一种面向多种库位场景的自动泊车路径规划方法
1.本发明涉及驾驶辅助技术领域,尤其是涉及一种面向多种库位场景的自动泊车路径规划方法。
背景技术:
2.自动泊车技术作为汽车智能化的一项代表性技术,已经受到了高校与企业的高度关注。具有高精度性能的自动泊车路径规划算法,不仅可以使得车辆泊车无需过大的安全裕度,有助于改善库位规划增大土地利用效率,也可与未来需要车辆精准泊车的自动充电技术等进行有机结合。
3.相比于一般的自动驾驶场景,自动泊车的路径规划具有以下要求:
①
能够规划分段路径,以应对多段泊车及平行泊车的揉库过程;
②
规划应在确保安全性的基础上尽可能达到高精度,以便空间的充分利用以及与未来的充电桩技术相配合;
③
规划应尽可能以统一的规划算法完成规划,便于算法的简化;
④
随着未来车辆进一步的智能化,算法本身应具备自我更新的潜力,如此可以同人一样不断自我优化。现有的混合a*算法、rrt算法、lattice算法、人工势场法均无法单独运用实现多段路径的规划.
4.中国专利cn 113830079 a提出了一种混合a*算法配合cc曲线拼接的泊车路径规划算法,虽能够在不同库位下实现规划功能,但混合a*算法的代价函数的设计需要大量的前期计算工作,且对于不同库位仍然需要设计不同的cc曲线拼接形式,没有完全实现在不同库位下规划过程的统一。
5.中国专利cn 114906128 a通过使用强化学习进行平行泊车的规划,虽然保留了后续自我更新的能力,但由于神经网络被限定在平行泊车场景下进行训练,限制了网络在其它场景下的通用性,同时,网络使用的训练数据以0.04m为扩展步长,这会导致起始位姿数量增加时,数据量会激增,迫使神经网络更加复杂以承接更多的数据,而更复杂的神经网络则对应更久的训练速度与更大的计算量,这也会增加对车载系统的计算负担。
6.总之,目前的算法暂时无法完全满足上面提到的4项要求,而开发一套能够满足上述要求的算法,具有重大意义。
技术实现要素:
7.本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种面向多种库位场景的自动泊车路径规划方法,满足上述要求。
8.本发明的目的可以通过以下技术方案来实现:
9.一种面向多种库位场景的自动泊车路径规划方法,所述方法包括以下步骤:
10.获取库位类别、库位角点坐标和起始位姿;
11.结合库位类型进行坐标转换,统一车辆在平行、斜向和垂直泊车下的坐标系;
12.在统一坐标系下,通过神经网络获取粗规划路径散点序列;
13.对粗规划路径散点序列通过包括模拟跟踪、dwa和末端平滑的后处理获取规划路
径。
14.作为优选技术方案,所述进行坐标转换,统一坐标系的方法具体步骤包括:
15.车辆在原坐标系下的起始位姿为目标位姿为平行泊车以入库位姿为目标位姿;斜向和垂直泊车以最终位姿为目标位姿;
16.以车辆在新坐标系下目标位姿为(0,0,pi/2)进行坐标转换,新坐标系相比于原坐标系在x、y方向偏移旋转
17.根据坐标系转换关系求得新坐标系下的初始位姿和库位角点;
18.所述新坐标系下的初始位姿(x0,y0,θ0)与原坐标系下的起始位姿和目标位姿的坐标转换公式为:
[0019][0020]
式中,和分别是原坐标系下起始位姿的的横纵坐标和角度;和分别是原坐标系下目标位姿的的横纵坐标和角度;x0、y0和θ0分别是新坐标系下起始位姿的的横纵坐标和角度。
[0021]
作为优选技术方案,所述通过神经网络获取粗规划路径散点序列步骤包括:
[0022]
以车辆的当前位姿和坐标转换后的库位角点作为神经网络输入,输出扩展方向π和扩展曲率k的动作组合;
[0023]
基于神经网络出输出的动作组合,车辆以几何推算方式进行大步长扩展至下一状态;直至车辆由起始位姿扩展至目标位姿。
[0024]
作为优选技术方案,所述神经网络的训练步骤包括:
[0025]
利用基于rs曲线拼接的路径数据对神经网络进行模仿学习;
[0026]
