煤粉锅炉瞬时给粉量的拟合样本选取及计量方法与流程
本发明属于能源生产领域,具体涉及一种煤粉锅炉瞬时给粉量的拟合样本选取及计量方法。
背景技术:
在能源生产领域,大量的热力发电厂、工业蒸汽生产企业、民用供暖企业都在使用煤粉锅炉进行蒸汽/热水的生产。煤粉锅炉通过燃烧煤粉产生热量将常温水加热为蒸汽或高温水。在这类生产过程中,主要的成本来源于煤粉的消耗,并且使用单位蒸汽的煤粉消耗来评估生产的效率,直接的评估指标是锅炉在一个时间周期内的燃效,锅炉燃效通过以下公式进行计算:
其中:蒸汽焓值=蒸汽生产(kg)*蒸汽热晗值(kj/kg)
给水焓值=给水重量(kg)*水热晗值(kj/kg)
即单位时间内消耗煤粉的热量转化为水汽热量的比例。
计算锅炉燃效有两种用途:
·管理报表:按天、月等统计锅炉的平均燃效,生成报表,用作管理目的。针对这种使用场景需要对煤粉、水、蒸汽按天、月等较大时间区间里的累计量进行计量。
·锅炉燃效优化:对锅炉的燃效按照分钟级进行计算,通过优化锅炉控制来提高锅炉燃效。针对这种使用场景需要对煤粉、水、蒸汽按分钟等较短时间区间里的累计量进行计量。
针对水、蒸汽的计量,可以通过相应的流量计精确计量累计量和瞬时量,可以比较准确的获得分钟等较小区间内的使用量和天、月等较大区间内的使用量。
针对煤粉的计量,通常有两种方式:通过煤粉仓的仓重差值计量累计煤粉消耗量和通过计量仪器计量瞬时量。
1)仓重计量
煤粉仓是容纳煤粉的密闭容器,通过计量煤粉仓的仓重变化量可以计量一段时间内煤粉的消耗量。然而由于煤粉仓的仓重计量仪器是针对百吨级粉仓的重量,其测量精度在几百千克左右,当仓重变化较小时误差极大;而且由于煤粉仓中的煤粉形状不同也会进一步增加测量的误差。所以,煤粉仓的重量差仅能用于测量相对较长时间内(至少小时级)的煤粉重量变化,无法对分钟级的粉仓重量差进行相对准确的计量。
2)计量仪器计量
煤粉是通过空气吹入锅炉,所以进入锅炉的煤粉是一种固气二相流,目前工业界普遍使用的计量方法是直接计量法,即对气煤二相流的流速和密度分别进行计量,从而计算出煤粉的瞬时流量,再对瞬时流量进行累加得出一个时间周期内的煤粉量。
对于流速进行测量的仪器主要有毕托管、热线风速计、激光多普勒测速计等。对于密度的测量方法相对较多,有微波法、光电检测法、超声波法等直接测量法;也有温度法、速度-压差法、能量法等间接计量法[2]。
使用这种计量方法存在以下不足:
·安装/改造/维护成本高、施工难度大:对流速和密度进行分别计量,每种计量仪器的安装和维护工艺相当复杂,不仅施工难度大,而且初次安装和后续维护的成本也极高。
·误差大:使用单独的仪器对流速和密度的瞬时量进行分别计量,而且有些计量方法还是通过间接计量计算的方式;再对瞬时量在一小段时间内进行积分计算累积量。每种计量仪器都存在测量误差,而且随着时间的增加测量值的偏离度会越来越大,再加上使用多层间接计算的方式获得最终结果,会导致误差的累积放大,导致最终结果误差大。
技术实现要素:
针对现有技术中存在的不足,本发明的目的在于,提供一种煤粉锅炉瞬时给粉量的计量方法,解决现有技术无法准确估计煤粉锅炉瞬时给粉量的技术问题。
为了解决上述技术问题,本申请采用如下技术方案予以实现:
一种煤粉锅炉瞬时给粉量的拟合样本选取方法,包括以下步骤:
步骤1,获取煤粉锅炉运行过程中的煤粉仓重量数据和m个给粉机的给粉频率数据,m为自然数;
步骤2,从所述煤粉仓重量数据和给粉机的给粉频率数据中截取多个样本序列,每个所述样本序列为v(h1,...,hm,δt),其中h1,...,hm分别表示m个给粉机的频率,δt表示每个样本序列起始到结束时煤粉仓的重量差值;
所述截取的每个样本序列符合以下条件:
(1)每个样本序列中煤粉仓重量处于连续下降阶段;
