一种基于射频信号的细粒度多尺度人体姿态估计方法
本发明属于无线智能感知,具体涉及一种基于射频信号的细粒度多尺度人体姿态估计方法。
背景技术:
1、人体姿态估计在医疗保健、安全监控、虚拟现实和增强现实、自动驾驶和交通安全、人机交互等领域有着重要的应用价值。相较于目前主流的光学相机方法,毫米波雷达不依赖可见光或红外线,因此可以在低光照、夜晚或恶劣天气条件下工作。此外相较于传统光学方法所带来的隐私问题,毫米波雷达不生成可识别的图像,因此对被监测者有一定的隐私保护,这在需要保护个人隐私的应用场景中很有价值,如安全检查或医疗保健。毫米波信号对于许多大气和天气条件具有较好的抗干扰性,因此在室外环境中的性能相对稳定。毫米波能够穿透一些材料,如衣物和非金属物体,因此可以在一定程度上检测到被遮挡的部分,这对于在现实世界应用是具有优势的,因为人体姿态可能会被物体或衣物部分遮挡。
2、基于毫米波点云的人体姿态估计中面临挑战:受限于天线数量和芯片处理能力,毫米波雷达产生的点云数据极其稀疏,难以直接看出物体的详细结构。目前多采用深度神经网络模型直接对毫米波雷达感知到的全局点云数据进行特征提取并估计出姿态,缺乏对多尺度信息的感知和利用,特别是有针对性的多尺度目标点云增强和多尺度人体姿态估计神经网络结构设计。
技术实现思路
1、针对现有技术的不足,本发明提出一种基于射频信号的细粒度多尺度人体姿态估计方法。
2、具体技术方案如下:
3、一种基于射频信号的细粒度多尺度人体姿态估计方法,包括以下步骤:
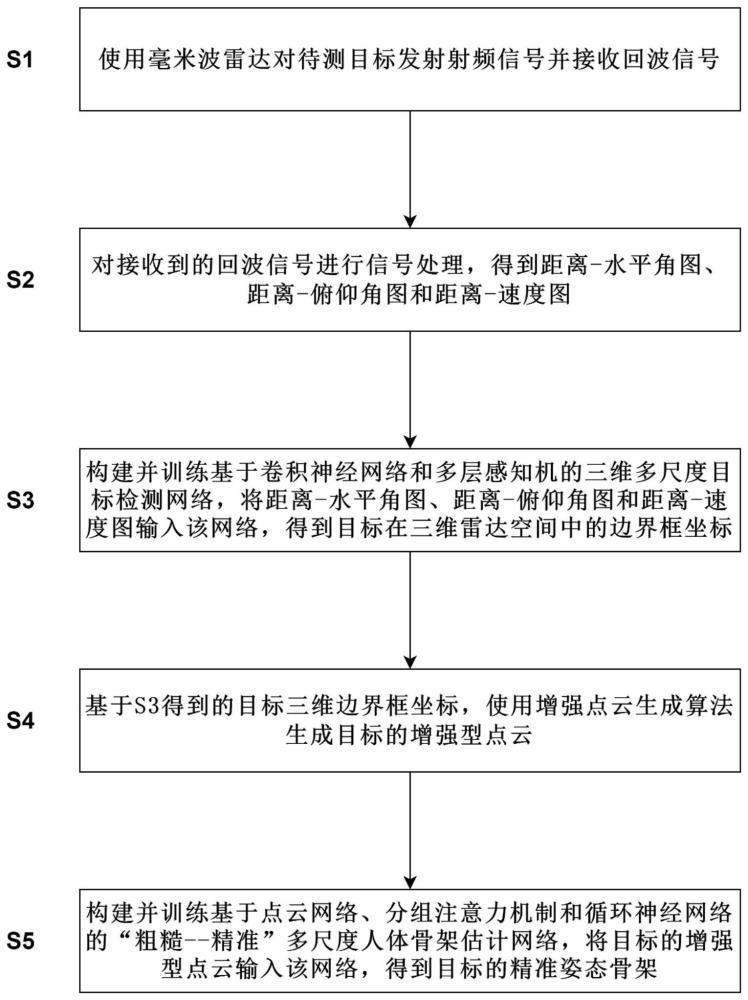
4、步骤s1:使用毫米波雷达对待测目标发射射频信号,并接收回波信号;
5、步骤s2:对接收到的回波信号进行信号处理,得到距离-水平角图、距离-俯仰角图和距离-多普勒图;
6、步骤s3:构建并训练基于卷积神经网络和多层感知机的三维多尺度目标检测网络,将距离-水平角图、距离-俯仰角图和距离-多普勒图输入该网络,得到目标在三维雷达空间中的边界框坐标;
7、步骤s4:基于s3得到的目标三维边界框坐标,使用增强点云生成算法生成目标的增强型点云;
8、步骤s5:构建并训练基于点云网络、分组注意力机制和循环神经网络的多尺度人体骨架估计网络,将目标的增强型点云输入多尺度人体骨架估计网络,得到目标的精准姿态骨架。
9、进一步地,所述步骤s2通过以下子步骤实现:
10、s21:对于由模数转换器(analog to digital converter,adc)采样的每一帧雷达数据data,其形状为(nc,na,ne,ns),其中nc代表啁啾(chirp)个数,na代表水平方向虚拟天线个数,ne代表垂直方向虚拟天线个数,ns代表adc采样点的个数。首先在data的adc采样维度ns上使用快速傅里叶变换(fast fourier transform,fft)得到data′;
11、s22:在data′的水平方向虚拟天线维度上使用快速傅里叶变换得到距离-水平角图;
12、s23:在data′的垂直方向虚拟天线维度上使用快速傅里叶变换得到距离-俯仰角图;
13、s24:在data′的chirp维度上使用快速傅里叶变换得到距离-多普勒图;
14、s25:根据实验场地范围的大小分别裁剪距离-水平角图、距离-俯仰角图和距离-多普勒图,具体裁剪方式为:设定实验场地为l×w×h的立体空间,其中l为长度,w为宽度,h为高度;则距离维度裁切后长度为水平角维度裁切后长度为俯仰角维度裁剪后长度为其中rres为距离分辨率,ares为水平角分辨率,eres为俯仰角分辨率。
15、进一步地,所述步骤s3通过以下子步骤实现:
16、s31:构建基于卷积神经网络(cnn)和多层感知机(mlp)的三维多尺度目标检测网络;该网络的输入为距离-水平角图(ramap)、距离-俯仰角图(remap)和距离-多普勒图(rdmap),将上述三张图分别输入各自的卷积神经网络cnn中,得到各自特征yi1,i1∈{ramap,remap,rdmap};
17、将yi1进行拼接得到特征z,再将z输入多层感知机mlp中得到目标三维边界框坐标o。
18、s32:训练基于卷积神经网络和多层感知机的三维多尺度目标检测网络,提出优化的三维目标检测损失函数lb,可以准确检测目标在雷达三维空间位置,同时使得预测边界框中尽可能包裹目标边界框,避免目标部分丢失导致点云生成质量下降,lb的定义为:
19、
20、其中,α,β,γ为超参数;表示目标三维边界矩形框的三个维度:距离r、水平角a、俯仰角e,均使用平滑损失smooth l1损失;表示在距离r和水平角a使用lwarp损失函数;表示在距离r和俯仰角e使用lwarp损失函数,其中lwarp定义为:
21、
22、其中slabel为真实目标框的面积,slabel∩pred为真实目标边界框与预测目标边界框面积的交集。使用adam优化器最小化估计目标三维边界框与真实目标三维边界框之间的损失lb。
23、进一步,所述步骤s31中,具体的cnn模块和mlp模块结构如下:其中cnnii∈{ramap,remap,rdmap}均由8个卷积层组成,且每个卷积层后均使用批量归一化和relu激活函数,分别将ramap输入cnnramap;remap输入cnnremap;rdmap输入cnnrdmap,得到三个长度均为512的中间特征yi1,i1∈{ramap,remap,rdmap}。拼接yi1,i1∈{ramap,remap,ramap}后输入由9个线性层组成的mlp得到目标三维边界框坐标其中包括目标在距离维度中的范围,水平角维度中的范围和俯仰角维度中的范围。
24、进一步地,所述步骤s4通过以下子步骤实现:
25、s41:根据预测的目标三维边界框中的距离维度范围对s24得到的距离-多普勒图进行距离维度裁切;
26、s42:将裁切后的距离-多普勒图的像素值按从大到小进行排序,并依次进入队列q;
27、s43:从队列q的队首取出一个点,分别使用fft计算出该点的水平角θ1和俯仰角
28、s44:判断该点的水平角θ1和俯仰角是否在预测的目标三维边界框内;
29、s45:如果该点在预测的目标三维边界框内,则将其标记为有效点并进行空间转换;
30、s46:如果该点不在预测的目标三维边界框内,则丢弃,并重复s43直到有效点个数达到n或队列为空;
31、s47:如果队列为空,判断有效点个数是否大于0,如果大于零则随机复制已有的有效点,使有效点的总数达到n;如果等于0则使用零填充n个点,保证点数的一致性;
32、s48:输出包含n个点的点云数据,即目标的增强型点云。
33、进一步地,所述步骤s45中,每个有效点包含其在雷达空间的距离r,水平角θ1,俯仰角多普勒d;空间转换公式为:
34、
35、其中,dres为多普勒分辨率,为雷达adc采样数据分别执行距离、速度、水平角和俯仰角快速傅里叶变换之后的值;x,y,z,v,e分别为该点在笛卡尔坐标系中的x,y,z坐标、速度和能量值。
36、进一步地,所述步骤s5通过以下子步骤实现:
37、s51:构建并训练基于点云网络、分组注意力机制和循环神经网络的多尺度人体骨架估计网络;
38、多尺度人体骨架估计网络由粗糙估计模块(coarsemodule)和精准估计模块(finemodule)组成,其输入为s4得到的增强型目标点云pcl,具体公式为:
39、pc,fskip=coarsemodule(pcl)
40、pf=finemodule(pcl,pc,fskip)
41、其中pc为coarsemodule输出的粗糙人体姿态骨架,fskip为连接特征,pf为finemodule输出的目标人体精准姿态骨架。
