抗体表位的制作方法
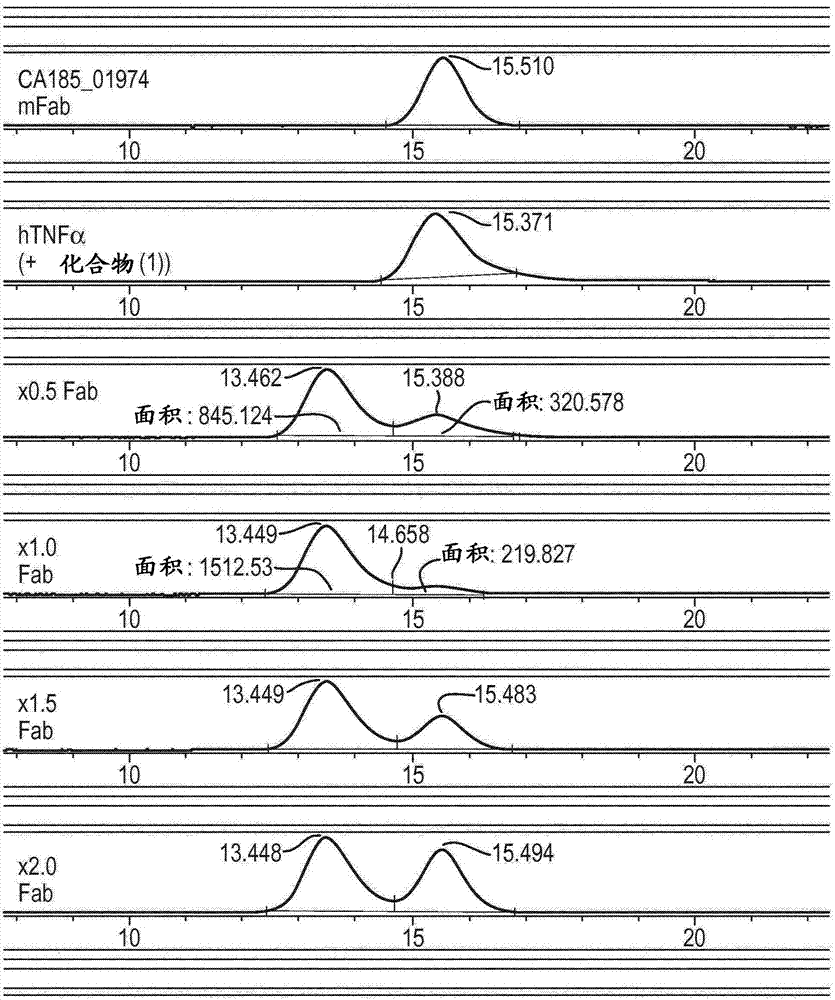
本发明涉及可用于筛选TNFα的小分子调节剂的抗体,特别是识别特定表位的抗体。本发明涉及选择性结合此类TNFα小分子调节剂复合物的抗体,以及此类抗体的用途。本发明还涉及使用所述抗体鉴定TNFα的新调节剂的测定法。
背景技术:
:肿瘤坏死因子(TNF)超家族是共有调节细胞存活和细胞死亡的主要功能的蛋白质家族。TNF超家族的成员共有共同的核心基序,其由两个反平行的β折叠片(具有反平行的β链)组成,形成“果冻卷(jellyroll)”β结构。TNF超家族成员共有的另一个共同特征是形成同源或异源三聚体复合物。TNF超家族成员的这些三聚体形式结合并激活特定的TNF超家族受体。TNFα是TNF超家族的原型成员。TNFα生产的失调牵涉到许多具有重大医学重要性的病理状况。例如,TNFα牵涉到类风湿性关节炎、炎性肠病(包括克罗恩氏病)、牛皮癣、阿尔茨海默氏病(AD)、帕金森病(PD)、疼痛、癫痫、骨质疏松症、哮喘、系统性红斑狼疮(SLE)和多发性硬化症(MS)。TNF超家族的其他成员也牵涉到病理状况,包括自身免疫性疾病。TNF超家族成员的常规拮抗剂是大分子的并且通过抑制TNF超家族成员与其受体的结合起作用。常规拮抗剂的实例包括抗-TNFα抗体,特别是单克隆抗体,例如英夫利昔单抗阿达木单抗和赛妥珠单抗或可溶性TNFα受体融合蛋白,例如依那西普发明概述本发明人已经鉴定了调节TNFα的小分子实体(SME)的类别。这些化合物通过结合TNFα的同三聚体形式、诱导和/或稳定TNFα同源三聚体的构象变化而发挥作用。例如,TNFα与结合的化合物的同源三聚体可以与TNFα受体结合,但不太能或不能启动TNFα受体下游的信号传导。这些化合物可以用于治疗由TNFα介导的病症。本发明人开发了选择性结合包含这种化合物和TNFα的复合物的抗体。这些抗体可用于以这种方式鉴定能够抑制TNFα的其他化合物,并且还可以用作靶接合生物标志物(targetengagementbiomarker)。因此,本发明提供了与包含选自SEQIDNO:36的TNFα的L94,P113和Y115的至少一个残基的表位结合的抗体。本发明还提供:-与如上定义的抗体竞争结合TNFα的抗体。-编码本发明抗体的分离的多核苷酸。-用于通过疗法治疗人或动物体的方法中使用的本发明的抗体。-包含本发明的抗体和药学上可接受的佐剂和/或载体的药物组合物。-使用本发明的抗体作为靶接合生物标志物用于检测从受试者获得的样品中的化合物-三聚体复合物;其中所述抗体是可检测的,并且所述复合物包含三聚体TNFα和能够与三聚TNFα结合的化合物,由此化合物-三聚体复合物结合必需的受体并调节三聚体通过受体诱导的信号传导。-检测化合物与三聚体TNFα的靶接合的方法,由此化合物-三聚体复合物结合必需的受体并调节三聚体通过受体诱导的信号传导,所述方法包括:(a)从施用所述化合物的受试者获得样品;(b)使本发明的抗体与所述样品和对照样品接触,其中所述抗体是可检测的;(c)确定所述可检测抗体与所述样品和所述对照样品的结合量,其中所述可检测抗体与所述样品的结合大于所述可检测抗体与所述对照样品的结合指示所述化合物与所述三聚TNFα的靶接合。-本发明的抗体用于筛选引起TNFα三聚体构象变化的化合物的用途,其中所述构象变化调节三聚体TNFα结合时必需受体的信号传导。-包含TNFα三聚体和与其结合的化合物的复合物,其中化合物-三聚体复合物结合必需的受体并调节三聚体通过受体诱导的信号传导,其中所述复合物与本发明的抗体以1nM或更低的KD-ab结合。-能够结合TNFα三聚体以形成复合物的化合物,由此化合物-三聚体复合物结合必需的受体并调节由三聚体通过受体诱导的信号传导,其中化合物-三聚体复合物以1nM或更小的KD-ab结合本发明的抗体。-鉴定能够结合TNFα三聚体并调节三聚体通过必需受体的信号传导的化合物的方法,其包括以下步骤:(a)进行结合测定以测量包含TNFα三聚体和测试化合物的测试化合物-三聚体复合物与选择性结合所述复合物的本发明抗体的结合亲和力;(b)将步骤(a)中测量的结合亲和力与已知以高亲和力与步骤(a)中提到的抗体结合的不同化合物-三聚体复合物的结合亲和力比较;和(c)如果根据步骤(b)中提到的比较考虑,其测量的结合亲和力是可接受的,则选择存在于步骤(a)的化合物-三聚体复合物中的化合物。附图的简要说明图1显示了人TNFα晶体结构上的残基N168,I194,F220和A221。图2显示了使用CA185_01974mFab和化合物(1)的HPLC实验的结果。对应于过量Fab的峰出现在1.5倍和2.0倍过量上。因此,化学计量确定为1Fab:1TNFα三聚体。图3显示了使用CA185_01979mFab和化合物(1)的HPLC实验的结果。同样,对应于过量Fab的峰出现在1.5倍和2.0倍过量上。化学计量因此也被确定为1Fab:1TNFα三聚体。图4表示使用市售抗TNFα多克隆抗体的化合物(3)、(4)和(5)的总TNFαELISA结果。图5显示了使用CA185_01974.0和化合物(3)、(4)和(5)的构象特异性TNFαELISA的结果。ApoTNFα在该测定中不提供信号,表明抗体CA185_01974与化合物结合的TNFα结合的特定性质。图6显示了在1和10μg/ml下用CA185_01974和CA185_01979染色的FACS直方图图。这些图表明抗体只识别已经与化合物(1)预温育的TNFα。DMSO对照没有染色图7显示了用CA185_01974对亲本NS0细胞系和过表达膜TNFα的工程化NS0细胞系进行染色的FACS直方图图。将细胞与化合物(1)或DMSO温育并用抗体Fab片段染色。同样,结果表明DMSO对照没有染色(对于亲本或工程化细胞系)。然而,在化合物(1)的存在下,观察到工程细胞系的染色。图8显示使用食蟹猴TNFα测定CA185_01974的亲和力值的传感图。对照(上图)含有食蟹猴TNFα和DMSO。然后底图显示与化合物(4)复合的食蟹猴TNFα的重复实验。图9显示了使用人TNFα测定CA185_01974的亲和力值的传感图。对照(上图)含有人TNFα和DMSO。然后底图显示与化合物(4)复合的人TNFα的重复实验。图10显示了化合物(1)-(7)的结构。图11显示了与CA185_01979Fab结合的TNFα单体(A链)的分辨率下的结构。图12显示了与图11相同的结构,但在计算上用对称三聚体(即在不存在化合物的情况下为未扭曲的三聚体)建模。用这个对称三聚体,三聚体的A链保留了与Fab片段的相互作用。然而,Fab片段和三聚体的C链之间存在空间相互作用。图13也显示了与图11相同的结构,除了在这种情况下,计算上模拟了非对称三聚体(即具有扭曲构象的三聚体)。这种不对称的三聚体结构最初是在化合物(6)的存在下产生的。同样,保留了Fab和三聚体的A链之间的相互作用。然而,与对称三聚体相比,Fab和C链之间不存在空间相互作用。图14显示了CA185_01979Fab在TNFα的A链上实验确定的表位的球体。使用截止(cut-off)来确定紧邻抗体CDR的残基。图15显示了CA185_01979Fab在TNFα的C链上的表位。表位是基于覆盖在Fab-TNFα结构上的基于化合物结合TNF三聚体(化合物(6))的模型在计算上推断的。图16显示了图14和图15的表位的覆盖图。序列表简述SEQIDNO:1显示了CA185_01974.0的LCDR1。SEQIDNO:2显示CA185_01974.0的LCDR2。SEQIDNO:3显示了CA185_01974.0的LCDR3。SEQIDNO:4显示了CA185_01974.0的HCDR1。SEQIDNO:5显示了CA185_01974.0的HCDR2。SEQIDNO:6显示了CA185_01974.0的HCDR3。SEQIDNO:7显示了CA185_01974.0的LCVR的氨基酸序列。SEQIDNO:8显示了CA185_01974.0的HCVR的氨基酸序列。SEQIDNO:9显示了CA185_01974.0的LCVR的DNA序列。SEQIDNO:10显示了CA185_01974.0的HCVR的DNA序列。SEQIDNO:11显示了CA185_01974.0的κ轻链的氨基酸序列。SEQIDNO:12显示了CA185_01974.0的mIgG1重链的氨基酸序列。SEQIDNO:13显示了CA185_01974.0的mFab(无铰链)重链的氨基酸序列。SEQIDNO:14显示了CA185_01974.0的κ轻链的DNA序列。SEQIDNO:15显示了CA185_01974.0的mIgG1重链的DNA序列。SEQIDNO:16显示了CA185_01974.0的mFab(无铰链)重链的DNA序列。SEQIDNO:17显示CA185_01979.0的LCDR2。SEQIDNO:18显示CA185_01979.0的LCDR3。SEQIDNO:19显示了CA185_01979.0的HCDR1。SEQIDNO:20显示CA185_01979.0的HCDR2。SEQIDNO:21显示CA185_01979.0的HCDR3。SEQIDNO:22显示CA185_01979.0的LCVR的氨基酸序列。SEQIDNO:23显示了CA185_01979.0的HCVR的氨基酸序列。SEQIDNO:24显示了CA185_01979.0的LCVR的DNA序列。SEQIDNO:25显示了CA185_01979.0的HCVR的DNA序列。SEQIDNO:26显示了CA185_01979.0的κ轻链的氨基酸序列。SEQIDNO:27显示了CA185_01979.0的mIgG1重链的氨基酸序列。SEQIDNO:28显示了CA185_01979.0的mFab(无铰链)重链的氨基酸序列。SEQIDNO:29显示了CA185_01979.0的κ轻链的DNA序列。SEQIDNO:30显示了CA185_01979.0的mIgG1重链的DNA序列。SEQIDNO:31显示了CA185_01979.0的mFab(无铰链)重链的DNA序列。SEQIDNO:32显示了大鼠TNFα的氨基酸序列。SEQIDNO:33显示了小鼠TNFα的氨基酸序列。SEQIDNO:34显示人TNFα的氨基酸序列。SEQIDNO:35显示了可溶形式的人TNFα的氨基酸序列。SEQIDNO:36显示了可溶形式的人TNFα的氨基酸序列,但没有起始的“S”(其是SEQIDNO:35的克隆制品)发明详述TNF超家族成员的调节剂已经鉴定出结合三聚体形式的TNF超家族成员的测试化合物。以下公开内容通常涉及这些化合物与任何TNF超家族成员的结合,尽管本权利要求特别涉及这些化合物与TNFα的结合。测试化合物是分子量为1000Da或更小,一般750Da或更小,更合适的是600Da或更小的小分子实体(SME)。分子量可以在约50-约1000Da,或约100-约1000Da的范围内。这些化合物稳定了与所需的TNF超家族受体结合三聚体TNF超家族成员的构象并调节受体信号传导。这样的化合物的实例包括式(1)-(7)的化合物。化合物对TNF超家族成员的三聚体形式的稳定作用可以通过在有和没有化合物的情况下测量三聚体的热转换中点(Tm)来定量。Tm表示50%的生物分子解折叠时的温度。稳定TNF超家族成员三聚体的化合物将增加三聚体的Tm。Tm可以使用本领域已知的任何适当的技术来确定,例如使用差示扫描量热法(DSC)或荧光探针热变性分析。该化合物可以结合在TNF超家族成员三聚体内的中央空间内(即三聚体的核心)。这些化合物可使TNF超家族成员变成TNF超家族受体拮抗剂。因此,这些化合物能够阻断TNF超家族成员信号传导而不必与TNF超家族成员与其受体之间的高亲和力相互作用竞争。或者,所述化合物可以稳定与所需的TNF超家族受体结合的三聚体TNF超家族成员的构象并增强受体的信号传导。因此,这些化合物能够增加TNF超家族成员信号传导而不必与TNF超家族成员与其受体之间的高亲和力相互作用竞争。在本文中化合物被描述为拮抗剂的情况下,应该理解的是,所述化合物可以同样是激动剂并增加与TNF超家族成员三聚体和这种激动剂化合物的复合物结合的TNF超家族受体的信号传导。类似地,在其它公开内容涉及拮抗性化合物、鉴定此类化合物的方法和此类化合物的用途的情况下,本公开内容可同样地指激动剂化合物。本文所述的化合物是变构调节剂,其与TNF超家族受体的天然激动剂(即TNF超家族成员的三聚体形式)结合,并驱使这些三聚体采用仍然结合必需的TNF超家族受体并调节通过受体的信号传导的构象。通过调节,可以理解该化合物可能具有拮抗作用,从而减少TNF超家族受体的信号传导,或者刺激作用,从而增加或增强TNF超家族受体的信号传导。这些化合物可以将天然的TNF超家族成员激动剂转化为拮抗剂。相反,常规的TNF超家族成员拮抗剂结合TNF超家族成员或TNF超家族受体并阻止TNF超家族成员与必需的受体结合。或者,当TNF超家族成员被结合时,与TNF超家族成员的信号传导水平相比,该化合物可以增加TNF超家族受体的信号传导。因此,这些化合物可将天然的TNF超家族成员激动剂转化为所谓的“超激动剂”。因此该化合物也可以称为配体活性的变构调节剂(AMLA)。只要它们与至少一种TNF超家族成员结合并稳定与所需的TNF超家族受体结合的三聚体TNF超家族成员的构象并调节TNF超家族受体的信号转导,化合物就其化学式或结构而言就不受限制。因此可以使用本文所述的抗体和方法来鉴定化合物。该化合物可以包含苯并咪唑部分或其电子等排体(isostere)。与不存在所述化合物的情况下TNF超家族成员与必需受体的结合亲和力相比,所述化合物可以增加TNF超家族成员(以化合物-三聚体复合物形式)与必需受体的结合亲和力。这些化合物结合TNF超家族成员的三聚体形式。这样的化合物可以特异性地(或选择性地)与一种或多种TNF超家族成员的三聚体形式结合。化合物可以特异性(或选择性地)与TNF超家族成员中的一个结合,但不与任何其他TNF超家族成员结合。化合物还可以特异性结合2、3、4种或全部的TNF超家族成员。通过特异性(或选择性),将理解的是,所述化合物结合一种或多种感兴趣的分子(在这种情况下是TNF超家族成员的三聚体形式),与任何其他分子(其可以包括TNF超家族成员的其他分子)没有显著的交叉反应性。交叉反应性可以通过任何合适的方法评估,例如表面等离子体共振。针对三聚体形式的TNF超家族成员的化合物与该特定三聚体形式的TNF超家族成员以外的分子的交叉反应性可以被认为是显著的,如果该化合物与其他分子的结合与其结合感兴趣的三聚体形式的TNF超家族成员至少5%,10%,15%,20%,25%,30%,35%,40%,45%,50%,55%,60%,65%,70%,75%,80%,85%,90%或100%一样强的话。例如,如果化合物与其他分子的结合与其结合感兴趣的三聚体形式的TNF超家族成员至少约5%-约100%,通常约20%-约100%,或约50%-约100%强,则交叉反应性可被认为是显著的。对TNF超家族成员的三聚体形式特异(或选择性)的化合物可以以小于90%,85%,80%,75%,70%,65%,60%,55%,50%,45%,40%,35%,30%,25%或20%的其结合三聚体形式的TNF超家族成员的强度结合另一种分子。所述化合物适当地以小于约20%,小于约15%,小于约10%或小于约5%,小于约2%或小于约1%的其结合三聚体形式的TNF超家族成员的强度(低至零结合)结合另一种分子。测试化合物与TNF超家族成员结合的速率在本文中称为“缔合”速率“kon-c”,并且测试化合物从TNF超家族成员解离的速率在本文中被称为“解离”速率或koff-c。如本文所用,符号“KD-c”表示测试化合物对TNF超家族成员的结合亲和力(解离常数)。KD-c被定义为koff-c/kon-c。测试化合物可具有缓慢的“缔合”速率,其可通过TNF超家族成员的质谱分析和化合物-三聚体复合物峰强度以分钟测量。测试化合物的KD-c值可以通过在不同的TNF超家族成员:化合物-三聚体复合物比率下重复该测量来估计。典型地,本发明化合物与TNF超家族三聚体的结合的特征在于快速的“缔合”速率,理想的是约107M-1s-1,具有慢的“解离”速率,例如典型值为10-3s-1,10-4s-1,或者没有可测量的“解离”速率。如本文所用,符号“kon-r”表示化合物-三聚体复合物结合TNF超家族受体的速率(“缔合”速率)。如本文所用,符号“koff-r”表示化合物-三聚体复合物从TNF超家族受体解离的速率(“解离”速率)。如本文所用,符号“KD-r”表示针对超家族受体的化合物-三聚体复合物的结合亲和力(解离常数)。KD-r被定义为koff-r/kon-r。在测试化合物存在下(即以化合物-三聚体复合物形式),TNF超家族成员与其受体结合的KD-r值可以比在没有测试化合物的情况下TNF超家族成员的KD-r值低至少约1.5倍,2倍,3倍,4倍,5倍,10倍,20倍,30倍,40倍,50倍,60倍,70倍,80倍,90倍,100倍。用于与TNF超家族成员结合的化合物-三聚体复合物的KD-r值可以与在不存在测试化合物的情况下与TNF超家族受体结合的TNF超家三聚体的KD-r值相比降低TNF超家族的KD-r值的至少约1.5倍,通常至少约3倍,更合适地至少约4倍,即化合物-三聚体复合物对TNF超家族受体的结合亲和力可以与不存在测试化合物时TNF超家族三聚体与TNF超家族受体的结合亲和力相比增加至少约1.5倍,一般至少约三倍,更合适至少约四倍,。与TNF超家族成员与其受体在不存在化合物时的结合亲和力相比较,本文所述的化合物可以将TNF超家族成员与其受体的结合亲和力提高约2倍,3倍,4倍,5倍,10倍,20倍,30倍,40倍,50倍,60倍,70倍倍,80倍,90倍,100倍或更多。结合亲和力可以以结合亲和力(KD-r)的形式给出,并且可以以任何合适的单位给出,例如μM,nM或pM。KD-r值越小,TNF超家族成员对其受体的结合亲和力越大。在该化合物存在下,TNF超家族成员与其受体结合的KD-r值可以比在不存在受试化合物的情况下TNF超家族成员与其受体结合的KD-r值低至少约为1.5倍,2倍,3倍,4倍,5倍,10倍,20倍,30倍,40倍,50倍,60倍,70倍,80倍,90倍,100倍。与单独结合TNF超家族受体的TNF超家族三聚体的KD-r值相比,化合物-三聚体复合物结合TNF超家族受体的KD-r值的降低可能是由于与单独的TNF超家族三聚体相比与TNF超家族受体结合的化合物-三聚体复合物的缔合速率(kon-r)增加,和/或与单独的TNF超家族三聚体相比解离速率(koff-r)降低。与TNF超家族受体结合的化合物-三聚体复合物的缔合速率(kon-r)通常比单独的TNF超家族三聚体增加。与TNF超家族受体结合的化合物-三聚体复合物的解离速率(koff-r)通常比单独的TNF超家族三聚体降低。最合适的是,与单独的TNF超家族三聚体相比,与TNF超家族受体结合的化合物-三聚体复合物的缔合速率(kon-r)增加,并且与TNF超家族受体结合的化合物-三聚体复合物的解离速率(koff-r)降低。与在不存在所述化合物的情况下与其受体结合的TNF超家族三聚体结合的kon-r值相比,化合物-三聚体复合物对必需的TNF超家族受体的kon-r值可以增加至少约1.5倍或至少约2倍,合适地至少约3倍,和/或与在不存在所述化合物的情况下与其受体结合的TNF超家族三聚体结合的koff-r值相比,化合物-三聚体复合体对必需的TNF超家族受体的koff-r值可以降低至少约1.2倍,至少约1.6倍,至少约2倍,更合适地至少约2.4倍。与TNF超家族三聚体结合的化合物的缔合速率(kon-c)通常比结合TNF超家族受体的化合物-三聚体复合物的缔合速率(kon-r)更快。结合TNF超家族受体的化合物-三聚体复合物的解离速率(koff-r)通常也快于与TNF超家族三聚体结合的化合物的解离速率(koff-c)。最合适的是,与TNF超家族三聚体结合的化合物的缔合速率(kon-c)比结合于TNF超家族受体的化合物三聚体复合物的缔合速率(kon-r)更快,化合物三聚体与TNF超家族三聚体的复合物缔合速率(koff-r)快于TNF超家族三聚体与化合物结合的解离速率(koff-c)。化合物结合TNF超家族三聚体的KD-c值通常低于与TNF超家族受体结合的化合物-三聚体复合物的KD-r值,即化合物对三聚体的亲和力高于化合物-三聚体复合体对受体的亲和力。化合物-三聚体复合物和TNF超家族三聚体与必需的TNF超家族受体的kon-r,koff-r和KD-r值可使用任何合适的技术来确定,例如表面等离子体共振,质谱和等温量热法。TNF超家族成员在测试化合物存在下与其受体结合的KD-r值可以是1μM,100nM,10nM,5nM,1nM,100pM,10pM或更低(通常低至约1pM的较低值)。在测试化合物存在下(即在化合物-三聚体复合物中),TNF超家族成员与其受体结合的KD-r值可以是1nM或更小。用于结合所需TNF超家族受体的化合物-三聚体复合物的KD-r值可以小于600pM,更优选小于500pM,小于400pM,小于300pM,小于200pM,小于100pM或小于50pM(再下降到约1pM的较低值)。用于结合必需的TNF超家族受体的化合物-三聚体复合物的KD-r值可以小于约200pM(至约1pM)。化合物可通过测定来鉴定,所述测定包括测定TNF超家族成员和化合物样品中TNF超家族成员的三聚体形式的KD-r;比较样品中TNF超家族成员的三聚体形式的KD-r与对照样品;并选择一个化合物。这些化合物稳定了TNF超家族成员的三聚体形式。如果与在不存在测试化合物的情况下含有TNF超家族成员的样品和去稳定剂的样品中观察到的三聚体的量相比,测试化合物增加三聚体的比例,则认为发生稳定化。与在没有测试化合物的情况下含有TNF超家族成员和去稳定剂的样品中存在的三聚体的量相比,受试化合物可使三聚体的量增加约10%,15%,20%,25%,30%,35%,40%,45%,50%,55%,60%,65%,70%,75%,80%,85%,90%,95%,100%,150%,200%,300%,400%。与不存在去稳定剂和测试化合物的情况下三聚体的量相比,测试化合物还可以增加对于TNF超家族成员样品观察到的三聚体的量。与在没有去稳定剂和测试化合物的情况下含有TNF超家族成员的样品中存在的三聚体的量相比,测试化合物可使三聚体的量增加约10%,15%,20%,25%,30%,35%,40%,45%,50%,55%,60%,65%,70%75%,80%,85%,90%,95%,100%,150%,200%,300%,400%。与在不存在测试化合物的情况下含有TNF超家族成员的样品中结合受体的TNF超家族成员的量相比,测试化合物可以将与其受体结合的TNF超家族成员的量增加约10%,15%,20%,25%,30%,35%,40%,45%,50%,55%,60%,65%,70%,75%,80%,85%,90%,95%,100%,150%,200%,300%,400%。测试化合物可以增强TNF超家族成员的三聚体形式的稳定性。如果测试化合物与对于不存在测试化合物的情况下含有TNF超家族成员和去稳定剂的样品观察到的TNF超家族成员的三聚体形式的Tm相比增加TNF超家族成员的三聚体形式的热转换中点(Tm),则认为TNF超家族成员的三聚体形式的稳定性提高。TNF超家族成员的三聚体形式的Tm是50%的生物分子解折叠的温度。在存在和/或不存在测试化合物的情况下,TNF超家族成员的三聚体形式的Tm可以使用本领域已知的任何适当的技术,例如使用差示扫描量热法(DSC)或荧光探针热变性测定来测量。与不存在测试化合物的情况下含有TNF超家族成员的样品中TNF超家族成员的三聚体形式的Tm相比,测试化合物可使TNF超家族成员的三聚体形式的Tm增加至少1℃,至少2℃,至少5℃,至少10℃,至少15℃,至少20℃或更高。测试化合物可使TNF超家族成员的三聚体形式的Tm提高至少1℃,通常至少10℃,更合适地提高10℃至20℃。当化合物-三聚体复合物形式的TNF超家族成员与受体结合时,所述化合物可完全或部分抑制通过TNF受体的信号传导。该化合物可以起到减少至少约10%,20%,30%,40%,50%,60%,70%,80%,90%或100%的通过TNF超家族受体的信号传导的作用。或者,当化合物-三聚体复合物形式的TNF超家族成员与受体结合时,所述化合物可以增加通过TNF受体的信号传导。该化合物可以起到使通过TNF超家族受体的信号传导增加至少约10%,20%,30%,40%,50%,60%,70%,80%,90%,100%或200%的作用。可通过任何适当的技术来测量信号水平的任何改变,包括通过碱性磷酸酶或萤光素酶测量报告基因活性,使用机器如CellomicsArrayscan测量的NF-κB易位,下游效应物的磷酸化,信号分子的募集或细胞死亡。