基于海量大气污染浓度数据的污染空间分析方法及装置与流程
本发明涉及大气污染监测技术领域,具体涉及一种基于海量大气污染浓度数据的污染空间分析方法及装置。
背景技术:
为推进空气质量改善,落实属地环保责任,按照清洁空气行动计划要求,北京市制定了《北京市2013-2017年清洁空气行动计划实施情况考核办法(试行)》(京政办发〔2014〕61号)和《北京市2013-2017年清洁空气行动计划实施情况考核办法(试行)实施细则》(京环发〔2014〕92号),每年对各区空气质量改善情况和清洁空气行动计划任务完成情况进行考核。传统的监测网络受人力和物力的制约,空间分辨率较粗,只针对空气质量进行常规监测,无法实时分析区内污染特征,定位疑似污染源,更产生不了精细化监测产品,落实属地管理和调动基层环保力量进行执法监管存在较大难度。
国家知识产权局于2017年3月22日公开了申请号为201510564563.8,名称为《基于大密度部署传感器的大气污染监控及管理方法及系统》的发明专利,该发明通过在区域内大密度部署传感器,并对返回的传感器数据采用云端算法进行联合校正,并进一步采用高斯推断模型在空间上推断出未部署传感器位置点的大气污染数据,再将上述已部署和未部署传感器位置点的大气污染物数据统一反馈给监控中心,进行监控和管理,以实现实时监测取证,量化评级及精细化管理的目标。但是,该发明只是将传感器数据反馈给监控中心,并未对大气污染数据进行后续处理。
技术实现要素:
本发明要解决的技术问题是提供一种基于海量大气污染浓度数据的污染空间分析方法及装置,其能够获得区县级别的空气质量变化精细化特征,并能够甄别本地的污染源特征,为环境管理形成更为系统化的技术支撑。
为解决上述技术问题,本发明提供技术方案如下:
一种基于海量大气污染浓度数据的污染空间分析方法,包括:
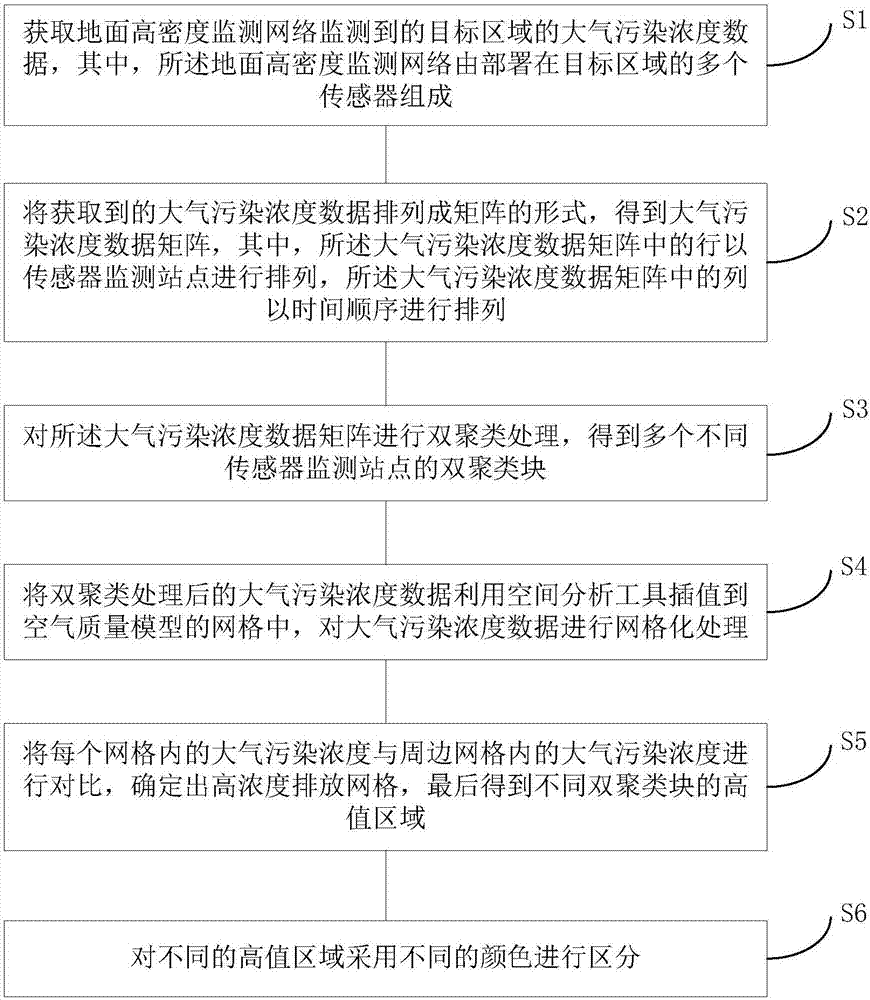
步骤1:获取地面高密度监测网络监测到的目标区域的大气污染浓度数据,其中,所述地面高密度监测网络由部署在目标区域的多个传感器组成;
步骤2:将获取到的大气污染浓度数据排列成矩阵的形式,得到大气污染浓度数据矩阵,其中,所述大气污染浓度数据矩阵中的行以传感器监测站点进行排列,所述大气污染浓度数据矩阵中的列以时间顺序进行排列;
步骤3:对所述大气污染浓度数据矩阵进行双聚类处理,得到多个不同传感器监测站点的双聚类块;
步骤4:将双聚类处理后的大气污染浓度数据利用空间分析工具插值到空气质量模型的网格中,对大气污染浓度数据进行网格化处理;
步骤5:将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,确定出高浓度排放网格,最后得到不同双聚类块的高值区域。
进一步的,所述步骤5之后还包括:
步骤6:对不同的高值区域采用不同的颜色进行区分。
进一步的,所述步骤3包括:
步骤31:将大气污染浓度数据矩阵分割成若干个子矩阵;
步骤32:计算第n个子矩阵的平均平方残基打分函数h(i,j)和子矩阵中每行和每列的平均残基a(i)和a(j):
其中,n大于等于1且小于等于子矩阵的总个数,|i|和|j|分别为子矩阵的行数和列数,aij为子矩阵的元素的值,aij、aij和aij分别为子矩阵中第i行的平均值、第j行的平均值和子矩阵整体的平均值,即:
若h(i,j)>δ,则执行步骤33,若h(i,j)≤δ,该子矩阵形成双聚类块,并且结束,其中,δ为预先设定的最大平均平方剩余分数;
步骤33:将所述子矩阵中最大的a(i)或a(j)对应的行或列删除;
步骤34:将所述子矩阵中最小的a(i)或a(j)对应的行或列添加到子矩阵中,之后转至所述步骤32。
进一步的,所述步骤3还包括:当一个双聚类块形成后,使用随机数代替已经形成的双聚类块中的元素的值,之后对其它的子矩阵进行双聚类处理。
进一步的,所述步骤5中,将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比时,采用等值线、阴影图、栅格图或填色图进行对比。
一种基于海量大气污染浓度数据的污染空间分析装置,包括:
获取模块:用于获取地面高密度监测网络监测到的目标区域的大气污染浓度数据,其中,所述地面高密度监测网络由部署在目标区域的多个传感器组成;
大气污染浓度数据矩阵建立模块:用于将网格化处理后的大气污染浓度数据排列成矩阵的形式,得到大气污染浓度数据矩阵,其中,所述大气污染浓度数据矩阵中的行以传感器监测站点进行排列,所述大气污染浓度数据矩阵中的列以时间顺序进行排列;
双聚类处理模块:用于对所述大气污染浓度数据矩阵进行双聚类处理,得到多个不同的双聚类块;
网格化处理模块:用于将获取的大气污染浓度数据利用空间分析工具插值到空气质量模型的网格中,对大气污染浓度数据进行网格化处理;
高值区域建立模块:用于将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,确定出高浓度排放网格,最后得到不同双聚类块的高值区域。
进一步的,所述高值区域建立模块之后还包括:
高值区域区分模块:用于对不同的高值区域采用不同的颜色进行区分。
进一步的,所述双聚类处理模块包括:
子矩阵分割模块:用于将大气污染浓度数据矩阵分割成若干个子矩阵;
计算模块:用于计算第n个子矩阵的平均平方残基打分函数h(i,j)和子矩阵中每行和每列的平均残基d(i)和d(j):
其中,n大于等于1且小于等于子矩阵的总个数,|i|和|j|分别为子矩阵的行数和列数,aij为子矩阵的元素的值,aij、aij和aij分别为子矩阵中第i行的平均值、第j行的平均值和子矩阵整体的平均值,即:
若h(i,j)>δ,则进入删除模块,若h(i,j)≤δ,该子矩阵形成双聚类块,并且结束,其中,δ为预先设定的最大平均平方剩余分数;
删除模块:用于将所述子矩阵中最大的a(i)或a(j)对应的行或列删除;
添加模块:用于将所述子矩阵中最小的a(i)或a(j)对应的行或列添加到子矩阵中。
进一步的,所述双聚类处理模块还包括:用于当一个双聚类块形成后,使用随机数代替已经形成的双聚类块中的元素的值,之后对其它的子矩阵进行双聚类处理。
进一步的,所述高值区域建立模块中,将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比时,采用等值线、阴影图、栅格图或填色图进行对比。
本发明具有以下有益效果:
与现有技术相比,本发明的基于海量大气污染浓度数据的污染空间分析方法及装置,通过在目标区域部署多个传感器建立地面高密度监测网络获取目标区域的大气污染浓度数据,并对目标区域的大气污染浓度数据进行双聚类处理得到不同的双聚类块,之后将双聚类处理后的大气污染浓度数据利用空间分析工具插值到空气质量模型的网格中,并将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,确定出高浓度排放网格,最后得到不同双聚类块的高值区域,并获得污染区域范围及边界、污染强度、高污染发生的频率,结合污染源排放数据和污染源调查,能够认识高值区域形成的污染源排放原因,支持市及区县展开污染排放的监察及控制。本发明利用了基于传感器地面高密度监测网络产生的海量数据进行空气质量排名和高值区识别,这些数据与传统的卫星遥感数据相比,时空分辨率较高且数据质量可靠,能够获得区县级别的空气质量变化精细化特征,形成甄别本地污染源特征的分析方法,为环境管理形成更为系统化的技术支撑。
附图说明
图1为本发明的基于海量大气污染浓度数据的污染空间分析方法的流程示意图;
图2为本发明的基于海量大气污染浓度数据的污染空间分析方法中对污染浓度数据进行双聚类处理的流程示意图;
图3为在北京市采用本发明的基于海量大气污染浓度数据的污染空间分析方法的地面高密度监测网络的布置示意图;
图4为北京市传统监测站点的布置示意图;
图5为对大气污染数据直接插值网格化与采用本发明的基于海量大气污染浓度数据的污染空间分析方法对大气污染浓度数据进行插值网格化的对比示意图,其中(a)为对大气污染数据直接插值网格化后的示意图,(b)为采用本发明的基于海量大气污染浓度数据的污染空间分析方法对大气污染浓度数据进行插值网格化后的示意图;
图6为采用本发明的基于海量大气污染浓度数据的污染空间分析方法及装置获得的北京某地区及其周边地区在某一时间段pm2.5浓度的变化示意图,其中(a)为工作日pm2.5浓度日变化的示意图,(b)为休息日pm2.5浓度日变化的示意图;
图7为采用本发明的基于海量大气污染浓度数据的污染空间分析方法及装置得到的北京市存在的污染源的示意图;
图8为本发明的基于海量大气污染浓度数据的污染空间分析装置的结构示意图;
图9为本发明的基于海量大气污染浓度数据的污染空间分析装置中双聚类处理模块的结构示意图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
一方面,本发明提供一种基于海量大气污染浓度数据的污染空间分析方法,如图1至图7所示,包括:
步骤s1:获取地面高密度监测网络监测到的目标区域的大气污染浓度数据,其中,地面高密度监测网络由部署在目标区域的多个传感器组成;
本步骤中,通过在目标区域内大密度部署传感器,利用传感器获取目标区域在特定的气象条件下的大气污染浓度数据,与传统的监测网络站点检测到的数据相比,时空分辨率较高且数据质量可靠。
本步骤中,以北京地区为例,如图3所示,在整个北京地区部署1500个左右的传感器,这些传感器的部署原则是:均匀覆盖、重点加密、弹性布设,平原地区每3x3公里至少部署一个传感器监测站点,山区每8x8公里至少部署一个传感器监测站点。
本步骤将多个传感器部署在近地面层,且传感器的分布密度远高于现有监测站,如图3和图4所示,因此经过混合反演可以得到该平面上空间精度小于500米的连续污染浓度指标。
步骤s2:将获取到的大气污染浓度数据排列成矩阵的形式,得到大气污染浓度数据矩阵,其中,大气污染浓度数据矩阵中的行以传感器监测站点进行排列,大气污染浓度数据矩阵中的列以时间顺序进行排列;
本步骤中,以北京地区为例,获取的大气污染浓度数据的矩阵如下:
其中,c1~cm表示m个传感器监测站点,r1~rn表示时间,aij表示第i个传感器在j时间监测到的大气污染浓度的数据。
步骤s3:对大气污染浓度数据矩阵进行双聚类处理,得到多个不同传感器监测站点的双聚类块;
由于传感器监测到的数据存在大量无关属性、分布较为稀疏、有较多局部信息的特征,使得基于距离或密度的传统聚类算法无法发现有价值的信息,而本步骤中采用双聚类算法对大气污染浓度数据进行处理,双聚类在矩阵的行和列两个方向上同时聚类,可以应用于不宜使用对象的所有属性度量对象的相似性,从而得到质量更高的聚类结果。
步骤s4:将双聚类处理后的大气污染浓度数据利用空间分析工具插值到空气质量模型的网格中,对大气污染浓度数据进行网格化处理;
本步骤中的空气质量模型可以采用多尺度空气质量模型(即cmaq模型)或综合空气质量模型和扩展(即camx模型)。
步骤s5:将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,确定出高浓度排放网格,最后得到不同双聚类块的高值区域;
本步骤中,通过将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,即可确定出高浓度排放网格。在不同的传感器监测站点的双聚类结果下,形成不同聚类的高值区,以便更好的对每个区域进行差别对待,形成高中筛高,低中取高的效果。
本发明的基于海量大气污染浓度数据的污染空间分析方法通过在目标区域部署多个传感器建立地面高密度监测网络获取目标区域的大气污染浓度数据,并对目标区域的大气污染浓度数据进行双聚类处理得到不同的双聚类块,之后将双聚类处理后的大气污染浓度数据利用空间分析工具插值到空气质量模型的网格中,并将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,确定出高浓度排放网格,最后得到不同双聚类块的高值区域,并获得污染区域范围及边界、污染强度、高污染发生的频率,结合污染源排放数据和污染源调查,能够认识高值区域形成的污染源排放原因,支持市及区县展开污染排放的监察及控制。本发明将多个传感器部署在近地面层,且传感器的分布密度远高于现有监测站,因此经过混合反演可以得到该平面上空间精度小于500米的连续污染浓度指标。本发明利用了基于传感器地面高密度监测网络产生的海量大气污染浓度数据进行空气质量排名和高值区识别,这些数据与传统的卫星遥感数据相比,时空分辨率较高且数据质量可靠,能够获得区县级别的空气质量变化精细化特征,形成甄别本地污染源特征的分析方法,为环境管理形成更为系统化的技术支撑。
本发明采用先将获取到的大气污染浓度数据进行双聚类处理,然后对双聚类处理后的大气污染浓度数据插值并进行网格化,由于双聚类处理后的大气污染浓度数据的质量更高,其网格化后的数据与直接对获取到的气污染浓度数据插值并进行网格化相比,如图5所示,可以更加微观、细致的反应局部地区污染情况变化趋势,实现“地面大气污染浓度监测的全覆盖”,即目标区域浓度估算。
本发明名称中的“空间”具体指的是目标区域近地面层的平面空间。
进一步的,步骤s5之后还优选包括:
步骤s6:对不同的高值区域采用不同的颜色进行区分。
本步骤中,通过对不同的高值区域采用不同的颜色进行区分,能够更明显有效地区分出不同浓度的区域。本实施例优选紫色为大气污染浓度最高的区域,红色次之,接下来依次为橙色、黄色,绿色为大气污染浓度最低的区域,即空气质量为优。