通过多次设置不同库位类别、不同初始位姿利用神经网络进行寻优探索,获取回报值更高的数据再次更新网络,完成强化学习。
[0027]
作为优选技术方案,所述基于rs曲线拼接的路径数据为生成式数据,其生成过程为:
[0028]
基于人类驾驶员在平行、斜向、垂直库位下泊车经验,定义多种rs曲线拼接形式;
[0029]
利用在不同库位下,不同起始位姿和目标位姿之间的位置关系,通过几何计算获得rs曲线的长度和曲率;
[0030]
基于rs曲线生成训练神经网络所需要的位置信息和对应的动作类别。
[0031]
作为优选技术方案,所述回报值r
total
的函数为:
[0032]rtotal
=r
change_dir
+r
space
+r
lengt
+r
reach
+r
colli
+r
change_cur
[0033]
式中:
[0034]rchang_dir
为换挡回报值,换挡次数越多换挡回报值越低;
[0035]rspace
为路径空间利用回报值,利用空间越多路径空间利用回报值越低;
[0036]rlengt
为路径长度回报值,路径长度越长路径长度回报值越低;
[0037]rreac
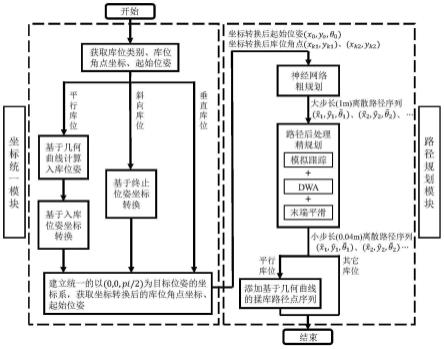
为最终姿势评估值,代表是否达到目标位姿,达到允许范围内可获得回报值,若再次基础之上能够以更小误差贴合目标位姿,可额外再获得回报值;
[0038]rcolli
为碰撞回报值,在扩展过程中若碰撞则大幅减少回报值;
[0039]rchang_cur
为曲率变化回报值,在扩展过程中曲率变化越大回报值越低。
[0040]
作为优选技术方案,所述模拟跟踪方法为:
[0041]
利用车辆运动学模型,建立横向控制状态方程,通过反馈加前馈设计前轮转角,考虑车辆动力学约束,模拟车辆对粗规划路径散点的跟踪过程,通过运动学模型以小步长扩展,模拟跟踪获得的路径散点序列作为的规划数据;
[0042]
所述运动学模型扩展由目标位姿出发,向起始位姿反向扩展。
[0043]
作为优选技术方案,所述dwa的步骤包括:
[0044]
对许可范围内的车辆前轮转角进行采样;
[0045]
设定固定的扩展长度,比较不同采样结果对应的扩展路径的回报值;选择价值r
total
最大的作为此刻的理想前轮转角值;
[0046]
其中价值r
total
的函数定义为:
[0047]rtotal
=r
follow_pat
+r
avoid_obstacle
[0048]
式中:
[0049]rfollow_path
代表与模拟跟踪计算的转角值的符合程度回报值,采样值与模拟跟踪计算的转角值偏差越小,符合程度回报值越高;
[0050]ravoid_obstacle
代表扩展完毕后车辆碰撞回报值,利用车辆与障碍物之间的距离计算,距离越小,撞回报值越低。
[0051]
作为优选技术方案,所述末端平滑为在探索终止位置与目标位姿的中线为界进行两段模拟跟踪:
[0052]
第一段保持反向扩展的方向继续以模拟跟踪的方式扩展出一定距离,消除车辆与中线之间的横向偏差;第二段与第一段反向,消除车辆与目标位姿之间的横向偏差。
[0053]
作为优选技术方案,进行平行泊车路径规划时,在后处理获取规划路径后额外添加基于几何圆弧曲线的揉库路径散点序列。
[0054]
与现有技术相比,本发明具有以下有益效果:
[0055]
1)统一性:本发明通过坐标转换并在新坐标系下进行规划,能够利用统一的算法完成在不同库位、不同初始位姿下的规划。
[0056]
2)精准性:本发明由于在路径后处理时由目标位姿反向扩展,因此实现了路径相对于目标位姿的零误差。
[0057]
3)自我更新性:本发明使用了神经网络,而神经网络本身具备探索能力,有机会探索更优数据,这意味着算法具备自我更新的潜力。
[0058]
4)低成本实现性:本发明规定神经网络扩展步长为1m,这使得在训练时,使用较少的数据量即可覆盖较多工况,无需增加神经网络复杂度。
附图说明
[0059]
图1为本发明的整体原理框图;
