(B)或SCH52-13163-6(C)的工程化细菌细胞体外生产的倍半萜的GCMS分析的总离子色谱图。所检测到的法尼醇起因于由大肠杆菌细胞生产的过量FPP的水解或可以是部分地由重组蛋白生产。具体实施方式对于本文的说明书以及所附的权利要求书,除非另有说明,使用的“或”是指“和/或”。类似地,“包含(comprise)”、“包含(comprises)”、“包含(comprising)”、“包括(include)”、“包括(includes)”和“包括(including)”可以互换使用并且不旨在限制。还应当理解的是,在各个实施方式的描述使用术语“包含”的情况下,本领域技术人员能够理解,在一些具体情形中,可以替代地使用语言“基本上由……组成”或“由……组成”来描述一个实施方式。在一个方面,此处提供一种生产补身醇的方法,包含:i)使无环萜烯焦磷酸酯(特别是法呢基二磷酸酯(FPP))接触具有补身醇合酶活性并且与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少或至少约70%、特别是75%、特别是80%、特别是85%、特别是90%、特别是95%、特别是96%、特别是97%、特别是98%或特别是99%或更高序列同一性的多肽,以生产补身醇;和ii)可选地分离所述补身醇。在一个方面,补身醇被分离出。此处进一步提供一种具有补身醇活性的多肽,其包含的氨基酸序列与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列的氨基酸序列具有至少或至少约70%、特别是75%、特别是80%、特别是85%、特别是90%、特别是95%、特别是96%、特别是97%、特别是98%或更高、特别是99%或更高的同一性。本文进一步提供一种分离的核酸分子,其编码一种多肽,该多肽包含与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列的氨基酸序列具有至少或至少约70%、特别是75%、特别是80%、特别是85%、特别是90%、特别是95%、特别是96%、特别是97%、特别是98%或更高、特别是99%或更高同一性的氨基酸序列。本文进一步提供一种核酸分子,其包含从由SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNo:13和SEQIDNO:15组成的组中选择的序列。此处进一步提供如权利要求1中所述的方法,其包含步骤:使用编码多肽的核酸转化宿主细胞或非人生物体,该多肽与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少或至少约70%、特别是75%、特别是80%、特别是85%、特别是90%、特别是95%、特别是96%、特别是97%、特别是98%或特别是99%或更高的序列同一性;和在允许生产所述多肽的条件下培养所述宿主细胞或生物体。进一步提供的是至少一种载体,其包含所述的核酸分子。本文进一步提供从由原核载体、病毒载体和真核载体组成的组中选择的载体。此处进一步提供一种载体,其为表达载体。作为“补身醇合酶”或作为“具有补身醇合酶活性的多肽”,此处我们指的是能够以无环萜烯焦磷酸酯(特别是FPP)为起始催化合成任一立体异构体形式或立体异构体混合物形式的补身醇的多肽。补身醇可以是唯一的产物或可以是倍半萜混合物的一部分。多肽催化特定倍半萜(例如补身醇)的合成的能力可以简单地通过进行如实施例2至5中详细说明的酶测定法来确认。多肽还意指包括截短的多肽,前提是它们保持了补身醇合酶活性。如下文所预期的,“通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列获得的核苷酸序列”涵盖使用本领域众所周知的任何方法(例如,通过导入任何类型的突变,诸如缺失、插入或取代突变),通过改变SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10或SEQIDNO:12的序列或它们的互补序列获得的任何序列。此种方法的例子在关于变体多肽及制备它们的方法的说明部分进行了列举。两个肽或核苷酸序列之间的同一性百分比是在比对已经产生的两个序列时,这两个序列中相同的氨基酸或核苷酸残基的数目的函数。相同的残基被定义为在两个序列中在比对的给定位置是相同的残基。如本文中使用的“序列同一性百分比”,是从最佳对比通过将两个序列之间的相同残基的数目除以最短序列中残基的总数目并且乘以100来计算的。最佳比对是其中同一性百分比为最高可能的比对。在比对的一个或多个位置可以向一个或两个序列中导入间隙以获得最佳比对。然后,将这些间隙视为用于计算序列同一性百分比的非相同残基。可以使用计算机程序且例如在万维网上可获得的公共可用的计算机程序,以各种方式来实现为确定氨基酸或核酸序列同一性百分比目的的比对。优选地,可在http://www.ncbi.nlm.nih.gov/BLAST/bl2seq/wblast2.cgi从国家生物技术信息中心(NCBI)获得的设定至缺省参数的BLAST程序(Tatianaetal,FEMSMicrobiolLett.,1999,174:247-250,1999)可以被用来获得肽或核苷酸序列的最佳比对以及计算序列同一性百分比。使用的缩写bp碱基对kb千碱基BSA牛血清白蛋白DNA脱氧核糖核酸cDNA互补DNADTT二硫苏糖醇FID火焰电离检测器FPP法尼基焦磷酸酯GC气相色谱IPTG异丙基-D-硫代半乳糖-吡喃糖苷LB溶源性肉汤MS质谱仪MVA甲羟戊酸PCR聚合酶链反应RMCE重组酶介导的盒式交换3’-/5’-RACE3’和5’快速扩增cDNA末端RNA核糖核酸mRNA信使核糖核酸miRNA微RNAsiRNA小干扰RNArRNA核糖体RNAtRNA转移RNA定义术语“多肽”是指连续聚合的氨基酸残基的氨基酸序列,例如,至少15个残基,至少30个残基,至少50个残基。在本文提供的一些实施方式中,多肽包含作为酶、其片段或其变体的氨基酸序列。术语“分离的”多肽是指通过本领域已知的任何方法(包括重组、生物化学和合成法)或方法的组合从天然环境中取出的氨基酸序列。术语“蛋白”是指任何长度的氨基酸序列,其中氨基酸被共价肽键所连接,并且包括寡肽、肽、多肽和全长蛋白,不管天然生成的还是合成的。术语“补身醇合酶”或“补身醇合酶蛋白”是指能够将法尼基二磷酸酯(FPP)转化为补身醇的酶。术语“生物学功能”、“功能”、“生物学活性”或“活性”是指补身醇合酶催化从FPP形成补身醇的能力。可互换使用的术语“核酸序列”、“核酸”和“多核苷酸”是指核苷酸的序列。核酸序列可以是任何长度的单链或双链脱氧核糖核苷酸或核糖核苷酸,并且包括基因、外显子、内含子、有义和反义互补序列、基因组DNA、cDNA、miRNA、siRNA、mRNA、rRNA、tRNA、重组核酸序列、分离的和纯化的天然产生的DNA和/或RNA序列、合成DNA和RNA序列、片段、引物和核酸探针的编码和非编码序列。本领域技术人员了解,RNA的核酸序列相同于DNA序列,差异在于胸腺嘧啶(T)被替代为尿嘧啶(U)。“分离的核酸”或“分离的核酸序列”被定义为一种核酸或核酸序列,其所处的环境与天然产生的核酸或核酸序列所处的环境不同。如本文使用的应用于核酸的术语“天然产生的”是指在自然的细胞中发现的核酸。例如,存在于能够从自然源中分离出的生物体(例如生物体的细胞)中的核酸序列,并且该核酸序列未经人类在实验室进行特意的改造,那么该核酸序列是天然产生的。“重组核酸序列”是使用实验室方法(分子克隆)将来自多于一个源的遗传物质组合在一起所生成的核酸序列,由此创造出不是天然产生并且不能以其它方式在生物生物体中发现的核酸序列。“重组DNA技术”是指用于制备重组核酸序列的分子生物学程序,例如描述于由Weigel和Glazebrook编制的实验室手册,2002ColdSpringHarborLabPress;和Sambrooketal.,1989ColdSpringHarbor,NY:ColdSpringHarborLaboratoryPress中。术语“基因”是指一种DNA序列,其包含可操作地连接到适当调控区域(例如启动子)的被转录为RNA分子(例如细胞中的mRNA)的区域。因此,基因可以包含多个可操作地连接的序列,诸如启动子、5’前导序列(包含例如参与翻译初始化的序列)、cDNA或基因组DNA的编码区、内含子、外显子和/或3’非翻译序列(包含例如转录终止位点)。“嵌合基因”是指通常不能在自然物种中找到的任何基因,特别是其中核酸序列存在一个或多个部分在性质上彼此不相关联的基因。例如,启动子在性质上与转录区的部分或全部或与另一调控区不相关联。术语“嵌合基因”应当被理解为包括表达构建体,其中启动子或转录调控序列被可操作地连接到一个或多个编码序列或反义(即有义链的反向互补链)或反向重复序列(有义和反义,由此RNA转录物在转录后形成双链RNA)。“3’UTR”或“3’非翻译序列”(也称为“3’未翻译区”或“3’末端”)是指在基因的编码序列的下游发现的核酸序列,其包含例如转录终止位点和(在大多数但非全部的真核imRNA中)多聚腺苷酸化信号诸如AAUAAA或其变体。在转录终止后,mRNA转录物可以被切去多聚腺苷酸化信号的下游并且可以添加poly(A)尾,其参与了mRNA向翻译位点的运输,例如胞浆。“基因的表达”包括基因的转录和mRNA向蛋白质的翻译。过表达是指在转基因细胞或生物体中,以mRNA水平、多肽和/或酶活性测量的基因产物的生产超过了相似遗传背景的非转化细胞或生物体中的生产水平。如本文中使用的“表达载体”是指使用分子生物学方法和重组DNA技术工程化以将外来或外源DNA递送到宿主细胞中的核酸分子。表达载体典型地包括适合转录核苷酸序列所需的序列。编码区通常编码目的蛋白,但是也可以编码RNA,例如反义RNA、siRNA等。如本文所使用的“表达载体”包括任何线性的或环状的重组载体,包括但不限于病毒载体、噬菌体和质粒。本领域技术人员根据表达系统能够选择适合的载体。在一个实施方式中,表达载体包括可操作地连接到至少一个调控序列(其控制转录、翻译、被始化和终止,诸如转录启动子、操纵子和增强子)或mRNA核糖体结合位点的并且任选地包括至少一个选择标记的本文实施方式的核酸。当调控序列功能性地涉及本文实施方式的核酸时,核苷酸序列是“可操作地连接的”。“调控序列”是指确定本文实施方式的核酸序列的表达水平、并且能够调控可操作地连接到该调控序列的核酸序列的转录速率的核酸序列。调控序列包含启动子、增强子、转录因子、启动子元素等。“启动子”是指控制编码序列的表达的核酸序列,其提供RNA聚合酶用的结合位点以及适合转录所需的其它因子,包括但不限于转录因子结合位点、抑制子和活化子蛋白结合位点。术语启动子的含义包括术语“启动子调控序列”。启动子调控序列可以包括可能影响转录、RNA加工或相关编码核酸序列的稳定性的上游和下游元素。启动子包括天然来源的和合成的序列。编码核酸序列通常位于启动子相对于以转录起始位点为起始的转录方向的下游。术语“组成型启动子”是指不受调控的启动子,其允许其可操作地连接的核酸序列持续转录。如本文使用的,术语“可操作地连接”是指处于功能性关系的多核苷酸元素的连接。当核酸与另一核酸序列处于功能性关系时,那么该核酸是“可操作地连接的”。例如,如果启动子或者转录调控序列能够影响编码序列的转录,那么该启动子或者转录调控序列是可操作地连接到该编码序列的。可操作地连接意味着被连接的DNA序列通常是邻接的。与启动子序列有关的核苷酸序列相对于要被转化的植物可以是同源或异源来源的。所述序列还可以是完全或部分合成的。不管来源如何,与启动子序列相关的核酸序列将根据在结合到本文实施方式的多肽后所连接的启动子性质而被表达或沉默。相关核酸在所有时间或替代地在特定时间在整个生物体中或在特定组织、细胞或细胞室中可以编码需要表达或抑制的蛋白。此种核苷酸序列特别地编码将所需表型性状赋予给由其改变或转化的宿主细胞或生物体的蛋白质。更特别地,相关核苷酸序列引起在生物体中生产补身醇。特别地,所述核苷酸序列编码补身醇合酶。“靶肽”是指一种氨基酸序列,其将蛋白质或多肽靶向细胞内细胞器(即,线粒体或质体)或细胞外空间(分泌信号肽)。编码靶肽的核酸序列可以被融合到编码蛋白或多肽的氨基末端(例如N-末端)的核酸序列或者可以被用来替换原有的靶多肽。