基于视觉飞行自稳定的方法、计算机可读介质和系统与流程
本发明涉及计算机技术,特别涉及一种基于视觉飞行自稳定的方法、计算机可读介质和系统。
背景技术:
飞行动力学(动态飞行稳定性和控制)在诸如无人驾驶飞行器(UAV)或无人机之类的移动平台的研究中是非常重要的。无人机通常需要一个高度稳定的定位系统,因为位置估计中的随机误差将产生不相干的控制动作,导致UAV的崩溃和贵重硬件的损失。目前,大多数无人机使用GPS获取位置。然而,GPS精度直接取决于估计位置的卫星数量多少。在城市环境,特别是室内环境中数量可以显然是不足的。
此外,用于横向稳定控制的常规方法是通过反馈状态变量来回应计算流体动力学(即横向平移速度,横摆率,滚动速度和滚动角度),其中,状态变量可以由无人机的感觉系统测量。然而,测量精度仍然低于室内环境应用的要求。
本发明公开的方法及其系统用于解决现有技术中的一个或者多个问题。
技术实现要素:
一方面本发明公开了一种深度门控循环Q网络(DGRQN)用于无人驾驶飞行器(UAV)基于视觉飞行自稳的方法,其特征在于,所述方法包括接收由安装在无人机上的相机拍摄的一个以上的原始图像,接收用于稳定的初始参考图像并从所述初始参考图像获得初始相机位姿,提取连续图像之间的基本矩阵并估计相对于所述初始相机位姿的当前相机位姿,其中相机位姿包括所述相机的取向和位置,基于已估计的所述当前相机位姿,预测基于深度门控循环Q网络来抵消所述无人机的横向干扰的动作,和基于预测的所述动作来抵消所述无人机的横向干扰,驱动所述无人机回到所述初始相机位姿。
另一方面本发明还包括一种具有计算机程序的非暂时性计算机可读介质,当由处理器执行时,实现一种深度门控循环Q网络(DGRQN)用于无人驾驶飞行器(UAV)基于视觉飞行自稳的方法,所述方法包括接收由安装在无人机上的相机拍摄的一个以上的原始图像,接收用于稳定的初始参考图像并从所述初始参考图像获得初始相机位姿,提取连续图像之间的基本矩阵并估计相对于所述初始相机位姿的当前相机位姿,其中相机位姿包括所述相机的取向和位置,基于已估计的所述当前相机位姿,预测基于深度门控循环Q网络来抵消所述无人机的横向干扰的动作,和基于预测的所述动作来抵消所述无人机的横向干扰,驱动所述无人机回到所述初始相机位姿。
另一方面本发明还包括一种深度门控循环Q网络(DGRQN)用于无人驾驶飞行器(UAV)基于视觉飞行自稳的系统,所述系统包括相机位姿估计模块(CPE)和深度门控循环Q网络引擎模块,其中所述相机位姿估计模块用于接收由安装在无人机上的相机拍摄的一个以上的原始图像,提取连续图像之间的基本矩阵并估计相对于所述初始相机位姿的当前相机位姿,其中相机位姿包括所述相机的取向和位置;所述深度门控循环Q网络引擎模块用于基于已估计的所述当前相机位姿,预测基于深度门控循环Q网络来抵消所述无人机的横向干扰的动作,和基于预测的所述动作来抵消所述无人机的横向干扰,驱动所述无人机回到所述初始相机位姿。
本发明的其他方面,所属技术领域的技术人员能够依据本发明的权利要求书,说明书,以及附图有效实施并充分公开。
以下附图仅仅是用于解释本发明的具体实施例,并不限制本发明的范围。
附图说明
图1为本发明具体实施方式的工作环境示意图;
图2为本发明具体实施方式的计算机系统的结构框图;
图3为本发明具体实施方式的通过深度门控循环Q网络(DGRQN)实现用于UAV的基于视觉的飞行自稳定的系统结构框图;
图4为本发明具体实施方式的通过DGRQN实现用于UAV的基于视觉的飞行自稳定的方法流程图;
