一种基于信息熵的立磨运行数据阶跃故障诊断方法与流程
本发明涉及建材行业立磨运行故障的诊断领域,特别是涉及基于信息熵的fisher分类器的立磨运行故障特征提取与诊断方法。
背景技术
立磨是一种建材行业中常见的大型粉末设备,对于提高企业生产效率发挥着重要的作用,通常在低速重载、强噪声环境下工作。目前对立磨的故障诊断一般都靠人工经验进行,尚缺乏快速准确的故障诊断理论和方法。立磨故障的表现存在着一定的模糊性和多样性;一种故障现象可能由多个故障原因产生,或多种现象由同一个故障原因产生等。因此,对立磨故障原因进行分析,故障特征进行提取和诊断的研究具有重要的工程实践价值。
目前,对立磨运行的故障诊断分析大都是基于采集的信号属性,然而这些信号大多具有非线性和非平稳等的特点,通过分析可以得到表征设备状态的信息。而信息本身的特征是可以通过熵值衡量的,本发明基于立磨运行数据信息熵以及fisher分类器对立磨运行故障特征进行提取,具有较为高的效率和准确性的特点,能够比较准确地诊断出立磨选粉机驱动阶跃故障、电动机参数阶跃故障、减速器参数阶跃故障、联轴器转速阶跃故障以及液压泵参数阶跃故障。
技术实现要素:
针对立磨运行故障采集的信号属性的非线性、非平稳等复杂情况,以及对故障的识别度偏低的现状,旨在提出一种立磨运行故障识别度高且实时有效的诊断方法,用以解决当前技术对立磨运行故障诊断可能复杂和识别度不高的问题。
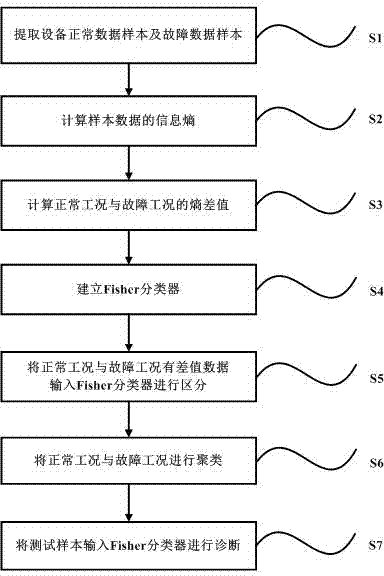
为了达到上面提及的要求或者目的,提出一种基于信息熵与fisher分类器的故障诊断方法,它包括以下七个步骤:获取立磨设备正常运行数据与故障数据样本;计算各类样本数据的信息熵;计算正常工况和故障工况的熵差值;建立fisher分类器;将正常工况样本数据和故障工况样本数据进行聚类;将测试样本输入fisher分类器进行诊断。
优选地,提取立磨运行正常工况和故障工况样本数据,计算异常属性的故障特征—属性的上下限,并根据上下限来判断可能发生的某种故障。每一类属性大都是高于或者低于它的上下限的正常值范围,因此有了异常的表现,导致了故障的发生,在这里,可以凭借信号属性的正常范围的上下限,来界定它是否是出现了异常的情况,高于上限或者低于下限就可以判定它异常。
优选地,计算样本数据的信息熵。分别作为即将要用的fisher分类器的训练样本和测试样本,用作输入数据。信息熵的计算公式如下:
h(x)=-∑p(xi)log(p(xi)),(i=1,2,……,n),
其中,h(x)为求得的信息熵,p(xi)为样本事件xi的发生概率,x表示随机变量,随机变量的取值为x1,x2,……xn,且有∑p(xi)=1,信息熵的单位为bit。
优选地,计算正常工况和故障工况的差值。把针对之前求得的正常和异常的熵值,将其作差值计算,提高直观性和区分度。分别设出两类信息熵h1(x)和h2(x),还有其差值c(x)和平均差值δc,计算公式如下:
c(x)=h1(x)-h2(x),
其中,x是对应信息熵的顺序点。若是c(x)小于或者等于δc,即说明没有发生突变,波动很平稳,则没有故障;若是c(x)大于δc,即说明发生了突变,波动变大,则出现了故障。
优选地,建立fisher分类器。将维d空间中的样本投射到一维空间中的一条直线上,在一维的直线上找到阈值点,大于该阈值点的样本分为一类,小于该阈值点的样本分为另一类,使两类样本在该轴上投影之间的距离尽可能远,而每一类样本的投影尽可能紧凑,从而使分类效果为最佳。假设集合ψ包含n个d维样本x1,x2,x3,……,xn,其中n1个属于ψ1的样本,n2个属于ψ2的样本。若对xn的分量做线性组合,可得到标量
yn=ωtxn,n=1,2,3,……n,
这样便得到n个一维样本yn的集合,可分为两个子集y1,y2。从几何上,如果||ω||=1,则每个yn就是对应于到方向为xn的直线ω的投影。ω方向的不同,将使样本投影后的可分程度不同,从而直接影响识别的效果。
计算各类样本均值mibar
其中,y1和y2为一维样本的集合。
样本类内离散度sibar2和总类内离散度swbar2