术语“引物”是指短的核酸序列,其被杂交到模板核酸序列并且被用于与该模板互补的核酸序列的聚合。如本文所使用的,术语“宿主细胞”或“转化细胞”是指被改变以包藏至少一种核酸分子(例如,编码所需蛋白或核酸序列的重组基团,该核酸序列在转录后产生有用于生产补身醇的补身醇合酶蛋白)的细胞(或生物体)。宿主细胞特别地是细菌细胞、真菌细胞或植物细胞。宿主细胞可以含有已经被整合到该宿主细胞的核或细胞器基因组中的重组基因。替代地,宿主可以含有染色体外的重组基因。同源序列包括直系或旁系同源序列。鉴别直系或旁系的方法包括现有技术中已知且在本文中描述的进化方法、序列相似性和杂交方法。旁系同源物来源于基因复制,其产生具有相似序列和相似功能的两种或更多种基因。旁系同源物典型地聚簇在一起并且通过基因在相关植物物种内的复制而形成。使用成对Blast分析或在基因家族的进化分析过程中使用程序诸如CLUSTAL在类似基因的组中发现旁系同源物。在旁系同源物中,共有序列可以是相关基因中序列的识别特性并且具有基因的类似功能。直系或直系同源序列是彼此相似的序列,因为它们被发现在由共同的祖先传下的物种中。例如,具有共同祖先的植物物种已知含有相同类似序列和功能的许多酶。本领域技术人员能够识别直系同源序列并预测直系同源的功能,例如通过使用CLUSTAL或BLAST程序构建一个物种的基因族的进化树。一种用于识别或确认同源序列间的相似功能的方法是通过比较过表达或缺乏(在基因敲除/敲除中)相关多肽的植物中的转录物概况。本领域技术人员能够理解,具有相似转录物概况的基因具有大于50%调控的共同转录物或具有大于70%调控的共同转录物或大于90%调控的共同转录物,所述转录物会具有相似的功能。本文所述序列的同源物、旁系同源物、直系同源物以及任何其它变体预期以类似的方式发挥作用,使得植物生产补身醇合酶蛋白。本文提供的一个实施方式提供补身醇合酶蛋白(包括直系同源物和旁系同源物)的氨基酸序列以及用于在其它生物体中识别和分离补身醇合酶的直系同源物和旁系同源物的方法。特别地,如此识别的补身醇合酶的直系同源物和旁系同源物保留了补身醇合酶活性并且能够以FPP前体为起始而生产补身醇。术语“选择性标记物”是指在表达后能够被用来选择包括该选择性标记物的细胞的任何基因。以下描述了选择性标记物的例子。本领域技术人员了解不同的抗生素、杀真菌剂、营养缺陷型或除草剂选择标记物可适用于不同的目标物种。本申请目的的“补身醇”是指(-)-补身醇(CAS:468-68-8)。术语“生物体”是指任何非人多细胞或单细胞生物体,诸如植物或微生物。特别地,微生物是细菌、酵母、藻类或真菌。术语“植物”被互换地用来包括植物细胞,包括植物原生质体、植物组织、产生再生植株的植物细胞组织培养物、或植物的部分、或植物机件诸如根、茎、叶、花、花粉、胚珠、胚、果实等。任何植物均可以用来实施本文实施方式的方法。在体外要与无环焦磷酸酯(例如FPP)接触的多肽可以使用标准蛋白或酶提取技术从表达它的任何生物体中提取得到。如果宿主生物体是将本文实施方式的多肽释放到培养基中的单细胞生物体或细胞,那么可以简单地从所述培养基收集所述多肽,例如,通过离心,任选地随后进行洗涤步骤和再悬浮于适合的缓冲液中。如果所述生物体或细胞将多肽累积于其细胞中,那么可以通过破裂或裂解所述细胞并且进一步从细胞裂解液中提取多肽来获得所述多肽。然后,可以将具有补身醇合酶活性的多肽(为分离的形式或与其它蛋白在一起,例如处于从培养的细胞或微生物中获得的粗制蛋白提取物中)悬浮于处在最佳pH的缓冲液中。如果适合,可以加入盐、DTT、无机阳离子及其它种类的酶促辅因子,以便使酶活性最佳化。向多肽悬浮液中加入前体FPP,然后在最佳的温度(例如15至40℃,特别地25至35℃,更特别地30℃)下进行培育。在培育之后,可以通过标准分离工序诸如溶剂提取,从培育的溶液中分离出所产生的补身醇,并且(任选地在从所述溶液中取出多肽之后)进行蒸馏。根据另一特定的实施方式,任一上述实施方式的方法是在体内进行的。在这种情况下,步骤a)包含在有助于生产补身醇的条件下,培养能够生产FPP并且经转化以表达至少一种多肽的非人宿主生物体或细胞,所述至少一种多肽包含与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少70%同一性的氨基酸序列并且具有补身醇合酶活性。根据更特别的实施方式,所述方法进一步包含,在步骤a)之前,使用至少一种编码多肽的核酸转化能够生产FPP的非人生物体或细胞,所述多肽包含与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少70%同一性的氨基酸序列并且具有补身醇合酶活性,以便所述生物体表达所述多肽。本文提供的这些实施方式是特别有利的,因为其能够在体内进行所述方法而无需预先分离出所述多肽。反应在经转化以表达所述多肽的生物体或细胞内直接发生。根据一个更特别的实施方式,在任一上述实施方式中使用的至少一种核酸包含已经通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列获得的核苷酸序列。根据另一个实施方式,所述至少一种核酸分离自林仙科家族(Winteraceaefamily)或白桂皮科家族(Canellaceaefamily)的植物,特别地分离自辛酸八角木或胡椒莓。所述生物体或细胞旨在“表达”多肽,前提是所述生物体或细胞经转化以包藏编码所述多肽的核酸,这种核酸被转录至mRNA并且在所述宿主生物体或细胞中发现所述多肽。术语“表达”涵盖“异源表达”和“过表达”,后者是指mRNA、多肽和/或酶活性的水平高于在非转化的生物体或细胞中所测量的水平。随后,在致力于此种转化的非人宿主生物体或细胞的说明书部分中以及在实施例中,将描述用于转化非人宿主生物体或细胞的适合方法的更详细说明。特定的生物体或细胞是指当其天然地产生FPP时、或当其不天然地产生FPP但是在使用本文所述的核酸转化之前或与使用所述核酸一起被转化以生产FPP时,“能够产生FPP”。经转化以比天然存在的生物体或细胞产生更高量的FPP的生物体或细胞也被“能够生产FPP的生物体或细胞”所涵盖。用于转化生物体(例如微生物)以便它们生产FPP的方法在本领域中是已知的。为了在体内进行本文的实施方式,在有助于补身醇的生产的条件下培养宿主生物体或细胞。因此,如果宿主是转基因植物,那么例如提供最佳的生长条件,诸如最佳光、水和营养条件。如果宿主是单细胞生物体,那么有助于补身醇的生产的条件可以包含向宿主的培养基中添加适合的辅因子。此外,可以选择培养基以便最大化补身醇合成。在下列实施例中以更详细的方式描述了最佳的培养条件。适合于在体内进行本文实施方式的方法的非人宿主生物体可以是任何非人多细胞或单细胞生物体。在一个特定的实施方式中,用来在体内进行本文实施方式的非人宿主生物体是植物、原核生物或真菌。可以使用任何植物、原核生物或真菌。特别有用的植物是天然产生高量萜烯的那些。在一个更特定的实施方式中,用来在体内进行本文实施方式的方法的非人宿主生物体是微生物。可以使用任何微生物,但根据甚至更特定的实施方式,所述微生物是细菌或酵母。更特别地,所述细菌是大肠杆菌并且所述酵母是酿酒酵母(Saccharomycescerevisiae)。这些生物体的一些天然不生产FPP。为了适合于进行本文实施方式的方法,这些生物体必须经转化以生产所述前体。如上所说明的,它们可以在使用根据任一上述实施方式所述的核酸改造之前或同时地被如此转化。还可以使用分离的更高等真核细胞以替代完整的生物体作为宿主,以在体内进行本文实施方式的方法。适合的真核细胞可以是任何非人细胞,但特别地是植物或真菌细胞。在另一个特定实施方式中,所述多肽由与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少70%、特别是至少75%、特别是至少80%、特别是至少85%、特别是至少90%、特别是至少95%、特别是至少96%、特别是至少97%、特别是至少98%且甚至更特别是至少99%序列同一性的氨基酸序列组成。在甚至更特别的实施方式中,所述多肽由SEQID组成。根据另一特定实施方式,在任一上述实施方式中使用的具有补身醇合酶活性的或者由在任一上述实施方式中使用的核酸编码的所述至少一种多肽包含氨基酸序列,该氨基酸序列是通过基因工程获得的SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14的变体,前提是所述变体保持了如上所定义的补身醇合酶活性并且与SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14具有所需的百分比同一性。换句话说,所述多肽特别地包含由已经通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列获得的核苷酸序列编码的氨基酸序列。根据一个更特别的实施方式,在任一上述实施方式中使用的具有补身醇合酶活性的或者由在任一上述实施方式中使用的核酸编码的所述至少一种多肽由氨基酸序列组成,该氨基酸序列是通过基因工程获得的SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14的变体,即由已经通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列获得的核苷酸序列编码的氨基酸序列。根据另一特定的实施方式,在任一上述实施方式中使用的具有补身醇合酶活性的或者由在任一上述实施方式中使用的核酸编码的所述至少一种多肽,是可以自然地在其它生物体(诸如其它植物物种)中发现的SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14的变体,前提是其保持了如上所定义的补身醇合酶活性并且与SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14具有所需的百分比同一性。如本文中使用的,所述多肽旨在是包含本文确定的氨基酸序列的多肽或肽片段以及截短的或变体多肽,前提是它们保持了如上所定义的补身醇合酶活性,并且它们与SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14的相应片段共享有至少确定百分比的同一性。变体多肽的例子是由交替mRNA剪接事件或本文所述多肽的蛋白水解切割产生的天然存在的蛋白。归因于蛋白水解的变种包括例如在不同类型的宿主细胞中表达后N-或C-末端的差异,这是由于从本文实施方式的多肽蛋白水解去除一个或多个末端氨基酸引起的。本文实施方式还涵盖了如下文所描述的,通过天然或人工突变本文实施方式的核酸获得的核酸所编码的多肽。由在氨基和羧基末端融合额外的肽序列产生的多肽变体也可以用在本文实施方式的方法中。特别地,此种融合能够增强多肽的表达,有用于蛋白的纯化或改善多肽在期望环境或表达系统中的酶活性。例如,此种额外的肽序列可以是信号肽。因此,本发明包括使用变体多肽(诸如通过与其它寡肽或多肽融合所获得的那些和/或连接到信号肽的那些)的方法。由与另一种功能肽(诸如来自萜烯生物合成路径的另一种蛋白)融合产生的多肽也可以有利地被用于本文实施方式的方法中。根据另一实施方式中,在任一上述实施方式中使用的具有补身醇合酶活性的或者由在任一上述实施方式中使用的核酸编码的所述至少一种多肽,是从林仙科家族或白桂皮科家族的植物中分离的,特别是分离自辛酸八角木或胡椒莓。实施本文实施方式的方法的一种重要工具是所述多肽本身。因此,本文提供具有补身醇合酶活性并且包含与SEQIDNO:2具有至少70%同一性的氨基酸序列的多肽。根据一个特定的实施方式,所述多肽能够生产倍半萜的混合物,其中补身醇占所产生的倍半萜的至少20%、特别地至少30%、特别地至少35%、特别地至少90%、特别地至少95%、更特别地至少98%。在本文提供的另一方面,以大于或等于95%、更特别地98%的选择性生产补身醇。根据一个特定的实施方式,所述多肽包含与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的序列具有至少70%、特别是至少75%、特别是至少80%、特别是至少85%、特别是至少90%、特别是至少95%、特别是至少96%、特别是至少97%、特别是至少98%且甚至更特别是至少99%同一性的氨基酸序列。