生物标志物在评估口腔鳞癌危险程度中的应用的制作方法
本发明属于生物医药领域,涉及生物标志物在评估口腔鳞癌危险程度中的应用,具体的涉及的生物标志物为gsdma。
背景技术:
口腔鳞状细胞(oralsquamouscellcarcinoma,oscc)是恶性程度最高的恶性肿瘤之一,同样是最常见的口腔肿瘤类型,口腔鳞状细胞癌患者常常伴有转移、高的复发率以及差的预后。流行病学统计分析每年全球大约有10万人死于口腔鳞状细胞癌及其带来的病发症,因此口腔鳞状细胞癌给整个社会医疗保障体系带来了巨大的挑战与负担。作为一种多因素导致的疾病,当前的研究认为烟草与酒精是导致其发生、发展的重要因素,同样慢性炎症、人类疱疹病毒感染也同样与该病的产生密切相关,除了环境因素,易感的基因遗传背景也是导致口腔鳞状细胞癌产生的重要原因。
虽然在过去几十年里肿瘤基础研究及临床治疗得到了迅速发展,但是口腔鳞状细胞癌的5年生存率并没有得到显著改善,约为50%左右,给患者的生活质量与社会公共医疗造成了极大的负担,因此加强恶性肿瘤的防治研究,准确、客观评价肿瘤生物学行为和预后、制定治疗方案显得更为迫切。
肿瘤的分级(grading)是目前评价肿瘤生物学行为和诊断的重要的指标,恶性肿瘤一般根据其分化程度的高低、异型性的大小及核分裂像的多少来确定恶性程度的级别。近年来较多的人倾向于用简明的、较易掌握的三级分级法,即i级为分化良好的,肿瘤细胞接近相应的正常发源组织,恶性程度低;ii级为分化中等的,属中度恶性;iii级为分化低的,肿瘤细胞与相应的正常发源组织区别大、分化差,为高度恶性。此外,还有学者将部分未显示分化倾向的恶性肿瘤称为未分化肿瘤,属于iv级(g4),为高度恶性。这种分级法虽有其优点,对临床治疗和判断预后也有一定意义。但缺乏定量标准,也不能排除主观因素的影响。随着分子生物学的发展,人们开始关注基因与肿瘤的相关性,探讨基因评估口腔鳞癌发展的进程,对实现口腔鳞癌的精准治疗具有重要的意义。
技术实现要素:
为了弥补现有技术的不足,本发明的目的在于提供一种与口腔鳞癌危险程度的相关的生物标志物,使用该标志物,可以判断评估患者患口腔鳞癌的发展进程。
为了实现上述目的,本发明采用如下技术方案:
本发明的第一方面提供了gsdma基因的应用,用于制备评估口腔鳞癌危险程度的产品。
进一步,所述产品包括检测样本中gsdma表达水平的试剂,其中,用于检测gsdma的样本包括细胞、组织、脏器、体液(血液、淋巴液等)、消化液、咳痰、肺胞支气管清洗液、尿、粪便等。优选的,所述样本为组织、血液。在本发明的具体实施方式中,所述样本为组织。
进一步,gsdma在危险程度高的口腔鳞癌样本中表达下调。
进一步,所述试剂通过rt-pcr、实时定量pcr、免疫检测、原位杂交或芯片检测gsdma表达水平的试剂。
进一步,所述通过rt-pcr检测gsdma表达水平的试剂至少包括一对特异扩增gsdma基因的引物;所述通过实时定量pcr检测gsdma表达水平的试剂至少包括一对特异扩增gsdma基因的引物;所述通过免疫检测gsdma表达水平的试剂包括与gsdma蛋白特异性结合的抗体和/或配体;所述通过原位杂交检测gsdma表达水平的试剂包括与gsdma基因的核酸序列杂交的探针;所述通过芯片检测gsdma表达水平的试剂包括与gsdma基因核酸序列杂交的探针、或与gsdma蛋白特异性结合的抗体和/或配体。
进一步,所述特异性扩增gsdma的引物序列如seqidno.3~4所示。
本发明第二方面提供了一种诊断口腔鳞癌危险程度的产品,包括制剂、核酸膜条、芯片或试剂盒,其中,所述制剂、核酸膜条、芯片或试剂盒包括检测gsdma表达水平的试剂。
进一步,所述芯片中检测gsdma表达水平的试剂包括特异性识别gsdma基因的探针,或特异性结合gsdma编码的蛋白的抗体或配体。
进一步,所述试剂盒中检测gsdma表达水平的试剂包括特异性扩增gsdma基因的引物;或特异性识别gsdma基因的探针;或特异性结合gsdma编码的蛋白的抗体或配体。
进一步,所述特异性扩增gsdma基因的引物序列如seqidno.3和seqidno.4所示。
进一步,所述试剂盒包括sybrgreen聚合酶链式反应体系、用于扩增管家基因的引物对;所述sybrgreen聚合酶链式反应体系包含:pcr缓冲液、dntps、sybrgreen荧光染料。
