基于模糊处理的深度学习在液压装备故障诊断中的应用的制作方法
本发明涉及液压装备故障诊断技术领域,尤其涉及一种基于模糊处理的深度学习在液压装备故障诊断中的应用。
背景技术:
液压设备作为现代工业中的最主要传动方式之一,是大型机械设备的重要组成部分。现代液压设备多为结构复杂,精密度高的机、电、液一体化设备,设备具有机液耦合、时变性和非线性等特性,由于液压设备工作环境复杂,随机性强,因此,快速、准确的液压设备故障诊断技术可有效实现现代工业的高生产效率。随着人工智能技术的发展,研究人员不断致力于设备故障诊断技术的研究,文章[刘晶等.一种带有风险控制的维修决策方法[J].计算机集成制造系统,2010,16(10):2087-2093.]是基于关联规则提出一种带有风险控制的维修决策方案;文章[古莹奎等.基于主成分分析和支持向量机的滚动轴承故障特征融合分析[J].中国机械工程,2015,26(20):2778-2883.]提出一种基于PCA和SVM的滚动轴承故障特征融合分析;文章[耿朝阳,薛倩倩.神经网络的故障诊断方法研究[J].西安工业大学学报,2015,35(07):527-533.]提出BP神经网络在设备故障诊断中的应用;文章[杨琦,孙玉清.基于SVM的液压设备仿真模型的故障诊断[J].机电设备(技术篇),2015,07:14-17.]是基于SVM的液压设备仿真设备的故障诊断技术;文章[武朝,胡军华,黎申,彭云飞等.基于二级模糊综合评判的液压系统故障诊断方法[J].液压与气动,2013,(05):130-133.]介绍了基于二级模糊评判的液压系统故障诊断方法,提出了一种有效解决故障症状与故障原因模糊对应关系的方法,但其不适用于大规模数据处理。尽管这些方法都在不同方面取得了较好的效果,但随着数据量的不断增长和数据的复杂多样化变化,传统的浅层诊断模型无法满足设备故障预警精确度的需求,因此如何提高基于数据分析的液压设备故障预警准确率成为亟待解决的问题。
技术实现要素:
本发明提供一种基于模糊处理的深度学习在液压装备故障诊断中的应用,首先引入时间标签和模糊权重的方法对数据进行预处理;然后使用稀疏自编码完成样本数据的高层特征提取,并使用Softmax分类器对设备故障状态进行分类诊断来构建ICM模型;最后利用BP算法微调整个网络全局最优参数,实现故障特征的自适应提取和故障状况的智能诊断。
本发明所采取的技术方案是:
一种基于模糊处理的深度学习在液压装备故障诊断中的应用,包括下述步骤:
(1)引入时间标签和模糊权重对液压设备运行监测数据进行预处理,并将数据预处理后的故障数据分成训练数据集和测试数据集,并对测试数据集进行标签化处理,即对测试数据样本标注具体故障种类;含有时间标签设备数据在数据预处理过程中会根据时间标签使用对应的模糊权重函数进行数据预处理;
(2)将训练数据集作为稀疏自编码网络的输入向量进行无监督预训练,对样本数据进行特征提取,得到经自学习后的故障特征向量;
(3)将有标签数据和经自学习后得到的无标签数据作为Softmax分类器的输入向量训练Softmax分类器,得到完整的ICM模型;利用训练好的ICM模型可有效实现设备故障分类诊断;
(4)为优化ICM模型的分类准确性,利用BP算法对稀疏自编码在无监督预训练中的相关参数和Softmax分类器训练中的相关参数进行全局微调,不断更新相关参数,得到使损失函数值达到最小的最优参数;这样做的目的是有效避免了参数陷入局部最优的缺点。
(5)基于上述ICM模型实现故障特征的自适应提取和故障状况的智能诊断。设备故障特征的自适应提取,即利用稀疏自编码网络对设备故障进行自学习来得到用于分类的特征向量;