[0060]
图2为不同库位下坐标转换的效果图;
[0061]
图3为坐标转换后不同库位过程的总结效果图;
[0062]
图4为平行泊车入库位姿计算方法示意图;
[0063]
图5为四种rs曲线拼接形式示意图;
[0064]
图6为直线-圆弧-直线的曲线尺寸计算示意图;
[0065]
图7为基于rs曲线的用于模仿学习的数据集数据示意图;
[0066]
图8为不同库位下障碍车角点示意图;
[0067]
图9为强化学习滚动探索流程示意图;
[0068]
图10为车辆对神经网络规划锚点进行模拟跟踪的示意图;
[0069]
图11为车辆模拟跟踪时横向偏差示意图;
[0070]
图12为车辆与锚点“平齐”状态的示意图;
[0071]
图13为dwa(动态窗口法)原理示意图;
[0072]
图14为利用包络圆覆盖八边形车辆轮廓示意图;
[0073]
图15为末端平滑原理示意图;
[0074]
图16为平行泊车规划结果示意图;
[0075]
图17为斜向泊车规划结果示意图;
[0076]
图18为垂直泊车规划结果示意图。
具体实施方式
[0077]
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
[0078]
本发明提出了一种面向多种库位场景的自动泊车路径规划方法,如图1所示,整个方法共分为坐标统一模块与路径规划模块。
[0079]
先前已提到,未来的自动泊车路径规划算法应满足四项要求:
①
能够规划分段路径,以应对多段泊车及平行泊车的揉库过程;
②
规划应在确保安全性的基础上尽可能达到高精度,以便空间的充分利用以及与未来的充电桩技术相配合;
③
规划应尽可能以统一的规划算法完成规划,便于算法的简化;
④
随着未来车辆进一步的智能化,算法本身应具备自我更新的潜力,如此可以同人一样不断自我优化。则根据第
①
点要求,不便于单独使用进行多段路径规划的方法如混合a*算法、rrt算法、lattice算法、人工势场法等不会使用,而能够考虑的方法只能是如中国专利cn 113830079 a提出的传统的曲线拼接,如cc曲线拼接的规划方法,以及如中国专利cn 114906128 a提出的机器学习的方法。而根据第
④
点要求,使用传统的曲线拼接没有自我更新的能力,因此使用机器学习的方法最为合适。然而该算法限定了平行泊车场景,其网络只能应用于平行泊车,其次,网络的训练采用的是以5ms为间隔的轨迹点数据,这使得单一工况对应了大量数据,有限的网络结构无法承接多工况的训练数据。不仅如此,轨迹点完全由网络探索获得,为确保探索能够结束,需设定较宽泛的终止条件,而宽泛的终止条件又无法确保规划结果的精确性。
[0080]
基于上述分析,神经网络的使用可以满足第
①④
点要求,而强化学习则是使网络获得优异性能的一种有效手段。在强化学习中,数据的价值是由回报函数确定的,而在回报函数中,规划终止位姿与目标位姿之间的贴合程度是极为重要的一项。由于单一的神经网
络应仅能基于一个回报函数进行训练,终止条件也应该是唯一的,这也就意味着平行、斜向、垂直泊车的目标位姿也必须是统一的,如此,神经网络就可以按统一的标准探索在不同库位下的数据,按统一的终止条件进行探索,也就能通用于不同库位,实现第
③
点要求中提到的算法统一性。由于神经网络探索的随机性,为确保其探索过程能够顺利结束,需要设定宽容的终止条件,即当探索到与目标位姿误差低于一定范围的位姿时结束探索,而一旦存在这样宽容的范围,神经网络又将在存在误差时停止探索,无法确保第
②
点提及的精准性要求。由于这一点要求无法仅依靠神经网络可靠地完成,因此在神经网络的基础上,还需增加其它算法的辅助。
[0081]
据此可得出结论,在应用神经网络之前,需要将不同库位下的目标位姿通过坐标转换进行统一才能进行训练。这样训练虽能够实现不同库位下算法的统一性,但这也意味着,神经网络的训练对象将是三种库位下的任意起始位姿,其数据量必然十分庞大,因此需制定对策,在确保训练有效性的前提下减少数据量,以避免数据量过大连带的网络复杂度增加的问题:
[0082]
a.第一种方式是尽可能降低网络输入维度,从而减少对应的场景数量以减少数据量。中国专利cn 114906128 a使用的网络输入为车辆坐标及航向角(x,y,θ)和车辆当前方向盘转角和车速v,输出为方向盘转角变化量和加速度a,确保了规划结果符合动力学约束,可这使得一个场景由五个量来决定,成倍增加了需要训练的场景数量。因此,新的神经网络将使用车辆坐标及航向角(x,y,θ),以及代表库位的库位角点(x
k1
,y
k1
)、(x
k2
,y
k2
),输出为前进方向π和扩展曲率k。以上输入是能够表示不同场景下不同位姿的最简化情况。
[0083]
b.第二种方式是增加探索步长。中国专利cn 114906128 a使用的数据为间隔5ms的轨迹数据,这使得单一工况即对应数百组数据,一旦工况增加,数据量会激增。因此新的神经网络以1m为步长探索,这使得单一工况最多只有20组左右的数据,因此网络无需增加复杂度即可承接更多的不同工况的数据。
[0084]
以上两点措施能够缓解神经网络的训练压力,但其缺陷也是很明显的:首先神经网络规划的不是带有实时速度和前轮转角轨迹点,而是单纯的表示位姿的路径点,无法同时设计速度和转角指令;其次,探索结果完全没有考虑动力学约束,曲率是不连续的;第三,路径点间隔为1m,路径点之间缺少信息,不能直接用于跟踪。以上三点决定了神经网络的探索只能是一个粗规划,需要增加后处理实现精规划。
[0085]
精规划的步长可设为0.04m,近似为车辆一个码盘格的长度。而为了确保路径能够零误差到达目标位姿,精规划的扩展方向是由目标位姿向起始位姿扩展的。由于不便直接修改神经网络的规划结果,这里采用了模拟跟踪的方法。在考虑车辆动力学约束的情况下,利用运动学模型建立车辆对神经网络规划路径的横向控制状态方程,模拟车辆在跟随曲率不连续的路径时的实际路径,而模拟出的路径结果即可作为规划结果。同时,为确保车辆在规划途中不会与前后障碍车、边界碰撞,使用dwa(动态窗口法)作为辅助,在能够避免碰撞的前提下,尽可能使车辆扩展方向与模拟跟踪计算所得的扩展方向一致。最后,由于车辆由目标位姿向起始位姿扩展,扩展停止时可能与起始位姿之间存在偏差,增加了末端平滑的机制,该机制通过设定参考线,使用一前一后的两段模拟跟踪消除残留误差。至此,路径后处理也设计完毕,能够与神经网络的粗规划良好配合。
[0086]
基于以上分析,现对本发明涉及的两个模块进行详细介绍。
[0087]
1、坐标统一模块
[0088]
坐标的统一是为了使得各种库位下泊车目标位姿统一,便于使用单一的神经网络进行训练并通用于所有库位,但目标位姿的选择需要考虑。在规划时,平行库位与垂直和斜向库位均有入库过程,而揉库部分是平行库位下特有的过程,因此在算法统一设计时不应把平行泊车的揉库规划考虑在内,统一的算法框架在平行库位时只规划到入库位姿为止。这也就意味着平行泊车的目标位姿实际上应是入库位姿,不是最终位姿;垂直和斜向泊车的目标位姿可以设定为最终位姿。
[0089]
三种库位下泊车路径的坐标转换效果如图2所示。三种库位下泊车坐标系初始有所不同,但一旦确定目标位姿后,进行坐标转换即可使目标位姿统一。而通过图2可以看到,车辆在不同库位下的泊车过程,本质上只是由不同位置出发,避开分布情况不同的障碍物,最终到达同一位置。这也意味着车辆在不同库位下的泊车过程可以总结为一个避障问题。图3是对上述结论的一个总结:
[0090]
a.垂直泊车由a点出发,避开障碍车
①②
向o点规划;
[0091]
b.斜向泊车由b点出发,避开障碍车
③④
向o点规划;
[0092]
c.平行泊车由c点出发,避开障碍车
⑤⑥
向o点规划;
[0093]
此外,车辆在不同库位下向o点规划时,在避开障碍车时也要避免与规划边界碰撞。
[0094]
若车辆在原坐标系下的起始位姿为目标位姿为则为使得车辆在新坐标系下目标位姿为(0,0,pi/2),则新坐标系相比于原坐标系在x、y方向应偏移旋转则根据坐标转换公式可建立在新坐标系下初始位姿(x0,y0,θ0)与和的关系:
[0095][0096]
新坐标系下的库位角点(x
k1
,y
k1
)、(x
k2
,y
k2
)可用类似的方式求得。
[0097]
前面特别提到,平行泊车需要计算出入库位姿后才能进行坐标转换。平行泊车入库位姿的计算如图4所示。揉库路径简单地设计成圆弧曲线,车辆在库位内由终止位置o点,通过圆弧曲线揉库至o
′
点,若此时车辆由当前位置以最小曲率半径前进时,最危险点k点不会与前障碍车碰撞,则认为车辆当前位姿为入库位姿。在揉库过程中,车辆需确保不会与前、后障碍车和右边界碰撞,即确保图4中δl1、δl2、δl3始终大于阈值,该阈值可设定为15cm至20cm。
[0098]
至此,坐标统一全部完成,而这是后续算法实施的重要基础。
[0099]
2、路径规划模块
[0100]
根据前文设计,路径规划模块包含两部分:神经网络粗规划和路径后处理精规划。下面分别进行详细介绍。
[0101]
(1)神经网络粗规划
[0102]
神经网络在使用之前需要进行训练才能确保良好性能,而为减少训练进程,神经网络可以首先通过模仿学习获得基本性能,而后通过强化学习进一步提升性能。因此,需要制作能够应用于模仿学习的数据集。
[0103]
a.数据集制作
[0104]
中国专利cn 113830079 a使用的cc曲线拼接的方法虽不具备自我更新能力,但该方法依靠的是严格的几何计算,其性能是较为稳定的。因此,数据集的制作也可以基于这种方法。由于cc曲线的计算较为复杂,且先前的设计也提及到,神经网络无需给出曲率连续的数据点,因此数据集的制作可以降低要求,使用rs曲线即可满足要求。
[0105]
使用rs曲线进行拼接之前,需首先定义若干拼接形式从而进行几何计算。基于人类驾驶员在平行、斜向、垂直库位下泊车经验,共定义如图5所示的四种曲线形式,分别为直线-圆弧-直线、直线-圆弧-圆弧-直线、圆弧-直线-圆弧-圆弧-直线、直线-圆弧-直线-圆弧-直线。图5中的叉代表不同形状段的边界点。
[0106]
路径的计算基于严格的几何关系,以最简单的直线-圆弧-直线为例说明计算过程,如图6所示,车辆由s点出发,初始坐标(xs,ys,θs),需泊车至终点o,其坐标为(xo,yo,θo),整个过程最易发生碰撞的点为c(xc,tc)。车辆以直线-圆弧-直线规划路径,将出现拐点a(xa,ya,θa)和b(xb,yb,θb),且按照几何关系,a、b点与o、s点之间的位置关系为
[0107][0108]
这里l
bs
、l
oa
为线段bs和oa的长度。在a、b航向角确定,圆弧角度δθ确定的情况下,一旦给定了圆弧半径r,则基于圆弧形状,可确定a、b间位置关系
[0109][0110]
因此,若圆弧半径r能确保车辆不与c碰撞,则可通过r求出l
bs
、l
oa
。
[0111]
其它形式的曲线计算机理类似。而在选择圆弧半径r,也即圆弧曲率κ时,为确保能够与后续的神经网络训练相配合,给定曲率κ的取值在-0.2与0.2之间,以0.05为间隔,共9个可选曲率。按上述规则计算后得到的rs曲线为隐式形式如式(2.3)
[0112][0113]
式中l1、l2、l3为沿弧长的分段边界;ρ1、ρ2、ρ3为本段内的曲率值;q1、q2、q3为本段路径的车辆行驶方向(前进为1,倒车为-1);π1、π2、π3为本段路径的方向盘转向方向(左转为1,右转为-1);sd为沿路径的长度。采集数据点可依据式(2.3)规定的形状与扩展方向,每1m取
一个数据。
[0114]
数据应包含平行、斜向、垂直三种库位下的多起始位姿的规划数据,且所有规划的目标位姿均为(0,0,pi/2),最终可提取出如图7所示的数据结果。图7中只显示了数据点所在的x、y坐标位置,但实际上航向角、运动方向、曲率、障碍车角点坐标也需要一并记录。图8标注了不同库位下分别需要记录的障碍车角点k1、k2。以上记录的所有数据均应是坐标转换之后的数据。
