一种盲人导航方法、装置及终端设备与流程
本发明涉及盲人导航技术领域,具体涉及到一种盲人导航方法、装置及终端设备。
背景技术:
盲人(视障人士)由于视觉缺失,无法直接观察身边的环境,在出行时往往会有极大的不便利性和危险性。盲人必须依靠导盲基建(盲道、盲文标识)和辅助设备(导盲手杖,导盲犬等)进行户外活动。
视障人群户外活动需要应对复杂多变的路面情况,依靠导盲基建和辅助设备获得的路面信息有限,盲道上的障碍物的未知性、不确定性以及导盲基建本身也存在损毁的情况,依靠当前已有的导航系统,很难为视障人群的户外活动提供避障指引。
技术实现要素:
为了解决上述问题,本发明提供一种盲人导航方法、装置及终端设备,可以很好的为盲人提供避障指引。
本发明提出了一种盲人导航方法,其特征在于,包括以下步骤:
获取盲道信息;
根据所述盲道信息判断盲道是否有障碍;
如果有障碍,判断所述障碍为动态障碍或静态障碍;
根据所述障碍判断结果,为盲人进行不同的导航。
进一步的,还包括步骤:判断盲道是否连续,如果盲道不连续,则进一步判断盲道是否有障碍。
进一步的,所述判断所述障碍是动态障碍还是静态障碍具体为:采用动态检测算法对所述动态障碍进行检测,对检测出的所述动态障碍与预设障碍模板进行匹配,确定所述动态障碍;采用图像深度估计算法对所述静态障碍进行识别。
进一步的,所述根据障碍判断结果,为盲人进行导航具体为:如果为动态障碍,则指导盲人选择暂时停下或绕路行进,如果为静态障碍,则获取盲人与障碍的位置信息,根据所述位置信息为盲人进行导航。
进一步的,所述获取盲道信息具体为:采集盲道图像,对应的,判断盲道是否连续具体为:对所述盲道图像进行识别,根据识别结果判断盲道是否连续。
另一方面,本发明还提出了一种盲人导航装置,其特征在于,包括:
获取模块,用于获取盲道信息;
第一判断模块,用于根据所述盲道信息判断盲道是否有障碍;
第二判断模块,用于在所述盲道有障碍时,判断所述障碍为静态障碍或动态障碍;
导航模块,用于根据障碍判断结果,为盲人进行不同的导航。
进一步的,还包括第三判断模块,所述第三判断模块用于判断盲道是否连续。
进一步的,所述第二判断模块中,判断所述障碍是动态障碍还是静态障碍具体为:采用动态检测算法对所述动态障碍进行检测,对检测出的所述动态障碍与预设障碍模板进行匹配,确定所述动态障碍;采用图像深度估计算法对所述静态障碍进行识别。
进一步的,所述导航模块中,根据障碍判断结果,为盲人进行不同的导航具体为:如果为动态障碍,则指导盲人选择暂时停下或绕路行进,如果为静态障碍,则获取盲人与障碍的位置信息,根据所述位置信息为盲人进行导航。
再一方面,本发明还提出了一种盲人导航终端设备,包括以上所述的盲人导航装置。
本发明实施例提出的盲人导航方法、装置及终端设备,在获取盲道信息后,根据盲道信息判断盲道是否有障碍,在确定盲道有障碍时,进一步判断障碍是动态障碍还是静态障碍,根据判断结果为盲人进行不同的导航,从而可以使盲人在盲道上行走时,更好的对障碍进行规避,提高盲人在盲道上行走的安全性。
附图说明
图1为本发明实施例提供的盲人导航方法的流程图;
图2为本发明实施例提供的摄影测量原理图;
图3为本发明实施例提供的盲人导航装置的结构示意图;
图4为本发明实施例提供的盲人导航装置的另一结构示意图。
具体实施方式
为了使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述,这里的描述不意味着对应于实施例中陈述的具体实例的所有主题都在权利要求中引用了。
