广谱结合流感病毒A的重组抗体片段及其制备方法与应用与流程
本发明属于抗体应用技术领域。涉及广谱流感病毒A人源重组抗体 设计及制备的潜在用途。具体地说是广谱结合流感病毒A的重组抗体片段及其制备方法与应用。
背景技术:
流行性感冒病毒(influenza virus)分为甲(A)、乙(B)、丙(C )3个型,其中甲型流感病毒不仅可以感染人,还可以感染与人类生活密切相关的马、猪等哺乳动物、鸟类和家禽类,因此甲型流感病毒可引起跨种间、爆发式的大范围流行感冒,严重威胁人类生命健康。流感病毒的外膜上有两种蛋白,一种为血凝素(hemagglutinin,HA),一种为神经氨酸酶(neuraminidase,NA),两者均易发生变异,导致流感病毒血清型众多,变异速度较快,成为流感预防和治疗的困惑。因此,开发广谱抗流感抗体具有重要的临床需求。
HA为一种糖蛋白,在病毒侵染细胞时发挥重要作用。HA蛋白的头部与细胞面膜的唾液酸结合,病毒被细胞内吞进入细胞内,随后HA的发生构象改变,使病毒囊膜与细胞膜融合,病毒基因就释放在细胞内。目前临床应用中的抗流感病毒HA抗体主要针对HA的头部结合,由于HA头部是高度可变区。因此,很多抗体不具有广谱抗流感的作用。
CR6261是近年来通过噬菌体展示技术筛选获得的中和抗体,能够抵御多种亚型的流感病毒,包括中和H1、H2、H5、H6、H8和H9亚型病毒[1]。已有报道证实CR6261抗体 是通过与HA2中非常保守的A螺旋结合,抑制了病毒的膜融合过程,发挥抗病毒功效,并且抗体轻链与病毒的中和效果无关[2-5]。因此,针对流感病毒蛋白HA的保守区,有望开发一种广谱的流感治疗用抗体。
本发明基于对流感病毒蛋白HA保守区和CR6261的相互作用构效关系 [3-5],采用计算机设计结合当今抗体生物信息学,设计出抗流感病毒蛋白HA保守区抗体片段序列,即VH和scFv序列,并在VH序列的基础上,设计和表达了VH抗体的三聚体等分子形式,获得新型广谱抗流感病毒蛋白HA保守区的小分子抗体。
技术实现要素:
为了实现上述目的,本发明公开了针对流感病毒A保守区的VH和scFv两类抗体的氨基酸序列、核苷酸序列及其VH-trimer的不同分子结构,以及涉及这些流感抗体的制备方法及其用途。
本发明公开了一种广谱结合流感病毒A的重组抗体,其特征在于它包含一组人源化重组流感病毒A 抗体片段;所述抗体片段包括重组形式 的VH、(VH)2、(VH)3、scFv、Fab、 Fab'、 F(ab')、IgG的形式。
本发明所述抗体片段为融合其它蛋白质或多肽或小分子标记物的形式。
其中所述重组单链抗体片段包含轻链、重链及一种结构柔性连接肽具有SEQ ID NO:1所示的氨基酸序列,SEQ ID NO:2所示的核苷酸序列。
所述重组抗体片段的单域重组抗体为只含重链可变区 (VH) , 无轻链可变区, 具有ID NO:3所示的氨基酸序列,具有SEQ ID NO:4所示的核苷酸序列。
所述体重组抗体单域片段的重链可变区VH可与其他蛋白,如与异亮氨酸拉链(isoleucine-zipper)融合, 形成具有SEQ ID NO: 5所示的氨基酸序列,具有SEQ ID NO:6所述的核苷酸序列。
本发明所述抗体片段融合形成同源VH三聚体,VH三聚体指的是同源三条VH,通过异亮氨酸拉链形成非共价键的同源三聚体,它们之间的重量份数比为1:1:1。
本发明所述的广谱结合流感病毒A的重组抗体,其特征在于所述抗体特异性结合到流感病毒A的血凝素上,其亲和力不低于10-7M。
本发明进一步公开了一种药物组合物,它含有广谱结合流感病毒A的重组抗体及与抗体相容的药学上可接受的载体。包括肌内注射、静脉内注射或局部给药、透皮吸收给药、喷雾给药。
本发明更进一步公开了广谱结合流感病毒A的重组抗体在制备作为治疗流感病毒A保守区的VH和scFv两类抗体药物中的应用。
