顺式‑5‑羟基‑L‑哌可酸的制造方法与流程
本发明涉及利用了具有生产顺式-5-羟基-l-哌可酸的能力的酶的顺式-5-羟基-l-哌可酸的制造方法。
背景技术:
顺式-5-羟基-l-哌可酸(以下有时称为“5oh-pa”)是作为药品的中间体等而有用的化合物。已知顺式-5-羟基-l-哌可酸可以利用生物学方法由l-哌可酸进行制造。
已经报道了百脉根中慢生根瘤菌(mesorhizobiumloti)maff303099来源的bab52605蛋白质、苜蓿中华根瘤菌(sinorhizobiummeliloti)1021来源的cac47686蛋白质(以下有时称为“smph”)具有将l-脯氨酸转变为顺式-4-羟基脯氨酸的能力(专利文献1)。
bab52605蛋白质虽然具有将l-哌可酸转变为顺式-5-羟基-l-哌可酸的能力,但据报道,其生产率比较低(专利文献2)。
虽然报道了cac47686蛋白质也具有将l-哌可酸转变为顺式-5-羟基-l-哌可酸的能力,但其在由l-哌可酸生产顺式-5-羟基-l-哌可酸的同时,还生产出几乎等量的顺式-3-羟基哌可酸(以下有时称为“3oh-pa”)(专利文献2)。
另外,专利文献2中报道了表达由segniliparusrugosusatccbaa-974来源的efv12517蛋白质的注释的更上游的48个碱基(相当于16个氨基酸)所表达的多核苷酸(cis基因)编码的蛋白质(以下有时称为“sruph”)的大肠杆菌具有l-哌可酸的顺式-5位羟化酶活性,能够将l-哌可酸转变为顺式-5-羟基-l-哌可酸。但是,如本说明书的实施例中所示,该蛋白质在由l-哌可酸生产顺式-5-羟基-l-哌可酸的同时,生产出约2%的顺式-3-羟基哌可酸。
专利文献3中报道了由l-哌可酸生产顺式-5-羟基-l-哌可酸的方法。在专利文献3中报道了,为了抑制不需要的顺式-3-羟基哌可酸的生产而改变了smph的基因,但即使改变smph的基因,也会生产出约9%的顺式-3-羟基哌可酸。
在非专利文献1中也报道了smph由l-哌可酸生产顺式-5-羟基-l-哌可酸和顺式-3-羟基哌可酸。在非专利文献1中报道了,为了提高顺式-5-羟基-l-哌可酸的生产率而改变了smph基因,但即使改变smph基因,也会生产出约4%的顺式-3-羟基哌可酸。
现有技术文献
专利文献
专利文献1:wo2009/139365
专利文献2:wo2013/187438
专利文献3:wo2013/169725
非专利文献
非专利文献1:koketsu等、acssynth.biol,doi:10.1021/sb500247a
技术实现要素:
发明所要解决的问题
由此可见,虽然利用生物学方法由l-哌可酸制造顺式-5-羟基-l-哌可酸的方法是已知的,但每种方法的顺式-5-羟基-l-哌可酸的生产率均低,并且,会一定程度地生产出顺式-3-羟基-l-哌可酸。因此,作为要求高纯度的药品的中间体等的制造方法,期望更高效地制造高纯度的顺式-5-羟基-l-哌可酸的方法。
本发明的课题在于提供顺式-3-羟基-l-哌可酸的生成少、更高效地制造光学纯度高的顺式-5-羟基-l-哌可酸的新方法。
用于解决问题的手段
本发明人们为了解决上述问题进行了深入研究,结果发现,xenorhabdusdoucetiaefrm16株来源的蛋白质(以下有时称为“xdph”)和xenorhabdusromaniistr.pr06-a株来源的蛋白质(以下有时称为“xrph”)具有高的l-哌可酸的顺式-5位羟化酶活性。而且发现,通过使用编码这些蛋白质的dna制作转化体并使该转化体细胞、其制备物和/或培养液与l-哌可酸发生作用,能够以高光学纯度及高浓度制造顺式-5-羟基-l-哌可酸。本发明是基于这些发现而完成的。
即,本发明的主旨如下所述。
[1]一种顺式-5-羟基-l-哌可酸的制造方法,其特征在于,使α-酮戊二酸依赖型l-哌可酸羟化酶、具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液与l-哌可酸发生作用,生成顺式-5-羟基-l-哌可酸,
上述α-酮戊二酸依赖型l-哌可酸羟化酶包含下述(a)、(b)或(c)所示的多肽:
(a)具有序列编号4或11所表示的氨基酸序列的多肽;
(b)具有在序列编号4或11所表示的氨基酸序列中缺失、置换和/或添加了1个或几个氨基酸而得到的氨基酸序列、且具有α-酮戊二酸依赖型l-哌可酸羟化酶活性的多肽;或
(c)具有与序列编号4或11所表示的氨基酸序列具有60%以上的同一性的氨基酸序列、且具有α-酮戊二酸依赖型l-哌可酸羟化酶活性的多肽。
[2]如[1]所述的顺式-5-羟基-l-哌可酸的制造方法,其中,编码上述α-酮戊二酸依赖型l-哌可酸羟化酶的dna包含下述(d)、(e)或(f)所示的dna:
(d)具有序列编号1、9或10所表示的碱基序列的dna;
(e)包含在序列编号1、9或10所表示的碱基序列中置换、缺失和/或添加了1个或几个碱基而得到的碱基序列、且编码具有α-酮戊二酸依赖型l-哌可酸羟化酶活性的多肽的dna;或
(f)包含在严格条件下与序列编号1、9或10所表示的碱基序列的互补链杂交的碱基序列、且编码具有α-酮戊二酸依赖型l-哌可酸羟化酶活性的多肽的dna。
[3]如[1]或[2]所述的顺式-5-羟基-l-哌可酸的制造方法,其中,使α-酮戊二酸依赖型l-哌可酸羟化酶、具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液在α-酮戊二酸和二价铁离子的存在下与上述l-哌可酸发生作用。
[4]一种α-酮戊二酸依赖型l-哌可酸羟化酶蛋白质,其具有与l-哌可酸发生作用而生成顺式-5-羟基-l-哌可酸的活性,并且包含下述(a)、(b)或(c)所示的多肽:
(a)具有序列编号4或11所表示的氨基酸序列的多肽;
(b)具有在序列编号4或11所表示的氨基酸序列中缺失、置换和/或添加了1个或几个氨基酸而得到的氨基酸序列、且具有α-酮戊二酸依赖型l-哌可酸羟化酶活性的多肽;或
(c)具有与序列编号4或11所表示的氨基酸序列具有60%以上的同一性的氨基酸序列、且具有α-酮戊二酸依赖型l-哌可酸羟化酶活性的多肽。
[5]一种多肽,其具有序列编号11所表示的氨基酸序列。
发明效果
根据本发明,能够由l-哌可酸更高效地制造光学纯度高的顺式-5-羟基-l-哌可酸。此外,由于顺式-3-羟基-l-哌可酸的生成少,因此在工业规模的制造中能够以低成本制造高纯度的顺式-5-羟基-l-哌可酸。
附图说明
图1是示出导入有各种l-哌可酸羟化酶基因的大肠杆菌的sds-聚丙烯酰胺电泳法的结果的图(电泳照片)。箭头示出l-哌可酸羟化酶的条带。
图2是示出由导入有各种l-哌可酸羟化酶基因的大肠杆菌得到的反应产物的分析结果的图。
图3是示出各种l-哌可酸羟化酶的活性的温度依赖性的图。
具体实施方式
以下,对本发明进行详细说明。
本说明书中,“将l-哌可酸转变为顺式-5-羟基-l-哌可酸的能力”是指以α-酮戊二酸依赖的方式在l-哌可酸的5位碳原子上添加羟基的能力。
是否具有“将l-哌可酸转变为顺式-5-羟基-l-哌可酸的能力”例如可以通过如下方法进行确认:在含有l-哌可酸作为底物、进而含有α-酮戊二酸作为辅酶的反应体系中,使作为测定对象的酶与l-哌可酸发生作用,直接测定由l-哌可酸转变而来的顺式-5-羟基-l-哌可酸的量。