根据一个更特别的实施方式,所述多肽包含从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11和SEQIDNO:14组成的组中选择的氨基酸序列。根据另一个特定的实施方式中,所述多肽由一种氨基酸序列组成,该氨基酸序列与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14组成的组中选择的序列具有至少70%、特别是至少75%、特别是至少80%、特别是至少85%、特别是至少90%、特别是至少95%、特别是至少96%、特别是至少97%、特别是至少98%且甚至更特别是至少99%的同一性。根据另一个特定的实施方式中,所述多肽由一种氨基酸组成,该氨基酸序列从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14组成的组中选择。所述至少一种多肽包含作为SEQIDNO:2的变体的氨基酸序列,其是通过基因工程获得的或者在辛辣木(Drimys)植物或在其他植物物种中发现的。换言之,当通过基因工程获得所述变体多肽时,所述多肽包含由已经通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列获得的核苷酸序列编码的氨基酸序列。根据一个更特定的实施方式,具有补身醇合酶活性的所述至少一种多肽由氨基酸序列组成的,该氨基酸序列是通过基因工程获得的SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14的变体,即由已经通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列获得的核苷酸序列编码的氨基酸序列。根据另一个实施方式,所述多肽分离自林仙科家族或白桂皮科家族的植物,特别是分离自辛酸八角木或胡椒莓。如本文所使用的,所述多肽旨在作为包含本文确定的氨基酸序列多肽或肽片段、以及截短的或变体多肽,前提是它们保持了如上定义的活性并且它们与SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14的相应片段共享至少确定百分比的同一性。如上所述,当在体内实施所述方法时,编码本文实施方式的多肽的核酸是一种用来改造将要使用的非人宿主生物体或细胞的有用工具。因此,本文还提供编码根据任一上述实施方式所述的多肽的核酸。根据一个特定的实施方式,所述核酸包含与从由NO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列组成的组中选择的序列具有至少50%、特别是至少55%、特别是至少60%、特别是至少65%、特别是至少70%、特别是至少75%、特别是至少80%、特别是至少85%、特别是至少90%、更特别是至少95%、特别是至少96%、特别是至少97%、特别是至少98%且甚至更特别是至少99%同一性的核苷酸序列。根据一个更特定的实施方式,所述核酸包含从由NO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15组成的组中选择的核苷酸序列。根据另一个特定的实施方式,所述核酸由核苷酸序列组成,该核苷酸序列与从由NO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列组成的组中选择的序列具有至少70%、特别是至少75%、特别是至少80%、特别是至少85%、特别是至少90%、特别是至少95%、特别是至少96%、特别是至少97%、特别是至少98%且甚至更特别是至少99%或更高的同一性。根据一个甚至更特定的实施方式,所述核酸由一种序列组成,该序列选自于由SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列组成的组。本文实施方式的核酸可以被定义为包括单链形式或双链形式的脱氧核糖核苷酸或核糖核苷酸聚合物(DNA和/或RNA)。术语“核苷酸序列”应当被理解为包含多核苷酸分子或独立片段形式的寡核苷酸分子或被理解为较大核酸的组件。本文实施方式的核酸还涵盖某些分离的核苷酸序列,包括基本上不含内源性污染物质的那些分离的核苷酸序列。本文实施方式的核酸可以是截短的,前提是其编码如上所述的本发明涵盖的多肽。在一个实施方式中,本文实施方式的核酸可以天然地存在于辛辣木物种中或其它物种中,或者可以通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列来获得。特别地,所述核酸由已经通过修饰SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列获得的核苷酸序列组成。包含通过SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列的突变所获得的序列的核酸被涵盖在本文的实施方式中,前提是它们与SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或它们的互补序列的相应片段共享有至少所定义百分比的同一性,并且前提是它们编码如任一上述实施方式所定义的具有补身醇合酶活性的多肽。突变可以是这些核酸的任何种类突变,诸如点突变、缺失突变、插入突变和/或移码突变。可以制备变体核酸以便使其核苷酸序列适应特定的表达系统。例如,如果氨基酸由特定的密码子编码,已知细菌表达系统能更有效地表达多肽。由于遗传密码的简并,多于一个密码子可以编码相同的氨基酸序列,多个核酸序列能够编码相同的蛋白或多肽,所有这些DNA序列均被涵盖在本文实施方式中。在适当的情况下,编码补身醇合酶的核酸序列可以被优化在增加在宿主细胞中的表达。例如,可以使用特定的密码子通过宿主合成本文实施方式的核苷酸以提高表达。用于转化适于在体内进行本文实施方式的方法的宿主生物体或细胞的另一重要工具是表达载体,其包含根据本文实施方式的任一实施方式所述的核酸。因此,本文还提供此种载体。如下文进一步披露的,本文提供的表达载体可以被用在用于制备遗传转化的宿主生物体和/或细胞的方法中,用在包藏本文实施方式的核酸的宿主生物体和/或细胞中,以及用在用于制备具有补身醇合酶活性的多肽的方法中。经转化以包藏本文实施方式的至少一种核酸以便异源表达或过表达本文实施方式的至少一种多肽的重组非人宿主生物体和细胞,也是实施本文实施方式的方法的非常有用的工具。因此,本文提供此种非人宿主生物体和细胞。根据任一上述实施方式所述的核酸可以被用来转化非人宿主生物体和细胞,并且所表达的多肽可以是任何上述的多肽。本文实施方式的非人宿主生物体可以是任何非人多细胞或单细胞生物体。在特定的实施方式中,所述非人宿主生物体是植物、原核生物或真菌。任何植物、原核生物或真菌均适于根据本文所述的方法进行转化。特别有用的植物是天然生产高量萜烯的那些植物。在更特别的实施方式中,所述非人宿主生物体是微生物。任何微生物均适合于在本文中使用,但根据甚至更特别的实施方式,所述微生物是细菌或酵母。更特别地,所述细菌是大肠杆菌且所述酵母是酿酒酵母。除了完整的生物体之外,分离的更高等的真核细胞也可被转化。作为更高等的真核细胞,我们在此指的是除酵母细胞之外的任何非人真核细胞。特别的更高等的真核细胞是植物细胞或真菌细胞。通过附接共价或非共价连接到多肽主链的修饰基团,变体也可以不同于本文实施方式的多肽。通过引入N-连接的或O-连接的糖基化位点、和/或添加半胱氨酸残基,所述变体还包括与本文所述的多肽不同的多肽。本领域技术人员能够了解如何修饰氨基酸序列并保留生物活性。可以使用各种方法确定任何补身醇合酶蛋白、变体或片段的功能性或活性。例如,在植物、细菌或酵母细胞中瞬时或稳定的过表达可以被用来测试蛋白是否具有活性,即从FPP前体生产补身醇。可以在指示功能性的微生物表达系统(诸如本文实施例2或3中描述的对补身醇生产的检测)来评估补身醇合酶活性。本文实施方式的补身醇合酶多肽的变体或衍生物保留了从FPP前体生产补身醇的能力。本文提供的补身醇合酶的氨基酸序列变体可以具有附加期望的生物学功能,包括例如改变的底物利用、反应动力学、产品分布或其它改变。本文的实施方式提供本文实施方式的多肽,其被用于生产补身醇的方法中,该方法在体外或体内使FPP前体与本文实施方式的多肽接触。本文还提供一种分离的重组或合成多核苷酸,其编码本文提供的多肽或变体多肽。本文实施方式的一个实施方式提供一种分离的重组或合成核酸序列SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15或其变体,其编码具有氨基酸序列的补身醇合酶,该氨基酸序列与从由SEQIDNO:2、SEQIDNO:5、SEQIDNO:8、SEQIDNO:11或SEQIDNO:14或其片段组成的组中选择的氨基酸序列具有至少70%、75%、80%、85%、90%、92%、95%、96%、97%、98%或99%的同一性,该补身醇合酶在细胞中催化从FPP前体生产补身醇。本文提供的实施方式包括但不限于cDNA、基因组DNA和RNA序列。在本文中,将编码补身醇合酶或其变体的任何核酸序列称为补身醇合酶编码序列。根据一个特定的实施方式,SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15SEQ的核酸是编码如实施例中所述获得的补身醇合酶的补身醇合酸基因的编码序列。SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15的多核苷酸的片段是指特别地为本文实施方式的多核苷酸的至少15bp、至少30bp、至少40bp、至少50bp和/或至少60bp长度的连续核苷酸。特别地,多核苷酸的片段包含本文实施方式的多核苷酸的至少25、更特别地至少50、更特别地至少75、更特别地至少100、更特别地至少150、更特别地至少200、更特别地至少300、更特别地至少400、更特别地至少500、更特别地至少600、更特别地至少700、更特别地至少800、更特别地至少900、更特别地至少1000个连续核苷酸。不受限制的,本文的多核苷酸的片段可以被用作PCR引物和/或用作探针、或用于反义基因沉默或RNAi。本领域技术人员清楚的是,基因(包括本文实施方式的多核苷酸)可以通过本领域已知的方法基于可获得的核苷酸序列信息(诸如在所附的序列表中发现的信息)进行克隆。这些包括例如表示此种基因的侧翼序列的DNA引物的设计,所述基因的一种是在有义取向上产生的并且初始化有义链的合成,而另一种以反向互补的方式创造并且产生反义链。诸如在聚合酶链反应中使用的那些热稳定的DNA聚合酶通常被用来进行此种实验。替代地,表示基因的DNA序列可以被化学合成并且随后导入到DNA载体分子中,所述DNA载体分子可以通过例如相容性细菌(诸如大肠杆菌)来繁殖。在一个本文实施方式的相关实施方式中,提供了PCR引物和/或用于检测编码补身醇合酶的核酸序列的探针。本领域技术人员将能够了解,基于SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15合成简并的或特定的PCR引物对的方法,所述PCR引物对用以扩增编码补身醇合酶或其片段的核酸序列。用于编码补身醇合酶的核酸序列的检测试剂盒可以包括特异于编码补身醇合酶的核酸序列的引物和/或探针,以及使用所述引物和/或探针在样品中检测编码补身醇合酶的核酸序列的相关协议。此种检测试剂盒可以被用来检测植物是否已被改造,即使用编码补身醇合酶的序列转化。本文提供通过NO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15的突变获得的核酸序列,此种突变可以常规地进行。本领域技术人员清楚的是,可以向SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15的DNA序列中导入一个或多个核苷酸的突变、缺失、插入和/或取代。通常,突变是基因的DNA序列的改变,其能够改变所生产的多肽的氨基酸序列。为了测试根据本文实施方式所述的变体DNA序列的功能,目标序列被可操作地连接到选择性或筛选性标记基因,并且在使用原生质体的瞬时表达分析中或在稳定转化的植物中测试报告基因的表达。