试验结果显示:
(1)VH和scFv抗体针对流感病毒A抗原,如N5H1、N5H2等常见流感病毒抗原具有特异性结合力,其亲和力不低于10-7M。
(2)VH抗体制备为三聚体后,对抗原的结合力提高了10倍。
(3)VH抗体组装为scFv形式后,抗体更为稳定,对抗原的结合力达到10-10M。
本发明公开的广谱结合流感病毒A的重组抗体也可以作为检测流感病毒A的试剂盒。
本发明还提供了VH抗体三聚体(VH-trimer)形式。 此外,VH抗体和scFv抗体序列可开发的其他形式的重组抗体,所述VH和scFv抗体还可以是与其它蛋白质或多肽或小分子标记物的融合形式,如与Fc片段或PEG修饰的抗体
本发明的抗体的核苷酸序列通常可以用PCR扩增法、重组法或人工合成的方法获得。一种简单可行的方法是用人工合成的方法来合成有关序列,尤其是片段长度较短时。本发明优先VH和scFv抗体为合成方法制备目标基因序列。
有关序列如下:
SEQ ID NO:1 单链scFv抗体片段氨基酸序列
EIVMTQSPSTLSASVGDRVIITCSGSSSNIGNDYVSWYQQKPGKAPKLLIYDNNKRPSGVPSRFSGSGSGTEFTLTISSLQPDDFATYYCATWDRRPTAYVVFGQGTKLTVLKRGGGGGSGGGGSGGGGSGGGGSEVQLVESGGGLVQPGGSLRLSCTVSGGPFRSYAISWVRQAPGKGLEWVGGIIPIFGTTKYAPKFQGRFTISKDDFAGTVYLQMNSLRAEDTAVYYCARHMGYQVRETMDVWGQGTLVTVSSHHHHHHLGGCDE
SEQ ID NO:2 单链scFv抗体片段核苷酸序列
GAAATCGTTATGACCCAGTCTCCGTCTACCCTGTCTGCGTCTGTTGGTGACCGTGTTATC ATCACCTGCTCTGGTTCTTCTTCTAACATCGGTAACGACTACGTTTCTTGGTACCAGCAG AAACCGGGTAAAGCGCCGAAACTGCTGATCTACGACAACAACAAACGTCCGTCTGGTGTT CCGTCTCGTTTCTCTGGTTCTGGTTCTGGTACCGAATTCACCCTGACCATCTCTTCTCTG CAGCCGGACGACTTCGCGACCTACTACTGCGCGACCTGGGACCGTCGTCCGACCGCGTAC GTTGTTTTCGGTCAGGGTACCAAACTGACCGTTCTGAAACGTGGTGGTGGTGGTGGTTCT GGTGGTGGTGGTTCTGGTGGTGGTGGTTCTGGTGGTGGTGGTTCTGAAGTTCAGCTGGTT GAATCTGGTGGTGGTCTGGTTCAGCCGGGTGGTTCTCTGCGTCTGTCTTGCACCGTTTCT GGTGGTCCGTTCCGTTCTTACGCGATCTCTTGGGTTCGTCAGGCGCCGGGTAAAGGTCTG GAATGGGTTGGTGGTATCATCCCGATCTTCGGTACCACCAAATACGCGCCGAAATTCCAG GGTCGTTTCACCATCTCTAAAGACGACTTCGCGGGTACCGTTTACCTGCAGATGAACTCT CTGCGTGCGGAAGACACCGCGGTTTACTACTGCGCGCGTCACATGGGTTACCAGGTTCGT GAAACCATGGACGTTTGGGGTCAGGGTACCCTGGTTACCGTTTCTTCTCACCACCACCAC CACCACCTGGGTGGTTGCGACGAA
SEQ ID NO:3 单域VH重链抗体片段氨基酸序列