另外,本说明书中的“酶”也包括纯化酶(包括部分纯化的酶)、使用公知的固定化技术固定化的酶、例如固定化于聚丙烯酰胺、卡拉胶等载体上的酶等。
本说明书中,“具有将l-哌可酸转变为顺式-5-羟基-l-哌可酸的能力的微生物或细胞”(以下有时称为“本发明的微生物或细胞”)只要具有“能够在l-哌可酸的5位碳原子上添加羟基的能力”,则没有特别限制,可以是内源性地具有上述能力的微生物或细胞,也可以是通过育种而赋予了上述能力的微生物或细胞。作为通过育种而赋予了上述能力的手段,可以采用基因重组处理(转化)、突变处理等公知的方法。作为转化的方法,可以使用导入目的基因、通过在染色体上改变启动子等表达调节序列等来强化目的基因的表达等方法。
需要说明的是,作为“微生物或细胞”的种类,可以列举后述的宿主生物或宿主细胞中记载的微生物或细胞。另外,本说明书中,作为“具有能够在l-哌可酸的5位碳原子上添加羟基的能力的微生物或细胞”,不限定于活的微生物或细胞,也包括作为生物体来说已死亡但仍具有酶能力的微生物或细胞。
本说明书中,作为“宿主生物”的生物的种类,没有特别限定,可以列举大肠杆菌、枯草杆菌、棒状杆菌、假单胞菌属细菌、芽孢杆菌属细菌、根瘤菌属细菌、乳杆菌属细菌、琥珀酸杆菌属细菌(サクシノバチルス属細菌)、厌氧螺菌属细菌、放线杆菌属细菌等原核生物、酵母、丝状真菌等菌类、植物、动物等真核生物。其中,优选为大肠杆菌、酵母、棒状杆菌,特别优选为大肠杆菌。
本说明书中,作为“宿主细胞”的细胞的种类,没有特别限定,可以使用动物细胞、植物细胞、昆虫细胞等。
本说明书中,“表达载体”是指用于通过整合入编码具有期望功能的蛋白质的多核苷酸并导入宿主生物而在上述宿主生物中复制和表达具有期望功能的蛋白质的遗传因子。可以列举例如质粒、病毒、噬菌体、粘粒等,但不限定于此。优选表达载体为质粒。
本说明书中,“转化体”是指使用上述表达载体等导入目的基因、从而变得能够表现出与具有期望功能的蛋白质相关的期望性状的微生物或细胞。
本说明书中,“微生物或细胞的处理物”是指下述物质等:对微生物或细胞进行培养并将该微生物或细胞1)利用有机溶剂等进行处理而得到的含有具有期望功能的蛋白质的物质、2)进行冷冻干燥而得到的含有具有期望功能的蛋白质的物质、3)固定化于载体等中而得到的含有具有期望功能的蛋白质的物质、4)利用物理方法或利用酶破坏而得到的含有具有期望功能的蛋白质的物质。
本说明书中,“对微生物或细胞进行培养而得到的含有酶的培养液”是指,1)微生物或细胞的培养液、2)利用有机溶剂等对微生物或细胞的培养液进行处理而得到的培养液、3)利用物理方法或利用酶将微生物或细胞的细胞膜破坏而得到的培养液。
<使用α-酮戊二酸依赖型l-哌可酸羟化酶的顺式-5-羟基-l-哌可酸的制造方法>
本发明的顺式-5-羟基-l-哌可酸的制造方法的特征在于,使α-酮戊二酸依赖型l-哌可酸羟化酶、具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液与l-哌可酸发生作用。如后所述,本发明的制造方法优选在α-酮戊二酸和二价铁离子的存在下进行。
本发明中使用的α-酮戊二酸依赖型l-哌可酸羟化酶(以下有时称为“本发明的l-哌可酸羟化酶”)将l-哌可酸羟化时的位置选择性和立体选择性高,因此,通过使用该酶,能够高效地得到光学纯度高的顺式-5-羟基-l-哌可酸。
本发明的α-酮戊二酸依赖型l-哌可酸羟化酶只要是具有将l-哌可酸转变为顺式-5-羟基-l-哌可酸的能力的酶则没有特别限制,优选为具有序列编号4或11记载的氨基酸序列的酶、或为该氨基酸序列的同源物且具有α-酮戊二酸依赖型l-哌可酸羟化酶活性的酶。即,本发明的l-哌可酸羟化酶优选为包含下述(a)、(b)或(c)所示的多肽的酶。
(a)具有序列编号4或11所表示的氨基酸序列的多肽;
(b)具有在序列编号4或11所表示的氨基酸序列中缺失、置换和/或添加了1个或几个氨基酸而得到的氨基酸序列、且具有α-酮戊二酸依赖型l-哌可酸羟化活性的多肽;或
(c)具有与序列编号4或11所表示的氨基酸序列具有60%以上的同一性的氨基酸序列、且具有α-酮戊二酸依赖型l-哌可酸羟化活性的多肽。
作为本发明中可使用的、具有序列编号4或11记载的氨基酸序列的α-酮戊二酸依赖型l-哌可酸羟化酶的同源物,如上述(b)所述,只要保持α-酮戊二酸依赖型l-哌可酸羟化活性,可以列举具有在序列编号4或11记载的氨基酸序列中缺失、置换或添加了1个或几个氨基酸而得到的氨基酸序列的同源物。在此,“1个或几个氨基酸”例如为1个~100个、优选为1个~50个、更优选为1个~20个、进一步优选为1个~10个、特别优选为1个~5个氨基酸。
另外,作为上述同源物,如上述(c)所述,只要保持α-酮戊二酸依赖型l-哌可酸羟化活性,也可以为与序列编号4或11所示的氨基酸序列全长具有至少60%以上、优选80%以上、更优选90%以上、进一步优选95%、特别优选99%以上的序列同一性的蛋白质。
序列编号4记载的氨基酸序列是基于xenorhabdusdoucetiaefrm16株的公知的基因组信息而得到的氨基酸序列。
序列编号11记载的氨基酸序列是基于利用使用pcr的公知方法从xenorhabdusromaniistr.pr06-a株克隆化而得的基因信息而得到的氨基酸序列。
包含序列编号4或11的氨基酸序列及其同源物的本发明的l-哌可酸羟化酶可选择性地将l-哌可酸的5位碳原子羟化,因此能够以高效率生成顺式-5-羟基-l-哌可酸。
需要说明的是,在本发明的制造方法中,也可以并用多个α-酮戊二酸依赖型l-哌可酸羟化酶。
本发明中可使用的α-酮戊二酸依赖型l-哌可酸羟化酶可以由xenorhabdusdoucetiaefrm16株或xenorhabdusromaniistr.pr06-a株纯化得到,也可以通过对于编码α-酮戊二酸依赖型l-哌可酸羟化酶的dna利用pcr、杂交等公知的方法将该基因克隆化、并使其在适当的宿主中进行表达而得到。
作为编码具有序列编号4或11所示的氨基酸序列的α-酮戊二酸依赖型l-哌可酸羟化酶的dna,可以分别列举包含序列编号1、9或10的碱基序列的dna,只要编码具有α-酮戊二酸依赖型l-哌可酸羟化活性的蛋白质,也可以为包含序列编号1、9或10的碱基序列的dna的同源物。即,作为本发明的编码l-哌可酸羟化酶的dna,可以列举下述(d)、(e)或(f)所示的碱基序列。
(d)具有序列编号1、9或10所表示的碱基序列的dna;
(e)包含在序列编号1、9或10所表示的碱基序列中置换、缺失和/或添加了1个或几个碱基而得到的碱基序列、且编码具有α-酮戊二酸依赖型l-哌可酸羟化活性的多肽的dna;或
(f)包含在严格条件下与序列编号1、9或10所表示的碱基序列的互补链杂交的碱基序列、且编码具有α-酮戊二酸依赖型l-哌可酸羟化活性的多肽的dna。
作为同源物,可以列举例如如上述(e)所述包含在序列编号1、9或10的碱基序列中置换、缺失或添加1个或几个碱基而得到的碱基序列的dna。在此所述的1个或几个碱基例如为1个~300个、优选为1个~150个、更优选为1个~60个、进一步优选为1个~30个、特别优选为1个~15个碱基。
需要说明的是,序列编号1是为了用于大肠杆菌表达而对编码序列编号4的氨基酸序列的xenorhabdusdoucetiaefrm16株的基因进行密码子优化而得到的碱基序列。这样根据作为转化对象的宿主的不同对密码子进行了优化的dna当然也包含在本发明中可使用的编码α-酮戊二酸依赖型l-哌可酸羟化酶的dna中。
