用于产生目标核酸分子的方法和组合物与流程
本申请涉及一种用于产生目标核酸分子的方法和组合物。
背景技术:
通过当前基于微阵列的基因合成技术合成的产物浓度处于飞摩尔(femtomolar)水平。因此,有必要通过pcr将合成产物的浓度提高到更高水平。为了满足这种需求,通常在基因合成期间合成引物结合区,并将限制酶识别序列引入引物结合区。限制酶识别序列用于在后续过程中除去引物结合区。
限制酶识别特定的核苷酸序列并切割序列中或序列周围的dna。该酶通常在序列中识别4至8个碱基。目标核酸中限制酶识别位点的存在可能是分离完整目标核酸的障碍。当需要获得完整形式的目标核酸时,根据合成序列选择合适的限制酶是麻烦的。
当需要对具有限制酶的反应产物进行特殊处理时,可能会出现时间和成本问题。通过基因组装将基因合成产物组装成更长的核酸分子。具有限制酶的反应产物可具有粘性末端(stickyends)。在这种情况下,需要额外的过程将粘性末端转换为钝端(bluntends)。
在这些情况下,本申请的发明人成功地设计了通过以序列非依赖性方式切割核酸来制备目标核酸分子的方法。
技术实现要素:
本申请要解决的问题
一方面提供了从双链核酸分子产生目标核酸分子的方法,所述双链核酸分子包括目标序列区域、与目标序列区域的5’端连接并含有一个或多个脱氨碱基的第一侧翼序列区域和与目标序列区域的3’端连接的第二侧翼序列区域。
另一方面提供了用于产生目标核酸分子的组合物,所述目标核酸分子包括双链核酸分子和脱氨碱基特异性核酸内切酶。
解决问题的手段
一方面提供了用于产生目标核酸分子的方法,包含:(a)提供双链核酸分子,其包括目标序列区域、与目标序列区域的5’端连接并含有一个或多个脱氨碱基的第一侧翼序列区域和与目标序列区域的3’端连接的第二侧翼序列区域;(b)孵育(incubation)核酸分子和对脱氨碱基具特异性的核酸内切酶,以去除范围从最靠近目标序列区域的5’端的脱氨碱基到核酸分子的5’端的第一侧翼序列区域。
第一侧翼序列区域可具有至少2个、至少3个或至少4个脱氨碱基。在第一侧翼序列区域中,一个或多个核苷酸可以排列在相邻的脱氨碱基之间。脱氨碱基可以是肌苷碱基或尿嘧啶碱基。
脱氨碱基可以是肌苷碱基。在这种情况下,3至8个核苷酸可以排列在相邻的肌苷碱基之间。例如,当在第一侧翼序列区域中存在3个肌苷碱基时,相邻的肌苷碱基可以被5和8个核苷酸分开。当在第一侧翼序列区域中存在4个肌苷碱基时,相邻的肌苷碱基可以被4、3和5个核苷酸分开。或者,脱氨碱基可以是尿嘧啶碱基。在这种情况下,一个或多个核苷酸可以排列在相邻的尿嘧啶碱基之间。
至少一个脱氨碱基可位于第一侧翼序列区域的3’端的第一、第二或第三核苷酸处。例如,至少一个脱氨碱基可存在于第一侧翼序列区域的3’端的核苷酸中、来自第一侧翼序列区域的3’端的第二核苷酸或来自第一侧翼序列区域的3’端的第三核苷酸
当脱氨碱基的碱基是肌苷碱基时,脱氨碱基特异性核酸内切酶可以是核酸内切酶v,通常称为脱氧肌苷3'-核酸内切酶。核酸内切酶v识别次黄嘌呤(在单链或双链dna上的脱氧肌苷的碱基),并主要水解识别碱基的3’端的第二或第三磷酸二酯键以产生“缺口(nicks)”。肌苷特异性核酸内切酶可以是源自海栖热袍菌(thermotogamaritima)或大肠杆菌(e.coli)的核酸内切酶v。
当脱氨碱基是尿嘧啶碱基时,脱氨碱基特异性核酸内切酶可以是尿嘧啶特异性切除试剂(user)。user是一种在尿嘧啶残基位置产生单核苷酸缺口的酶。user酶是尿嘧啶dna糖基化酶(udg)和dna糖基化酶-裂解酶核酸内切酶viii的混合物。udg催化尿嘧啶碱基的切除,形成脱碱基位点,同时保持磷酸二酯骨架完整。核酸内切酶viii的裂解酶活性在脱碱基位点的3'和5'侧破坏磷酸二酯骨架,从而释放无碱基的脱氧核糖。