基于上述步骤ICM模型有效实现了设备故障特征的自适应提取,即利用稀疏自编码网络对设备故障进行自学习来得到用于分类的特征向量;同时也实现了设备故障的智能诊断,即ICM模型有效解决了浅层分类器在处理少样本数据是泛化性差的问题,解决了因设备故障症状与故障原因间存在模糊对应关系而导致的分类准确率偏低的问题,并且在一定程度上验证了ICM模型在处理大规模数据时具有一定的优势。
其中,步骤(1)中数据预处理包括下述步骤:
1)样本特征选取及归一化:使用企业液压设备运行监测数据建立设备监控数据集,从中选取液压设备带时间标签的运行状态数据(监测数据包含正常状态数据及故障状态数据);将液压设备分A、B两组,选取温度T、压力P、震动S、转速R四个属性作为特征变量来描述液压设备状态,加入时间TS(用以保证样本数据为有效时间内的数据),得到维度为8的特征向量V1={TA1,TB1,PA1,PB1,SA1,SB1,RA1,RB1},得到V2={TS,TA1,TB1,PA1,PB1,SA1,SB1,RA1,RB1};为防止因数据两极化引起的误差,将样本数据进行归一化处理,使样本值域为[0,1],以提高设备诊断的准确率;
a.将数据进行标准化处理:
X0为设备运行状态的原始数据,Xh为设备正常运行的理想值,Xn中n分别为TA1,TB1,PA1,PB1,SA1,SB1,RA1,RB1;
b.将标准化的数据样本按比例缩放,使其落在[0,1]区间;
c.模型的输出向量根据故障种类分为以下四种:0代表无故障;1代表故障1;2代表故障2;3代表故障3;
故障种类判定根据分类输出概率值判断,即最大概率值对应的故障种类为当前设备所处的运行状态,当该概率值超过给定阈值时,设备报警应立即停机检修,以免发生严重故障;
2)ZAC白化
模型选取的原始数据集有m个样本,每个样本的维数8,则ZCA白化的过程如下:
a.首先将原始数据集排成一个8×m的数值矩阵然后进行使每个属性均值为零的标准化处理,得到的矩阵记为G;
b.计算G对应的样本协方差矩阵Σ,求出相应的特征值,并按从大到小顺序分别记为γ1,γ2...,γ8,对应的特征向量分别记为u1,u2,...,u8,并记
U=u1,u2,...,u8];
c.左乘UT得到旋转矩阵:
将旋转矩阵属性值具有单位方差:
d.ZAC白化结果:
矩阵的每一列对应ZCA白化后的样本数据,将转置得到V′1为后续的数据处理做准备;
3)模糊处理
a.时间标签的处理
向量V2中的时间TS(单位:月)代表样本数据获取的时间与系统时间的距离,由于设备处于一直运行的状态(理想状态下),所以数据具有更新快,增长快的特点;采用随机方式选取近12个月内的样本数据,使数据的时间呈现不规律性,根据现实意义距离系统时间比较早的数据的使用价值要明显低于近期收集的数据,对不同日期的状态数据进行权重标记;
时间标签格式为“年-月-日”,TSn为处理数据时的系统当前时间,TSc为数据样本采集时间;
对时间的权重处理采取模糊数学理论中的模糊子集权重系数的确定方法,采取专家评语集的方式设定不同距离样本数据的权重:
b.确定隶属度函数:
V′1根据V2中的TS值得到每条数据在故障诊断中的权重,即得到V3=μ1V′1;根据模糊理论,因素集为V3,评判集为Y,权重矩阵K选取梯形分布的隶属函数:
其中x值V3中的特征向量,t为特征向量x的第t(t=1,2,…,m)个值;a、b的确定根据不同特征的属性来确定;这样便可以得到样本数据中的每个值的权重,从而改进一种故障原因对多种故障状态的模糊对应关系;
c.得到SAE输入向量
V1′经时间标签的处理后得到V3,V3经确定隶属度函数处理后得到SAE的输入向量V=μ(xt)KV3,记为V={TA,TB,PA,PB,SA,SB,RA,RB};