本领域技术人员能够理解,能够推动表达的DNA序列被构建为模块。因此,来自较短DNA片段的表达水平可能不同于来自最长片段的表达水平,并且可能彼此不同。本文还提供了编码补身醇合酶蛋白的核酸序列的功能性等同物,即在严格条件下杂交到SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15的核酸序列的核苷酸序列。本领域技术人员能够想到用于识别其它生物体中同源序列的方法以及用于确定同源序列之间的序列同一性百分比的方法(在本文的定义部分识别)。然后可以对此种新识别的DNA分子进行测序并且可以将所述序列与SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15的核酸序列进行比较,并且测试功能等同性。本文提供的是与SEQIDNO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15的核苷酸序列具有至少70%、特别是75%、特别是80%、特别是85%、特别是90%、特别是95%、特别是96%特别是97%、特别是98%、或更特别是99%或更高序列同一性的DNA分子。相关实施方式提供与根据SEQIDNO:1或SEQIDNO:3所述的核酸序列互补的核酸序列(诸如抑制性RNA),或者在严格条件下杂交到根据NO:1、SEQIDNO:3、SEQIDNO:4、SEQIDNO:6、SEQIDNO:7、SEQIDNO:9、SEQIDNO:10、SEQIDNO:12、SEQIDNO:13或SEQIDNO:15所述的核苷酸序列的至少一部分的核酸序列。本文提供的替代实施方式提供一种改变宿主细胞中基因表达的方法。例如,在某些背景下(例如,在昆虫叮咬或蛰伤之后或在暴露于一定的温度下),在宿主细胞或宿主生物体中可以增强或过表达或诱导本文实施方式的多核苷酸。本文提供的多核苷酸的表达的改变还会产生“异位表达”,其在改变的以及在对照或野生型生物体中是一种不同的表达模式。表达的改变是由本文实施方式的多肽与外源性或内源性调节剂的相互作用而发生的或者是由于多肽的化学修饰导致的。所述术语还指本文实施方式的多核苷酸的改变的表达模式,其被改变至低于检测水平或者完全被抑制活性。在一个实施方式中,在单一宿主中共同表达多种补身醇合酶编码核酸序列,特别地在不同启动子的控制下进行。替代地,在单个转化载体上可以存在多种补身醇合酶蛋白编码核酸序列,或者可以同时使用单独的载体进行共转化并且选择包含两个嵌合基因的转化体。类似地,在单一植物中可以与其它嵌合基因(例如编码增强虫害抗性等的其它蛋白的嵌合基因等)一起表达一种或多种补身醇合酶编码基因。本文实施方式的编码补身醇合酶的核酸序列可以被插入到表达载体中和/或被包含在插入到表达载体中的嵌合基因中,以便在宿主细胞或宿主生物体中生产补身醇合酶蛋白。用于将转基因插入到宿主细胞的基因组中的载体在本领域中是众所周知的,并且包括质粒、病毒、粘粒和人工染色体。其中插入了嵌合基因的二元或共整合载体也被用来转化宿主细胞。本文提供的实施方式提供重组表达载体,其包含补身醇合酶基因的核酸序列、或可操作地连接到缔合核酸序列(诸如例如启动子序列)的包含补身醇合酶基因的核酸序列的嵌合基因。例如,包含SEQIDNO:1或SEQIDNO:3的核酸序列的嵌合基因可以被可操作地连接到适合于在植物细胞、细菌细胞或真菌细胞中表达的启动子序列,任选地被可操作地连接到3’非翻译的核酸序列。替代地,启动子序列可以已经存在于载体中,以便要被转录的核酸序列被插入到该启动子序列的载体下游。载体通常被工程化以具有复制起点、多克隆位点和选择性标记物。下列实施例仅是说明性的并且不旨在限制本文提供的实施方式或权利要求的范围。实施例实施例1胡椒莓和辛酸八角木植物材料和叶转录组测序辛酸八角木和胡椒莓植物获自BluebellNursery(Leicestershire,UK)。为了分析萜烯分子的组成,采集叶子并且使用MTBE(甲基叔丁基醚)进行溶剂提取。使用连接到Agilent5975质量检测器的Agilent6890SeriesGC系统通过GCMS分析提取物。GC配备有0.25mm内径×30mDB-1ms毛细管柱(Agilent)。载气是1mL/min恒定流量的He。初始烘箱温度为50℃(保持1min),随后以10℃/min的梯度升温至300℃。在设定在260℃的分流/不分流进样器中并且以不分流模式进行进样。产品的鉴定基于质谱和保留指数的比较,使用真实标准和内部质谱数据库。两种植物的叶子中含有显著量的补身烷倍半萜化合物,包括(-)-补身醇,水蓼二醛(polygodial)和表水蓼二醛(图1)。因此,将辛酸八角木和胡椒莓的小叶用于转录组分析。使用ConcertTM植物RNA试剂(Invitrogen)提取总RNA。使用Illumina总RNA-测序技术和IlluminaHiSeq2000测序仪处理这种总RNA。辛酸八解木和胡椒莓各自总共产生101和105百万个2x100bp配对读出物。使用Velvet从头基因组装配仪(http://www.ebi.ac.uk/~zerbino/velvet/)和Oases软件(http://www.ebi.ac.uk/~zerbino/oases/)装配所述读出物。对于辛酸八角木,装配了平均尺寸为1’080bp的40’586个重叠群(contigs),而对于胡椒莓,获得平均尺寸为1’179bp的28’255个重叠群。使用tBlastn算法(Altschuletal,J.Mol.Biol.215,403-410,1990)并且使用已知倍半萜合酶的氨基酸序列作为查询检索所述重叠群。这一途径提供37个新的假定倍半萜合酶的序列。如在下列显示出补身醇合酶活性的合酶的实施例中所述的,评价这些合酶的酶活性。实施例2.来自胡椒莓的DlTps589的功能性表达和表征在选定的倍半萜合酶DlTps589的DNA序列进行密码子优化、进行体外合成并且克隆在pJ444-SR表达质料中(DNA2.0,MenloPark,CA,USA)。在KRX大肠杆菌细胞(Promega)中进行DlTps589合酶的异源表达。将使用pJ444SR-DlTps589表达质料转化的细胞的单个群落用来培育5mlLB培养基。在37℃培育5至6个小时之后,将培养物转移到20℃培育箱,放置1小时进行平衡。然后,通过添加1mMIPTG和0.2%L-鼠李糖诱导蛋白的表达,并且将培养物在20℃下培育过夜。次日,通过离心收集细胞,重悬浮于0.1体积50mMMOPSOpH7、10%甘油中并通过超声处理裂解。通过离心使提取物澄清(在20,000g下30min),并且将含有溶解性蛋白的上清液用于进一步实验。将含有重组蛋白的粗制大肠杆菌蛋白用于酶活性的表征。在80μM法呢基二磷酸酯(FPP,Sigma)和0.1~0.5mg粗制蛋白的存在下,在2mL50mMMOPSOpH7、10%甘油、1mMDTT、15mMMgCl2中进行检测。在30℃下将试管培育12至24小时,并且使用一体积戊烷提取两次。在氮气流下浓缩后,通过GC和GC-MS分析提取物并且与使用对照蛋白进行的检测的提取物进行比较。如实施例1中描述的GCMS进行由酶形成的产物的分析。在相同条件下使用空pJ444质粒转化的大肠杆菌进行阴性对照。在这些条件下,DlTps589重组酶以超过98%的选择性生产作为主要产物的(-)-补身醇(图2)。通过匹配分离自西方檀香油(香脂檀,Amyrisbalsamifera)的真实补身醇标准的质谱和保留时间来确认(-)-补身醇的身份。实施例3.使用DlTps589在大肠杆菌细胞中体内生产(-)-补身醇为了评价(-)-补身醇在异源细胞中的体内生产,使用pJ444SR-DlTps589表达质粒转化大肠杆菌细胞,并且评价从内源FPP库对倍半萜的生产。为了提高细胞的生产力,在同一细胞中还表达异源FPP合酶和来自完整异源甲羟戊酸(MVA)路径的酶。在专利WO2013064411中或在Schalketal(2013)J.Am.Chem.Soc.134,18900-18903中描述了含有FPP合酶基因和用于完整MVA路径的基因的表达质粒的构建。简要地,制备了含有由编码用于完整甲羟戊酸路径的酶的基因组成的两个操纵子的表达质粒。在体外合成(DNA2.0,MenloPark,CA,USA)由大肠杆菌乙酰乙酰基-CoA硫解酶(atoB)、金黄色葡萄球菌HMG-CoA合酶(mvaS)、金黄色葡萄球菌HMG-CoA还原酶(mvaA)和酿酒酵母FPP合酶(ERG20)基因组成的第一合成操纵子,并且连接到NcoI-BamHI消化的pACYCDuet-1载体(Invitrogen)中,得到pACYC-29258。从肺炎链球菌(ATCCBAA-334)的基因组DNA扩增含有甲羟戊酸激酶(MvaK1)、磷酸甲羟戊酸激酶(MvaK2)、甲羟戊酸二磷酸脱羧酶(MvaD)和异戊烯二磷酸异构酶(idi)的第二操纵子,并且连接到pACYC-29258的多克隆位点,提供质粒pACYC-29258-4506。因此,这种质粒含有编码从乙酰辅酶A导向FPP的生物合成路径的所有酶的基因。使用质粒pACYC-29258-4506和质粒pJ444SR-DlTps589共转化KRX大肠杆菌细胞(Promega)。在羧苄青霉素(50μg/ml)和氯霉素(34μg/ml)LB-琼脂糖板板上选择经转化的细胞。将单个菌落用来接种5mL补充有相同抗生素的液体LB培养基。将培养物在37℃下培育过夜。次日,使用0.2mL所述过夜培养物接种2mL补充有相同抗生素的TB培养基。在37℃下培育6小时之后,将培养物冷却至28℃并且向每个试管中加入0.1mMIPTG和0.2%鼠李糖。在28℃下将培养物培育48小时。然后,使用2体积MTBE将培养物提取两次,将有机相浓缩至500μL并且如上实施例1中所述的通过GC-MS进行分析。在这种体内条件下,DlTps589重组酶以与在实施例2中描述的体外测定中相同的表观选择性生产作为主要产物的(-)-补身醇(图3)。使用这些工程化的大肠杆菌细胞,使用更大量的(1L)培养物来纯化充分量的由酶产生的倍半萜,以通过NMR分析和比旋度测量确认所述结构是图4中示出的(-)-补身醇的结构。在配备有ChiraSil柱(Agilent)的VarianCP-3800GC系统上使用3.0℃/min的烘箱梯度温度从125℃升温至180℃,通过手性GC分析确认对映体纯度(图5)。实施例4.来自辛酸八角木的SCH51-3228-9和SCH51-3228-11的功能性表达和表征SCH51-3228-9和SCH51-3228-11是推定编码倍半萜合酶的两种其它的DNA序列并且分离自辛酸八角木的转录组序列。所推导出的氨基酸序列分别与DlTps589氨基酸序列共享有92.6%和95.1%的同一性。这两个序列是密码子优化的和在体外合成的(Invitrogen)并且克隆在pETDuet-1(Novagen)表达质粒(Invitrogen)的NdeI和KpnI限制性酶识别位点之间。SCH51-3228-9和SCH51-3228-11合酶的异源表达在BL21(DE3)大肠杆菌细胞(Invitrogen)中进行。如实施例2中所述的,将使用pETDuet-SCH51-3228-9或thepEDTDuet-SCH51-3228-11表达质粒转化的单个菌落用来生产重组酶。如实施例2中所描述的,将含有重组蛋白的粗制大肠杆菌蛋白提取物用于酶活性的表征,不同之处不在于如下进行GCMS分析条件。在连接到Agilent5975质量检测器的Agilent6890SeriesGC系统上进行GCMS分析。GC配备有0.25mm内径x30mDB-1ms毛细管柱(Agilent)。载气为1mL/min恒定流速的He。初始烘箱温度为50℃(保持5min),随后以5℃/min的梯度升温至300℃。在250℃在分流模式下以5:1的分流比进行进样。所述两种重组酶以高选择性生产作为主要产物的(-)-补身醇。通过匹配分离自西方檀香油(香脂檀)的真实补身醇标准的质谱和保留时间确认了(-)-补身醇的身份(图6)。使用实施例3中描述的整个大肠杆菌细胞系统和方法(不同之处在于GCMS分析条件为如上所述),使用SCH51-3228-9和SCH51-3228-11重组蛋白也能够在细菌中体内生产补身醇(图7)。实施例5.