当化合物-三聚体复合物形式的TNF超家族成员结合受体时,所述化合物可以调节通过TNF受体的信号传导的下游作用中的至少一种。这些效应在本文中讨论并且包括TNF超家族诱导的IL-8,IL17A/F,IL2和VCAM产生,TNF超家族诱导的NF-κB活化和嗜中性粒细胞募集。本领域已知用于测量TNF超家族成员的下游效应的标准技术。所述化合物可以调节至少1、2、3、4、5、10种或直至所有通过TNF受体的信号传导的下游效应。化合物的活性可使用标准术语例如IC50或半数有效浓度(EC50)值来量化。IC50值代表50%抑制特定生物或生物化学功能所需的化合物的浓度。EC50值表示其最大效应的50%所需的化合物的浓度。所述化合物可具有500nM,400nM,300nM,200nM,100nM,90nM,80nM,70nM,60nM,50nM,40nM,30nM,20nM,10nM,5nM,1nM,100pM或更低(降至约10pM或1pM的较低值)的IC50或EC50值。可以使用任何适当的技术测量IC50和EC50值,例如可以使用ELISA定量细胞因子的产生。然后可以使用也被称为S形剂量响应模型的标准4-参数逻辑模型生成IC50和EC50值。如上所述,能结合TNF和调节信号传导的化合物的实例是式(1)-(7)的化合物。调节因子-TNF超家族成员复合物已鉴定本文所述的化合物与三聚体形式的TNF超家族成员的结合导致TNF超家族三聚体的构象变化。具体而言,TNF超家族成员三聚体在被本文公开的化合物结合时呈现变形或扭曲的构象。例如,当化合物(1)-(7)与人TNFα的可溶性结构域结合时,TNF保留其三聚体结构,但A和C亚基彼此远离并且C旋转以在这些亚基之间产生裂隙。不受理论束缚,据信在不存在所述化合物的情况下,三聚体TNF超家族成员(包括三聚体TNFα)能够结合三个单独二聚体TNF超家族成员受体。每个二聚体TNF超家族成员受体能够结合两个单独的TNF超家族三聚体。这导致多个TNF超家族成员三聚体和TNF超家族成员受体二聚体的聚集,产生引发下游信号传导的信号传导筏。当三聚体TNFα与化合物结合时,所得复合物的构象发生变形。因此,不受理论的约束,相信在本文公开的化合物存在下,三聚体TNF超家族成员,包括三聚体TNFα仅能够结合两个单独二聚体TNF超家族成员受体。只有两个,而不是三个单独的二聚体TNF超家族成员受体与三聚体TNF超家族成员结合的事实减少或抑制了多个TNF超家族成员三聚体和TNF超家族成员受体二聚体的聚集。这减少或抑制了信号传导筏的形成,因此减少或抑制了下游信号由于本文公开的化合物的结合,本发明的抗体可用于检测具有扭曲构象的TNFα。通常具有扭曲或变形构象的TNFα是三聚体TNFα。然而,本发明的抗体也可以与其他形式的TNFα结合。例如,本发明的抗体可以结合TNFα。TNFα通常是三聚体TNFα并且可以是TNFαs或三聚体TNFαs。因此,本发明提供了一种复合物,其包含TNFα三聚体和与其结合的化合物,其中化合物-三聚体复合物结合必需的TNFα受体并调节三聚体通过受体诱导的信号传导,其中所述复合物以至少1nM(即1nM或更低,至低至约1pM)的亲和力与本发明的抗体结合。TNF超家族成员通常是TNFαs。此外,相对于在TNFα三聚体的情况下结合化合物和/或在不存在化合物的情况下结合TNFα三聚体的亲和力,抗体通常以至少约100倍(亲和力提高至少约100倍),合适地约200倍的亲和力结合复合物。本发明进一步提供了一种化合物,其能够与TNFα三聚体结合形成复合物,其中化合物-三聚体复合物结合必需的TNF超家族受体并调节三聚体通过受体,其中所述化合物-三聚体复合物以1nM或更低(低至约1pM)的KD-ab结合本发明的抗体。TNFα通常是TNFαs。再一次,相对于在TNFα三聚体的情况下结合化合物和/或在不存在化合物的情况下结合TNFα三聚体的亲和力,抗体通常以至少低约100倍(亲和力提高至少约100倍),更合适地低约200倍的亲和力与复合物结合。化合物-三聚体复合物可以结合本发明的任何抗体。本文所述的化合物或复合物可用于治疗和/或预防病理状态。因此,提供了用于在人体或动物体上实施的治疗方法中使用的本发明的化合物或复合物。本发明还提供一种治疗方法,其包括将本发明的化合物或复合物施用于受试者。本发明的化合物或复合物可以用于本文所述的任何治疗适应症和/或药物组合物中。抗体本发明提供了选择性结合包含至少一种本文公开的化合物和至少一种TNFα三聚体的化合物-三聚体复合物的抗体。典型地,相对于在不存在TNFα的情况下抗体与化合物的结合,或者在没有化合物的情况下抗体与TNFα的结合或与其他(不同)化合物-(三聚体)复合物的结合,测量本发明的抗体与化合物-(三聚体)复合物的选择性结合。该化合物可以是上述任何化合物,包括化合物(1)-(7)(或其盐或溶剂合物)。如下面进一步讨论的,TNF超家族成员是TNFα。TNFα可以是人TNFα,特别是可溶性TNFα(TNFαS)。TNFαS可以具有SEQIDNO:35或SEQIDNO:36(其缺乏SEQIDNO:35的N末端“S”)的序列,或者可以是其变体。此类变体通常保留与SEQIDNO:35或SEQIDNO:36具有至少约60%,70%,80%,90%,91%,92%,93%,94%或95%(或甚至约96%,97%,98%或99%同一性)的同一性。换句话说,这样的变体可以与SEQIDNO:35或SEQIDNO:36保持约60%至约99%的同一性,适当地保留约80%至约99%的同一性,更合适地与SEQIDNO:35或SEQIDNO:36具有约90%-约99%的同一性,并且最适合的是与SEQIDNO:35或SEQIDNO:36具有约95%-约99%的同一性。下面进一步描述变体。如上所述,尽管本公开内容总体上涉及本发明的抗体与三聚体TNFα的结合,但是本发明的抗体也可以与其他形式的TNFα结合。为了说明,本申请的实施例证明CA185_0179抗体结合三聚体TNFα。但是,如图1所示(在存在化合物(1)的情况下与TNFα单体结合的CA185_0179抗体的晶体结构),该抗体似乎也与单体TNFα结合。不受理论束缚,在该化合物的存在下,认为TNF的可溶性结构域保留其三聚体结构。然而,A和C亚基彼此远离(并且C亚基旋转)以在这两个亚基之间产生裂缝。因此,虽然本发明的抗体结合扭曲的三聚体,但是如果三聚体结构被迫分开成单体,抗体仍然可能结合。(对于A和C亚基的进一步讨论见下文)。如本文所提及的术语“抗体”包括完整抗体和任何抗原结合片段(即“抗原结合部分”)或其单链。抗体指包含通过二硫键相互连接的至少两条重链(H)和两条轻链(L)的糖蛋白或其抗原结合部分。每条重链由重链可变区(本文缩写为HCVR或VH)和重链恒定区组成。每条轻链由轻链可变区(本文缩写为LCVR或VL)和轻链恒定区组成。重链和轻链的可变区含有与抗原相互作用的结合结构域。VH和VL区可以进一步细分成称为互补决定区(CDR)的高变区,散布有更保守的区域,称为框架区(FR)。抗体的恒定区可以介导免疫球蛋白与宿主组织或因子(包括免疫系统的各种细胞(例如效应细胞)和经典补体系统的第一组分(Clq))的结合。本发明的抗体可以是单克隆抗体或多克隆抗体,并且通常将是单克隆抗体。本发明的抗体可以是嵌合抗体,CDR移植抗体,纳米抗体,人或人源化抗体或其任何抗原结合部分。为了生产单克隆抗体和多克隆抗体,实验动物通常是非人类哺乳动物,如山羊,兔,大鼠或小鼠,但是抗体也可以在其他物种中产生。多克隆抗体可以通过常规方法产生,例如用目的抗原免疫合适的动物。随后可从动物中取出血液并纯化IgG部分。可以在需要免疫动物时通过给动物施用多肽获得针对本发明的化合物-三聚体复合物产生的抗体。使用众所周知的常规方案,参见例如HandbookofExperimentalImmunology,D.M.Weir(ed.),Vol4,BlackwellScientificPublishers,Oxford,England,1986)。可以免疫许多温血动物,如兔,小鼠,大鼠,绵羊,牛,骆驼或猪。然而,小鼠,兔子,猪和大鼠通常是最合适的。单克隆抗体可通过本领域已知的任何方法制备,如杂交瘤技术(Kohler和Milstein,1975,Nature,256:495-497),三源杂交瘤技术,人B细胞杂交瘤技术(Kozbor等,1983,ImmunologyToday,4:72)和EBV-杂交瘤技术(Cole等,MonoclonalAntibodiesandCancerTherapy,pp77-96,AlanRLiss,Inc.,1985)。本发明的抗体还可以通过使用单淋巴细胞抗体方法通过克隆和表达由选择用于产生特异性抗体的单一淋巴细胞产生的免疫球蛋白可变区cDNA来产生,例如通过Babcook,J.等人,1996,Proc.Natl.Acad.Sci.USA93(15):7843-7848l;WO92/02551;WO2004/051268;WO2004/051268和WO2004/106377描述的方法。本发明的抗体还可以使用本领域已知的各种噬菌体展示方法产生,包括由Brinkman等人(在J.Immunol.Methods,1995,182:41-50中),Ames等人(J.Immunol.Methods,1995,184:177-186),Kettleborough等(Eur.J.Immunol.1994,24:952-958),Persic等,(Gene,19971879-18),Burton等(AdvancesinImmunology,1994,57:191-280)和WO90/02809;WO91/10737;WO92/01047;WO92/18619;WO93/11236;WO95/15982;WO95/20401;和美国专利5,698,426;5,223,409;5,403,484;5,580,717;5,427,908;5750753;5821047;5,571,698;5,427,908;5516637;5780225;5,658,727;5,733,743和5,969,108公开的那些。完全人抗体是这样的抗体,其中重链和轻链的可变区和恒定区(如果存在的话)都是人来源的,或者与人来源的序列基本上相同,但不一定来自相同的抗体。完全人抗体的实例可以包括例如通过上述噬菌体展示方法产生的抗体和其中鼠免疫球蛋白可变区和任选地恒定区基因已经被它们的人类对应物替换的小鼠产生的抗体,例如如EP0546073,US5,545,806,US5,569,825,US5,625,126,US5,633,425,US5,661,016,US5,770,429,EP0438474和EP0463151中一般描述的。或者,可通过包括以下步骤的方法产生本发明的抗体:用包含三聚体TNFα和本文公开的化合物的化合物-三聚体复合物的免疫原免疫非人类哺乳动物;从所述哺乳动物获得抗体制剂;其中衍生出选择性识别所述复合物的单克隆抗体,并且仅在所述化合物存在的情况下筛选与TNFα结合的单克隆抗体群。本发明的抗体分子可以包含具有全长重链和轻链或其片段或抗原结合部分的完整抗体分子。术语抗体的“抗原结合部分”是指保留选择性结合抗原的能力的一个或多个抗体片段。已经显示抗体的抗原结合功能可以通过全长抗体的片段进行。抗体及其片段和抗原结合部分可以是但不限于Fab,修饰的Fab,Fab',修饰的Fab',F(ab’)2,Fv,单结构域抗体(例如VH或VL或VHH),scFv,二价、三价或四价抗体,双scFv,双抗体,三抗体,四抗体和以上任一种的表位结合片段(参见例如HolligerandHudson,2005,NatureBiotech.23(9):1126-1136;AdairandLawson,2005,DrugDesignReviews-Online2(3),209-217)。用于产生和制造这些抗体片段的方法是本领域公知的(参见例如Verma等,1998,JournalofImmunologicalMethods,216,165-181)。用于本发明的其它抗体片段包括国际专利申请WO2005/003169,WO2005/003170和WO2005/003171中描述的Fab和Fab'片段以及国际专利申请WO2009/040562中描述的Fab-dAb片段。多价抗体可以包含多种特异性或者可以是单特异性的(参见例如WO92/22853和WO05/113605)。这些抗体片段可以使用本领域技术人员已知的常规技术获得,并且可以以与完整抗体相同的方式筛选片段的效用。如果存在的话,本发明的抗体分子的恒定区结构域可以根据所提出的抗体分子的功能来选择,特别是可能需要的效应功能。例如,恒定区结构域可以是人IgA,IgD,IgE,IgG或IgM结构域。特别地,当抗体分子打算用于治疗用途并且需要抗体效应子功能时,可以使用人IgG恒定区结构域,尤其是IgG1和IgG3同种型。或者,当抗体分子旨在用于治疗目的并且不需要抗体效应子功能时,可以使用IgG2和IgG4同种型。本发明的抗体可以通过重组方法制备、表达、产生或分离,例如(a)从感兴趣免疫球蛋白基因的转基因或转染色体的动物(例如小鼠)分离的抗体或由其制备的杂交瘤,(b)从经转化以表达目标抗体的宿主细胞(例如从转染瘤)分离的抗体,(c)从重组组合抗体文库中分离的抗体,和(d)通过涉及将免疫球蛋白基因序列剪接到其他DNA序列的任何其他手段制备、表达、产生或分离的抗体。本发明的抗体可以是人抗体或人源化抗体。如本文所用,术语“人抗体”旨在包括具有可变区的抗体,其中框架区和CDR区均源自人种系免疫球蛋白序列。此外,如果抗体含有恒定区,恒定区也来自人种系免疫球蛋白序列。本发明的人抗体可以包括不由人种系免疫球蛋白序列编码的氨基酸残基(例如通过体外随机或位点特异性诱变或通过体内体细胞突变引入的突变)。然而,如本文所用,术语“人抗体”不意图包括其中来源于另一哺乳动物物种(例如小鼠)的种系的CDR序列已被移植到人框架序列上的抗体。这样的人抗体可以是人单克隆抗体。这样的人单克隆抗体可以由杂交瘤产生,所述杂交瘤包括从转基因非人动物(例如转基因小鼠)获得的B细胞,所述转基因小鼠具有包含人重链转基因和融合至永生化细胞的轻链转基因的基因组。人抗体可以通过体外免疫人淋巴细胞然后用EB病毒转化淋巴细胞来制备。术语“人抗体衍生物”是指人抗体的任何修饰形式,例如抗体与另一种试剂或抗体的缀合物。术语“人源化抗体”旨在指CDR-移植的抗体分子,其中来源于另一种哺乳动物物种(例如小鼠)的种系的CDR序列已被移植到人框架序列上。可以在人框架序列内进行另外的框架区修饰。如本文所用,术语“CDR移植的抗体分子”是指其中重链和/或轻链含有来自供体抗体(例如鼠或大鼠单克隆抗体)的一个或多个CDR(如果需要,包括一个或多个修饰的CDR)接枝到受体抗体(例如人抗体)的重链和/或轻链可变区框架中的抗体分子。对于综述,参见Vaughan等人,NatureBiotechnology,16,535-539,1998。在一个实施方案中,不是转移整个CDR,而是来自上文所述的任何一个CDR的只有一个或多个特异性决定残基是转移至人抗体框架(参见例如Kashmiri等,2005,Methods,36,25-34)。在一个实施方案中,仅将来自上文所述的一个或多个CDR的特异性决定残基转移至人抗体框架。在另一个实施方案中,仅将本文上述每个CDR的特异性决定残基转移至人抗体框架。当移植CDR或特异性决定残基时,考虑到CDR所来源的供体抗体的种类/类型,可以使用任何合适的受体可变区框架序列,包括小鼠、灵长类动物和人框架区。合适地,根据本发明的CDR移植的抗体具有包含人受体框架区以及上述一个或多个CDR或特异性决定残基的可变结构域。因此,在一个实施方案中提供的是中和CDR-移植抗体,其中可变结构域包含人受体框架区和非人供体CDR。可以用于本发明的人框架的实例是KOL,NEWM,REI,EU,TUR,TEI,LAY和POM(Kabat等,同上)。例如,KOL和NEWM可以用于重链,REI可以用于轻链,EU,LAY和POM可以用于重链和轻链。或者,可以使用人种系序列;这些可在例如http://www.vbase2.org/获得(参见Retter等,Nucl.AcidsRes。(2005)33(增刊1),D671-D674)。在本发明的CDR移植的抗体中,受体重链和轻链不一定需要来源于相同的抗体,并且如果需要,可以包含具有衍生自不同链的框架区的复合链。而且,在本发明的CDR移植抗体中,框架区不需要具有与受体抗体完全相同的序列。例如,不寻常的残基可以被改变为该受体链种类或类型的更频繁出现的残基。或者,可以改变受体框架区中的选定残基,使其对应于在供体抗体的相同位置上发现的残基(参见Reichmann等,1998,Nature,332,323-324)。这种变化应保持在恢复供体抗体亲和力所需的最低限度。在WO91/09967中阐述了用于选择可能需要改变的受体框架区中的残基的方案。本领域技术人员还将理解,抗体可经历多种翻译后修饰。这些修饰的类型和程度通常取决于用于表达抗体的宿主细胞系以及培养条件。这种修饰可以包括糖基化,甲硫氨酸氧化,二酮哌嗪形成,天冬氨酸异构化和天冬酰胺脱酰胺化的变化。常见的修饰是由于羧肽酶的作用而丧失羧基末端碱性残基(如赖氨酸或精氨酸)(如Harris,RJ,JournalofChromatography705:129-134,1995中所述)。在一个实施方案中,抗体重链包含CH1结构域,并且抗体轻链包含CL结构域,κ或λ。生物分子如抗体或片段含有酸性和/或碱性官能团,其中给该分子带来净正电荷或负电荷。总“观察”电荷的量将取决于实体的绝对氨基酸序列,3D结构中带电荷的基团的局部环境以及分子的环境条件。等电点(pI)是特定分子或表面不带净电荷的pH值。在一个实施方案中,根据本公开内容的抗体或片段具有至少7的等电点(pI)。在一个实施方案中,抗体或片段具有至少8的等电点,例如8.5,8.6,8.7,8.8或9。在一个实施方案中,抗体的pI是8。程序例如**ExPASYhttp://www.expasy.ch/tools/pi_tool.html(参见Walker,TheProteomicsProtocolsHandbook,HumanaPress(2005),571-607)可用于预测抗体或片段的等电点。结合本文公开的表位的抗体可以包含SEQIDNOS:4至6(分别为HCDR1/HCDR2/HCDR3)的至少一个,至少两个或全部三个重链CDR序列。这些是实施例的CA185_01974抗体的HCDR1/HCDR2/HCDR3序列。此外,这样的抗体可以包含SEQIDNOS:1至3(分别为LCDR1/LCDR2/LCDR3)的至少一个,至少两个或全部三个轻链CDR序列。这些是实施例的CA185_01974抗体的LCDR1/LCDR2/LCDR3序列。抗体合适地包含至少一个SEQIDNO:6的HCDR3序列。典型地,抗体包含至少一个选自SEQIDNOS:4至6的重链CDR序列和至少一个选自SEQIDNOS1至3的轻链CDR序列。抗体可以包含至少选自SEQIDNOS:4至6的两个重链CDR序列和选自SEQIDNOS:1至3的至少两个轻链CDR序列。抗体通常包含全部三个重链CDR序列SEQIDNOS:4至6(分别为HCDR1/HCDR2/HCDR3)和全部三个轻链CDR序列SEQIDNOS:1至3(分别为LCDR1/LCDR2/LCDR3)。抗体可以是嵌合抗体,人抗体或人源化抗体。抗体还可以包含SEQIDNOS:19至21(分别为HCDR1/HCDR2/HCDR3)的至少一个,至少两个或全部三个重链CDR序列。这些是实施例的CA185_01979抗体的HCDR1/HCDR2/HCDR3序列。抗体通常包含SEQIDNO:21的HCDR3序列。抗体还可以包含SEQIDNO:1、17、18(分别为LCDR1/LCDR2/LCDR3)的至少一个,至少两个或全部三个轻链CDR序列。这些是实施例的CA185_01979抗体的LCDR1/LCDR2/LCDR3序列通常,抗体包含至少一个选自SEQIDNOS:19至21的重链CDR序列和至少一个选自SEQIDNOS:1、17、18的轻链CDR序列。抗体可以包含选自SEQIDNOS:19至21的至少两个重链CDR序列和选自SEQIDNOS:1,17,18的至少两个轻链CDR序列。抗体可以包含全部三个重链CDR序列SEQIDNOS:19至21(分别为HCDR1/HCDR2/HCDR3)和全部三个轻链CDR序列SEQIDNOS:1、17、18(分别为LCDR1/LCDR2/LCDR3)。抗体可以是嵌合抗体,人抗体或人源化抗体。抗体可以包含CA185_01974抗体和CA185_01979抗体的CDR序列的任何组合。特别地,抗体可以包含选自SEQIDNO:4-6和19-21的至少一个HCDR序列和/或选自SEQIDNO:1-3、17和18的至少一个LCDR序列。该抗体可以包含:-选自SEQIDNO:4和19的HCDR1;和/或-选自SEQIDNO:5和20的HCDR2;和/或-选自SEQIDNO:6和21的HCDR3;和/或-SEQIDNO:1的LCDR1;和/或-选自SEQIDNO:2和17的LCDR2;和/或-选自SEQIDNO:3和18的LCDR3。抗体可以包含SEQIDNO:8(CA185_01974的HCVR)的重链可变区(HCVR)序列。抗体可以包含SEQIDNO:7的轻链可变区(LCVR)序列(CA185_01974的LCVR)。抗体适宜地包含SEQIDNO:8的重链可变区序列和SEQIDNO:7的轻链可变区序列。抗体还可以包含SEQIDNO:23(CA185_01979的HCVR)的重链可变区(HCVR)序列。抗体可以包含SEQIDNO:22的轻链可变区(LCVR)序列(CA185_01979的LCVR)。抗体适宜地包含SEQIDNO:23的重链可变区序列和SEQIDNO:22的轻链可变区序列。此外,抗体可以包含来自CA185_01974和CA185_01979抗体的重链和轻链可变区的组合。换句话说,本发明的抗体可以包含SEQIDNO:8或23的重链可变区和/或SEQIDNO:7或22的轻链可变区。抗体可以包含SEQIDNO:12(CA185_01974mIgG1)或13(CA185_01974mFab(无铰链))的重链(H链)序列。抗体可以包含SEQIDNO:11(CA185_01974κ轻链)的轻链(L-链)序列。本发明的抗体通常包含SEQIDNO:12/13的重链序列和SEQIDNO:11的轻链序列。抗体可以是嵌合抗体,人抗体或人源化抗体。抗体可以包含SEQIDNO:27(CA185_01979mIgG1)或28(CA185_01979mFab(无铰链))的重链序列。抗体可以包含SEQIDNO:26(CA185_01979κ轻链)的轻链序列。通常,抗体包含SEQIDNO:27/28的重链序列和SEQIDNO:26的轻链序列。抗体可以是嵌合抗体,人抗体或人源化抗体。同样,来自CA185_01974和CA185_01979的序列可以被组合。所述抗体可以可选地是或可以包含上述特定序列之一的变体。例如,变体可以是任何上述氨基酸序列的取代,缺失或添加变体。变体抗体可以包含1,2,3,4,5,至多10,至多20个或更多个(通常至多最多50个)来自上述特定序列的氨基酸取代和/或缺失。“缺失”变体可以包括个别氨基酸的缺失,小氨基酸组例如2、3、4或5个氨基酸的缺失或者更大氨基酸区域的缺失,例如缺失特定氨基酸结构域或其他特性。“取代”变体通常涉及用相同数目的氨基酸取代一个或多个氨基酸并进行保守氨基酸取代。例如,氨基酸可以用具有相似性质的另一种氨基酸取代,例如另一种碱性氨基酸,另一种酸性氨基酸,另一种中性氨基酸,另一种带电荷的氨基酸,另一种亲水性氨基酸,另一种疏水性氨基酸,另一种极性氨基酸,另一种芳香族氨基酸或另一种脂肪族氨基酸。可用于选择合适取代基的20个主要氨基酸的一些性质如下:“衍生物”或“变体”通常包括其中代替天然存在的氨基酸的序列中出现的氨基酸为其结构类似物的那些。序列中使用的氨基酸也可以被衍生或修饰,例如被标记,前提是抗体的功能没有明显的不利影响。如上所述的衍生物和变体可以在抗体合成过程中或通过后期生产修饰来制备,或者当抗体是重组形式时,采用已知的核酸定点诱变、随机诱变或酶切割和/或连接来制备。变体抗体可具有这样的氨基酸序列,其与本文公开的氨基酸序列(特别是HCVR/LCVR序列和H链和L链序列)具有超过约60%或超过约70%,例如75或80%,通常大于约85%,例如超过约90或95%的氨基酸同一性。此外,所述抗体可以是与本文公开的HCVR/LCVR序列和H链和L链序列具有超过约60%,或超过约70%75或80%,典型地多于约85%,例如超过约90或95%的氨基酸同一性,同时保留针对这些序列公开的确切的CDR的变体。