一种基于气相/液相色谱质谱平台的数据分析系统的制作方法
本发明属于计算机操作系统领域,具体涉及一种基于气相/液相色谱质谱平台的数据分析系统。
背景技术
代谢组学是以生物系统内的小分子代谢物为研究对象,运用高通量高灵敏度仪器进行检测,分析其不同生理或病理状态下的波动或变化以及其通路特点。这些高通量检测仪器产生的海量数据具有高维度、高噪音和高变异性的特点,且数据之间具有复杂的相关性和冗余性,因而数据分析与处理被视为代谢组学研究的一大难点。
近年来随着代谢组学的不断发展和广泛应用,各种代谢组学分析工具也相继涌现。其中包括经典的算法、分析工具以及多功能分析软件等,例如经典工具xcms、amdis、simcap,以及综合型分析工具如metaboanalyst、w4m、xcmsonline、galaxy-m等。这些经典的算法和分析工具为本软件的搭建和开发提供了可能。
技术实现要素:
鉴于上述现有技术的不足之处,本发明的目的在于提供一种基于气相/液相色谱质谱平台的数据分析系统,旨在实现对质谱数据从原始数据的预处理、物质鉴定、数据调理、定性定量分析、差异分析、相关分析到通路分析、富集分析以及效能分析一站式服务,极大地提高了工作效率、降低了代谢组学研究中的数据分析难度。
为了达到上述目的,本发明采取了以下技术方案:
一种基于气相/液相色谱质谱平台的数据分析系统,包括
液相色谱质谱原始数据预处理模块,其通过调用‘metams’r包中的‘runlc()’函数,用于完成液相色谱质谱原始数据的预处理;
气相色谱质谱原始数据预处理模块,其通过调用函数对气相色谱质谱原始数据进行预处理;
物质鉴定模块,其提供自建库和公共库数据,并用于对气相数据和液相数据进行物质鉴定;
数据调理模块,其用于对预处理数据进行数据清洗、调理和转换;
统计分析模块,其提供单维和多维统计分析方法,并用于对数据分析;
通路分析和富集分析模块,其将代谢物与人类代谢组数据库、京都基因与基因组百科全书、有机小分子生物活性数据库进行整合分析,得到化合物相应的id号码、详细信息和通路信息;
控制中心模块,其分别与所述液相色谱质谱原始数据预处理模块、所述气相色谱质谱原始数据预处理模块、所述物质鉴定模块、所述数据调理模块、所述统计分析模块、所述通路分析和富集分析模块串口连接,并用于接收和处理数据信号。
优选的,所述控制中心模块包括简化流程模块,所述简化流程模块为所述控制中心模块提供一键式快捷分析流程指令。
优选的,所述液相色谱质谱原始数据的预处理包括:色谱峰提取、峰分组、保留时间校正和缺失值填充。
优选的,所述气相色谱质谱原始数据预处理方式包括:第一,通过调用‘metams’r包中的‘rungc()’函数,完成峰提取、伪谱鉴定及伪谱删除;
第二,通过调用‘erah’r包,完成峰识别、峰解卷积、峰对齐和缺失值填充。
优选的,所述公共库数据对比时,仅利用代谢物的质荷比进行比对;自建库对比时,可保留时间与质荷比作为双重衡量标准进行物质鉴定。
优选的,所述数据调理模块包括:异常值替换、零值填充、数据归一化、基本统计量计算、行求平均值、数据提取、数据转换和转置。
优选的,所述单维统计分析涵盖配对与非配对、参数与非参数的多种检验方法,并提供三种p值矫正方法。具体包括t-检验、方差分析、wilcoxon(符号)秩和检验、kruskalwallis检验;
所述多维统计分析包括:主成分分析法、(正交)偏最小二乘法、支持向量机法、随机森林法和biosigner生物标志物判别分析法。
优选的,所述通路分析和富集分析模块分析目标代谢物与特定生理或病理状态的关联和可能的作用以及其所在代谢通路或网络的重要性和富集情况。
优选的,所述简化流程模块提供个基本的数据分析和挖掘流程,包括气相色谱质谱数据预处理、液相色谱质谱数据预处理、数据调理、统计分析、通路和富集分析。
优选的,所述一种基于气相/液相色谱质谱平台的数据分析系统还包括:受试者工作特征曲线分析、线性回归及相关分析、层次聚类、亚层次聚类分析、作图工具、合并lecocsv文件、样本量及效能分析。
与现有技术相比,本发明的有益效果:
1.提供了几乎全部的非靶向代谢组学数据分析步骤,实现了代谢组学研究的流程化、自动化的一站式分析,提高了工作效率。
2.与传统的代谢组学分析工具不同,本发明不仅仅局限于单一的分析平台和有限的数据处理功能,而是整合了气相和液相两种色谱质谱平台数据分析工具,并提供从原始数据预处理、统计分析到通路分析的代谢组学数据分析所涉及的全部分析工具。且为每个过程整合了最新或最经典的分析方法或算法,确保了软件的优越性。
3.除具备常用的代谢组学数据分析工具和各种绘图功能外,本发明还提供了一些实用且高效的工具。如整合多个leco仪器输出的原始数据文件,免去了人工操作的繁琐和错误;为cytoscape生物网路分析提供数据准备;样本量及效能分析,为实验前后的预测和评估提供参考。
4.与传统的软件不同,本发明不要求用户具备计算机编程基础和成熟的统计分析能力,为此设计了用户友好的、简洁明了的操作界面以及详尽的参数说明。并设计了工作流程模块,实现一键式快捷分析,为广大的用户群体提供低门槛的使用可能。
5.本发明为代谢组学研究的物质鉴定和结果的生物化学意义挖掘提供了大量的知识库,具备本地化多数据库查询功能。
附图说明
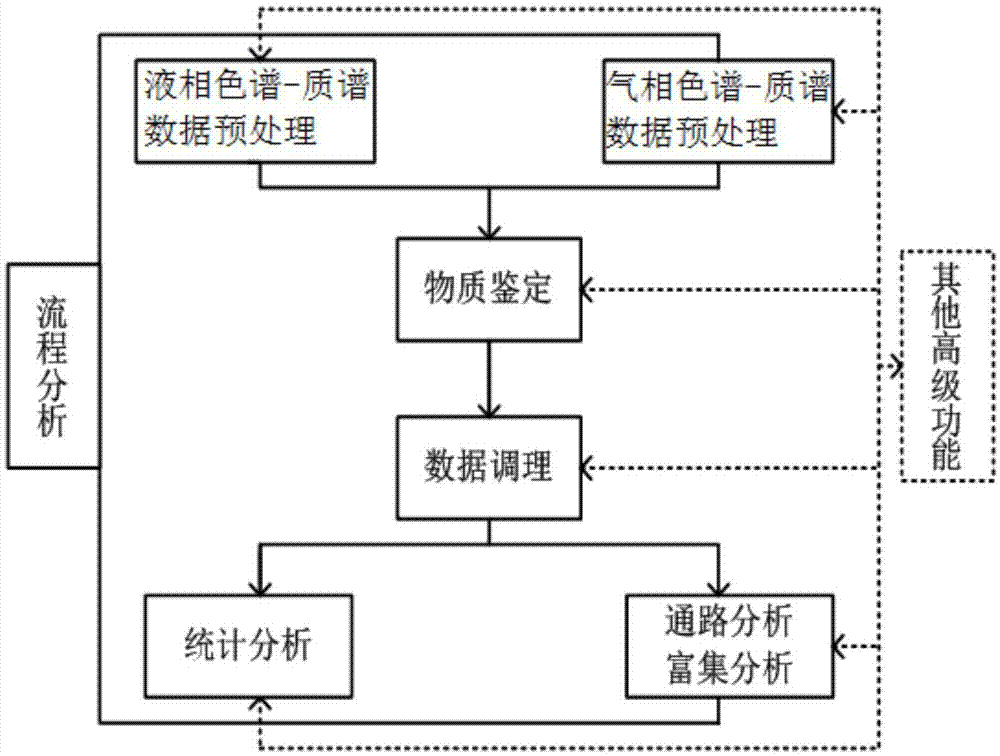
图1为本发明优选实施例一种基于气相/液相色谱质谱平台的数据分析系统的框图;
图2为本发明优选实施例一种基于气相/液相色谱质谱平台的数据分析系统的各模块具有的功能框图;
图3为本发明优选实施例一种基于气相液相/色谱质谱平台的数据分析系统的简化流程模块框图;
图4为本发明优选实施例的附加功能的框图。
具体实施方式
为使本发明的目的、技术方案及效果更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1-2所示,本发明提供的一种基于气相/液相色谱质谱平台的数据分析系统,包括:
液相色谱质谱原始数据预处理模块,通过调用‘metams’r包中的‘runlc()’函数,用于完成液相色谱质谱原始数据的预处理,输入为多组液相原始数据文件,输出为一个包含质量、保留时间、峰强度的峰列表文件;
气相色谱质谱原始数据预处理模块,其用于完成气相色谱质谱原始数据的预处理。
物质鉴定模块,其提供自建库和公共库数据,并用于对气相数据和液相数据进行成分鉴定;其中本系统提供7种公共数据库资源,包括nsen、gmd_fame、gmd_alk、gmd_msir、mona-hmdb、mona-metabobase、mona-respect。液相数据的物质鉴定,提供多种可能的加合物形式,用于精确计算小分子代谢物的质量和电荷,具体包括[m+h]、[m+nh4]、[m+na]及[m+k]等多种化合物形式。输入为峰列表文件和/或质谱信息,输出为鉴定后的峰列表、筛选后的峰列表及物质详情文件;
数据调理模块,其用于对预处理数据进行数据清洗、调理和转换;输入为峰列表文件,输出为处理后的峰列表文件;
统计分析模块,其提供单维和多维统计分析方法,并用于对数据分析;输入为峰列表文件或其他矩阵、分组文件,输出为统计分析详情和差异物筛选结果文件;
通路分析和富集分析模块,其将代谢物与人类代谢组数据库、京都基因与基因组百科全书、有机小分子生物活性数据库进行整合分析,得到化合物相应的id号码、详细信息和通路信息;输入为物质名列表文件(来源于物质鉴定)、化合物id号,输出为化合物详情、通路分析列表、富集分析列表和图形可视化结果;
控制中心模块,其分别与所述液相色谱质谱原始数据预处理模块、所述气相色谱质谱原始数据预处理模块、所述物质鉴定模块、所述数据调理模块、所述统计分析模块、所述通路分析和富集分析模块串口连接,并用于接收和处理数据信号。
具体的,控制中心模块收到用户检测请求命令后会向对应的功能模块发送数据处理指令,比如液相色谱质谱原始数据预处理模块收到控制中心模块发送的对数据进行预处理指令,则对液相色谱质谱原始数据进行预处理,并将预处理的结果反馈至控制中心模块,控制中心模块接收用户下一个命令,比如向物质鉴定模块发送运行指令,控制中心模块将峰列表文件和/或质谱信息输入至物质鉴定模块,物质鉴定模块对数据进行鉴定分析后输出为鉴定后的峰列表、筛选后的峰列表及物质详情文件,并将输出结果反馈至控制中心模块进行储存;以此类推,其他功能模块的工作原理也是如此。