优选的,如图2所示,步骤s3可以包括:
步骤31:将大气污染浓度数据矩阵分割成若干个子矩阵;
本步骤中,已知大气污染浓度的矩阵a如下,其中行(时间)集合(r1,r2,…,rn)记为x,列(传感器监测站点)集合(c1,c2,…,cm)记为y,矩阵a中元素aij表示第i个传感器监测站点在j时间监测到的大气污染物的浓度。
现有一个集合i∈x和j∈y,则矩阵aij=(i,j)为原矩阵a的一个子矩阵。
步骤s32:计算第n个子矩阵的平均平方残基打分函数h(i,j)和子矩阵中每行和每列的平均残基d(i)和d(j):
其中,n大于等于1且小于等于子矩阵的总个数,|i|和|j|分别为子矩阵的行数和列数,aij为子矩阵的元素的值,aij、aij和aij分别为子矩阵中第i行的平均值、第j行的平均值和子矩阵整体的平均值,即:
若h(i,j)>δ,则执行步骤s33,若h(i,j)≤δ,该子矩阵形成双聚类块,并且结束,其中δ为预先设定的最大平均平方剩余分数;
本步骤中,当对其中一个子矩阵aij进行双聚类时,如果存在一个δ≥0,使得子矩阵aij的平均平方残基打分函数h(i,j)≤δ,则该子矩阵aij则形成一个双聚类块。
步骤s33:将该子矩阵中最大的a(i)或a(j)对应的行或列删除;
本步骤优选采用贪心算法策略,通过删除行或列来寻找一个平均平方残基打分函数值尽可能小、块的尺寸尽可能大的双聚类块,如图2所示。
当采用删除行或列的方式时,首先初始化一个包含矩阵a的全部行和全部列的聚类块,然后在一个循环中不断地删除当前聚类块的行或列以期达到降低平均平方残基打分函数h(i,j)的目的,直至h(i,j)小于等于预先设定的δ时循环终止。
步骤s34:将该子矩阵中最小的a(i)或a(j)对应的行或列添加到子矩阵中,之后转至步骤s32。
由于通过删除操作,得到的双聚类块的平均平方残基打分函数h(i,j)有可能不是最大的,因此某些剩余的行和列有可能可以被添加进去,只要保证双聚类块的平均平方残基打分函数h(i,j)小于等于预先设定的δ即可。
由于双聚类算法是确定的,所以对同一数据集重复使用上述双聚类算法每次找到的双聚类模块都是同一个,并不能找出第二个双聚类块。因此,为了找到多个双聚类块,步骤s32还优选包括:当一个双聚类块形成后,使用随机数代替已经形成的双聚类块中的元素的值,之后对其它的子矩阵进行双聚类处理。
进一步的,步骤s5中,将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比时,优选采用等值线、阴影图、栅格图或填色图进行对比。通过采用等值线、阴影图、栅格图或填色图等方式进行大气污染浓度的空间专题分析,分析内容涵盖实时、小时、日均、月均等时间尺度目标区域精细污染空间分布图。
采用本发明的方法甄别本地污染源时,主要是分析某一网格与周边网格平均浓度日变化的同比变化情况,如果该网格在某几个小时比方上下班或者夜间浓度高,说明该网格存在一定的污染源排放。之后采用实地调查或者卫星遥感的方法,将该网格周边的排放源情况结合污染物浓度变化分析,即可甄别本地污染源突变情况。
下面以图6为例进一步说明。