本发明下述各实施例提供的盲人导航方法,应用于终端设备。其中,该终端设备可以为移动终端如手机、PAD等。
下述通过多个具体的实例进行说明。
图1为本发明提供的一种盲人导航方法的流程图。该方法可由终端设备执行。如图1所示,该方法可包括:
S101、获取盲道信息;
具体地,获取盲道信息为采集盲道图像。
具体地,可以通过摄像头对盲道进行拍照,从而采集盲道图像。
S102、根据盲道信息判断盲道是否有障碍;
其中,图2为盲道被占用情况图;
进一步的,判断盲道是否有障碍具体为:对盲道图像进行识别,根据识别结果确定是否有障碍。
S103、如果有障碍,判断障碍为动态障碍或静态障碍;
进一步的,判断障碍为动态障碍或静态障碍具体为:采用动态检测算法对所述动态障碍进行检测,对检测出的所述动态障碍与预设障碍模板进行匹配,确定所述动态障碍;采用图像深度估计算法对所述静态障碍进行识别。
具体地,终端设备提前存储有障碍模板,建立障碍模板库,如果对于盲道图像采用动态检测算法检测出有障碍,则将障碍与障碍模板库中的障碍进行匹配,如果障碍与障碍模板库中的障碍模板匹配,则确定动态障碍。
下面具体描述实现过程。
对于动态障碍的识别通过以下步骤来实现:
首先,对摄像头拍摄的图像序列进行分离,实现对障碍的定位和识别。
对动态障碍的检测采用改进的背景差法、帧间差分法、光流法和前景建模法等。帧间差分(Frame Differencing)在相邻两帧(也可以为多帧)间计算逐个象素的灰度差,并通过设置阈值来确定对应运动前景的像素,进而得到运动前景区域,这是一种直接利用前景所特有的信息检测前景的方法。
利用双帧差分实现的运动检测如下:
如果In,In-1表示图像序列中任意相邻的两帧图像,则逐像素的差分图Dn可以由公式定义为如下的形式:
Dn(i,j)=|In(i,j)-In-1(i,j)|
对上述差分图阈值化(假设预先设定的阈值为T),即可确定运动前景区域Mn:
利用双帧差分、三帧差分进行动态障碍检测,基于图像模式库(Pattern Database),对得到的动态图像进行匹配,确定图像模式,从而确定出动态障碍。
对于静态障碍的识别通过以下步骤实现:
利用图像深度估计算法来对静态障碍进行识别。
该算法可分为内容理解和深度估计两部分:(1)理解街景图像的景物构成,对图像进行分块并进行特征提取,通过机器学习的方法依据图像块特征识别各类景物目标,获取图像内各个景物间的构图关系;(2)场景深度估计,根据相机小孔成像模型推导地面区域的深度和图像坐标之间的对应关系,完成地面区域的深度估计,然后依据景物与地面以及景物之间的构图关系估计场景内各个景物的深度信息。
A、图像内容理解
图像内容理解主要是依据景物特征从街景图像中识别每个景物目标,从而解析图像内的景物结构关系,为后续的深度估计做准备。
a、图像分块
一幅图像是由许多个具有RGB颜色信息的像素点所构成的2维阵列将图像内相似的像素点聚合成图像块,可以有效屏蔽底层像素特征的差异性和复杂性,有助于理解图像内容。首先将街景图像划为若干规则的像素块,并构造无向图G=(V,E)来进行描述,V表示图像的每一个像素块,E表示像块之间的相邻关系ω(vi,vj),通过对像素块V的合并聚类得到图像分块C,并建立相应的数学模型来描述图像块C内部各像素之间的一致性和相邻图像快C1,C2之间的差异性在初始状态,每个像素快V都是一个图像分块C,通过比较相邻图像快C1,C2之间的差异性和一致性,动态迭代优化对图像块合并聚类,直至获得最优的图像分块结果。
b.图像块特征提取