步骤(1)中标签化处理为:标注设备的具体故障状态,并分成两部分一部分用于训练ICM模型,另一部分用于验证ICM模型的性能。
步骤(2)中稀疏自动编码器的训练方法采用非监督贪婪逐层训练算法,包括下述步骤:
1)假设一个无类别标签的训练数据样本v,通过下述公式将v变换为激活后的y,v与y满足公式:
y=fθ(v)=s(WTv+b)
其中s是一个非线性函数,θ={W,b}为参数集合,y经反向编码将输入值v重构表示为z,y与z满足公式:
其中θ1={W1,b1}为参数集合,公式中参数W1、WT的关系为W1=WT,最后通过不断优化更新θ和得到最小化重构误差JAE,JAE定义为:
JAE=∑v∈VL(v,z):其中L为重构误差函数;
2)由于自动编码器无法满足复杂数据结构需要学习到复杂的非线性函数的需求,因此采用稀疏编码事先更好的特征学习。稀疏自编码是在自动编码器的基础上加入稀疏性限制达到使用最少的隐藏层单元数来表达多维输入特征的目的。
设置稀疏性参数为ρ(通常情况下将其设置为一个接近于0的较小数值,例如ρ=0.05),并加入稀疏性限制为实现这一限制需要在优化目标函数中加入一个额外的惩罚因子,惩罚那些和ρ有显著不同的情况,将隐藏层神经单元的平均活跃度控制在一个较小的范围内;惩罚因子采用相对熵的表达形式:
稀疏自编码网络的整体代价函数为:其中μ为惩罚系数,μ越大,惩罚力度越大,结果越稀疏;
反向传导残差计算公式:
所述步骤(3)中Softmax分类器的训练方法为:
1)给定输入训练样本集合L,采用假设函数的方法分析每个类j属于不同分类的概率值p=(y=j|x),于是定义假设函数hθ(x)形式如下:
其中:θ1,θ2,…,θk为要求取的模型参数;
2)定义代价函数:
3)在代价函数中加入权重衰减项使代价函数变为严格的凸函数,来惩罚权值过大的参数,有利于参数收敛到局部最优;加入权重衰减项后的代价函数为
通过最小化J(θ)得到最优参数值,得到的用于深度学习网络顶层的分类器,最终生成用于故障诊断的ICM模型。
液压系统的故障症状与故障原因之间是“模糊映射”的对应关系,即一种故障症状对应着多种故障原因,一种故障原因对应着多种故障症状,对于这种模糊现象,需要考虑相应的参数描述各种故障原因对故障症状的贡献。本发明提出一种模糊数学理论的隶属度函数解决这一现象。更进一步,深度学习是一种模拟人脑多层感知结构来认识数据模式的学习算法,近年来作为数据挖掘的一个新兴领域,在处理图像、文本、语言等非结构化数据等方面体现出了极为卓越的性能,但其在液压设备故障诊断的应用研究才刚刚起步,本发明根据液压设备的运行状态数据特点,应用深度学习算法构建了液压设备故障诊断模型-皇冠模型(Imperial Crown Model,简称ICM),并经实验证明,该模型具有较好的自学习更新能力和层次知识学习能力,可有效实现液压设备故障智能分类诊断。
一、本发明方法的理论依据:
1、ZCA白化:为了减少原始数据的冗余性,需要对数据进行白化处理,使得所有属性的方差相同,不同属性之间不相关或具有较低的相关性。常用的一种白化方法是ZCA白化,它可以使得白化后的数据尽可能接近原始数据,并且保持与原始数据相同的维数。
2、模糊数学理论能够处理故障诊断中的不确定信息和不完整信息,能够克服由于过程本身的不确定性、不精确性所带来的困难,其利用集合论中的隶属度函数和模糊关系矩阵的概念来解决故障症状与故障原因之间的不确定关系。因素集U,评判集V,权数矩阵A,评判矩阵R是组成模糊综合评判数学模型的四要素,模糊综合评判的逻辑步骤见图1。
3、自动编码器是深度学习的一种具有快速学习能力的方法,其本质是运用人工神经网络(ANN)的层次结构特点,利用经过逐层贪心无监督预训练和系统性参数优化的从高维复杂输入数据中提取分层特征,处理大型高维数据表现出较高的效率。
