一种环状探针和基于环状探针捕获的测序文库构建方法与流程
本发明涉及分子生物学
技术领域:
,具体涉及一种环状探针和基于环状探针捕获的测序文库构建方法。
背景技术:
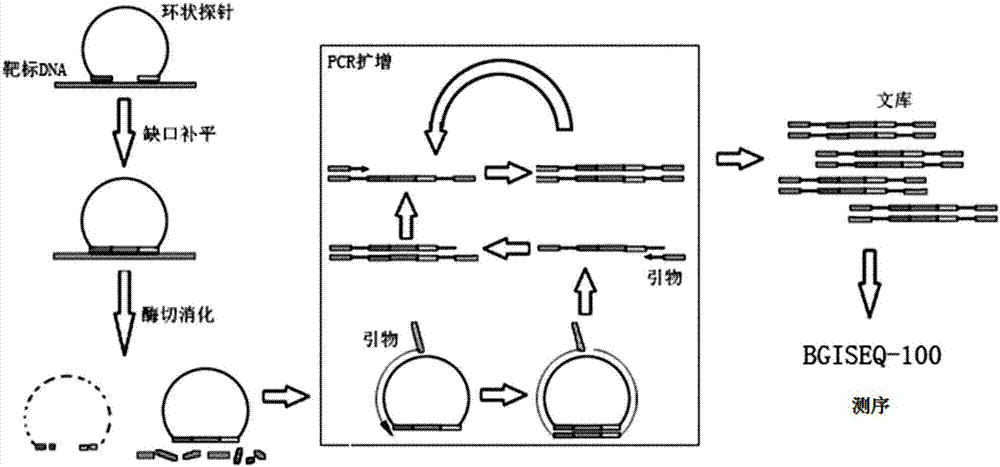
:随着测序技术发展,第二代测序(ngs)迅猛发展,依靠着高通量的特点,成为了研究dna和rna的主要工具。在ngs中,人们可以同时对高达1亿条核酸序列进行同步的测序,在碱基上的通量到达了gb的数量级,对整个基因组进行测序(wgs)也变得越来越常规。尽管在技术上可以做到wgs,但是测序时间和测序花销却是限制其应用的因素。通过对特定感兴趣区域进行捕获,既可以避免不需的序列信息占据结果中的大部分,降低所需数据量最终节省成本,也可以提高特定区域的测序深度,从而提供更有价值的信息。对特定感兴趣区域进行捕获,现有主流技术方案有两种:nimblegenseqcap技术方案和ampliseq技术方案。nimblegenseqcap技术方案,捕获对象为已经添加接头的文库,通过对目标区域设计长度为50-105bp的带标记线性探针,经杂交对目标区域片段进行富集,然后进行高通量测序。整个流程包括常规流程的文库构建、标记探针杂交、磁珠分离、目标文库洗脱、目标文库的二次扩增。ampliseq技术方案,在建库之间对目标区域进行扩增,以增加对测序结果中目标区域的检出。技术针对每一个目标区域设计一对或多对引物,这些引物的扩增产物末端之间有重叠,使得每个区域对应的pcr产物可以覆盖整个区域。pcr之后,对pcr进行常规的ngs建库以及测序。由于经过了指数扩增,目标区域的核酸在总核酸中占的比例大大提升,因此能用于低频率突变的检测等应用。nimblegenseqcap技术方案的缺点有以下几点:(1)捕获效率低,全外芯片平均捕获效率在50%-60%,小芯片捕获效率平均在40%;(2)芯片成本高昂,单个反应价格最低为1200元以上,加上洗脱试剂,单次试验成本大于1500元;(3)试验操作复杂繁琐,稳定性差,不利于产业化推广;(4)不适用较小区域的捕获,区域越小捕获效果越差。ampliseq技术方案的缺点有以下几点:(1)多重pcr技术存在稳定性缺陷,不同引物扩增效率差异较大,不能有效反映不同靶标之间量的差异;(2)不适用于已经片段化样本,对片段化样本灵敏性大大降低;(3)复杂区域引物效率低下,很难捕获到;(4)pcr扩增循环数高,引入的pcr错误会影响低频检测。技术实现要素:本发明提供一种环状探针和基于环状探针捕获的测序文库构建方法,具有高效、低成本、均一性好、简便快捷的优势。根据第一方面,一种实施例中提供一种基于环状探针捕获的测序文库构建方法,包括:将环状探针与靶标核酸退火杂交,其中上述环状探针为线性核酸探针,其包括两个末端的特异性臂区和中间的通用序列,其中上述特异性臂区用于与上述靶标核酸杂交,杂交后探针的两个末端首尾相向,上述通用序列用于连接两个末端的特异性臂区并作为通用引物的识别区域;在聚合酶和连接酶的作用下,使上述环状探针的3’末端以上述靶标核酸为模板进行扩增并与5’末端连接形成环状分子;和加入核酸外切酶将线性核酸分子消化。进一步地,上述通用引物是带有测序接头的引物;上述核酸外切酶将线性核酸分子消化之后,加入上述通用引物进行pcr扩增。进一步地,上述通用引物是不带测序接头的引物;上述核酸外切酶将线性核酸分子消化之后,加入上述通用引物进行pcr扩增;上述pcr扩增之后,将扩增产物连接上测序接头。进一步地,上述扩增产物连接上测序接头之后,环化并通过滚环复制制备dna纳米球。进一步地,上述核酸外切酶将线性核酸分子消化之后,通过滚环复制制备dna纳米球。进一步地,上述扩增产物连接上测序接头之后,环化并通过滚环复制制备dna纳米球。进一步地,上述环状探针的两个末端的特异性臂区长度各自为15~30个碱基。进一步地,上述环状探针的中间的通用序列长度从25个碱基到数百个碱基。进一步地,上述环状探针的的gc含量是30~70%,优选40~60%。进一步地,上述环状探针的中间的通用序列中包括一段随机序列。进一步地,上述通用引物的5’端包括不同的酶切位点以适应不同的测序平台接头。