每类景物都有独特的特征,通过提取每个图像块自身的特征以及相邻图像块之间的相关特征,为判断图像块所属的景物类别提供依据。
1)图像块自身特征
颜色可以很直观的描述图像块的特征,现实生活中的很多景物对象都具有非常典型的颜色特征。例如:天空总是蓝色或白色的,且亮度高。
位置和形状特征也为识别景物目标提供了重要线索。在图像中,天空一般是位于图像的上方且对应的图像块具有较大面积,而地面则位于图像的下方。
纹理特征反映了图像块内部像素的复杂性和变化规律,也是图像识别中的重要特征。比如,树上大量的叶子交错掩映于万里无云的天空就是两种完全不同的纹理。
2)邻域图像块的联合特征
在图像分块时,不可能将每个对象都恰好分割成一个图像块,必然出现过分割的情况。那么,具有相似的颜色,纹理等特征的相邻图像块很可能属于同一个景物。而对于特征不相似的相邻图像模块,或者反映了同一个对象内的各个组成要素之间的关系。例如汽车是由车轮,车身,车窗3类不同特征的图像块依据一定的位置关系组成的;或者反映了图像内景物的组成结构。比如街景图象中天空一般不和地面相邻,汽车位于地面附近等线索。因此,每个图像块都与其邻域图像块快的特征存在一定关系,在提取图像块特征时,通过条件随机场模型对邻域图像块之间的特征相关性进行描述。
式中,景物类别为C,图像分块xi的邻域为S,特征集ψ中的各类特征为θk,函数gij表示相邻图像块xi和xj之间在特征上的相互影响关系。这里使用机器学习的方法通过训练样本中的街景图像进行学习训练得到式中的参数,然后根据上述公式可以计算图像块xi在其邻域S的各类特征作用下属于景物C的概率,即邻域联合特征。
c.图像块分类识别
根据提取的图像块特征,使用基于统计学习理论的SVM(支持向量机)分类器对图像进行分类识别。SVM的基本原理是:通过学习训练,在多个不同类型的样本(xi,xj)之间,寻找一个最优的分类面,使得该分类间隔最大,从而获得最佳的分类效果。具体实施步骤如下:1)对街景图象进行分块,并构建每个图像块xi的特征向量。一方面依据图像块xi自身的颜色,位置,纹理等特征构建特征向量;另一方面考察图像块xi与邻域图像块在各类特征之间的相关性,即根据上述公式计算图块xi在其邻域各类特征作用下属于景物C的概率,并以此来组织图像块邻域特征向量。
2)使用训练样本中街景图像的景物特征,采用交叉验证的方法选择适合的惩罚因子和核函数参数,完成对SVM分类器的训练。
3)将待分类图像中每个图像块对应的特征向量输入SVM分类器,判断该图像块所属的景物类别,得到街景图像的分类识别结果。
4)根据图像中景物目标分类的结果,确定每个景物的初始轮廓曲线,通过对Snake能量函数的动态迭代优化来精确提取景物目标轮廓,提高景物分类识别的精度。
按照以上的方法,依据街景图像中每个图像块的特征,使用SVM分类器判断该图像块所属的景物类别,从街景图像中识别各个景物目标,获取景物之间的相对位置关系,理解街景图像的景物组成结构。
B.图像深度估计
结合人的深度认知,通过分析理解图像内景物之间的构图关系,首先估计地面区域的深度,并以地面的深度为参考,根据景物和地面的相对位置以及景物之间的前后遮挡关系,依次确定每个景物的深度信息。
a.天空
在真实世界中,天空与相机拍摄位置之间的距离远大于其他位置目标,可以近似认为是无限远的。因此相对于其他景物,天空的深度可以认为是最大的。在处理图像中的天空区域时,可以直接在灰度深度图中将其深度指为最大值。
b.地面
地面区域的深度估计是整幅图像深度估计的基础,通过分析相机的小孔成像模型,可以估计地面区域的深度信息。