变体可与本文公开的HCVR/LCVR序列和H-和L-链序列具保持至少约90%,91%,92%,93%,94%,95%,96%,97%,98%或99%相同(在某些情况下,同时保留确切的CDR)。变体通常保持约60%至约99%同一性,约80%至约99%同一性,约90%至约99%同一性或约95%至约99%同一性。这种氨基酸同一性水平可以在相关的SEQIDNO序列的全长上或在一部分序列上,例如跨约20,30,50,75,100,150,200或更多个氨基酸,取决于全长多肽的大小。关于氨基酸序列,“序列同一性”是指当使用ClustalW(Thompson等,1994,同上)评估时具有所述值的序列,其中使用以下参数:成对比对参数-方法:准确,矩阵:PAM,空位开放罚分:10.00,空位延伸罚分:0.10;多重比对参数-矩阵:PAM,空位开放罚分:10.00,延迟的同一性百分比:30,惩罚结束间隔:开,间隔距离:0,否定矩阵:否,空位延伸罚分:0.20,残基特异性空位罚分:开,亲水间隙处罚:开,亲水残留物:GPSNDQEKR。特定残基的序列同一性旨在包括已简单衍生化的相同残基。因此,提供了具有维持这些链的功能或活性的特定序列和变体的抗体。本发明还提供了编码本发明抗体分子的重链和/或轻链可变区的分离的DNA序列。SEQIDNO:10的分离的DNA序列编码SEQIDNO:8的重链可变区。SEQIDNO:9的分离的DNA序列编码SEQIDNO:7的轻链可变区。SEQIDNO:25的分离的DNA序列编码SEQIDNO:23的重链可变区。SEQIDNO:24的分离的DNA序列编码SEQIDNO:22的轻链可变区。本发明还提供了编码本发明任何抗体分子的重链和/或轻链的分离的DNA序列。合适地,DNA序列编码本发明抗体分子的重链或轻链。SEQIDNO:15或16的分离的DNA序列分别编码SEQIDNO:12和13的重链。SEQIDNO:14的分离的DNA序列编码SEQIDNO:11的轻链。SEQIDNO:30或31的分离的DNA序列分别编码SEQIDNO:27和28的重链。SEQIDNO:29的分离的DNA序列编码SEQIDNO:26的轻链。可选地,合适的多核苷酸序列可以是这些特定多核苷酸序列之一的变体。例如,变体可以是任何上述核酸序列的取代,缺失或添加变体。变体多核苷酸可以包含在序列表中给出序列的1,2,3,4,5,多达10,多达20,多达30,多达40,多达50,多达75或更多个核酸取代和/或缺失。通常,变体具有1-20,1-50,1-75或1-100个取代和/或缺失。合适的变体可以与本文公开的任何一种核酸序列的多核苷酸至少约70%同源,通常至少约80或90%,更合适的是至少约95%,97%或99%同源。变体可保留至少约90%,91%,92%,93%,94%,95%,96%,97%,98%或99%的同一性。变体通常保持约60%至约99%同一性,约80%至约99%同一性,约90%至约99%同一性或约95%至约99%同一性。在这些水平上的同源性和同一性通常至少在多核苷酸的编码区存在。测量同源性的方法是本领域众所周知的,本领域技术人员将会理解,在本文中,基于核酸同一性来计算同源性。这样的同源性可以存在于至少约15,至少约30,例如至少约40,60,100,200个或更多个连续核苷酸(取决于长度)的区域上。这种同源性可以在未修饰的多核苷酸序列的整个长度上存在。测量多核苷酸同源性或同一性的方法是本领域已知的。例如,UWGCG软件包提供可用于计算同源性的BESTFIT程序(例如,在其默认设置下使用)(Devereuxetal(1984)NucleicAcidsResearch12,p387-395)。PILEUP和BLAST算法也可用于计算同源性或排列顺序(通常在其默认设置下),例如如AltschulS.F.(1993)JMolEvol36:290-300;Altschul,S,F等(1990)JMolBiol215:403-10。进行BLAST分析的软件可以通过国家生物技术信息中心(http://www.ncbi.nlm.nih.gov/)公开获得。该算法涉及首先通过在查询序列中识别长度W的短字来识别高评分序列对(HSP),所述短字在匹配或满足某个正值阈值分数T时与数据库序列中的相同长度的字对齐。T被称为邻近词评分阈值(Altschul等,同上)。这些最初的邻居单词命中作为启动搜索寻找包含它们的HSP的种子。只要累积比对得分可以增加,单词命中就沿每个序列在两个方向上延伸。在以下情况下,针对每个方向的单词命中的扩展被停止:由于一个或多个负评分残基比对的积累,累积比对分数变为零或低于零;或者达到任一序列的结束。BLAST算法参数W,T和X确定比对的灵敏度和速度。BLAST程序使用11的字长(W),BLOSUM62评分矩阵(参见Henikoff和Henikoff(1992)Proc.Natl.Acad.Sci.USA89:10915-10919)的比对(B)50,期望值(E)10,M=5,N=4,以及两条链的比较。BLAST算法对两个序列之间的相似性进行统计分析;参见例如KarlinandAltschul(1993)Proc.Natl.Acad.Sci.USA90:5873-5787。由BLAST算法提供的一种相似性度量是最小总和概率(P(N)),其提供了偶然出现两个核苷酸或氨基酸序列之间的匹配的概率的指示。例如,如果第一序列与第二序列比较的最小总和概率小于约1,典型地小于约0.1,合适地小于约0.01,并且最合适地小于约0.001,则序列被认为与另一序列类似。例如,最小的总和概率可以在约1至约0.001的范围内,通常约0.01至约0.001。同源物可以与相关多核苷酸中的序列差异小于约3,5,10,15,20或更多个突变(其每个可以是取代,缺失或插入)。例如,同源物可以有3-50个突变,通常3-20个突变。这些突变可以在同源物的至少30个,例如至少约40个,60个或100个或更多个连续核苷酸的区域上进行测量。在一个实施方案中,由于遗传密码中的冗余,变体序列可以不同于序列表中给出的特定序列。DNA编码具有4个主要核酸残基(A,T,C和G),并用它们“拼写”三个字母的密码子,代表生物体基因中编码的蛋白质的氨基酸。沿着DNA分子的密码子的线性序列被翻译成由这些基因编码的蛋白质中的氨基酸的线性序列。该密码是高度简并的,具有编码20个天然氨基酸的61个密码子和代表“停止”信号的3个密码子。因此,大多数氨基酸由多于一个密码子编码-实际上有几个由四个或更多个不同的密码子编码。因此,本发明的变体多核苷酸可以编码与本发明的另一种多核苷酸相同的多肽序列,但由于使用不同的密码子来编码相同的氨基酸,所以可能具有不同的核酸序列。本发明的DNA序列可以包含例如通过化学处理产生的合成DNA,cDNA,基因组DNA或其任何组合。编码本发明抗体分子的DNA序列可以通过本领域技术人员熟知的方法获得。例如,编码部分或全部抗体重链和轻链的DNA序列可根据需要从所测定的DNA序列或基于相应的氨基酸序列合成。可以构建载体的一般方法,转染方法和培养方法是本领域技术人员公知的。在这方面,参考“CurrentProtocolsinMolecularBiology”,1999,F.M.Ausubel(编),WileyInterscience,NewYork和TheColdSpringHarborPublishing出版的Maniatis手册。还提供了包含一个或多个克隆或表达载体的宿主细胞,所述克隆或表达载体包含编码本发明抗体的一个或多个DNA序列。任何合适的宿主细胞/载体系统都可用于表达编码本发明抗体分子的DNA序列。可以使用细菌,例如大肠杆菌和其它微生物系统,或者可以使用真核生物,例如哺乳动物宿主细胞表达系统。合适的哺乳动物宿主细胞包括CHO,骨髓瘤或杂交瘤细胞。本发明还提供了生产根据本发明的抗体分子的方法,包括在适合于导致来自编码本发明的抗体分子的DNA的蛋白质表达的条件下培养含有本发明的载体的宿主细胞并分离抗体分子。如本文所述的筛选方法可用于鉴定能够结合化合物-三聚体复合物的合适抗体。因此,可以进行本文所述的筛选方法以测试感兴趣的抗体。可以通过例如标准ELISA或Western印迹来测试本发明的抗体与化合物-三聚体复合物的结合。也可以使用ELISA测定来筛选与靶蛋白质显示出阳性反应性的杂交瘤。还可以通过监测抗体与表达靶蛋白的细胞的结合(例如通过流式细胞术)来确定抗体的结合选择性。因此,本发明的筛选方法可以包括通过进行ELISA或Western印迹或通过流式细胞术来鉴定能够结合化合物-三聚体复合物的抗体的步骤。本发明的抗体选择性(或特异性)识别TNFα三聚体-化合物复合物,即化合物-三聚体复合物内的表位。当抗体或其它化合物以优先或高亲和力与其选择性结合的蛋白质结合但实质上不结合或以低亲和力结合其他蛋白质时,该抗体或其它化合物“选择性结合”或“选择性识别”蛋白质。本发明的抗体对于化合物-三聚体复合物的靶的选择性可以通过确定抗体是否如上所述与其它相关的化合物-三聚体复合物结合或者其是否区分它们来进一步研究。抗体可以特异性地(或选择性地)与包含一个或多个TNF超家族成员的其它三聚体形式的化合物-三聚体复合物结合。例如,抗体可以结合包含TNFα的化合物-三聚体复合物,包含TNFβ的化合物-三聚体复合物和包含CD40L的化合物-三聚体复合物。或者,抗体可以特异性(或选择性地)与仅包含TNFα的化合物-三聚体复合物结合,但不与包含任何其他TNF超家族成员的化合物-三聚体复合物结合。例如,抗体可以结合包含TNFα的化合物-三聚体复合物,但不结合包含TNFβ的化合物-三聚体复合物或包含CD40L的化合物-三聚体复合物。抗体可以特异性地(或选择性地)结合至包含多达2、3、4种或甚至全部TNF超家族成员的化合物-三聚体复合物。通过特异性(或选择性),应该理解,抗体结合感兴趣的化合物-三聚体复合物,对任何其他分子(可能包括TNF超家族三聚体不存在时的测试化合物或没有测试化合物的情况下的TNF超家族成员三聚体)没有显著的交叉反应性。交叉反应性可以通过本文描述的任何合适的方法来评估。如果抗体与其他分子的结合与其结合感兴趣的化合物-三聚体复合物约5%,10%,15%,20%,25%,30%,35%,40%,45%,50%,55%,60%,65%,70%,75%,80%,85%,90%或100%一样强的话,针对化合物-三聚体复合物的抗体与该化合物-三聚体复合物以外的分子的交叉反应性可以被认为是显著的。特异于(或选择性)化合物-三聚体复合物的抗体可以以小于约90%,85%,80%,75%,70%,65%,60%,55%,50%,45%,40%,35%,30%,25%或20%的其结合化合物-三聚体复合物的强度结合另一种分子。优选地,所述抗体以小于约20%,小于约15%,小于约10%或小于约5%,小于约2%或小于约1%的其结合化合物-三聚体复合物的强度结合另一种分子。与(i)不存在所述化合物的情况下TNFα的三聚体形式和/或(ii)TNFα三聚体不存在时的所述化合物相比,所述抗体特异性地(或选择性地)结合化合物-三聚体复合物。抗体与化合物-三聚体复合物结合的速率在本文中称为“缔合”速率“kon-ab”,并且抗体从化合物-三聚体复合物解离的速率在本文中称为“解离”速率或koff-ab。如本文所用,符号“KD-ab”表示抗体对化合物-三聚体复合物的结合亲和力(解离常数)。KD-ab定义为koff-ab/kon-ab。抗体可能具有缓慢的“缔合”速率,其可以通过化合物-三聚体复合物的质谱分析和抗体峰强度以分钟测量。通过在不同的抗体:化合物-三聚体复合物比率下重复该测量,可以估计抗体的KD-ab值。相对于在不存在化合物的情况下抗体结合三聚体TNF超家族成员的KD-ab值和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物结合的KD-ab值,抗体与化合物-三聚体复合物结合的KD-ab值可以是至少约1.5倍,2倍,3倍,4倍,5倍,10倍,20倍,30倍,40倍,50倍,60倍,70倍,80倍,90倍,100倍,200倍,300倍或400倍或更低。抗体结合化合物-三聚体复合物的KD-ab值可以降低在不存在测试化合物的情况下与TNF超家族受体结合的TNF超家族三聚体的KD-ab值的至少约10倍,至少约100倍,至少约200倍,至少约300倍,即与不存在所述化合物时所述抗体对所述三聚体TNF超家族成员的结合亲和力和/或不存在三聚体TNF超家族成员时所述抗体与所述化合物的结合亲和力相比,抗体对化合物-三聚体复合物的结合亲和力通常增加至少约10倍,合适地至少约100倍,更适合至少约200倍,最合适地至少约300倍。结合亲和力可以以结合亲和力(KD-ab)的形式给出,并且可以以任何合适的单位给出,例如μM,nM或pM。KD-ab值越小,抗体与化合物-三聚体复合物的结合亲和力越大。相对于在不存在所述化合物时抗体与三聚体TNF超家族成员结合的KD-ab值和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物结合的KD-ab值,抗体与化合物-三聚体复合物结合的KD-ab值可以是至少约1.5倍,2倍,3倍,4倍,5倍,10倍,20倍,30倍,40倍,50倍,60倍,70倍,80倍,90倍,100倍或甚至更低。相对于在不存在所述化合物时抗体与三聚体TNF超家族成员结合的KD-ab值和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物结合的KD-ab值,所述抗体与所述化合物三聚体复合物结合的KD-ab值的降低可以是由于与不存在所述化合物时抗体与三聚体TNF超家族成员结合和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物结合相比,与化合物-三聚体复合物结合的抗体的缔合速率(kon-ab)的增加,和/或与不存在所述化合物时抗体与三聚体TNF超家族成员结合和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物结合相比,解离速率(koff-ab)的降低。结合于化合物-三聚体复合物的抗体的缔合速率(kon-ab)通常相较于不存在所述化合物时抗体与三聚体TNF超家族成员结合的缔合速率和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物结合的缔合速率增加。结合于化合物-三聚体复合物的抗体的解离速率(koff-ab)通常相较于不存在所述化合物时抗体与三聚体TNF超家族成员结合的解离速率和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物结合的解离速率降低。最典型地,相较于不存在所述化合物时抗体与三聚体TNF超家族成员的结合和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物的结合,与化合物-三聚体复合物结合的抗体的缔合速率(kon-ab)增加,与化合物-三聚体复合物结合的抗体的解离速率(koff-ab)降低。相较于不存在所述化合物时抗体与三聚体TNF超家族成员的结合和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物的结合的kon-ab值,与化合物-三聚体复合物结合的抗体的kon-ab值可以增加至少约1.5倍或至少两倍并且典型地至少约三倍,和/或相较于不存在所述化合物时抗体与三聚体TNF超家族成员的结合和/或在不存在三聚体TNF超家族成员的情况下抗体与化合物的结合的koff-ab值,与化合物-三聚体复合物结合的抗体的koff-ab值可以减少至少约2倍,至少约10倍,至少约20倍,至少约30倍,至少约40倍,至少约50倍,至少约60倍,至少约70倍,至少约80倍,合适地至少约90倍。kon-ab,koff-ab和KD-ab值可以使用任何适当的技术来确定,例如表面等离子体共振,质谱和等温量热法。结合化合物-三聚体复合物的抗体的KD-ab值可以是1nM,900pM,700pM,500pM,100pM,10pM或更低(通常低至约1pM)。本发明的抗体将理想地以高亲和力(例如在皮摩尔范围内)与本发明的化合物-三聚体复合物结合。与化合物-三聚体复合物结合的抗体的KD-ab值可以是1nM或更少,900pM或更少,700pM或更少,500pM或更少,400pM或更少,300pM或更少,200pM或更少100pM或更少,90pM或更少,80pM或更少,70pM或更少,60pM或更少,50pM或更少,40pM或更少,30pM或更少,20pM或更少,10pM或更少更少(再次,下降到约1pM)。一旦鉴定并选择了合适的抗体,可以通过本领域已知的方法鉴定抗体的氨基酸序列。编码抗体的基因可以使用简并引物进行克隆。抗体可以通过常规方法重组生产。根据H链/L链,HCVR/LCVR或CDR序列,抗体可与根据H链/L链、HCVR/LCVR或CDR序列定义的抗体竞争结合TNFα,或结合与之相同的表位。特别地,抗体可以与包含SEQIDNO:4/5/6/1/2/3或SEQIDNO:19/20/21/1/17/18的HCDR1/HCDR2/HCDR3/LCDR1/LCDR2/LCDR3序列组合的抗体竞争与TNFα的结合,或结合相同的表位。抗体可以与包含SEQIDNO:8/7或SEQIDNO:23/22的HCVR和LCVR序列对的抗体竞争与TNFα的结合,或与相同的表位结合。术语“表位”是被抗体结合的抗原的区域。表位可以被定义为结构或功能。功能表位通常是结构表位的子集,并具有直接有助于相互作用亲和力的那些残基。表位也可以是构象的,即由非线性氨基酸组成。在某些实施方案中,表位可以包括决定簇,所述决定簇是分子的化学活性表面基团,例如氨基酸,糖侧链,磷酰基或磺酰基,并且在某些实施方案中,可以具有特定的三维结构特征,和/或具体的电荷特征。通过使用本领域已知的常规方法,人们可以容易地确定抗体是否与参考抗体结合相同的表位或与参考抗体竞争结合。例如,为了确定测试抗体是否与本发明的参考抗体结合相同的表位,允许参考抗体在饱和条件下与蛋白质或肽结合。接下来,评估测试抗体结合蛋白质或肽的能力。如果测试抗体能够在与参考抗体饱和结合后与蛋白质或肽结合,则可以推断测试抗体与参考抗体结合不同的表位。另一方面,如果测试抗体在与参考抗体饱和结合后不能结合蛋白质或肽,那么测试抗体可以与本发明参照抗体结合的表位结合相同的表位。为了确定抗体是否与参考抗体竞争结合,上述结合方法在两个方向上进行。在第一方向,允许参考抗体在饱和条件下与蛋白质/肽结合,然后评估测试抗体与蛋白质/肽分子的结合。在第二方向上,使测试抗体在饱和条件下与蛋白质/肽结合,接着评估参考抗体与蛋白质/肽的结合。如果在两个方向上只有第一个(饱和的)抗体能够与蛋白质/肽结合,则推断测试抗体和参考抗体竞争结合蛋白质/肽。如本领域技术人员将理解的,与参考抗体竞争结合的抗体可能不一定与参考抗体结合相同的表位,但是可以通过结合重叠或相邻表位来空间阻断参考抗体的结合。如果两种抗体竞争性抑制(阻断)另一种与抗原的结合,则两种抗体结合相同或重叠的表位。也就是说,如在竞争性结合测定中所测量的,1倍,5倍,10倍,20倍或100倍过量的一种抗体抑制另一种抗体的结合至少50%,75%,90%或甚至99%(参见例如Junghans等,CancerRes,1990:50:1495-1502)。或者,如果基本上抗原中降低或消除一种抗体的结合的所有氨基酸突变减少或消除另一种抗体的结合,则两种抗体具有相同的表位。如果一些降低或消除一种抗体结合的氨基酸突变降低或消除另一种抗体的结合,则两种抗体具有重叠的表位。然后可进行额外的常规实验(例如肽突变和结合分析)以确认观察到的测试抗体的结合缺乏是否实际上是由于与参考抗体结合相同的表位,或者如果空间阻断(或另一种现象)是造成缺乏观察结合的原因。可以使用ELISA,RIA,表面等离子体共振,流式细胞术或本领域可用的任何其他定量或定性抗体结合测定来进行这种实验。本发明的抗体与包含选自L94,P113和Y115的至少一个残基的表位结合,其中残基编号对应于SEQIDNO:36的TNFα。如下文进一步讨论的,SEQIDNO:36表示人可溶性TNFα的序列。尽管为人可溶性TNFα的特定序列提供了这些残基,但是本领域技术人员可以使用常规技术将这些残基的位置可读地外推至其他TNFα序列(小鼠或大鼠)。因此,本发明还提供了与包含这些其他TNF序列内的相应残基的表位结合的抗体。如在实施例中进一步讨论的,在不存在化合物的情况下,上述鉴定的残基在TNFα三聚体内隐藏(和不可接近)。然而,当TNF三聚体与本文公开的化合物结合时,这些残基在三聚体的扭曲构象内变得可接近。因此,结合包含L94,P113和/或Y115的表位的本发明抗体将识别三聚体(其调节TNF信号传导)的扭曲构象,而不识别三聚体在不存在化合物时的正常构象。本发明的抗体通常识别(结合)三聚体TNFα中的表位。本发明的抗体可以结合包含两个或更多个选自L94,P113和Y115的残基的表位,其中L94存在于TNFα三聚体的A链上并且P113和Y115存在于TNFα三聚体的C链上。本发明的抗体可结合包含L94,P113和Y115全部三种的表位,其中L94存在于TNFα三聚体的A链上,并且P113和Y115存在于TNFα三聚体的C链上。“A”和“C”链是指组成TNF三聚体的第一和第三单体。因此,本发明的抗体通常识别跨越TNF三聚体的两个单体的构象表位。更详细地,当从侧面观察TNFα三聚体的晶体结构时,其大致形状如金字塔/锥体。当你向下看三聚体轴,单体末端的N-和C-末端指向你,那么你正在看三聚体的“肥”端。在具有化合物的扭曲结构中,裂缝在A和C亚基之间开放,不受理论束缚,在其中结合本发明的Ab。哪一条链是A,B或C可以通过测量三个相同残基的三个C-α原子之间的三个距离来确定-例如,每个链中的P117(G121也是合适的)。三个距离形成一个三角形,在apo-TNF中是等边的,但是当化合物结合时是扭曲的。最短的距离是BC与AC之间最长的距离(例如从而通过N/C末端指向您的分子轴向下看,最长的距离定义C,然后A链逆时针旋转,然后B和C再次逆时针旋转。本发明的抗体可以与另外包含SEQIDNO:36的TNFα的任何以下残基的表位结合:T77(A链);T79(A链);Y87(A链);T89(A链);K90(A链);V91(A链);N92(A链);L93(A链);S95(A链);A96(A链);I97(A链);E135(A链);I136(A链),R138(A链),L63(C链);D143(C链);F144(C链);S147(C链);Q149(C链)。同样,这些残基可以外推到其他TNFα序列。本发明的抗体可以结合包含T77,T79,Y87,T89,K90,V91,N92,L93,S95,A96,I97,E135,I136和R138全部的表位,所述残基存在于TNFα三聚体的A链。本发明的抗体还可以结合包含存在于TNFα三聚体的C链上的所有L63,D143,F144,S147和Q149的表位。特别地,本发明的抗体可以结合包含存在于TNFα三聚体的A链上的T77,T79,Y87,T89,K90,V91,N92,L93,S95,A96,I97,E135,I136和R138中的全部的表位,以及存在于TNFα三聚体的C链上的L63,D143,F144,S147和Q149。此外,所述抗体可以与另外包含SEQIDNO:36的任何以下TNFα残基的表位结合:L75(A链),S81(A链),R82(A链);I83(A链);I97(A链);D140(A链);P20(C链);F64(C链)和K65(C链)。再次,这些残基可以外推到其他TNFα序列。因此,本发明的抗体可以与包含T77,T79,Y87,T89,K90,V91,N92,L93,S95,A96,I97,E135,I136,R138,L75,S81,R82,I83,I97和D140的全部的表位结合,所述残基存在于TNFα三聚体的A链上。同样地,本发明的抗体可以结合包含的L63,D143,F144,S147,Q149,P20,F64和K65的全部的表位,所述残基存在于TNFα三聚体C链上。本发明的抗体可以结合包含存在于TNFα三聚体的A链上的T77,T79,Y87,T89,K90,V91,N92,L93,S95,A96,I97,E135,I136,R138,L75,S81,R82,I83,I97和D140的全部和存在于TNFα三聚体的C链上的L63,D143,F144,S147,Q149,P20,F64和K65的表位。