根据第二方面,一种实施例中提供一种用于测序文库构建的环状探针,用于与靶标核酸退火杂交,上述环状探针为线性核酸探针,其包括两个末端的特异性臂区和中间的通用序列,其中上述特异性臂区用于与上述靶标核酸杂交,杂交后探针的两个末端首尾相向,上述通用序列用于连接两个末端的特异性臂区并作为通用引物的识别区域。本发明的方法,利用扩增原理,解决了捕获效率低和成本高昂等问题,单个反应成本约为100-200元,利用环状探针解决了引物对数量有限的问题,利用通用引物扩增解决了多重扩增均一性差的问题,该方法操作简单快捷,从核酸提取到上机可以在8时内完成。附图说明图1为本发明一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图;图2为本发明另一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图;图3为本发明又一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图;图4为本发明再一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图;图5为采用本发明的基于环状探针捕获的测序文库构建方法和ampliseq技术分别建库后bgiseq-100平台测序结果对比图,其中,纵坐标为比对上数据库该种病原菌基因组的读段(reads)数量,ec(黑色柱)、ef(灰色柱)、ab(白色柱)分别代表大肠杆菌、屎肠球菌、鲍曼不动杆菌的情况。具体实施方式下面通过具体实施方式结合附图对本发明作进一步详细说明。在以下的实施方式中,很多细节描述是为了使得本发明能被更好的理解。然而,本领域技术人员可以毫不费力的认识到,其中部分特征在不同情况下是可以省略的,或者可以由其他元件、材料、方法所替代。在某些情况下,本发明相关的一些操作并没有在说明书中显示或者描述,这是为了避免本发明的核心部分被过多的描述所淹没,而对于本领域技术人员而言,详细描述这些相关操作并不是必要的,他们根据说明书中的描述以及本领域的一般技术知识即可完整了解相关操作。在本发明中,“环状探针”是线性核酸探针,探针的两个末端是特异性臂区(例如长度为15~30个碱基),特异性臂区可以与靶标核酸杂交,杂交后探针的末端首尾相向,因此称为“环状探针”。中间为通用序列,长度例如从25个碱基到数百个碱基(例如100个、200个、300个、500个、800个碱基等),可以根据两个末端的特异性臂区在靶标核酸中的距离而变化,通用序列的作用在于连接两个末端的特异性臂区以及作为通用引物的识别区域。在一套体系当中,不同探针的通用序列共同识别一对通用引物,因此后续操作可以通过一对通用引物完成不同环状探针的扩增。特异性臂区序列的设计与pcr引物类似,由于针对不同靶标核酸的臂区之间性质不同,退火需要从98℃到56℃梯度下降温度进行。在本发明实施例中,环状探针的gc含量是30~70%,优选40~60%。在优选的实施例中,环状探针的中间的通用序列中包括一段随机序列,以用于确定不同扩增子之间的区别是来源于扩增引入的错误还是核酸多态性。在优选的实施例中,通用引物的5’端包括不同的酶切位点以适应不同的测序平台接头。相对于线性探针的捕获技术,环状探针必须两端都参与退火才能有效连接,增加了反应的特异性。环状探针与基于pcr的富集技术相比,由于两个末端由通用序列相连,可以避免后者不同靶标引物之间交叉导致的非特异性扩增。图1示出了本发明一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图。设计针对靶标区域的特异性环状探针,每条探针的中间环区(黑色)为通用序列,5’末端和3’末端为针对靶标核酸的特异性臂区,与带有靶标序列的dna退火杂交,在聚合酶和连接酶的作用下,探针的3’末端以靶标序列为模板扩增并与5’末端连接,探针构成环状分子。加入核酸外切酶将线性dna分子消化,再加入带有测序接头的引物进行pcr扩增,扩增产物经纯化后即可用于bgiseq-100测序。图2示出了本发明另一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图。