图5为本发明具体实施方式的相对于多个连续视图的初始相机位姿估计现在相机位姿的流程图;
图6为本发明具体实施方式的DGRQN;
图7为本发明具体实施方式的用于根据DGRQN预测无人机横向干扰的动作的方法流程图;
图8为本发明具体实施方式的单个门控循环单元(GRU);
图9为本发明具体实施方式的训练Q网络的方法。
具体实施方式
为了便于理解本发明,下面参照相关附图对本发明进行更全面的描述。下面将结合本发明实施例的附图,对本发明实施例的技术方案进行描述。除非另外指出,在各图中相同的参考数字用于相同或相似的部件。显然,所描述的实施例是本发明的实施例的一部分,而不是全部的实施例。基于所描述的本发明的实施例,本领域普通技术人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
鉴于GPS和感觉系统的不可用性和不准确性,本发明提供了一种用于无人机的通过深度门控循环Q网络(DGRQN)实现基于视觉的飞行自稳定的方法和系统。所公开的系统可以是用于无人机的智能自定位控制系统,其仅基于在室内环境中从车载单目相机捕获的视觉信息。可以改善无人机悬停状态下的自稳定性,并且可以实现在任何运动规划之前给定了初始参考相机视图的无人机的固有稳定性。没有抵抗横向干扰运动的能力,无人机可能很容易偏离预先设计的位置,并且因此可能干扰随后的视觉导航。
在所公开的实施例中,一旦无人机进入悬停状态,基于视觉的飞行自稳定问题可以变为了视觉场景匹配问题。通过给定初始参考相机视图来估计相对于目前为止捕获的多个视图的初始参考相机视图的相机运动,并且通过将无人机驱使回到其起点来抵消相机运动,从而来实现自稳定。
确定无人机是否稳定的标准可以取决于与原始视图的场景匹配的质量。在估计和抵消相机运动的过程中面临了大量不确定性的挑战,例如相机运动估计的准确性以及无人机的精确控制等。在大且高度动态的环境下,在未知环境中通过交互和分析反馈来推断无人机的最佳行为的方法是非常期望的。
此外,在公开的实施例中,基于增强学习范式,无人机可以学习最佳控制行为以通过探索实现自我稳定。尤其是,将初始相机位姿与迄今捕获的多个视图估计的位姿之间的差异结合到深度Q学习框架内的强化学习范式中。其真正的意图是,横向干扰引起的所述无人机运动和所述无人机的控制动作会起到两者相互抵消的作用。通过奖励高质量的场景匹配和惩罚低质量的场面匹配,所述无人机能够逐步学习最优控制的行为以实现自稳定。
图1为本发明具体实施方式的工作环境100示意图,如图1所示,所述环境100包括移动平台102,服务器104,用户106,网络108,其中也可以包括其他设备。所述移动平台102指包括任何合适的移动平台,例如,自行车,汽车,卡车,轮船,船,火车,直升机,飞机和各种混合动力车等。
所述移动平台102可以通过网络108回应来自用户106的命令。所述用户106可以使用遥控器110来控制移动平台102。所述遥控器110可以不连接到所述移动平台102并且可以从远处无线与所述移动平台102通信。所述移动平台102可以遵循一组预定指令。在某些实施例中,所述移动平台102可以通过回应用户106的一个或多个命令半自主地操作,而其他是自主地操作。
在一个实施例中,所述移动平台102可以是无人驾驶飞行器(UAV)或无人机102。各种类型的无人机102可以适用于所公开的系统和方法。例如,所述无人机102可以是由多个旋转器推动的空中旋翼飞机。如图1所示,所述无人机102可以包括机身1021,一个以上旋转器1022和一个或一个以上起落架1023。也可以包括其他合适的部件。