此外,作为上述dna的同源物,如上述(f)所述,只要编码具有α-酮戊二酸依赖型l-哌可酸羟化活性的蛋白质,可以为在严格条件下与序列编号1、9或10的碱基序列的互补链杂交的dna。在此,“在严格条件下杂交的碱基序列”是指使用dna作为探针,通过在严格条件下利用菌落杂交法、噬菌斑杂交法或southern印记杂交法等而得到的dna的碱基序列。作为严格条件,可以列举例如下述条件:在菌落杂交法和噬菌斑杂交法中,使用固定有来源于菌落或噬菌斑的dna或该dna的片段的过滤器,在0.7mol/l~1.0mol/l的氯化钠水溶液的存在下、在65℃进行杂交后,使用0.1~2×ssc溶液(1×ssc的组成为150mmol/l氯化钠水溶液、15mmol/l柠檬酸钠水溶液),在65℃的条件下对过滤器进行清洗。
各杂交可以基于molecularcloning:alaboratorymannual(分子克隆实验指南),第2版,冷泉港实验室,冷泉港,纽约,1989.等记载的方法进行。
本领域技术人员可以通过使用定点突变法(nucleicacidsres.10,pp.6487(1982)、methodsinenzymol.100,pp.448(1983)、molecularcloning、pcrapracticalapproachirlpresspp.200(1991))等在序列编号1、9或10的dna中适当导入置换、缺失、插入和/或添加突变而得到如上所述的dna同源物。
另外,也可以基于序列编号4或11的氨基酸序列或其一部分、序列编号1、9或10所表示的碱基序列或其一部分,对例如dnadatabankofjapan(日本dna数据库)(ddbj)等数据库进行同源性检索而获得α-酮戊二酸依赖型l-哌可酸羟化酶的氨基酸信息或编码该酶的dna的碱基序列信息。
在本发明的羟基-l-哌可酸的制造方法中,可以将α-酮戊二酸依赖型l-哌可酸羟化酶直接用于反应,但优选使用含有α-酮戊二酸依赖型l-哌可酸羟化酶的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液。
作为含有α-酮戊二酸依赖型l-哌可酸羟化酶的微生物或细胞,可以使用原本就具有α-酮戊二酸依赖型l-哌可酸羟化酶的微生物或细胞,但优选使用利用编码α-酮戊二酸依赖型l-哌可酸羟化酶的基因进行了转化的微生物或细胞。
另外,作为含有α-酮戊二酸依赖型l-哌可酸羟化酶的微生物或细胞的制备物,例如可以使用将该微生物或细胞用丙酮、二甲亚砜(dmso)、甲苯等有机溶剂、表面活性剂进行处理而得到的制备物、进行冷冻干燥处理而得到的制备物、利用物理方法或利用酶进行破碎而得到的制备物等微生物或细胞的制备物、将微生物或细胞中的酶级分以粗制物或纯化物的形式取出而得到的制备物、以及将这些制备物固定于以聚丙烯酰胺凝胶、卡拉胶等为代表的载体上而得到的制备物等。
作为对含有α-酮戊二酸依赖型l-哌可酸羟化酶的微生物或细胞进行培养而得到的培养液,例如可以使用该微生物或细胞与液体培养基的混悬液,在该微生物或细胞为分泌表达型微生物或细胞的情况下,可以使用通过离心分离等除去该微生物或细胞后而得到的上清或其浓缩物。
通过将如上所述分离出的编码α-酮戊二酸依赖型l-哌可酸羟化酶的dna以可表达的方式插入到公知的表达载体中,可提供α-酮戊二酸依赖型l-哌可酸羟化酶表达载体。然后,通过利用该表达载体对宿主细胞进行转化,能够得到导入有编码α-酮戊二酸依赖型l-哌可酸羟化酶的dna的转化体。转化体也可以通过利用同源重组等方法将编码α-酮戊二酸依赖型l-哌可酸羟化酶的dna以可表达的状态整合到宿主的染色体dna中而得到。
作为转化体的制作方法,具体而言,可以例示下述方法:将编码α-酮戊二酸依赖型l-哌可酸羟化酶的dna导入到在微生物等宿主细胞中稳定存在的质粒载体、噬菌体载体、病毒载体中并将所构建的表达载体导入到该宿主细胞中,或者直接将该dna导入到宿主基因组中,对其遗传信息进行转录、翻译。此时,优选在宿主中在dna的5’-侧上游连接适当的启动子,更优选进一步在3’-侧下游连接终止子。作为这样的启动子和终止子,只要是已知在用作宿主的细胞中发挥功能的启动子和终止子则没有特别限定,例如,在“微生物学基础讲座8基因工程、共立出版”等中详细记载了在宿主微生物中可利用的载体、启动子和终止子。
作为用于表达α-酮戊二酸依赖型l-哌可酸羟化酶的作为转化对象的宿主微生物,只要宿主本身不会对l-哌可酸的反应造成不利影响则没有特别限定,具体可以列举如下所示的微生物。
属于埃希氏菌(escherichia)属、芽孢杆菌(bacillus)属、假单胞菌(pseudomonas)属、沙雷氏菌(serratia)属、短杆菌(brevibacterium)属、棒状杆菌(corynebacterium)属、链球菌(streptococcus)属、乳杆菌(lactobacillus)属等的已建立了宿主载体系统的细菌。
属于红球菌(rhodococcus)属、链霉菌(streptomyces)属等的已建立了宿主载体系统的放线菌。属于酵母菌(saccharomyces)属、克鲁维酵母(kluyveromyces)属、裂殖酵母(schizosaccharomyces)属、接合酵母(zygosaccharomyces)属、解脂耶氏酵母菌(yarrowia)属、丝孢酵母菌(trichosporon)属、红冬孢酵母(rhodosporidium)属、汉逊酵母(hansenula)属、毕赤酵母(pichia)属、念珠菌(candida)属等已建立了宿主载体系统的酵母。
属于脉孢菌(neurospora)属、曲霉(aspergillus)属、头孢霉(cephalosporium)属、木霉(trichoderma)属等的已建立了宿主载体系统的霉菌。
用于转化体制作的程序、适合于宿主的重组载体的构建和宿主的培养方法可以基于分子生物学、生物工程、基因工程的领域中惯用的技术来进行(例如,molecularcloning(分子克隆)中记载的方法)。
以下,具体地列举优选的宿主微生物、各微生物的优选转化方法、载体、启动子、终止子等的示例,但本发明不限定于这些示例。
在埃希氏菌属、特别是大肠杆菌(escherichiacoli)中,作为质粒载体,可以列举pbr、puc系质粒等,可以列举lac(β-半乳糖苷酶)、trp(色氨酸操纵子)、tac、trc(lac、trp的融合)、λ噬菌体pl、pr等来源的启动子等。另外,作为终止子,可以列举trpa来源、噬菌体来源、rrnb核糖体rna来源的终止子等。
在芽孢杆菌属中,作为载体,可以列举pub110系质粒、pc194系质粒等,另外,也可以整合到染色体中。作为启动子和终止子,可以利用碱性蛋白酶、中性蛋白酶、α-淀粉酶等的酶基因的启动子、终止子等。
在假单胞菌属中,作为载体,可以列举在恶臭假单胞菌(pseudomonasputida)、洋葱假单胞菌(pseudomonascepacia)等中建立的通常的宿主载体系统、参与甲苯化合物的分解的质粒、以tol质粒为基础的广宿主载体(包含来源于rsf1010等的自主复制所需的基因)pkt240(gene,26,273-82(1983))等。
