事故主动呼叫救援的方法及车载自动求救系统与流程
本发明涉及汽车智能报警系统,特别涉及一种事故主动呼叫救援的方法及车载自动求救系统以及装置。
背景技术:
我国每年因道路交通安全事故死亡人数在5~6万人之间,因事故发生后1小时内未得到及时救助而死亡的人数高达60%。当车辆发生严重交通事故,尤其是事故地点相对偏僻时,及时呼叫救助对拯救事故车辆车内人员的生命意义重大。在事故车辆碰撞较严重,车内人员无法自主呼救时,需要一种可靠的车辆主动呼叫技术提供呼叫服务。另外,针对车辆和司乘人员的犯罪活动也日趋增加,司乘人员碰到抢劫车辆和财物的事件时,可能无法安全地发出救援信号。
现有技术中的自动求救系统大多通过车身损坏的信号,如安全气囊、汽车姿态等其他信号来判定是否处于交通事故,但是驾驶员在发生事故之后大多数情况都可以通过自主实现求救,因此会导致一案多报的情况,只有当驾驶员无法或者不能自主求救时,自动求救系统才有意义。
技术实现要素:
本发明为了解决上述技术问题,提供一种事故主动呼叫救援的方法及车载自动求救系统以及装置。
一种事故主动呼叫救援的方法,包括如下步骤:
s10、采集车内的实时视频数据;
s20、截取视频数据中的帧图像,并且分析驾驶位人员的实时坐姿;
s30、判断所述实时坐姿与标定坐姿的差别是否达到偏差阈值,若持续达到阈值的持续时间超过第一预设时间段时,执行步骤s40;
s40、调用无线通讯模块向外发送求救信号。
进一步的,所述步骤s20包括如下子步骤:
s21、通过角点检测绘画驾驶员实时坐姿轮廓,并从中确定关键识别点;
s22、计算关键识别点之间的实时位置比例关系;
s23、将实时位置比例关系与标定坐姿的位置比例关系进行比较;
s24、计算变差量。
进一步的,所述步骤关键识别点包括人脸五官、肩位轮廓或者头部轮廓中的至少一种。
进一步的,所述步骤s10还包括音频采集步骤:
s101、获取车内音频信号,并进行降噪处理;
s102、分析语音,并分解出关键词;
s103、当分解出的所述关键词与预设关键词匹配时,直接执行步骤s40。
进一步的,还包括与外部建立实时视频通信的步骤。
进一步的,执行步骤s30还包括车身图像实时情况的获取:
s301、获取安全气囊区域、汽车a柱区域以及车头区域中至少一处图像;
s302、分析步骤s301中的图像关键区域,并与标定图像进行对比;
s303、所差别超过偏差阈值则执行步骤s40。
进一步的,所述步骤s40中的求救信号包括驾驶员预设的个人信息、卫星定位以及实时视频数据中的至少一种。
另外,基于上述的事故主动呼叫救援方法,本发明还提供一种车载自动求救系统,包括:
gps模块,用于获取汽车位置信息;
摄像头模块,用于获取车内和周围的图像信息;
声音采集模块,用于获取车内声音信息;
处理单元,用于接收以及分析所述摄像头模块以及声音采集模块所输出的信息,并判定是否出现事故;以及
无线通讯模块,用于转发处理单元发出的求救信号。
进一步的,所述摄像头模块安装在所述汽车内后视镜上。
进一步的,所述摄像头模块为环视摄像头模块,可获取车内人员、汽车a主以及车前盖方向图像信息。
本发明的事故主动呼叫救援的方法及车载自动求救系统及系统所起到的有益效果包括:
1.基于智能的图像识别能力判断车辆事故后驾驶员的实际情况,可更加准确地动发出救援信息;
2.通过实现在车辆内部构建全景环视系统的方案以及识别和语音识别可以判断车辆遭遇劫持后主动发出救援信息。
附图说明
图1为本发明实施例1中的方法流程图。
图2为本发明实施例2中的方法原理图。
图3为本发明实施例3的系统架构图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征更易被本领域技术人员理解,从而对本发明的保护范围作出更为清楚的界定。
实施例1:
如图1所示,本实施例公开一种事故主动呼叫救援的方法,主要用于交通事故的判定以及自动呼叫救援,具体包括如下步骤:
s10、采集车内的实时视频数据,通过摄像头模块,实时采集车内的图像信息。另外为了减少误判断情况的发声,在汽车启动后,并且当检测到主驾驶位的安全带已经系上时,视频数据才开始采集。
s20、截取视频数据中的帧图像,并且分析驾驶位人员的实时坐姿。通常在正常驾驶的过程中,由于车座椅的限制,驾驶员的坐姿是比较固定的,只有出现了事故导致驾驶员失去意识时,驾驶员的坐姿才会发生长时间比较大的改变。
具体的,分析驾驶员实时坐姿的步骤如下子步骤:
s21、通过角点检测绘画驾驶员实时坐姿轮廓,并从中确定关键识别点。首先通过角点检测的方法,将驾驶员的轮廓进行绘画,并按照该轮廓对图像进行抽离处理。在将驾驶员轮廓抽取出来之后进行关键识别点的确定,本实施例中,关键识别点可以但不仅限于包括人脸五官、肩位轮廓或者头部轮中的一种。
坐姿可以但不仅限于廓包括手部动作,头部动作以及身位等,由于驾驶过程中手部活动频率多变,因此本实施例将确定重点放在了人脸、头部动作以及身位这些个要素。
通过描绘肩部轮廓来识别驾驶员是否处于正常驾驶状态,处于正常驾驶状态是,其肩部轮廓应该是大致对称的,而且头部也是会向前张望。若出现事故导致失去意识,其头部和身位将失去了支撑,会持续倒向一边。
另外,脸部识别可以进行判断依据,可以通过人脸识别抽离五官位置,当出现事故时,五官位置将会产生很大的变化,如整体偏转、闭眼或者受伤流血等。
s22、计算关键识别点之间的实时位置比例关系,
s23、将实时位置比例关系与标定坐姿的位置比例关系进行比较;
在上述两个步骤中,将步骤s21中分离出来的关键识别点进行计算,如肩位轮廓信息,倾斜后,其位置关系将发生了变化。可倾斜角度等数据。同时人侧头、低头等会产生相对位置的偏离。在通过相关的算法进行计算后与标定坐姿的位置比例关系进行比较。
举个例子,正常情况下,驾驶员双肩连线应该是趋近水平的,因此连线与水平线之间的夹角大于会在10°以内,如果驾驶员发生意外并是去意识后,其身位会产生倾斜,甚至达到30°或以上。
s24、计算变差量。将实际得到的数据与标定的数据进行计算,最终获得偏差量。
s30、如果偏差量显示实时坐姿与标定坐姿的差别过大,并且达到偏差阈值时,则判定为疑似发生事故。偏差阈值根据不同的判断对象进行设定,可以理解的,如过判断对象为肩部轮廓,其偏差阈值则是超过10°,如果为五官,则可以从其整体的倾斜角度,图像中五官间的距离等方面去设定。
另外,若持续达到阈值的持续时间超过第一预设时间段时,如1分钟等,则可以判定驾驶员出现异常,执行步骤s40。
s40、调用无线通讯模块向外发送求救信号。其中求救信号包括驾驶员预设的个人信息、卫星定位以及实时视频数据中的至少一种。
另外,司乘人员碰到抢劫车辆和财物的事件时,可能无法安全地发出救援信号,需要车辆辅助提供报警呼叫及影像资料,协助打击盗窃、抢劫机动车犯罪活动,维护车主的安全和利益。因此步骤s10还可以包括音频采集步骤:
s101、获取车内音频信号,并进行降噪处理;
s102、分析语音,并分解出关键词;
s103、将分解出的所述关键词与预设关键词匹配,预设关键词可以是劫匪在实施抢劫是所常用的词汇、语气等。
并且通过图像算法对车内人员的面部表情、相对动作来识别,识别到车内人员的惊恐表情、劫持动作时,结合语意进行基本分析,既可以判定此时是否出现犯罪情况,当确定犯罪情况发生后,通过无线通信模块将录音或者视频发送给服务商或者警方的服务器,对相关语意进行最终确认。
当服务商或者警方最终确定后,还可以控制车内的系统与外部建立实时视频通信,留下犯罪证据以及监控车内情况。
实施例2:
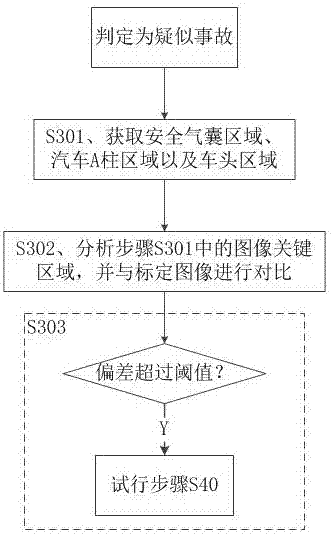
本实施在实施例1的基础上进一步的优化,如图2所示,为了提高事故判断的准确率,在实施例的步骤s30中,判断为疑似事故时,开可以通过执行车身图像实时情况的步骤:
s301、获取安全气囊区域、汽车a柱区域以及车头区域中至少一处图像。发生碰撞事故时,这三个位置通常损坏或者变化比较严重,可以通过获取上述三个区域的图像信息进行辅助判断。
s302、分析步骤s301中的图像关键区域,并与标定图像进行对比;
s303、当差别超过偏差阈值时,即可以判定该疑似事故为交通事故,直接执行步骤40。
实施例3:
另外,基于上述实施例的事故主动呼叫救援方法,本实施例还提供一种车载自动求救系统,如图3所示,包括:gps模块、gps模块、声音采集模块以及处理单元。
其中gps模块与处理单元通过通讯接口连接,用于获取汽车当前的位置信息。
摄像头模块与处理单元通过通讯接口连接,用于获取车内和周围的图像信息。本实施例中,摄像头安装在汽车内后视镜上,其包括前广角摄像头以及后广角摄像头,两者配合形成车内环视摄像头,可以获取车内人员、汽车a主以及车前盖方向图像信息。
声音采集模块则与处理器单元通过音频信号接口连接用于获取车内声音信息。
无线通讯模块与处理单元通过数据传输接口以及通讯接口连接,用于转发处理单元发出的求救信号。
处理单元,用于接收以及分析所述摄像头模块以及声音采集模块所输出的信息,并判定是否出现事故。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!