双链核酸分子可以是通过扩增模板核酸分子而获得的产物,所述模板核酸分子包含目标序列区域、与目标序列区域的5’端连接的第三侧翼序列区域和与目标序列区域的3’端连接的第四侧翼序列区域,所述目标序列区域的3’端具有含有一个或多个脱氨碱基并黏接(annealing)到第四侧翼序列区域的引物组。
模板核酸分子可以是从有机体中分离的一种、从核酸库中分离的一种、通过基因工程修饰或组合分离的核酸片段获得的一种、通过化学合成获得的一种,或其组合。模板核酸分子可以是单链或双链的。
或者,可以通过基于微阵列的合成来制备模板核酸分子。基于微阵列的合成是指在固体基质上以厘米或微米范围的间隔固定的合成位点上,同时平行合成相同、相似或不同类型的生物化学分子的技术。
用于扩增模板核酸分子的引物组可以与模板核酸分子的第四侧翼序列区域黏接,并且可以具有至少2个、至少3个或至少4个脱氨碱基。脱氨碱基可以是肌苷碱基或尿嘧啶碱基。
脱氨碱基可以是肌苷碱基。在这种情况下,3至8个核苷酸可以排列在相邻的肌苷碱基之间。例如,当在第一侧翼序列区域中存在3个肌苷碱基时,相邻的肌苷碱基可以被5和8个核苷酸分开。当在第一侧翼序列区域中存在4个肌苷碱基时,相邻的肌苷碱基可以被4、3和5个核苷酸分开。或者,脱氨碱基可以是尿嘧啶碱基。在这种情况下,一个或多个核苷酸可以排列在相邻的尿嘧啶碱基之间。
引物组可以是具有seqidno:1所示核苷酸序列的寡核苷酸和具有seqidno:2所示核苷酸序列的寡核苷酸的一对、具有seqidno:3所示核苷酸序列的寡核苷酸和具有seqidno:4所示核苷酸序列的寡核苷酸的一对、具有seqidno:5所示核苷酸序列的寡核苷酸和具有seqidno:6所示核苷酸序列的寡核苷酸的一对、具有seqidno:7所示核苷酸序列的寡核苷酸和具有seqidno:8所示核苷酸序列的寡核苷酸的一对或具有seqidno:15所示核苷酸序列的寡核苷酸和具有seqidno:16所示核苷酸序列的寡核苷酸的一对。
该方法可以进一步包括(c)孵育不含第一侧翼序列区域的核酸分子和3'→5'核酸外切酶以除去单链第二侧翼序列区域。核酸外切酶可以是t4dna聚合酶。
步骤(b)和(c)可以通过一步法(one-shotprocess)进行。根据一步法,将包括双链核酸分子、脱氨碱基特异性核酸内切酶和核酸外切酶的反应物在更高温度下孵育(步骤(b)),然后在较低温度下孵育(步骤(c))。
例如,包括双链核酸分子、脱氨碱基特异性核酸内切酶和核酸外切酶的反应物可以在36℃至65℃、38℃至60℃、40℃至58℃、40℃至55℃或40℃至50℃下孵育20分钟至40分钟或25分钟至35分钟,例如30分钟,然后在20℃至30℃、22℃至28℃或23.5℃至26.5℃下孵育15分钟至25分钟或18分钟至23分钟,例如20分钟。
另一方面提供了用于产生目标核酸分子的组合物,包括:双链核酸分子,其包含目标序列区域、与目标序列区域的5’端连接并含有一个或多个脱氨碱基的第一侧翼序列区域和与目标序列区域3’端连接的第二侧翼序列区域;和对脱氨碱基具特异性的核酸内切酶。