本发明所述的基因芯片或基因检测试剂盒可用于检测包括gsdma基因在内的多个基因(例如,与口腔鳞癌危险程度相关的多个基因)的表达水平。所述蛋白芯片或蛋白免疫检测试剂盒可用于检测包括gsdma蛋白在内的多个蛋白质(例如与口腔鳞癌危险程度相关的多个蛋白质)的表达水平。将口腔鳞癌危险程度的多个标志物同时进行检测,可大大提高口腔鳞癌危险程度诊断的准确率。
本发明的优点和有益效果:
本发明选择gsdma作为分子标志物,可以实现口腔鳞癌的危险程度高低的分级,从而指导医生对危险度高中低不同的口腔鳞癌患者采取不同的治疗策略、手段及措施,不但可以避免过度治疗,也可以避免治疗强度不足,从而提高口腔鳞癌患者的治疗效果,节约医疗资源和成本。
本发明利用gsdma开发成检测产品,检测快速方便、检测灵敏度、特异度高、成本低,可以满足绝大多数口腔鳞癌病人的检测需求,应用范围广。
附图说明
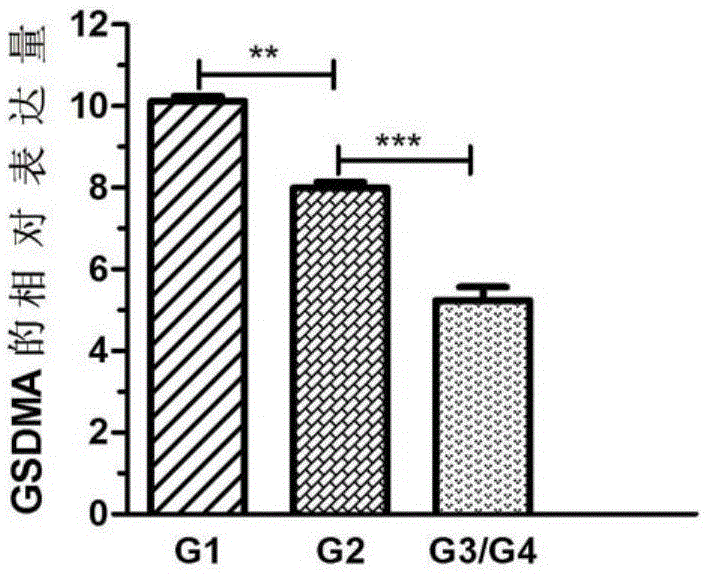
图1是利用qpcr检测gsdma在口腔鳞癌组织中的表达情况,其中**:p<0.01,***:p<0.001。
具体的实施方式
本发明经过广泛而深入的研究,通过高通量测序以及生物信息学分析,首次发现了在不同危险程度的口腔鳞癌患者中gsdma呈现特异性表达,为口腔鳞癌分级的评估提供了更好的途径和方法。
生物标志物
“生物标志物”也称为“分子标志物”,是在组织或细胞中的表达水平与正常或健康细胞或组织的表达水平相比发生改变的任何基因或蛋白。
本文包含用于检测分子标志物表达的现有技术中任何可用方法。本发明分子标志物的表达可在核酸水平上被检测(如,rna转录物)或蛋白质水平。通过“检测表达”旨在确定rna转录物或其分子标志物基因的表达产物的数量或存在。因此,“检测表达”包含一分子标志物被确定不能被表达、不能被检测表达,表达在低水平、表达在正常水平或过表达的实例。
本领域技术人员将认识到,本发明的实用性并不局限于对本发明的标志物基因的任何特定变体的基因表达进行定量。所述gsdma基因在目前国际公共核酸数据库genebank中的id为284110,作为非限制性的实例,一种代表性的人gsdma的编码序列或氨基酸序列分别如seqidno.1和seqidno.2所示。gsdma包括包含seqidno.2的多肽和其它gsdma天然序列多肽,诸如天然存在变体和天然序列多肽,其由seqidno.1所示的核苷酸序列编码。
本发明的多核苷酸可以是dna形式或rna形式。dna形式包括cdna、基因组dna或人工合成的dna。dna可以是单链的或是双链的。dna可以是编码链或非编码链。
本发明的多肽可以是重组多肽、天然多肽、合成多肽,优选重组多肽。本发明的多肽还可包括或不包括起始的甲硫氨酸残基。
编码gsdma的成熟多肽的多核苷酸包括:只编码成熟多肽的编码序列;成熟多肽的编码序列和各种附加编码序列;成熟多肽的编码序列(和任选的附加编码序列)以及非编码序列。术语“编码多肽的多核苷酸”可以是包括编码此多肽的多核苷酸,也可以是还包括附加编码和/或非编码序列的多核苷酸。
本发明还涉及上述多核苷酸的变异体,其编码与本发明有相同的氨基酸序列的多肽或多肽的片段、类似物和衍生物。此多核苷酸的变异体可以是天然发生的等位变异体或非天然发生的变异体。这些核苷酸变异体包括取代变异体、缺失变异体和插入变异体。如本领域所知的,等位变异体是一个多核苷酸的替换形式,它可能是一个或多个核苷酸的取代、缺失或插入,但不会从实质上改变其编码多肽的功能。
本发明还涉及与上述的序列杂交的核酸片段,包括正义和反义的核酸片段。如本文所用,“核酸片段”的长度至少含15个核苷酸,较好是至少30个核苷酸,更好是至少50个核苷酸,最好是至少100个核苷酸以上。核酸片段可用于核酸的扩增技术(如pcr)以确定和/或分离编码gsdma蛋白的多核苷酸。
本发明的人gsdma核苷酸全长序列或其片段通常可以用pcr扩增法、重组法或人工合成的方法获得。对于pcr扩增法,可根据已公开的有关核苷酸序列,尤其是开放阅读框序列来设计引物,并用市售的cdna库或按本领域技术人员已知的常规方法所制备的cdna库作为模板,扩增而得有关序列。当序列较长时,常常需要进行两次或多次pcr扩增,然后再将各次扩增出的片段按正确次序拼接在一起。一旦获得了有关的序列,就可以用重组法来大批量地获得有关序列。这通常是将其克隆入载体,再转入细胞,然后通过常规方法从增殖后的宿主细胞中分离得到有关序列。
检测方法
本发明可以使用本领域普通技术人员已知的多种核酸以及蛋白技术进行检测,这些技术包括但不限于:核酸测序、核酸杂交、核酸扩增技术、蛋白免疫技术。