由于自动编码器无法满足复杂数据结构需要学习到复杂的非线性函数的需求,因此采用稀疏编码进行更好的特征学习,即自动编码器的基础上加入稀疏性限制达到使用最少的隐藏层单元数来表达多维输入特征的目的。
稀疏自动编码器(SpareseAuto encoder)的训练方法采用Hinton基于深信度网络(Deep BeliefNets,简称DBN)提出的非监督贪婪逐层训练算法是目前训练深层网络比较先进的一种方法。将各个单层单独训练得到的权重系数用来初始化最终的深度网络权重系数。
4、Softmax分类器是logistic分类回归在多分类问题上的拓展,给定输入训练样本集合L,采用假设函数的方法分析每个类j属于不同分类的概率值p=(y=j|x)。
二、ICM模型设计:
现实生活中假设液压设备处在一直运行的状态,因此,设备的运行数据不断增长,这就要求模型具有较强的数据更新自学习能力,本发明选用的挖掘技术对设备的运行数据只作形式归纳。采取半监督学习模型,首先将数据进行预处理,再使用稀疏自编码网络从大量的无标签设备运行数据中发现其存在的共有特性用以表征样本,然后使用有标签数据和无标签数据样本来训练分类器,利用反向传播不断更新各层参数得到满足全局最优的最优参数值,最终形成一个可以对液压设备故障种类及故障概率进行准确诊断的分类模型ICM。
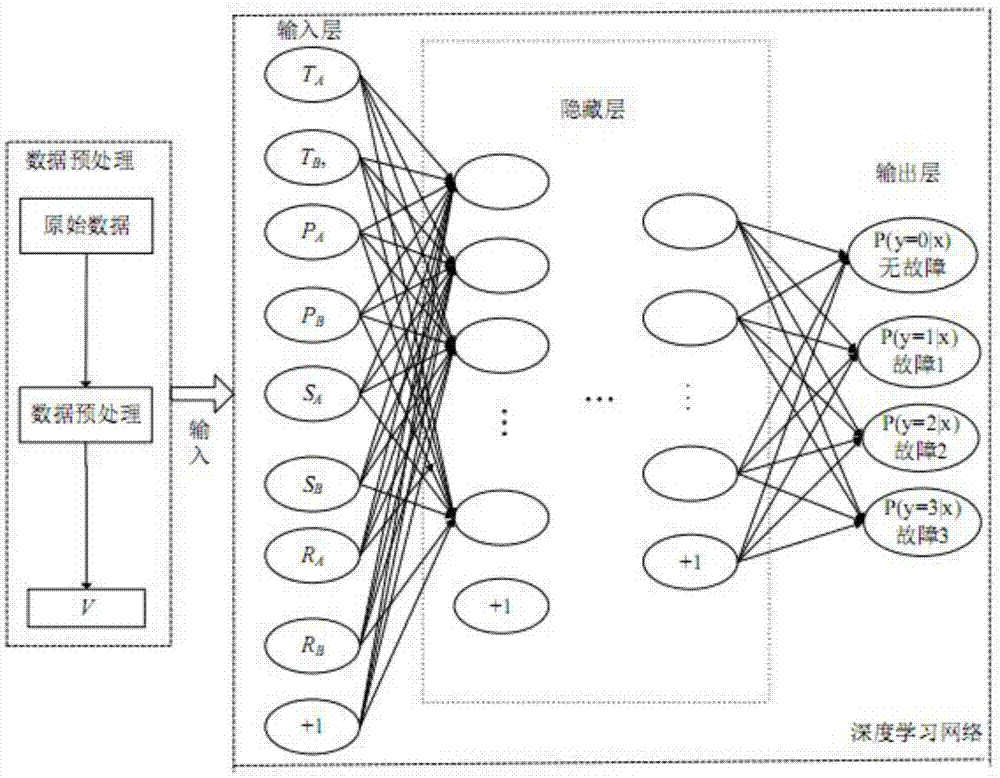
1、ICM模型结构
ICM模型由数据预处理过程和深度学习网络两部分组成,首先将数据预处理,将处理后的向量V作为输入,即输入神经元数为8,输出向量为Y,即故障种类及其概率值。深度学习网络底层采用稀疏自编码网络,但由于其只对样本特征向量进行深层特征挖掘得到隐层的权重参数,因此需要在模型的顶层添加Softmax分类器,ICM结构图见图2。
2、具体算法实现
ICM算法具体实现如图3所示,实现步骤为:
(1)预处理收集到的液压设备运行数据并分成训练数据集和测试数据集。
(2)将用于测试数据集进行标签化处理,即标注设备的具体故障状态,并分成两部分一部分用于训练ICM模型,另一部分用于验证ICM模型的性能。
(3)由于液压设备数据具有大容量、多样性和高速率的特性,因此模型利用反复实验的方法确定稀疏自编码网络隐含层的层数及各层神经元数,以达到更精确的故障分类预警。
(4)将训练数据集作为稀疏自编码网络的输入向量进行无监督预训练。
(5)将有标签数据和无标签数据作为Softmax分类器的输入向量训练分类器。
(6)利用反向传播算法对深度学习网络参数进行微调,使参数达到全局最优。
采用上述技术方案所产生的有益效果在于:
本发明首先引入时间标签和模糊权重的方法对数据进行预处理;然后使用稀疏自编码完成样本数据的高层特征提取,并使用Softmax分类器对设备故障状态进行分类诊断来构建ICM模型;最后利用BP算法微调整个网络全局最优参数,实现故障特征的自适应提取和故障状况的智能诊断。
通过仿真分析,ICM模型分类准确率达83%,明显高于传统的浅层分类器,具有较好的精确判断力、自学习更新能力和层次知识学习能力,可有效实现对液压设备故障的智能精确分类诊断。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1是模糊综合评判的逻辑步骤示意图;
图2是本发明ICM模型结构图;
图3是本发明ICM算法具体实现流程示意图;
图4是系统仿真操作流程示意图;
图5、图6分别为隐藏层层数与分类精度关系图和隐藏层单元个数与分类精度关系图;
图7、图8分别为误报率对比图和漏报率对比图,X代表数据未经过预处理过程,直接使用深度网络模型的分类结果;Y代表使用ICM模型的分类结果;