第一侧翼序列区域可具有至少2个、至少3个或至少4个脱氨碱基。在第一侧翼序列区域中,一个或多个核苷酸可以排列在相邻的脱氨碱基之间。脱氨碱基可以是肌苷碱基或尿嘧啶碱基。脱氨碱基可以是肌苷碱基。在这种情况下,3至8个核苷酸可以排列在相邻的肌苷碱基之间。或者,脱氨碱基可以是尿嘧啶碱基。在这种情况下,一个或多个核苷酸可以排列在相邻的尿嘧啶碱基之间。至少一个脱氨碱基可位于第一侧翼序列区域的3’端的第一、第二或第三核苷酸处。
当脱氨碱基是肌苷碱基时,脱氨碱基特异性核酸内切酶可以是核酸内切酶v。核酸内切酶v与上述相同。当脱氨碱基是尿嘧啶碱基时,脱氨碱基特异性核酸内切酶可以是尿嘧啶特异性切除试剂(user)。尿嘧啶特异性切除试剂与上述相同。
双链核酸分子可以是通过扩增模板核酸分子获得的产物,所述模板核酸分子包括目标序列区域、与目标序列区域的5’端连接的第三侧翼序列区域和与目标序列区域的3’端连接的第四侧翼序列区域,目标序列区域的3’端具有含有一个或多个脱氨碱基并黏接到第四侧翼序列区域的引物组。模板核酸分子与上述相同。或者,可以通过基于微阵列合成来制备模板核酸分子。用于扩增模板核酸分子的引物组与上述相同。
该组合物可进一步包括3'→5'核酸外切酶。核酸外切酶可以是t4dna聚合酶。
本申请的效果
根据各方面的用于产生目标核酸分子的方法和组合物可广泛用于合成生物学和分子生物学领域。
附图说明
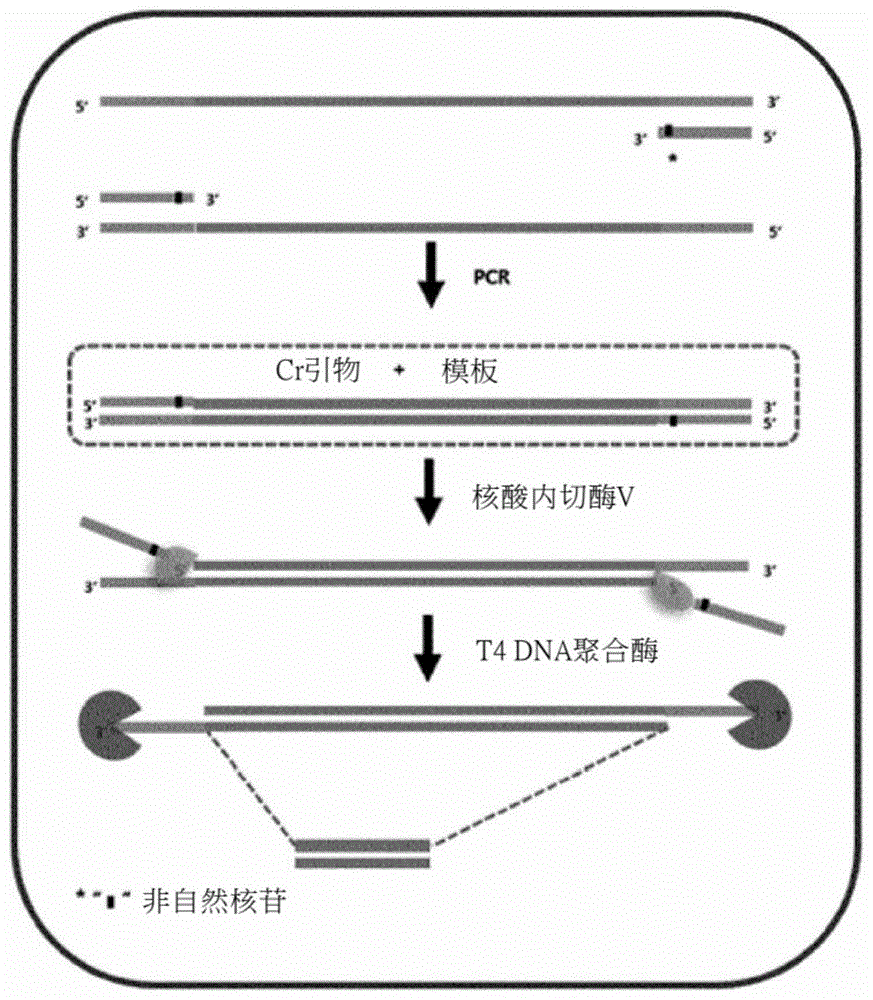
图1a显示根据一个方面的用于产生目标核酸分子的方法的示意图。
图1b显示根据一个方面的在产生目标核酸分子的方法中制备双链核酸分子的方法。
图2a显示使用含肌苷的引物和限制酶在各个步骤中的电泳结果。
图2b显示使用含尿嘧啶的引物和限制酶在各个步骤中的电泳结果。
图3显示两种酶在不同温度下的活性。
图4显示确定是否可以省略纯化过程并且可以使用缓冲混合物的实验结果。
图5a显示根据一个方面的一步反应的示意图。
图5b显示在不同温度下一步反应后获得的结果。
附图标记:
end代表通过endrepair酶将切割产物平端化的电泳结果
m标准液的电泳结果
up3代表使用引物组up3所获得的pcr产物的电泳结果
user代表使用user酶切割的产物的电泳结果
具体实施方式
实施本申请的方式
参考以下示例更详细地解释本申请。然而,提供这些示例是为了帮助理解本申请,并非要限制本申请的范围。
示例1:用含肌苷的引物切割
1.1.dna片段和引物组的制备和pcr
使用基于半导体的电化学酸生产阵列(customarray)从生殖支原体(mycoplasmagenitalium)的基因组dna制备257个140bp的单链dna片段。每个片段具有用于引物黏接的共同序列(seqidno:9和10),其位于目标序列的侧翼。根据位于100bp目标序列中的80bp重迭区域,将257个片段分类为20组盒。
制备可以与常见序列黏接的引物组。引物组的序列与常见序列相同,除了共同序列中的一个或多个鸟嘌呤碱基被肌苷碱基取代。引物组命名为cp引物组。所有引物均由integrateddnatechnology(coralvile,ia,usa)定制。cp引物组如表1所示。
表1
如表1所示,每个cp1引物(seqidno:1和2)在3’端的胸腺嘧啶前面具有一个肌苷碱基。每个cp2引物(seqidno:3和4)和cp3引物(seqidno:5和6)具有三个肌苷碱基。在cp2和cp3引物中的每一个的相邻肌苷碱基分开5和8个核苷酸。与cp2引物不同,每个cp3引物在3’端具有脱氧肌苷。每个cp4引物(seqidno:7和8)具有四个肌苷碱基。相邻的肌苷碱基分开4、3和5个核苷酸。