为了筛选结合特定表位的抗体,可以进行例如Antibodies,Harlow和Lane(ColdSpringHarborPress,ColdSpringHarb。,NY)中所述的常规交叉阻断测定。其他方法包括丙氨酸扫描突变体,肽印迹(Reineke(2004)MethodsMolBiol248:443-63)或肽切割分析。另外,可以使用抗原的表位切除,表位提取和化学修饰等方法(Tomer(2000)ProteinScience9:487-496)。这样的方法在本领域中是公知的。抗体表位也可以通过X射线晶体学分析来确定。因此可以通过与TNFα三聚体结合的抗体的X-射线晶体学分析来评估本发明的抗体。特别地,可以通过确定抗体互补位残基之内的TNFα上的残基来以这种方式鉴定表位。本发明的抗体还可以与结合包含上述TNFα残基的表位的抗体竞争。以上讨论了鉴定这种抗体的方法。本发明的抗体可用于鉴定本文所述的本发明化合物。本发明的抗体也可以用作靶接合生物标志物。靶接合生物标志物可用于检测接合,即配体与感兴趣的靶的结合。在本案中,本发明的抗体仅结合本发明化合物与三聚体TNFα的复合物。因此,如果本发明的抗体能够与化合物-三聚体复合物结合,则证明配体(化合物)已经结合靶(TNFα三聚体)。如本文所述,可以修饰本发明的抗体以添加可检测标记。因此,可以使用这样的抗体检测本发明的化合物与靶TNFα的接合。使用本发明的抗体作为靶接合生物标志物可能在临床或临床前环境中有用,其中样品可以取自根据本发明治疗的受试者。从受试者获得的样品可以用本发明的抗体处理,以确定用于治疗受试者的化合物是否已经结合到靶TNFα。从受试者获得的样品可以是任何合适的组织或流体,例如血液,血浆或尿液。受试者可以是哺乳动物,通常是人。因此,本发明提供了本发明的抗体作为靶接合生物标志物用于检测包含三聚体TNFα和能够结合三聚体TNFα的化合物的化合物-三聚体复合物的用途,其中化合物-三聚体复合物结合必需的TNFα受体,并调节从受试者获得的样品中三聚体通过受体诱导的信号传导。调节合适地是TNFR1信号传导的拮抗作用。类似地,本发明提供了检测化合物与三聚体TNFα的靶接合的方法,其中化合物-三聚体复合物结合必需的受体并调节三聚体通过受体诱导的信号传导,所述方法包括:(a)从施用所述化合物的受试者获得样品;(b)使本发明的抗体与所述样品和对照样品接触,其中所述抗体是可检测的;(c)确定所述可检测抗体与所述样品和所述对照样品的结合量,其中所述可检测抗体与所述样品的结合大于所述可检测抗体与所述对照样品的结合指示所述化合物与所述三聚体TNFα的靶接合。检测抗体和测量抗体与靶结合的量的方法在本领域中是公知的。通常,抗体可以被标记。这种标记包括酶,生物素/链霉抗生物素蛋白,荧光蛋白和荧光染料。例如,可以通过免疫测定法来测量抗体与靶的结合。免疫分析包括Western印迹,ELISA,免疫荧光,免疫组织化学和流式细胞术。可以使用任何适当的技术来测量抗体与TNFα的结合。在上述方法中,将可检测抗体与已施用化合物的受试者的样品的结合与抗体与对照样品的结合进行比较。对照样品可以是任何适当的样品。对照样品通常是“阴性对照”,其代表在不存在所述化合物的情况下抗体与三聚体TNFα的结合。例如,可以在施用化合物之前从患者获得样品。对照还可以基于先前确定的测量,例如,没有化合物的来自不同受试者的多个样品中。可以使用约5、10、20、50或100个受试者的测量值来确定对照值。对照可以是平均值,或者是获得的所有值的范围。实验条件例如来自施用化合物的受试者的样品和对照样品的检测方法相同。在这两种情况下抗体也是相同的。与抗体与对照样品的结合相比,可检测抗体对来自施用化合物的患者的样品的更高的结合(增加的结合)表明化合物与三聚体TNF超家族成员的靶接合。换句话说,相对于对照来说,来自施用化合物的患者的样品的等同或较低结合(降低的结合)表明所述化合物没有靶接合。换句话说,两个量没有显著差异表示没有靶接合。技术人员可以容易地确定何时相对于对照存在增加的结合。例如,当对照是数据范围时,可以基于数据的扩展,对照数据与检测到的样本中抗体的检测结合之间的差异以及计算的置信度来确定靶接合。当检测到的样品的结合高于在任何阴性对照中检测到的结合的最大量时,也可能识别靶接合。如果抗体的结合相对于对照范围的最高量增加约30%或更多,则可以检测靶接合。如果抗体的结合相对于对照范围增加约40%或更多,或约50%或更多,则也可以检测靶接合。当对照是平均值时,这同样适用,或者在施用化合物之前基于来自患者的样品的单一值。相对于对照百分比的增加当然没有上限。本发明的抗体可用于筛选在三聚体TNFα中引发构象变化的化合物,其中所述构象变化在三聚体TNFα结合时调节必需的TNFα受体的信号传导。调节合适地是TNFR1信号传导的拮抗作用。本发明的抗体可用于治疗和/或预防病理状态。因此,提供了用于在人体或动物体上实施的治疗方法中使用的本发明的抗体。本发明还提供了包括将本发明的抗体施用于受试者的治疗方法。本发明的抗体可以用于本文所述的任何治疗适应症和/或药物组合物中。抗体测定如本文所述,本发明提供了相对于其单独与化合物的结合或在不存在所述化合物的情况下与TNFα的结合选择性结合本文所述的至少一种化合物-三聚体复合物的抗体。这些抗体可用于鉴定具有相同性质的其他化合物或化合物种类。使用本文所述的标准技术可以产生针对TNFα的单克隆抗体。然后可以筛选这些抗TNFα抗体的结合本发明的化合物-三聚体复合物的抗体,或针对与TNFα的结合被本文所述的化合物抑制的单克隆抗体。或者,可以针对特定的TNFα三聚体化合物复合物产生单克隆抗体。然后可以筛选这些抗体中的单克隆抗体,该单克隆抗体相对于其在不存在该化合物的情况下与TNFα的结合在存在化合物的情况下选择性地结合TNF超家族成员。一旦产生了相对于其单独与化合物的结合或在不存在所述化合物的情况下与TNFα的结合选择性结合本发明的至少一种化合物-三聚体复合物的抗体,其可以用于筛选其它化合物具有与测试化合物相同的活性。因此,本发明提供了用于鉴定本发明化合物的测定法,其包括以下步骤:a)进行结合测定以测量测试化合物-三聚体复合物与本发明的抗体的结合亲和力;b)将步骤(a)中测量的结合亲和力与已知以高亲和力结合步骤(a)中提及的抗体的不同化合物-三聚体复合物的结合亲和力比较;和c)如果根据步骤(b)中提到的比较考虑其测量的结合亲和力是可接受的,则选择存在于步骤(a)的化合物-三聚体复合物中的化合物。可以理解,上述步骤(b)中提到的“不同的”化合物-三聚体复合物通常是含有与步骤(a)的化合物-三聚体复合物相同的TNFα三聚体的复合物,但是是不同的化合物。该化合物可以是化合物(1)-(7)中的任何一种。步骤(c)中的“可接受”是指步骤(a)中所述的化合物-三聚体复合物的结合亲和力与步骤(b)中所述的不同化合物-三聚体复合物的结合亲和力大致相当。所述抗体与所述复合物的选择性结合通常相对于所述抗体在不存在所述化合物时与所述TNFα的结合或相对于所述抗体在所述TNFα不存在时与化合物的结合来测量。步骤(a)中涉及的化合物-三聚体复合物的结合亲和力通常优于步骤(b)中涉及的不同化合物-三聚体复合物的结合亲和力。适当地,步骤(a)中涉及的化合物-三聚体复合物的结合亲和力相对于步骤(b)中涉及的不同化合物-三聚体复合物的结合亲和力将在10倍,20倍,50倍,100倍,200倍或500倍的范围内。可以使用本发明的抗体来测定化合物文库。文库化合物可以在存在和不存在TNFα的情况下与所述抗体一起温育。仅在TNFα和化合物两者存在下形成与本发明的抗体结合的化合物-三聚体复合物的一部分的化合物可能是具有与本文所述化合物相同活性的候选物。然后可以使用本文公开的测定来验证测试化合物是否是如本文所述的化合物。本发明的一种或多种抗体可以用于测定中。能够结合本发明的任何化合物与特定的TNFα的复合物的通用抗体可以用于本发明的抗体测定中。在本发明的抗体测定中可以使用对不同化合物-三聚体复合物特异的本发明的多种抗体的组。抗体组可以包括至少5个,至少10个,至少15个,至少20个,至少30个,至少40个或至少50个抗体(例如至多75个抗体)。本发明的抗体测定可以是能够在短时间内筛选大量测试化合物以鉴定本发明化合物的高通量测定。TNFα及其受体可以纯化或以混合物存在,例如在培养细胞,组织样品,体液或培养基中。可以开发定性或定量分析,后者可用于确定测试化合物对TNFα的三聚体形式的结合参数(亲和常数和动力学),以及化合物-三聚体复合物的结合参数到必需的TNF受体。包含TNFα和化合物的样品可以进一步包含去稳定剂。去稳定剂(也称为离液剂)包括低摩尔浓度(例如1M)尿素,胍或乙腈,这些试剂的高浓度(例如6M或更高)将导致TNFα三聚体的完全解离和组成性TNFα单体亚基的解折叠。去稳定剂可以是DMSO,通常浓度为5%,10%或更高。测试化合物可以具有上面讨论的任何/全部性质。肿瘤坏死因子超家族及其受体目前已知有22种TNF超家族成员:TNFα(TNFSF1A),TNFβ(TNFSF1B),CD40L(TNFSF5),BAFF(TNFSF13B/BlyS),APRIL(TNFSF13),OX40L(TNFSF4),RANKL(TNFSF11/TRANCE),TWEAK(TNFSF12),TRAIL(TNFSF10),TL1A(TNFSF15),LIGHT(TNFSF14),淋巴毒素,淋巴毒素β(TNFSF3),4-1BBL(TNFSF9),CD27L(TNFSF7),CD30L(TNFSF8),EDA(外胚叶发育不全),EDA-A1(外胚叶发育不全A1),EDA-A2(外胚叶发育不全A2),FASL(TNFSF6),NGF和GITRL(TNFSF18)。在本发明中,TNF超家族成员是TNFα。TNFα以可溶性(TNFαs)和膜结合形式(TNFαm)存在。当本文提到TNFα时,这包括TNFαs和TNFαm两种形式。TNFα通常以TNFαs形式存在。TNFαs可以包含SEQIDNO:35或SEQIDNO:36的序列或其变体(如上所述)。本发明的测定可用于鉴定TNFα的调节剂。具体而言,本发明的测定法可用于鉴定与TNFα结合的化合物,特别是与TNFα的三聚体形式结合的化合物,并使这些三聚体稳定在能够结合所需TNF受体的构象中,其通过所述受体调节信号传导。TNFα可以是TNFαs。本文所述的化合物可以是至少TNFα调节剂。TNFα通常是TNFαs。本发明的化合物-三聚体复合物包括TNFα的三聚体形式。TNFα通常是TNFαs。TNF超家族的成员结合并启动通过TNF受体的信号传导。目前已知有34种TNF受体:4-1BB(TNFRSF9/CD137),NGFR(TNFRSF16),BAFFR(TNFRSF13C),骨保护素(TNFRSF11B),BCMA(TNFRSF17),OX40(TNFRSF4),CD27(TNFRSF7),RANK(TNFRSF11A),CD30(TNFRSF8),RELT(TNFRSF19L),CD40(TNFRSF5),TACI(TNFRSF13B),DcR3(TNFRSF6B),TNFRH3(TNFRSF26),DcTRAILR1(TNFRSF23),DcTRAILR2(TNFRSF22),TNF-R1(TNFRSF1A),TNF-R2(TNFRSF1B),DR3(TNFRSF25),TRAILR1(TNFRSF10A),DR6(TNFRSF21),TRAILR2(TNFRSF10B),EDAR,TRAILR3(TNFRSF10C),Fas(TNFRSF6/CD95),TRAILR4(TNFRSF10D),GITR(TNFRSF18),TROY(TNFRSF19),HVEM(TNFRSF14),TWEAKR(TNFRSF12A),TRAMP(TNFRSF25),淋巴毒素βR(TNFRSF3)和XEDAR。TNF受体合适的是TNF-R1(TNFR1)或TNF-R2(TNFR2)。当在此涉及TNF-R时,这包括TNF-R1和TNF-R2,包括TNF-R1和TNF-R2的细胞外结构域(ECD)。本发明的测定可用于鉴定通过任何必需的TNF受体调节TNFα的信号转导的化合物。本发明的测定可用于鉴定通过TNF-R1或TNF-R2调节TNFα的信号传导的化合物。TNF超家族成员可以是TNFα,TNF受体可以是TNF-R1。特别地,TNF超家族成员可以是TNFαs,TNF受体可以是TNF-R1。本发明的测定可用于鉴定通过TNF-R1特异性调节TNFα的信号发挥作用的化合物。具体而言,这些化合物可以通过TNF-R1调节TNFα的信号传导而起作用,但对通过TNF-R2的TNFα的信号传导没有影响。治疗适应症TNFα是TNF超家族的原型成员。TNFα是介导免疫调节和炎症反应的多效细胞因子。在体内,已知TNFα参与对细菌、寄生虫和病毒感染的应答。具体而言,已知TNFα在类风湿性关节炎(RA),炎症性肠病(包括克罗恩氏病),牛皮癣,阿尔茨海默病(AD),帕金森病(PD),疼痛,癫痫,骨质疏松症,哮喘,脓毒症,发热,系统性红斑狼疮(SLE)和多发性硬化症(MS)和癌症中起作用。也已知TNFα在肌萎缩侧索硬化(ALS),缺血性中风,免疫复合物介导的肾小球肾炎,狼疮性肾炎(LN),抗中性粒细胞胞质抗体(ANCA-)相关肾小球肾炎,微小病变,糖尿病性肾病(DN),急性肾损伤(AKI),梗阻性尿路病,肾同种异体移植排斥,顺铂诱导的AKI和梗阻性尿路疾病。已知TNF超家族的其他成员涉及自身免疫性疾病和免疫缺陷。特别是已知TNF超家族成员参与RA,SLE,癌症,MS,哮喘,鼻炎,骨质疏松症和多发性骨髓瘤(MM)。已知TL1A在器官移植排斥中发挥作用。本文描述的化合物可用于治疗、预防或改善可由常规TNF超家族成员调节剂治疗、预防或改善的任何疾病。化合物可以单独使用或与常规的TNF超家族成员调节剂组合使用。原则上,根据本发明可以治疗、预防或改善部分或全部由TNF超家族成员通过TNF受体的致病性信号传导或通过TNF超家族成员通过TNF受体的信号传导缺陷导致的任何病症。TNF超家族成员通过TNF受体的致病信号传导包括超过正常生理水平的信号传导的通过TNF受体的信号传导增加,正常启动的通过TNF受体的信号传导但不响应正常的生理信号而停止,和处于正常生理范围内但是由非生理手段启动的通过TNF受体的信号传导。本发明涉及治疗,预防或改善由TNFα介导或影响的病症。与TNFα相互作用的化合物因此有益于治疗和/或预防各种人类疾病。这些包括自身免疫和炎性疾病;神经和神经退行性疾病;疼痛和伤害性疾病;和心血管疾病。炎性和自身免疫性疾病包括全身性自身免疫性疾病,自身免疫性内分泌疾病和器官特异性自身免疫性疾病。系统性自身免疫病症包括系统性红斑狼疮(SLE),牛皮癣,血管炎,多肌炎,硬皮病,多发性硬化症,强直性脊柱炎,类风湿性关节炎和舍格伦综合征。自身免疫性内分泌疾病包括甲状腺炎。器官特异性自身免疫性疾病包括艾迪生病,溶血性或恶性贫血,肾小球性肾炎(包括古德帕斯彻氏综合征),格雷夫斯病,特发性血小板减少性紫癜,胰岛素依赖性糖尿病,青少年糖尿病,葡萄膜炎,炎性肠病(包括克罗恩氏病和溃疡性结肠炎),天疱疮,特应性皮炎,自身免疫性肝炎,原发性胆汁性肝硬化,自身免疫性肺炎,自身免疫性心脏炎,重症肌无力,自发性不育,骨质疏松症,哮喘和肌营养不良(包括杜氏肌营养不良)。神经和神经退行性疾病包括阿尔茨海默病,帕金森病,亨廷顿舞蹈病,中风,肌萎缩性侧索硬化,脊髓损伤,头部创伤,癫痫发作和癫痫。心血管疾病包括血栓形成,心脏肥大,高血压,心脏不规则收缩(例如心力衰竭期间)和性功能障碍(包括勃起功能障碍和女性性功能障碍)。具体而言,化合物可用于治疗或预防炎性病症,CNS病症,免疫病症和自身免疫性疾病,疼痛,骨质疏松症,发热和器官移植排斥。化合物可用于治疗或预防类风湿性关节炎,炎性肠病(包括克罗恩氏病),牛皮癣,阿尔茨海默病,帕金森病,癫痫,哮喘,脓毒病,系统性红斑狼疮,多发性硬化症,哮喘,鼻炎,癌症和骨质疏松症。在化合物可用于治疗或预防类风湿性关节炎(RA),非特异性炎性关节炎,糜烂性骨疾病,软骨炎,软骨退化和/或破坏,幼年炎性关节炎,斯蒂尔病(幼年和/或成人发作),幼年特发性关节炎,少年特发性关节炎(少关节和多关节形式),炎症性肠病(包括克罗恩病,溃疡性结肠炎,不确定结肠炎,囊袋炎),牛皮癣,银屑病性关节炎,强直性脊柱炎,舍格伦氏病,阿尔茨海默氏病(AD),白塞病,帕金森病(PD),肌萎缩侧索硬化症(ALS),缺血性中风,疼痛,癫痫,骨质疏松症,骨质缺乏,慢性病贫血,恶病质,糖尿病,血脂异常,代谢综合征,哮喘,慢性阻塞呼吸道(或肺)疾病,败血症,发热,呼吸窘迫综合征,系统性红斑狼疮(SLE),多发性硬化(MS)免疫复合物介导的肾小球性肾炎,狼疮性肾炎(LN),抗中性粒细胞胞质抗体(ANCA-)相关肾小球肾炎,微小病变,糖尿病性肾病(DN),急性肾损伤(AKI),梗阻性尿路病,肾同种异体移植排斥,顺铂诱导的AKI和梗阻性尿路疾病,眼病(包括糖尿病性视网膜病,糖尿病性黄斑水肿,早产儿视网膜病,年龄相关性黄斑变性,黄斑水肿,增生性和/或非增殖性视网膜病,角膜血管化包括新血管形成,视网膜静脉阻塞,各种形式的葡萄膜炎和角膜炎),甲状腺炎,纤维化疾病包括各种形式的肝纤维化,各种形式的肺纤维化,系统性硬化症,硬皮病,癌症和癌症相关的并发症(包括骨骼并发症,恶病质和贫血)。如上所述,本发明的抗体可以用作靶接合生物标志物以评估用本文所述的化合物或复合物治疗的有效性。在一个实施方案中,取自用本文所述的化合物或复合物治疗的受试者的样品可以与本发明的抗体接触。然后可以使用抗体来确定样品中存在的TNFα-化合物复合物的量。使用抗体确定的复合物的量可能与治疗的有效性有关。例如,本发明的抗体检测得越复杂,治疗越有效。使用抗体确定的复合物的量与治疗的有效性成正比。例如,使用抗体确定的复合物的数量加倍可能表明治疗效果加倍。本发明的抗体可用于使用任何适当的技术来确定化合物-三聚体复合物的量。标准技术在本领域是已知的并且在本文中公开。例如,用本发明的抗体进行ELISA和蛋白质印迹可用于确定化合物-三聚体复合物的量。化合物-三聚体复合物的量可以通过测量化合物-三聚体复合物的质量,化合物-三聚体复合物的浓度和化合物-三聚体复合物的摩尔浓度来确定。这个数额可以用任何适当的单位给出。例如,化合物-三聚体复合物的浓度可以以pg/ml,ng/ml或μg/ml给出。化合物-三聚体复合物的质量可以以pg,ng或μg给出。可以将感兴趣的样品中的化合物-三聚体复合物的量与另一样品如对照样品中的化合物-三聚体复合物的水平比较,如本文所述。在这样的方法中,可以评估化合物-三聚体复合物的实际量,例如样品中化合物-三聚体复合物的质量,摩尔量,浓度或摩尔浓度。可以将化合物-三聚体复合物的量与另一个样品中的量进行比较,而不量化化合物-三聚体复合物的质量,摩尔量,浓度或摩尔浓度。因此,根据本发明的样品中化合物-三聚体复合物的量可以基于比较评估为化合物-三聚体复合物的相对量,例如相对质量,相对摩尔量,相对浓度或相对摩尔浓度在两个或更多的样本之间。药物组合物,剂量和剂量方案本发明的抗体,化合物或复合物可以以药物组合物提供。通常将是无菌的药物组合物通常包括药学上可接受的载体和/或佐剂。本发明的药物组合物可以另外包含药学上可接受的佐剂和/或载体。如本文所用,“药学上可接受的载体”包括生理上相容的任何和所有溶剂,分散介质,包衣,抗细菌剂和抗真菌剂,等渗剂和吸收延迟剂等。载体可适用于肠胃外,例如,静脉内,肌肉内,皮内,眼内,腹膜内,皮下,脊髓或其他肠胃外施用途径,例如通过注射或输注。或者,载体可适用于非肠胃外施用,例如局部施用,表皮施用或粘膜施用途径。载体可以适合于口服施用。取决于施用途径,可以将调节剂包被在材料中以保护化合物免受可使化合物失活的酸和其它自然条件的作用。本发明的药物组合物可以包含一种或多种药学上可接受的盐。“药学上可接受的盐”是指保留母体化合物的所需生物学活性并且不赋予任何不希望的毒理学作用的盐。这种盐的例子包括酸加成盐和碱加成盐。药学上可接受的载体包含水性载体或稀释剂。可以在本发明的药物组合物中使用的合适的含水载体的例子包括水,缓冲水和盐水。其它载体的实例包括乙醇,多元醇(如甘油,丙二醇,聚乙二醇等)及其合适的混合物,植物油如橄榄油,和可注射的有机酯如油酸乙酯。在许多情况下,期望在组合物中包含等渗剂,例如糖,多元醇如甘露醇,山梨糖醇或氯化钠。治疗组合物通常在制造和储存条件下必须是无菌的和稳定的。该组合物可以配制成适合于高药物浓度的溶液,微乳剂,脂质体或其它有序结构。本发明的药物组合物可以包含另外的活性成分。包含本发明的抗体、化合物和/或复合物和使用说明书的试剂盒也在本发明的范围内。试剂盒可以进一步含有一种或多种另外的试剂,如上面讨论的另外的治疗剂或预防剂。可以施用由本发明的方法和/或抗体和本发明的抗体或其制剂或组合物鉴定的化合物用于预防性和/或治疗性治疗。在治疗应用中,将化合物以足以治愈,缓解或部分阻滞病症或其一种或多种症状的量施用于已经患有如上所述的病症或病症的受试者。这种治疗可能导致疾病症状的严重程度降低,或无症状期的频率或持续时间增加。足以实现这一点的量被定义为“治疗有效量”。在预防性应用中,将制剂以足以预防或减少病症或其一种或多种症状的后续影响的量施用于处于如上所述的病症或病症风险的受试者。足以实现这一点的量被定义为“预防有效量”。每个目的的有效量将取决于疾病或受伤的严重程度以及受试者的体重和一般状态。施用对象可以是人类或非人类的动物。术语“非人动物”包括所有脊椎动物,例如哺乳动物和非哺乳动物,如非人灵长类动物,绵羊,狗,猫,马,牛,鸡,两栖动物,爬行动物等。。本发明的化合物或药物组合物可以通过一种或多种施用途径使用本领域已知的多种方法中的一种或多种来施用。如本领域技术人员将理解的,施用的途径和/或模式将取决于期望的结果而变化。本发明化合物或药物组合物的给药途径的例子包括静脉内,肌内,真皮内,眼内,腹膜内,皮下,脊髓或其他肠胃外给药途径,例如通过注射或输注。本文使用的短语“肠胃外施用”是指除肠内和局部施用之外的施用模式,通常通过注射。或者,本发明的化合物或药物组合物可以通过非肠胃外途径给药,例如局部,表皮或粘膜给药途径。本发明的化合物或药物组合物可以用于口服给药。本领域普通技术人员可以确定本发明化合物或药物组合物的合适剂量。本发明药物组合物中活性成分的实际剂量水平可以变化,以获得有效实现对于特定患者,组合物和给药模式的所需治疗反应的活性成分的量,而无需对病人有毒。所选择的剂量水平将取决于各种药代动力学因素,包括所用本发明特定组合物的活性,给药途径,给药时间,所用特定化合物的排泄速率,治疗,与所用特定组合物联合使用的其他药物,化合物和/或材料,所治疗患者的年龄,性别,体重,状况,一般健康状况和既往病史,以及医学领域众所周知的类似因素。合适的剂量可以是例如约0.01μg/kg至约1000mg/kg体重,典型地约0.1μg/kg至约100mg/kg待治疗患者的体重的范围。例如,合适的剂量可以是每天约1μg/kg至约10mg/kg体重或每天约10μg/kg至约5mg/kg体重。可以调整剂量方案以提供最佳的期望响应(例如治疗响应)。例如,可以施用单一剂量,可以随着时间的推移施用几个分开的剂量,或者可以根据治疗情况的紧急情况的指示按比例减少或增加剂量。本文使用的剂量单位形式是指适合作为待治疗对象的单位剂量的物理上分立的单位;每个单位含有预定量的活性化合物,其经计算与所需的药物载体结合产生所需的治疗效果。可以单剂量或多剂量给药。多个剂量可以通过相同或不同的途径和相同或不同的位置施用。或者,剂量可以通过缓释制剂,在这种情况下,需要较少的频率给药。剂量和频率可以根据拮抗剂在患者中的半衰期和期望的治疗持续时间而变化。如上所述,本发明的化合物或药物组合物可以与一种或多种其他治疗剂共同给药。例如,其他药剂可以是镇痛剂,麻醉剂,免疫抑制剂或抗炎剂。两种或更多种药剂的联合给药可以以许多不同的方式实现。两者可以一起施用于单一组合物中,或者可以作为组合疗法的一部分以分开的组合物施用。例如,可以在另一个之前,之后或同时施用。以下实施例说明了本发明。实施例实施例1-化合物的合成WO2013/186229(实施例44)中公开了化合物(1)的合成。WO2013/186229(实施例89)公开了化合物(2)的合成。WO2014/009295(实施例129)中公开了化合物(3)的合成。WO2014/009295(实施例173)中公开了化合物(4)的合成。WO2014/009295(实施例319)中公开了化合物(5)的合成。化合物(6)的合成公开于WO2013/186229(实施例490)中。WO2013/186229(实施例156)公开了化合物(7)的合成。实施例2-抗体衍生物在用苯并咪唑化合物(1)与人TNFα复合的5只SpragueDawley大鼠的免疫之后,将免疫B细胞在96孔板中培养以诱导克隆扩增和抗体分泌(Tickle,S。