设计针对靶标区域的特异性环状探针,每条探针的中间环区(黑色)为通用序列,5’末端和3’末端为针对靶标核酸的特异性臂区,与带有靶标序列的dna退火杂交,在聚合酶和连接酶的作用下,探针的3’末端以靶标序列为模板扩增并与5’末端连接,探针构成环状分子。加入核酸外切酶将线性dna分子消化,再加入针对环区的通用引物进行pcr扩增。之后将扩增产物加上测序接头,即可用于bgiseq-100测序。图3示出了本发明又一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图。设计针对靶标区域的特异性环状探针,每条探针的中间环区(黑色)为通用序列,5’末端和3’末端为针对靶标核酸的特异性臂区,与带有靶标序列的dna退火杂交,在聚合酶和连接酶的作用下,探针的3’末端以靶标序列为模板扩增并与5’末端连接,探针构成环状分子。加入核酸外切酶将线性dna分子消化,再加入针对环区的通用引物进行pcr扩增。之后将扩增产物连接上接头,通过环化(例如借助splitoligo),然后制备dna纳米球(dnb),直接bgiseq-500上机测序。图4示出了本发明再一个实施例中基于环状探针捕获的测序文库构建方法的原理示意图。设计针对靶标区域的特异性环状探针,每条探针的中间环区(黑色)为通用序列,5’末端和3’末端为针对靶标核酸的特异性臂区,与带有靶标序列的dna退火杂交,在聚合酶和连接酶的作用下,探针的3’末端以靶标序列为模板扩增并与5’末端连接,探针构成环状分子。加入核酸外切酶将线性dna分子消化。然后制备dna纳米球(dnb),直接bgiseq-500上机测序。需要说明的是,上述示例性实施方案主要列出目前较为常用的应用平台范围,该技术为基因组通用富集技术,也可以用于其它二代或者三代测序平台,例如proton、pacbio和qiagen测序平台等。以下通过实施例详细说明本发明的技术方案,应当理解,实施例仅是示例性的,不能理解为对本发明保护范围的限制。实施例1:基于bgiseq-100测序平台的病原菌分析分别使用本发明实施例的环状探针技术和ampliseq技术对样品进行测序文库构建,两种技术的文库使用不同的条形码以作区分。在本发明实施例的环状探针技术中,寻找大肠杆菌(ec)、屎肠球菌(ef)、鲍曼不动杆菌(ab)基因组中3个500bp的保守区域,每个区域针对内部序列设计一条环状探针(核酸探针和引物由上海生工生物科技有限公司合成),探针序列如表1所示:表1将大肠杆菌(ec)、屎肠球菌(ef)、鲍曼不动杆菌(ab)的菌液分别提取核酸(采用天根dp-316试剂盒),提取的核酸使用qubitdsdnahsassaykit进行定量并根据各自基因组大小推算提取前的菌体浓度,分别将核酸稀释成相当于1000拷贝/ml的浓度,再将三种核酸按体积等比例混合。本实施例使用的试剂信息如下表2所示:表21、探针退火将环状探针(ec_1~ab_3)以相同摩尔浓度混合,加入提取的基因组dna样品中,形成如下表3所示的反应体系,加热到98℃逐渐梯度降温到56℃,并在56℃保持2小时,使dna样品中的双链打开并逐渐与环状探针杂交。表3示出了探针退火的反应体系和程序:表32、缺口补平退火杂交完成后,配置如下表4所示的反应体系,并将该反应体系加入到探针退火后的反应体系中,混匀,按照表4所示的反应程序进行反应,使探针的3’末端延伸并与5’末端连接,探针环化。表43、外切酶消化往产物中加入1μlexoi(20u/μl)、1μlexoiii(100u/μl),按照如下表5所示的反应程序进行反应,消化体系内的线性核酸,之后80℃孵育10分钟使外切酶失活。表54、pcr扩增配置如下表6所示的pcr反应体系,并按照表6所示的反应程序反应,对环化的探针进行pcr扩增。表65、纯化pcr产物通过axygen磁珠进行纯化,获得文库。