用于对已加工材料进行量化检测的装置和方法与流程
本发明总体上涉及用于测量诸如油之类的已加工材料的质量的系统和方法。
背景技术:
诸如油或葡萄酒之类的已加工材料的质量可能随时间或在使用过程中发生变化。例如,如果在适当的条件下老化,葡萄酒的质量会提高。暴露于空气会损害葡萄酒的质量;暴露于热会破坏诸如烹饪油之类的油。此外,经加工材料的质量可以取决于用作原材料的果实或植物的种类、原材料的原产地区或国家以及许多其他因素。
质量还可以受到不道德行为或欺诈行为的影响,如使用同一类型但是质量较差的材料对已加工材料进行掺杂、向声称天然的产品中添加人工材料如糖或水、或者添加相关的但是价格较便宜的材料。最后一种情况的示例是将橘汁添加到橙汁中,后者较为昂贵。
在烹饪油的情况下,在被加热时,油氢化,增加形成油的碳链的碳原子之间的双键的数目。它们还可以分解,形成较短的链以及形成自由基。氢化的一个效果是使油的凝固温度升高,使得油在室温下变成固体或半固体脂肪。更重要的是,氢化产物中的一些氢化产物和降解产物中的一些降解产物可能是致癌的。
一批油保持使用的时间越长,油中的降解产物的分数越大,并且油会包含相当大比例的致癌物质的可能性就越大。
因此,油的重复使用,尤其是用于高温下烹饪的油的重复使用随着时间的推移对厨师的健康而言会变得危险,并且在油的重复使用很普遍的一些国家中,正在对于油中的降解产物,尤其是致癌物的允许水平设定标准。
然而,降解产物的检测可以是缓慢而费时的。然而,C-C单键的NMR频率显著地不同于C=C双键的核磁共振(NMR)频率,使得NMR能够用于区分高饱和油和低饱和氢化油。
因此,长期需要提供用于使用手持成像设备来确定油的样本中的氧化量的设备和方法。
技术实现要素:
本发明的目的是公开用于使用NMR来确定诸如油之类的已加工材料中的氧化量的系统。
附图说明
为了更好地理解本发明及其在实践中的实现,现在仅通过非限制性示例通过参考附图来描述多个实施方式,其中:
图1示意性地示出了可由于烹饪油的氢化而形成的致癌自由基;
图2至图4示意性地示出了橄榄油的组分的成分;
图5描绘了油的基于NMR分析的方法;
图6示意性地示出了确定油或其他植物提取物的来源的方法;
图7A至图7C示出了油的降解对NMR谱的影响;以及
图8A至图8C示意性地示出了本发明的系统。
具体实施方式
下面的描述与本发明的所有章节一起提供,以使本领域的任何技术人员能够使用所述发明,并提出由实施本发明的发明人构想的最佳方式。然而,对本领域的技术人员而言,各种变型仍将显而易见,这是由于本发明的一般原理已经具体地被限定成提供用于使用手持成像设备来确定油的样本中的氧化量的装置和方法。
术语“磁共振成像设备”和“MRD”在本发明中指代使用磁共振以便测量物质的具体属性的设备。
术语“非侵入性的”在本发明中将所公开的发明本身的操作的描述称为不影响正要测量的所述物质并且不中断涉及所述物质的一般工业过程。
术语“已知出处”在本发明中指代——对于非限制性示例:材料的源是已知的物种,材料的源是已知的亚种或种类,原材料的原产地区是已知 的,原材料的原产国是已知的,在加工时原材料的年龄是已知的,在加工前对原材料的加工是已知的(例如,加工前的储存条件),将原材料加工成成品的加工方法是已知的,以及在加工后对已加工材料的加工方法是已知的(例如,烹饪油的加热的持续时间以及其保持的温度)以及以上的任意组合。
术语“大约”在下文中指代值左右25%的范围。