图9为模型预测准确率统计图。
具体实施方式
一种基于模糊处理的深度学习在液压装备故障诊断中的应用,包括下述步骤:
(1)引入时间标签和模糊权重对液压设备运行监测数据进行预处理,并分成训练数据集和测试数据集,并对测试数据集进行标签化处理:标注设备的具体故障状态,并分成两部分一部分用于训练ICM模型,另一部分用于验证ICM模型的性能。
数据预处理包括下述步骤:
1)样本特征选取及归一化:使用某钢铁企业液压设备运行监测数据建立设备监控数据集,从中选取液压设备带时间标签的运行状态数据(监测数据包含正常状态数据及故障状态数据)。液压设备分A、B两组,选取温度T、压力P、震动S、转速R四个属性作为特征变量来描述液压设备状态,加入时间TS(用以保证样本数据为有效时间内的数据),得到维度为8的特征向量V1={TA1,TB1,PA1,PB1,SA1,SB1,RA1,RB1},得到V2={TS,TA1,TB1,PA1,PB1,SA1,SB1,RA1,RB1}。为防止因数据两极化引起的误差,将样本数据进行归一化处理,使样本值域为[0,1],以提高设备诊断的准确率。
a.将数据进行标准化处理:
X0为设备运行状态的原始数据,Xh为设备正常运行的理想值,Xn中n分别为TA1,TB1,PA1,PB1,SA1,SB1,RA1,RB1;
b.将标准化的数据样本按比例缩放,使其落在[0,1]区间;
c.模型的输出向量根据故障种类分为以下四种:0代表无故障;1代表故障1;2代表故障2;3代表故障3;
故障种类判定根据分类输出概率值判断,即最大概率值对应的故障种类为当前设备所处的运行状态,当该概率值超过给定阈值时,设备报警应立即停机检修,以免发生严重故障;
2)ZAC白化
模型选取的原始数据集有m个样本,每个样本的维数8,则ZCA白化的过程如下:
a.首先将原始数据集排成一个8×m的数值矩阵然后进行使每个属性均值为零的标准化处理,得到的矩阵记为G;
b.计算G对应的样本协方差矩阵Σ,求出相应的特征值,并按从大到小顺序分别记为γ1,γ2...,γ8,对应的特征向量分别记为u1,u2,...,u8,并记U=[u1,u2,...,u8];
c.左乘UT得到旋转矩阵:
将旋转矩阵属性值具有单位方差:
d.ZAC白化结果:
矩阵的每一列对应ZCA白化后的样本数据,将转置得到V′1为后续的数据处理做准备;
3)模糊处理
a.时间标签的处理
向量V2中的时间TS(单位:月)代表样本数据获取的时间与系统时间的距离,由于设备处于一直运行的状态(理想状态下),所以数据具有更新快,增长快的特点;采用随机方式选取近12个月内的样本数据,使数据的时间呈现不规律性,根据现实意义距离系统时间比较早的数据的使用价值要明显低于近期收集的数据,对不同日期的状态数据进行权重标记;
时间标签格式为“年-月-日”,TSn为处理数据时的系统当前时间,TSc为数据样本采集时间;
对时间的权重处理采取模糊数学理论中的模糊子集权重系数的确定方法,采取专家评语集的方式设定不同距离样本数据的权重:
b.确定隶属度函数:
V′1根据V2中的TS值得到每条数据在故障诊断中的权重,即得到V3=μ1V′1;根据模糊理论,因素集为V3,评判集为Y,权重矩阵K选取梯形分布的隶属函数:
其中x值V3中的特征向量,t为特征向量x的第t(t=1,2,…,m)个值;a、b的确定根据不同特征的属性来确定;这样便可以得到样本数据中的每个值的权重,从而改进一种故障原因对多种故障状态的模糊对应关系;
c.得到SAE输入向量
V1′经时间标签的处理后得到V3,V3经确定隶属度函数处理后得到SAE的输入向量V=μ(xt)KV3,记为V={TA,TB,PA,PB,SA,SB,RA,RB};