等,HighthroughputscreeningforhighaffinityantibodiesJournalofLaboratoryAutomation200914:303-307)。在基于均质珠粒的FMAT测定中,筛选培养物上清液中的IgG抗体与人化合物(1)(与50倍摩尔过量)复合的人TNFα的结合。通过使用人TNF受体I-Fc融合蛋白(R&DSystems目录号372-R1-050)的捕获系统将人TNFα(+/-化合物(1))呈递在珠表面(超级抗生物素蛋白包被的BangsBeads,目录号CP01N),与生物素化的抗人Fc(Jackson目录号109-066-098)结合。证明优先结合TNFα-化合物(1)复合物的抗体被称为“构象选择性”,并被用于克隆。使用荧光焦点法(美国专利7993864/欧洲专利EP1570267B1)从阳性孔中鉴定和分离抗原特异性B细胞,通过逆转录(RT)-PCR从单个细胞中回收特异性抗体可变区基因。下面显示了两种代表性抗体CA185_01974和CA185_01979的氨基酸序列,其显示了与人和小鼠TNFα+化合物的构象选择性结合:CA185_01974.0(VR0001837)轻链可变区(LCVR)SEQIDNO:7(加下划线的CDR)DIQMTQSPASLPASPEEIVTITCQASQDIGNWLSWYQQKPGKSPQLLIYGATSLADGVPSRFSASRSGTQYSLKISRLQVEDFGIFYCLQGQSTPYTFGAGTKLELK重链可变区(HCVR)SEQIDNO:8(加下划线的CDR)DVQLVESGGGLVQPGRSLKLSCAASGFTFSAYYMAWVRQAPTKGLEWVASINYDGANTFYRDSVKGRFTVSRDNARSSLYLQMDSLRSEDTATYYCTTEAYGYNSNWFGYWGQGTLVTVSSCA185_01979.0(VR0001842)轻链可变区(LCVR)SEQIDNO:22(加下划线的CDR)DIQMTQSPASLSASLEEIVTITCQASQDIGNWLSWYQQKPGKSPHLLIYGTTSLADGVPSRFSGSRSGTQYSLKISGLQVADIGIYVCLQAYSTPFTFGSGTKLEIK重链可变区(HCVR)SEQIDNO:23(加下划线的CDR)EVHLVESGPGLVKPSQSLSLTCSVTGYSITNSYWDWIRKFPGNKMEWMGYINYSGSTGYNPSLKSRISISRDTSNNQFFLQLNSITTEDTATYYCARGTYGYNAYHFDYWGRGVMVTVSS实施例3-衍生的抗体的潜在表位鉴于在化合物存在的情况下,源于大鼠的抗体结合人和小鼠TNFα的能力,进行大鼠、小鼠和人的氨基酸序列以及TNFα的X射线晶体结构的详细分析以确定是否可能的表位可能被确定。大鼠UniProtP16599(SEQIDNO:32)小鼠UniProtP06804(SEQIDNO:33)人UniProtP01375(SEQIDNO:34)通过大鼠,小鼠和人TNFαUniProt序列的比对和比较,其中大鼠氨基酸序列与人不同以及人和小鼠序列在成熟的切割产物中相同的实例包括N168,I194,F220和A221(来自人序列的残基和编号)。这些残基突出显示在人TNFα(1TNF)的晶体结构上(图1)。这些氨基酸中的任何一种都可能包含在抗体CA185_01974和CA185_01979所靶向的表位中。在将抗体可变区克隆到小鼠IgG和小鼠Fab(非铰链)载体中之后,使用各种与TNFα结合的测试化合物在HPLC,BIAcore,ELISA和基于细胞的分析中证实抗体CA185_01974和CA185_01979的结合的构象选择性性质。在下面的实施例9和10中提供了对CA185_01979的表位的更全面的分析。实施例4-高效液相色谱(HPLC)测定抗体特征小鼠Fab片段的特异性结合使用尺寸排阻色谱法通过与化合物(1)络合的CA185_01974和人TNFα之间的复合物形成来证明。结果显示在图2中。如该图所示,用0.5x摩尔过量的Fab,主要峰对应于结合的Fab和三聚体化合物复合物(尽管存在一个小峰表明存在一些三聚体化合物复合物结合到Fab)。在1.0x摩尔过量的Fab中,存在单独的较高分子量的对应于与三聚体复合物结合的Fab的峰。在Fab的1.5倍和2倍摩尔过量时,存在对应于未结合的Fab的越来越低的分子峰。因此,化学计量确定为1Fab:1TNFα三聚体,过量的Fab以1.5倍和2倍摩尔过量出现。还使用尺寸排阻色谱法研究CA185_01979与化合物(1)络合的人TNFα的结合。结果显示在图3中。对于CA185_01974,化学计量学确定为1Fab:1TNFα三聚体,其中过量的Fab出现在1.5倍和2倍摩尔过量。实施例5-确定抗体特征的BIAcore测定使用BIAcoreT200(GEHealthcare)在25℃下进行表面等离子体共振。通过胺偶联化学将抗鼠Fc(Jackson115-006-071)固定在CM5传感器芯片(GEHealthcare)上,达到个应答单位的捕获水平。使用HBS-EP缓冲液(10mMHEPESpH7.4,0.15MNaCl,3mMEDTA,0.05%(v/v)表面活性剂P20-GEHealthcare)+1%DMSO作为运行缓冲液。使用10μl注射1μg/ml的每种IgG通过固定的抗小鼠Fc来捕获以产生TNFα结合表面。将50nM的人或小鼠TNFα(内部)与2μM化合物在HBS-EP+(1%DMSO)中预温育5小时。将人或小鼠TNFα+/-测试化合物的3分钟注射以30μl/min的流速通过每个捕获的IgG。以10μl/min的流速通过60s注射40mMHClx2和30s5mMNaOH再生表面。按照标准程序,使用T200评估软件(版本1.0)分析双重参考背景扣除的结合曲线。动力学参数由拟合算法确定。下表1和2中显示了在存在和不存在来自两个化学系列的测试化合物的情况下人和小鼠TNFα的动力学结合数据。表1-用人TNFα的BIAcore数据抗体人TNFαka(M-1s-1)kd(s-1)KD(M)CA185_01974+化合物(2)4.2x1053.9x10-59.4x10-11CA185_01974+化合物13.2x1053.8x10-51.2x10-10CA185_01974apo6.6x1041.3x10-31.9x10-8CA185_01979+化合物(2)5.7x1053.3x10-55.8x10-11CA185_01979+化合物(1)4.7x1051.6x10-53.4x10-11CA185_01979apo1.1x1057.1x10-46.7x10-9CA185_01974和CA185_01979均显示对化合物扭曲的人TNFα的>2log选择性结合,具有来自两个化学系列的代表性测试化合物。表2-用小鼠TNFα的BIAcore数据抗体小鼠TNFαka(M-1s-1)kd(s-1)KD(M)CA185_01974+化合物(2)6.7x1044.8x10-57.1x10-10CA185_01974+化合物(1)5.8x1048.8x10-51.5x10-9CA185_01974apo4.2x1044.9x10-31.2x10-7CA185_01979+化合物(2)1.9x1053.5x10-51.9x10-10CA185_01979+化合物(1)1.6x1056.3x10-53.8x10-10CA185_01979apo7.2x1042.0x10-32.7x10-8CA185_01974和CA185_01979均表现出对化合物扭曲的小鼠TNFα的>1.5和>2log的选择性结合,具有来自两个化学系列的代表性测试化合物。实施例6-确定抗体特征的ELISA开发夹心ELISA以测量与本发明化合物结合的TNFα浓度,使用特异性检测与这些化合物复合时的TNFα构象的抗体CA185_01974.0。简而言之,用CA185_01974.0包被微量滴定板以固定与测试化合物复合的TNFα。TNFα在28℃下与50x摩尔过量的测试化合物一起温育过夜。在过夜温育之后,在异嗜性抗体阻断剂存在的情况下,将TNFα系列地稀释在纯化的人血浆中去除内源性TNFα,并加入到包被的平板中。生成的曲线浓度范围为0.78pg/ml-50pg/mlTNFα。使用生物素化的多克隆抗TNFα抗体来检测结合的TNFα,用链霉抗生物素蛋白-过氧化物酶和TMB底物来产生比色信号。使用来自PerkinElmer的ELAST试剂盒作为链霉抗生物素蛋白-过氧化物酶与底物之间的附加步骤,使用酪胺信号扩增来增加测定的灵敏度。还开发了ELISA平行测量总TNFα(与测试化合物复合的游离TNFα+TNFα)。对于该测定,用市售抗TNFα多克隆抗体(InvitrogenAHC3812)代替包被抗体。样品温育时间也增加到3小时。所有其他步骤与构象特异性测定相同。这使得与测试化合物复合的TNFα的量可以计算为总TNFα的比例。图4显示了化合物(3),(4)和(5)的总TNFαELISA结果。在图5中显示了具有CA185_01974.0和化合物(3),(4)和(5)的构象特异性TNFαELISA的结果。在该测定中,ApoTNFα不给出信号,证明了抗体CA185_01974与化合物结合的TNFα。该抗体能够识别来自不同化学系列的各种测试化合物结合的TNFα。实施例7-基于细胞的测定以确定抗体特征还使用人胚胎肾(HEK)JumpIn细胞在用1μg/ml多西环素诱导2.5小时后过度表达TNF-RI的FACS测定中测试重组抗体与化合物扭曲的TNFα的结合。用胰蛋白酶消化HEK细胞,并在培养基中孵育2小时以回收消化的TNFRI水平。将2μg/mL的人TNFα与40μM化合物(1)或0.4%DMSO在37℃预温育1小时。将预孵育混合物在冰上(1:4稀释,终浓度:0.5μg/mL人TNFα+/-10μM化合物(1)或0.1%DMSO)加入到细胞中1小时。洗涤细胞,固定(1.5%PFA),并用1或10μg/mL抗体在冰上染色1小时。(第二抗体:抗小鼠Alexa488),然后分析受体结合的TNFα。如图6所示,用1μg/ml和10μg/ml的CA185_01974和CA185_01979染色的FACS直方图显示抗体仅识别已经与化合物(1)一起温育的TNFα。DMSO对照没有染色。此外,用化合物扭曲的膜结合TNFα证实了CA185_01974和CA185-01979Fab片段的特异性结合。将由于剔除TACE切割位点而过量表达膜TNFα的工程化NS0细胞系与0.001-10μM化合物(1)或0.1%DMSO在37℃温育1小时。将细胞洗涤,固定并在冰上用0.01或0.1μg/ml的抗体Fab片段染色1小时。(第二抗体是JacksonImmunoResearch的抗小鼠Fab-DyeLight488)。用CA185_01974(图7)和CA185_01979Fab片段染色的FACS直方图图表证明抗体仅识别已经与化合物(1)预温育的TNF。DMSO对照没有染色。实施例8-抗体CA185_01974对人TNF-化合物(4)复合物显示出300倍的选择性将化合物(4)与人和食蟹猴TNF孵育并在小鼠全长抗体CA185_01974上滴定以确定准确的亲和力值。实验包括以下对照:(i)人或食蟹猴TNF+DMSO相对于1974;(ii)人或食蟹猴TNF+DMSO相对于无抗体;和(iii)人或食蟹猴TNF+化合物(4)相对于无抗体。每个样品和对照进行一式两份,并在每个重复中使用四个浓度。如图8和9所示,在测定过程中,hTNF+化合物(4)和cTNF+化合物(4)的背景结合增加5-10RU。这在第二个重复中的h/cTNF+化合物(4)与CA185_01974结合的较高响应中可见。在不存在所述化合物(4)的情况下hTNF和cTNF的结合一直非常低。在该测定中,hTNF+DMSO结合小鼠全长IgGCA185_1974_P8的动力学非常类似于之前的单一浓度分析。食蟹猴TNF对小鼠全长IgGCA185_1974_P8的亲和力相似,但动力学不同。表3给出了与CA185_1974_P8结合的每种分析物的动力学。表4给出了CA185_1974_p8的TNF动力学的平均值和倍数差异+/-化合物(4)。图8给出了cTNF+/-化合物(4)的两个重复的传感图。图9给出了hTNF+/-化合物(4)的两个重复的传感图。表3:hTNF和cTNF+/-化合物(4)与CA185_1974_P8抗体的结合动力学表4:CA185_1974_p8的hTNF和cTNF动力学的平均值和倍数差异+/-化合物(4)。实施例9-hTNFα-Fab1979复合物结构可溶形式的人TNFα(VC2043,UniProtP01375)在大肠杆菌中表达为融合蛋白,并具有最终序列:SVRSSSRTPSDKPVAHVVANPQAEGQLQWLNRRANALLANGVELRDNQLVVPSEGLYLIYSQVLFKGQGCPSTHVLLTHTISRIAVSYQTKVNLLSAIKSPCQRETPEGAEAKPWYEPIYLGGVFQLEKGDRLSAEINRPDYLDFAESGQVYFGIIAL(SEQIDNO:35)SEQIDNO:35的起始“S”是克隆人工物,而不是TNF的天然序列的一部分。因此,SEQIDNO:35的残基编号从V开始,即V1,R2,S3等。SEQIDNO:36代表SEQIDNO:35,但没有该初始“S”残基即VRSSSRTPSDKPVAHVVANPQAEGQLQWLNRRANALLANGVELRDNQLVVPSEGLYLIYSQVLFKGQGCPSTHVLLTHTISRIAVSYQTKVNLLSAIKSPCQRETPEGAEAKPWYEPIYLGGVFQLEKGDRLSAEINRPDYLDFAESGQVYFGIIAL(SEQIDNO:36)将细胞在富培养基中在37℃下预培养,加入0.1%阿拉伯糖诱导,并使其在25℃下在载体pEMB54中表达过夜。该载体引入可切割的N端His6Smt标签。将细胞裂解并通过Ni-NTA螯合层析进行纯化。用含有咪唑的缓冲液洗脱融合蛋白,并加入蛋白酶切割。通过减去Ni螯合物层析步骤纯化最终切割的TNFα蛋白质以除去融合标签,并通过尺寸排阻色谱进一步纯化以除去剩余的杂质。通常将最终的TNFα产物浓缩至20.0mg/ml并在液氮中快速冷冻。将纯化的人TNFα(38.6μl,20.4mg/ml,VC2043)直接加入到10mMHEPESpH7.5,150mMNaCl缓冲液中的Fab1979(61.4μl,24.4mg/ml)中。通过在80μl相同的结晶溶液中混合0.5μl的复合物与0.5μl6.4%PEGPEG5000MME,5%tacsimate,0.1MHEPES,pH6.8,通过坐滴蒸气扩散使TNFαFab1979复合物结晶。最初建立后大约2周收集晶体以收集数据。将晶体简单地浸泡在乙二醇中,并直接在液氮中玻璃化以用于数据收集。在高级光子源(APS)上以0.9785的波长收集X射线衍射数据,并记录在RAYONIXMX300CCD检测器上。使用XDS软件包可以减少衍射数据(Kabsch,2010)。通过使用具有四个输入模型的Phaser通过分子置换来解析TNFαFab1979复合物的结构:1)hTNFα-化合物(7)结构的链A;2)Fab1974轻链的残基1-105;3)Fab1974轻链的残基110-214;和4)Fab1974重链的残基1-120。模型被剥夺了配体和水域。使用Coot(Emsley和Cowtan,2004)和Phenix(Afonine,P。等人,2012)的迭代手工建模模型一直持续到R和Rfree收敛。使用Coot和MolProbity验证模型质量(Chen等人,2010)。表1列出了最终的数据处理和细化统计。参考文献:Kabsch,W.2010.XDS.ActaCrystallogr.DBiol.Crystallogr.Feb;66(Pt2):1125-32.PMID:20124692.Emsley,P.andCowtan,K.2004.Coot:model-buildingtoolsformoleculargraphics.ActaCrystallogr.DBiol.Crystallogr.Dec;60(Pt12Pt1):2126-32.PMID:15572765.Afonine,P.etal.2012.Towardsautomatedcrystallographicstructurerefinementwithphenix.refine.ActaCrystallogr.DBiol.Crystallogr.Apr;68(Pt4):352-67.PMID:22505256.Chen,V.etal.2010.MolProbity:all-atomstructurevalidationformacromolecularcrystallography.ActaCrystallogr.DBiol.Crystallogr.Jan;66(Pt1):12-21.PMID:20057044.表1.数据收集和细化统计。细化统计图11显示了与TNFα单体结合的Fab1979的结构(晶体的界限允许这样的结合)。由于取向和空间原因,确定单体与A亚基相当。图12显示了与图11相同的结构,但在计算上用对称三聚体(即在不存在化合物的情况下是未扭曲的三聚体)建模。用这个对称三聚体,三聚体的A链保留了与Fab片段的相互作用。然而,Fab片段和三聚体的C链之间存在空间相互作用。图13也显示了与图11相同的结构,除了在这种情况下,计算上模拟了非对称三聚体(即具有扭曲构象的三聚体)。这种不对称的三聚体结构最初是在化合物(6)的存在下产生的。同样,保留了Fab和三聚体的A链之间的相互作用。然而,与对称三聚体相比,Fab和C链之间不存在空间相互作用。实施例10-表位残基的鉴定程序NCONT(CCP4晶体学套件的一部分)用于在的距离内鉴定Fab1979和TNF单体之间的残基。来自该距离内的残基的TNFα中的任何原子被鉴定为表位。将表位定义为抗原原子在抗体原子的内是本领域常规的(参见例如Andersen等(2006),ProteinScience,15,2258-2567)。以这种方式鉴定的TNFα的A链上的残基是T77,T79,Y87,T89,K90,V91,N92,L93,L94,S95,A96,I97,E135,I136和R138。残基编号基于SEQIDNO:36(缺少“S”克隆制品的可溶性人TNFα序列)。鉴定了在邻近范围内的以下另外的A链残基(也可能形成更宽的表位的一部分):L75,S81,R82,I83,I97和D140。同样,残基编号基于SEQIDNO:36。在程序COOT中使用LSQ方法将化合物结合的TNFα(与化合物(6)结合)的结构覆盖在(TNFα/Fab1979复合物的)TNFαA链上。这使得能够鉴定接近Fab残基的TNFα的亚基C中的残基(图15)。这些也被确定为表位残基。在C链中被鉴定为在以内的残基是L63,P113,Y115,D143,F144,S147,Q149。确定在以内的残留物是P20,F64,K65。在Fab1979复合物的TNFαA亚单位上,与化合物结合的TNFα同时覆盖对称的TNFα(没有结合化合物)的结构。在化合物结合结构的表面上,但是被掩埋(一层深的原子)的残留物通过目测确定,并且被确定为不能结合。在未失活的三聚体(不结合化合物)内不可见的残基,因此不能结合,被鉴定为A链上的L94和C链上的残基P113和Y115。结论已经证明抗体CA185_01974和CA185_01979特异性结合TNFα的化合物扭曲状态(compound-distortedstate),并且将是本发明化合物的有用的靶接合生物标志物。已显示抗体结合TNFα的构象,其由来自不同化学系列的化合物特别稳定。设想这些抗体将成为定义TNFα三聚体的这种和紧密相关的生物学相关构象的标准,所述TNFα三聚体通过比这里描述的更宽范围的化学系列来稳定。基于所显示的数据,如果CA185_01974或CA185_01979抗体在上述BIAcore测定形式中以优于1nM的KD结合,则认为人TNFα三聚体可以稳定在所述的确定的生物相关构型中。实施例11-Ma等人(2014)和Silvian等人(2011)的化合物和复合物具有与本发明不同的特征如Ma等人(2014)JBC289:12457-12466的第12458页所述,为了试图找到在与TNFβ的外表面的相互作用中由TNFR1的环2/结构域2的7个氨基酸的肽所占据的空间的分子,通过虚拟筛选发现C87。Ma等人的C87化合物和来自Silvian等人(2011)ACSChemicalBiology6:636-647的BIO8898化合物由本发明人测试。发现结果概述在Ma等人描述的对于C87的Biacore观察不能重复。没有观察到细胞中TNF特异性抑制的证据。另外,通过对毫摩尔亲和力敏感的质谱,C87未被观察到结合。广泛的晶体学试验仅产生apo-TNF(没有化合物的TNF)。在荧光偏振(FP)测定中,C87在荧光读出的化合物的干扰水平以上没有显示出显著的抑制。测量TNFα的热解链温度稳定性的Thermofluor对于C87显示出小的稳定性。总之,没有证据表明C87结合在三聚体的中心。绝大多数数据表明与TNFα没有直接的相互作用。BIO8898也被发现不与TNFα结合。细胞-TNF诱导的HEKNFκB报告基因测定C87与TNFα预培养1小时,然后加入在NFκB控制下用SEAP稳定转染的HEK-293细胞。为了检测非TNF相关(非目标)活性,还测试了合适的反筛选。将测定孵育过夜,然后测量与对照化合物的100%阻断相比的抑制。最大C87浓度是10,000nM,连续稀释3倍。没有检测到不能归因于脱靶活性的抑制作用。Biacore使用avi-标签接头固定TNF,并将C87通过芯片。在一个实验中,进行了来自最高浓度10μM的C87的剂量响应。没有观察到结合。在第二个实验中,C87通过芯片的流速降低了。观察到一个小的转变,但整体结合可以忽略不计。Ma等人描述的C87与TNF的结合很可能是基于Y轴上RU值的超化学计量。在芯片上的标准TNF密度下,该值比单纯1:1结合的预期值高出三十倍。在另一个实验中,BIO8898在Biacore4000机器上通过SPR针对固定的可溶形式的CD40L和可溶形式的TNFα进行了测试。测定了与CD40L的结合的17μM的几何IC50,而在该测定中,在浓度高达100μM的TNFα下未检测到结合。质谱在400μM的浓度下没有C87与人TNFα(20μM)结合的证据。一种较低分子量的物质(约473Da似乎在低于5%的占有率时结合)。C87具有503Da的分子量。基于400μM浓度的占有率,预测低分子量物质超过1mM的亲和力。结晶学总的来说,将大量努力用于使TNFα与C87结晶,包括常规使用本申请中描述的化合物的测试条件。这包括在不同配体浓度,不同蛋白质浓度和不同浸泡时间下进行大量结晶试验。观察到一些晶体,经分析证明是盐或TNF,没有化合物。荧光偏振(FP)在针对荧光化合物(探针)进行测定之前,C87与TNFα预孵育1小时。通过FP的降低来检测与荧光化合物直接(在相同位点结合)或间接(破坏TNF)的竞争。抑制曲线的外推产生约100μM的IC50。然而,在抑制剂的最高浓度下观察到荧光猝灭,当在该测定中其被扣除时导致抑制C87的作用可忽略不计。ThermofluorThermofluor测量由于化合物稳定或破坏蛋白质而导致的TNFα的解链温度(Tm)的变化。当浓度为500μMC87时,观察到3.8℃的稳定效应,表明弱结合的可能性,这可能不是特异性的。