根据本发明的优选实施方式,手持成像设备(HHID)包括磁共振成像设备。MRD包括:核磁共振成像(MRI)谱计,该MRI谱计用于使样本在所生成的磁场内经受射频(RF)信号的照射,测量由所述样本再次发射的RF信号以及产生所述样本的MRI;用于控制所述MRI谱计的RF波生成和检测功能的计算机处理器;用于存储用于所述计算机处理器的机器指令以及用于存储与所述RF信号的测量有关的信息的计算机可读介质(CRM);用于所述MRD与计算机通信网络之间的数字通信的数字电子连接端口。
优选的HHID包括MRD,然而,HHID能够包括选自下项的成像设备:红外线(IR)设备、MRD、傅里叶变换红外线(FTIR)设备、相机、至少一个光检测器以及以上的任意组合。
NMR能够在相对较简单的样本制备的情况下非常快速地提供对样本的生物分子组成的分析。NMR是用于包含NMR活性核的所有分子的通用检测器。对于所有带有质子的分子,所有质子信号的强度与代谢物的摩尔浓度绝对成正比。通过使用适当的内标物,能够容易地计算代谢物的真实浓度。因为NMR谱法是基于化合物的物理特性的,所以其具有非常高的重现性。
能够通过统计方法来进一步分析从分析方法获得的数据,以便从数据提取所有可能的信息。待通过统计方法进行进一步分析的数据的准确性和正确性不可避免地依赖于原始分析数据集的稳健性。NMR具有非常高的可靠性,因为与基于色谱法的技术中的保留时间不同,只要在相同的条件(所施加的场强度、溶剂、pH值和温度)下测量,除个别例外以外,NMR谱中每个信号的化学偏移、耦合常数和积分不会改变。虽然NMR的内部灵敏度较低,但是数据的稳健性和覆盖广范围的代谢物的能力已经使得NMR能够成为优选的总体指纹图谱工具。除了数据稳健性的优势以外,NMR在代谢物的结构分析方面的能力也是任何其他方法无法比拟的。NMR在天然产物化学领域作为用于结构分析的工具具有很长的历史。通 过使用适当的数据库,其能够生成能够几乎永久保存的数据。
如下文所描述的,本发明的设备能够具体用于:油——具体地食用油、果汁、药用植物、中药的成分、其他天然药物的成分、植物提取物、草药、香料、咖啡、茶、橡胶、商业化生产的食品以及以上的任意组合。
食用油,具体地橄榄油,以及在食用油被用作烹饪油的情况下的食用油中的降解将用作示意性示例,但是这个示例性的使用不限制本发明的范围。
由于烹饪的加热,在烹饪中使用的油随时间降解和氢化。降解和氢化二者都能够产生通常与由于氢化而产生的双键(图1)相关联的致癌降解产物和致癌自由基。因此,油的重复使用,尤其是延长的重复使用,会成为对于厨师的健康危害。
世界上许多地方的一种共同的烹饪油是橄榄油。橄榄油由甘油三酯(大于98%)和构成油的不可皂化部分的次要组分(约1%到2%)如角鲨烯、α-生育酚、植物甾醇、酚类化合物、类胡萝卜素、以及脂肪族和萜烯醇组成。表1示出了典型的橄榄油的组成,同时图2至图4示意性地示出了橄榄油的主要组分的化学几何结构。
表2:典型的橄榄油的组成
其他常见的烹饪油包括:花生油、核桃油、菜子油、杏仁油、鳄梨油、 黄油、椰子油、玉米油、棉籽油、亚麻籽油、酥油、葡萄籽油、榛子油、大麻油、猪油、澳洲坚果油、人造黄油、芥子油、橄榄果渣油、棕榈油、南瓜籽油、米糠油、红花油、芝麻油、大豆油、葵花籽油、牛脂、茶籽油、植物起酥油以及以上的任意组合。
NMR谱可以是1H、13C和/或31P-NMR、或者2D-NMR。在优选的实施方式中,通过1H-NMR获得谱。
图5中示出了用于确定诸如烹饪油之类的已加工材料中的降解产物的量的通用技术。如果要测量1H、13C和/或31P-NMR的谱,则样本制备(210)包括在标准样本支持器中提供适当体积的样本,并且使样本达到预定温度。在一些实施方式中,将样本的pH值调节成预定值。