本发明所述核酸扩增技术选自聚合酶链式反应(pcr)、逆转录聚合酶链式反应(rt-pcr)、转录介导的扩增(tma)、连接酶链式反应(lcr)、链置换扩增(sda)和基于核酸序列的扩增(nasba)。其中,pcr需要在扩增前将rna逆转录成dna(rt-pcr),tma和nasba直接扩增rna。
通常,pcr使用变性、引物对与相反链的退火以及引物延伸的多个循环,以指数方式增加靶核酸序列的拷贝数;rt-pcr则将逆转录酶(rt)用于从mrna制备互补的dna(cdna),然后将cdna通过pcr扩增以产生dna的多个拷贝;tma在基本上恒定的温度、离子强度和ph的条件下自身催化地合成靶核酸序列的多个拷贝,其中靶序列的多个rna拷贝自身催化地生成另外的拷贝,tma任选地包括使用阻断,部分、终止部分和其他修饰部分,以改善tma过程的灵敏度和准确度;lcr使用与靶核酸的相邻区域杂交的两组互补dna寡核苷酸。dna寡核苷酸在热变性、杂交和连接的重复多个循环中通过dna连接酶共价连接,以产生可检测的双链连接寡核苷酸产物;sda使用以下步骤的多个循环:引物序列对与靶序列的相反链进行退火,在存在dntpαs下进行引物延伸以产生双链半硫代磷酸化的(hemiphosphorothioated)引物延伸产物,半修饰的限制性内切酶识别位点进行的核酸内切酶介导的切刻,以及从切口3'端进行的聚合酶介导引的物延伸以置换现有链并产生供下一轮引物退火、切刻和链置换的链,从而引起产物的几何扩增。
本发明中非扩增或扩增的核酸可通过任何常规的手段检测。
本发明中的核酸杂交技术包括但不限于原位杂交(ish)、微阵列和southern或northern印迹。原位杂交(ish)是一种使用标记的互补dna或rna链作为探针以定位组织一部分或切片(原位)或者如果组织足够小则为整个组织(全组织包埋ish)中的特异性dna或rna序列的杂交。dnaish可用于确定染色体的结构。rnaish用于测量和定位组织切片或全组织包埋内的mrna和其他转录本(例如,ncrna)。通常对样本细胞和组织进行处理以原位固定靶转录本,并增加探针的进入。探针在高温下与靶序列杂交,然后将多余的探针洗掉。分别使用放射自显影、荧光显微术或免疫组织化学,对组织中用放射、荧光或抗原标记的碱基标记的探针进行定位和定量。ish也可使用两种或更多种通过放射性或其他非放射性标记物标记的探针,以同时检测两种或更多种转录本。
将southern和northern印迹分别用于检测特异性dna或rna序列。使从样本中提取的dna或rna断裂,在基质凝胶上通过电泳分离,然后转移到膜滤器上。使滤器结合的dna或rna与和所关注的序列互补的标记探针杂交。检测结合到滤器的杂交探针。该程序的一种变化形式是反向northern印迹,其中固定到膜的底物核酸为分离的dna片段的集合,而探针是从组织提取并进行了标记的rna。
蛋白免疫技术包括夹心免疫测定,例如夹心elisa,其中使用识别生物标志物上不同表位的两种抗体进行该生物标志物的检测;放射免疫测定(ria)、直接、间接或对比酶联免疫吸附测定(elisa)、酶免疫测定(eia)、荧光免疫测定(fia)、蛋白质印迹法、免疫沉淀法和基于任何颗粒的免疫测定(如使用金颗粒、银颗粒或乳胶颗粒、磁性颗粒或量子点)。可例如在微量滴定板或条的形式中实施免疫法。
根据本发明的免疫法可基于,例如,以下方法中的任一种。
免疫沉淀法是最简单的免疫测定方法;这种方法测量沉淀物的量,在试剂抗体已与样本一起孵育并与其中存在的靶抗原反应以形成不溶性团聚体之后形成所述沉淀。免疫沉淀反应可以是定性的或是定量的。
在颗粒免疫测定中,多种抗体与该颗粒连接,且所述颗粒能够同时结合很多抗原分子。这大大地加速了可见反应的速度。这允许生物标志物的快速且灵敏的检测。
在免疫比浊法(immunonephelometry)中,抗体和生物标志物上的靶抗原的相互作用引起免疫复合物的形成,所述免疫复合物太小而不能沉淀。但是,这些复合物将散射入射光,这可使用比浊计来测量。可在反应的几分钟之内测定抗原(即生物标志物)的浓度。
放射免疫测定(ria)法使用放射性同位素例如i125来标记抗原或抗体。所使用的同位素发射γ射线,通常在除去非结合的(游离的)放射性标记之后测量所述射线。与其它的免疫测定相比较,ria的主要优势在于更高的灵敏度、容易的信号检测和确认的、快速的测定。主要的劣势在于由放射物的使用引起的健康和安全风险和与维护许可放射物安全和处理程序相关的时间和费用。出于该原因,在常规临床实验室实践中,ria已很大程度上被酶免疫测定所取代。