具体包括如下步骤:(1)将pcr产物用水补足到100μl并加入80μl(0.8倍)axygen磁珠,充分混匀后室温静置5min;(2)将上一步溶液——磁珠混合物短暂离心后置于磁力架上2min,小心将上清转移到新的1.5mlep管;(3)往上一步的上清中加入20μl(原体积的0.2倍)axygen磁珠,充分混匀后室温静置5min,短暂离心后置于磁力架上2min,小心弃去上清;(4)小心加入500μl80%乙醇,并旋转离心管以充分洗涤磁珠(旋转次数一般为2次),洗涤之后静止1min,吸弃乙醇;(5)重复步骤(4)一次;(6)小心吸弃乙醇之后室温晾干(时间长短与室内湿度有关,一般为5min),至磁珠表面哑光;(7)加入20μleb溶液(多次小心吹打混匀磁珠),静止5min(间隔轻弹管壁混匀);(8)短暂离心(时间稍长磁珠晾干的时间可能更短)后置于磁力架上2min,小心吸取溶液至新的1.5ml离心管中。6、上机测序将纯化的dna文库稀释至合适浓度,与ampliseq技术构建的文库按照等摩尔浓度混合,用bgiseq-100平台上机测序分析。下机数据与三种病原菌的基因组比对,将仅能比上一种病原的读段进行计数,统计不同技术中三种病原菌的读段情况(参见图5),结果显示环状探针技术建库的测序结果中不同病原菌之间的差异较小。然而,在ampliseq技术建库的结果中,三种相同浓度的菌在测序结果中数据量之间的差异较大,说明ampliseq技术建库中引物对扩增效率存在一定差异,导致扩增不均一性的发生。实施例2:基于bgiseq-500测序平台的病原菌分析本发明实施例中,基于bgiseq-500平台的技术原理,在文库构建阶段可以去除文库pcr步骤,缩短病原菌分析的时间,更快速地获得分析结果。在本发明实施例的环状探针技术中,大肠杆菌(ec)、屎肠球菌(ef)、鲍曼不动杆菌(ab)基因组中针对的保守区域与实施例1相同,每个区域针对内部序列设计一条环状探针,每一条探针序列设计一组探针引物(f、r)。探针中部的通用序列(linker)以及每组探针引物由上海生工生物科技有限公司合成),核酸序列如表7所示:表7将大肠杆菌(ec)、屎肠球菌(ef)、鲍曼不动杆菌(ab)的菌液分别提取核酸(采用天根dp-316试剂盒),提取的核酸使用qubitdsdnahsassaykit进行定量并根据各自基因组大小推算提取前的菌体浓度,分别将核酸稀释成相当于1000拷贝/ml的浓度,再将三种核酸按体积等比例混合。本实施例使用的试剂信息如下表8所示:表8试剂厂家货号taqdnaligasenebm0208sdntpenzymaticsn205lphusionthermofisherf-530lexoinebm0293sexoiiinebm0206s2×phusionmastermixthermofisherf-5311、探针pcr合成配置如下表9所示的pcr反应体系,并按照表9所示的反应程序反应,对linker进行pcr扩增。本发明实施例中针对9个保守区域,因此需要分别对9个区域的探针进行pcr合成。表92、环状探针纯化pcr产物通过axygen磁珠进行纯化,获得环状探针。具体包括如下步骤:(1)将pcr产物用水补足到100μl并加入100μlaxygen磁珠,充分混匀后室温静置5min;(2)将上一步溶液——磁珠混合物短暂离心后置于磁力架上2min,小心将上清转移到新的1.5mlep管;(3)小心加入500μl80%乙醇,并旋转离心管以充分洗涤磁珠(旋转次数一般为2次),洗涤之后静止1min,吸弃乙醇;(4)重复步骤(4)一次;(5)小心吸弃乙醇之后室温晾干(时间长短与室内湿度有关,一般为5min),至磁珠表面哑光;(6)加入20μleb溶液(多次小心吹打混匀磁珠),静止5min(间隔轻弹管壁混匀);(7)短暂离心(时间稍长磁珠晾干的时间可能更短)后置于磁力架上2min,小心吸取溶液至新的1.5ml离心管中。纯化后的探针用qubitdsdnahsassaykit试剂盒定量,将不同的探针混合成1μm/每种的探针液,-20℃储存备用,探针液可以提前准备并供多次文库构建使用,无需在文库构建时才配制。3、探针退火按照表10配制反应体系,加热到98℃逐渐梯度降温到56℃,并在56℃保持2小时,使dna样品中的双链打开并逐渐与环状探针杂交。表10示出了探针退火的反应体系和程序:表104、缺口补平退火杂交完成后,配置如下表11所示的反应体系,并将该反应体系加入到探针退火后的反应体系中,混匀,按照表11所示的反应程序进行反应,使探针的3’末端延伸并与5’末端连接,探针环化。