QVQLVESGGGLVQPGGSLRLSCKASGGPFRSYAISWVRQAPGKGLEWMGGIIPIFGTTKYAPKFQGRFTISRDDFAGTVYLQMNSLRAEDTAMYYCAKHMGYQVRETMDVWGQGTLVTVSSLGGCDPHHHHHH*
SEQ ID NO:4 单域VH重链抗体片段核苷酸序列
CAGGTTCAGCTGGTTGAATCTGGTGGTGGTCTGGTTCAGCCGGGTGGTTCTCTGCGT CTGTCTTGCAAAGCGTCTGGTGGTCCGTTCCGTTCTTACGCGATCTCTTGGGTTCGTCAG GCGCCGGGTAAAGGTCTGGAATGGATGGGTGGTATCATCCCGATCTTCGGTACCACCAAA TACGCGCCGAAATTCCAGGGTCGTTTCACCATCTCTCGTGACGACTTCGCGGGTACCGTT TACCTGCAGATGAACTCTCTGCGTGCGGAAGACACCGCGATGTACTACTGCGCGAAACAC ATGGGTTACCAGGTTCGTGAAACCATGGACGTTTGGGGTCAGGGTACCCTGGTTACCGTT TCTTCTCTGGGTGGTTGCGACCCGCACCACCACCACCACCACTAA
SEQ ID NO:5
单域VH重链抗体片段三聚体氨基酸序列
EQKLISEEDLMQVQLVESGGGLVQPGGSLRLSCKASGGPFRSYAISWVRQAPGKGLEWMGGIIPIFGTTKYAPKFQGRFTISRDDFAGTVYLQMNSLRAEDTAMYYCAKHMGYQVRETMDVWGQGTLVTVSSGGGSQRMKQIEDKIEEILSKIYHIENEIARIKKLVGEHHHHHH**
SEQ ID NO:6
单域VH重链抗体片段三聚体核苷酸序列
GAACAGAAACTGATCTCTGAAGAAGACCTGCAGGTTCAGCTGGTTGAATCTGGTGGTGGTCTGGTTCAGCCGGGTGGTTCTCTGCGTCTGTCTTGCAAAGCGTCTGGTGGTCCGTTCCGT TCTTACGCGATCTCTTGGGTTCGTCAGGCGCCGGGTAAAGGTCTGGAATGGATGGGTGGT ATCATCCCGATCTTCGGTACCACCAAATACGCGCCGAAATTCCAGGGTCGTTTCACCATC TCTCGTGACGACTTCGCGGGTACCGTTTACCTGCAGATGAACTCTCTGCGTGCGGAAGAC ACCGCGATGTACTACTGCGCGAAACACATGGGTTACCAGGTTCGTGAAACCATGGACGTT TGGGGTCAGGGTACCCTGGTTACCGTTTCTTCTGGTGGTGGTTCTCAGCGTATGAAACAG ATCGAAGACAAAATCGAAGAAATCCTGTCTAAAATCTACCACATCGAAAACGAAATCGCG CGTATCAAAAAACTGGTTGGTGAACACCACCACCACCACCACTAATAA
说明:斜线序列为构建三聚体时N-端引入的通用Myc 检测标签。
一旦获得了有关的序列,也可以用重组法来大批量的获得有关的其他分子组合,如序列二聚体、IgG等分子。随后通常是将其DNA序列克隆入载体(例如pET22(b)、pET32),再转入细胞(例如BL21(DE3)、Rossetta细胞),然后通过常规的方法从增殖后的宿主细胞中分离得到。此外可以通过PCR法或化学法将任意设计的突变引入本发明的蛋白序列中。
本发明还涉及包含上述的适当DNA序列以及适当启动子、二聚体和三聚体等控制序列的设计及载体,这些载体可以用于转化适当的宿主细胞,以使能够表达蛋白。
