用于检测嗜酸性食管炎的免疫测定的制作方法
本发明涉及通过使用对嗜酸性食管炎标记物的免疫测定来检测食管纤维化和吞咽困难,所述嗜酸性食管炎标记物是存在于vi型胶原α3链的c末端处的表位。
背景技术:
1、嗜酸性食管炎(eoe)是一种过敏原/免疫介导的食管纤维狭窄性疾病。随着时间的推移,可能会出现进行性上皮下纤维化,随后有食管狭窄的风险,这可能会导致吞咽困难和食物嵌塞,即使浅表粘膜嗜酸性炎症消退。
2、vi型胶原是一种独特的细胞外胶原,其可以在细胞基底膜中形成独立的微纤维网络。vi型胶原可以与包括胶原、双糖链和蛋白聚糖在内的其他基质蛋白相互作用。在肌肉中,vi型胶原是肌膜的一部分,并且参与将肌纤维锚定到肌内细胞外基质中,并因此参与力传递。此外,vi型胶原的突变可能导致bethlem肌病和ullrich先天性肌营养不良。据报道,vi型胶原α3链的c末端氨基酸序列在分泌后从成熟的vi型微纤维上裂解下来。然而,vi型胶原不仅仅与肌肉和肌肉损失有关。
3、微丝状间质vi型胶原是一种由组成链α1(vi)、α2(vi)和α3(vi)构成的三螺旋分子,其在大多数结缔组织中表达,尤其在脂肪组织中表达,在那里它通过与其他ecm蛋白的相互连接来锚定细胞。在微丝的形成过程中,vi型胶原的三螺旋核心通过蛋白水解从前肽中释放出来,并且α3(vi)链的c末端前肽的裂解产生内养素(endotrophin)(一种脂肪因子)。
4、pro-c6是vi型胶原形成和内养素释放的生物标记物,其包含vi型胶原的α3链的c5结构域的c末端表位,当新的vi型胶原分子在细胞外基质中组装时,该表位被裂解,并且该c末端表位也是生物活性片段内养素的c末端表位。wo2016/156526中描述了pro-c6生物标记物和pro-c6测定(具体地,pro-c6elisa)。该测定利用了特异性结合vi型胶原的α3链的c5结构域的c末端10个氨基酸序列的单克隆抗体。已经在乳腺癌和肝纤维化的临床前模型中观察到内养素作为促纤维化、促炎症和促肿瘤发生分子的作用1-5。pro-c6已经被确定为慢性肾病和糖尿病肾病患者死亡率和疾病进展的预断生物标记物6-8,以及糖尿病患者对降糖疗法响应的预测标记物9。
技术实现思路
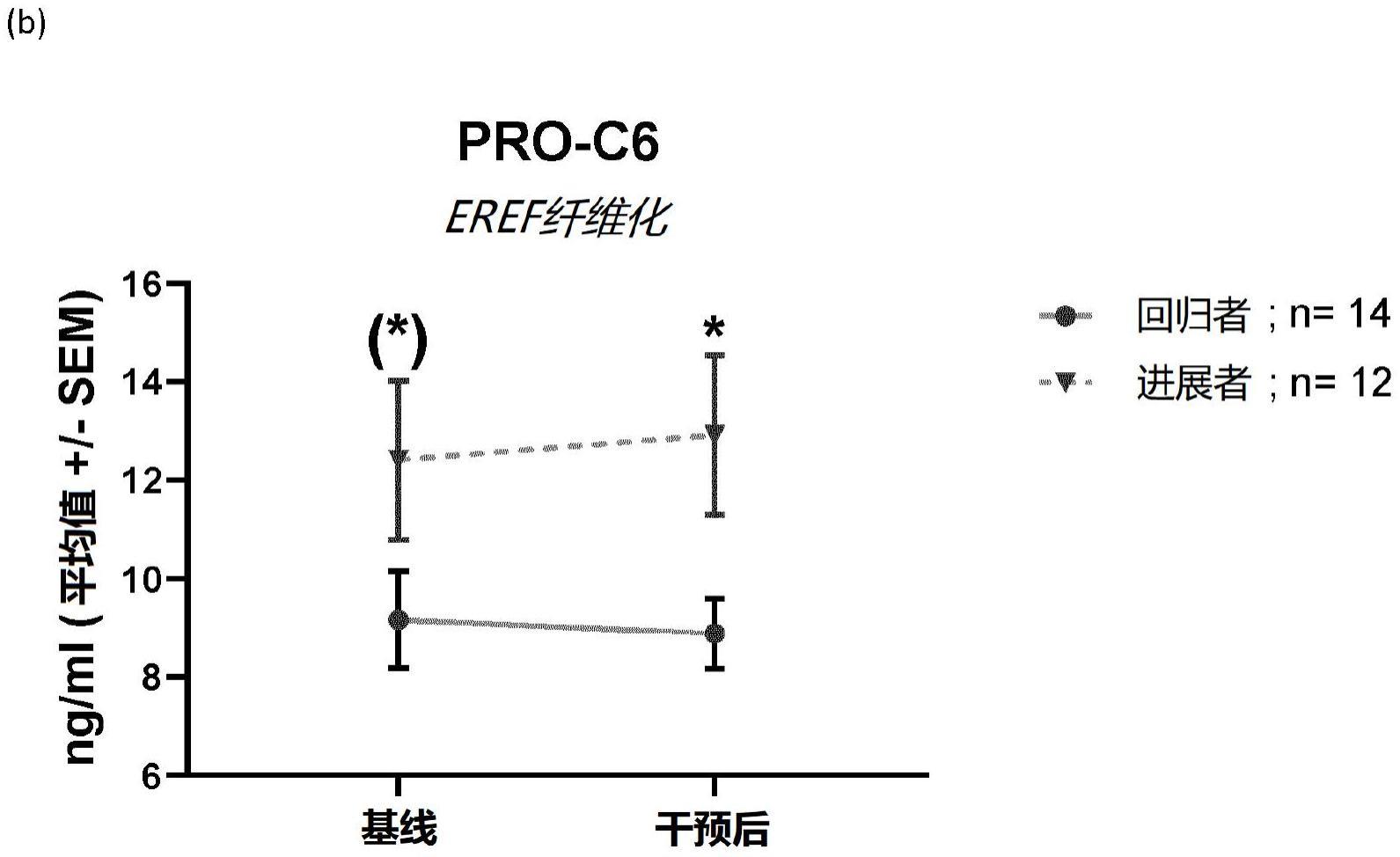
1、本发明人现已将pro-c6鉴定为检测食管纤维化和吞咽困难的eoe标记物。
2、因此,在第一方面,本发明提供了一种用于检测和/或监测患者的食管纤维化和/或吞咽困难和/或评估患者的食管纤维化和/或吞咽困难的可能性或严重程度的免疫测定方法,其中所述方法包括:
3、(i)使来自患者的生物流体样品与单克隆抗体接触,所述单克隆抗体特异性结合vi型胶原的α3链的c5结构域的c末端表位,
4、(ii)检测并确定一个或多个所述样品中在步骤(i)中使用的所述单克隆抗体与肽之间的结合量,以及
