基于近红外PCA分析判别片剂包衣终点的方法及其应用与流程
本发明涉及一种薄膜包衣终点判别方法,具体涉及基于近红外pca分析判别片剂包衣终点的方法及其应用。
背景技术:
近年来,近红外光谱结合判别模式分析技术,由于可直接对样品进行快速、无损检测,而被广泛应用于制药行业的过程分析技术。该技术已用于缓控释制剂、糖包衣片、滴丸、肠溶片、中药片剂薄膜包衣及在线监测等包衣终点判断领域的研究。主成分分析法(principalcomponentanalysis,pca)是一种有效地数据降维的方法。该方法是基于方差最大原则,将原始数据进行特征分解,得到相互正交的新变量(主成分)。方差越大的主成分则包含原始数据的信息也就越大。因而,利用较少的几个主成分变量就可以包含原始数据的信息,实现数据的特征提取。
现有技术中,授权专利cn101713731a“一种药物制剂包衣质量的鉴别方法”,其公开了通过结合近红外光谱、间隔主成分分析法和支持向量机法等方法快速建立了包衣质量定性鉴别模型。由于上述专利中采用的间隔主成分分析法是以特征信息与类别的相关性最大为原则,分类结果不准确,而且受预处理的影响大,部分测试结果还不足40%,预测包衣终点的准确率低。此外,上述专利中用于鉴别的样品标记为合格与非合格,仅适用于包衣终点合格性鉴定,而无法呈现包衣过程变化,因而不适用于包衣过程监测。
因此,本发明致力于开发一种准确率更高、适用于过程监测的近红外结合主成分分析法测定薄膜包衣终点的方法。
技术实现要素:
本发明的目的在于提供一种快速便捷、简单准确的判别片剂薄膜包衣终点的方法及其应用。该法利用近红外技术采集得到的薄膜衣标准片的近红外图谱,建立pca分析模型,从而对待测片剂进行薄膜包衣进程监测和薄膜包衣终点的判断。
为了实现上述目的,本发明采用以下技术方案:
一方面,提供了一种基于近红外pca分析判别片剂包衣终点的方法及其应用,包括以下步骤:
s1.采集近红外光谱:采集薄膜包衣标准片和片剂薄膜包衣全过程内样品的近红外光谱;
s2.处理近红外光谱:对步骤s1获得的近红外光谱作残差分析,检测并剔除明显远离平均光谱的异常光谱,再经预处理和pca分析处理,即得主成分信息;
s3.建立pca终点判别模型:利用步骤s2获得的主成分信息,计算主成分得分值,进行pca终点判别模型建模,并建立pca得分图;
s4.终点判断:运用步骤s3中的pca终点判别模型对待测片剂薄膜包衣全过程内样品的薄膜包衣进程监测和薄膜包衣终点情况进行判断;所述判断标准为:在pca得分图中,当第一个主成分得分值pc1未到达阈值时即未到达薄膜包衣终点。
进一步地,步骤s1中薄膜包衣标准片是指通过实验或专家确定的进入薄膜包衣终点的薄膜包衣片,具体的是指符合药典标准的薄膜包衣片或经过防潮实验、崩解实验、口感评价等实验确定进入薄膜包衣终点的薄膜包衣片;所述片剂薄膜包衣全过程内样品包括片芯、不同薄膜包衣时间但未进入薄膜包衣终点的中间片和薄膜包衣成品片。
进一步地,步骤s3pca得分图中,标准片与片芯、中间片在第1个主成分得分值pc1的分布有明显差异,据此分析标准片的类簇第一个主成分得分值pc1的边界,得到终点判别的阈值。
更进一步地,pca得分图上呈现顺序为:
所述片芯分布在得分图的最左侧;所述标准片分布在得分图的最右侧;所述中间片在得分图的分布随时间递增向右侧平移;所述标准片与所述片芯、中间片在得分图上分布有清晰的界限。
进一步地,步骤s2中预处理包括平滑处理、多元散射校正、标准正太变量变换、导数微分、傅里叶变换、小波变换中的一种或几种的组合。
更进一步地,导数微分为二阶导数。
另一方面,提供了一种利用上述方法应用于制药领域中薄膜包衣进程监测和薄膜包衣终点情况进行判断。
有益效果:
1.本发明发现在建立pca判别分析模型时,在所得pca得分图上,经观察和计算发现近红外光谱经预处理和pca分析处理后,提取得到的第一个主成分得分值pc1与薄膜包衣时间呈正相关,经pearson相关性检验得到相关系数r=0.987,p值=0.02,证明薄膜包衣时间与第一个主成分得分值pc1呈高度正相关,这与pca得分图显示结果一致。且随时间增大,pc1将增大,样品分布将向右侧偏移,可直观呈现整个薄膜包衣进程。为直观反映测试样品与标准片间的光谱差异,采用pc1与置信区间相结合,实现薄膜包衣过程监测与薄膜包衣终点判别。因此,相比于生产中常用的称重法、人工肉眼辨别等薄膜包衣过程质量控制方法,本文方法的优势在于快速、准确,能更客观、准确地反映薄膜包衣进程和质量。
2.本发明较现有的间隔pca判别分析模型,在pca模型做主成分分析前,以类别间对应特征信息相差最大为原则确定优选光谱波段,再对光谱波段上的信息进行主成分分析的特征提取,特征信息能使得不同类别间相差最大,不同类别间才更容易分辨,即分类结果更准确。因此,从分类性能上看,本发明方法更优;从准确率上看,间隔pca模型分析内部交叉的仅为90%,而本发明的数据在数据量更多的情况下,均为99%以上;其次,间隔pca模型分析的结果明显受预处理的影响,部分测试结果还不足40%,而本发明方法准确率远高于此;再者,现有方法仅仅是用于薄膜包衣终点合格线的鉴定,无法对薄膜包衣过程变化进行监测。而本发明方法不仅用于终点判断,还可有效地反映薄膜包衣状态随时间变化,逐渐向薄膜包衣终点靠近,可适用于过程监测。
附图说明
图1是地格达-4味汤片片芯近红外原始光谱;
图2是地格达-4味汤片薄膜包衣中间片的近红外原始光谱;
图3是地格达-4味汤片薄膜包衣过程内各时间点的近红外平均光谱;
图4是地格达-4味汤片薄膜包衣过程片的与标准片经预处理的近红外光谱;
图5是地格达-4味汤片薄膜包衣过程片与标准片的pca得分图;
图6是本发明方法所得nc系数与薄膜包衣时间的关系图;
图7是合格率随时间变化趋势图;
图8是roc曲线图。
具体实施方式
下面结合实施例对本发明做进一步的描述,有必要在此指出的是以下实施例只是用于对本发明进行进一步的说明,不能理解为对本发明保护范围的限制,该领域的技术熟练人员根据上述发明内容所做出的一些非本质的改进和调整,仍属于本发明的保护范围。
下面通过具体的近红外pca分析建立薄膜包衣终点判别模型实验,来进行说明,包括如下步骤:
1.挑选一级品以及以上等级成品薄膜包衣片作为薄膜包衣标准片,进行近红外漫反射的光谱,并将其近红外光谱作为参照光谱。
在本申请中所述的薄膜包衣标准片,是指通过实验或专家确定的进入薄膜包衣终点的薄膜包衣片,具体的是指符合药典标准的薄膜包衣片或经过防潮实验、崩解实验、口感评价等实验确定进入薄膜包衣终点的薄膜包衣片。
2.从片芯开始抽样,采集片剂薄膜包衣全过程内样品进行近红外漫反射的光谱。
3.将近红外光谱进行预处理,预处理方法包括:平滑处理、多元散射校正、标准正太变量变换(snv)、微分、傅里叶变换等预处理,并用遗传算法(ga)、间隔最小二乘法(ipls)、组合偏最小二乘法(sipls)、无信息变量消除法(uve)、退火算法、竞争自适应重加权采样(cars)等相关算法对光谱进行光谱段的选择。
这些预处理方法可单独使用,也可以是多个的组合使用,以达到最佳的预处理效果。采集过程中,高频随机噪声、基线漂移严重、信号本底过强、样品不均匀、光散射等因素都会影响光谱质量,进而影响模型的准确性。因此提取光谱特征信息前,必须对光谱进行预处理。