如果要测量2D-NMR谱,则如现有技术中已知的,在如上文所描述的将样本放入样本支持器中、平衡至温度以及调节pH值之前、过程中或者之后,使用适当的技术对样本进行氚化。优选地,样本制备是自动完成的。在制备(210)完成后,测量NMR谱,并且在必要的情况下对NMR谱进行数字化并且分析以确定——对于非限制性示例——峰位置、峰高度和峰面积(220)。下一个步骤是对已分析的谱执行多变量数据分析(230),随后,在需要的情况下,对数据执行2D NMR分析(240)。
常规的高分辨率1H和13C NMR能够用于分析油料籽实中的脂肪酸含量,其典型的总采集时间以数分钟计。也可以使用基于1H横向弛豫时间(T2)的低分辨率NMR,其总采集时间是若干秒。
可以选择已加工材料的表型特征,例如但不限于:原产地区、原产国、所述已加工材料的来源、无掺杂、颜色、氢化、IR谱、NMR谱、FTIR谱、至少一个峰的宽度、至少一个峰的高度、至少一个峰的面积、至少一个峰的波长、峰的数目、至少一个峰的波长位移、基线高度以及以上的任意组合。如下文所描述的,在已加工材料的所选择的一种或更多种表型特征PC与已知出处的已加工材料的相同的一种或更多种表型特征PCKP之间可以做出比较。
在一些实施方式中,分析是通过主成分分析(PCA)进行的。在一些实施方式中使用主成分回归(PCR)和偏最小二乘(PLS)分析。随后可以进行以下中的至少一个:单变量分析(ANOVA,费雪指数和箱须图)和多变量方法(线性判别分析(LDA)和偏最小二乘判别分析(PLS-DA))。能够使用数据定标,包括自动定标和Pareto定标。
在期望获得油的原产地区或类型的实施方式中,可以使用监督模式识别方法来构建能够区分不同类型的油和/或来自不同地区的油的分类模型。在这样的实施方式中,可以在受控条件下通过从实验室确定的可识别差异来对来自已知油/地区的样本进行测试。
在执行定性分析的情况下(250),对结果进行检查以查看已降解材料的分数是否低于预定极限值(270),从而确定油是否可用。如果降解材料的分数在预定极限值以上(280),则油已经变得不可用并且必须被丢弃。如果降解材料的分数在预定极限值以下(290),则油仍然是可用的(290)。
在执行定量分析的情况下(250),可以对结果进行进一步分析(260)以确定(对于非限定性示例)降解产物的性质、油的来源以及以上的任意组合,并且能够显示或存储定量分析的结果(265)。所显示的或所存储的结果可以包括降解产物的性质、油的来源、样本中降解产物的分数、油的天然组分的分数以及以上的任意组合。分析的类型、分析的时间、分析的日期、样本的温度、稀释剂的类型(在使用的情况下)、稀释剂的量(在使用的情况下)、磁场的强度和说明也可以被显示和/或被存储。
质子NMR测量能够用于检测已加工材料,以用于与分析相关的各种方面。随后,可以对于每个样本定义数学期望值。同时,相同的测量可以用于对一系列重要的组分进行量化。可以使用所得到的结果建立参考数据库,使得能够对将来待被分析的样本按类别进行分组。可以使用化学计量统计法和定量分析的组合来检测各种质量不合格。
例如,根据1H-NMR谱,能够容易地识别许多代谢物(氨基酸,酚,糖,和TCA相关的有机酸)。对于每个质子的所观察的化学位移位置和自旋-自旋耦合模式提供关于在分子中发现什么种类的质子以及随后的质子如何排布的信息。此外,能够根据谱中信号的积分容易地计算样本中的每个代谢物的浓度。不需要如在其他方法中使用的将信号强度转换为浓度的校准曲线。对于获得关于浓度的可重现结果,以下参数是重要的:弛豫延迟、脉冲宽度和采集时间。