在短杆菌属、特别是乳糖发酵短杆菌(brevibacteriumlactofermentum)中,作为载体,可以列举paj43(gene39,281(1985))等质粒载体。作为启动子和终止子,可以利用在大肠杆菌中使用的各种启动子和终止子。
在棒状杆菌属、特别是谷氨酸棒杆菌(corynebacteriumglutamicum)中,作为载体,可以列举pcs11(日本特开昭57-183799号公报)、pcb101(mol.gen.genet.196,175(1984))等质粒载体。
在酵母菌(saccharomyces)属、特别是酿酒酵母菌(saccharomycescerevisiae)中,作为载体,可以列举yrp系、yep系、ycp系、yip系质粒等。另外,可以利用醇脱氢酶、甘油醛-3-磷酸脱氢酶、酸性磷酸酶、β-半乳糖苷酶、磷酸甘油酸激酶、烯醇酶等各种酶基因的启动子、终止子。
在裂殖酵母(schizosaccharomyces)属中,作为载体,可以列举mol.cell.biol.6,80(1986)中记载的粟酒裂殖酵母来源的质粒载体等。特别是paur224由宝生物株式会社销售,可以容易地利用。
在曲霉(aspergillus)属中,黑曲霉(aspergillusniger)、米曲霉(aspergillusoryzae)等在霉菌中研究得最多,可用于向质粒、染色体中整合,可以利用菌体外蛋白酶、淀粉酶来源的启动子(trendsinbiotechnology7,283-287(1989))。
另外,除了上述以外,已建立了适应于各种微生物的宿主载体系统,可以适当使用这些宿主载体系统。
另外,除了微生物以外,在植物、动物中也建立了各种宿主、载体系统,特别是建立了在昆虫(例如蚕)等动物中(nature315,592-594(1985))、菜籽、玉米、土豆等植物中大量表达异种蛋白质的系统、使用大肠杆菌无细胞提取液或小麦胚芽等的无细胞蛋白质合成系统的系统,可以适当利用。
在本发明的制造方法中,通过使α-酮戊二酸依赖型l-哌可酸羟化酶、具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液在α-酮戊二酸的存在下与作为反应底物的l-哌可酸发生作用,能够制造顺式-5-羟基-l-哌可酸。
本发明的制造方法只要使α-酮戊二酸、以及α-酮戊二酸依赖型l-哌可酸羟化酶、具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液与l-哌可酸发生作用,则没有特别限制,但通常优选在水性介质中或该水性介质与有机溶剂的混合物中进行。本发明的制造方法优选进一步在二价铁离子的存在下进行。
作为上述水性介质,可以列举例如水或缓冲液。
另外,作为上述有机溶剂,可以使用甲醇、乙醇、1-丙醇、2-丙醇、1-丁醇、叔丁醇等醇类溶剂、丙酮、二甲亚砜等反应底物的溶解度高的溶剂。另外,作为上述有机溶剂,也可以使用对除去反应副产物等有效的乙酸乙酯、乙酸丁酯、甲苯、氯仿、正己烷等。
作为反应底物的l-哌可酸通常在底物浓度为0.01%w/v~90%w/v、优选为0.1%w/v~30%w/v的范围内使用。反应底物可以在反应开始时一次性添加,但从减少存在酶的底物抑制时的影响的观点和提高产物的蓄积浓度的观点出发,优选连续地或间歇地添加。
α-酮戊二酸通常在与底物为等摩尔或更多、优选为等摩尔~1.2倍摩尔的范围内添加。α-酮戊二酸可以在反应开始时一次性添加,但从减少对酶具有抑制作用时的影响的观点和提高产物的蓄积浓度的观点出发,优选连续地或间歇地添加。另外,也可以添加葡萄糖等宿主可代谢的廉价的化合物来代替α-酮戊二酸,使宿主进行代谢,将该过程中产生的α-酮戊二酸用于反应。
本发明的制造方法优选在二价铁离子的存在下进行。二价铁离子通常优选在0.01mmol/l~100mmol/l、优选在0.1mmol/l~10mmol/l的范围内使用。二价铁离子可以以硫酸铁等的形式在反应开始时一次性添加,但在反应中添加的二价铁离子被氧化为三价、形成沉淀而减少的情况下,追加添加也是有效的。另外,在本发明的l-哌可酸羟化酶、具有生产该酶的能力的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液中已经含有足够量的二价铁离子的情况下,也不是一定要进行添加。
反应在通常为4℃~60℃、优选为15℃~45℃、特别优选为20℃~40℃的反应温度下在通常为ph3~ph11、优选为ph5~ph8下进行。反应时间通常为约1小时~约72小时。
关于向反应液中添加的微生物或细胞、该微生物或细胞的处理物、和/或对该微生物或细胞进行培养而得到的含有该酶的培养液的量,例如在添加细胞的情况下,按照该细胞的浓度以湿菌体重量计通常为约0.1%w/v~约50%w/v、优选为1%w/v~20%w/v的方式添加到反应液中,在使用处理物的情况下,求出酶的比活性,以添加后达到上述细胞浓度的量进行添加。
通过本发明的制造方法生成的羟基-l-哌可酸可以通过在反应结束后利用离心分离、膜处理等对反应液中的菌体、蛋白质等进行分离、然后将利用1-丁醇、叔丁醇等有机溶剂进行的萃取、蒸馏、使用离子交换树脂或硅胶等的柱层析、等电点晶析或利用一盐酸盐、二盐酸盐、钙盐等进行的晶析等适当组合而进行纯化。
[实施例]
以下,利用实施例进一步详细地对本发明进行说明,但本发明并不限定于此。
实施例1
α-酮戊二酸依赖型哌可酸羟化酶基因的克隆
由dna2.0公司人工合成了编码xenorhabdusdoucetiaefrm16株来源的推测的l-脯氨酸顺式-4-羟化酶xdph(genbank登录号cdg16639、序列编号4)的为了用于大肠杆菌表达而进行了密码子优化的基因序列(xdph_ecodon、序列编号1),插入到pjexpress411(dna2.0)中,制作成质粒pj411xdph。
同样地,也进行了公知的显示出哌可酸5位羟化活性的代表性的酶基因的克隆。由dna2.0公司人工合成了编码segniliparusrugosusnbrc101839株来源的l-哌可酸顺式-5-羟化酶sruph(genbank登录号efv12517、序列编号6)和苜蓿中华根瘤菌(sinorhizobiummeliloti)1021株来源的l-脯氨酸顺式-4-羟化酶smph(genbank登录号cac47686、序列编号5)的、为了用于大肠杆菌表达而进行了密码子优化的基因序列sruph_ecodon(序列编号3)和smph_ecodon(序列编号2),分别插入到pjexpress411(dna2.0)和pjexpress401中,制作成质粒pj411sruph、pj401smph。合成针对smph_ecodon的引物smph_f(序列编号7)和smph_r(序列编号8),使用它们以质粒dna为模板按照常规方法进行pcr反应,得到约1.0kbp的dna片段。利用限制性内切酶ndei、hindiii对所得到的dna片段进行消化,按照常规方法与利用ndei、hindiii消化后的pet24a(novagen)连接,由此分别得到pet24smph。
实施例2
α-酮戊二酸依赖型哌可酸羟化酶基因表达菌体的获取和表达量的确认