酶免疫测定(eia)发展为放射免疫测定(ria)的替代物。这些方法使用酶来标记抗体或靶抗原。eia的灵敏度接近ria的灵敏度,且不存在由放射性同位素引起的危险。用于检测的最广泛使用的eia方法之一是酶联免疫吸附测定(elisa)。elisa方法可使用两种抗体,其一对于靶抗原是特异性的,而另一与酶偶联,酶底物的添加引起化学发光信号或荧光信号的产生。
荧光免疫测定(fia)指使用荧光标记或酶标记的免疫测定,所述荧光标记或酶标记作用在底物上以形成荧光产物。荧光测量固有比色(分光光度法的)测量更加灵敏。因此,fia方法具有比利用吸收(光密度)测量的eia方法更高的分析灵敏度。
化学发光免疫测定使用化学发光标记,当其被化学能激发时产生光;使用光检测器测量发射。
因此,可使用熟知的方法进行根据本发明的免疫法。在本发明的生物标志物的检测中可使用任何直接(如使用传感器芯片)或间接的方法。
探针
“探针”是指能够用于测量特定基因的表达情况的分子。示例性探针包括pcr引物以及基因特异性dna寡核苷酸探针,例如固定于微阵列基底上的微阵列探针、定量核酸酶保护检验探针、与分子条形码连接的探针、以及固定于珠上的探针。
本发明中术语“探针”指能与另一分子的特定序列或亚序列或其它部分结合的分子。除非另有指出,“探针”通常指能通过互补碱基配对与另一多核苷酸(往往称为“靶多核苷酸”)结合的多核苷酸探针。根据杂交条件的严谨性,探针能和与该探针缺乏完全序列互补性的靶多核苷酸结合。探针可作直接或间接的标记,其范围包括引物。杂交方式,包括,但不限于:溶液相、固相、混合相或原位杂交测定法。
作为探针,可以使用荧光标记、放射标记、生物素标记等对癌检测用多核苷酸进行了标记的标记探针。多核苷酸的标记方法本身是公知的。可通过如下方法检查试样中是否存在受试核酸:固定受试核酸或者其扩增物,与标记探针进行杂交,洗涤,以及然后测定与固相结合的标记。备选地,还可固定癌检测用多核苷酸,使受试核酸与其杂交,然后应用标记探针等检测结合于固相上的受试核酸。在这种情况下,结合于固相上的癌检测用多核苷酸也称为探针。使用多核苷酸探针测定受试核酸的方法在本领域也是公知的。可以如下进行该方法:在缓冲液中使多核苷酸探针与受试核酸在tm或者其附近(优选在±4℃以内)接触用于杂交,洗涤,然后测定杂交的标记探针或者与固相探针结合的模板核酸。
在作为探针使用的多核苷酸的大小优选为18个或更多个核苷酸、更优选为20个或更多个核苷酸,以及编码区域的全长或更少。作为引物使用时,该多核苷酸大小优选为18个或更多个核苷酸,以及50个或更少核苷酸。这些探针具有与靶点基因的特定的碱基序列互补的碱基序列。这里,所谓“互补”,只要是杂交即可,可以不是完全互补。这些多核苷酸通常相对于该特定的碱基序列具有80%以上、优选90%以上、更优选95%以上、特别优选100%的同源性。这些探针可以是dna,也可以是rna,另外,可以为在其一部分或全部中核苷酸通过pn、lna、ena、gna、tna等人工核酸置换得到的多核苷酸。
核酸膜条、芯片、试剂盒
在本发明中,核酸膜条包括基底和固定于所述基底上的寡核苷酸探针;所述基底可以是任何适于固定寡核苷酸探针的基底,例如尼龙膜、硝酸纤维素膜、聚丙烯膜、玻璃片、硅胶晶片、微缩磁珠等。
“芯片”也称为“阵列”,指包含连接的核酸或肽探针的固体支持物。阵列通常包含按照不同的已知位置连接至基底表面的多种不同的核酸或肽探针。这些阵列,也称为“微阵列”,通常可以利用机械合成方法或光引导合成方法来产生这些阵列,所述光引导合成方法合并了光刻方法和固相合成方法的组合。阵列可以包含平坦的表面,或者可以是珠子、凝胶、聚合物表面、诸如光纤的纤维、玻璃或任何其它合适的基底上的核酸或肽。可以以一定的方式来包装阵列,从而允许进行全功能装置的诊断或其它方式的操纵。
“微阵列”是杂交阵列原件有序排列在基质上,所述杂交阵列原件诸如聚核苷酸探针(例如寡核苷酸)或结合剂(例如抗体)。所述基质可以是固体基质,例如,玻璃或二氧化硅玻片、珠、纤维光学粘结剂或半固态基质,例如硝酸纤维素膜。核苷酸序列可以是dna、rna或其中的任何排列。