5、(iii)将在步骤(ii)中确定的各单克隆抗体的所述结合量与以下值相关联:与正常健康受试者相关联的值和/或与已知疾病严重程度相关联的值和/或在先前时间点从所述患者获得的值和/或预定的截断值。
6、所述免疫测定可以是但不限于竞争性测定或夹心式测定。所述免疫测定可以是例如放射免疫测定或酶联免疫吸附测定(elisa)。此类测定是本领域技术人员已知的技术。
7、所述患者生物流体样品可以是但不限于血液、血清、血浆、尿液或羊水。优选地,所述生物流体是血清或血浆。
8、如本文所用,术语“单克隆抗体”是指完整抗体及其保留完整抗体的结合特异性的片段,例如fab片段、f(ab’)2片段、单链fv片段或本领域技术人员已知的其他此类片段。众所周知,完整抗体通常具有两对相同的多肽链的“y形”结构,每对由一条“轻”链和一条“重”链组成。每条轻链和重链的n末端区域含有可变区,而每条重链和轻链的c末端部分组成恒定区。可变区包含三个互补决定区(cdr),它们主要负责抗原识别。恒定区允许抗体募集免疫系统的细胞和分子。保留结合特异性的抗体片段至少包含cdr和可变区的其余部分的足够部分以保留所述结合特异性。
9、在本发明的方法中,可以使用包含本领域已知的任何恒定区的单克隆抗体。人恒定轻链被分类为κ和λ轻链。重恒定链被分类为μ、δ、γ、α或ε,并且将抗体的同型分别定义为igm、igd、igg、iga和ige。igg同型具有几个亚类,包括但不限于igg1、igg2、igg3和igg4。所述单克隆抗体可以优选地具有igg同型,包括igg1、igg2、igg3或igg4中的任一种。
10、抗体的cdr可以使用本领域已知的方法、诸如kabat等人所述的方法来确定。如示例中所述,可以由b细胞克隆生成抗体。抗体的同型可以通过对人igm、igg或iga同型或人igg1、igg2、igg3或igg4亚类具特异性的elisa来确定。生成的抗体的氨基酸序列可以使用标准技术来确定。例如,可以从细胞中分离出rna,并且使用rna通过逆转录来生成cdna。然后使用扩增抗体重链和轻链的引物对cdna进行pcr。例如,对所有vh(可变重链)序列的前导序列具特异性的引物可以与结合至位于先前确定的同型的恒定区中的序列的引物一起使用。可以使用与κ或λ链的3’末端结合的引物以及退火至vκ或vλ前导序列的引物来扩增轻链。可以生成全长重链和轻链并对其进行测序。
11、在根据本发明第一方面的方法的一些实施方案中,使所述生物流体样品与单克隆抗体接触,所述单克隆抗体特异性结合vi型胶原的α3链的c5结构域的c末端表位。优选地,所述单克隆抗体特异性结合c末端氨基酸序列kpgvisvmgt(seq id no:1)(在本文中也称为“pro-c6序列”,或简称为“pro-c6”)。优选地,所述单克隆抗体不识别或不特异性结合所述c末端氨基酸序列的延长形式:kpgvisvmgta(seq id no:2),或所述c末端氨基酸序列的截短形式:kpgvisvmg(seq id no:3)。