接着,使用所得到的各质粒按照常规方法对大肠杆菌(escherichiacoli)bl21(de3)(invitrogen制)进行转化,得到重组大肠杆菌bl21(de3)/pj411xdph、bl21(de3)/pj411sruph、bl21(de3)/pet24smph。为了得到表达所导入的基因的菌体,对于各重组大肠杆菌,使用含有卡那霉素和lac启动子诱导物质的液体lb培养基在28℃下培养4小时~6小时后,在15℃下进一步培养约40小时,然后收集菌体。
将所得到的重组大肠杆菌以浊度od630为约10的方式悬浮到ph7的50mmol/lmes(2-吗啉乙磺酸)缓冲液中。在冰上对该悬浮液0.5ml进行超声波破碎处理,然后以12000rpm的转速进行离心分离,由此分离成上清和残渣。将所得到的上清作为可溶性级分,将残渣作为不溶性级分。
按照常规方法对所得到的可溶性级分和不溶性级分进行处理后,利用sds-聚丙烯酰胺电泳法确认所表达的蛋白质表达量。将结果示于图1。
实施例3
α-酮戊二酸依赖型哌可酸羟化酶的活性确认
在塑料管内将5mmol/ll-哌可酸、10mmol/lα-酮戊二酸、1mmol/ll-抗坏血酸、0.5mmol/l硫酸铁、以及以约2mg/ml的蛋白质浓度添加有实施例2中得到的各粗制酶液的液体0.2ml在30℃下振荡1小时。
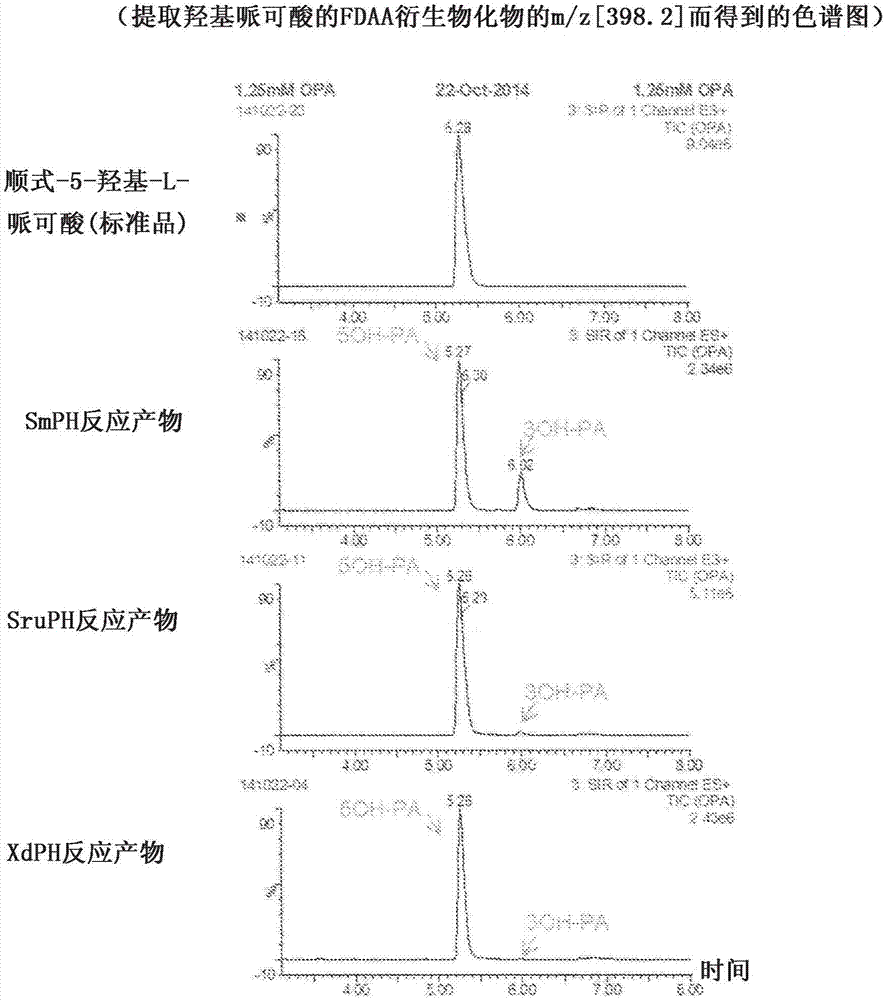
利用1-氟-2,4-二硝基苯基-5-l-丙氨酰胺(fdaa)使反应产物形成衍生物,然后利用uplc‐ms(waters制)进行分析。结果如图2所示,确认到由使用各粗制酶液进行了反应后的液体生成了与5-羟基哌可酸标准品的保留时间5.3分钟一致的化合物。各酶液显示出的5-羟基哌可酸生成活性(u/g)以单位蛋白质量(g)计分别算出为4.1u/g、8.9u/g、3.1u/g。此处的单位(u)表示在1分钟内生成1微摩尔的底物的能力。
另外,确认到由smph反应产物生成了认为是顺式-3-羟基哌可酸的保留时间为6.0分钟的化合物。将利用色谱图上的羟基哌可酸峰的面积值对顺式-3-羟基哌可酸在总羟基哌可酸量中所占的比例进行比较的结果示于表2。可知xdph反应产物中仅生成了0.17%的顺式-3-羟基哌可酸。
需要说明的是,利用hplc的羟基哌可酸的分析条件如下述表1所示。
实施例4
羟化反应的温度依赖性的确认
为了确认各酶反应的温度依赖性,将各羟化酶的粗制酶液在各种温度下温育1小时30分钟后,测定在30℃下反应1小时后的5-羟基哌可酸生成量。将所得到的结果以将各酶的最高活性值设为100(%)时的相对活性的形式示于图3。
表1
a)lc的设定
b)洗脱条件
c)ms的条件
表2
实施例5
α-酮戊二酸依赖型哌可酸羟化酶基因的克隆
以xenorhabdusdoucetiaefrm16株及其近缘种xenorhabdusromaniistr.pr06-a株来源的染色体dna作为模板,使用扩增推测的l-脯氨酸顺式-4-羟化酶xdph基因(xdphori:genbank登录号fo704550-xdd1_0936、序列编号9)的引物xdphfus-f(序列编号12)和xdphfus-r(序列编号13),利用聚合酶链式反应(pcr)分别扩增出约1kbp的dna片段。使用in-fusionhd克隆试剂盒(宝生物株式会社制)按照常规方法将所得到的两种dna片段插入到利用限制性内切酶ncoi、hindiii消化后的pqe60(qiagen)中,分别得到pqexdphori、pqexrphori。
接着,使用所得到的各质粒,按照常规方法对大肠杆菌(escherichiacoli)jm109进行转化,得到重组大肠杆菌jm109/pqexdphori和jm109/pqexrphori。按照常规方法对插入到pqe60中的基因序列进行确认,决定了xenorhabdusromaniistr.pr06-a株来源的氨基酸羟化酶的基因序列(xrph_ori、序列编号10)和氨基酸序列(xrph、序列编号11)。xrph相对于xdph具有99%的同一性。
为了得到表达所导入的基因的菌体,使用含有氨苄青霉素的液体lb培养基对各重组大肠杆菌培养一夜后,收集菌体。
在塑料管内添加20mmol/ll-哌可酸、15mmol/lα-酮戊二酸、10mmol/l三(2-羧乙基)膦盐酸盐(tcep)、0.5mmol/l硫酸铁、10mmol/l柠檬酸钠、1%nymeen、以及将由所得到的重组大肠杆菌jm109/pqexdphori、jm109/pqexrphori的培养液0.4ml得到的菌体用ph6.5的50mmol/l双(2-羟乙基)亚氨基三(羟甲基)甲烷缓冲液悬浮而得到的液体0.2ml,制成总容量为1ml的反应液,使其在20℃下振荡20小时。
使用accq·tag(waters公司制)使反应后的液体形成衍生物后,以下述条件的hplc条件进行分析,测定所生成的5-羟基-l-哌可酸。
柱:xbridgec185μm(2.1×150mm)(waters公司制)
洗脱液a:10mmol/l乙酸铵(ph5)
洗脱液b:甲醇(0~0.5分钟
流速:0.3ml/分钟
检测:荧光检测器
温度:30℃
将测定结果示于表3。确认到不仅xenorhabdusdoucetiaefrm16株来源的羟化酶xdph保持了哌可酸5位羟化活性,xenorhabdusromaniistr.pr06-a株来源的羟化酶也保持了哌可酸5位羟化活性。
表3
序列表
<110>株式会社api(apicorporation)
<120>顺式-5-羟基-l-哌可酸的制造方法(methodofproducingcis-5-hydroxy-l-pipecolicacid)
<130>ap351-15399
<150>jp2014-229685
<151>2014-11-12
<160>13
<170>patentinversion3.5
<210>1
<211>882
<212>dna
<213>artificalsequence
<220>
<223>xdph_ecodon
<400>1
atgatgagcgcaaaactgctggcaagcattgaattgaaccaagaacagatcgagcatgat60
ctgaatattgttggtagcgagatcctggacgtggcgtacagcgagtatgcgtgcggcaat120
tggggtaccattaccctgtggaaccacagcggcgatgctggcgaccagacgagccgcgaa180
tacgttggtcaggcccgtccgactgagctgggccagcaattagactgcattaatcagctg240
atccgtaacaatttcaacatcagcctgatcaagagcgtgcgcatcttccgtagctataac300
ggtggtgcgatctatccgcacattgactacttggaattcaaccaaggttttaagcgcgtg360
cacctggttctgaaatccgaccgttcatgtctgaatagcgaagagaacacggtttatcac420
atgctgcctggtgaagtgtggtttgtcgatggtcatagcgcgcactcggcgatgagcctg480
agccgtgtcggcaagtactcgctggtcctggactttgattctggcgccaaattcgaagat540
ctgtattctgagagccacaccctgtgtgttgataacctggagccggacattatccatgac600
