一种电动汽车充放电管理方法及系统与流程
本发明涉及电动汽车充放电的,具体涉及一种电动汽车充放电管理方法及系统。
背景技术:
1、目前,市面上的电动汽车充电模式主要分为直流快充、交流慢充与更换电池三种模式。直流快充指的是直流高压大电流充电,具有充电功率大,充电时间短的特点,能在较短时间内完成充电任务,但是如此高的功率会给电网稳定运行带来一定的威胁。交流慢充指的是通过交流电源小电流充电,具有充电功率较小,充电时间长的特点,其充电功率一般在3.5kw/h或7kw/h,这种充电方式对电网冲击较小,并且有利于延长电动汽车的电池使用寿命。更换电池则是通过更换一个已经充好电的电池来给汽车重新供电,但是技术推广难度大,应用并不广泛。
2、电动汽车的迅猛发展给电网的经济、安全运行带来了巨大的机遇与挑战,电动汽车的充电过程主要分三个阶段,分为涓流充电、恒流充电与恒压充电三个阶段,第一阶段刚开始进行充电时电压较低,在该阶段电压会快速升高,持续的时间较短;第二阶段维持充电电流稳定,此阶段是电动汽车整个充电过程中的主要阶段,一般能将电池容量充至其额定容量的80%;第三阶段的充电电压将不会再变化,充电电流会随着电压的升高而减小,当电流减小至某一个值时,充电就会自动结束从而保护电池。
3、因此电动汽车作为一种分布式储能单元参与电网调控,引导其有序充放电,可以发挥负荷调度的作用,实现削峰填谷、促进新能源消纳。现有电动汽车充放电管理技术通常默认已知拓扑的信息和相关参数,或者部分方法还需对配电网进行改造,但是当前实际配电网中,尤其是配电台区的拓扑信息和量测数据都相对缺失,不利于电动汽车充放电管理,而对配电网进行改造的方法,增大了经济投资压力。
技术实现思路
1、为解决现有技术中存在的不足,本发明提供一种电动汽车充放电管理方法及系统,通过电动汽车充电桩与ttu之间的信息交互,即深度强化学习模型中智能体与环境的交互,以有功功率损耗最小为优化目标,得到电动汽车最优的调控策略,进行电动汽车充放电管理,在经过基于深度强化学习的电动汽车调控后,可以有效的提高电网的利用效率,考虑了配电网尤其是配电台区内拓扑未知、信息量测不全的未知环境下对电动汽车充放电时间进行合理的调控,适用于在复杂不确定性的环境中寻找最优策略,从而可以发挥负荷调度的作用,实现削峰填谷、促进新能源消纳,同时提高了台区现有设备的利用率,避免了额外的经济投入。
2、本发明采用如下的技术方案。