在测量1H-NMR谱时,其中一个问题是水信号,水信号是与糖或糖苷的端位异构质子(δ为4.8到5.2)重叠的由残留的水产生的巨大信号。为了抑制这个不期望的水信号,已经应用了若干方法,例如,加入顺磁离子如Mg2+,随后是Carr-Purcell(CPMG)自旋回波脉冲程序的Meiboom-Gill修改和使用附加的脉冲的预饱和。然而,当在弛豫延迟期间应用预饱和技术时——这是最常用的方法,会发生接近被抑制的水的信 号强度的不期望的下降。为了避免这样的不期望的抑制,选择样本的温度和pH值以使水信号最小化,因为样本的温度和pH值强烈地影响水信号。
根据代谢物的分子大小,可以应用具体的脉冲序列。为了将来自小分子的信号与来自大分子的信号分开,可以使用自旋扩散差分。
在包含大分子(例如,蛋白质或脂囊泡)的矩阵的情况下,诸如CMPG脉冲序列之类的自旋回声序列的应用实现来自大分子的不需要的共振的衰减。然而,在使用不同的脉冲序列的植物提取物的任意1H-NMR谱中,存在代谢物的密集的信号;如上文所公开的,多变量数据分析可以用于区分复杂的谱中的信号。
图6是如何能够找到原产国或原产地区的示意图。按国家或按橄榄种植区绘制在实践中可以从先前对已知地区的样本进行的多变量分析得到的数据,以形成概率椭球体,一个概率椭球体对应于每个国家或地区(字母A到G)。在图6中,为了清晰起见,这些数据被示出为减少到三维。星标示意性地示出了来自对于单个样本的多变量分析的数据;星标的位置表示样本可能来源于国家D。
图7A至图7C示出了对油的样本进行的加热的效果。图7A示出了加热前的样本。图7B示出了在165℃下加热3小时之后的样本,而图7C示出了在80℃下加热168小时的样本。化学位移约3.9处的主峰(710)基本没有受到加热的影响,而辅峰的大小增加,尤其是化学位移约1.15处的峰(720),其在图7A与图7B之间高度几乎增加一倍,而在图7B与图7C之间高度增加一倍以上,因此示出了:如果NMR被调谐到化学位移约为1.15的频率,则峰的高度与未使用的油的峰的(已知)高度的比值能够估计油的降解的量。如果NMR被调谐到已知的自由基或预自由基(pre-radical)的频率,则能够确定存在的自由基的分数,以及如果自由基或预自由基是致癌的或致畸形的,则能够确定样本的致癌性和致畸性。
由于NMR被预调谐到预定频率,因此需要机械的或电子的宽带或甚至中带调谐机构,从而减小系统的尺寸。在一些实施方式中,系统可以是台式机尺寸;在优选的实施方式中,其可以是手持的,从而使得其可以容易地搬运。
由于既没有宽带调谐也没有中带调谐,因此重调谐软件也是不必要的,这进一步减小了系统的尺寸并降低了系统的成本。
在一些实施方式中,存在硬件或软件精细调谐机构,以使得能够在系 统已经漂移的情况下对系统进行重调谐,以将系统重新调谐到不同的操作频率(例如,对于不同类型的油)以及以上的任意组合。
在优选的实施方式中,可以通过降解参数Q来确定降解或认证,降解参数Q是已加工材料的至少一个表型特征PCPM和已知物源的已加工材料的至少一个表型特征PCKP的函数:
Q=F(PCPM,PCKP)
其中Q被定义使得对于未降解材料或未掺杂材料而言,降解参数Q基本上等于第一预定值。
在测量降解的实施方式中,如果Q大于第二预定值,则可以认为已加工材料不可用。
在测量认证的实施方式中,如果Q小于预定值,则已加工材料被认证。对于非限制性示例,其是所声称的地区或国家(参见下文示例8)的产品,或者其包含所声称的原材料(参加下文示例1至示例7).