4.将薄膜包衣标准片与片剂薄膜包衣全过程内样品的近红外光谱经预处理,再对其进行pca处理,得到主成分信息。从上述主成分信息中,选择与薄膜包衣时间高度相关的信息作为光谱特征,结合置信区间,建立薄膜包衣终点判别模型。具体算法流程:(1)计算主成分得分值;(2)确定含有薄膜包衣时间的主成分得分值作为光谱特征;(3)计算合格片光谱特征的置信区间;(4)判别测试样品,判断其主成分得分值是否在(3)所述的置信区间范围内。参考光谱的置信区间的计算公式如下:
置信区间=
其中,
为方便判别测试样品的合格性,结合上述公式(1)提出了判别系数
其中,
5.采用g-mean用于评价模型性能,f值衡量少数类(终点类别)的分类性能。采用auc值对不同模型性能进行比较。
考虑采用过程是以一定时间间隔采集相同数量的样品,而标准片仅出现在薄膜包衣终点时刻,剩余的样品均为非薄膜包衣终点片(片芯与中间片)。因此非薄膜包衣终点片的数量远多于标准片,出现了样本不均衡现象。普通的正确率将主要受多数类结果的影响,而无法有效评价模型性能。为此,采用几何平均值g-mean对模型整体性能进行评价,而对少数类的分类性能采用f值。考虑对少数类别的查全率与查准率是同等重要,因而β=1,即f值。具体见公式(4)、(5),将标准片类别设为正类,非终点的类别设为负类,p+为正类查准率,p-为负类查准率,r+为正类查全率,r-为负类查全率。g-mean越接近1表明模型分类性能越好,f值越接近1表明对终点类别的分类效果越好。auc值是roc曲线下方面积,该值越大的模型,模型整体性能越好。
实施例1
将本发明的方法应用于地格达-4味汤片薄膜包衣进度监测和终点的快速判断,地格达-4味汤片的薄膜包衣材料为欧巴代胃溶型黄色薄膜包衣粉。
1.实验材料
(1)实验仪器:
包衣锅:ht/f700无孔包衣机(意大利immergas公司);
近红外光谱仪:micronironsite便携式近红外光谱仪(viavisolutions公司),光谱采集软件:micronirprov2.5.1,处理软件:pycharm2018.2.4软件;
扫描条件:波长范围908.0-1678.8nm,积分时间7.9ms,扫描次数100次;测试条件:温度23±3℃,湿度25±4%。
(2)实验样品:
地格达-4味汤片片芯、12个不同薄膜包衣时间的样品中间片、薄膜包衣成品片(实验室自制);经人工挑选出合格片作为薄膜包衣标准片,另外6个批次为片剂薄膜包衣全过程内样品,批号分别为20191126a、20191126b、201912101、201912102、201912103、201912104。
2.实验方法和结果
2.1获取近红外原始平均光谱
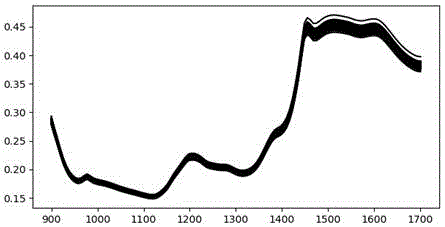
将薄膜包衣标准片、片芯与中间片按扫描条件和测试条件,获得近红外原始平均光谱,如图1所示;再将获得的近红外原始平均光谱,经基于pca的nir薄膜包衣终点判别软件读取显示,读取结果如图2所示。
为考察模型对薄膜包衣合格性判别能力,在建模前需对样品类别标记为合格片与非合格片。结合薄膜包衣液用量、薄膜包衣时间、人工辨认,将0-130min时间段内14个点和合格片置于同一图谱中进行比较,如图3所示。由图3分析可知,在波段908.0-1412.2nm处吸光度上,0-100min的样品与合格片差异显著,可能是因片芯表面衣膜不完整或不均匀;而100min后的样品与合格片光谱差异不显著,可能是部分样品已合格。因此,对0-100min样品标记为非合格片,而仅对薄膜包衣终点的样品标记为合格片。
2.2预处理和pca分析处理
采用snv+二阶导数预处理方法,对薄膜包衣标准片、片芯与中间片的近红外光谱图进行预处理,结果如图4所示。由图4可知,其信噪比相比于原始光谱得到了明显改善,光谱的分辨率也得到相应提高。