3、一种电动汽车充放电管理方法,基于电动汽车充电桩与ttu之间的交互信息,以有功功率损耗最小为奖励函数构建深度强化学习模型,采用深度强化学习模型对电动汽车充放电过程进行学习,并同时考虑t时刻和t+1时刻的奖励,最终得到电动汽车最优的调控策略,根据最优的调控策略进行电动汽车充放电管理。
4、优选地,所述方法包括以下步骤:
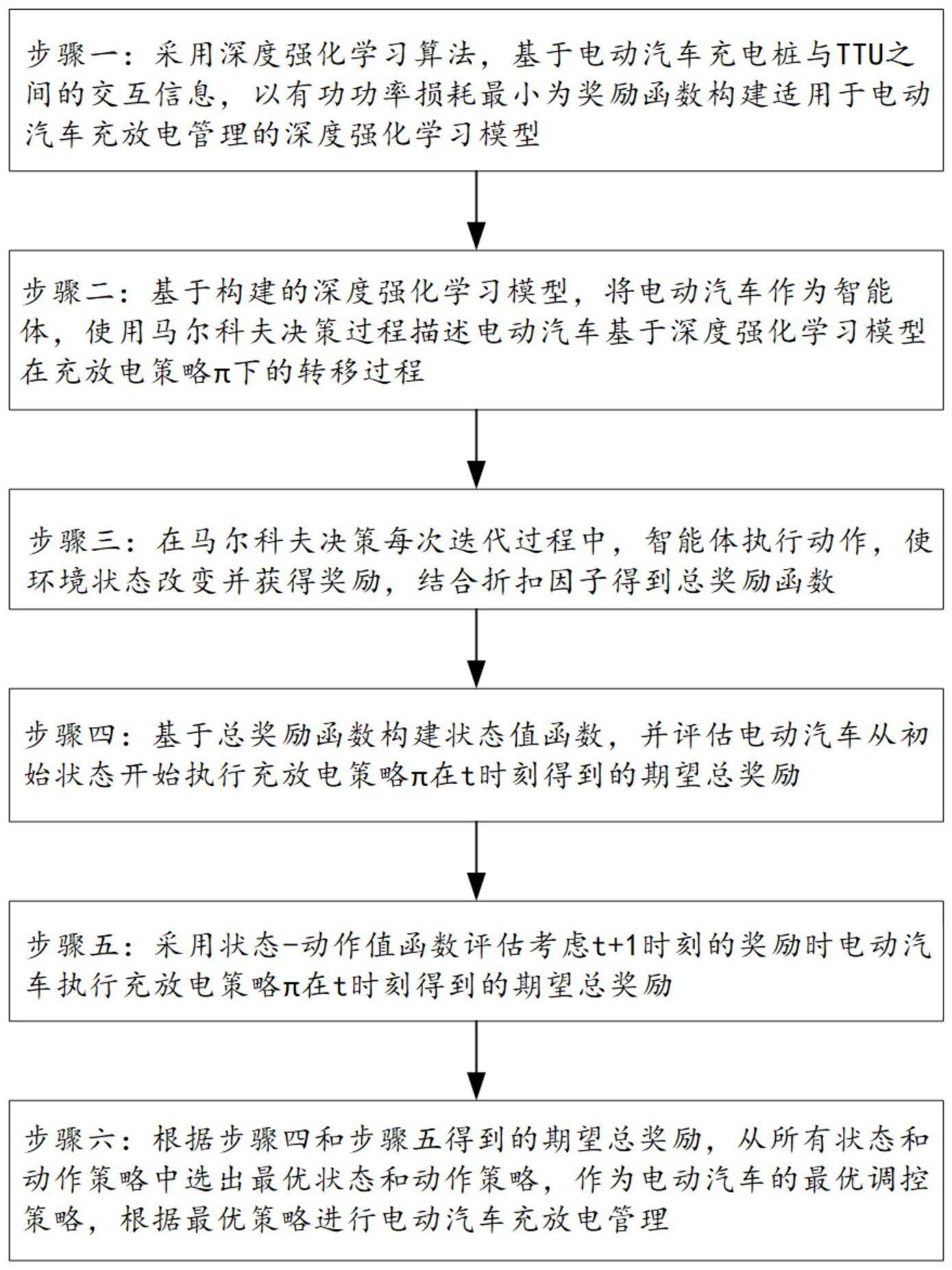
5、步骤一:采用深度强化学习算法,基于电动汽车充电桩与ttu之间的交互信息,以有功功率损耗最小为奖励函数构建适用于电动汽车充放电管理的深度强化学习模型;
6、步骤二:基于构建的深度强化学习模型,将电动汽车作为智能体,使用马尔科夫决策过程描述电动汽车基于深度强化学习模型在充放电策略π下的转移过程;
7、步骤三:在马尔科夫决策每次迭代过程中,智能体执行动作,使环境状态改变并获得奖励,结合折扣因子γ得到总奖励函数;
8、步骤四:基于总奖励函数构建状态值函数,并评估电动汽车从初始状态s0开始执行充放电策略π在t时刻得到的期望总奖励;
9、步骤五:采用状态-动作值函数评估考虑t+1时刻的奖励时电动汽车执行充放电策略π在t时刻得到的期望总奖励;
10、步骤六:根据步骤四和步骤五得到的期望总奖励,从所有状态和动作策略中选出最优状态和动作策略,作为电动汽车的最优调控策略,根据最优策略进行电动汽车充放电管理。
11、优选地,步骤一中,适用于电动汽车充放电管理的深度强化学习模型为元组(s,a,p,r);
12、其中,s表示状态的集合,所述状态为充电桩所在节点的有功功率、无功功率以及电压;
13、a表示动作的集合,所述动作为电动汽车功率调节挡位;
14、p表示状态转移概率集合;
15、r表示奖励函数,为有功功率损耗最小。
16、优选地,步骤二中,电动汽车基于深度强化学习模型在充放电策略π下的转移过程为:
17、在充放电策略π下,当智能体在状态st时执行动作at,并以概率p转移到下一状态st+1,同时接收来自环境对于动作的反馈,即奖励rt;
18、上述的转移过程满足马尔科夫性:下一时刻状态仅与当前时刻状态有关,而与前序状态无关,即:p(st+1|st,...,s0)=p(st+1|st);
19、其中,s0、st和st+1分别代表初始时刻、t时刻和t+1时刻的状态。
20、优选地,步骤三中,总奖励函数为:
21、
22、式中,rt代表总奖励函数;
23、rt+i代表t+i时刻的奖励,i=1,2,3,...,k+1;
24、γ代表折扣因子;
25、k代表迭代次数。
26、优选地,步骤四中,状态值函数vπ(s)为:
27、
28、式中,vπ(s)为电动汽车从初始状态s0开始执行充放电策略π在t时刻得到的期望总奖励;