在一些实施例中,所述控制中心模块包括简化流程模块,所述简化流程模块为所述控制中心模块提供一键式快捷分析指令,方便用户操作,更加高效。
在一些实施例中,所述液相色谱质谱原始数据的预处理包括:色谱峰提取、峰分组、保留时间校正和缺失值填充。
在一些实施例中,所述气相色谱质谱原始数据预处理方式包括:第一,通过调用‘metams’r包中的‘rungc()’函数,完成峰提取、伪谱鉴定及伪谱删除,该方法高效快速,但识别峰的数量和准确度有限;
第二,通过调用‘erah’r包,完成峰识别、峰解卷积、峰对齐和缺失值填充,该方法能够更精确的获取较多的峰信息,但耗时长。
在一些实施例中,所述公共库数据对比时,仅利用代谢物的质荷比进行比对;自建库对比时,可保留时间与质荷比作为双重衡量标准进行物质鉴定,可以多方面对比。本系统提供7类公共的质谱数据库资源,包括nsen、gmd_fame、gmd_alk、gmd_msir、mona-hmdb、mona-metabobase、mona-respect,主要来源于美国国家标准与技术研究院(nist)、golm代谢组学数据库(gmd)和北美质谱数据库(mona)。
在一些实施例中,所述数据调理模块的主要功能包括:异常值替换、零值填充、数据归一化、基本统计量计算、行求平均值、数据提取、数据转换和转置;
其中,零值填充共4种:1)最小值法;2)邻近算法(knn);3)qirlc算法;4)自主设定。
归一化方法共三种,即1)总强度归一化;2)内标归一化;3)混合样本(qc)归一化;
数据转换方式共三种,即1)log2转换;2)log2转换,且中位数转换;3)zscore转换;
在一些实施例中,所述单维统计分析涵盖配对与非配对、参数与非参数的多种检验方法,并提供三种p值矫正方法。具体包括t-检验、方差分析、wilcoxon(符号)秩和检验、kruskalwallis检验;
所述多维统计分析包括:主成分分析法、(正交)偏最小二乘法、支持向量机法、随机森林法和biosigner生物标志物判别分析法。
其中,(正交)偏最小二乘法用于多因素统计分析,本发明提供三种归一化法,1)
支持向量机法具体采用四种核函数,1)线性核函数,2)多项式核函数,3)高斯核函数,4)sigmoid核函数;
在一些实施例中,所述通路分析和富集分析模块分析目标代谢物与特定生理或病理状态的关联和可能的作用以及其所在代谢通路或网络的重要性和富集情况,并提供21个物种(人类、小鼠、大鼠、鱼、微生物、古细菌等)的1600余个代谢通路,人类生理或病理状态下的各类样本(血液、尿液、唾液、脑脊液、组织或器官等)的近7000个代谢物集。
在一些实施例中,所述简化流程模块提供个基本的数据分析和挖掘流程,包括气相色谱质谱数据预处理、液相色谱质谱数据预处理、数据调理、统计分析、通路和富集分析,允许用户设置关键参数,实现一键式分析,适于批量操作和初级用户。
在一些实施例中,所述一种基于气相/液相色谱质谱平台的数据分析系统还包括:受试者工作特征曲线分析、线性回归及相关分析、层次聚类、亚层次聚类分析、作图工具、合并lecocsv文件、样本量及效能分析。
综上所述,本发明提供一种数据分析与处理的全功能软件系统,实现了对质谱数据从原始数据的预处理、物质鉴定、数据调理、定性定量分析、差异分析、相关分析到通路分析、富集分析以及效能分析等一站式服务。极大地提高了工作效率、降低了代谢组学研究中的数据分析难度。
需要说明的是,在本文中,诸如术语“包括”、“包含”或者其任何非排他性的包含,从而使得包括一系列要素的过程、方法或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法或者设备所固有的要素。
可以理解的是,对本领域普通技术人员来说,可以根据本发明的技术方案及其发明构思加以等同替换或改变,而所有这些改变或替换都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!