[0115]
b.模仿学习/强化学习
[0116]
上述的基于rs曲线的数据集将用于模仿学习。这里再次说明,数据集每一组数据包含的是车辆的位置信息(x,y,θ)、车辆所在库位障碍车角点坐标(x
k1
,y
k1
)和(x
k2
,y
k2
)、车辆运动方向π、车辆运行曲率κ。神经网络的7输入即为车辆位置信息和库位障碍车角点,18分类输出由不同的车辆运动方向与不同的运行曲率两两组合而成,其中运动方向为前进与后退2种,运行曲率为-0.2至0.2,以0.05为间隔。
[0117]
由于通过大步长提取数据,因此即使工况众多,数据量仍然适中。本发明中,在三种库位下通过改变初始位姿,生成了约500种不同工况下的10000~15000组数据。这使得神经网络结构无需过于复杂。本发明使用的网络除去输入层和分类层外,包含两个隐藏层,神经元数量均为25。上述数据中有70%为训练集,15%为验证集,15%为测试集。
[0118]
神经网络在经过模仿学习后已经有了初步的规划能力,而强化学习将使网络的性能得到进一步提升。强化学习的目标是在现有策略基础上,通过探索尽可能获得更加优秀的数据序列{(si,ai)|i=0,1...n-1}并加以储存,最后利用不同工况下存储的数据序列对网络再一次更新,进一步提升网络性能。其中,si代表第i个状态,包含了车辆在某一工况下的坐标、航向角和障碍车角点共7个数据,ai代表在状态si下的、包含了运动方向与运行曲率的最优动作组。i=0时的s0代表初始状态,车辆处于si状态时,采取动作组ai转移到下一状态s
i+1
,当i=n-1时,车辆采取动作组a
n-1
将转移至最终状态sn。
[0119]
车辆遵循运动学模型进行扩展,但由于是大步长(1m)扩展,车辆的扩展结果需要借助几何计算:
[0120]
①
当曲率κi=0时
[0121][0122]
②
当曲率κi》0时
[0123][0124]
③
当曲率κi《0时
[0125][0126]
强化学习的回报函数r
total
被设计为
[0127]rtotal
=r
change_dir
+r
space
+r
length
+r
reach
+r
colli
+r
chang_cur
(2.7)
[0128]
各部分具体定义为
[0129][0130]
以上各式中:
[0131]
①rchange_dir
代表换挡回报值,根据换挡次数dir_change计算;
[0132]
②rspace
代表空间利用回报值,根据路径最左x坐标值x
left
、最右x坐标值x
right
、最上y坐标值y
up
、最下坐标值y
down
计算;
[0133]
③rleng
代表路径长度回报值,根据路径总长度length_total计算;
[0134]
④rreach
代表最终姿势评估值,由基础回报值r
reac_basic
和额外回报值r
reach_extra
两部分构成。由于神经网络采用大步长探索,且神经网络规划后仍有后处理过程,因此网络的探索不必十分精确地到达最终位姿,只需到达便于后处理的位姿即可。若探索结果(x,y,θ)能够满足
[0135][0136]
即可获得r
rea_basic
=40000,若探索结果在此基础上能够进一步贴近目标位姿,可获得额外回报值r
reach_extra
,可计算为
[0137]rrea_extr
=20*(0.05-|x|)/0.05+100*(0.25-|θ-pi/2|)/0.25(2.10)
[0138]
⑤rcolli
代表碰撞回报值,若路径与障碍车发生碰撞,is_colli即为1,否则为0;
[0139]
⑥rchange_cur
代表曲率变化回报值,由连续两步最大曲率变化量max_curve_change计算。
[0140]