来自辛酸八角木的SCH51-998-28和来自胡椒莓的SCH52-13163-6的功能性表达和表征类似于实施例4,将两个cDNASCH51-998-28和SCH52-13163-6进行优化并且克隆到pETDuet表达质粒中。如实施例2和实施例4所述,在BL21(DE3)大肠杆菌细胞(Invitrogen)中生产重组蛋白并且使用FPP作为底物进行体外测定。这些测定显示了SCH51-998-28和SCH52-13163-6的补身醇合酶活性(图6)。使用从重组甲羟戊酸路径(实施例2和4)过度生产FPP的大肠杆菌细胞,使用SCH51-998-28和SCH52-13163-6蛋白也可以在体内生产补身醇(图7)。实施例6.来自辛辣木物种的补身醇合酶的序列比较使用ClustalW多重比对程序(Thompsonetal,1994,NucleicAcidRes.22(22),4673-4680)将来自辛酸八角木和胡椒莓的补身醇合酶的氨基酸序列进行比较,并且基于这些对比计算序列同一性。来自辛辣木物种的不同补身醇合酶之间的百分比同一性(%):DlTps589SCH51‐3228‐11SCH51‐3228‐9SCH51‐998‐28SCH52‐13163‐6DlTps589ID95.192.670.588SCH51_3228_1195.1ID97.170.687.6SCH51_3228_992.697ID7190.1SCH51_998_2870.570.60.71ID72.5SCH52_13163_68887.690.172.5ID-序列表-SEQIDNO.:1SCH52-ctg589,来自胡椒莓的ClTps589的开放阅读框,野生型DNA序列。ATGGATCTTATTAATCCCTCCCCAGCGGCTTCCACCCTCCCTCTCCCAGTTGATGGAGATTCAGAAGTTGTTAGGCGATCTGCCGGGTTTCATCCGACTATCTGGGGCGATCACTTCCTCTCCTACAAGCCCGATCCAAAGAAAATAGATGCATGGAATAAAAGGGTTGAAGAGCTGAAGGAAGAAGTGAAGAAGATATTAAGCAATGCAAAAGGGACGGTGGAAGAGCTGAATTTGATTGATGATCTCGTACACCTTGGGATTAGTTATCATTTTGAGAAGGAGATTGATGATGCTCTACAACACATCTTTGATACCCATCTTGATGATTTTCCTAAGGATGATCTATATGTCGCCGCTCTCCGATTTGGCGTCTTAAGGAAACAGGGGCACCGTGTTTCTCCAGATGTATTCAAAAAATTCAAAGATGAGCAGGGGAATTTCAAGGCAGAGTTGAGCACCGATGCGAAAGGTTTGCTATGTTTAAATGATGTGGCTTATCTCAGCACAAGAGGGGAAGATATCTTGGATGAAGCCATTCCTTTCACTGAGGAGCACCTTAGGTCTTGTATTAGCCATGTAGATTCTCATATGGCAGCAAAAATTGAACATTCTCTCGAGCTTCCCCTTCATCATCGCATACCAAGGCTAGAGAACAGGCACTACATCTCAGTCTATGAAGGAGACAAGGAAAGGAACGAAGTTGTCCTTGAGCTTGCCAATTTAGATTTCAATCTGATTCAAATCTTGCACCAAAGAGAGCTGAGAGACATCACAATGTGGTGGAAGGAGATTGACCTTGCAGCAAAGCTGCCTTTTATTAGGGATAGGTTGGTGGAGTGCTACTACTGGATCATGGGGGTCTATTTTGAACCAATATACTCGAGGGCTAGGGTTTTTTCCACCAAAATGACAATGTTGGTCTCAGTTGTGGACGACATATATGATGTGTATGCTACCGAGGATGAGCTTCAACTATTCACTGATGCCATCTATAGGTGGGATGCTGATGACATTGATCAGCTGCCTCAGTACTTGAAAGATGCTTTTATGGTACTCTACAACACTGTGAAGACTCTAGAAGAAGAACTTGAACCAGAAGGAAACTCTTATCGTGGATTCTATGTAAAAGATGCAATGAAGGTTTTGGCAAGGGATTACTTTGTGGAGCACAAATGGTATAACAGAAAAATTGTGCCATCCGTAGAGGAATACTTGAAAATTTCTTGCATCAGTGTGGCCGTTCATATGGCTACAGTTCACTGTATTGCTGGGATGTATGAAATTGCAACCAAAGAGGCATTCGAATGGTTGATGACTGAGCCCAAACTTGTTATTGATGCATCTCTGATTGGTCGTCTCCTTGATGACATGCAGTCCACCTCGTTTGAGCAACAGAGAGGCCACGTGTCATCAGCAGTACAGTGTTACATGGCTGAATATGGTGTAACAGCGGAAGAAGCATGTGAAAAGCTCCGAGATATGGCTGCAATTGCTTGGAAAGATGTGAACGAGGCATGCCTTAGGCCCACGGTTTTCCCTATGCCTATCCTTTTGCCTTCTATCAACTTGGCACGTGTGGCAGAAGTCATCTACCTACGTGGAGATGGATACACGCACGCTGGGGGTGAGACCAAGAAACACATCACGGCCATGCTTGTTAAGCCAATTGAAGTCTGASEQIDNO.:2来自胡椒莓的ClTps589,氨基酸序列.MDLINPSPAASTLPLPVDGDSEVVRRSAGFHPTIWGDHFLSYKPDPKKIDAWNKRVEELKEEVKKILSNAKGTVEELNLIDDLVHLGISYHFEKEIDDALQHIFDTHLDDFPKDDLYVAALRFGVLRKQGHRVSPDVFKKFKDEQGNFKAELSTDAKGLLCLNDVAYLSTRGEDILDEAIPFTEEHLRSCISHVDSHMAAKIEHSLELPLHHRIPRLENRHYISVYEGDKERNEVVLELANLDFNLIQILHQRELRDITMWWKEIDLAAKLPFIRDRLVECYYWIMGVYFEPIYSRARVFSTKMTMLVSVVDDIYDVYATEDELQLFTDAIYRWDADDIDQLPQYLKDAFMVLYNTVKTLEEELEPEGNSYRGFYVKDAMKVLARDYFVEHKWYNRKIVPSVEEYLKISCISVAVHMATVHCIAGMYEIATKEAFEWLMTEPKLVIDASLIGRLLDDMQSTSFEQQRGHVSSAVQCYMAEYGVTAEEACEKLRDMAAIAWKDVNEACLRPTVFPMPILLPSINLARVAEVIYLRGDGYTHAGGETKKHITAMLVKPIEVSEQIDNO.:3DlTps589_opt,来自胡椒莓的DlTps589的密码子优化的DNA序列。ATGGACCTGATTAACCCGAGCCCTGCTGCATCCACCCTGCCACTGCCAGTCGATGGTGATAGCGAAGTTGTGCGCCGTAGCGCGGGTTTCCATCCGACCATCTGGGGTGACCACTTTCTGTCTTATAAGCCGGACCCGAAAAAGATTGATGCGTGGAACAAGCGTGTTGAGGAACTGAAAGAAGAGGTCAAAAAGATTTTGAGCAATGCGAAAGGCACGGTTGAGGAACTGAATTTGATTGACGACCTGGTACACCTGGGTATTAGCTATCACTTTGAGAAAGAAATCGACGACGCGCTGCAGCATATCTTCGATACGCACCTGGATGATTTCCCGAAAGATGACCTCTACGTGGCTGCGCTGCGTTTTGGCGTCCTGCGTAAGCAAGGCCATCGTGTCAGCCCGGACGTCTTTAAGAAATTCAAAGACGAGCAAGGCAACTTCAAAGCGGAGCTGTCAACCGATGCAAAGGGCCTGTTGTGCCTGAACGATGTGGCGTACCTGAGCACCCGTGGTGAGGATATCCTGGACGAAGCGATCCCGTTCACGGAAGAACATTTGCGCTCGTGCATTAGCCACGTTGATAGCCACATGGCAGCGAAGATTGAGCACTCTCTGGAGCTGCCGCTGCACCATCGCATTCCGCGTTTAGAGAATCGCCATTACATCTCCGTGTACGAGGGTGACAAAGAGCGTAATGAAGTCGTTCTGGAGTTGGCTAACTTGGACTTTAATCTTATCCAGATCCTGCACCAGCGCGAGCTGCGCGACATCACGATGTGGTGGAAAGAAATTGATCTGGCCGCAAAGCTGCCGTTTATTCGTGACCGTCTGGTGGAGTGTTACTATTGGATTATGGGCGTGTACTTCGAGCCGATCTACAGCCGTGCGCGCGTGTTTAGCACCAAGATGACCATGCTGGTTAGCGTGGTGGATGACATCTATGATGTCTACGCTACGGAAGATGAGTTGCAGCTGTTTACCGACGCCATTTACAGATGGGACGCCGATGACATTGATCAACTGCCGCAATATCTGAAAGACGCCTTTATGGTTCTGTACAACACCGTCAAAACCCTGGAAGAAGAACTGGAGCCGGAAGGTAACTCTTATCGTGGTTTCTACGTTAAAGATGCGATGAAAGTTCTGGCGCGTGACTATTTCGTTGAGCATAAGTGGTACAATCGTAAGATCGTCCCGTCCGTTGAAGAGTACTTGAAGATTAGCTGTATCAGCGTCGCAGTCCACATGGCGACCGTGCACTGTATCGCCGGCATGTATGAGATCGCCACGAAAGAAGCATTCGAGTGGCTGATGACCGAGCCGAAACTGGTGATTGACGCAAGCCTGATTGGTCGCCTGCTGGACGATATGCAGAGCACGAGCTTTGAGCAGCAGCGCGGTCATGTTAGCTCCGCAGTTCAATGCTACATGGCTGAGTACGGTGTGACTGCCGAAGAAGCATGCGAGAAGCTGCGTGATATGGCGGCCATTGCGTGGAAAGATGTGAATGAAGCATGCCTGCGCCCGACCGTTTTCCCGATGCCGATTTTACTGCCTAGCATCAACCTGGCACGTGTGGCGGAAGTTATCTATCTGCGTGGCGACGGTTATACGCACGCGGGTGGTGAGACTAAGAAGCACATCACCGCGATGCTGGTCAAGCCGATCGAAGTGTAASEQIDNO.:4来自辛酸八角木的SCH51-3228-9,开放阅读框,野生型DNA序列。