12、优选地,所述抗体对c末端氨基酸序列kpgvisvmgt(seq id no:1)的亲和力与所述抗体对延长的c末端氨基酸序列kpgvisvmgta(seq id no:2)和/或截短的c末端氨基酸序列kpgvisvmg(seq id no:3)的亲和力比率为至少10比1,并且更优选地为至少50比1、至少100比1、至少500比1、至少1000比1、至少10000比1、至少100000比1或至少1000000比1。
13、如本文所用,术语“c末端”是指多肽末端处(即,多肽的c末端处)的c末端肽序列,并且不应当被解释为在其一般方向上的含义。
14、特异性结合pro-c6序列的单克隆抗体可以优选地包含一个或多个选自以下的互补决定区(cdr):
15、cdr-l1:rssqrivhsngitfle(seq id no:4)
16、cdr-l2:rvsnrfs (seq id no:5)
17、cdr-l3:fqgshvplt (seq id no:6)
18、cdr-h1:dfnmn (seq id no:7)
19、cdr-h2:ainphngatsynqkfsg (seq id no:8)
20、cdr-h3:wgngkns (seq id no:9)。
21、优选地,所述抗体包含上文列出的cdr序列中的至少2、3、4、5或6个。
22、优选地,所述单克隆抗体轻链可变区包含以下cdr序列:
23、cdr-l1:rssqrivhsngitfle(seq id no:4)
24、cdr-l2:rvsnrfs (seq id no:5)和
25、cdr-l3:fqgshvplt (seq id no:6)。
26、优选地,所述单克隆抗体轻链包含cdr之间的框架序列,其中所述框架序列与以下轻链序列中的cdr之间的框架序列基本上相同或基本上相似(其中cdr以粗体显示并加下划线,并且框架序列以斜体显示)
27、
28、优选地,所述单克隆抗体重链可变区包含以下cdr序列
29、cdr-h1:dfnmn (seq id no:7)
30、cdr-h2:ainphngatsynqkfsg (seq id no:8)和
31、cdr-h3:wgngkns (seq id no:9)。
32、优选地,所述单克隆抗体重链包含cdr之间的框架序列,其中所述框架序列与以下重链序列中的cdr之间的框架序列基本上相同或基本上相似(其中cdr以粗体显示并加下划线,并且框架序列以斜体显示)
33、
34、如本文所用,如果抗体的cdr之间的框架氨基酸序列与另一抗体的cdr之间的框架氨基酸序列具有至少70%、80%、90%或至少95%的相似性或同一性,则所述框架氨基酸序列基本上相同或基本上相似。所述相似或相同的氨基酸可以是相邻的或非相邻的。
35、所述框架序列可以含有一个或多个氨基酸取代、插入和/或缺失。氨基酸取代可能是保守的,这意味着取代的氨基酸具有与原始氨基酸相似的化学特性。技术人员将了解哪些氨基酸具有相似的化学特性。例如,以下几组氨基酸具有相似的化学特性,诸如大小、电荷和极性:第1组,ala、ser、thr、pro、gly;第2组,asp、asn、glu、gln;第3组,his、arg、lys;第4组,met、leu、ile、val、cys;第5组,phe thy trp。