各种探针阵列已经描述在文献中并且可以用于本发明上下文中检测可能与本文所述表型相关的标志物。例如,dna探针阵列芯片或较大的dna探针阵列晶片(否则,可以通过打断晶片而获得各个体芯片)用于本发明的一个实施方案。dna探针阵列晶片一般包含玻璃晶片,其上放置了高密度dna探针(短dna片段)阵列。这些晶片各自可以保持例如约6000万个用于识别较长样品dna序列(例如,来自个体或群体,例如,包含所关注的标志物)的dna探针。用玻璃晶片上的dna探针组识别样品dna通过dna杂交进行。当dna样品与dna探针阵列杂交时,样品结合于样品dna序列互补的那些探针。通过评价个体样品dna与那些探针更稳固地杂交,有可能确定已知的核酸序列是否存在于样品中,由此确定核酸中发现的标志物是否存在。还可以使用这一手段通过控制杂交条件以允许区别单一核苷酸,例如,用于snp鉴定和一种或多种snp的样品基因分型来进行ash。阵列提供了一种同时(或串连)检测多个多态性标志物的便利性实施方案。
本发明中,试剂盒可用于检测gsdma基因或蛋白的表达水平,包含用于gsdma检测和/或定量的本发明的配体、和/或芯片。任选的与试剂盒的说明书在一起。
试剂盒包括一种或多种无菌容器,这样的容器可以是盒、安瓿、瓶子、管形瓶、管、袋、小袋、泡罩包装、或本领域已知的其它合适的容器形式。这样的容器可以由塑料、玻璃、层压纸、金属箔、或适于容器药物的其它材料。
在本发明中,术语“包括”用于指短语“包括但不限于”,并与短语“包括但不限于”可以互换使用。
抗体
在本发明中,术语“抗体”是指选择性结合目标抗原的天然或合成抗体。该术语包括多克隆和单克隆抗体。除了完整的免疫球蛋白分子外,那些免疫球蛋白分子的片段或聚合物以及选择性结合目标抗原的免疫球蛋白分子的人类或人源化形式也包括在术语“抗体”的范围内,只要它们展现出期望的生物学活性即可。“单克隆抗体”指从一群基本上同质的抗体获得的抗体,即构成群体的各个抗体相同和/或结合相同表位,除了生产单克隆抗体的过程中可能产生的可能变体外,此类变体一般以极小量存在。此类单克隆抗体典型的包括包含结合靶物的多肽序列的抗体,其中靶物结合多肽序列是通过包括从众多多肽序列中选择单一靶物结合多肽序列在内的过程得到的。
单克隆抗体还包括“嵌合”抗体,其中重链和/或轻链的一部分与衍生自特定物种或属于特定抗体类别或亚类的抗体中的相应序列相同或同源,而链的剩余部分与衍生自另一物种或属于另一抗体类别或亚类的抗体中的相应序列相同或同源,以及此类抗体的片段,只要它们展现出期望的生物学活性即可。
非人(例如鼠)抗体的“人源化”形式指最低限度包含衍生自非人免疫球蛋白的序列的嵌合免疫球蛋白、免疫球蛋白链或其片段诸如fv、fab、fab’、f(ab’)2或抗体的其它抗原结合子序列。
“抗体片段”包含全长抗体的一部分,一般是其抗原结合区或可变区。抗体片段的例子包括fab、fab′、f(ab′)2和fv片段;双抗体;线性抗体;单链抗体分子;及由抗体片段形成的多特异性抗体。
“fv”是包含完整抗原识别和结合位点的最小抗体片段。该片段由紧密、非共价结合的一个重链可变域和一个轻链可变域的二聚体组成。从这两个结构域的折叠结构中散发出六个高变环(重链和轻链各3个环),促成结合抗原的氨基酸残基并赋予抗体以抗原结合特异性。然而,即使是单个可变域(或是只包含对抗原特异的三个cdr的半个fv)也可具有识别和结合抗原的能力,只是亲和力低于完整结合位点。
本发明的抗体的“功能性片段”指那些保留与衍生它们的完整全链分子以基本上相同的亲和力结合多肽且在至少一种测定法中有活性的片段。
多克隆抗体包含对产生人抗体的动物(例如,小鼠)免疫gsdma蛋白质而得的抗体。当制备了嵌合抗体或人源化抗体之后,可以将可变区(例如,fr)和/或恒定区中的氨基酸用其他氨基酸替换等。
统计学方法
在本发明中,实验至少采用3次重复实验,结果数据都是以平均值±标准差的方式来表示,使用spss18.0统计软件来进行统计分析的,两者之间的差异采用t检验,认为当p<0.05时具有统计学意义。
下面结合附图和实施例对本发明作进一步详细的说明。以下实施例仅用于说明本发明而不用于限制本发明的范围。实施例中未注明具体条件的实验方法,通常按照常规条件,或按照制造厂商所建议的条件。
实施例1筛选与口腔鳞癌相关的基因标志物
1、样品收集
各收集68例口腔鳞癌组织和癌旁组织,其中包括经组织学分级为i级(g1)的患者20例,组织学分级为ii级(g2)的患者30例,组织学分级为iii/iv级(g3/g4)的患者18例。患者术前未接受任何治疗。患者均知情同意,上述所有标本的取得均通过组织伦理委员会的同意每组各取4例标本进行基因表达谱的检测分析,进行差异表达基因的筛选,并在各组全部标本中进行验证实验。