序列表SEQIDNO:1(1974的LCDR1)QASQDIGNSEQIDNO:2(1974的LCDR2)GATSLADSEQIDNO:3(1974的LCDR3)LQGQSTPYTSEQIDNO:4(1974的HCDR1)AYYMASEQIDNO:5(1974的HCDR2)ASINYDGANTFYRDSVKGSEQIDNO:6(1974的HCDR3)EAYGYNSNWFGYSEQIDNO:7(1974的LCVR)DIQMTQSPASLPASPEEIVTITCQASQDIGNWLSWYQQKPGKSPQLLIYGATSLADGVPSRFSASRSGTQYSLKISRLQVEDFGIFYCLQGQSTPYTFGAGTKLELKSEQIDNO:8(1974的HCVR)DVQLVESGGGLVQPGRSLKLSCAASGFTFSAYYMAWVRQAPTKGLEWVASINYDGANTFYRDSVKGRFTVSRDNARSSLYLQMDSLRSEDTATYYCTTEAYGYNSNWFGYWGQGTLVTVSSSEQIDNO:9(1974的LCVRDNA)GACATCCAGATGACCCAGTCTCCTGCCTCCCTGCCTGCATCCCCGGAAGAAATTGTCACCATCACATGCCAGGCAAGCCAGGACATTGGTAATTGGTTATCATGGTATCAGCAGAAACCAGGGAAATCGCCTCAGCTCCTGATCTATGGTGCAACCAGCTTGGCAGATGGGGTCCCATCAAGGTTCAGCGCCAGTAGATCTGGCACACAGTACTCTCTTAAGATCAGCAGACTGCAGGTTGAAGATTTTGGAATCTTTTACTGTCTACAGGGTCAAAGTACTCCGTACACGTTTGGAGCTGGGACCAAGCTGGAACTGAAASEQIDNO:10(1974的HCVRDNA)GACGTGCAGCTGGTGGAATCTGGAGGAGGCTTAGTGCAGCCTGGAAGGTCCCTGAAACTCTCCTGTGCAGCCTCAGGATTCACTTTCAGTGCCTATTACATGGCCTGGGTCCGCCAGGCTCCAACGAAGGGTCTGGAGTGGGTCGCATCCATTAATTATGATGGTGCTAACACTTTCTATCGCGACTCCGTGAAGGGCCGATTCACTGTCTCCAGAGATAATGCAAGAAGCAGCCTATACCTACAAATGGACAGTCTGAGGTCTGAGGACACGGCCACTTATTACTGTACAACAGAGGCTTACGGATATAACTCAAATTGGTTTGGTTACTGGGGCCAAGGCACTCTGGTCACTGTCTCGAGCSEQIDNO:11(1974LCkappa全长)DIQMTQSPASLPASPEEIVTITCQASQDIGNWLSWYQQKPGKSPQLLIYGATSLADGVPSRFSASRSGTQYSLKISRLQVEDFGIFYCLQGQSTPYTFGAGTKLELKRTDAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPKDINVKWKIDGSERQNGVLNSWTDQDSKDSTYSMSSTLTLTKDEYERHNSYTCEATHKTSTSPIVKSFNRNECSEQIDNO:12(1974HCmIgG1全长)DVQLVESGGGLVQPGRSLKLSCAASGFTFSAYYMAWVRQAPTKGLEWVASINYDGANTFYRDSVKGRFTVSRDNARSSLYLQMDSLRSEDTATYYCTTEAYGYNSNWFGYWGQGTLVTVSSAKTTPPSVYPLAPGSAAQTNSMVTLGCLVKGYFPEPVTVTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVPSSTWPSETVTCNVAHPASSTKVDKKIVPRDCGCKPCICTVPEVSSVFIFPPKPKDVLTITLTPKVTCVVVDISKDDPEVQFSWFVDDVEVHTAQTQPREEQFNSTFRSVSELPIMHQDWLNGKEFKCRVNSAAFPAPIEKTISKTKGRPKAPQVYTIPPPKEQMAKDKVSLTCMITDFFPEDITVEWQWNGQPAENYKNTQPIMDTDGSYFVYSKLNVQKSNWEAGNTFTCSVLHEGLHNHHTEKSLSHSPGKSEQIDNO:13(1974HCmFabno铰链全长)DVQLVESGGGLVQPGRSLKLSCAASGFTFSAYYMAWVRQAPTKGLEWVASINYDGANTFYRDSVKGRFTVSRDNARSSLYLQMDSLRSEDTATYYCTTEAYGYNSNWFGYWGQGTLVTVSSAKTTPPSVYPLAPGSAAQTNSMVTLGCLVKGYFPEPVTVTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVPSSTWPSETVTCNVAHPASSTKVDKKIVPRDCSEQIDNO:14(1974LCDNAkappa全长)GACATCCAGATGACCCAGTCTCCTGCCTCCCTGCCTGCATCCCCGGAAGAAATTGTCACCATCACATGCCAGGCAAGCCAGGACATTGGTAATTGGTTATCATGGTATCAGCAGAAACCAGGGAAATCGCCTCAGCTCCTGATCTATGGTGCAACCAGCTTGGCAGATGGGGTCCCATCAAGGTTCAGCGCCAGTAGATCTGGCACACAGTACTCTCTTAAGATCAGCAGACTGCAGGTTGAAGATTTTGGAATCTTTTACTGTCTACAGGGTCAAAGTACTCCGTACACGTTTGGAGCTGGGACCAAGCTGGAACTGAAACGTACGGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTACCCCAAAGACATCAATGTCAAGTGGAAGATTGATGGCAGTGAACGACAAAATGGCGTCCTGAACAGTTGGACTGATCAGGACAGCAAAGACAGCACCTACAGCATGAGCAGCACCCTCACGTTGACCAAGGACGAGTATGAACGACATAACAGCTATACCTGTGAGGCCACTCACAAGACATCAACTTCACCCATTGTCAAGAGCTTCAACAGGAATGAGTGTSEQIDNO:15(1974HCDNAmIgG1全长)GACGTGCAGCTGGTGGAATCTGGAGGAGGCTTAGTGCAGCCTGGAAGGTCCCTGAAACTCTCCTGTGCAGCCTCAGGATTCACTTTCAGTGCCTATTACATGGCCTGGGTCCGCCAGGCTCCAACGAAGGGTCTGGAGTGGGTCGCATCCATTAATTATGATGGTGCTAACACTTTCTATCGCGACTCCGTGAAGGGCCGATTCACTGTCTCCAGAGATAATGCAAGAAGCAGCCTATACCTACAAATGGACAGTCTGAGGTCTGAGGACACGGCCACTTATTACTGTACAACAGAGGCTTACGGATATAACTCAAATTGGTTTGGTTACTGGGGCCAAGGCACTCTGGTCACTGTCTCGAGTGCCAAAACGACACCCCCATCTGTCTATCCACTGGCCCCTGGATCTGCTGCCCAAACTAACTCCATGGTGACCCTGGGATGCCTGGTCAAGGGCTATTTCCCTGAGCCAGTGACAGTGACCTGGAACTCTGGATCCCTGTCCAGCGGTGTGCACACCTTCCCAGCTGTCCTGCAGTCTGACCTCTACACTCTGAGCAGCTCAGTGACTGTCCCCTCCAGCACCTGGCCCAGCGAGACCGTCACCTGCAACGTTGCCCACCCGGCCAGCAGCACCAAGGTGGACAAGAAAATTGTGCCCAGGGATTGTGGTTGTAAGCCTTGCATATGTACAGTCCCAGAAGTATCATCTGTCTTCATCTTCCCCCCAAAGCCCAAGGATGTGCTCACCATTACTCTGACTCCTAAGGTCACGTGTGTTGTGGTAGACATCAGCAAGGATGATCCCGAGGTCCAGTTCAGCTGGTTTGTAGATGATGTGGAGGTGCACACAGCTCAGACGCAACCCCGGGAGGAGCAGTTCAACAGCACTTTCCGCTCAGTCAGTGAACTTCCCATCATGCACCAGGACTGGCTCAATGGCAAGGAGTTCAAATGCAGGGTCAACAGTGCAGCTTTCCCTGCCCCCATCGAGAAAACCATCTCCAAAACCAAAGGCAGACCGAAGGCTCCACAGGTGTACACCATTCCACCTCCCAAGGAGCAGATGGCCAAGGATAAAGTCAGTCTGACCTGCATGATAACAGACTTCTTCCCTGAAGACATTACTGTGGAGTGGCAGTGGAATGGGCAGCCAGCGGAGAACTACAAGAACACTCAGCCCATCATGGACACAGATGGCTCTTACTTCGTCTACAGCAAGCTCAATGTGCAGAAGAGCAACTGGGAGGCAGGAAATACTTTCACCTGCTCTGTGTTACATGAGGGCCTGCACAACCACCATACTGAGAAGAGCCTCTCCCACTCTCCTGGTAAASEQIDNO:16(1974HCDNAmFabno铰链全长)GACGTGCAGCTGGTGGAATCTGGAGGAGGCTTAGTGCAGCCTGGAAGGTCCCTGAAACTCTCCTGTGCAGCCTCAGGATTCACTTTCAGTGCCTATTACATGGCCTGGGTCCGCCAGGCTCCAACGAAGGGTCTGGAGTGGGTCGCATCCATTAATTATGATGGTGCTAACACTTTCTATCGCGACTCCGTGAAGGGCCGATTCACTGTCTCCAGAGATAATGCAAGAAGCAGCCTATACCTACAAATGGACAGTCTGAGGTCTGAGGACACGGCCACTTATTACTGTACAACAGAGGCTTACGGATATAACTCAAATTGGTTTGGTTACTGGGGCCAAGGCACTCTGGTCACTGTCTCGAGTGCCAAAACGACACCCCCATCTGTCTATCCACTGGCCCCTGGATCTGCTGCCCAAACTAACTCCATGGTGACCCTGGGATGCCTGGTCAAGGGCTATTTCCCTGAGCCAGTGACAGTGACCTGGAACTCTGGATCCCTGTCCAGCGGTGTGCACACCTTCCCGGCTGTCCTGCAATCTGACCTCTACACTCTGAGCAGCTCAGTGACTGTCCCCTCCAGCACCTGGCCCAGCGAGACCGTCACCTGCAACGTTGCCCACCCGGCCAGCAGCACCAAGGTGGACAAGAAAATTGTGCCCAGGGATTGTSEQIDNO:17(1979的LCDR2)GTTSLADSEQIDNO:18(1979的LCDR3)LQAYSTPFTFSEQIDNO:19(1979的HCDR1)NSYWDSEQIDNO:20(1979的HCDR2)YINYSGSTGYNPSLKSSEQIDNO:21(1979的HCDR3)GTYGYNAYHFDYSEQIDNO:22(1979的LCVR)DIQMTQSPASLSASLEEIVTITCQASQDIGNWLSWYQQKPGKSPHLLIYGTTSLADGVPSRFSGSRSGTQYSLKISGLQVADIGIYVCLQAYSTPFTFGSGTKLEIKSEQIDNO:23(1979的HCVR)EVHLVESGPGLVKPSQSLSLTCSVTGYSITNSYWDWIRKFPGNKMEWMGYINYSGSTGYNPSLKSRISISRDTSNNQFFLQLNSITTEDTATYYCARGTYGYNAYHFDYWGRGVMVTVSSSEQIDNO:24(1979的LCVRDNA)GACATCCAAATGACACAGTCTCCTGCCTCCCTGTCTGCATCTCTGGAAGAAATTGTCACCATTACATGCCAGGCAAGCCAGGACATTGGTAATTGGTTATCATGGTATCAGCAGAAACCAGGGAAATCTCCTCACCTCCTGATCTATGGTACCACCAGCTTGGCAGATGGGGTCCCATCAAGGTTCAGCGGCAGTAGATCTGGTACACAGTATTCTCTTAAGATCAGCGGACTACAGGTTGCAGATATTGGAATCTATGTCTGTCTACAGGCTTATAGTACTCCATTCACGTTCGGCTCAGGGACAAAGCTGGAAATAAAASEQIDNO:25(1979的HCVRDNA)GAGGTGCACCTGGTGGAGTCTGGACCTGGCCTTGTGAAACCCTCACAGTCACTCTCCCTCACCTGTTCTGTCACTGGTTACTCCATCACTAATAGTTACTGGGACTGGATCCGGAAGTTCCCAGGAAATAAAATGGAGTGGATGGGATACATAAACTACAGTGGTAGCACTGGCTACAACCCATCTCTCAAAAGTCGAATCTCCATTAGTAGAGACACATCGAACAATCAGTTCTTCCTGCAGCTGAACTCTATAACTACTGAGGACACAGCCACATATTACTGTGCACGAGGGACCTATGGGTATAACGCCTACCACTTTGATTACTGGGGCCGAGGAGTCATGGTCACAGTCTCGAGCSEQIDNO:26(1979LCKappa全长)DIQMTQSPASLSASLEEIVTITCQASQDIGNWLSWYQQKPGKSPHLLIYGTTSLADGVPSRFSGSRSGTQYSLKISGLQVADIGIYVCLQAYSTPFTFGSGTKLEIKRTDAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPKDINVKWKIDGSERQNGVLNSWTDQDSKDSTYSMSSTLTLTKDEYERHNSYTCEATHKTSTSPIVKSFNRNECSEQIDNO:27(1979HCmIgG1/全长)EVHLVESGPGLVKPSQSLSLTCSVTGYSITNSYWDWIRKFPGNKMEWMGYINYSGSTGYNPSLKSRISISRDTSNNQFFLQLNSITTEDTATYYCARGTYGYNAYHFDYWGRGVMVTVSSAKTTPPSVYPLAPGSAAQTNSMVTLGCLVKGYFPEPVTVTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVPSSTWPSETVTCNVAHPASSTKVDKKIVPRDCGCKPCICTVPEVSSVFIFPPKPKDVLTITLTPKVTCVVVDISKDDPEVQFSWFVDDVEVHTAQTQPREEQFNSTFRSVSELPIMHQDWLNGKEFKCRVNSAAFPAPIEKTISKTKGRPKAPQVYTIPPPKEQMAKDKVSLTCMITDFFPEDITVEWQWNGQPAENYKNTQPIMDTDGSYFVYSKLNVQKSNWEAGNTFTCSVLHEGLHNHHTEKSLSHSPGKSEQIDNO:28(1979HCmFabno铰链/全长)EVHLVESGPGLVKPSQSLSLTCSVTGYSITNSYWDWIRKFPGNKMEWMGYINYSGSTGYNPSLKSRISISRDTSNNQFFLQLNSITTEDTATYYCARGTYGYNAYHFDYWGRGVMVTVSSAKTTPPSVYPLAPGSAAQTNSMVTLGCLVKGYFPEPVTVTWNSGSLSSGVHTFPAVLQSDLYTLSSSVTVPSSTWPSETVTCNVAHPASSTKVDKKIVPRDCSEQIDNO:29(1979LCDNAKappa/全长)GACATCCAAATGACACAGTCTCCTGCCTCCCTGTCTGCATCTCTGGAAGAAATTGTCACCATTACATGCCAGGCAAGCCAGGACATTGGTAATTGGTTATCATGGTATCAGCAGAAACCAGGGAAATCTCCTCACCTCCTGATCTATGGTACCACCAGCTTGGCAGATGGGGTCCCATCAAGGTTCAGCGGCAGTAGATCTGGTACACAGTATTCTCTTAAGATCAGCGGACTACAGGTTGCAGATATTGGAATCTATGTCTGTCTACAGGCTTATAGTACTCCATTCACGTTCGGCTCAGGGACAAAGCTGGAAATAAAACGTACGGATGCTGCACCAACTGTATCCATCTTCCCACCATCCAGTGAGCAGTTAACATCTGGAGGTGCCTCAGTCGTGTGCTTCTTGAACAACTTCTACCCCAAAGACATCAATGTCAAGTGGAAGATTGATGGCAGTGAACGACAAAATGGCGTCCTGAACAGTTGGACTGATCAGGACAGCAAAGACAGCACCTACAGCATGAGCAGCACCCTCACGTTGACCAAGGACGAGTATGAACGACATAACAGCTATACCTGTGAGGCCACTCACAAGACATCAACTTCACCCATTGTCAAGAGCTTCAACAGGAATGAGTGTSEQIDNO:30(1979HCDNAmIgG1/全长)GAGGTGCACCTGGTGGAGTCTGGACCTGGCCTTGTGAAACCCTCACAGTCACTCTCCCTCACCTGTTCTGTCACTGGTTACTCCATCACTAATAGTTACTGGGACTGGATCCGGAAGTTCCCAGGAAATAAAATGGAGTGGATGGGATACATAAACTACAGTGGTAGCACTGGCTACAACCCATCTCTCAAAAGTCGAATCTCCATTAGTAGAGACACATCGAACAATCAGTTCTTCCTGCAGCTGAACTCTATAACTACTGAGGACACAGCCACATATTACTGTGCACGAGGGACCTATGGGTATAACGCCTACCACTTTGATTACTGGGGCCGAGGAGTCATGGTCACAGTCTCGAGTGCCAAAACGACACCCCCATCTGTCTATCCACTGGCCCCTGGATCTGCTGCCCAAACTAACTCCATGGTGACCCTGGGATGCCTGGTCAAGGGCTATTTCCCTGAGCCAGTGACAGTGACCTGGAACTCTGGATCCCTGTCCAGCGGTGTGCACACCTTCCCAGCTGTCCTGCAGTCTGACCTCTACACTCTGAGCAGCTCAGTGACTGTCCCCTCCAGCACCTGGCCCAGCGAGACCGTCACCTGCAACGTTGCCCACCCGGCCAGCAGCACCAAGGTGGACAAGAAAATTGTGCCCAGGGATTGTGGTTGTAAGCCTTGCATATGTACAGTCCCAGAAGTATCATCTGTCTTCATCTTCCCCCCAAAGCCCAAGGATGTGCTCACCATTACTCTGACTCCTAAGGTCACGTGTGTTGTGGTAGACATCAGCAAGGATGATCCCGAGGTCCAGTTCAGCTGGTTTGTAGATGATGTGGAGGTGCACACAGCTCAGACGCAACCCCGGGAGGAGCAGTTCAACAGCACTTTCCGCTCAGTCAGTGAACTTCCCATCATGCACCAGGACTGGCTCAATGGCAAGGAGTTCAAATGCAGGGTCAACAGTGCAGCTTTCCCTGCCCCCATCGAGAAAACCATCTCCAAAACCAAAGGCAGACCGAAGGCTCCACAGGTGTACACCATTCCACCTCCCAAGGAGCAGATGGCCAAGGATAAAGTCAGTCTGACCTGCATGATAACAGACTTCTTCCCTGAAGACATTACTGTGGAGTGGCAGTGGAATGGGCAGCCAGCGGAGAACTACAAGAACACTCAGCCCATCATGGACACAGATGGCTCTTACTTCGTCTACAGCAAGCTCAATGTGCAGAAGAGCAACTGGGAGGCAGGAAATACTTTCACCTGCTCTGTGTTACATGAGGGCCTGCACAACCACCATACTGAGAAGAGCCTCTCCCACTCTCCTGGTAAASEQIDNO:31(1979HCDNAmFabno铰链/全长)GAGGTGCACCTGGTGGAGTCTGGACCTGGCCTTGTGAAACCCTCACAGTCACTCTCCCTCACCTGTTCTGTCACTGGTTACTCCATCACTAATAGTTACTGGGACTGGATCCGGAAGTTCCCAGGAAATAAAATGGAGTGGATGGGATACATAAACTACAGTGGTAGCACTGGCTACAACCCATCTCTCAAAAGTCGAATCTCCATTAGTAGAGACACATCGAACAATCAGTTCTTCCTGCAGCTGAACTCTATAACTACTGAGGACACAGCCACATATTACTGTGCACGAGGGACCTATGGGTATAACGCCTACCACTTTGATTACTGGGGCCGAGGAGTCATGGTCACAGTCTCGAGTGCCAAAACGACACCCCCATCTGTCTATCCACTGGCCCCTGGATCTGCTGCCCAAACTAACTCCATGGTGACCCTGGGATGCCTGGTCAAGGGCTATTTCCCTGAGCCAGTGACAGTGACCTGGAACTCTGGATCCCTGTCCAGCGGTGTGCACACCTTCCCGGCTGTCCTGCAATCTGACCTCTACACTCTGAGCAGCTCAGTGACTGTCCCCTCCAGCACCTGGCCCAGCGAGACCGTCACCTGCAACGTTGCCCACCCGGCCAGCAGCACCAAGGTGGACAAGAAAATTGTGCCCAGGGATTGTSEQIDNO:32–大鼠TNFαMSTESMIRDVELAEEALPKKMGGLQNSRRCLCLSLFSFLLVAGATTLFCLLNFGVIGPNKEEKFPNGLPLISSMAQTLTLRSSSQNSSDKPVAHVVANHQAEEQLEWLSQRANALLANGMDLKDNQLVVPADGLYLIYSQVLFKGQGCPDYVLLTHTVSRFAISYQEKVSLLSAIKSPCPKDTPEGAELKPWYEPMYLGGVFQLEKGDLLSAEVNLPKYLDITESGQVYFGVIALSEQIDNO:33–小鼠TNFαMSTESMIRDVELAEEALPQKMGGFQNSRRCLCLSLFSFLLVAGATTLFCLLNFGVIGPQRDEKFPNGLPLISSMAQTLTLRSSSQNSSDKPVAHVVANHQVEEQLEWLSQRANALLANGMDLKDNQLVVPADGLYLVYSQVLFKGQGCPDYVLLTHTVSRFAISYQEKVNLLSAVKSPCPKDTPEGAELKPWYEPIYLGGVFQLEKGDQLSAEVNLPKYLDFAESGQVYFGVIALSEQIDNO:34–人TNFαMSTESMIRDVELAEEALPKKTGGPQGSRRCLFLSLFSFLIVAGATTLFCLLHFGVIGPQREEFPRDLSLISPLAQAVRSSSRTPSDKPVAHVVANPQAEGQLQWLNRRANALLANGVELRDNQLVVPSEGLYLIYSQVLFKGQGCPSTHVLLTHTISRIAVSYQTKVNLLSAIKSPCQRETPEGAEAKPWYEPIYLGGVFQLEKGDRLSAEINRPDYLDFAESGQVYFGIIALSEQIDNO:35–人TNFα的可溶性形式SVRSSSRTPSDKPVAHVVANPQAEGQLQWLNRRANALLANGVELRDNQLVVPSEGLYLIYSQVLFKGQGCPSTHVLLTHTISRIAVSYQTKVNLLSAIKSPCQRETPEGAEAKPWYEPIYLGGVFQLEKGDRLSAEINRPDYLDFAESGQVYFGIIALSEQIDNO:36–TNFα的可溶性形式,但排除SEQIDNO:35的最前面的“S”,其是克隆人工物VRSSSRTPSDKPVAHVVANPQAEGQLQWLNRRANALLANGVELRDNQLVVPSEGLYLIYSQVLFKGQGCPSTHVLLTHTISRIAVSYQTKVNLLSAIKSPCQRETPEGAEAKPWYEPIYLGGVFQLEKGDRLSAEINRPDYLDFAESGQVYFGIIAL序列表<110>UCBBiopharmaSPRLSanofi<120>抗体表位<130>N403766WO<150>GB1418781.9<151>2014