表115、外切酶消化往产物中加入1μlexoi(20u/μl)、1μlexoiii(100u/μl),按照如下表12所示的反应程序进行反应,消化体系内的线性核酸,之后80℃孵育10分钟使外切酶失活。表126、纯化消化产物通过axygen磁珠进行纯化,获得环状文库。具体包括如下步骤:(1)将消化产物用水补足到50μl并加入50μlaxygen磁珠,充分混匀后室温静置5min;(2)将上一步溶液——磁珠混合物短暂离心后置于磁力架上2min,小心将上清转移到新的1.5mlep管;(3)小心加入500μl80%乙醇,并旋转离心管以充分洗涤磁珠(旋转次数一般为2次),洗涤之后静止1min,吸弃乙醇;(4)重复步骤(3)一次;(5)小心吸弃乙醇之后室温晾干(时间长短与室内湿度有关,一般为5min),至磁珠表面哑光;(6)加入20μleb溶液(多次小心吹打混匀磁珠),静止5min(间隔轻弹管壁混匀);(7)短暂离心(时间稍长磁珠晾干的时间可能更短)后置于磁力架上2min,小心吸取溶液至新的1.5ml离心管中。6、上机测序将纯化的环状文库稀释至合适浓度,根据bgiseq-500平台的要求制备dnb,上机测序分析。以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。对于本发明所属
技术领域:
的技术人员,依据本发明的思想,还可以做出若干简单推演、变形或替换。sequencelisting<110>深圳华大基因股份有限公司<120>一种环状探针和基于环状探针捕获的测序文库构建方法<130>17i24630<160>30<170>patentinversion3.3<210>1<211>70<212>dna<213>人工序列<400>1tccaggtccgctggctttgcttcagcttcccgatatccgacggtagtgtcgctgaggata60attgccagca70<210>2<211>75<212>dna<213>人工序列<400>2tccagccgtcccttttcacttcagcttcccgatatccgacggtagtgtcgtcctcgatta60tggctgcacagtctc75<210>3<211>75<212>dna<213>人工序列<400>3cctgagcaacttcgtatttgggccattaccttcagcttcccgatatccgacggtagtgta60caaaacacaacaata75<210>4<211>75<212>dna<213>人工序列<400>4gtcgtggaattcgtgttgcataaacgcttcagcttcccgatatccgacggtagtgtgctg60ttgtgtttgatgctt75<210>5<211>74<212>dna<213>人工序列<400>5cagtagacccaatcagtaaaatcagcagcttcagcttcccgatatccgacggtagtgtaa60aaacaaatacccag74<210>6<211>75<212>dna<213>人工序列<400>6cgaaatacatggtcttggcatccaacttccttcagcttcccgatatccgacggtagtgta60tgcacctgaccaaaa75<210>7<211>75<212>dna<213>人工序列<400>7gtacgacttcagtggcgatgtgtatcgcacttcagcttcccgatatccgacggtagtgta60gagaagcgattggaa75<210>8<211>73<212>dna<213>人工序列<400>8gtttcaggggcgttgtagtgtccgtcttcagcttcccgatatccgacggtagtgtggtgc60agcgattggtaat73<210>9<211>74<212>dna<213>人工序列<400>9gcagcaacagcatctagttactcaagccttcagcttcccgatatccgacggtagtgtctg60gttcattgtgtttt74<210>10<211>58<212>dna