cgccagccactgccgaccagcctgcgtgatagcctggcacacattgctgagcatgcggat660
gaattcaatatccaatccattctgttcctggccacccgttttcactttagctacgcagtg720
agcattcgtgagtacttccaactcctggacgagtgcttttctcgcaacccgtacaagtcc780
gttcgcgagcgttacgaagcgctgaaagacattttggtgcgtagcggttataccagccac840
aatgtcaatcatttcaacagcttgtccggtgtcacgatcggc882
<210>2
<211>843
<212>dna
<213>artificalsequence
<220>
<223>smph_ecodon
<400>2
atgagcacccattttctcggcaaggtaaagtttgatgaagcgcgtttggcagaggacttg60
agcaccctggaagtggctgagtttagcagcgcctacagcgactttgcatgcggcaaatgg120
gaagcgtgcgtcctgcgcaaccgcaccggtatgcaagaagaagatatcgttgttagccac180
aatgctccggcgctggcgacgccgctgagcaagtccctgccgtatctgaacgagctggtg240
gaaacccatttcgactgtagcgccgtgcgttacacgcgcattgttcgtgtctctgagaac300
gcatgtatcattccgcattctgactatctggagttggatgaaacgttcacgcgcctgcac360
ctggttctggacacgaatagcggttgtgcgaataccgaagaggataagattttccacatg420
ggtctgggcgagatctggttcctggatgctatgctgccgcacagcgccgcatgctttagc480
aaaactccgcgtctgcacttgatgattgatttcgaggcgaccgcgttcccagagagcttt540
ttgcgtaacgttgagcagccggtcaccacccgtgatatggtggacccgcgtaaagagctg600
accgacgaggtgatcgaaggtatcctgggcttttccatcatcattagcgaggcaaattac660
cgtgagattgtctccattctggcgaaactgcacttcttttacaaggcggattgccgcagc720
atgtacgactggctgaaagaaatctgcaaacgtcgtggtgaccctgccctgattgaaaag780
accgcgtcgctggagcgcttcttcctgggtcatcgtgaacgcggtgaggttatgacgtat840
taa843
<210>3
<211>897
<212>dna
<213>artificalsequence
<220>
<223>sruph_ecodon
<400>3
atgaaaagctattccttgggcaagtttgaggaccgttctattgacagcctgatcgaagaa60
gcgtccggtctgccggacagcgcgtattcttctgcgtaccaagagtacagcatcggtctg120
tgggacaccgccacgctgtggaacgaacgtggcaacgagagcggcgaggttagcgagcac180
gcggcagccgctgcgccgaccgcaattggtcgtagcaccccgcgtctgaacgaatttgta240
cgtgccaagttcaatgtcgatgtcctgcgtgcggttcgcttgttcagagcgcgtcagggt300
gcaattatcatcccgcaccgcgattacctggagcatagcaatggtttttgccgtattcac360
cttccgctggttacgaccccgggtgcgcgtaatagcgagaataacgaagtgtatcgcatg420
ctgcctggcgagctgtggttcctggattcaaacgaagtgcacagcggtggcgttctggac480
agcggtacgcgcattcacctcgttttagatttcacccacgagcataatgagaatccggct540
gcagtgctgaagaacgccgaccgtttgcgtccgatcgcgcgtgacccgcgcatctcgcgc600
tccaaactggatcacgaagcgctggagagcctgatccgcggtggccgtgtcgtcactctg660
gcgatgtggccagctctggtgcagatgctggcacgcattcatctgaccagcgacgcacat720
ccggccgagctgtacgactggttggatgacctggcggaccgcagcggcaacgatgagctg780
gttgcagaagcgcgtcgtatgcgtcgttactttctgaccgatggtattagccgtacgccg840
agcttcgaacgcttttggcgcgaactggatgccgctcgtaaaggtgagttggtgagc897
<210>4
<211>294
<212>prt
<213>xenorhabdusdoucetiaefrm16
<400>4
metmetseralalysleuleualaserilegluleuasnglnglugln
151015
ilegluhisaspleuasnilevalglysergluileleuaspvalala
202530
tyrserglutyralacysglyasntrpglythrilethrleutrpasn
354045
hisserglyaspalaglyaspglnthrserargglutyrvalglygln
505560
alaargprothrgluleuglyglnglnleuaspcysileasnglnleu
65707580
ileargasnasnpheasnileserleuilelysservalargilephe
859095
argsertyrasnglyglyalailetyrprohisileasptyrleuglu
100105110
pheasnglnglyphelysargvalhisleuvalleulysserasparg
115120125
sercysleuasnserglugluasnthrvaltyrhismetleuprogly
130135140
gluvaltrpphevalaspglyhisseralahisseralametserleu
145150155160
serargvalglylystyrserleuvalleuasppheaspserglyala
165170175
lysphegluaspleutyrsergluserhisthrleucysvalaspasn
180185190