使用具有cp引物组的taqdna聚合酶(thermoscientific)进行dna片段的pcr。具体地,使含有700ng的生殖支原体基因组dna和1pm的每种cp引物组的溶液(50μl)在95℃反应2分钟。在由95℃/30秒、退火温度/20秒和72℃/30秒组成的10-15个循环之后,在72℃下继续反应2分钟。退火温度根据引物类型而改变。使用qiagenminelutepcr纯化试剂盒(qiagen,valencia,ca,usa)纯化反应产物,并洗脱至最终体积为15μl。
1.2.与核酸内切酶和核酸外切酶反应并测序
将来自海栖热袍菌(thermotogamaritima(tma))的700ng的每种含dna的纯化pcr产物和核酸内切酶v(thermofisherscientific,st.leon-rotgermany,5u/μl)在65℃孵育30分钟,纯化,并洗脱至最终体积为15μl。
此后,使洗脱液与具有3'→5'核酸外切酶活性的t4dna聚合酶(thermoscientific,5u/μl)在11℃下反应20分钟或在室温下反应5分钟。在2.5%琼脂糖凝胶中在120v下进行高分辨率电泳60-90分钟以确定dna片段的大小和量。
为了测序,通过用碱性磷酸酶(calfintestinal;newenglandbiolabs)处理除去5'和3’端的磷酸残基。根据制造商的说明,使用allinonepcr克隆试剂盒(biofact)除去来自两端的磷酸残基的20ng/μldna的1μltopo克隆,然后进行sanger测序(macrogeninc.)。为了以低成本获得大量菌落的序列信息,将所有菌落收集在一个管中,将细胞培养在液体lb培养基中,然后用geneallexprepplasmidmini试剂盒纯化质粒。从质粒的克隆位点的侧翼序列设计引物,使得目标序列存在于扩增产物中。要求扩增产物用illuminamiseq测序。获得了数万个模板的测序结果。
图1a显示根据一个方面的用于产生目标核酸分子的方法的示意图。
图1b显示根据一个方面的在产生目标核酸分子的方法中制备双链核酸分子的方法。如图1b所示,模板核酸分子包括与目标序列区域的5’端连接的第三侧翼序列区域和与目标序列区域的3’端连接的第四侧翼序列区域。将含有脱氨碱基的引物组黏接至第四侧翼序列区域。此黏接使得模板核酸分子的扩增成为可能。
图2a显示使用含肌苷的引物和限制酶在各个步骤中的电泳结果。泳道1-4分别代表使用通用引物组、cp1引物组、cp2引物组和cp3引物组的pcr产物。泳道5-8分别代表通过泳道1-4中的pcr产物与tmaendov反应获得的产物。泳道9-12分别代表通过泳道5-8中的产物与t4dna聚合酶反应获得的产物。
如图2a所示,对于cp1引物组(泳道10),切割的片段和未切割的片段共存。对于cp2和cp3引物组(泳道11和12),产生100-bp的最终产物。最终产物的sanger测序显示73.7%(cp2)和93.8%(cp3)被切割。
对于cp4引物,sanger测序显示100%切割。illuminami-seq再次证实了切割表现。结果显示在表2中。在表2中,f和r分别代表正向和反向引物,切割(cut)和未切割(uncut)分别代表引物的肌苷碱基处的切割和非切割读数的数目。样品1和样品2是在相同条件下处理的两个平行实验组。作为样品1的illumina测序的结果,f和r引物位点在总共95365个读数中被准确切割,目标序列仅保留在94631个读数中,r引物在732个读数中未被切割,并且f引物在2个读数中未被切割。样品2的illumina测序显示f和r引物被精确切割并且目标序列仅保留在88649个读数中,r引物在361个读数中未被切割,并且f引物在815个读数中未被切割。如表2所示,98.97%的模板被成功切割。所估计的剩余部分(1.03%)是由于引物构建期间的误差。这些结果得出结论,本申请方法在大规模实验中也是有效的。