2、rna样品的制备(利用qiagen的组织rna提取试剂盒进行操作)
取出冻存于液氮中的组织样本,把组织样本放入已预冷的研钵中进行研磨,按照试剂盒中的说明书提取分离rna。具体如下:
1)加入trizol,室温放置5min;
2)加入氯仿0.2ml,用力振荡离心管,充分混匀,室温下放置5-10min;
3)12000rpm离心15min,将上层水相移到另一新的离心管中(注意不要吸到两层水相之间的蛋白物质),加入等体积的-20℃预冷的异丙醇,充分颠倒混匀,置于冰上10min;
4)12000rpm高速离15min后小心弃掉上清液,按1ml/mltrizol的比例加入75%depc乙醇洗涤沉淀(4℃保存),洗涤沉淀物,振荡混匀,4℃,12000rpm离心5min;
5)弃去乙醇液体,室温下放置5min,加入depc水溶解沉淀;
6)用nanodrop2000紫外分光光度计测量rna纯度及浓度,冻存于-70℃冰箱。
3、构建cdna文库
使用ribo-zero试剂盒除去总rna中的核糖体rna,利用illuminatruseqtmrnasampleprepkit进行cdna文库的构建,具体操作按说明书进行。
4、上机测序
使用illuminax-ten测序平台对cdna文库进行测序,具体操作按说明书进行。
5、高通量转录组测序数据分析
对测序结果进行生物信息学分析,使用工具为r-3.3.3进行linearbylinearassociationtest分析,根据每个基因的表达量的四分位数将每个样本划分到为4个表达量区间,然后检测表达量区间与tumorgrade的相关性。当fdr值<0.05时,认为基因显著差异表达。
6、结果
gsdma基因在不同分化程度的口腔鳞癌组织中的表达量呈现显著性差异,与g1相比,g2和g3/g4中gsdma的表达显著下调,与g2相比,g3/g4中gsdma的表达显著下调,提示gsdma可有效的区分不同分化程度的口腔鳞癌。
实施例2qpcr测序验证gsdma基因的差异表达
1、对gsdma基因差异表达进行大样本qpcr验证。
2、rna提取步骤如实施例1所述。
3、逆转录:
采用fastqμantcdna第一链合成试剂盒(货号:kr106)进行mrna反转录,首先去除基因组dna反应,在试管中加入5×gdnabμffer2.0μl,总rna1μg,加rnasefreeddh2o使总体积至10μl,水浴锅中42℃加热3min,再将10×fastrtbμffer2.0μl,rtenzymemix1.0μl,fq-rtprimermix2.0μl,rnasefreeddh2o5.0μl,混合后加入上述试管中一起混合共20μl,水浴锅中42℃加热15min,95℃加热3min。
4、qpcr扩增检测
根据gsdma和gapdh的序列设计qpcr扩增引物,由博迈德生物公司合成。具体引物序列如下:
gsdma基因:
正向引物为5’-caaaggcaaagatgagtg-3’(seqidno.3);
反向引物为5’-cttctcctctcctgactt-3’(seqidno.4)。
管家基因gapdh的引物序列为:
正向引物:5’-ctctggtaaagtggatattgt-3’(seqidno.5)
反向引物:5’-ggtggaatcatattggaaca-3’(seqidno.6)
用superrealpremixplus(sybrgreen)(货号:fp205),进行扩增,实验操作按产品说明书进行。
采用20μl反应体系:2×superrealpremixplus10μl,正反向引物(10μm)各0.6μl,5×roxreferencedye△2μl,dna模板2μl,灭菌蒸馏水4.8μl。每个样本设置3个平行管,所有扩增反应均重复三次以上以保证结果的可靠性。
扩增程序为:95°15min,(95℃10s,55℃30s,72℃32s)×40个循环,95℃15s,60℃60s,95℃15s)。以sybrgreen作为荧光标记物,通过融解曲线分析和电泳确定目的条带,2-δδct法进行相对定量。
6、结果