(2)每个样本序列中m个给粉机的给粉频率均保持恒定;
(3)每个样本序列的采样时间大于等于30分钟。
本发明还提供了一种煤粉锅炉瞬时给粉量的计量方法,包括:
步骤1,根据权利要求1所述的拟合样本选取方法选取多个样本序列,将所述多个样本序列划分为两个完全不相交的样本集合,即得到训练样本集sl1和测试样本集sl2,其中l1为训练样本集sl1的样本序列数量,l2为测试样本集sl2的样本序列数量;
步骤2,利用n个回归算法分别对训练样本集sl1进行训练,得到n个初级学习器f1......fn;
步骤3,将测试样本集sl2输入n个初级学习器f1......fn中,得到测试样本集sl2的预测结果v1...vx...vl2,其中vx=(δtxf1...δtxfy...δtxfn),δtxfy表示初级学习器fy对测试样本集sl2中第x个测试样本的预测结果,x=1.....l2,y=1.....n;
步骤4,将测试样本集sl2的预测结果v1...vx...vl2作为输入量,将测试样本集sl2中每个样本序列的给粉量观测值作为输出量,训练高层学习器f,该学习器即为给粉机的给粉频率与煤粉锅炉出粉量的关系;
步骤5,将煤粉锅炉中每个给粉机的瞬时频率代入给粉机的给粉频率与煤粉锅炉出粉量的关系中,得到每个给粉机的瞬时给粉量;
步骤6,对每个给粉机的瞬时给粉量进行积分,获得任意微小时间段的给粉量。
本发明与现有技术相比,有益的技术效果是:
(1)本发明不需要加装任何新的计量设备,仅依靠粉仓自带的粉仓重量计量设备,没有额外的实施和维护成本。
(2)本发明仅依赖一种计量设备,而且对计量设备的精度要求不高,所以计量设备的测量精度误差对计量效果影响很小,通过数据试验可达到较高的准确度。
附图说明
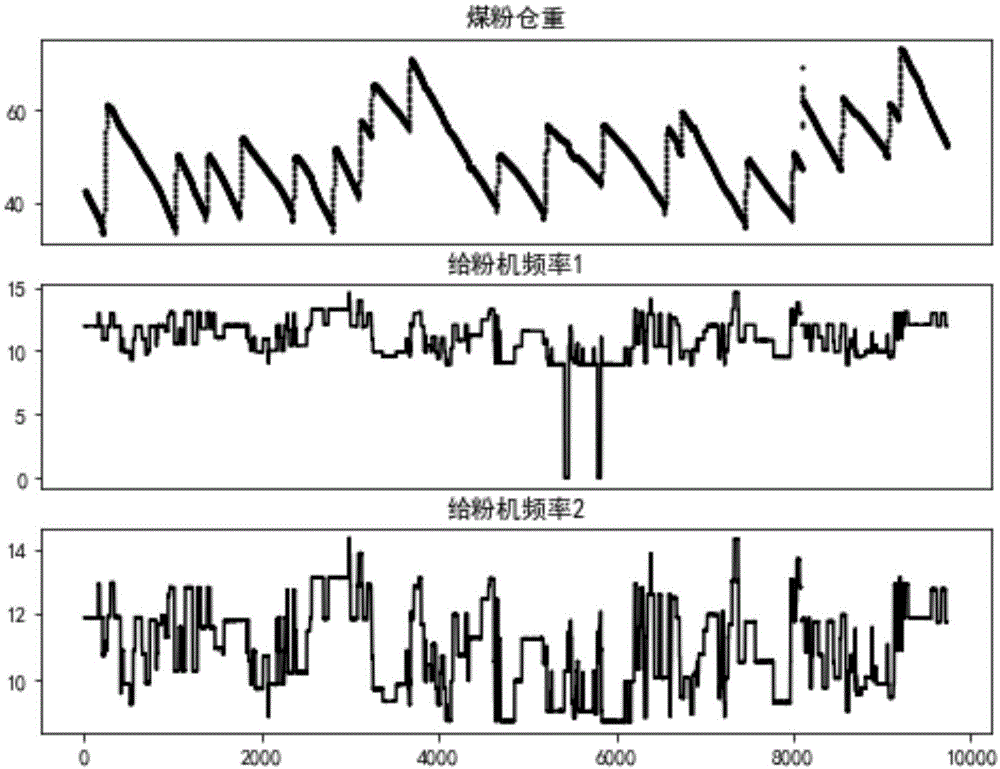
图1是给粉机频率与粉仓重量随时间变化趋势图;
图2是按平稳段截取的样本序列图。
以下结合附图和实施例对本发明的具体内容作进一步详细解释说明。
具体实施方式
以下给出本发明的具体实施例,需要说明的是本发明并不局限于以下具体实施例,凡在本申请技术方案基础上做的等同变换均落入本发明的保护范围。
实施例1:
本实施例给出一种煤粉锅炉瞬时给粉量的拟合样本选取方法,包括以下步骤:
步骤1,获取煤粉锅炉运行过程中的煤粉仓重量数据和m个给粉机的给粉频率数据,m为自然数;
本实施例所获取的煤粉锅炉运行过程中的煤粉仓重量数据和m个给粉机的给粉频率数据是在锅炉稳定运行时的历史数据,如图1为一个煤粉仓重量和两个给粉机频率的变化曲线图,其中煤粉仓重量的增加是给煤粉仓加粉的过程;
步骤2,从所述煤粉仓重量数据和给粉机的给粉频率数据中截取多个样本序列,每个所述样本序列为v(h1,...,hm,δt),其中h1,...,hm分别表示m个给粉机的频率,δt表示每个样本序列起始到结束时煤粉仓的重量差值;
截取所述多个样本序列的具体操作包括:
(1)每个样本序列中煤粉仓重量处于连续下降阶段;
(2)每个样本序列中m个给粉机的给粉频率均保持恒定;
(3)每个样本序列的采样时间大于等于30分钟;
如图2所示为按照上述截取样本序列的具体操作所截取的样本序列,这样选择的样本序列具有以下优点:
(1)煤粉仓的计量精度通常为0.5吨,在一个相对长的时间内,煤粉仓的仓重变化值相对较大,例如100吨,这种情况下煤粉仓的计量误差对仓重变化值的计量影响不大;
(2)所有给粉机频率处于恒定状态,即煤粉仓的下降段是一条直线,可以用仓重变化值除以时间周期获得煤粉仓重的下降率,并且使用该下降率表达当前给粉机频率下的给粉速率;
(3)从历史数据中获取大量训练样本进行模型训练,可充分消除单条样本的统计误差。
实施例2:
本实施例提供了一种煤粉锅炉瞬时给粉量的计量方法,包括:
步骤1,根据本发明所提供的拟合样本选取方法选取多个样本序列,将所述多个样本序列划分为两个完全不相交的样本集合,即得到训练样本集sl1和测试样本集sl2,其中l1为训练样本集sl1的样本序列数量,l2为测试样本集sl2的样本序列数量;
步骤2,利用n个回归算法分别对训练样本集sl1进行训练,得到n个初级学习器f1......fn;
本实施例中的回归算法可以采用线性回归算法、ridge回归算法或lasso回归算法中的任一种,具体参见下述参考文献。
步骤3,将测试样本集sl2输入n个初级学习器f1......fn中,得到测试样本集sl2的预测结果v1...vx...vl2,其中vx=(δtxf1...δtxfy...δtxfn),δtxfy表示初级学习器fy对测试样本集sl2中第x个测试样本的预测结果,x=1.....l2,y=1.....n;
步骤4,将测试样本集sl2的预测结果v1...vx...vl2作为输入量,将测试样本集sl2中每个样本序列的给粉量观测值作为输出量,训练高层学习器f,该学习器即为给粉机的给粉频率与煤粉锅炉出粉量的关系;
步骤5,将煤粉锅炉中每个给粉机的瞬时频率代入给粉机的给粉频率与煤粉锅炉出粉量的关系中,得到每个给粉机的瞬时给粉量;
步骤6,对每个给粉机的瞬时给粉量进行积分,获得任意微小时间段的给粉量。
如表1是一小段时间内的某煤粉仓给粉数据:
表1某煤粉仓给粉数据
其中:
·给粉机频率1~4表示该煤粉仓所有4个给粉机的频率开度;
·仓重是当前时刻煤粉仓称重的计量数据;
·仓重变化是当前一个时间点煤粉仓重量的变化值,正数表示粉仓重量的减少量,负数和零是由于仓重测量误差导致;
·模型预测是使用本发明进行数据模拟计算的计量值。
通过该数据可以从以下两个方面评价本发明所述方法的有效性:
1)使用起始时刻和末尾时刻仓重的变化量与每个时刻模型预测量的累计值进行比较,可获得模型在该时间段内的累计误差;
总误差模型预测=|仓重减少量–sum(所有模型预测值)|÷仓重减少量×100%
=|0.520152–0.516456|÷0.520152×100%
=0.7%
总误差仓重变化=|仓重减少量–sum(所有仓重变化值)|÷仓重减少量×100%
=|0.520152–0.446886|÷0.520152×100%
=14.1%
模型预测的总误差仅为仓重变化总误差的5%。
2)表1中除最后一行,其他时间内给粉机频率基本保持恒定,所以仓重的变化应该是均匀的,通过计算每个时间周期标准差可以评价模型方法计量的随机误差;
随机误差模型预测=标准差÷均值×100%
=0.00154÷0.032419×100%
=4.8%
随机误差仓重变化=标准差÷均值×100%
=0.02433÷0.030597×100%
=79.5%
模型预测的随机误差仅为仓重变化总误差的6%。
【参考文献】
[1].《统计学习方法》1.10回归问题,李航,清华大学出版社;
[2].《机器学习》第3章线性模型p53,周志华,清华大学出版社;
[3].《线性回归分析基础》,威廉·d.贝里(美国),格致出版社;
[4].岭回归分析及其应用,http://www.doc88.com/p-9803114479516.html
[5].机器学习中的范数规则化之(一)l0、l1与l2范数,https://blog.csdn.net/zouxy09/article/details/24971995
[6].岭回归和lasso,http://f.dataguru.cn/thread-598486-1-1.html
[7].正则化的线性回归——岭回归与lasso回归,https://www.cnblogs.com/belter/p/8536939.html
- 还没有人留言评论。精彩留言会获得点赞!