表2
示例2:用含尿嘧啶的引物切割
2.1.引物组的制备和pcr
使用具有表3中所示序列的引物组,以示例1中描述的来源于生殖支原体的dna片段作为模板进行pcr。每个引物组包括一个或多个尿嘧啶碱基。引物组命名为up引物组。up引物组如表3所示。
表3
如表3中所示,每个up1引物(seqidno:11和12)在3’端具有一个尿嘧啶碱基,并且每个up2引物(seqidno:13和14)在3'端的第五或第三位置具有一个尿嘧啶碱基。在每个up3引物(seqidno:15和16)中,6或7个核苷酸排列在两个尿嘧啶碱基之间。
将含有1μl的10μm生殖支原体基因组dna、25pmol的每种up引物组和25μl的kapahifihotstarturacil+readymix(2x)溶液(50μl)在95℃下反应2分钟。在由98℃/20秒、58℃/15秒和72℃/30秒组成的11个循环后,在72℃下继续反应2分钟。pcr产物的大小恒定在140bp。
2.2.与核酸内切酶和核酸外切酶反应和测序
将含有50μl在2.1中获得的每种pcr产物、10μl的10xcutsmart缓冲液和10μluser酶(neb)的溶液(100μl)在37℃下孵育20分钟,纯化,并洗脱至最终体积为12μl。将含有10μl的洗脱液、2μl的10xendrepair反应缓冲液和1μl的endrepair酶混合物(neb)的溶液(20μl)在20℃下反应30分钟,纯化,并洗脱至最终体积为12μl。在2.5%琼脂糖凝胶中在120v下进行高分辨率电泳60-90分钟以确定dna片段的大小和量。
图2b显示了使用含尿嘧啶的引物和限制酶在各个步骤中的电泳结果。在图2b中,up3代表使用含有尿嘧啶的引物组up3所获得的pcr产物(140bp),user代表使用user酶切割的产物,end代表通过endrepair酶将切割产物(100bp)平端化(blunt-ended)。总共83种切割产物的sanger测序显示,6种(7.2%)产物的长度≤99bp,77种(92.8%)产物的长度为100bp,表明所有核酸片段都通过含尿嘧啶的引物和user酶进行切割。
示例3:酶促反应条件的延长
3.1.测试温度依赖性活性
在各种温度条件下测试tma核酸内切酶v(tmaendov)和t4dna聚合酶的活性。
图3显示两种酶在各种温度下的活性。
tmaendov在各种温度下以及在推荐的孵育温度(65℃)下孵育。泳道1-4显示通过在25℃、35℃、50℃和65℃下孵育获得的每种产物在25℃下与t4dna聚合酶反应20分钟后的电泳结果。如图3a所示,tmaendov在≤35℃(泳道1和2)的温度下没有显示出实质活性。在50℃和65℃下观察到tmaendov的活性。
t4dna聚合酶的3'→5'核酸外切酶活性的推荐孵育条件是11℃/20分钟或室温/5分钟。然而,如图3b所示,t4dna聚合酶在各种温度条件下保持其活性,包括25℃、35℃、50℃和65℃,以及推荐的孵育温度(泳道5-8)。
3.2.测试以确定是否可以省略纯化过程并且可以使用缓冲混合物
通过去除不必要的组分(包括盐、核苷酸、酶和引物)来纯化pcr产物。随后的酶处理也需要清洁dna样品。然而,纯化会产生巨大的成本,并且在大规模实验中难以完全自动化。因此,省略纯化有助于节省时间和成本,因此对于操作者是有利的。