宿主细胞可以是原核细胞,如细菌细胞,或是低等真核细胞,如酵母细胞;或是高等真核细胞,如哺乳动物细胞。代表性例子有:大肠杆菌,链霉菌属,真菌细胞如酵母,哺乳动物细胞如CHO、COS或293细胞(商业购买)。
用重组DNA转化宿主细胞可以用本领域技术人员熟知的常规技术进行。当宿主为原核生物如大肠杆菌时,能吸收DNA的感受态细胞可在指数生长期后收获,用CaCl2法处理或电转移技术,所用的步骤在本领域众所周知。当宿主是真核细胞,可选用如下的 DNA转染方法:磷酸钙共沉淀法,常规机械方法如显微注射、电穿孔、脂质体等。
获得的转化子可以用常规的方法培养,获得本发明基因编码的多肽。根据所用的宿主细胞,培养中所用的培养基可选自常规培养基或改良培养基。在适于宿主细胞生长的条件下进行培养。当宿主细胞生长到适当的细胞密度后,用合适的方法(如温度转换或化学诱导)诱导选择的启动子,将细胞再培养一段时间。
在上面的方法中的种族多肽可在细胞内、或在细胞膜上表达、或分泌到细胞外。如果需要,可利用物理的、化学的和其他特性通过各种分离方法分离和纯化重组的蛋白。这些方法是本领域技术人员所熟知的。包括但不限于:常规的复兴处理、用蛋白沉淀剂处理(盐析方法)、离心、渗透破菌、超声波处理、超离心、分子筛层析(凝胶过滤)、吸附层析、离子交换层析、高效液相层析(HPLC)和其它各种液相层析技术及这些方法的结合。
本发明进一步公开了一种药物组合物,它含有所述的广谱结合流感病毒A的重组抗体及与抗体相容的药学上可接受的载体。药学上可接受的载体应该与本发明的抗体相容,即能与其共混而不会在通常情况下大幅度降低药物组合物的效果,药物制剂与给药方式相匹配。药理学上可接受的载体包括一种或多种药用赋形剂,例如粘合剂、稀释剂、崩解剂、防腐剂、分散剂、助流剂和润滑剂。可作为药学上可接受的载体或其组分的一些物质的具体例子是盐水、缓冲液,糖类,如乳糖、葡萄糖和蔗糖;麦芽、明胶;多元醇,如丙二醇、甘油、山梨酸醇、甘油糖醇和聚乙二醇,海藻酸;乳化剂,如Tween;润湿剂,如月桂酸硫酸钠;稳定剂;抗氧化剂;防腐剂;无热原水;等渗盐溶液;和磷酸盐缓冲液等。
本发明所述的注射剂,主要包括肌内注射,例如分针注射液、水针注射,可以是静脉内注射或局部给药、透皮吸收给药、喷雾给药、药膜等等。静脉内注射包括大输液、小输液、皮试、粉针等等。
注射液中,活性成分的浓度为50mg/ml-0.5mg/ml,优选5-30mg/ml格。Ok
2. 赋形剂是指甘露醇、低分子右旋糖苷、山梨醇、 聚乙二醇、 吐温、 葡萄糖、 乳糖、半乳糖、甘氨酸的一种或几种的混合物,优选甘露醇、乳糖 、葡萄糖。Ok
3. PH调节剂是:tris、磷酸、等非挥发性的酸。以及氢氧化钠、、碳酸钠或钾或铵盐、磷酸钠或钾或铵盐、、乙酸钠或铵盐等生理可接受的有机或无机酸和碱及盐,优选枸橼酸、磷酸、氢氧化钾、氢氧化钠。
4. 增溶剂是:PEG6000、PEG4000、吐温20-80、十二烷基硫酸钠、三羟甲基氨基甲烷等,优选PEG6000、PEG4000、精氨酸。
5. 抗氧剂是:含有无机硫或有机硫的抗氧剂;无机硫抗氧剂为亚硫酸盐,如亚硫酸钠、亚硫酸钾、焦亚硫酸钠、硫代硫酸钠、亚硫酸氢钠、亚硫酸氢钾;有机硫抗氧剂为硫代甘油、硫脲素、2-巯基乙醇、2-巯基丙醇、1-硫代山梨糖醇;本发明所述的抗氧剂必须是医药上允许的,且本身不具有生物活性或药理活性,特别优选亚硫酸盐,如亚硫酸钠、亚硫酸钾、焦亚硫酸钠、硫代硫酸钠、亚硫酸氢钠、硫代甘油、硫脲素。
6. 滲透压调节剂,是氯化钠、氯化钾的一种或两种的组合。
本发明公开的广谱结合流感病毒A的重组抗体及其制备方法与应用所具有的积极效果在于:
(1)抗体为人源化的分子小,免疫原性低,药物的安全性高。
(2)小分子抗体采用相对廉价的E.coli细胞制备,制造成本较低。