(2)将训练数据集作为稀疏自编码网络的输入向量进行无监督预训练;稀疏自动编码器的训练方法采用非监督贪婪逐层训练算法,包括下述步骤:
1)假设一个无类别标签的训练数据样本v,通过下述公式将v变换为激活后的y,v与y满足公式:
y=fθ(v)=s(WTv+b)
其中s是一个非线性函数,θ={W,b}为参数集合,y经反向编码将输入值v重构表示为z,y与z满足公式:
其中θ1={W1,b1}为参数集合,公式中参数W1、WT的关系为W1=WT,最后通过不断优化更新θ和得到最小化重构误差JAE,JAE定义为:
JAE=∑v∈VL(v,z):其中L为重构误差函数;
2)由于自动编码器无法满足复杂数据结构需要学习到复杂的非线性函数的需求,因此采用稀疏编码事先更好的特征学习。稀疏自编码是在自动编码器的基础上加入稀疏性限制达到使用最少的隐藏层单元数来表达多维输入特征的目的。
设置稀疏性参数为ρ(通常情况下将其设置为一个接近于0的较小数值,例如ρ=0.05),并加入稀疏性限制为实现这一限制需要在优化目标函数中加入一个额外的惩罚因子,惩罚那些和ρ有显著不同的情况,将隐藏层神经单元的平均活跃度控制在一个较小的范围内;惩罚因子采用相对熵的表达形式:
稀疏自编码网络的整体代价函数为:其中μ为惩罚系数,μ越大,惩罚力度越大,结果越稀疏;
反向传导残差计算公式:
(3)将有标签数据和无标签数据作为Softmax分类器的输入向量训练Softmax分类器,得到ICM模型;Softmax分类器的训练方法为:
1)给定输入训练样本集合L,采用假设函数的方法分析每个类j属于不同分类的概率值p=(y=j|x),于是定义假设函数hθ(x)形式如下:
其中:θ1,θ2,…,θk为要求取的模型参数;
2)定义代价函数:
3)在代价函数中加入权重衰减项使代价函数变为严格的凸函数,来惩罚权值过大的参数,有利于参数收敛到局部最优;加入权重衰减项后的代价函数为
通过最小化J(θ)得到最优参数值,得到的用于深度学习网络顶层的分类器,最终生成用于故障诊断的ICM模型。
(4)利用BP算法对深度学习网络参数进行微调,使参数达到全局最优;
(5)故障特征的自适应提取和故障状况的智能诊断。
ICM模型的仿真和验证:
1、仿真数据规模及仿真流程
模型的仿真和验证基于某钢厂的液压设备运行数据进行的,共包含5000组数据,每组含有20条样本,依据所构建的故障诊断模型,需要将预处理后数据样本整理为两类学习集,一个是特征学习集用于训练稀疏自编码网络得到变换核函数、损失函数及其偏导数,另一个是分类学习集用于训练Softmax分类器参数。1)特征学习集,为保证普适性采用随机抽取的方式从总体样本中选取3000组样本数据集;2)分类学习集,选取样本总数为1000组,并为每个特征向量设置类别标签,类别标签与输出向量一致。随机选取600组数据用于训练Softmax分类器,其余400组样本数据用以验证模型的分类性能。具体仿真流程如图所示4。
仿真工作在Windows 764位系统Intel-I3CPU计算机上运行,编码实现在Ri386平台下完成。
2、分类性能评价指标
根据《分类性能评价指标》(王成,刘亚峰,王新成,闫桂荣等,电子设计工程,2011,19(08):13-15,21.)采用准确率(Presicion,P)和召回率(Recall,R)进行评估:
P=正确分到该类的数目实际分到该类的数目
R=正确分到该类的数目实际应分到该类的数目
利用误报率(False positive rate,FPR)和漏报率(False negative rate,FNR)两个评价标准来进行判断,误报率是指设备本没有故障却被错误的诊断为故障状态,漏报率是指设备发生故障时未被诊断出来。