ATGGCTTCCACCCTCCCTCTCCCAGCTTATGGAGATTCAGAAGTTGTTAGGCGATCTGCCGGGTTTCATCCGACGATCTGGGGCGATCACTTCCTCTCCTACAAGCCTGATCCAACGAAAATAGATGAATGGAATAAAAGGGTTGAAGAGCTGAAGGAAGAAGTGAAGAAGATATTAAGCAATGCAAAAGGGACAGTGGAAGAGCTGAATTTGCTTGATGATCTCGTACACCTTGGGATTAGTTATCATTTTGAGAAGGAGATTGATGATGCTTTACAACAAATCTTTGATACCCATCTTGATGTTTTTCCTAAGGATGATCTATATGCCACCGCTCTCCGATTTGGCGTCTTAAGGAAACAGGGGCACCGTGTTTCTCCAGATGTATTCAAAAAATTCAAAGATGAGCAGGGGAATTTCAAGGCAGAGTTGAGCACCGATGCGAAGGGTTTGCTATGTTTATATGATGTGGCTTATCTCAGCACAAGAGGGGAAGATATCTTGGATGAAGCCATTCCTTTCACTAAGGAGCACCTTAGGTCTTGTATTAGCCATGTCGATTCTCATATGGCAGCAAAAATTGAGCATTCTCTAGAGCTTCCCCTTCATCATCGCATACCAAGGCTAGAGAACAGGCACTACATCTCAGTCTATGAAGGAGACAAGGAAAGGAATGAAGTTGTCCTTGAGCTTGCCAAATTAGATTTCAATCTGATTCAAATCTTGCACCAAAGAGAGCTGAGGGACATCACAACGTGGTGGAAGGAGATTGACCTTGCAGCAAAGCTACCTTTTATTAGGGATAGGTTGGTGGAGTGCTACTATTGGATCATGGGAGTCTATTTTGAACCAATATACTCAAGGGCTAGAGTTTTTTCGACCAAAATGACAATCTTGGTCTCAGTTGTGGACGACATATATGATGTATATGCTACAGAGGATGAGCTCCAACTTTTCACTGATGCAATCTATAGGTGGGATGCTGAGGACATTGAGCAGCTTCCACAGTACTTGAAAGATGCTTTTCTTGTACTCTATAACACTGTGAAGGACCTAGAAGAGGAATTGGAACCAGAAGGAAACTCTTATCGTGGATACTATGTAAAAGATGCGATGAAGGTTTTGGCAAGGGATTACTTTGTGGAGCACAAATGGTATAACAGAAAAATTGTGCCATCAGTAGAGGACTACCTGCGAATTTCTTGCATTAGTGTTGCCGTTCATATGGCCACAGTTCATTGTATTGCTGGGATGTATGAAATTGCAACCAAAGAGGCATTCGAATGGTTGAAGACGGAACCTAAACTTGTTATAGATGCATCACTGATTGGGCGTCTCCTCGATGACATGCAGTCCACCTCGTTTGAGCAACAGAGAGGTCATGTGTCATCAGCGGTACAGTGTTACATGATCCAATATGGGGTATCACACGAAGAAGCGTGTGAGAAGTTGCGAGAAATGGCTGCAATTGCGTGGAAAGATGTAAACCAAGCATGCCTTAGGCCCACTGTTTTCCCTATGCCTATTCTTCTGCCCTCCATCAACCTTGCACGTGTGGCAGAAGTGATTTACCTACGCGGAGATGGATATACACATGCGGGTGGTGAGACCAAAAAACATATCACGGCCATGCTTGTTGATCCAATCAAAGTCTGASEQIDNO.:5来自辛酸八角木的SCH51-3228-9,氨基酸序列。MASTLPLPAYGDSEVVRRSAGFHPTIWGDHFLSYKPDPTKIDEWNKRVEELKEEVKKILSNAKGTVEELNLLDDLVHLGISYHFEKEIDDALQQIFDTHLDVFPKDDLYATALRFGVLRKQGHRVSPDVFKKFKDEQGNFKAELSTDAKGLLCLYDVAYLSTRGEDILDEAIPFTKEHLRSCISHVDSHMAAKIEHSLELPLHHRIPRLENRHYISVYEGDKERNEVVLELAKLDFNLIQILHQRELRDITTWWKEIDLAAKLPFIRDRLVECYYWIMGVYFEPIYSRARVFSTKMTILVSVVDDIYDVYATEDELQLFTDAIYRWDAEDIEQLPQYLKDAFLVLYNTVKDLEEELEPEGNSYRGYYVKDAMKVLARDYFVEHKWYNRKIVPSVEDYLRISCISVAVHMATVHCCAGMDEIATKEAFEWLKTEPKLVIDASLIGRLLDDMQSTSFEQQRGHVSSAVQCYMIQYGVSHEEACEKLREMAAIAWKDVNQACLRPTVFPMPILLPSINLARVAEVIYLRGDGYTHAGGETKKHITAMLVDPIKVSEQIDNO.:6SCH51-3228-9_opt,SCH51-3228-9的密码子优化的DNA序列。ATGGCAAGCACCCTGCCGCTGCCTGCCTATGGTGATAGCGAAGTTGTTCGTCGTAGCGCAGGTTTTCATCCGACCATTTGGGGTGATCATTTTCTGAGCTATAAACCGGATCCGACCAAAATTGATGAATGGAATAAACGTGTCGAAGAACTGAAAGAAGAAGTGAAAAAAATCCTGAGCAATGCCAAAGGCACCGTTGAGGAACTGAATCTGCTGGATGATCTGGTTCATCTGGGTATCAGCTATCACTTTGAGAAAGAAATCGATGATGCACTGCAGCAGATTTTTGATACCCATCTGGATGTTTTCCCGAAAGATGATCTGTATGCAACCGCACTGCGTTTTGGTGTTCTGCGTAAACAGGGTCATCGTGTTAGTCCGGATGTGTTCAAAAAATTCAAAGATGAACAGGGCAACTTCAAAGCAGAACTGAGCACCGATGCAAAAGGTCTGCTGTGTCTGTATGATGTTGCATATCTGAGCACCCGTGGTGAAGATATTCTGGATGAAGCAATTCCGTTTACCAAAGAACATCTGCGTAGCTGTATTAGCCATGTTGATAGCCACATGGCAGCGAAAATTGAACATAGCCTGGAACTGCCTCTGCATCACCGTATTCCGCGTCTGGAAAATCGTCACTATATTAGCGTTTATGAGGGCGATAAAGAACGCAATGAAGTTGTGCTGGAACTGGCAAAACTGGATTTTAACCTGATTCAGATTCTGCATCAGCGTGAACTGCGTGATATTACCACCTGGTGGAAAGAAATTGATCTGGCAGCAAAACTGCCGTTTATTCGTGATCGTCTGGTTGAATGCTATTATTGGATTATGGGCGTGTATTTCGAACCGATTTATAGCCGTGCACGTGTTTTTAGCACCAAAATGACCATTCTGGTTAGCGTGGTGGATGATATCTATGATGTTTATGCCACCGAAGATGAACTGCAGCTGTTTACCGATGCCATTTATCGTTGGGATGCAGAAGATATTGAACAGCTGCCGCAGTATCTGAAAGATGCATTTCTGGTTCTGTACAACACCGTGAAAGATCTGGAAGAAGAACTGGAACCGGAAGGTAATAGCTATCGTGGTTATTATGTTAAAGATGCCATGAAAGTTCTGGCACGCGATTATTTTGTTGAGCACAAATGGTATAACCGCAAAATTGTTCCGAGCGTGGAAGATTATCTGCGTATTAGCTGCATTAGCGTTGCAGTTCACATGGCAACCGTTCATTGTTGTGCAGGTATGGATGAAATTGCAACCAAAGAAGCATTTGAGTGGCTGAAAACCGAACCGAAACTGGTTATTGATGCAAGCCTGATTGGTCGTCTGCTGGACGATATGCAGAGCACCAGCTTTGAACAGCAGCGTGGTCATGTTAGCAGCGCAGTTCAGTGTTATATGATTCAGTATGGTGTTAGCCATGAAGAAGCATGCGAAAAACTGCGCGAAATGGCAGCAATTGCATGGAAAGATGTTAATCAGGCATGTCTGCGTCCGACCGTTTTTCCGATGCCGATTCTGCTGCCGAGCATTAATCTGGCACGTGTTGCCGAAGTTATCTATCTGCGTGGTGATGGTTATACCCATGCCGGTGGTGAAACCAAAAAACATATTACCGCAATGCTGGTCGATCCGATTAAAGTTTAASEQIDNO.:7来自辛酸八角木的SCH51-3228-11,开放阅读框,野生型DNA序列。ATGGCTTCCACCCTCCCTCTCCCAGCTTATGGAGATTCAGAAGTTGTTAGGCGATCTGCCGGGTTTCATCCGACGATCTGGGGCGATCACTTCCTCTCCTACAAGCCTGATCCAACGAAAATAGATGAATGGAATAAAAGGGTTGAAGAGCTGAAGGAAGAAGTGAAGAAGATATTAAGCAATGCAAAAGGGACAGTGGAAGAGCTGAATTTGCTTGATGATCTCGTACACCTTGGGATTAGTTATCATTTTGAGAAGGAGATTGATGATGCTTTACAACAAATCTTTGATACCCATCTTGATGTTTTTCCTAAGGATGATCTATATGCCACCGCTCTCCGATTTGGCGTCTTAAGGAAACAGGGGCACCGTGTTTCTCCAGATGTATTCAAAAAATTCAAAGATGAGCAGGGGAATTTCAAGGCAGAGTTGAGCACCGATGCGAAGGGTTTGCTATGTTTATATGATGTGGCTTATCTCAGCACAAGAGGGGAAGATATCTTGGATGAAGCCATTCCTTTCACTAAGGAGCACCTTAGGTCTTGTATTAGCCATGTCGATTCTCATATGGCAGCAAAAATTGAGCATTCTCTAGAGCTTCCCCTTCATCATCGCATACCAAGGCTAGAGAACAGGCACTACATCTCAGTCTATGAAGGAGACAAGGAAAGGAATGAAGTTGTCCTTGAGCTTGCCAAATTAGATTTCAATCTGATTCAAATCTTGCACCAAAGAGAGCTGAGGGACATCACAATGTGGTGGAAGGAGATTGACCTTGCAGCAAAGCTACCTTTTATTAGAGATAGGTTGGTGGAGTGCTACTACTGGATCATGGGGGTCTATTTTGAACCAATATACTCCAGGGCTAGGGTTTTTTCCACTAAAATGACAATCTTGGTCTCAGTTGTGGACGACATATATGATGTCTATGCTACGGAGGATGAGCTTCAACTATTCACTGATGCAATCTATAGGTGGGATGCTGATGACATTGATCAGCTGCCTCAGTACTTGAAAGATGCTTTTATGGTACTCTATAACACTGTGAAGACTCTAGAAGAAGAACTTGAACCAGAAGGAAACTCTTATCGTGGATACTACGTAAAAGATGCAATGAAGGTTTTGGCAAGAGATTACTTTGTGGAACACAAATGGTATAACAGACAAATTGTGCCATCCGTAGAGGAATACTTGAAAATTTCTTGCATTAGTGTGGCTGTTCATATGGCTACAGTTCATTGTATTGCTGGGATGTATGAAATTGCTACCAAAGAGGCATTCGAATGGTTGAAGACTGAACCCAAACTTGTTATCGATGCATCTCTGATCGGTCGTCTTCTTGATGACATGCAGTCTACCTCGTTTGAGCAACAAAGAGGGCACGTGTCATCAGCAGTACAGTGTTACATGGCCCAATATGGAGTAACAGCAGAAGAAGCATGTGAAAAGCTACGAGAAATGGCTGCAATTGCTTGGAAAGATGTGAATGAAGCATGCCTTAGGCCCACGGTATTCCCTATGCCTATCCTCTTGCCTTCTATCAACTTGGCACGTGTGGCAGAAGTGATCTACCTACGTGGAGATGGATACACGCACGCTGGGGGTGAGACCAAAAAACACATCACGGCCATGCTTGTTAAGCCAATTGAAGTCTGASEQIDNO.:8来自辛酸八角木的SCH51-3228-11,氨基酸序列。