所述机身1021可以包括控制单元,惯性测量单元(IMU),处理器,电池,电源和/或其他传感器。所述旋转器1022可以经由从所述机身1021的边缘或中心部分分支的一个或一个以上臂或延伸部连接到所述机身1021,并且一个或一个以上臂可以在臂的端部处或附近具有所述旋转器1022。所述旋转器1022可以旋转以产生用于无人机102的升力,并且所述无人机102能够通过空气自由移动的推进单元。所述起落架1023可以支撑所述无人机102的重量,并提供滚动底盘/滑行和减震功能。
此外,一个或一个以上图像传感器1024可以安装在无人机102上。所述图像传感器1024可以是基于各种机构的图像传感器,诸如超声波检测器,雷达,单目相机和双目相机等等。所述图像传感器1024可以直接安装在无人机102的所述机身1021上。在一些实施例中,所述无人机102还可以包括设置在所述无人机102的所述机身1021表面上的万向节机构1025。所述图像传感器1024可以附属于所述万向节机构1025,为所述图像传感器1024提供了关于所述机身1021的一个或一个以上轴的旋转自由度。
所述服务器104可以包括用于向所述用户106提供个性化内容的任何适当类型的计算机服务器或一个或一个以上计算机服务器。例如,所述服务器104可以是云计算服务器。所述服务器104还可以促进其他服务器和所述移动平台102之间的通信,数据存储和数据处理。所述移动平台102和所述服务器104可以通过一个或多个通信网络108彼此通信,诸如有线网络,无线网络和/或卫星网络等。
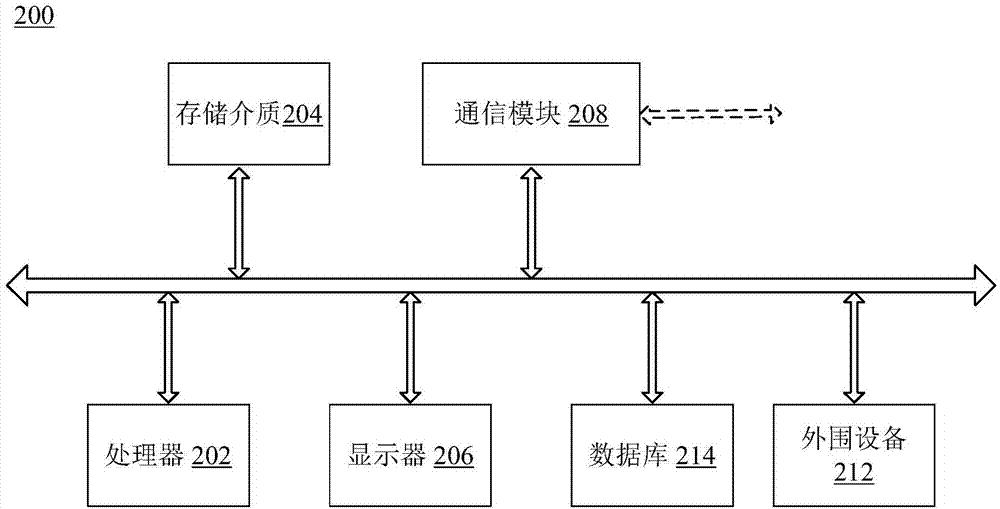
所述移动平台102和/或所述服务器104可以在任何适当的计算电路平台上实现。图2是能够实现所述移动平台102和/或所述服务器104的计算机系统的结构框图。
如图2所示,所述计算机系统200包括处理器202,存储介质204,显示器206,通讯模块208,数据库214以及外围设备212。其中某些组件可被省略,也可以包括其他组件。
所述处理器202可以包括任何合适的一个或多个处理器。具体的,所述处理器202可以包括用于多线程或并行处理的多个核心。所述存储介质204可以包括内存模块,如ROM、RAM、闪存模块和大容量存储器,比如CD-ROM和硬盘等。所述存储介质204可以存储有计算机程序,当所述处理器202执行这些计算机程序时,可以实现各种方法步骤。
具体的,所述外围设备212可以包括各种传感器和I/O设备,比如键盘和鼠标,所述通讯模块208包括用于通过交流网络建立连接的网络交互设备。所述数据库214包括一个或多个数据库以用于存储某些数据以及在存储数据中的进行某些操作,如数据库搜索。
回到图1,通过深度门控循环Q网络实现基于视觉的飞行自稳定系统可以应用所述移动平台102。图3为本发明具体实施方式的通过深度门控循环Q网络(DGRQN)实现用于UAV基于视觉的飞行自稳定的系统。如图3所示,UAV的通过DGRQN实现视觉自稳定系统300包括相机位姿估计(CPE)模块302和深度门控循环Q-网络(DGRQN))引擎模块304。所述CPE模块302还可以包括初始化模块3022和位姿估计模块3024。