29、e为期望;
30、st=s0表示从初始时刻的状态开始。
31、优选地,步骤五中,状态-动作值函数为:
32、qπ(st,at)=e[rt+1+γqπ(st+1,at+1)|st=s0,at=a0];
33、式中,qπ(st,at)代表考虑t+1时刻的奖励时电动汽车执行充放电策略π在t时刻得到的期望总奖励;
34、st和at分别代表t时刻的状态和动作;
35、st=s0表示从初始的动作开始;
36、at=a0表示从初始的动作开始。
37、优选地,步骤六中,最优状态和动作策略为下述两式的最大值对应的状态和动作:
38、(1)π*=arg max vπ(s)和(2)π*=arg max qπ(s,a)
39、其中,π*代表策略π的估计值函数;
40、vπ(s)、qπ(s,a)分别为步骤四和步骤五得到的期望总奖励;
41、arg max为取最大值函数。
42、一种电动汽车充放电管理系统,包括智能融合终端ttu、电动汽车充电桩和电动汽车充放电管理模块;
43、电动汽车充放电管理模块基于电动汽车充电桩与ttu之间的交互信息,以有功功率损耗最小为奖励函数构建深度强化学习模型,采用深度强化学习模型对电动汽车充放电过程进行学习,并同时考虑t时刻和t+1时刻的奖励,最终得到电动汽车最优的调控策略,根据最优的调控策略进行电动汽车充放电管理。
44、一种终端,包括处理器及存储介质;所述存储介质用于存储指令;
45、所述处理器用于根据所述指令进行操作以执行所述方法的步骤。
46、计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述方法的步骤。
47、本发明的有益效果在于,与现有技术相比:
48、本发明采用深度强化学习的方法,将电动汽车优化调度问题转换为考虑多种不确定因素下对电动汽车充放电状态的时序安排问题,通过深度强化学习在复杂不确定性的环境中寻找最优策略,可以再台区等拓扑信息和量测数据不全的情况下进行电动汽车的有序调控;且深度强化学习具备深度学习的感知能力和强化学习的决策能力,用神经网络来代替传统强化学习的q值表等内容,能够解决更高维度的问题,适合于电网此类复杂且数据较多的环境;本发明同时考虑了t时刻和t+1时刻的期望总价值(期望总奖励),避免了局部最优问题的出现;
49、本发明以智能融合终端ttu作为中心评判单元,将电动汽车充电桩作为局部决策单元,依托于台区现有的ttu装置,无需额外进行配电网的设备改造,提高了台区现有设备的利用率,避免了额外的经济投入。
- 还没有人留言评论。精彩留言会获得点赞!