结果如图1所示,gsdma在不同分化程度的组织中呈现显著性差异,且分化程度越低,gsdma的表达水平越低,提示gsdma可作为分子标志物应用于口腔鳞癌分化等级的判断,从而指导医生对危险度高中低不同的口腔鳞癌患者采取不同的治疗策略、手段及措施,不但可以避免过度治疗,也可以避免治疗强度不足,从而提高口腔鳞癌患者的治疗效果
上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。
序列表
<110>湖南中南大学湘雅口腔医院
<120>生物标志物在评估口腔鳞癌危险程度中的应用
<160>6
<170>siposequencelisting1.0
<210>1
<211>1338
<212>dna
<213>homosapiens
<400>1
atgaccatgtttgaaaatgtcacccgggccctggccagacagctaaaccctcgaggggac60
ctgacaccacttgacagcctcatcgacttcaagcgcttccatcccttctgcctggtgctg120
aggaagaggaagagcacgctcttctggggggcccggtacgtccgcaccgactacacgctg180
ctggatgtgcttgagcccggcagctcaccttcagacccaacagacactgggaattttggc240
tttaagaatatgctggacacccgagtggagggagatgtggatgtaccaaagacggtgaag300
gtgaagggaacggcagggctctcgcagaacagcactctggaggtccagacactcagtgtg360
gctcccaaggccctggagaccgtgcaggagaggaagctggcagcagaccacccattcctg420
aaggagatgcaagatcaaggggagaacctgtatgtggtgatggaggtggtggagacggtg480
caggaggtcacactggagcgagccggcaaggcagaggcctgcttctccctccccttcttc540
gccccattggggctacagggatccataaatcacaaggaggctgtaaccatccccaagggc600
tgcgtcctggcctttcgagtgagacagctgatggtcaaaggcaaagatgagtgggatatt660
ccacatatctgcaatgataacatgcaaaccttccctcctggagaaaagtcaggagaggag720
aaggtcatccttatccaggcatctgatgttggggacgtacacgaaggcttcaggacacta780
aaagaagaagttcagagagagacccaacaagtggagaagctgagccgagtagggcaaagc840
tccctgctcagctccctcagcaaacttctagggaagaaaaaggagctacaagaccttgag900
ctcgcacttgaaggggctctagacaagggacatgaagtgaccctggaggcactcccaaaa960
gatgtcctgctatcaaaggaggccgtgggcgccatcctctatttcgttggagccctaaca1020
gagctaagtgaagcccaacagaagctgctggtgaaatccatggagaaaaagatcctaccc1080
gtgcagctaaagctggtggagagcacgatggaacagaacttcctgctggataaagagggt1140
gttttccccctgcaacctgagctgctctcctcccttggggacgaggagctgaccctcacg1200
gaggctctagtcgggctgagtggcctggaagtgcagagatcgggcccccaatatatgtgg1260
gacccagacaccctccctcgcctctgtgctctttatgcaggcctctctctccttcagcag1320
cttaccaaggcctcctaa1338
<210>2
<211>445
<212>prt
<213>homosapiens
<400>2
metthrmetphegluasnvalthrargalaleualaargglnleuasn
151015
proargglyaspleuthrproleuaspserleuileaspphelysarg
202530