采用本发明的方法得到北京市某地区在2016年12月16日-12月19日的pm2.5浓度变化情况及其与周边地区的pm2.5浓度的对比情况,如图6所示,其中图6(a)为2016年12月16日及12月19日(工作日)的pm2.5浓度变化情况,图6(b)为2016年12月17日和12月18日(休息日)的pm2.5浓度变化情况。由此可知,该地区pm2.5浓度在凌晨时段明显比周边地区高,工作日凌晨3点最大高于周边272ug/m3。根据结果可选择在凌晨0-7点进行现场排查或通过遥感卫星排查污染产生的原因。
图7中显示了在北京市使用本发明的基于海量大气污染浓度数据的污染空间分析方法及装置得到的北京市存在的pm2.5浓度污染源的示意图,其中3条虚线表示北京市存在的污染带。目前发现城六区加海淀朝阳,pm2.5分布比较均匀(图7中虚线圆圈部分)。南部的污染带主要分布在房山南部至大兴中心部一线,和通州大兴的六环沿线地区。北部污染带主要是昌平-顺义-平谷一线。其中,房山南部至大兴中心部一线上(即西南线),1表示大兴区庞各庄镇(pm2.5浓度160ug/m3),2表示大兴区礼贤镇(pm2.5浓度159ug/m3),3表示大兴区北藏村镇(pm2.5浓度158ug/m3),4表示大兴区榆垡镇(pm2.5浓度151ug/m3),5表示房山区窦店镇(pm2.5浓度151ug/m3),6表示房山区琉璃河镇镇(pm2.5浓度149ug/m3),7表示房山区良乡镇(pm2.5浓度149ug/m3),8表示房山区长沟镇(pm2.5浓度148ug/m3),9表示房山区石楼镇(pm2.5浓度148ug/m3)。通州大兴的六环沿线上(即东南线),1表示大兴区魏善庄镇(pm2.5浓度150ug/m3),2表示通州区张家湾镇(pm2.5浓度147ug/m3),3表示大兴区青云店镇(pm2.5浓度145ug/m3),4表示通州区永乐店镇(pm2.5浓度144ug/m3),5表示通州区马驹桥镇(pm2.5浓度143ug/m3)。昌平-顺义-平谷一线上(即北线),1表示顺义区李桥镇(pm2.5浓度133ug/m3),2表示顺义区南法信镇(pm2.5浓度126ug/m3),3表示顺义区南彩镇(pm2.5浓度126ug/m3),4表示顺义区北务镇(pm2.5浓度125ug/m3),5表示昌平区百善镇(pm2.5浓度123ug/m3),6表示顺义区李遂镇(pm2.5浓度123ug/m3),7表示顺义区马坡镇(pm2.5浓度122ug/m3),8表示平谷区马坊镇(pm2.5浓度122ug/m3),9表示平谷区兴谷街9道镇(pm2.5浓度118ug/m3)。
通过本发明的基于海量大气污染浓度数据的污染空间分析方法,可后期针对3条污染带上的6区23镇采取监察及控制,可落实属地责任、全面摸排,全面整治、“一镇(街道)一策”;细化责任分解、细化落实方案、解决环保工作“最后一公里”。
综上,本发明通过在目标区域大密度部署传感器监测站点,获取海量大气污染浓度数据,通过双聚类与大气污染浓度空间网格化热力图相结合的方法,识别高污染发生的区域,并获得污染区域范围及边界、污染强度、高污染发生的频率,结合污染源排放数据与污染源调查,认识高污染区域形成的污染源排放原因,支持市及区县展开污染排放的监察及控制。潜在的应用对象包括小工业集中区域、大型工业园区、物流集中区域、城乡结合部、城中村等。首先,本发明将监测结果的空间精度从离散稀疏的点位读数扩展为时空连续的面测量值。由于绝大多数监测网络设备(即传感器)处于近地面层,且分布密度远高于现有监测站,因此经过混合反演可以得到该平面上空间精度小于500米的连续污染浓度指标。其次,采用大数据分析手段,从时域和空间指标两个方面,提取高于背景浓度场的高值区域和疑似源。其中,时域指标表征高值区域和疑似源的持续时间和周期性规律,空间指标表征高值区域和疑似源的污染程度和影响范围。综合采用以上两类指标集,量化评估高值区域和疑似源的污染贡献排序,为后续模型和决策支持提供原始排查清单和优先级排序。