降解参数Q的一种示例是根据表型特征的比值确定的降解参数Q:
其中N是在确定降解参数时所包括的表型特征的数目。在这种情况下,对于未降解材料,Q=1。当然,显而易见的是这个比值的倒数也是降解参数Q的一种示例。
降解参数Q的另一示例是根据表型参数的比值确定的降解参数Q:
其中N是在确定降解参数时所包括的表型特征的数目。在这种情况下,对于未降解材料,Q=1。
降解参数Q的另一示例是根据表型特征之间的差来确定的降解参数Q:
其中N是在确定降解参数时所包括的表型特征的数目。在这种情况下,对于未降解材料,Q=0。
降解参数Q的另一示例是根据表型特征之间的均方根差确定的降解参数Q:
其中N是在确定降解参数时所包括的表型特征的数目。在这种情况下,对于未降解材料,Q=0。
降解参数的许多其他示例对本领域的技术人员将是明显的。这样的函数可以包括但不限于选自以下的函数:求和函数、减法函数、乘法函数、除法函数、对数函数、多项式函数、指数函数、三角函数、双曲函数、复变函数、β函数、误差函数以及以上的任意组合。
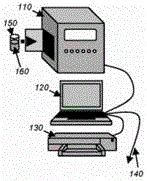
参照图8A至图8C,在一种实施方式中,本发明的系统包括调谐成单个频率的NMR(110),NMR(110)与计算机控制系统(120)和样本提供系统通信。优选地,样本提供系统也是计算机控制的。样本提供系统可以包括:如图8A中所示意性地示出的支持器(150),支持器(150)用于将单个样本(160)输送到NMR的关注区域,在分析过程中保持样本,以及在分析之后将样本从其移除;如图8B中所示意性地示出的一系列机械可连接支撑件(180),一系列机械可连接支撑件(180)被配置成容纳和输送多个支持器(150)使得多个样本(160)能够依次被输送到关注区域、被分析、以及从关注区域被移除,或者如图8C中所示意性地示出的流导管(170),流导管(170)用于连续地或分批将流动的样本输送通过关注区域。
该系统还可以包括打印机(130)、到其他设备和系统的通信装置(140)以及以上的任意组合。
在一些实施方式中,打印机可以打印用于已加工材料的样本的标签,标签优选地包括已加工材料的样本的标识、已知出处的已加工材料的样本的标识、已加工材料的表型特征PCPM、已知出处的已加工材料的表型特征PCKP、降解标识Q、已加工材料的图像、已知出处的已加工材料的图像、已加工材料的谱、已知物源的已加工材料的谱、时间以及以上的任意组合。
标签可以包括条形码、图片、图表、图示、符号、文本、日期、时间以及以上的任意组合,其中,上述项中的任意一项可以是已加工材料的样本的标识或已知产地的已加工材料的标识。
打印结果可以包括条形码、图片、图表、图示、符号、文本、日期、时间以及以上的任意组合。优选地,所打印的结果包括通过样本唯一地识别结果或一组结果的手段。
可以将上述项的任意组合存储在数据库(未示出)中,或者通过因特网、通过网络、通过有线通信、通过无线通信以及以上的任意组合传送到(140)另一系统或从另一系统传送。
通信机构优选地是双向的,并且被配置成传送选自下项的成员:至少一个已加工材料的表型特征PCPM、至少一个已知出处的已加工材料的表型特征PCKP、降解参数Q、至少一个已加工材料的图像、至少一个已知出处的已加工材料的图像、至少一个已加工材料的谱、至少一个已知出处的已加工材料的谱、至少一个已加工材料的样本的标识、至少一个已知出处的已加工材料的样本的标识、时间以及以上的任意组合。
在一些实施方式中,能够对上述项的任意组合进行存储、进一步分析、打印、与其他数据聚合以及以上的任意组合。
来自设备的输出可以选自:Q、已加工材料是否可信(是-否)、已加工材料是否降解(是-否)、PCKP、PCPM以及以上的任意组合。用于呈现信息的机构可以选自:显示至少一个输出的屏幕;打印至少一个输出的打印机;存储至少一个输出的数据库;提供至少一个预定声音模式的麦克风,每个声音模式表示至少一个输出;提供至少一个光模式的光、每个光模式表示至少一个输出,以及以上的任意组合。