图4显示确定是否可以省略纯化过程并且可以使用缓冲混合物的实验结果。使用cp3引物组获得140-bp扩增产物,用tmaendov(泳道2)处理,纯化(泳道4)或不纯化(泳道3),并用t4dna聚合酶处理。对于泳道5-8,在tmaendov缓冲液和t4dna聚合酶缓冲液的缓冲液混合物(bm)中孵育后,比较所得的反应产物。图4的b+代表一次性添加t4dna聚合酶缓冲液。
如图4所示,泳道3和4的比较证实,在添加t4dna聚合酶之前省略纯化不影响切割。还证实使用缓冲液混合物不会抑制两种酶的活性。
3.3.一步反应
考虑到省略纯化或使用缓冲液混合物对酶的活性没有影响,如3.2中所证实的,在基质中进行两种酶的一步反应。研究了此反应的最佳温度和时间条件。
将700ng的模板基质、5单位的tmaendov、1μl的t4dna聚合酶和dntp以及缓冲液混合物混合在一起以制备100μl的溶液。
图5a是显示根据一个方面的一步反应的示意图。
图5b显示在不同温度下一步反应后获得的结果。泳道1-4代表在50℃下孵育30分钟并接着在25℃下孵育20分钟后(泳道1)、在40℃下孵育30分钟并接着在25℃下孵育20分钟后(泳道2)、在40℃下孵育30分钟并接着在25℃下孵育20分钟后(泳道3)以及在45℃下孵育30分钟并接着在25℃下孵育20分钟后(泳道4)获得的结果。如图5b所示,在40℃下孵育30分钟并接着在25℃下孵育20分钟,是最佳的一步反应条件。
<110>首尔大学校产学协力团
塞勒密斯株式会社
<120>用于产生目标核酸分子的方法和组合物
<130>sdp2017-1001
<160>16
<170>kopatentin3.0
<210>1
<211>19
<212>dna
<213>人工序列
<220>
<223>cp1_f
<220>
<221>modified_base
<222>(18)
<223>i
<400>1
gtgccttggcagtctcant19
<210>2
<211>22
<212>dna
<213>人工序列
<220>
<223>cp1_r
<220>
<221>modified_base
<222>(21)
<223>i
<400>2
cgtggatgaggagccgcagtnt22
<210>3
<211>19
<212>dna
<213>人工序列
<220>
<223>cp2_f
<220>
<221>modified_base
<222>(3)
<223>i
<220>
<221>modified_base
<222>(9)
<223>i
<220>
<221>modified_base
<222>(18)
<223>i
<400>3
gtnccttgncagtctcant19
<210>4
<211>22
<212>dna
<213>人工序列
<220>
<223>cp2_r
<220>
<221>modified_base
<222>(5)
<223>i
<220>
<221>modified_base
<222>(13)
<223>i
<220>
<221>modified_base
<222>(21)
<223>i
<400>4
cgtgnatgagganccgcagtnt22
<210>5
<211>18
<212>dna
<213>人工序列
<220>
<223>cp3_f
<220>
<221>modified_base
<222>(3)
<223>i