phehisprophecysleuvalleuarglysarglysserthrleuphe
354045
trpglyalaargtyrvalargthrasptyrthrleuleuaspvalleu
505560
gluproglyserserproseraspprothraspthrglyasnphegly
65707580
phelysasnmetleuaspthrargvalgluglyaspvalaspvalpro
859095
lysthrvallysvallysglythralaglyleuserglnasnserthr
100105110
leugluvalglnthrleuservalalaprolysalaleugluthrval
115120125
glngluarglysleualaalaasphispropheleulysglumetgln
130135140
aspglnglygluasnleutyrvalvalmetgluvalvalgluthrval
145150155160
glngluvalthrleugluargalaglylysalaglualacyspheser
165170175
leuprophephealaproleuglyleuglnglyserileasnhislys
180185190
glualavalthrileprolysglycysvalleualapheargvalarg
195200205
glnleumetvallysglylysaspglutrpaspileprohisilecys
210215220
asnaspasnmetglnthrpheproproglyglulysserglygluglu
225230235240
lysvalileleuileglnalaseraspvalglyaspvalhisglugly
245250255
pheargthrleulysglugluvalglnarggluthrglnglnvalglu
260265270
lysleuserargvalglyglnserserleuleuserserleuserlys
275280285
leuleuglylyslyslysgluleuglnaspleugluleualaleuglu
290295300
glyalaleuasplysglyhisgluvalthrleuglualaleuprolys
305310315320
aspvalleuleuserlysglualavalglyalaileleutyrpheval
325330335
glyalaleuthrgluleuserglualaglnglnlysleuleuvallys
340345350
sermetglulyslysileleuprovalglnleulysleuvalgluser
355360365
thrmetgluglnasnpheleuleuasplysgluglyvalpheproleu
370375380
glnprogluleuleuserserleuglyaspglugluleuthrleuthr
385390395400
glualaleuvalglyleuserglyleugluvalglnargserglypro
405410415
glntyrmettrpaspproaspthrleuproargleucysalaleutyr
420425430
alaglyleuserleuleuglnglnleuthrlysalaser
435440445
<210>3
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>3
caaaggcaaagatgagtg18
<210>4
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>4
cttctcctctcctgactt18
<210>5
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>5
ctctggtaaagtggatattgt21
<210>6
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>6
ggtggaatcatattggaaca20
- 还没有人留言评论。精彩留言会获得点赞!