在理想条件下,认为相机成像模型符合小孔成像模型,因此依据小孔成像模型推导出真实世界中地面点G的深度和它在相机中所成像点g的图像坐标之间的对应关系。对于大多数的街景图像,真实景物的深度(即物距)要远大于景物所成像的距离。根据凸透镜成像原理,可近似认为景物所成的像都位于相机焦平面上。基于上面的假设,可以推理景物深度和成像之间的关系。
小孔成像模型图
根据小孔成像模型,所有的光线均经过相机镜头的光心o点,主光轴与地面倾斜角为∠cop,像平面中心点c坐标为vc,地面点G所成的像点坐标g的坐标为vg,图像中地平线上点p的坐标为vp,且相机感光CCD(电荷耦合器)器件的实际尺寸与图像像素坐标之间的比例关系为s,那么可以得到如下关系:
上式反映了景物深度和所成像之间的对应关系,其中f和s可以根据街景图像文件属性中记录的相机拍摄参数获得,而相机高度yc则由于街景图像一般是由摄影师手持相机进行拍摄的,可近似的认为yc为1.5米。首先通过计算街景图像中的灭点,天地边缘特征等方法估计街景图像内的地平线位置,获取地平线对应的坐标vp,然后结合像平面中心坐标vc,计算地面区域像素点G的深度信息。通过实验分析,发现该公式也适用于拍摄时相机旋转所导致的图像中地平线不水平的情况。此时,需要依据图像的灭点等特征估计图像中地平线的位置,并旋转图像将地平线调制水平,再根据旋转之后地面区域像素点的坐标使用上式计算图像中地面区域的深度,完成对街景图像地面区域的深度估计。
C.其他景物
a.根据景物与地面相对位置估计深度
按照人的深度认知,街景图像中的汽车,建筑物等景物都是直立与地面之上的。因此。在获得图像中地面区域深度后,以图像中地面区域作为深度参考面,依据景物与地面之间的相对位置关系,在景物正下方检测提取其与地面交线lc,然后根据深度估计式(上式),按照交线lc上每个像素点的图像坐标可以计算景物与地面相交位置lc的深度,从而确定该景物目标的深度信息。
b.景物与地面相对位置缺失时的深度估计
由于遮挡和成像范围的限制,拍摄的图片中可能存在某些景物与地面的相对位置关系无法确定的情况,此时无法通过地面估计景物的深度信息。但是,如果事先知道景物本身或者其中的一部分的真实尺寸,那么根据相机的小孔成像模型,通过比较景物目标的真实尺寸和对应的像的尺寸,就可以估计该景物的深度信息。
如上图所示,景物AB的深度d,其真实尺寸为yAB,已知物点A和B分别成像于像平面vavb,那么根据三角函数的比例关系,即yAB=d(tan∠pob+tan(∠poc+∠aoc)),可以推导出景物的实际尺寸,像的尺寸和深度之间的关系:
如果已知景物的真实尺寸yAB,根据上式,通过比较景物的真实尺寸yAB和像的尺寸va-vb,可以估计该景物对应的深度。
但是,对于某些特征不明显的景物,可能无法根据先验知识获取景物某部分的真实尺寸。此时,仅仅通过单幅图像中所蕴含的深度视觉线索无法正确的估计景物的深度信息。对于此,引入深度分层参数L,通过分析图像内景物X与其邻近景物之间的构图关系,找出在深度上与景物X相邻的景物目标Y,然后根据景物X和景物Y之间的前后遮挡关系在景物Y的深度上添加或减去深度分层参数L,得到景物X的深度,以区分景物X和它邻近的景物Y是处于不同的深度层次之上。
dX=dY±L
通过使用大量的街景图像进行实验对比,发现将图像的总深度分为25个层次时(即L=255/25),人眼在前后两个相邻深度层的景物对象之间就可以感觉到十分明显的深度层次差异。
c.景物自身深度变化趋势的估计
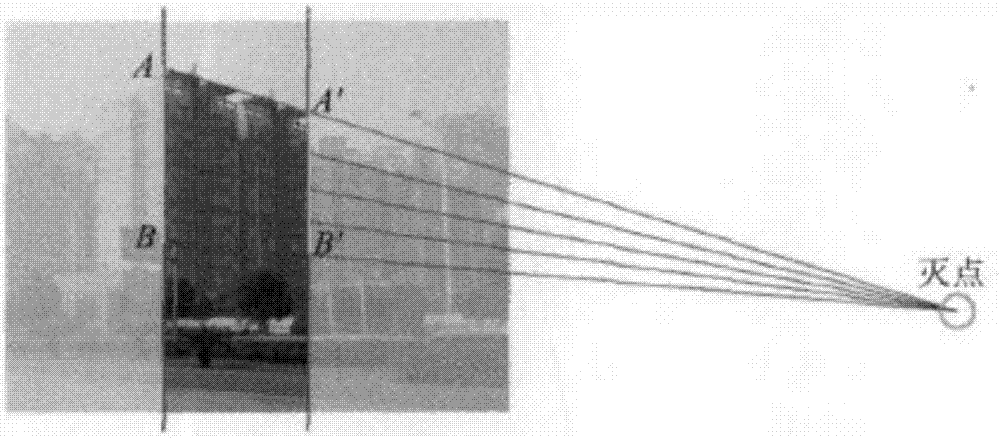