-10-22<150>GB1418776.9<151>2014-10-22<150>GB1418774.4<151>2014-10-22<150>GB1418773.6<151>2014-10-22<150>GB1510758.4<151>2015-06-18<160>36<170>PatentInversion3.5<210>1<211>8<212>PRT<213>人工序列<220><223>LCDR1of1974/1979<400>1GlnAlaSerGlnAspIleGlyAsn15<210>2<211>7<212>PRT<213>人工序列<220><223>LCDR2of1974<400>2GlyAlaThrSerLeuAlaAsp15<210>3<211>9<212>PRT<213>人工序列<220><223>LCDR3of1974<400>3LeuGlnGlyGlnSerThrProTyrThr15<210>4<211>5<212>PRT<213>人工序列<220><223>HCDR1of1974<400>4AlaTyrTyrMetAla15<210>5<211>18<212>PRT<213>人工序列<220><223>HCDR2of1974<400>5AlaSerIleAsnTyrAspGlyAlaAsnThrPheTyrArgAspSerVal151015LysGly<210>6<211>12<212>PRT<213>人工序列<220><223>HCDR3of1974<400>6GluAlaTyrGlyTyrAsnSerAsnTrpPheGlyTyr1510<210>7<211>107<212>PRT<213>人工序列<220><223>LCVRof1974<400>7AspIleGlnMetThrGlnSerProAlaSerLeuProAlaSerProGlu151015GluIleValThrIleThrCysGlnAlaSerGlnAspIleGlyAsnTrp202530LeuSerTrpTyrGlnGlnLysProGlyLysSerProGlnLeuLeuIle354045TyrGlyAlaThrSerLeuAlaAspGlyValProSerArgPheSerAla505560SerArgSerGlyThrGlnTyrSerLeuLysIleSerArgLeuGlnVal65707580GluAspPheGlyIlePheTyrCysLeuGlnGlyGlnSerThrProTyr859095ThrPheGlyAlaGlyThrLysLeuGluLeuLys100105<210>8<211>121<212>PRT<213>人工序列<220><223>HCVRof1974<400>8AspValGlnLeuValGluSerGlyGlyGlyLeuValGlnProGlyArg151015SerLeuLysLeuSerCysAlaAlaSerGlyPheThrPheSerAlaTyr202530TyrMetAlaTrpValArgGlnAlaProThrLysGlyLeuGluTrpVal354045AlaSerIleAsnTyrAspGlyAlaAsnThrPheTyrArgAspSerVal505560LysGlyArgPheThrValSerArgAspAsnAlaArgSerSerLeuTyr65707580LeuGlnMetAspSerLeuArgSerGluAspThrAlaThrTyrTyrCys859095ThrThrGluAlaTyrGlyTyrAsnSerAsnTrpPheGlyTyrTrpGly100105110GlnGlyThrLeuValThrValSerSer115120<210>9<211>321<212>DNA<213>人工序列<220><223>LCVRDNAof1974<400>9gacatccagatgacccagtctcctgcctccctgcctgcatccccggaagaaattgtcacc60atcacatgccaggcaagccaggacattggtaattggttatcatggtatcagcagaaacca120gggaaatcgcctcagctcctgatctatggtgcaaccagcttggcagatggggtcccatca180aggttcagcgccagtagatctggcacacagtactctcttaagatcagcagactgcaggtt240gaagattttggaatcttttactgtctacagggtcaaagtactccgtacacgtttggagct300gggaccaagctggaactgaaa321<210>10<211>363<212>DNA<213>人工序列<220><223>HCVRDNAof1974<400>10gacgtgcagctggtggaatctggaggaggcttagtgcagcctggaaggtccctgaaactc60tcctgtgcagcctcaggattcactttcagtgcctattacatggcctgggtccgccaggct120ccaacgaagggtctggagtgggtcgcatccattaattatgatggtgctaacactttctat180cgcgactccgtgaagggccgattcactgtctccagagataatgcaagaagcagcctatac240ctacaaatggacagtctgaggtctgaggacacggccacttattactgtacaacagaggct300tacggatataactcaaattggtttggttactggggccaaggcactctggtcactgtctcg360agc363<210>11<211>214<212>PRT<213>人工序列<220><223>1974LCkappafull<400>11AspIleGlnMetThrGlnSerProAlaSerLeuProAlaSerProGlu151015GluIleValThrIleThrCysGlnAlaSerGlnAspIleGlyAsnTrp202530LeuSerTrpTyrGlnGlnLysProGlyLysSerProGlnLeuLeuIle354045TyrGlyAlaThrSerLeuAlaAspGlyValProSerArgPheSerAla505560SerArgSerGlyThrGlnTyrSerLeuLysIleSerArgLeuGlnVal65707580GluAspPheGlyIlePheTyrCysLeuGlnGlyGlnSerThrProTyr859095ThrPheGlyAlaGlyThrLysLeuGluLeuLysArgThrAspAlaAla100105110ProThrValSerIlePheProProSerSerGluGlnLeuThrSerGly115120125GlyAlaSerValValCysPheLeuAsnAsnPheTyrProLysAspIle130135140AsnValLysTrpLysIleAspGlySerGluArgGlnAsnGlyValLeu145150155160AsnSerTrpThrAspGlnAspSerLysAspSerThrTyrSerMetSer165170175SerThrLeuThrLeuThrLysAspGluTyrGluArgHisAsnSerTyr180185190ThrCysGluAlaThrHisLysThrSerThrSerProIleValLysSer195200205PheAsnArgAsnGluCys210<210>12<211>445<212>PRT<213>人工序列<220><223>1974HCmIgG1full<400>12AspValGlnLeuValGluSerGlyGlyGlyLeuValGlnProGlyArg151015SerLeuLysLeuSerCysAlaAlaSerGlyPheThrPheSerAlaTyr202530TyrMetAlaTrpValArgGlnAlaProThrLysGlyLeuGluTrpVal354045AlaSerIleAsnTyrAspGlyAlaAsnThrPheTyrArgAspSerVal505560LysGlyArgPheThrValSerArgAspAsnAlaArgSerSerLeuTyr65707580LeuGlnMetAspSerLeuArgSerGluAspThrAlaThrTyrTyrCys859095ThrThrGluAlaTyrGlyTyrAsnSerAsnTrpPheGlyTyrTrpGly100105110GlnGlyThrLeuValThrValSerSerAlaLysThrThrProProSer115120125ValTyrProLeuAlaProGlySerAlaAlaGlnThrAsnSerMetVal130135140ThrLeuGlyCysLeuValLysGlyTyrPheProGluProValThrVal145150155160ThrTrpAsnSerGlySerLeuSerSerGlyValHisThrPheProAla165170175ValLeuGlnSerAspLeuTyrThrLeuSerSerSerValThrValPro180185190SerSerThrTrpProSerGluThrValThrCysAsnValAlaHisPro195200205AlaSerSerThrLysValAspLysLysIleValProArgAspCysGly210215220CysLysProCysIleCysThrValProGluValSerSerValPheIle225230235240PheProProLysProLysAspValLeuThrIleThrLeuThrProLys245250255ValThrCysValValValAspIleSerLysAspAspProGluValGln260265270PheSerTrpPheValAspAspValGluValHisThrAlaGlnThrGln275280285ProArgGluGluGlnPheAsnSerThrPheArgSerValSerGluLeu290295300ProIleMetHisGlnAspTrpLeuAsnGlyLysGluPheLysCysArg305310315320ValAsnSerAlaAlaPheProAlaProIleGluLysThrIleSerLys325330335ThrLysGlyArgProLysAlaProGlnValTyrThrIleProProPro340345350LysGluGlnMetAlaLysAspLysValSerLeuThrCysMetIleThr355360365AspPhePheProGluAspIleThrValGluTrpGlnTrpAsnGlyGln370375380ProAlaGluAsnTyrLysAsnThrGlnProIleMetAspThrAspGly385390395400SerTyrPheValTyrSerLysLeuAsnValGlnLysSerAsnTrpGlu405410415AlaGlyAsnThrPheThrCysSerValLeuHisGluGlyLeuHisAsn420425430HisHisThrGluLysSerLeuSerHisSerProGlyLys435440445<210>13<211>223<212>PRT<213>人工序列<220><223>1974HCmFabnohingefull<400>13AspValGlnLeuValGluSerGlyGlyGlyLeuValGlnProGlyArg151015SerLeuLysLeuSerCysAlaAlaSerGlyPheThrPheSerAlaTyr202530TyrMetAlaTrpValArgGlnAlaProThrLysGlyLeuGluTrpVal354045AlaSerIleAsnTyrAspGlyAlaAsnThrPheTyrArgAspSerVal505560LysGlyArgPheThrValSerArgAspAsnAlaArgSerSerLeuTyr65707580LeuGlnMetAspSerLeuArgSerGluAspThrAlaThrTyrTyrCys859095ThrThrGluAlaTyrGlyTyrAsnSerAsnTrpPheGlyTyrTrpGly100105110GlnGlyThrLeuValThrValSerSerAlaLysThrThrProProSer115120125ValTyrProLeuAlaProGlySerAlaAlaGlnThrAsnSerMetVal130135140ThrLeuGlyCysLeuValLysGlyTyrPheProGluProValThrVal145150155160ThrTrpAsnSerGlySerLeuSerSerGlyValHisThrPheProAla165170175ValLeuGlnSerAspLeuTyrThrLeuSerSerSerValThrValPro180185190SerSerThrTrpProSerGluThrValThrCysAsnValAlaHisPro195200205AlaSerSerThrLysValAspLysLysIleValProArgAspCys210215220<210>14<211>642<212>DNA<213>人工序列<220><223>1974LCDNAkappafull<400>14gacatccagatgacccagtctcctgcctccctgcctgcatccccggaagaaattgtcacc60atcacatgccaggcaagccaggacattggtaattggttatcatggtatcagcagaaacca120gggaaatcgcctcagctcctgatctatggtgcaaccagcttggcagatggggtcccatca180aggttcagcgccagtagatctggcacacagtactctcttaagatcagcagactgcaggtt240gaagattttggaatcttttactgtctacagggtcaaagtactccgtacacgtttggagct300gggaccaagctggaactgaaacgtacggatgctgcaccaactgtatccatcttcccacca360tccagtgagcagttaacatctggaggtgcctcagtcgtgtgcttcttgaacaacttctac420cccaaagacatcaatgtcaagtggaagattgatggcagtgaacgacaaaatggcgtcctg480aacagttggactgatcaggacagcaaagacagcacctacagcatgagcagcaccctcacg540ttgaccaaggacgagtatgaacgacataacagctatacctgtgaggccactcacaagaca600tcaacttcacccattgtcaagagcttcaacaggaatgagtgt642<210>15<211>1335<212>DNA<213>人工序列<220><223>1974HCDNAmIgG1full<400>15gacgtgcagctggtggaatctggaggaggcttagtgcagcctggaaggtccctgaaactc60tcctgtgcagcctcaggattcactttcagtgcctattacatggcctgggtccgccaggct120ccaacgaagggtctggagtgggtcgcatccattaattatgatggtgctaacactttctat180cgcgactccgtgaagggccgattcactgtctccagagataatgcaagaagcagcctatac240ctacaaatggacagtctgaggtctgaggacacggccacttattactgtacaacagaggct300tacggatataactcaaattggtttggttactggggccaaggcactctggtcactgtctcg360agtgccaaaacgacacccccatctgtctatccactggcccctggatctgctgcccaaact420aactccatggtgaccctgggatgcctggtcaagggctatttccctgagccagtgacagtg480acctggaactctggatccctgtccagcggtgtgcacaccttcccagctgtcctgcagtct540gacctctacactctgagcagctcagtgactgtcccctccagcacctggcccagcgagacc600gtcacctgcaacgttgcccacccggccagcagcaccaaggtggacaagaaaattgtgccc660agggattgtggttgtaagccttgcatatgtacagtcccagaagtatcatctgtcttcatc720ttccccccaaagcccaaggatgtgctcaccattactctgactcctaaggtcacgtgtgtt780gtggtagacatcagcaaggatgatcccgaggtccagttcagctggtttgtagatgatgtg840gaggtgcacacagctcagacgcaaccccgggaggagcagttcaacagcactttccgctca900gtcagtgaacttcccatcatgcaccaggactggctcaatggcaaggagttcaaatgcagg960gtcaacagtgcagctttccctgcccccatcgagaaaaccatctccaaaaccaaaggcaga1020ccgaaggctccacaggtgtacaccattccacctcccaaggagcagatggccaaggataaa1080gtcagtctgacctgcatgataacagacttcttccctgaagacattactgtggagtggcag1140tggaatgggcagccagcggagaactacaagaacactcagcccatcatggacacagatggc1200tcttacttcgtctacagcaagctcaatgtgcagaagagcaactgggaggcaggaaatact1260ttcacctgctctgtgttacatgagggcctgcacaaccaccatactgagaagagcctctcc1320cactctcctggtaaa1335<210>16<211>669<212>DNA<213>人工序列<220><223>1974HCDNAmFabnohingefull<400>16gacgtgcagctggtggaatctggaggaggcttagtgcagcctggaaggtccctgaaactc60tcctgtgcagcctcaggattcactttcagtgcctattacatggcctgggtccgccaggct120ccaacgaagggtctggagtgggtcgcatccattaattatgatggtgctaacactttctat180cgcgactccgtgaagggccgattcactgtctccagagataatgcaagaagcagcctatac240ctacaaatggacagtctgaggtctgaggacacggccacttattactgtacaacagaggct300tacggatataactcaaattggtttggttactggggccaaggcactctggtcactgtctcg360agtgccaaaacgacacccccatctgtctatccactggcccctggatctgctgcccaaact420aactccatggtgaccctgggatgcctggtcaagggctatttccctgagccagtgacagtg480acctggaactctggatccctgtccagcggtgtgcacaccttcccggctgtcctgcaatct540gacctctacactctgagcagctcagtgactgtcccctccagcacctggcccagcgagacc600gtcacctgcaacgttgcccacccggccagcagcaccaaggtggacaagaaaattgtgccc660agggattgt669<210>17<211>7<212>PRT<213>人工序列<220><223>LCDR2of1979<400>17GlyThrThrSerLeuAlaAsp15<210>18<211>10<212>PRT<213>人工序列<220><223>LCDR3of1979<400>18LeuGlnAlaTyrSerThrProPheThrPhe1510<210>19<211>5<212>PRT<213>人工序列<220><223>HCDR1of1979<400>19AsnSerTyrTrpAsp15<210>20<211>16<212>PRT<213>人工序列<220><223>HCDR2of1979<400>20TyrIleAsnTyrSerGlySerThrGlyTyrAsnProSerLeuLysSer151015<210>21<211>12<212>PRT<213>人工序列<220><223>HCDR3of1979<400>21GlyThrTyrGlyTyrAsnAlaTyrHisPheAspTyr1510<210>22<211>107<212>PRT<213>人工序列<220><223>LCVRof1979<400>22AspIleGlnMetThrGlnSerProAlaSerLeuSerAlaSerLeuGlu151015GluIleValThrIleThrCysGlnAlaSerGlnAspIleGlyAsnTrp202530LeuSerTrpTyrGlnGlnLysProGlyLysSerProHisLeuLeuIle354045TyrGlyThrThrSerLeuAlaAspGlyValProSerArgPheSerGly505560SerArgSerGlyThrGlnTyrSerLeuLysIleSerGlyLeuGlnVal65707580AlaAspIleGlyIleTyrValCysLeuGlnAlaTyrSerThrProPhe859095ThrPheGlySerGlyThrLysLeuGluIleLys100105<210>23<211>120<212>PRT<213>人工序列<220><223>HCVRof1979<400>23GluValHisLeuValGluSerGlyProGlyLeuValLysProSerGln151015SerLeuSerLeuThrCysSerValThrGlyTyrSerIleThrAsnSer202530TyrTrpAspTrpIleArgLysPheProGlyAsnLysMetGluTrpMet354045GlyTyrIleAsnTyrSerGlySerThrGlyTyrAsnProSerLeuLys505560SerArgIleSerIleSerArgAspThrSerAsnAsnGlnPhePheLeu65707580GlnLeuAsnSerIleThrThrGluAspThrAlaThrTyrTyrCysAla859095ArgGlyThrTyrGlyTyrAsnAlaTyrHisPheAspTyrTrpGlyArg100105110GlyValMetValThrValSerSer115120<210>24<211>321<212>DNA<213>人工序列<220><223>LCVRDNAof1979<400>24gacatccaaatgacacagtctcctgcctccctgtctgcatctctggaagaaattgtcacc60attacatgccaggcaagccaggacattggtaattggttatcatggtatcagcagaaacca120gggaaatctcctcacctcctgatctatggtaccaccagcttggcagatggggtcccatca180aggttcagcggcagtagatctggtacacagtattctcttaagatcagcggactacaggtt240gcagatattggaatctatgtctgtctacaggcttatagtactccattcacgttcggctca300gggacaaagctggaaataaaa321<210>25<211>360<212