leugluproaspileilehisaspargglnproleuprothrserleu
195200205
argaspserleualahisilealagluhisalaaspglupheasnile
210215220
glnserileleupheleualathrargphehisphesertyralaval
225230235240
serileargglutyrpheglnleuleuaspglucyspheserargasn
245250255
protyrlysservalarggluargtyrglualaleulysaspileleu
260265270
valargserglytyrthrserhisasnvalasnhispheasnserleu
275280285
serglyvalthrilegly
290
<210>5
<211>280
<212>prt
<213>sinorhizobiummeliloti1021
<400>5
metserthrhispheleuglylysvallyspheaspglualaargleu
151015
alagluaspleuserthrleugluvalalaglupheserseralatyr
202530
seraspphealacysglylystrpglualacysvalleuargasnarg
354045
thrglymetglnglugluaspilevalvalserhisasnalaproala
505560
leualathrproleuserlysserleuprotyrleuasngluleuval
65707580
gluthrhispheaspcysseralavalargtyrthrargilevalarg
859095
valsergluasnalacysileileprohisserasptyrleugluleu
100105110
aspgluthrphethrargleuhisleuvalleuaspthrasnsergly
115120125
cysalaasnthrglugluasplysilephehismetglyleuglyglu
130135140
iletrppheleuaspalametleuprohisseralaalacyspheser
145150155160
lysthrproargleuhisleumetileasppheglualathralaphe
165170175
progluserpheleuargasnvalgluglnprovalthrthrargasp
180185190
metvalaspproarglysgluleuthraspgluvalilegluglyile
195200205
leuglypheserileileileserglualaasntyrarggluileval
210215220
serileleualalysleuhisphephetyrlysalaaspcysargser
225230235240
mettyrasptrpleulysgluilecyslysargargglyaspproala
245250255
leuileglulysthralaserleugluargphepheleuglyhisarg
260265270
gluargglygluvalmetthrtyr
275280
<210>6
<211>299
<212>prt
<213>segniliparusrugosusatccbaa-974
<400>6
metlyssertyrserleuglylysphegluaspargserileaspser
151015
leuilegluglualaserglyleuproaspseralatyrserserala
202530
tyrglnglutyrserileglyleutrpaspthralathrleutrpasn
354045
gluargglyasngluserglygluvalsergluhisalaalaalaala
505560
alaprothralaileglyargserthrproargleuasnglupheval
65707580
argalalyspheasnvalaspvalleuargalavalargleuphearg
859095
alaargglnglyalaileileileprohisargasptyrleugluhis
100105110
serasnglyphecysargilehisleuproleuvalthrthrprogly
115120125
alaargasnsergluasnasngluvaltyrargmetleuproglyglu
130135140
leutrppheleuaspserasngluvalhisserglyglyvalleuasp
145150155160
serglythrargilehisleuvalleuaspphethrhisgluhisasn
165170175
gluasnproalaalavalleulysasnalaaspargleuargproile
180185190
alaargaspproargileserargserlysleuasphisglualaleu
195200205
gluserleuileargglyglyargvalvalthrleualamettrppro
210215220
alaleuvalglnmetleualaargilehisleuthrseraspalahis
225230235240
proalagluleutyrasptrpleuaspaspleualaaspargsergly
245250255
asnaspgluleuvalalaglualaargargmetargargtyrpheleu
260265270
thraspglyileserargthrproserphegluargphetrpargglu
275280285
leuaspalaalaarglysglygluleuvalser
290295
<210>7
<211>36
<212>dna
<213>artificalsequence
<220>
<223>primer
<400>7
tttcatatgagcacccattttctcggcaaggtaaag36
<210>8
<211>33
<212>dna
<213>artificalsequence
<220>
<223>primer
<400>8
tttaagcttttaatacgtcataacctcaccgcg33
<210>9
<211>858
<212>dna
<213>xenorhabdusdoucetiaefrm16
<400>9
atgagaacgcattttgtgggtgaagttgcattggacctggcacgtctggaggctgatctg60
gcaacctgtcgtagcctggagtggagcgaagcgtattcggattacgtctttggtggtagc120
tggaaaagctgcatgctgtgggcgcctggtggcgatgccggcgatggtgttgtgacggac180