在街景图像中,对于建筑物这种大尺度的景物目标,其自身的深度可能会出现较大的变化。而Hoiem只是按照景物与地面的相对位置确定每个景物的深度。当建筑物的正面沿街分布时,得到的景物深度基本正确,但是,在街景图心中,很多建筑物的走向并不是沿街的,靠近街边地面处的部分和远离街边的部分在深度上完全不同。为了获得准确的景物深度信息,需要结合摄影测量原理,估计每个建筑物在深度方向上的变化趋势。
摄影测量原理
对于一幅街景图,首先使用HOUGH变换提取建筑物对象中的直线,根据摄影测量理论,将建筑物对象中提取的直线延长寻找这些直线的交点(即灭点),并结合建筑物的颜色,边缘等特征从建筑物区域中区分出每栋建筑物的边界及其走势(途中的AB和A′B′),如图2所示。根据建筑物和地面之间的相对位置关系,可以确定建筑物靠近街边部分的深度dAB(AB处的深度)等于其正下方地面的深度,并且由于真实世界中该建筑物目标的边缘AB和A′B′具有同样的尺寸(即yAB=yA′B′).因此根据前面的公式可以推导图像中景物特征的变化趋势和深度之间的关系:
根据上述公式,通过估计图像中建筑物目标的变化趋势可以计算该建筑物对象内部每个像素点对应的深度信息,从而得到景物自身的深度变化,使得景物目标的深度估计结果能够反映其在真实世界的深度分布。
S104、根据障碍判断结果,为盲人进行不同的导航。
进一步的,根据障碍判断结果,为盲人进行导航具体为:如果为动态障碍,则指导盲人选择暂时停下或绕路行进,如果为静态障碍,则获取盲人与障碍的位置信息,根据该位置信息为盲人进行导航。
进一步的,还包括步骤:判断盲道是否连续,如果盲道不连续,则进一步判断盲道是否有障碍。
具体地,判断盲道是否连续通过对采集盲道图像进行识别来确定。
具体地,可以通过终端设备的摄像头对盲道进行拍照,通过对采集的盲道图像进行识别来确定盲道是否连续。
另外,还可以通过导航仪和群智感知数据进行即时的判断,看是否前方路段由于事故、施工或者遭到破坏等原因无法通行,如果是这种情况,则导航装置为盲人进行二次路径的规划,重新择路。
针对视障人士导航过程中盲道障碍的距离测算,可以利用摄像头按一定间隔先后捕获两张障碍图像信息,根据先后两张图像中事物尺寸的变化,结合相机透镜组组成像原理,计算出距离障碍的距离。用户对同一目标连续拍摄两张照片,假设得到两张照片成像的大小为图中的z1,z2,由成像原理得到公式(其中d为物距,l为像距,f为焦距,k=z1/z2,Δd=d1-d2),并可通过该公式得到物距d的计算公式。
1/l+1/d=1/f
z*d=s*l
d2-k*d1=f*(1-k)
用户拍摄两张照片之间手臂伸展长度可以通过加速度传感器获取到,即可得到Δd,这
样k和Δd都已知,即可求出d1和d2,从而得到目标的距离。
在实际照相时,手机角度发生一个小的改变会导致捕获对象发生移动,测量照片中目标对象的尺寸时对手机的旋转进行补偿是非常必要的。当手机旋转r角时,物体的投影由原来的h1变为h2,图像位置运动公式为:
Δh=h2-h1=f·tan(β+γ)-tanβ
≈f·γ·sec2(β)≈f·γ
焦距f是一个内在的参数可以从摄像头属性参数获得的,而旋转角度可以通过终端设备的陀螺仪来进行获取,则物体的移动距离Δh由公式即可得到。
当有障碍阻挡无法直行通过时,移动导盲装置可以通过处理从路面上捕获的多模数据得到障碍的空间信息和与用户之间的相对位置,利用像素点和地磁传感器和陀螺仪读数计算补偿角度范围,通过语音提示绕过障碍,如果障碍不可逾越则需要为用户重新规划行走路径,用户如何绕过障碍。