>DNA<213>人工序列<220><223>HCVRDNAof1979<400>25gaggtgcacctggtggagtctggacctggccttgtgaaaccctcacagtcactctccctc60acctgttctgtcactggttactccatcactaatagttactgggactggatccggaagttc120ccaggaaataaaatggagtggatgggatacataaactacagtggtagcactggctacaac180ccatctctcaaaagtcgaatctccattagtagagacacatcgaacaatcagttcttcctg240cagctgaactctataactactgaggacacagccacatattactgtgcacgagggacctat300gggtataacgcctaccactttgattactggggccgaggagtcatggtcacagtctcgagc360<210>26<211>214<212>PRT<213>人工序列<220><223>1979LCKappafull<400>26AspIleGlnMetThrGlnSerProAlaSerLeuSerAlaSerLeuGlu151015GluIleValThrIleThrCysGlnAlaSerGlnAspIleGlyAsnTrp202530LeuSerTrpTyrGlnGlnLysProGlyLysSerProHisLeuLeuIle354045TyrGlyThrThrSerLeuAlaAspGlyValProSerArgPheSerGly505560SerArgSerGlyThrGlnTyrSerLeuLysIleSerGlyLeuGlnVal65707580AlaAspIleGlyIleTyrValCysLeuGlnAlaTyrSerThrProPhe859095ThrPheGlySerGlyThrLysLeuGluIleLysArgThrAspAlaAla100105110ProThrValSerIlePheProProSerSerGluGlnLeuThrSerGly115120125GlyAlaSerValValCysPheLeuAsnAsnPheTyrProLysAspIle130135140AsnValLysTrpLysIleAspGlySerGluArgGlnAsnGlyValLeu145150155160AsnSerTrpThrAspGlnAspSerLysAspSerThrTyrSerMetSer165170175SerThrLeuThrLeuThrLysAspGluTyrGluArgHisAsnSerTyr180185190ThrCysGluAlaThrHisLysThrSerThrSerProIleValLysSer195200205PheAsnArgAsnGluCys210<210>27<211>444<212>PRT<213>人工序列<220><223>1979HCmIgG1full<400>27GluValHisLeuValGluSerGlyProGlyLeuValLysProSerGln151015SerLeuSerLeuThrCysSerValThrGlyTyrSerIleThrAsnSer202530TyrTrpAspTrpIleArgLysPheProGlyAsnLysMetGluTrpMet354045GlyTyrIleAsnTyrSerGlySerThrGlyTyrAsnProSerLeuLys505560SerArgIleSerIleSerArgAspThrSerAsnAsnGlnPhePheLeu65707580GlnLeuAsnSerIleThrThrGluAspThrAlaThrTyrTyrCysAla859095ArgGlyThrTyrGlyTyrAsnAlaTyrHisPheAspTyrTrpGlyArg100105110GlyValMetValThrValSerSerAlaLysThrThrProProSerVal115120125TyrProLeuAlaProGlySerAlaAlaGlnThrAsnSerMetValThr130135140LeuGlyCysLeuValLysGlyTyrPheProGluProValThrValThr145150155160TrpAsnSerGlySerLeuSerSerGlyValHisThrPheProAlaVal165170175LeuGlnSerAspLeuTyrThrLeuSerSerSerValThrValProSer180185190SerThrTrpProSerGluThrValThrCysAsnValAlaHisProAla195200205SerSerThrLysValAspLysLysIleValProArgAspCysGlyCys210215220LysProCysIleCysThrValProGluValSerSerValPheIlePhe225230235240ProProLysProLysAspValLeuThrIleThrLeuThrProLysVal245250255ThrCysValValValAspIleSerLysAspAspProGluValGlnPhe260265270SerTrpPheValAspAspValGluValHisThrAlaGlnThrGlnPro275280285ArgGluGluGlnPheAsnSerThrPheArgSerValSerGluLeuPro290295300IleMetHisGlnAspTrpLeuAsnGlyLysGluPheLysCysArgVal305310315320AsnSerAlaAlaPheProAlaProIleGluLysThrIleSerLysThr325330335LysGlyArgProLysAlaProGlnValTyrThrIleProProProLys340345350GluGlnMetAlaLysAspLysValSerLeuThrCysMetIleThrAsp355360365PhePheProGluAspIleThrValGluTrpGlnTrpAsnGlyGlnPro370375380AlaGluAsnTyrLysAsnThrGlnProIleMetAspThrAspGlySer385390395400TyrPheValTyrSerLysLeuAsnValGlnLysSerAsnTrpGluAla405410415GlyAsnThrPheThrCysSerValLeuHisGluGlyLeuHisAsnHis420425430HisThrGluLysSerLeuSerHisSerProGlyLys435440<210>28<211>222<212>PRT<213>人工序列<220><223>1979HCmFabnohingefull<400>28GluValHisLeuValGluSerGlyProGlyLeuValLysProSerGln151015SerLeuSerLeuThrCysSerValThrGlyTyrSerIleThrAsnSer202530TyrTrpAspTrpIleArgLysPheProGlyAsnLysMetGluTrpMet354045GlyTyrIleAsnTyrSerGlySerThrGlyTyrAsnProSerLeuLys505560SerArgIleSerIleSerArgAspThrSerAsnAsnGlnPhePheLeu65707580GlnLeuAsnSerIleThrThrGluAspThrAlaThrTyrTyrCysAla859095ArgGlyThrTyrGlyTyrAsnAlaTyrHisPheAspTyrTrpGlyArg100105110GlyValMetValThrValSerSerAlaLysThrThrProProSerVal115120125TyrProLeuAlaProGlySerAlaAlaGlnThrAsnSerMetValThr130135140LeuGlyCysLeuValLysGlyTyrPheProGluProValThrValThr145150155160TrpAsnSerGlySerLeuSerSerGlyValHisThrPheProAlaVal165170175LeuGlnSerAspLeuTyrThrLeuSerSerSerValThrValProSer180185190SerThrTrpProSerGluThrValThrCysAsnValAlaHisProAla195200205SerSerThrLysValAspLysLysIleValProArgAspCys210215220<210>29<211>642<212>DNA<213>人工序列<220><223>1979LCDNAKappafull<400>29gacatccaaatgacacagtctcctgcctccctgtctgcatctctggaagaaattgtcacc60attacatgccaggcaagccaggacattggtaattggttatcatggtatcagcagaaacca120gggaaatctcctcacctcctgatctatggtaccaccagcttggcagatggggtcccatca180aggttcagcggcagtagatctggtacacagtattctcttaagatcagcggactacaggtt240gcagatattggaatctatgtctgtctacaggcttatagtactccattcacgttcggctca300gggacaaagctggaaataaaacgtacggatgctgcaccaactgtatccatcttcccacca360tccagtgagcagttaacatctggaggtgcctcagtcgtgtgcttcttgaacaacttctac420cccaaagacatcaatgtcaagtggaagattgatggcagtgaacgacaaaatggcgtcctg480aacagttggactgatcaggacagcaaagacagcacctacagcatgagcagcaccctcacg540ttgaccaaggacgagtatgaacgacataacagctatacctgtgaggccactcacaagaca600tcaacttcacccattgtcaagagcttcaacaggaatgagtgt642<210>30<211>1332<212>DNA<213>人工序列<220><223>1979HCDNAmIgG1full<400>30gaggtgcacctggtggagtctggacctggccttgtgaaaccctcacagtcactctccctc60acctgttctgtcactggttactccatcactaatagttactgggactggatccggaagttc120ccaggaaataaaatggagtggatgggatacataaactacagtggtagcactggctacaac180ccatctctcaaaagtcgaatctccattagtagagacacatcgaacaatcagttcttcctg240cagctgaactctataactactgaggacacagccacatattactgtgcacgagggacctat300gggtataacgcctaccactttgattactggggccgaggagtcatggtcacagtctcgagt360gccaaaacgacacccccatctgtctatccactggcccctggatctgctgcccaaactaac420tccatggtgaccctgggatgcctggtcaagggctatttccctgagccagtgacagtgacc480tggaactctggatccctgtccagcggtgtgcacaccttcccagctgtcctgcagtctgac540ctctacactctgagcagctcagtgactgtcccctccagcacctggcccagcgagaccgtc600acctgcaacgttgcccacccggccagcagcaccaaggtggacaagaaaattgtgcccagg660gattgtggttgtaagccttgcatatgtacagtcccagaagtatcatctgtcttcatcttc720cccccaaagcccaaggatgtgctcaccattactctgactcctaaggtcacgtgtgttgtg780gtagacatcagcaaggatgatcccgaggtccagttcagctggtttgtagatgatgtggag840gtgcacacagctcagacgcaaccccgggaggagcagttcaacagcactttccgctcagtc900agtgaacttcccatcatgcaccaggactggctcaatggcaaggagttcaaatgcagggtc960aacagtgcagctttccctgcccccatcgagaaaaccatctccaaaaccaaaggcagaccg1020aaggctccacaggtgtacaccattccacctcccaaggagcagatggccaaggataaagtc1080agtctgacctgcatgataacagacttcttccctgaagacattactgtggagtggcagtgg1140aatgggcagccagcggagaactacaagaacactcagcccatcatggacacagatggctct1200tacttcgtctacagcaagctcaatgtgcagaagagcaactgggaggcaggaaatactttc1260acctgctctgtgttacatgagggcctgcacaaccaccatactgagaagagcctctcccac1320tctcctggtaaa1332<210>31<211>666<212>DNA<213>人工序列<220><223>1979HCDNAmFabnohingefull<400>31gaggtgcacctggtggagtctggacctggccttgtgaaaccctcacagtcactctccctc60acctgttctgtcactggttactccatcactaatagttactgggactggatccggaagttc120ccaggaaataaaatggagtggatgggatacataaactacagtggtagcactggctacaac180ccatctctcaaaagtcgaatctccattagtagagacacatcgaacaatcagttcttcctg240cagctgaactctataactactgaggacacagccacatattactgtgcacgagggacctat300gggtataacgcctaccactttgattactggggccgaggagtcatggtcacagtctcgagt360gccaaaacgacacccccatctgtctatccactggcccctggatctgctgcccaaactaac420tccatggtgaccctgggatgcctggtcaagggctatttccctgagccagtgacagtgacc480tggaactctggatccctgtccagcggtgtgcacaccttcccggctgtcctgcaatctgac540ctctacactctgagcagctcagtgactgtcccctccagcacctggcccagcgagaccgtc600acctgcaacgttgcccacccggccagcagcaccaaggtggacaagaaaattgtgcccagg660gattgt666<210>32<211>235<212>PRT<213>褐家鼠<400>32MetSerThrGluSerMetIleArgAspValGluLeuAlaGluGluAla151015LeuProLysLysMetGlyGlyLeuGlnAsnSerArgArgCysLeuCys202530LeuSerLeuPheSerPheLeuLeuValAlaGlyAlaThrThrLeuPhe354045CysLeuLeuAsnPheGlyValIleGlyProAsnLysGluGluLysPhe505560ProAsnGlyLeuProLeuIleSerSerMetAlaGlnThrLeuThrLeu65707580ArgSerSerSerGlnAsnSerSerAspLysProValAlaHisValVal859095AlaAsnHisGlnAlaGluGluGlnLeuGluTrpLeuSerGlnArgAla100105110AsnAlaLeuLeuAlaAsnGlyMetAspLeuLysAspAsnGlnLeuVal115120125ValProAlaAspGlyLeuTyrLeuIleTyrSerGlnValLeuPheLys130135140GlyGlnGlyCysProAspTyrValLeuLeuThrHisThrValSerArg145150155160PheAlaIleSerTyrGlnGluLysValSerLeuLeuSerAlaIleLys165170175SerProCysProLysAspThrProGluGlyAlaGluLeuLysProTrp180185190TyrGluProMetTyrLeuGlyGlyValPheGlnLeuGluLysGlyAsp195200205LeuLeuSerAlaGluValAsnLeuProLysTyrLeuAspIleThrGlu210215220SerGlyGlnValTyrPheGlyValIleAlaLeu225230235<210>33<211>235<212>PRT<213>小家鼠<400>33MetSerThrGluSerMetIleArgAspValGluLeuAlaGluGluAla151015LeuProGlnLysMetGlyGlyPheGlnAsnSerArgArgCysLeuCys202530LeuSerLeuPheSerPheLeuLeuValAlaGlyAlaThrThrLeuPhe354045CysLeuLeuAsnPheGlyValIleGlyProGlnArgAspGluLysPhe505560ProAsnGlyLeuProLeuIleSerSerMetAlaGlnThrLeuThrLeu65707580ArgSerSerSerGlnAsnSerSerAspLysProValAlaHisValVal859095AlaAsnHisGlnValGluGluGlnLeuGluTrpLeuSerGlnArgAla100105110AsnAlaLeuLeuAlaAsnGlyMetAspLeuLysAspAsnGlnLeuVal115120125ValProAlaAspGlyLeuTyrLeuValTyrSerGlnValLeuPheLys130135140GlyGlnGlyCysProAspTyrValLeuLeuThrHisThrValSerArg145150155160PheAlaIleSerTyrGlnGluLysValAsnLeuLeuSerAlaValLys165170175SerProCysProLysAspThrProGluGlyAlaGluLeuLysProTrp180185190TyrGluProIleTyrLeuGlyGlyValPheGlnLeuGluLysGlyAsp195200205GlnLeuSerAlaGluValAsnLeuProLysTyrLeuAspPheAlaGlu210215220SerGlyGlnValTyrPheGlyValIleAlaLeu225230235<210>34<211>233<212>PRT<213>智人<400>34MetSerThrGluSerMetIleArgAspValGluLeuAlaGluGluAla151015LeuProLysLysThrGlyGlyProGlnGlySerArgArgCysLeuPhe202530LeuSerLeuPheSerPheLeuIleValAlaGlyAlaThrThrLeuPhe354045CysLeuLeuHisPheGlyValIleGlyProGlnArgGluGluPhePro505560ArgAspLeuSerLeuIleSerProLeuAlaGlnAlaValArgSerSer65707580SerArgThrProSerAspLysProValAlaHisValValAlaAsnPro859095GlnAlaGluGlyGlnLeuGlnTrpLeuAsnArgArgAlaAsnAlaLeu100105110LeuAlaAsnGlyValGluLeuArgAspAsnGlnLeuValValProSer115120125GluGlyLeuTyrLeuIleTyrSerGlnValLeuPheLysGlyGlnGly130135140CysProSerThrHisValLeuLeuThrHisThrIleSerArgIleAla145150155160ValSerTyrGlnThrLysValAsnLeuLeuSerAlaIleLysSerPro165170175CysGlnArgGluThrProGluGlyAlaGluAlaLysProTrpTyrGlu180185190ProIleTyrLeuGlyGlyValPheGlnLeuGluLysGlyAspArgLeu195200205SerAlaGluIleAsnArgProAspTyrLeuAspPheAlaGluSerGly210215220GlnValTyrPheGlyIleIleAlaLeu225230<210>35<211>158<212>PRT<213>智人<400>35SerValArgSerSerSerArgThrProSerAspLysProValAlaHis151015ValValAlaAsnProGlnAlaGluGlyGlnLeuGlnTrpLeuAsnArg202530ArgAlaAsnAlaLeuLeuAlaAsnGlyValGluLeuArgAspAsnGln354045LeuValValProSerGluGlyLeuTyrLeuIleTyrSerGlnValLeu505560PheLysGlyGlnGlyCysProSerThrHisValLeuLeuThrHisThr65707580IleSerArgIleAlaValSerTyrGlnThrLysValAsnLeuLeuSer859095AlaIleLysSerProCysGlnArgGluThrProGluGlyAlaGluAla100105110LysProTrpTyrGluProIleTyrLeuGlyGlyValPheGlnLeuGlu115120125LysGlyAspArgLeuSerAlaGluIleAsnArgProAspTyrLeuAsp130135140PheAlaGluSerGlyGlnValTyrPheGlyIleIleAlaLeu145150155<210>36<211>157<212>PRT<213>智人<400>36ValArgSerSerSerArgThrProSerAspLysProValAlaHisVal151015ValAlaAsnProGlnAlaGluGlyGlnLeuGlnTrpLeuAsnArgArg202530AlaAsnAlaLeuLeuAlaAsnGlyValGluLeuArgAspAsnGlnLeu354045ValValProSerGluGlyLeuTyrLeuIleTyrSerGlnValLeuPhe505560LysGlyGlnGlyCysProSerThrHisValLeuLeuThrHisThrIle65707580SerArgIleAlaValSerTyrGlnThrLysValAsnLeuLeuSerAla859095IleLysSerProCysGlnArgGluThrProGluGlyAlaGluAlaLys100105110ProTrpTyrGluProIleTyrLeuGlyGlyValPheGlnLeuGluLys115120125GlyAspArgLeuSerAlaGluIleAsnArgProAspTyrLeuAspPhe130135140AlaGluSerGlyGlnValTyrPheGlyIleIleAlaLeu145150155当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1