另一方面,本发明提供一种基于海量大气污染浓度数据的污染空间分析装置,如图8和图9所示,包括:
获取模块1:用于获取地面高密度监测网络监测到的目标区域的大气污染浓度数据,其中,地面高密度监测网络由部署在目标区域的多个传感器组成;
大气污染浓度数据矩阵建立模块2:用于将获取到的大气污染浓度数据排列成矩阵的形式,得到大气污染浓度数据矩阵,其中,大气污染浓度数据矩阵中的行以传感器监测站点进行排列,大气污染浓度数据矩阵中的列以时间顺序进行排列;
双聚类处理模块3:用于对大气污染浓度数据矩阵进行双聚类处理,得到多个不同的双聚类块;
网格化处理模块4:用于将双聚类处理后的大气污染浓度数据利用空间分析工具插值到空气质量模型的网格中;
高值区域建立模块5:用于将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,确定出高浓度排放网格,最后得到不同双聚类块的高值区域。
本发明的基于海量大气污染浓度数据的污染空间分析装置,通过在目标区域部署多个传感器建立地面高密度监测网络获取目标区域的大气污染浓度数据,并对目标区域的大气污染浓度数据进行双聚类处理得到不同的双聚类块,之后将双聚类处理后的大气污染浓度数据利用空间分析工具插值到空气质量模型的网格中,并将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比,确定出高浓度排放网格,最后得到不同双聚类块的高值区域,并获得污染区域范围及边界、污染强度、高污染发生的频率,结合污染源排放数据和污染源调查,能够认识高值区域形成的污染源排放原因,支持市及区县展开污染排放的监察及控制。本发明将多个传感器部署在近地面层,且传感器的分布密度远高于现有监测站,因此经过混合反演可以得到该平面上空间精度小于500米的连续污染浓度指标。本发明利用了基于传感器地面高密度监测网络产生的海量数据进行空气质量排名和高值区识别,这些数据与传统的卫星遥感数据相比,时空分辨率较高且数据质量可靠,能够获得区县级别的空气质量变化精细化特征,形成甄别本地污染源特征的分析方法,为环境管理形成更为系统化的技术支撑。
进一步的,高值区域建立模块5之后还优选包括:
高值区域区分模块6:用于对不同的高值区域采用不同的颜色进行区分。高值区域区分模块6通过对不同的高值区域采用不同的颜色进行区分,能够更明显有效地区分出不同浓度的区域。本实施例优选紫色为大气污染浓度最高的区域,红色次之,接下来依次为橙色、黄色,绿色为大气污染浓度最低的区域,即空气质量为优。
优选的,双聚类处理模块3可以包括:
子矩阵分割模块31:用于将大气污染浓度数据矩阵分割成若干个子矩阵;
计算模块32:用于计算第n个子矩阵的平均平方残基打分函数h(i,j)和子矩阵中每行和每列的平均残基d(i)和d(j):
其中,n大于等于1且小于等于子矩阵的总个数,|i|和|j|分别为子矩阵的行数和列数,aij为子矩阵的元素的值,aij、aij和aij分别为子矩阵中第i行的平均值、第j行的平均值和子矩阵整体的平均值,即:
若h(i,j)>δ,则进入删除模块33,若h(i,j)≤δ,该子矩阵形成双聚类块,并且结束,其中,δ为预先设定的最大平均平方剩余分数;
删除模块33:用于将该子矩阵中最大的a(i)或a(j)对应的行或列删除;
添加模块34:用于将该子矩阵中最小的a(i)或a(j)对应的行或列添加到子矩阵中,之后转至计算模块32。
已知大气污染浓度的矩阵a如下,其中行(时间)集合(r1,r2,…,rn)记为x,列(传感器监测站点)集合(c1,c2,…,cm)记为y,矩阵a中元素aij表示第i个传感器监测站点在j时间监测到的大气污染物的浓度。
现有一个集合i∈x和j∈y,则矩阵aij=(i,j)为原矩阵a的一个子矩阵。
双聚类处理模块3采用贪心算法策略,通过删除或添加行或列来寻找一个平均平方残基打分函数值尽可能小、块的尺寸尽可能大的双聚类块,如图2所示。
当采用删除行或列的方式时,首先初始化一个包含矩阵a的全部行和全部列的聚类块,然后在一个循环中不断地删除当前聚类块的行或列以期达到降低平均平方残基打分函数h(i,j)的目的,直至h(i,j)小于等于预先设定的δ时循环终止。
由于通过删除操作,得到的双聚类块的平均平方残基打分函数h(i,j)有可能不是最大的,因此某些剩余的行和列有可能可以被添加进去,只要保证双聚类块的平均平方残基打分函数h(i,j)小于等于预先设定的δ即可。
由于双聚类算法是确定的,所以对同一数据集重复使用上述双聚类算法每次找到的双聚类模块都是同一个,并不能找出第二个双聚类块。因此,为了找到多个双聚类块,,计算模块32还优选包括:用于当一个双聚类块形成后,使用随机数代替已经形成的双聚类块中的元素的值,之后对其它的子矩阵进行双聚类处理。
进一步的,高值区域建立模块5中,将每个网格内的大气污染浓度与周边网格内的大气污染浓度进行对比时,优选采用等值线、阴影图、栅格图或填色图进行对比。高值区域建立模块5通过采用等值线、阴影图、栅格图或填色图等方式进行大气污染浓度的空间专题分析,分析内容涵盖实时、小时、日均、月均等时间尺度目标区域精细污染空间分布图。
综上,本发明通过在目标区域大密度部署传感器监测站点,获取海量大气污染浓度数据,通过双聚类与大气污染浓度空间网格化热力图相结合的方法,识别高污染发生的区域,并获得污染区域范围及边界、污染强度、高污染发生的频率,结合污染源排放数据与污染源调查,认识高污染区域形成的污染源排放原因,支持市及区县展开污染排放的监察及控制。潜在的应用对象包括小工业集中区域、大型工业园区、物流集中区域、城乡结合部、城中村等。首先,本发明将监测结果的空间精度从离散稀疏的点位读数扩展为时空连续的面测量值。由于绝大多数监测网络设备(即传感器)处于近地面层,且分布密度远高于现有监测站,因此经过混合反演可以得到该平面上空间精度小于500米的连续污染浓度指标。其次,采用大数据分析手段,从时域和空间指标两个方面,提取高于背景浓度场的高值区域和疑似源。其中,时域指标表征高值区域和疑似源的持续时间和周期性规律,空间指标表征高值区域和疑似源的污染程度和影响范围。综合采用以上两类指标集,量化评估高值区域和疑似源的污染贡献排序,为后续模型和决策支持提供原始排查清单和优先级排序。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!