sωbar=s1bar2+s2bar2,
其中,s1bar2与s2bar2为样本1和样本2的类内离散度矩阵。
优选地,将正常工况和故障工况有差值的数据部分,分别输入fisher分类器进行分类。定义fisher总则函数为:
其中,m1bar与m2bar为样本1和样本2的均值,求jf(ω)取极大值时的ω*,用lagrange乘子法求解得:
ω*=sω-1(m1-m2),
其中,sω-1为总类内离散度矩阵的逆矩阵,ω*就是fisher总则函数取极大值时得解,也就是d维x空间到一维y空间的最好投影方向。确定阈值y0:
通过投影计算,找到一条直线ω*,即分类直线。
优选地,根据聚类的原理,将上个步骤中区分开的部分进行k-means聚类分析,通过聚类,实现将正常数据和故障数据的分类。目标函数达到最优或者迭代次数达到最大值时,聚类分析过程停止,在笛卡尔直角坐标系中,以欧氏距离作为参数,则目标函数取为最小化对象到质心的距离的平方和:
其中k是类别,阶跃故障中k=2,ci是质心,x是样本数据,dist是笛卡尔坐标系中的距离。
优选地,将测试样本输入fisher分类器进行诊断,根据上述步骤,实现对测试样本的区分和聚类,即实现了故障诊断。
附图说明
图1显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法流程示意图。
图2显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法获取正常工况数据图。
图3显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法获取阶跃故障数据图。
图4显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法正常工况和故障工况熵值图。
图5显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法正常工况和故障工况熵差值图。
图6显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法在笛卡尔坐标系故障fisher识别结果图。
图7显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法训练样本聚类结果图。
图8显示为本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法测试样本聚类结果图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易的了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
请参阅图1至图8。需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图示中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的形态、数量及比例可为一种随意的改变,且其组件布局形态也可能更为复杂。
立磨是水泥工业中常见的设备,通常工作在灰尘大、噪声大、各种工况参数变化需求大的恶劣环境中,运行参数发生突变或者阶跃故障的概率较大,容易对设备造成损坏。实际工作现场,通常无法对阶跃故障做有效的预测,只有当工况数据发生阶跃故障后,累积到一定程度造成设备本身损坏,表现出异常(例如温度过高)或者对监测设备造成一定损坏(例如过流),才可以确定故障的发生,进行停机维修。在这种情况下,如何利用好时域信号本身的信息特征,减少计算环节,简化故障诊断算法,提高故障诊断效率的目的,导致目前需要寻求一种可以较快并有效提取工况参数阶跃故障特征并进行诊断的方法,本发明就是基于这些理念而形成的。
本发明的目的在于提供一种立磨工况参数阶跃故障诊断方法,用于解决现有技术中对立磨工况参数阶跃故障诊断效率较低的问题。以下将详细描述本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法的原理和实施方式,使本领域技术人员不需要创造性劳动即可理解本发明的一种基于信息熵的立磨运行数据阶跃故障诊断方法。