FPR=错误分到该类的数目/实际分到该类的数目
FNR=未分到该类的数目/实际应分到该类的数目
3、结果分析
1)稀疏自编码网络隐藏层层数及个隐藏层单元数对分类性能的影响
在输入样本数为500的相同条件下,分别测试隐藏层层数从1到10的分类精度,如图5所示,当隐藏层层数从1层增加到3层时精确度逐渐增加,但是在3层以后精确度不再变化,因此实验采取含有3个隐藏层的稀疏自编码网络。
当训练数据集为1200组数据时,设置迭代次数为100,隐层层数为3,稀疏性参数值为0.05(一般设置为接近于0的较小数值),图6所示为第一隐层单元数变化对分类性能的影响,三个隐藏层单元数按照3:2:2的比例增加,因此根据图6可以推测出第2、3隐层单元数目变化引起的分类精度的变化。因此确定隐藏层单元数分别为6、4、4。
2)ICM模型与其它浅层分类器性能比较
仿真工作首先验证ICM模型在不同样本数下的性能变化趋势。为更好地了解ICM模型分类性能,将未进行特征学习的样本数据经SVM(支持向量机)以及Softmax分类器进行分类预测并验证其分类精度。将3组具有不同规模的学习集采用3种分类模型分类后得到精度和时间对比如表1所示。
表1 不同数据规模各算法预测精度及耗时对比
从表2中可以得出随着数据规模的不断增长,ICM模型表现出较高的准确率,且相对于其它两种浅层学习算法耗时较短,凸显了ICM模型对液压设备运行数据有较强的增量自学习能力,对于大量、持续增长和多变的数据特点,ICM模型有明显的分类诊断优势。
3)模糊信息处理能力
为验证ICM模型对模糊信息的处理能力,随机选取4000组样本数据分别使用两个分类模型进行分类诊断,即直接使用深度学习网络的分类结果与使用ICM模型的分类结果对比,其误判率对比图为图7,漏报率对比图为图8:
从图7和图8比较结果看,ICM模型分类结果的误判率和漏报率明显低于未经过预处理直接使用深度学习模型的分类结果,说明对数据进行模糊预处理可以明显提高模型对模糊信息的识别能力。
4)性能优化
表2 分类预测精确度变化表
ICM未优化之前只有66.98%的精确度,优化后其精确度提高了近16%,从表2中我们可以发现随着迭代次数的增加分类的准确度不断增加,证明了微调对提高ICM模型分类精确度是有效性的。
5)泛化性
泛化性也是考量模型性能的重要方面。使用新数据集对ICM模型进行测试,将数据集从0增长到50组数据,每组容量为20条,验证不同隐藏层数对不同数据规模的样本的处理能力。将数据集分别在含有不同三个隐层的稀疏自编码网络上进行分类诊断,数据的分类精度如图9所示。
从实验结果看,具有3个隐藏层稀疏自编码网络对处理少量样本时的精度明显高于仅有1个隐藏层的自编码网络,且随着样本数量的增长虽然三组实验结果精度均呈上升趋势但具有3个隐藏层的稀疏自编码网络准确率增长趋势明显高于其它两组实验。因此可以得到适当增加稀疏自编码网络的层数可以提高模型的泛化性能。
4、结论
本发明结合工业大数据特征和深度学习算法优势构建ICM模型,引入模糊理论进行数据预处理过程,并根据工业大数据的特性采取反复实验的方法确定稀疏自编码网络的隐藏层层数及各层单元数,有效提高了模型的分类准确度。本发明的模型经稀疏自编码网络进行特征提取,顶层使用Softmax分类器进行分类,实现多分类问题,并经仿真分析,验证了ICM模型在设备故障诊断预警方面解决了现有浅层学习方法存在的问题:(1)针对故障特征与故障类型的模糊对应关系,有效降低了错报率和误报率;(2)针对工业数据的多样性,该模型具有较好的泛化性,改善了浅层学习对少量数据认知能力差的问题;(3)针对工业数据迅速增长的特点,该模型具有较强的增量学习能力。
- 还没有人留言评论。精彩留言会获得点赞!