光模式可以选自:具有恒定的色调的光、具有变化的色调的光、具有恒定的亮度的光、具有变化的亮度的光以及以上的任意组合。
呈现输出的光的一种非限制性示例可以是绿光表示烹饪油仍然可用,而红光表示油已经降解使得其不再可用。类似地,如果一个光亮起,则材料是掺杂的,而如果第二个光亮起,则材料基本上是未掺杂的。更多示例对本领域的技术人员是显而易见的。
声音模式可以选自:具有恒定的音调的声音、具有变化的音调的声音、具有恒定的响度的声音、具有变化的响度的声音、单音调声音、包括多个音调的声音以及以上的任意组合。
尽管已经通过烹饪油示出了上面的系统的使用,然而该系统能够用于具有至少一个NMR可识别标记物的任意其他已加工材料。这样的已加工材料的非限制性示例包括:果汁、中药或其他药物的成分、其他植物提取物、香味剂、草药、香料、咖啡、茶、橡胶、以及商业化生产的食品。
在优选的实施方式中,该系统能够识别由于环境条件或使用条件如温度、湿度、或者昆虫,霉菌或细菌侵染而产生的已加工材料的降解或者由于时间的流逝而产生的降解。
在一些实施方式中,该系统能够对已加工材料进行认证。这样的认证可以包括例如验证已加工材料的原产地区、验证已加工材料的来源,对于非限制性示例,已加工材料由其制成的品种、或者确定已加工材料的掺杂。
尽管无论农产品在哪里生长,天然产物的主要组分都保持相同,然而较小的和/或微量的组分的类型和量可能不同,这取决于气候和土壤中的微量元素。因此。例如,在英国生长的葡萄与在法国生长的同一品种的葡萄的味道可能不同,尽管所有的加工条件都是相同的,由英国葡萄制成的葡萄酒与由法国葡萄制成的葡萄酒的味道也可能不同。
类似地,较小的和/或微量的组分在天然产物的同一物种的不同变种之间可以是不同的,并且在成熟过程中和储存过程中较小的和/或微量的组分可以变化。
如上文所讨论的(参见图6),在一些实施方式中,本发明的设备可以用于区分来自不同地区或国家的已加工材料。类似地,在一些实施方式中,其可以用于区分早期收获的产物和晚期收获的产物。在一些实施方式中,其可以用于识别储存条件,尤其是可能对已加工材料的质量有不利影响的存储条件。
掺杂可以包括加入一种或更多种人造材料,加入来自不同的较不理想的地区的已加工材料,加入不同物源的已加工材料或稀释。第一种情况的一个非限制性示例是将蒸馏醋加入到香脂醋中,或者将果糖加入到橙汁中。第二中情况的一个非限制性示例是将摩洛哥橄榄油加入到利古里亚橄榄油中,因为利古里亚橄榄油是法定产区等级,并且在市场中占有30%的优势。第三种情况的一种非限制性示例是将橘汁(柑橘)加入到橙汁(甜橙)中。第三种情况的另一非限制性示例是将水加入果汁或牛奶中。
示例
示例1—冬青
一种示例是对冬青属的研究。分析了十一个品种的冬青,十一个品种的冬青根据它们的代谢物是可区分的,尤其是可以将巴拉圭茶(巴拉圭冬青)与它的掺杂物区分开。起作用的代谢物是熊果苷、苯丙素、咖啡因和可可碱。咖啡因和可可碱仅存在于巴拉圭冬青中,而熊果苷只存在于其他品种中。
示例2—甘菊
对甘菊(母菊)的头状花序的研究表明这个技术可以用于评估不同批次的花中茎材料的相对量。
示例3—马钱子
使用植物的不同部分(种子、根、叶和树皮)对三种不同的马钱子品种进行了表征。基于所有样本的代谢物如马钱子碱、马钱子苷、马钱子icaja生物碱(伊卡晶、sungucine)以及脂肪酸,所有样本都是明显的可区分的。
示例4
对于十二个大麻品种,可以使用——对于非限制性示例——以下化合物来对品种进行区分:THCA、CBDA、葡萄糖、天冬酰胺和谷氨酸,以及以上的任意组合。
示例5—中药
中药(TCM)通常是若干植物的混合物,并且作为出售的药物中的各种植物的组分可以是非常不同的,因为质量控制法规倾向于关注某种化合物或一组化合物的存在和量,而不是药物的总体组成。
麻黄