(3)本抗体针对流感病毒A的保守区,适应范围较广,有效性稳定。
附图说明
图1: VH单域抗体的ELISA 结合曲线;
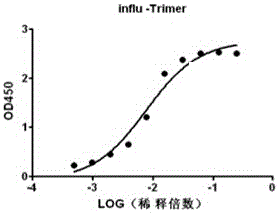
图2:VH单域三聚体抗体的ELISA 结合曲线;
图3:单链抗体的ELISA 结合曲线。
具体实施方式
下面通过具体的实施方案叙述本发明。除非特别说明,本发明中所用的技术手段均为本领域技术人员所公知的方法。另外,实施方案应理解为说明性的,而非限制本发明的范围,本发明的实质和范围仅由权利要求书所限定。对于本领域技术人员而言,在不背离本发明实质和范围的前提下,对这些实施方案中的物料成分和用量进行的各种改变或改动也属于本发明的保护范围。
本文所用的术语“抗体”片段是有抗体结构特征的蛋白,其中VH单域抗体仅具有抗体重链可变区,分子量约15000道尔顿,scFv单链抗体具有抗体重链和轻链可变区通过连接肽(GGGGS)4形成,分子量约28000。VH 三聚体是VH单域抗体通过 Ziplinker肽实现的产物。
实施例1.
抗体序列的设计及合成
采用计算机设计手段,分别设计出SEQ ID NO:1和SEQ ID NO:3抗体的氨基酸序列。然后根据E.coli细胞密码子偏性,设计出适宜E.coli细胞异原表达的SEQ ID NO:2 和SEQ ID NO:4核苷酸序列。将SEQ ID NO:2 VH和SEQ ID NO:4序列送基因合成公司,合成后的基因与pET22(b)载体连接。克隆质粒通过电转化(电压1.9KV,Resistance 200Ω Cuvette 1mm,TC 5ms)至BL21(DE3)感受态细胞,细胞涂布在氨苄抗性的LB固体平板,挑取了10株单菌落,菌落PCR鉴定阳性克隆。
实施例2.
克隆菌表达鉴定
菌体培养:分别挑单克隆菌分别接种于2 ml含50 ng/L Amp的LB培养基试管中,37 ℃振荡培养过夜,按5%接种量接种于25 ml/100 ml三角瓶的2YT(含50 ng/L Amp)培养基中,37 ℃ 240 rpm振荡培养至对数生长期,加入终浓度为0.5 mmol/L异丙基硫代半乳糖苷(IPTG)诱导,37 ℃ 240 rpm振荡继续培养5 h,1 300×g离心10 min收集菌体。Bugbuster液抽提菌体中的可溶性scFv抗体,蛋白质印迹检测阳性表达克隆。
实施例3
抗体样品的制备
抗体放大制备:按照400 ml/2000ml三角瓶体积培养细胞,制备条件同1实施例3。离心收集菌体,按5 ml/g菌体重悬于破碎缓冲液(0.3 mol/L NaCl,50 mmol/L NaH2PO4·2H20,10 mmol/L咪唑)中,超声波破碎99次(工作4 s,停顿5 s),4 ℃,13 000g离心20 min,收集上清。
针对VH及VH-trimer单域抗体纯化:第一步用hitrap his预装柱纯化抗体,上样缓冲液(同破碎缓冲液)平衡5个柱体积(CV),上样50 ml,上样缓冲液冲洗5 CV,然后用洗涤缓冲液(50 mmol/L NaH2PO4、0.3 mol/L NaCL、50 mmol/L咪唑,pH 8.0)10 CV,最后用洗脱缓冲液(500 mmol/L咪唑,其余同洗涤缓冲液)洗脱,收集组分与bufferA (Tris 50mM,NaCl 200 mM,pH8.0)中。第二步采用hiscreen capto Adheree预装柱纯化抗体,bufferA 样品上样,并洗涤5CV(柱体积),buffer B (Tris 50mM,NaCl 1M,pH8.0)洗涤5CV,buffer C(NaAC 50mM, NaCl 200 mM,pH5.0)洗涤5CV,最后用100% buffer D (NaAC 50mM,pH5.0)洗脱。分别得到VH单域抗体4-6mg/L ,获得VH 三聚体产量为4-8mg/L。