<213>人工序列<400>10ccatctcatccctgcgtgtctccgactcagtccaagctgcgatatccgacggtagtgt58<210>11<211>56<212>dna<213>人工序列<400>11ccactacgcctccgctttcctctctatgggcagtcggtgatatcgggaagctgaag56<210>12<211>82<212>dna<213>人工序列<400>12agtcggaggccaagcggtcttaggaagacaatgtcataaatcaactccttggctcacaga60acgacatggctacgatccgact82<210>13<211>36<212>dna<213>人工序列<400>13tccaggtccgctggctttgagtcggaggccaagcgg36<210>14<211>38<212>dna<213>人工序列<400>14tgctggcaattatcctcagcgagtcggatcgtagccat38<210>15<211>35<212>dna<213>人工序列<400>15tccagccgtcccttttcaagtcggaggccaagcgg35<210>16<211>44<212>dna<213>人工序列<400>16gagactgtgcagccataatcgaggacgagtcggatcgtagccat44<210>17<211>46<212>dna<213>人工序列<400>17cctgagcaacttcgtatttgggccattacagtcggaggccaagcgg46<210>18<211>33<212>dna<213>人工序列<400>18tattgttgtgttttgtagtcggatcgtagccat33<210>19<211>43<212>dna<213>人工序列<400>19gtcgtggaattcgtgttgcataaacgagtcggaggccaagcgg43<210>20<211>36<212>dna<213>人工序列<400>20aagcatcaaacacaacagcagtcggatcgtagccat36<210>21<211>45<212>dna<213>人工序列<400>21cagtagacccaatcagtaaaatcagcagagtcggaggccaagcgg45<210>22<211>33<212>dna<213>人工序列<400>22ctgggtatttgtttttagtcggatcgtagccat33<210>23<211>46<212>dna<213>人工序列<400>23cgaaatacatggtcttggcatccaacttcagtcggaggccaagcgg46<210>24<211>33<212>dna<213>人工序列<400>24ttttggtcaggtgcatagtcggatcgtagccat33<210>25<211>46<212>dna<213>人工序列<400>25gtacgacttcagtggcgatgtgtatcgcaagtcggaggccaagcgg46<210>26<211>33<212>dna<213>人工序列<400>26ttccaatcgcttctctagtcggatcgtagccat33<210>27<211>42<212>dna<213>人工序列<400>27gtttcaggggcgttgtagtgtccgtagtcggaggccaagcgg42<210>28<211>35<212>dna<213>人工序列<400>28attaccaatcgctgcaccagtcggatcgtagccat35<210>29<211>44<212>dna<213>人工序列<400>29gcagcaacagcatctagttactcaagcagtcggaggccaagcgg44<210>30<211>34<212>dna<213>人工序列<400>30aaaacacaatgaaccagagtcggatcgtagccat34当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1