tacgcgtacgaccgtagcgcgggttttacgccgcacgcagagcgcctgccgtatctggca240
gagcttattcgtgagactgcagatctggatcgcctgaatttcgcgcgcttggcgctggta300
accaactctgtgattatcccgcaccgtgacctgttggaattaagcgacttgccggacgaa360
gctcgcaatgaacaccgtatgcacattccgctggcgaccaatgataactgcttcttcaac420
gaggacaacgttgtgtatcgtatgcgtcgtggtgaagtttggtttctggatgccagccgt480
attcatagcgtcgctgtcctgacggcgcagccacgtatccatctgatgctggatttcgtg540
gacaccccgggtgcgggcagcttcacgcgcgttgcgggtggcggcgttgaggccggcatc600
ccggtcgatcgcatcgtgacccgtccgccgctgggcgacgacgagcgtgcggacctgttc660
ggtgtcgccccactcctgtccatggataccttcgacgaagtgttttccattgttatcaag720
aaacacttccgtcgtgatggtggcagcgactttgtgtgggacaccatgctggaactggcg780
gcgaagtctccggatccggccgtcctgccgcataccgaagaactgcgcaagcactacacc840
ctggaccgcagcgcataa858
<210>10
<211>885
<212>dna
<213>xenorhabdusromaniipr06-a
<400>10
atgatgagtgcaaaattgttggccagcattgaactgaatcaggaacaaattgaacacgac60
ttaaatattgtaggtagtgaaattctggatgttgcatatagcgaatatgcttgtggcaac120
tggggcaccatcacgttatggaatcacagtggagacgctggtgaccaaacatcaagagag180
tatgttgggcaggctcgtcctacagagcttggacagcagttggattgtattaaccaactt240
attcgaaacaattttaatatatctctgatcaaatcagtgcgtatattccgttcttataac300
ggtggagccatttatccacatattgattatttggaattcaatcaagggttcaaacgtgtg360
catctggtgctaaaatcagaccgaagttgcctcaattccgaagagaatacagtttatcac420
atgctccctggtgaagtatggtttgttgacggtcatagtgcacacagtgcaatgtcacta480
agtcgtgtagggaaatacagtttagtgcttgattttgactctggtgctaaattcgaggat540
ttgtattccgaaagccacacgttatgtgtagacaacctagaaccagatattattcatgat600
cggcaaccattgccaacatcactgcgggattcactcgctcatatagctgagcacgccgat660
gaattcaacattcagtctatcctgtttcttgctacccgctttcactttagttatgcagtg720
tcaatcagagaatattttcaattgttagatgaatgttttagtcgtaatccgtacaaatca780
gttagagaaagatacgaggcattgaaggatattctagtccgaagtggctatacatcccat840
aagtttaaccactttaactcactgtctggagtcactattggttaa885
<210>11
<211>294
<212>prt
<213>xenorhabdusromaniipr06-a
<400>11
metmetseralalysleuleualaserilegluleuasnglnglugln
151015
ilegluhisaspleuasnilevalglysergluileleuaspvalala
202530
tyrserglutyralacysglyasntrpglythrilethrleutrpasn
354045
hisserglyaspalaglyaspglnthrserargglutyrvalglygln
505560
alaargprothrgluleuglyglnglnleuaspcysileasnglnleu
65707580
ileargasnasnpheasnileserleuilelysservalargilephe
859095
argsertyrasnglyglyalailetyrprohisileasptyrleuglu
100105110
pheasnglnglyphelysargvalhisleuvalleulysserasparg
115120125
sercysleuasnserglugluasnthrvaltyrhismetleuprogly
130135140
gluvaltrpphevalaspglyhisseralahisseralametserleu
145150155160
serargvalglylystyrserleuvalleuasppheaspserglyala
165170175
lysphegluaspleutyrsergluserhisthrleucysvalaspasn
180185190
leugluproaspileilehisaspargglnproleuprothrserleu
195200205
argaspserleualahisilealagluhisalaaspglupheasnile
210215220
glnserileleupheleualathrargphehisphesertyralaval
225230235240
serileargglutyrpheglnleuleuaspglucyspheserargasn
245250255
protyrlysservalarggluargtyrglualaleulysaspileleu
260265270
valargserglytyrthrserhislyspheasnhispheasnserleu
275280285
serglyvalthrilegly
290
<210>12
<211>47
<212>dna
<213>artificialsequence
<220>
<223>primer
<400>12
gaattcattaaagaggagaaattaaccatgatgagtgcaaaattgtt47
<210>13
<211>47
<212>dna
<213>artificialsequence
<220>
<223>primer
<400>13
caacaggagtccaagctcagctaattattaaccaatagtgactccag47
- 还没有人留言评论。精彩留言会获得点赞!