针对scFv单链抗体纯化:第一步用protein L预装柱纯化抗体,上样缓冲液(同破碎缓冲液)平衡5个柱体积(CV),上样50 ml,用buffer A(PBS+0.1M甘氨酸, pH 8.0)洗涤5 CV,然后用buffer B(柠檬酸 50mM,pH 3.5)洗涤5 CV,最后用buffer C(柠檬酸 50mM,pH 3.0)洗脱到第二步纯化用的buffer A溶液中。第二步采用hiscreen capto Adhere预装柱纯化抗体,bufferA 样品上样,并洗涤5CV(柱体积),buffer B (Tris 50mM,NaCl 1M,pH8.0)洗涤5CV,buffer C(NaAC 50mM, NaCl 200 mM,pH5.0)洗涤5CV,最后用buffer D (NaAC 50mM,pH5.0)洗脱。得到10-18mg/L 发酵液。
实施例4.
酶联免疫吸附法检测抗原抗体结合力
酶联免疫吸附法(ELISA)检测目标抗体的结合活性:10 µg/ml的流感病毒蛋白(H5N2)包被ELISA板孔,4 ℃过夜。含2% BSA的PBS在37 ℃封闭1 h。每孔加入100 µl纯化的可溶性抗体,37 ℃孵育1 h。100 µl用PBST稀释(1:4 000)的抗-His抗体-HRP,37 ℃孵育1 h。100 µl TMB显色,100 µl 1 mol/L HCl终止显色反应,酶标仪于450 nm波长读数。
(1)VH单域抗体的ELISA 结合曲线:详见图1的 VH单域抗体的ELISA 结合曲线;
未稀释样品蛋白浓度为48.4ug/ml,按2倍稀释法稀释10个梯度。
表1 VH单域抗体的ELISA 吸收值检测结果:
(2)VH单域三聚体抗体的ELISA 结合曲线,详见图2:VH单域三聚体抗体的ELISA 结合曲线亲和力KD=6.85x10-9 M。
表2 VH单域三聚体抗体的ELISA 吸收值结果
未稀释样品蛋白浓度为1.93ug/ml,按2倍稀释法稀释8个梯度;
(3)单链抗体的ELISA 结合曲线,详见图3:单链抗体的ELISA 结合曲线。亲和力KD=2.0x10-10M。未稀释样品蛋白浓度为0.28ug/ml,按2倍稀释法稀释10个梯度
表3 单链抗体的ELISA 吸收值结果:
结果显示:
单域VH抗体及其三聚体以及单链抗体对流感病毒蛋白(H5N2)具有良好的特异性和结合力。
实施例5
无菌条件下量取 2mg/ml的纯化抗体5ml,按下述配方加入辅料,使得原液最终成份为:10mg 抗体。 50mM tris ,100mM Glycine,10mM NaCl,25mM arginine,PH 7.5 ,4℃磁力搅拌10分钟,移液器精准分装至20ml灭菌、除热源的西林瓶中,盖塞,置于冻干机冻干。冻干条件:预冻阶段:-40℃,4小时。主干燥阶段:-40℃,10分钟;-30℃,25小时;-10℃,9小时。终极干燥阶段:20℃,3小时。冻干结束后,真空下压盖,即得到产品。
参考文献:
1. Throsby M,Van Den Brink E,et al.heterosubtypic neutralizing monoclonal antibodies cross-protective against H5N1 and H1N1recovered from human IgM+ memory B cells.PLos One. 2008,3(12):e3942
2.Ekiert DC ,et al. Antibody recognition of a highly conserved influenza virus epitope.Science.2009.324(59240246-251.