本发明实施例提出的盲人导航方法,在获取盲道信息后,根据盲道信息判断盲道是否有障碍,在确定盲道有障碍时,进一步判断障碍是动态障碍还是静态障碍,根据判断结果为盲人进行导航,从而可以使盲人在盲道上行走时,更好的对障碍进行规避,提高盲人在盲道上行走的安全性。
如图3所示,本发明实施例还提供了一种盲人导航装置,包括:
获取模块21,用于获取盲道信息;
第一判断模块22,用于根据盲道信息判断盲道是否有障碍;
第二判断模块23,用于在盲道有障碍时,判断障碍为动态障碍或静态障碍;
导航模块24,用于根据障碍判断结果,为盲人进行不同的导航。
本发明实施例提出的盲人装置,在获取盲道信息后,根据盲道信息判断盲道是否有障碍,在确定盲道有障碍时,进一步判断障碍是动态障碍还是静态障碍,根据判断结果为盲人进行导航,从而可以使盲人在盲道上行走时,更好的对障碍进行规避,提高盲人在盲道上行走的安全性。
进一步的,如图4所示,还包括第三判断模块25,第三判断模块25用于判断盲道是否连续。
进一步的,第二判断模块23中,判断障碍为动态障碍或静态障碍具体为:采用动态检测算法对所述动态障碍进行检测,对检测出的所述动态障碍与预设障碍模板进行匹配,确定所述动态障碍;采用图像深度估计算法对所述静态障碍进行识别。
进一步的,导航模块24中,根据障碍判断结果,为盲人进行导航具体为:如果为动态障碍,则指导盲人选择暂时停下或绕路行进,如果为静态障碍,则获取盲人与障碍的位置信息,根据该位置信息为盲人进行导航。
进一步的,获取模块21中获取盲道信息具体为:采集盲道图像,对应的,第三判断模块25中,判断盲道是否连续具体为:对盲道图像进行识别,根据识别结果判断盲道是否连续。
本发明实施例还提供了一种盲人导航终端设备,包括上述的盲人导航装置。
本发明实施例提出的盲人导航终端设备,在获取盲道信息后,根据盲道信息判断盲道是否有障碍,在确定盲道有障碍时,进一步判断障碍是动态障碍还是静态障碍,根据判断结果为盲人进行导航,从而可以使盲人在盲道上行走时,更好的对障碍进行规避,提高盲人在盲道上行走的安全性。
其中,盲人导航终端设备可以为手机、PAD等移动终端设备。
获取模块21可以通过终端设备的摄像头来采集盲道图像的方式获取盲道信息。
第一判断模块22、第二判断模块23、第三判断模块25均可通过终端设备的处理器来执行。
此外,终端设备还包括存储器,用于存储盲道信息。
此外,终端设备具有多模传感器,如陀螺仪、加速度传感器、地磁传感器、电子罗盘、摄像头、GPS导航模块等,可以通过这些传感器和摄像头进行感知数据的获取。
如加速度传感器、陀螺仪可以用来采集加速度数据、角速度数据,内置摄像头可以用来录像和拍摄照片,内置的麦克风可以用来采集语音数据,GPS导航模块可以确定当前的位置,每个用户利用自己的手机对所在的地理位置进行感知数据的采集,如拍摄该地理位置的路况照片,并且读取拍摄时的地理位置的经纬度,陀螺仪的角度,光照等传感器信息,这些感知数据进行存储。
需要说明的是:对于这些数据的处理可以通过终端设备本身的处理器进行处理,也可以通过发送给服务器,通过服务器来处理,然后服务器将处理结果传送给终端设备。本发明对此并不做具体限定。
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:ROM、RAM、磁碟或者光盘等各种可以存储程序代码的介质。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!