麻黄被广泛应用于中药中。然而,三个品种的麻黄——草麻黄、中麻黄和木贼麻黄——普遍被使用,并且可互换地使用,因为通常法规制定麻黄碱的量(干重的8%)。
然而,可以使用本系统的方法区分草麻黄、中麻黄和木贼麻黄。区别特征包括麻黄碱、和次级代谢产物——苯甲酸类似物二者的量和类型。例如,在九个被测的商品麻黄材料中,一个被显示为是两个品种的混合物,其他包括单个品种。
人参
人参(人参(Panax ginseng))制剂是最普遍使用的草药之一。人参制品可以由不同年龄(4年、5年以及6年)的人参并且通过不同的加工(红和白)制成。数据表示可以通过化合物存在的分数来区分各种人参制剂,化合物例如但不限于:丙氨酸,精氨酸,富马酸,肌醇和人参皂甙。
当归
对于已经测试的两个东当归亚种:东当归(yamato-toki)和北海当归(hokkai-toki),就它们的地理位置和它们种类而言,根部是可区分的。
青蒿
已经测试的两个青蒿品种:黄花蒿和非洲青蒿已经表现出是可区分的。
在进一步的测试中,商业产品中的青蒿素的含量表现出与商业声称不同。
其他药用植物
可区分的其他药用植物包括但不限于小白菊、卡法根和圣约翰麦芽汁。
示例6—果汁的掺杂
在与参考标准相比较的情况下,具体化合物的浓度的具体偏差或化合物的具体组合的型谱的具体偏差可以表示特性质量和可靠性问题,如糖的添加。在一些实施方式中,可以获知果汁中化合物的绝对浓度。这些化合物包括但不限于蔗糖、葡萄糖、果糖、脯氨酸、丙氨酸、5-羟甲基糠醛(HMF)、乙醇、甲醇、丙酮、根皮三酸、乙醛、苯甲醛、3-羟基丁酮(acetoine)、熊果苷(arbutine)、苹果酸、柠檬酸、异柠檬酸、绿原酸、乳酸、富马酸、奎尼酸、琥珀酸、柠苹酸、甲酸、苯甲酸、乙酸、山梨酸、葡糖酸和半乳糖醛酸。此外,可以计算各种化合物的浓度之间的关系,如葡萄糖与果糖的比例或蔗糖与总糖的比例。
因此,能够检测欺诈,例如但不限于:将糖加入果汁、消耗性酶加工(标记物:半乳糖醛酸)、添加柠檬酸或柠檬汁(例如,在苹果汁中)、橘皮提取物(标记物:根皮三酸)或使用未成熟的水果(例如,苹果汁中高浓度的奎尼酸)。
示例7—果汁中水果的种类
在一些实施方式中,能够获知果汁中使用的水果的种类。能够区分的水果的种类包括但不限于:苹果、橘子、柑橘、酸樱桃、菠萝、黑醋栗、百香果、柠檬、葡萄柚、香蕉、桃子、覆盆子、草莓、梨、杏、芒果、番石榴、胡萝卜、接骨木果、石榴和葡萄。
一种果汁与另一种果汁的掺杂是不常见的,除了橙汁(甜橙)与橘汁(柑橘)混合的情况。后者通常较为便宜,因此一些公司在没有声明的情况下将其添加到橙汁中,这在欧洲是非法的。使用传统的分析难以检测橘汁到橙汁中的添加。然而通过本系统,水平为10%或更高的橘汁的检测应该是可行的。
示例8—区分果汁的来源
在一些实施方式中,设备能够区分直接果汁和来自浓缩的果汁。
在一些实施方式中,如上文参考图6讨论的,设备能够检测水果的原产地。
用于这样的鉴别的基本统计学方法是PCA(主要组分分析)和鉴别分析。可以通过交叉验证和蒙特卡罗分析来对准确性进行检查。在确定最可能的组分配之后,通过两个步骤来验证样本。首先,单变量分析将每个谱关注区域与参考数据集相比较,并且检测化合物浓度的偏差。第二个方法是基于PCA/SIMCA的多变量分析,用于检测在单变量分析中不明显的偏差。如果两个方法提供相同的结果,则样本与模型一致,被认为表示预期的来源,并且已经成功通过预筛选试验。在这种情况下不需要对样本进行进一步测试。
然而,如果检测到与常态的偏差,则可以进行进一步的分析。这种非针对性的方法甚至使得能够检测先前未知的污染物。
示例9—果汁的水果含量的估计
通常,通过对所选择的化合物和矿物质进行量化分析并且将这些量与参考分布相比较来估计果汁的水果含量。通过本设备,可以在仅一个谱的基础上测量数百个变量,使得可以使用回归分析来估计水果含量。测试已经显示,对于样本中95%以上的样本,结果具有约10%的相对准确性。
- 还没有人留言评论。精彩留言会获得点赞!