3. Anvir,Y at al., (2014) Molecular Signatures of Hemagglutinin Stem-Directed Heterosubtypic Human Neutralizing Antibodies against Influenza A Viruses. PLOS Pathogens. e1004103.
4. Cui, W et al., (2012) The Molecular Mechanism of Action of the CR6261-Azichromycin Combination Found through Computational Analysis PLOS one e37790.
5. Lingwood, D et al., (2012) Structural and genetic basis for development of broadly neutralizing influenza antibodies. Nature 489, 566-571。
<110> 晋明(天津)生物医药技术有限公司
<120> 广谱结合流感病毒A的重组抗体片段及其制备方法与应用
<160> 6
<170> PatentIn version 3.5
<210> 1
<211> 268
<212> PRT
<213> 单链scFv抗体片段
<400> 1
Glu Ile Val Met Thr Gln Ser Pro Ser Thr Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Ile Ile Thr Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn
20 25 30
Asp Tyr Val Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu
35 40 45
Leu Ile Tyr Asp Asn Asn Lys Arg Pro Ser Gly Val Pro Ser Arg Phe
50 55 60
Ser Gly Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu
65 70 75 80
Gln Pro Asp Asp Phe Ala Thr Tyr Tyr Cys Ala Thr Trp Asp Arg Arg
85 90 95
Pro Thr Ala Tyr Val Val Phe Gly Gln Gly Thr Lys Leu Thr Val Leu
100 105 110
Lys Arg Gly Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly
115 120 125
Gly Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Val Glu Ser Gly Gly
130 135 140
Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser Cys Thr Val Ser
145 150 155 160
Gly Gly Pro Phe Arg Ser Tyr Ala Ile Ser Trp Val Arg Gln Ala Pro
165 170 175
Gly Lys Gly Leu Glu Trp Val Gly Gly Ile Ile Pro Ile Phe Gly Thr
180 185 190
Thr Lys Tyr Ala Pro Lys Phe Gln Gly Arg Phe Thr Ile Ser Lys Asp
195 200 205
Asp Phe Ala Gly Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Ala Glu
210 215 220
Asp Thr Ala Val Tyr Tyr Cys Ala Arg His Met Gly Tyr Gln Val Arg
225 230 235 240
Glu Thr Met Asp Val Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
245 250 255
His His His His His His Leu Gly Gly Cys Asp Glu
260 265
<210> 2
<211> 804
<212> DNA
<213> 人工序列
<400> 2
gaaatcgtta tgacccagtc tccgtctacc ctgtctgcgt ctgttggtga ccgtgttatc 60
atcacctgct ctggttcttc ttctaacatc ggtaacgact acgtttcttg gtaccagcag 120
aaaccgggta aagcgccgaa actgctgatc tacgacaaca acaaacgtcc gtctggtgtt 180
ccgtctcgtt tctctggttc tggttctggt accgaattca ccctgaccat ctcttctctg 240
cagccggacg acttcgcgac ctactactgc gcgacctggg accgtcgtcc gaccgcgtac 300
gttgttttcg gtcagggtac caaactgacc gttctgaaac gtggtggtgg tggtggttct 360
ggtggtggtg gttctggtgg tggtggttct ggtggtggtg gttctgaagt tcagctggtt 420
gaatctggtg gtggtctggt tcagccgggt ggttctctgc gtctgtcttg caccgtttct 480
ggtggtccgt tccgttctta cgcgatctct tgggttcgtc aggcgccggg taaaggtctg 540
gaatgggttg gtggtatcat cccgatcttc ggtaccacca aatacgcgcc gaaattccag 600
ggtcgtttca ccatctctaa agacgacttc gcgggtaccg tttacctgca gatgaactct 660
ctgcgtgcgg aagacaccgc ggtttactac tgcgcgcgtc acatgggtta ccaggttcgt 720