42、s52:训练基于点云网络、注意力机制和循环神经网络的多尺度人体骨架估计网络,使用优化器最小化估计目标骨架与真实骨架之间的损失lp,其公式为:
43、
44、其中,λ和μ是超参数,表示使用l1损失优化pc和实际值之间的误差,表示使用l1损失优化pf和实际值之间的误差。将步骤s4得到的目标点云输入到训练好的人体骨架估计网络中得到对应的人体姿态骨架预测值。
45、进一步地,所述步骤s51通过以下子步骤实现:
46、s511:对于coarsemodule由共享多层感知机(sharedmlp)、注意力机制(attention)和门控循环单元(gru)组成,其公式为:
47、
48、
49、
50、
51、其中i2∈{s,a,g,m}为各模块可学习的参数;i3∈{1,2}分别为sharedmlp模块和attention的输出特征;fskip是gru模块的输出特征;pc为mpl模块的输出的粗糙人体姿态骨架;
52、s512:对于finemodule由分组(group)、sharedmlp、attention、gru、拼接(concat)和mlp组成,其公式为:
53、
54、
55、
56、
57、
58、
59、其中i2∈{s,a,g,m},j∈{1,2,…,njoint}为各模块可学习的参数;i5∈{1,2,3,4},j∈{1,2,…,njoint}分别为sharedmlp、attention、gru和concat模块输出的每个关节点聚簇特征;pf为mlp模块的输出的精准人体姿态骨架;concat表示对输入的特征向量fskip与j∈{1,2,…,njoint}进行拼接操作。
60、进一步地,所述步骤s511中sharedmlpc模块与步骤s512中sharedmlpf,i4 i4∈{1,2,…,njoint}结构相同,均以卷积核为1的多层卷积实现。
61、进一步地,所述步骤s511中attentionc模块与步骤s512中attentionf,i4结构相同,对于输入为b×p×f的数据,其中b为批量大小,p为点云中点的个数,f为特征向量长度。首先使用线性层将特征向量长度f变换为1;再对点个数维度p进行softmax操作,将结果作为注意力分数,将输入数据与注意力分数相乘并在p维度上进行求和操作最终得到的特征形状为b×p。
62、进一步地,所述步骤s511中gruc模块与步骤s512中gruf,i4模块参数定义如下:gruc的输入大小、隐藏层特征大小均为p;层数为3,其中,p为点云中点的个数。
63、gruf,i4的输入大小、隐藏层特征大小均为k;层数为3,其中k为一个group中的点云点数。
64、进一步地,所述步骤s512中group的具体方式为:以coarsemodule得到的人体粗糙骨架pc中的njoint个关节点为聚簇中心,计算其附近欧氏距离最近的k个点作为一个聚簇,即为一个group,记作gi4。
65、综上所述,本发明使用fft对雷达采集的包含人体活动的数据进行处理;将其输入本发明提出的三维多尺度目标检测网络和点云增强算法获得目标细粒度的点云表示;将目标细粒度的点云数据输入本发名提出的多尺度人体骨架估计网络,得到目标人体姿态数据,实现对人体姿态的精准估计。
66、本发明的有益效果是:
67、(1)本发明提出的三维多尺度目标检测网络学可以学习目标的多尺度特征,预测目标的位置和体积,结合本发明提出的点云增强算法可以获得稳定且较为准确的目标点云数据。
68、(2)本发明提出的多尺度人体骨架估计网络可以分阶段提取目标点云数据中的多尺度特征信息,其预测的人体姿态更为准确。
69、(3)相较于传统的基于视觉的人体姿态估计方法,本发明基于射频信号,工作不受视距,光照强度等不利因素的影响,且能够保护用户一定的隐私。
- 还没有人留言评论。精彩留言会获得点赞!