寻优过程如图9所示。在选定库位和起始位姿后,使用单步mcts进行探索:未达到终止条件前,以当前状态进行扩展,遍历全部的18类动作组合,获得对应的18个子状态,而后由18个子状态开始利用神经网络结合轮盘赌规则进行滚动探索,可获得18条路径点序列,选取回报值最高的序列对应的动作组作为本次扩展的动作组,进入下一状态,并将该序列与当前库位、起始位姿下最大回报值对应的序列相比对,保留回报值较大的序列;到达下一状态后重复上述过程;达到终止条件后,将该起始位姿下最大回报值序列存入数据池。以上探索的直接效果是,在扩展过程中不断试图利用更优的路径点序列更新已有序列,最终
使得当前库位、起始位姿下的路径点序列是最优的。若在不同库位、不同起始位姿下均多次进行上述过程,则数据池中将保存大量的优化数据,以这些数据对神经网络再次进行训练,即可增强网络效果。
[0141]
(2)路径后处理精规划
[0142]
由于神经网络的规划结果是间距为1m的离散路径点,存在相邻点扩展曲率不连续的问题,不能被直接用来进行跟踪,因此需要进行后处理,其步长可设置为一个码盘单元的长度0.04m。不仅如此,神经网络的规划只到达了便于后处理的位姿,并未精确到达目标位姿,为确保规划的精准性,后处理的扩展应从目标位姿向起始位姿反向扩展。
[0143]
a.模拟跟踪
[0144]
模拟跟踪,顾名思义即是通过假想车辆正在跟踪某条路径,虽然由于动力学约束,车辆无法完全跟踪该路径,但车辆为跟踪该路径实际走出的路径必定是符合车辆动力学约束,可以真正被跟踪的,从而可以将车辆在模拟跟踪时走出的实际路径作为最终的路径规划结果。
[0145]
神经网络规划出的路径点实际上可以视为若干“锚点”,车辆在模拟跟踪时只需要沿着这些锚点标注的扩展方向跟踪即可,而是否能够精确到达锚点并不是必须要求。模拟跟踪的示意图为图10。
[0146]
由于神经网络的锚点包含了锚点的坐标和航向角该位置下扩展方向和扩展曲率这使得由神经网络规划的任意两点间的路径可以视为简单的圆弧,而模拟跟踪则是尝试在动力学约束下,跟随这条由若干圆弧首尾连接的、曲率不连续的路径。由于路径是圆弧,使得车辆与路径之间的横向偏距与角度误差易于计算,因此采取简单的前馈+反馈设计横向控制器即可。车辆跟随圆弧曲线的过程如图11所示,以车辆后轴中点的车辆参考点,控制器设计过程如下:
[0147]
①
横向偏差e1的变化率与车辆速度v和角度偏差e2相关,并结合小角度假设,有
[0148][0149]
②
角度偏差e2的变化率与车辆速度v、车辆当前前轮转角ψ、车辆轴距l、路径曲率κ相关,并结合小角度假设,有
[0150][0151]
设定控制变量u=tanψ,则有状态方程
[0152][0153]
建立控制变量u与偏差e1、e2的关系,并添加前馈量,为
[0154]
u=-k1e
1-k2e
2-lκ
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2.14)
[0155]
由此建立横向控制器用于模拟跟踪,而在模拟跟踪时需结合动力学约束设置前轮转角ψ的变化范围。
[0156]
先前提到,模拟跟踪时不把车辆是否能够精确到达锚点作为要求,只需按照锚点指引的方向进行扩展即可。实际在模拟跟踪时,当车辆到达与锚点“平齐”的位置,即认为车辆可以进行下一段圆弧的跟踪。车辆与锚点“平齐”的状态如图12所示,当车辆状态为(x,y,
θ),锚点为且锚点处储存的动作组为则当锚点与车辆所成向量与锚点自身方向所成角度小于pi/2时,认为“平齐”。
[0157]
b.dwa(动态窗口法)
[0158]
需注意的一点是,神经网络在规划时没有考虑泊车环境的边界,同时为进一步确保车辆在扩展过程中不会与前后障碍车以及环境中可能出现的其它障碍物碰撞,需要辅助使用能够灵活结合当前位置进行避障的方法。
[0159]
本发明中采取的即是dwa(动态窗口法)。其原理是通过对可能的动作进行采样,利用采样动作前进一段距离,根据前进过程中是否与障碍物碰撞、是否符合预期设计前进方向等对采样动作进行评价,选择评价最高的动作作为本次前进选择的动作。dwa被广泛应用于机器人的路径规划,而本发明面向的是车辆的路径规划,因此在使用dwa时进行了如下修改:
[0160]
①
仅使用在单个采样动作前进后达到的终止位置进行评价,而不是利用整段前进路径进行评价。这是由于车辆的尺寸比一般的机器人要大得多,而采样动作扩展的距离不及车身总长度的一半,若车辆在扩展过程中与障碍物碰撞,则实际上终止位置大概率也将与障碍物碰撞,终止位置的状态足够代表整段路径的状态。同时,仅计算终止位置将省去较多计算,不至对车载系统造成过大压力。
[0161]
②
对前轮转角采样时,仅考虑前轮转角能够达到的最大范围,不考虑在当前转角下使用采样动作是否满足转速要求。这是由于泊车时,车辆所处环境狭小,车辆始终与障碍物保持较近的距离,若考虑转速,将导致探索范围减小,可能会导致使用所有采样动作扩展时全部都与障碍物碰撞的情况,此时车辆更加需要知道的是是否有一个方向可能避开障碍物,而不是仅仅能够满足转速要求的转角。
[0162]
dwa的示意图如图13。在采样时,由于车辆前轮转角范围为
±
30
°
,为避免采样动作过多增加过多计算量,采样时以3
°
为间隔,共21个采样动作,并结合实际效果,选择扩展40*0.04=1.6m,获取21个终止位置,并对该21个终止位置进行评价,选择最高评价对应的动作作为下一步动作。
[0163]
评价函数被定义为
[0164]rtotal
=r
follow_path
+r
avoid_obstacle
ꢀꢀꢀꢀꢀꢀꢀ
(2.15)
[0165]
其中:
[0166]
①rfollow_path
代表采样值ψc与模拟跟踪计算的转角值ψ
p
的符合程度回报值,采样值与模拟跟踪计算的转角值偏差越小,该项价值越高,具体定义为
[0167]rfollow_path
=-|ψ
c-ψ
p
|
ꢀꢀꢀꢀꢀꢀꢀ
(2.16)
[0168]
②ravoid_obstacle
代表扩展完毕后车辆碰撞回报值,利用车辆与障碍物之间的距离dis计算,距离越小,该项价值越低,具体定义为
[0169][0170]
这里需注意的是,车辆与障碍物之间的距离dis实际计算较为麻烦,车辆原为八边形轮廓,与其它障碍物距离的计算实际为多边形与多边形之间距离的计算,计算繁琐。本发明使用4个包络圆将车辆轮廓覆盖如图14,如此,虽多花费一些空间,但车辆与其它障碍物
之间的距离计算可简化为点与多边形之间的距离计算。
[0171]
c.末端平滑
[0172]
前面已提到,后处理由目标位姿向起始位姿反向探索。但由于神经网络的路径点曲率不连续,模拟跟踪本身即无法完全跟随;其次,dwa的使用会使车辆在临近障碍物时做出些许调整。以上两点均会导致车辆在反向扩展时,无法精确回到起始位姿。若反向探索结果与起始位姿相差过大,则车辆在初始时将有较大误差,导致后续路径跟踪模块会计算出一个较大的转角值,使得车辆在初始运行时方向盘转角有强烈抖动,使得乘客的舒适度有所降低。因此,需补充末端平滑策略避免初始误差过大。
[0173]
造成方向盘转角抖动具体是由于反向探索的终止位置与目标位姿之间存在较大的横向误差,因此,末端平滑的目标是通过增加车辆的运行过程,通过额外的进退消除横向偏差。由于在大多数情况下,乘客不会故意在障碍物附近开启自动泊车功能,因此出于简化设计的目的,末端平滑不考虑避障。
[0174]
如图15所示,车辆在反向探索终止位置与目标位姿存在横向偏差,可取二者中线为界进行两段模拟跟踪:第一段保持反向探索的方向,消除车辆与中线之间的横向偏差;第二段与第一段反向,消除车辆与目标位姿之间的横向偏差。
[0175]
通过上述过程即可利用统一框架,完成车辆在不同库位、不同起始位姿下的规划。特别地,对于平行泊车而言,上述框架只能规划出入库路径,其库位内路径需要基于几何圆弧线,与入库路径合并为最终规划路径。图16、17、18分别为车辆在平行、斜向、垂直库位下规划的效果图,而仿真结果也表明,规划出的路径是完全可以被跟踪的。
[0176]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1