gaaaccatgg acgtttgggg tcagggtacc ctggttaccg tttcttctca ccaccaccac 780
caccacctgg gtggttgcga cgaa 804
<210> 3
<211> 133
<212> PRT
<213> 单域VH重链抗体片段
<400> 3
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Lys Ala Ser Gly Gly Pro Phe Arg Ser Tyr
20 25 30
Ala Ile Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met
35 40 45
Gly Gly Ile Ile Pro Ile Phe Gly Thr Thr Lys Tyr Ala Pro Lys Phe
50 55 60
Gln Gly Arg Phe Thr Ile Ser Arg Asp Asp Phe Ala Gly Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Met Tyr Tyr Cys
85 90 95
Ala Lys His Met Gly Tyr Gln Val Arg Glu Thr Met Asp Val Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Leu Gly Gly Cys Asp Pro His
115 120 125
His His His His His
130
<210> 4
<211> 402
<212> DNA
<213> 人工序列
<400> 4
caggttcagc tggttgaatc tggtggtggt ctggttcagc cgggtggttc tctgcgtctg 60
tcttgcaaag cgtctggtgg tccgttccgt tcttacgcga tctcttgggt tcgtcaggcg 120
ccgggtaaag gtctggaatg gatgggtggt atcatcccga tcttcggtac caccaaatac 180
gcgccgaaat tccagggtcg tttcaccatc tctcgtgacg acttcgcggg taccgtttac 240
ctgcagatga actctctgcg tgcggaagac accgcgatgt actactgcgc gaaacacatg 300
ggttaccagg ttcgtgaaac catggacgtt tggggtcagg gtaccctggt taccgtttct 360
tctctgggtg gttgcgaccc gcaccaccac caccaccact aa 402
<210> 5
<211> 175
<212> PRT
<213> 单域VH重链抗体片段
<400> 5
Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Met Gln Val Gln Leu Val
1 5 10 15
Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly Ser Leu Arg Leu Ser
20 25 30
Cys Lys Ala Ser Gly Gly Pro Phe Arg Ser Tyr Ala Ile Ser Trp Val
35 40 45
Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Met Gly Gly Ile Ile Pro
50 55 60
Ile Phe Gly Thr Thr Lys Tyr Ala Pro Lys Phe Gln Gly Arg Phe Thr
65 70 75 80
Ile Ser Arg Asp Asp Phe Ala Gly Thr Val Tyr Leu Gln Met Asn Ser
85 90 95
Leu Arg Ala Glu Asp Thr Ala Met Tyr Tyr Cys Ala Lys His Met Gly
100 105 110
Tyr Gln Val Arg Glu Thr Met Asp Val Trp Gly Gln Gly Thr Leu Val
115 120 125
Thr Val Ser Ser Gly Gly Gly Ser Gln Arg Met Lys Gln Ile Glu Asp
130 135 140
Lys Ile Glu Glu Ile Leu Ser Lys Ile Tyr His Ile Glu Asn Glu Ile
145 150 155 160
Ala Arg Ile Lys Lys Leu Val Gly Glu His His His His His His
165 170 175
<210> 6
<211> 528
<212> DNA
<213> 人工序列
<400> 6
gaacagaaac tgatctctga agaagacctg caggttcagc tggttgaatc tggtggtggt 60
ctggttcagc cgggtggttc tctgcgtctg tcttgcaaag cgtctggtgg tccgttccgt 120
tcttacgcga tctcttgggt tcgtcaggcg ccgggtaaag gtctggaatg gatgggtggt 180
atcatcccga tcttcggtac caccaaatac gcgccgaaat tccagggtcg tttcaccatc 240
tctcgtgacg acttcgcggg taccgtttac ctgcagatga actctctgcg tgcggaagac 300
accgcgatgt actactgcgc gaaacacatg ggttaccagg ttcgtgaaac catggacgtt 360
tggggtcagg gtaccctggt taccgtttct tctggtggtg gttctcagcg tatgaaacag 420
atcgaagaca aaatcgaaga aatcctgtct aaaatctacc acatcgaaaa cgaaatcgcg 480
cgtatcaaaa aactggttgg tgaacaccac caccaccacc actaataa 528
- 还没有人留言评论。精彩留言会获得点赞!