<220>
<221>modified_base
<222>(9)
<223>i
<220>
<221>modified_base
<222>(18)
<223>i
<400>5
gtnccttgncagtctcan18
<210>6
<211>21
<212>dna
<213>人工序列
<220>
<223>cp3_r
<220>
<221>modified_base
<222>(5)
<223>i
<220>
<221>modified_base
<222>(13)
<223>i
<220>
<221>modified_base
<222>(21)
<223>i
<400>6
cgtgnatgagganccgcagtn21
<210>7
<211>19
<212>dna
<213>人工序列
<220>
<223>cp4_f
<220>
<221>modified_base
<222>(3)
<223>i
<220>
<221>modified_base
<222>(8)
<223>i
<220>
<221>modified_base
<222>(12)
<223>i
<220>
<221>modified_base
<222>(18)
<223>i
<400>7
gtnccttngcantctcant19
<210>8
<211>20
<212>dna
<213>人工序列
<220>
<223>cp4_r
<220>
<221>modified_base
<222>(3)
<223>i
<220>
<221>modified_base
<222>(9)
<223>i
<220>
<221>modified_base
<222>(14)
<223>i
<220>
<221>modified_base
<222>(19)
<223>i
<400>8
tgnatgagnagccncagtnt20
<210>9
<211>19
<212>dna
<213>人工序列
<220>
<223>common_f
<400>9
gtgccttggcagtctcagt19
<210>10
<211>23
<212>dna
<213>人工序列
<220>
<223>common_r
<400>10
acactgcgggctcctcatccacg23
<210>11
<211>19
<212>dna
<213>人工序列
<220>
<223>up1_f
<400>11
gtgccttggcagtctcagu19
<210>12
<211>22
<212>dna
<213>人工序列
<220>
<223>up1_r
<400>12
cgtggatgaggagccgcagtgu22
<210>13
<211>19
<212>dna
<213>人工序列
<220>
<223>up2_f
<400>13
gtgccttggcagtcucagt19
<210>14
<211>22
<212>dna
<213>人工序列
<220>
<223>up2_r
<400>14
cgtggatgaggagccgcagugt22
<210>15
<211>18
<212>dna
<213>人工序列
<220>
<223>up3_f
<400>15
gtgccutggcaguctcag18
<210>16
<211>21
<212>dna
<213>人工序列
<220>
<223>up3_r
<400>16
cgtggaugaggagcugcagtg21
- 还没有人留言评论。精彩留言会获得点赞!