MASTLPLPAYGDSEVVRRSAGFHPTIWGDHFLSYKPDPTKIDEWNKRVEELKEEVKKILSNAKGTVEELNLLDDLVHLGISYHFEKEIDDALQQIFDTHLDVFPKDDLYATALRFGVLRKQGHRVSPDVFKKFKDEQGNFKAELSTDAKGLLCLYDVAYLSTRGEDILDEAIPFTKEHLRSCISHVDSHMAAKIEHSLELPLHHRIPRLENRHYISVYEGDKERNEVVLELAKLDFNLIQILHQRELRDITMWWKEIDLAAKLPFIRDRLVECYYWIMGVYFEPIYSRARVFSTKMTILVSVVDDIYDVYATEDELQLFTDAIYRWDADDIDQLPQYLKDAFMVLYNTVKTLEEELEPEGNSYRGYYVKDAMKVLARDYFVEHKWYNRQIVPSVEEYLKISCISVAVHMATVHCIAGMYEIATKEAFEWLKTEPKLVIDASLIGRLLDDMQSTSFEQQRGHVSSAVQCYMAQYGVTAEEACEKLREMAAIAWKDVNEACLRPTVFPMPILLPSINLARVAEVIYLRGDGYTHAGGETKKHITAMLVKPIEVSEQIDNO.:9来自辛酸八角木的SCH51-3228-11_opt,SCH51-3228-11的密码子优化的DNA序列。ATGGCATCTACTCTTCCACTGCCGGCTTATGGTGATTCTGAGGTTGTTCGTCGTTCCGCGGGTTTTCACCCTACCATCTGGGGCGATCACTTTCTGTCCTATAAGCCAGACCCGACCAAGATTGACGAGTGGAATAAGCGTGTCGAGGAACTGAAAGAAGAAGTGAAAAAGATCCTGTCCAACGCAAAAGGTACTGTCGAGGAGCTGAATCTGCTGGATGACCTGGTGCATCTGGGCATCAGCTATCACTTCGAAAAGGAAATTGACGACGCTTTGCAGCAAATTTTTGATACGCACCTGGACGTCTTTCCGAAAGATGACCTGTATGCGACCGCGCTGCGCTTTGGTGTGCTGCGTAAACAGGGTCATCGCGTGTCTCCTGATGTGTTCAAGAAATTTAAAGATGAACAGGGCAATTTCAAGGCCGAGTTGAGCACGGACGCCAAAGGTTTGCTCTGCCTGTACGACGTTGCATATCTGAGCACCCGTGGTGAAGATATCCTGGACGAAGCGATTCCGTTCACCAAGGAACATCTGCGCTCGTGCATTTCCCATGTAGATAGCCACATGGCGGCCAAGATCGAGCACAGCCTGGAGCTGCCTTTGCACCATCGTATTCCGCGCCTGGAGAATCGCCATTACATTAGCGTCTATGAGGGTGACAAAGAGCGCAACGAAGTCGTGTTAGAGCTGGCGAAGCTGGACTTCAACCTGATTCAAATTCTGCATCAACGCGAGCTGCGCGACATTACCATGTGGTGGAAAGAGATTGATCTGGCAGCGAAGCTGCCGTTCATCCGCGATCGTCTGGTTGAGTGCTACTACTGGATCATGGGCGTCTACTTCGAGCCGATCTACAGCCGCGCTCGTGTGTTTTCGACGAAGATGACCATCCTGGTTAGCGTTGTTGATGACATTTATGACGTTTACGCGACCGAAGATGAACTGCAGCTGTTTACGGACGCAATCTACCGTTGGGACGCGGATGATATCGACCAGCTGCCGCAATACTTGAAAGATGCGTTCATGGTTTTGTACAACACCGTCAAAACGCTGGAAGAAGAACTGGAGCCGGAAGGCAACAGCTACCGTGGTTACTATGTTAAAGATGCGATGAAAGTTCTGGCGCGCGACTACTTCGTCGAGCACAAGTGGTATAACCGTCAGATTGTGCCGAGCGTCGAGGAATACCTGAAGATTAGCTGTATCAGCGTTGCCGTTCACATGGCAACGGTGCACTGCATCGCCGGTATGTACGAGATTGCGACGAAAGAAGCCTTCGAATGGTTGAAAACCGAGCCGAAGCTGGTTATCGACGCCAGCCTGATCGGTCGTTTGCTGGACGACATGCAAAGCACGAGCTTCGAGCAGCAGCGCGGCCATGTGAGCAGCGCTGTTCAGTGTTATATGGCGCAATATGGCGTGACCGCAGAAGAAGCGTGCGAGAAGCTGCGTGAGATGGCAGCAATTGCGTGGAAAGATGTGAATGAAGCCTGTCTGCGTCCGACTGTGTTTCCGATGCCGATCCTGCTGCCGAGCATTAACCTGGCGCGTGTGGCAGAGGTCATCTATCTGCGTGGTGACGGTTACACCCACGCGGGTGGCGAAACCAAGAAACATATCACCGCAATGCTGGTTAAGCCGATTGAAGTGTAASEQIDNO.:10来自辛酸八角木的SCH51-998-28,开放阅读框,野生型DNA序列。ATGGATCTTAGTACTTCACCTGTTCTTTCTTCCTCCCCCCTTCCGGTGGAAGACGGAAAAAATCCGGCCGTTCGCCGTTCAGCTGGATTTCACCCCAGTATTTGGGGTGATCATTTCCTCTCCTACACTGAAGATCACAAGAAGCTGGATGCATGGAGCGAAAGGACTCAAGTGTTGAAGGAAGAGGTGAGGAGAATTTTAATCAATGCCAAGGGGTCACTAGAAGAGTTGGATTTGTTGGATGCAATCCAACGCCTTGGGGTGAAATATCACTTTGAGAAAGAGATTGAAGAGGCATTACACCATATTTATGTTGCAGAAACTCATGTTTCTACTGATGACTTATATTCCGTTTCTCTCCGGTTTCGACTTCTTAGACAACAAGGGTACAATGTATCTGCTGATGTATTTAAAAAGTTCAAAGATGAGAGGGGCAACTTCAAGGCAAGCTTAAGTACTGATGCCAGGGGGTTGCTAAGCTTGTATGAAGCTGCATTTCTCAGCATACGAGGAGATGATATCTTAGATGAAGCCATAACTTTCACAAGAGAGCAGCTTAAGTCTTCTATGACCCATGTTGATGCCCCTCTTGCCAAACAAATAGCCCATGCCTTAGAGGTACCAGCGCACAAGCGCATACAAAGACTAGAGAACATTCGCTACCTCACAATCTACCAAGAAGAGAAAGGAAGGAATGATGTGTTGCTTGAGCTTGCCAAGTTGGATTTCAATATCTTACAACAATTGCATAAGAAAGAACTGAGAGACCTTACAAAGTGGTGGAAGGACACAGACGTTGCAGGAAAGCTACCTTTCATCAGAGATAGGTTGGTGGAATGCTATTATTGGATCTTGGGTGTGTATTATGAGCCAGAATACTCCAGAGCTAGAATTTTTTCTACCAAAATGACAATCATGGTCTCAGTTGTTGATGACATATATGACGTATATGCTACTGAAGATGAGCTCCAACTATTCACTGATGCAATCTATAGGTGGGATCTGGAGGGCCTAGATCAACTCCCACAGTTCTTGAAAGACTGTTTTCTTGTACTCTATGACACCGTCAAGGAATTAGAAGACGAACTAGAACCGGAAGGAAAATCCTATCGTGGATACTATGTAAAGGATGCGATGAAGGTTTTGGCTAGAGATTACTTCGTTGAGCACAAATGGTATAACAGAAACATAGTGCCAAGTGTAGAAGAATATCTCCGTGTTTCTTGCATCAGTGTTGCAGTCCATATGGCTAACGTCCATTGCTGTGCTGGGATGGGAGATGTAATGAGCAAAGAGGCATTCGAATGGTTGAAGAGTGAACCAAAGGTTGTAATGGATGCATCACTAATTGGCCGACTGCTCGATGACATGCAGTCCACCGAGTTTGAGCAAAAGAGAGGCCATGTTGCATCGGCTGTCCAATGTTACATGAATGAGTATGGAGTGACTTACAAAGAAGCGTGTGAAAAGCTGCATGAAATGGCTGCCCTTGCATGGAAAGACGTAAACCAGGCTTGCCTTAAACCAACTGTTTTCCCTCTCCCTGTATTTATGCCTGCAATCAACCTTGCGCGAGTGGCTGAAGTCATCTACCTTCGTGGAGATGGGTATACTCATTCAGGAGGAGAGACTAAAGAAAATATCACGTTGATGCTTGTCAATCCAATCTCTGTGTGASEQIDNO.:11来自辛酸八角木的SCH51-998-28,氨基酸序列。MDLSTSPVLSSSPLPVEDGKNPAVRRSAGFHPSIWGDHFLSYTEDHKKLDAWSERTQVLKEEVRRILINAKGSLEELDLLDAIQRLGVKYHFEKEIEEALHHIYVAETHVSTDDLYSVSLRFRLLRQQGYNVSADVFKKFKDERGNFKASLSTDARGLLSLYEAAFLSIRGDDILDEAITFTREQLKSSMTHVDAPLAKQIAHALEVPAHKRIQRLENIRYLTIYQEEKGRNDVLLELAKLDFNILQQLHKKELRDLTKWWKDTDVAGKLPFIRDRLVECYYWILGVYYEPEYSRARIFSTKMTIMVSVVDDIYDVYATEDELQLFTDAIYRWDLEGLDQLPQFLKDCFLVLYDTVKELEDELEPEGKSYRGYYVKDAMKVLARDYFVEHKWYNRNIVPSVEEYLRVSCISVAVHMANVHCCAGMGDVMSKEAFEWLKSEPKVVMDASLIGRLLDDMQSTEFEQKRGHVASAVQCYMNEYGVTYKEACEKLHEMAALAWKDVNQACLKPTVFPLPVFMPAINLARVAEVIYLRGDGYTHSGGETKENITLMLVNPISVSEQIDNO.:12来自辛酸八角木SCH51-998-28_opt,SCH51-998-28的密码子优化的DNA序列。