再经pca分析处理,提取前两个主因子(pc1、pc2)。将薄膜包衣标准片设为数据集,6批片剂薄膜包衣全过程内样品的主成分信息,批次20191126a、201912102设为训练集,批次20191126b、201912101、201912103、201912104设为外部测试集建立模型。
2.3建立pca终点判别模型
将步骤2.2中获得的样品主成分信息,计算主成分得分值,进行pca终点判别模型建模,并建立pca得分图;在pca得分图中,标准片与片芯、中间片在第1个主成分得分值pc1的分布有明显差异,据此分析标准片的类簇第一个主成分得分值pc1的边界,得到终点判别的阈值
6批次片剂薄膜包衣全过程内样品,在pca得分图中,当第一个主成分得分值pc1未到达阈值时即未到达薄膜包衣终点,如图5所示,横坐标为第一个主成分得分值pc1,纵坐标为第二个主成分得分值pc2,从图中可知,随着薄膜包衣时间增加,中间片在pca得分图的分布随时间递增向右侧平移,到达薄膜包衣终点标准片集中在右侧。
pca判别模型模型性能评价:
训练集进行分层k折交叉验证(k=4)作为内部验证,用于预处理选择与优化模型,找到最佳的建模条件。将由训练集得到的模型对外部测试集进行预测作为外部测试,得到相应指标的均值及其相对标准偏差,验证模型性能与泛化能力。
判别模型模型性能评价指标f值和g-mean,分别采用分层k折内部验证和外部验证,计算性能指标均值与相对标准差(rsd)。具体情况如表1所示:利用内部交叉验证对比不同预处理,得到最佳预处理方法。内部验证结果表明,模型在训练集上具有良好性能,对终点分析准确且性能稳定。外部验证结果显示,g-mean接近1,f值良好,表明模型整体性能良好,对终点的分类效果好,而这两个指标对应的相对标准偏差rsd均小于5%,说明模型对多个数据集的测试结果稳定,因而该方法性能良好且稳定,具有良好的预测能力和鲁棒性。
表1pca判别模型评价指标
3.结论
i.在pca得分图中,不同薄膜包衣时间片剂呈现一定分布规律。图5所示,片芯分布在得分图的最左侧,标准片分布在得分图的最右侧,中间片在得分图的分布随时间递增向右侧平移,即薄膜包衣时间与pc1值呈正相关性。
为更具体对薄膜包衣过程进行分析,采用本发明所得nc系数分析整个薄膜包衣过程上的片剂与合格片的光谱差异,得到薄膜包衣时间与nc系数的变化趋势,进而实现薄膜包衣的过程分析,具体可见图6。如图6所示,随薄膜包衣时间的增加,nc值有整体下降趋势,表明样品与合格片间的差异程度逐渐减小。模型判别参数nc系数的具体表现为:(1)0min素片(片芯)模型判别参数分布集中,说明素片一致性好;(2)10-20min的样品模型判别参数与0min差异性小,表明大部分样品仍为素片;(3)30-40min的样品模型判别参数分布较分散,表明部分样品的衣膜开始形成;(4)50-90min的样品的模型判别参数有下降趋势,且样品与合格片的差异减小,表明衣膜逐渐形成;(5)100min后的样品中合格片数量随时间增加而增多,在薄膜包衣终点上基本为合格片。结果表明,(1)素片一致性好,而在生产上薄膜包衣片与素片间的差异主要来自衣膜。因此,近红外光谱可有效反映薄膜包衣片与素片间由衣膜引起的差异;(2)模型判别参数对薄膜包衣合格性判别准确,并对衣膜形成过程有一定解释能力,可用于过程分析。此外,为整体分析,采用模型预测合格率及其变化趋势进行过程分析与薄膜包衣终点判别。利用上述模型对测试集样品合格率计算,如图7所示,其中横坐标为时间,纵坐标为预测终点比例,虚线为合格率95%并作为薄膜包衣终点判别的阈值。合格率整体变化趋势:(1)0-70min的合格率约为0,几乎为非合格片;(2)80-90min的合格率不足25%,开始出现少量合格片;(3)100min-薄膜包衣终点时刻好的合格率逐渐增加。