36、诸如clustal程序的程序可以用于比较氨基酸序列。这一程序比较氨基酸序列,并且通过在任一序列中适当插入空格来找到最佳比对。有可能计算氨基酸的同一性或相似性(同一性加上氨基酸类型的保守性)以实现最佳比对。如blastx的程序将比对相似序列的最长延伸,并且为拟合指定值。因此,有可能获得一种比较,其中发现数个相似的区域,每个区域具有不同的分数。本发明预期这两种类型的分析。同一性或相似性优选地在框架序列的整个长度上计算。
37、在某些优选实施方案中,特异性结合pro-c6序列的单克隆抗体可以包含以下轻链可变区序列:
38、
39、和/或以下重链可变区序列:
40、
41、(cdr为粗体并加下划线;框架序列为斜体)
42、在根据本发明第一方面的方法的一些实施方案中,对vi型胶原的α3链的c5结构域的c末端表位特异的单克隆抗体的结合量与与以下值相关联:与正常健康受试者相关联的值和/或与已知疾病严重程度相关联的值和/或在先前时间点从所述患者获得的值。
43、如本文所用,术语“与正常健康受试者相关联的值和/或与已知疾病严重程度相关联的值”意指通过上述方法针对被认为健康(即没有心血管疾病)的受试者确定的标准化量,和/或通过上述方法针对已知患有已知严重程度的eoe的受试者确定的标准化量。
44、在根据第一方面的方法的一些实施方案中,将对vi型胶原的α3链的c5结构域的c末端表位特异的单克隆抗体的结合量与一个或多个预定的截断值进行比较。
45、如本文所用,“截断值”意指在统计学上经确定以指示患者发生eoe的高可能性或eoe的特定严重程度的结合量,其中患者样品中的生物标记物结合的测量值等于或高于统计学截断值,对应于eoe存在或可能性或所述疾病特定严重程度的至少70%概率、优选至少80%概率、优选至少85%概率、更优选至少90%概率,并且最优选至少95%概率。
46、对vi型胶原的α3链的c5结构域的c末端表位特异的单克隆抗体结合量的预定截断值优选地为至少9.0ng/ml,更优选地为至少12.0ng/ml。通过具有至少9.0ng/ml,且更优选至少12.0ng/ml的统计学截断值,有可能利用本发明的方法以高置信度给出eoe的预断。应用此类统计学截断值是特别有利的,因为它导致独立的诊断测定;即,它不需要与健康个体和/或具有已知疾病严重程度的患者进行任何直接比较来得出诊断结论。当使用所述测定来评价已经具有一般指示eoe的医学体征或症状(例如,如通过体检和/或咨询医务人员所确定的医学体征或症状)的患者时,这也可能是特别有利的,因为它可以充当一种快速且明确的工具来证实最初的预断,从而可能不需要更具侵入性的程序,并加快合适治疗方案的开始。它还可以避免长时间住院的需要。
- 还没有人留言评论。精彩留言会获得点赞!