ATGGATCTGAGCACCAGTCCGGTTCTGAGCAGCTCACCGCTGCCGGTTGAAGATGGTAAAAATCCGGCAGTTCGTCGTAGCGCAGGTTTTCATCCGAGCATTTGGGGTGATCATTTTCTGAGCTATACCGAGGATCACAAAAAACTGGATGCATGGTCAGAACGTACCCAGGTTCTGAAAGAAGAAGTGCGTCGTATTCTGATTAATGCAAAAGGTAGCCTGGAAGAACTGGATCTGCTGGATGCAATTCAGCGTCTGGGTGTTAAATATCACTTTGAGAAAGAAATCGAAGAAGCCCTGCATCATATTTATGTTGCAGAAACCCATGTGTCAACCGATGATCTGTATAGCGTTAGCCTGCGTTTTCGTCTGCTGCGTCAGCAGGGTTATAATGTTAGCGCAGATGTGTTCAAAAAATTCAAAGATGAACGCGGTAACTTCAAAGCAAGCCTGAGCACCGATGCACGTGGTCTGCTGAGCCTGTATGAAGCAGCATTTCTGAGCATTCGTGGTGATGATATTCTGGATGAAGCAATTACCTTTACCCGTGAACAGCTGAAAAGCAGCATGACCCATGTTGATGCACCGCTGGCAAAACAAATTGCACATGCACTGGAAGTTCCGGCACATAAACGTATTCAGCGCCTGGAAAATATTCGCTATCTGACCATTTACCAAGAAGAGAAAGGTCGTAACGATGTTCTGCTGGAACTGGCCAAACTGGATTTTAACATTCTGCAGCAGCTGCATAAAAAAGAACTGCGTGATCTGACCAAATGGTGGAAAGATACCGATGTTGCAGGTAAACTGCCGTTTATTCGTGATCGTCTGGTTGAATGCTATTATTGGATTCTGGGCGTTTATTATGAGCCGGAATATAGCCGTGCACGTATTTTTAGCACCAAAATGACCATTATGGTTAGCGTGGTGGATGACATCTATGATGTTTATGCAACCGAAGATGAACTGCAGCTGTTTACCGATGCAATTTATCGTTGGGATCTGGAAGGTCTGGATCAGCTGCCGCAGTTCCTGAAAGATTGTTTTCTGGTTCTGTATGATACCGTGAAAGAACTGGAAGATGAGCTGGAACCGGAAGGTAAAAGCTATCGTGGTTATTATGTTAAAGATGCCATGAAAGTTCTGGCACGCGATTATTTTGTTGAGCACAAATGGTATAACCGCAATATTGTTCCGAGCGTGGAAGAATATCTGCGTGTTAGCTGTATTAGCGTTGCAGTTCACATGGCAAATGTTCATTGTTGTGCAGGTATGGGTGATGTGATGAGCAAAGAAGCATTTGAATGGCTGAAAAGTGAACCGAAAGTTGTTATGGATGCCAGCCTGATTGGTCGCCTGCTGGACGATATGCAGAGCACCGAATTTGAACAGAAACGTGGTCATGTTGCAAGCGCAGTTCAGTGTTATATGAATGAATATGGCGTGACCTATAAAGAGGCATGCGAAAAACTGCATGAAATGGCAGCACTGGCATGGAAAGATGTTAATCAGGCATGTCTGAAACCGACCGTTTTTCCGCTGCCTGTTTTTATGCCTGCAATTAATCTGGCACGTGTTGCCGAAGTTATTTACCTGCGTGGGGATGGTTATACCCATAGCGGTGGTGAAACCAAAGAAAACATTACCCTGATGCTGGTTAATCCGATTAGCGTTTAASEQIDNO.:13来自胡椒莓的SCH52-13163-6,DNA序列。ATGGATGTTCTAATTCCCTCCCCTGTGGCTTCCACTCTCCCTCTGCCCGAAGATGGAAACTTGGACGTCGTTCGCAGATCCGCCGGGTTTCATCCGACGGTCTGGGGCGATCACTTCCTCGCTTACTCGCCCGATCCAACCAAAATAGATGCTTGGACTAAAAGAGTTGAAGAGCTGAAGCAAGAAGTGAAGAGGATTCTAAGCAATGTGAAAGGGTCACTGGAAGAGCTGAACTTGCTTGATGCTATCCAACACCTTGGGATTGGTTATCATTTTGAGAAAGAGATTGATGATGCTTTACAACTAATCTTTGATTCCCATATTGATGCTTTTCCTACTGATGATCTATATGTGGCTGCCCTCCGATTTAGCCTACTAAGGCGACAAGGGCACTGTGTTTCTTCAGATGTATTCAAAAAATTCAAAGATGAGCAGGGGAATTTCAAGGCAGAGCTGAGCACCGATGCGAAAGGTTTGCTGAGTCTCTATGACGCGGCGTATCTCAGTGTAAGAGGGGAAGATATATTGGATGAGGCCATTCCTTTCACTAGGGAGCACCTTAGGACTTGTATTAGCCATGTAGATTCTCATTTGGCAGCAAAAATTGAGCATTCTCTAGAGCTTCCCCTGCATCATCGCATACCAAGGCTAGAGAACAGGCACTACATCTCAGTGTACGAAGGAGAGAAGGAAAGGAATGAAGTTGTACTAGAGCTTGCCAAATTAGATTTCAATCTGATTCAAATCTTGCACCAAAGAGAGCTGAGGGACATCACAACGTGGTGGAATGAGATTGACCTCGCAGCAAAGCTACCATTTATTAGGGATAGGTTGGTGGAGTGCTACTATTGGATCATGGGTGTCTATTTTGAACCAATATTCTCAAGGGCTAGAGTTTTTTCGACCAAAATGACAATTTTGGTCTCAGTTGTCGACGACATATATGATGTCTACGCTACAGAGGATGAGCTCCAACTTTTCACTGACGCAATCTATAGGTGGGATGCCGAGGACATTGAGCAGCTTCCACAGTACTTGAAAGATTCTTTTCTTGTACTCTATAACACCGTGAAGGACTTAGAAGAGGAGCTGAAACCAGAAGGAAACTCATATCGTGGAGACTATGTAAAAGATGCGATGAAGGTTTTGGCAAGAGATTACTTTGTGGAGCACAAATGGTATAACAGAAAAATTGTACCGTCAGTAGAGGACTACCTACGAATTTCTTGCATTAGTGTTGCCGTTCATATGGCTACAGTTCATTGTTGTGCTGGGATGGATGAAATTGCAACCAAAGAGGCATTCGAATGGTTGAAGACCGAACCTAAACTTGTTATAGATGCATCACTGATTGGGCGTCTCCTCGATGACATGCAGTCCACCTCGTTTGAGCAACAGAGAGGTCATGTGTCATCGGCGGTACAGTGTTACATGATCCAATATGGCGTATCACACGAAGAAGCGTGTGAGAAGTTGACAGAAATGGCTGCAATTGCATGGAAAGATGTAAACCAAGCATGCCTTAGGCCCACTGTTTTCCCAATGCCTATTCTTCTGCCTTCAATCAACCTTGCACGTGTGGCAGAAGTCATCTACCTGCGCGGAGATGGATATACACATGCTGGTGGTGAGACCAAAAAACATATCACGGCCATGCTTGTTGAACCAATCCAAGTCTGASEQIDNO.:14来自胡椒莓的SCH52-13163-6,开放阅读框,野生型DNA序列。MDVLIPSPVASTLPLPEDGNLDVVRRSAGFHPTVWGDHFLAYSPDPTKIDAWTKRVEELKQEVKRILSNVKGSLEELNLLDAIQHLGIGYHFEKEIDDALQLIFDSHIDAFPTDDLYVAALRFSLLRRQGHCVSSDVFKKFKDEQGNFKAELSTDAKGLLSLYDAAYLSVRGEDILDEAIPFTREHLRTCISHVDSHLAAKIEHSLELPLHHRIPRLENRHYISVYEGEKERNEVVLELAKLDFNLIQILHQRELRDITTWWNEIDLAAKLPFIRDRLVECYYWIMGVYFEPIFSRARVFSTKMTILVSVVDDIYDVYATEDELQLFTDAIYRWDAEDIEQLPQYLKDSFLVLYNTVKDLEEELKPEGNSYRGDYVKDAMKVLARDYFVEHKWYNRKIVPSVEDYLRISCISVAVHMATVHCCAGMDEIATKEAFEWLKTEPKLVIDASLIGRLLDDMQSTSFEQQRGHVSSAVQCYMIQYGVSHEEACEKLTEMAAIAWKDVNQACLRPTVFPMPILLPSINLARVAEVIYLRGDGYTHAGGETKKHITAMLVEPIQVSEQIDNO.:15SCH52-13163-6_opt,SCH51-13163-6的密码子优化的DNA序列。ATGGATGTTCTGATTCCGAGTCCGGTTGCAAGCACCCTGCCGCTGCCGGAAGATGGTAATCTGGATGTTGTTCGTCGTAGCGCAGGTTTTCATCCGACCGTTTGGGGTGATCATTTTCTGGCATATAGTCCGGATCCGACCAAAATTGATGCATGGACCAAACGTGTTGAGGAACTGAAACAAGAAGTGAAACGTATTCTGAGCAATGTGAAAGGTAGCCTGGAAGAACTGAATCTGCTGGATGCAATTCAGCATCTGGGTATTGGTTATCACTTCGAGAAAGAAATTGATGATGCACTGCAGCTGATCTTTGATAGCCATATTGATGCCTTTCCGACCGATGATCTGTATGTTGCAGCACTGCGTTTTAGCCTGCTGCGTCGTCAGGGTCATTGTGTTAGCAGTGATGTTTTCAAAAAATTCAAAGACGAGCAGGGCAACTTTAAAGCAGAACTGAGCACCGATGCAAAAGGTCTGCTGAGCCTGTATGATGCCGCATATCTGAGCGTTCGTGGTGAAGATATTCTGGATGAAGCAATTCCGTTTACCCGTGAACATCTGCGTACCTGTATTAGCCATGTGGATAGCCATCTGGCAGCAAAAATTGAACATAGTCTGGAACTGCCTCTGCATCATCGTATTCCGCGTCTGGAAAATCGTCACTATATTAGCGTTTATGAAGGCGAAAAAGAACGCAATGAAGTTGTGCTGGAACTGGCAAAACTGGATTTTAACCTGATTCAGATTCTGCATCAGCGTGAACTGCGTGATATTACCACCTGGTGGAATGAAATTGACCTGGCAGCCAAACTGCCGTTTATTCGTGATCGTCTGGTTGAATGCTATTATTGGATTATGGGCGTGTATTTTGAACCGATTTTTAGCCGTGCACGTGTGTTTAGCACCAAAATGACCATTCTGGTTAGCGTGGTGGATGATATCTATGATGTTTATGCAACCGAAGATGAGCTGCAACTGTTTACCGATGCCATTTATCGTTGGGATGCAGAAGATATTGAACAGCTGCCTCAGTATCTGAAAGATAGCTTTCTGGTTCTGTACAACACCGTGAAAGATCTGGAAGAAGAACTGAAACCGGAAGGTAATAGCTATCGTGGTGATTATGTTAAAGACGCCATGAAAGTTCTGGCACGCGATTATTTTGTTGAGCACAAATGGTATAACCGCAAAATTGTTCCGAGCGTGGAAGATTATCTGCGTATTAGCTGCATTAGCGTTGCAGTTCACATGGCAACCGTTCATTGTTGTGCAGGTATGGATGAAATTGCAACCAAAGAAGCATTTGAGTGGCTGAAAACCGAACCGAAACTGGTTATTGATGCAAGCCTGATTGGTCGTCTGCTGGACGATATGCAGTCAACCAGCTTTGAACAGCAGCGTGGTCATGTTAGCAGCGCAGTTCAGTGTTATATGATTCAGTATGGTGTTAGCCATGAAGAAGCATGCGAAAAACTGACCGAAATGGCAGCAATTGCATGGAAAGATGTTAATCAGGCATGTCTGCGTCCGACCGTGTTTCCTATGCCGATTCTGCTGCCGAGCATTAATCTGGCACGTGTTGCCGAAGTTATCTATCTGCGTGGTGATGGTTATACCCATGCCGGTGGTGAAACCAAAAAACATATTACCGCAATGCTGGTAGAACCGATTCAGGTTTAA当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1