ii.pca得分图中,未到达薄膜包衣终点的片剂与标准片的分布能比较清晰的分辨。如图5所示,此处的垂线可作为未到达薄膜包衣终点与已到达薄膜包衣终点的分界线。因此,pc1与薄膜包衣时间存在较高的相关性。为验证,采用pearson相关性检验分析薄膜包衣时间与pc1的相关性,计算得到相关系数r=0.987,p值=0.02,证明薄膜包衣时间与第一个主成分得分值pc1呈高度正相关,因而在pca得分图中可反映薄膜包衣进程——随薄膜包衣时间增加,pc1增加,样品将向右侧的薄膜包衣终点区域逐渐靠近。对pca判别模型的内部验证与外部验证的f值分别为0.838和0.835,g-mean分别为0.96和0.926,且两项指标的相对标准偏差(rsd)均小于5%,因而具有良好的预测能力和鲁棒性。此外,将pca判别模型与决策树判别模型和k近邻判别模型做性能比较,结果表明pca判别模型的性能更优。由此,表明本模型可进行对未知样品的薄膜包衣进程监测和薄膜包衣终点的快速判断。
对比例1
采用决策树判别模型
步骤2.1和2.2采用同实施例1,步骤2.3建立决策树判别模型,所建立的决策树判别模型模型性能评价如下:
决策树判别模型模型性能评价:
判别模型模型性能评价指标f值和g-mean,分别采用分层k折内部验证和外部验证,计算性能指标均值与相对标准差(rsd)。具体情况如表2所示:利用内部交叉验证对比不同预处理,得到最佳预处理方法。内部验证结果表明,模型在训练集上具有良好性能,对终点分析准确且性能稳定。外部验证结果显示,g-mean接近1,f值良好,表明模型整体性能良好,对终点的分类效果良好,但这两个指标对应的相对标准偏差rsd均大于13%,说明模型对多个数据集的测试结果稳定性较差。因而,该方法稳定性差,泛化能力差,不能作为终点判断模型。
表2决策树判别模型评价指标
对比例2
采用k近邻判别模型
步骤2.1和2.2采用同实施例1,步骤2.3建立k近邻判别模型,所建立的k近邻判别模型模型性能评价如下:
决策树判别模型模型性能评价:
判别模型模型性能评价指标f值和g-mean,分别采用分层k折内部验证和外部验证,计算性能指标均值与相对标准差(rsd)。具体情况如表3所示:利用内部交叉验证对比不同预处理,得到最佳预处理方法。内部验证结果表明,模型在训练集上具有良好性能,对终点分析准确且性能稳定。外部验证结果显示,g-mean接近1,f值良好,表明模型整体性能良好,对终点的分类效果良好,但f值的相对标准偏差rsd略大于5%,g-mean略小于5%,说明模型对多个数据集的测试结果有一定浮动,但对不同测试数据集的结果无明显差异。因而,该方法预测能力良好,但稳定性一般,仍需进一步改进。
表3k近邻判别模型评价指标
将实施例1和对比例1-2,采用评价指标比较与auc值,对pca判别分析、决策树判别模型和k近邻判别模型,这三个判别模型的性能进行比较,结果见表4与图8。由表4各指标参数可知,f值与g-mean无明显差异,而相应相对标准差rsd中,决策树表现最差,因而决策树性能最差。在比较pca判别模型与k近邻模型时,发现f值、g-mean指标上k近邻法优于pca判别模型,说明k近邻模型预测能力更优,而相应相对标准偏差rsd上pca判别模型优于k近邻法,说明pca判别模型的稳定性更优。为综合比较模型性能,采用roc曲线分析,计算auc值,如图8所示。图8结果显示roc曲线上,其中横坐标为伪正类率,纵坐标为真正类率。pca判别模型为最上方曲线,pca判别模型下方面积包含了k近邻法判别模型,而k近邻法判别模型又包含了决策树判别模型,具体表现为pca判别模型的auc值更大,因此本文提出的pca判别模型最佳。模型性能优劣关系为:pca判别模型>k近邻法判别模型>决策树判别模型。
表4不同判别模型评价指标比较
- 还没有人留言评论。精彩留言会获得点赞!