如图1所示,本文提出了一种基于信息熵的立磨运行数据阶跃故障诊断方法,该方法的步骤包括:
s1、提取设备正常数据样本及故障数据样本;
s2、计算样本数据的信息熵;
s3、计算正常工况和故障工况的熵差值;
s4、建立fisher分类器;
s5、将正常工况和故障工况差值大的部分输入fisher分类器进行区分;
s6、将正常工况和故障工况进行聚类;
s7、将测试样本输入fisher分类器进行诊断。
下面结合了具体实施例,对本文进行详细的说明。本实例在matlab2013a软件环境下操作完成。具体的操作实施方法如下:通过立磨装备监测系统中温度传感器采集正常工况下和故障工况下的主轴轴承温度数据,其中主轴轴承的正常温度范围为82~84℃;故障数据主要表现形式为阶跃变化。信号是通过16通道的dat记录器采集的,数字信号的采样频率为1200hz。
执行步骤s1,提取设备正常数据样本及故障数据样本。在样本数据中,以信号属性的正常范围的上限值和下限值,来界定它是正常工况还是故障工况,通常高于上限值或者低于下限值就可以判定它异常。根据上述的情况,观察可得:主轴轴承的正常温度范围为82~84℃,此为正常工况,如图2所示;立磨出口温度在正常的时候升高了,直到94~96℃才稳定下来,超出温度的上限值,如图3所示,此为故障工况。
执行步骤s2,计算样本数据的信息熵。对获取的正常工况样本数据和故障工况样本数据求其信息熵:
h(x)=-∑p(xi)log(p(xi)),(i=1,2,……,n);
每类故障采集了600个数据点,前400个是训练样本,其中前200个是正常的训练数据,后200个是异常的训练数据,最后200个是测试样本的数据。在这600个数据中,每10个取一段,累计求熵,最后每一类故障得到40个训练样本的熵,20个测试样本的熵,结果如图4所示。
执行步骤s3,计算正常工况和故障工况的熵差值。计算正常工况和故障工况的熵值差,设出两类信息熵h1(x)和h2(x)差值:
c(x)=h1(x)-h2(x);
其中,x是对应信息熵的顺序点。若是c(x)小于或者等于容限δc,即说明没有发生突变,波动很平稳,则没有故障;若是c(x)大于δc,即说明发生了突变,波动变大,则出现了故障。结果如图5所示。
执行步骤s4,建立fisher分类器,求各类样本均值m1bar,m2bar:
求出样本类内离散度s1bar2,s2bar2和总类内离散度swbar2:
sωbar=s1bar2+s2bar2;
基于此构建出fisher分类器,用于故障的诊断。
执行步骤s5,将正常工况和故障工况有差值的数据部分,分别输入fisher分类器进行分类。定义fisher总则函数为:
其中,m1bar与m2bar为样本1和样本2的均值。
求jf(ω)取极大值时的ω*,用lagrange乘子法求解得:
ω*=sω-1(m1-m2);
其中,sω-1为总类内离散度矩阵的逆矩阵,ω*就是fisher总则函数取极大值时得解,也就是d维x空间到一维y空间的最好投影方向。
确定阈值y0:
通过投影计算,找到一条直线ω*,即分类直线。针对故障数据样本,采集了600个数据点,经过数据处理,得到40个训练样本的熵,20个测试样本的熵,用作fisher分类器的输入数据,进行分类。在阈值点y0上下,训练样本被分为了两类,根据fisher的原理是大于阈值为一类,小于阈值为另一类。结果如图6所示。
执行步骤s6,将上个步骤中区分开的部分进行k-means聚类分析,通过聚类,实现将正常数据和故障数据的分类。目标函数达到最优或者迭代次数达到最大值时,聚类分析过程停止,在笛卡尔直角坐标系中,以欧氏距离作为参数,则目标函数取为最小化对象到质心的距离的平方和:
聚类分析结果如图7所示。
执行步骤s7,将测试样本输入fisher分类器进行诊断,根据上述步骤,实现对测试样本的区分和聚类,即实现了故障诊断,测试故障工况样本数据诊断结果如图8所示。
- 还没有人留言评论。精彩留言会获得点赞!