所述CPE模块302可以用于为接收一个或一个以上原始图像或原始视图301,在连续视图之间提取基本矩阵,并且相对于初始相机位姿估计当前相机位姿。特别地,所述初始化模块3022可以用于接收为了稳定的参考图像(即,I_ref),并从所述初始参考图像获得初始相机位姿。所述位姿估计模块3024可以用于在连续视图之间提取基本矩阵,并且相对于初始相机位姿估计当前相机位姿。
在一实施例中,所述位姿估计模块3024可以根据来自于两个连续视图的所述初始相机位姿来估计所述当前相机位姿。在另一实施例中,所述位姿估计模块3024可以根据来自于多个连续视图(大于两个)的所述初始相机位姿来估计当所述当前相机位姿。
应当注意,所述位姿估计模块3024可以用于仅在初始化之后估计所述当前相机位姿,即,所述初始化模块3022已经接收到用于稳定的所述参考图像(即,I_ref)。如此初始化可以促进所述初始参考图像和所述后续图像之间的所述场景匹配。
所述DGRQN引擎模块304可以包括增强学习引擎,所述增强学习引擎可以通过无模式强化学习技术Q学习推动的最终神经网络来实现。所述DGRQN引擎模块304可以用于将所述已估计的相机位姿作为所述输入进行编码,预测理想动作305以抵消所述无人机的横向干扰,并且驱使无人机回到其初始位置。在所述无人机行动有明确计划的情况下,增强学习的参与可以减轻其负担。
在一些实施例中,所述UAV通过所述DGRQN的实现基于视觉的飞行自稳定系统300还包括用于为训练Q网络的Q网络训练模块。所述初步模块,所述CPE模块,所述DGRQN引擎模块和所述Q网络训练模块的详细功能将在通过深度门控循环Q-网络(DGRQN)实现基于视觉的飞行自稳定的方法的描述中进一步说明。图4所示为本发明具体实施方式的通过深度门控循环Q-网络(DGRQN)实现基于视觉的飞行自稳定的方法流程图。
如图4所示,开始时接收多个原始图像或原始视图(S402)。特别地,可以通过诸如超声,视觉,飞行时间(TOF)和雷达等各种方法来接收所述原始图像。在所公开的实施例中,可以通过安装在无人机上的单眼相机接收所述原始输入图像,同时接收用于稳定的初始参考图像(即,I_ref),并且从所述初始参考图像获得初始相机位姿(S404)。
在获得用于稳定的所述初始参考图像(即,I_ref)之后,提取连续视图之间的基本矩阵,并且相对于所述初始相机位姿估计当前相机位姿(S406)。
在一个实施例中,可以从两个连续视图中提取连续视图之间的基本矩阵,并且可以从两个连续视图估计当前相机相对于在初始参考图像中获得的初始相机位姿的位姿。特别地,在第一视图和第二视图中分别用同质3维向量q和q'表示图像点。同质的4维向量Q表示世界点。图像投影q~PQ的3×4相机矩阵P表示透视图,其中~表示比例的相等。具有有限投影中心的视图可以被分解为P=K[R|T],其中K是保持固有参数的三角校准矩阵并且R是旋转矩阵。第一视图和第二视图的相机矩阵分别为K1[I|0]和K2[R|T]。[T]×是斜对称矩阵,表示为:
因此对所有x来说,[T]×x=T×x。然后,第一视图和第二视图之间的基本矩阵表示为:
所述基本矩阵可以根据如下等式(3)编码为共面约束或极线约束:
q′TFq=0 (3)
在不知道校准矩阵的情况下,可以考虑第一视图和第二视图之间的基本矩阵。此外,当投影中心不是有限时,基本矩阵可以继续存在。如果K1和K2是已知的,可以认为相机已被校准。在所公开的实施例中,可以认为图像点q和q'分别预先乘以和并且可以将极线约束简化为:
q′TEq=0, (4)
其中,所述矩阵E=[T]×R是必要矩阵。
根据相机是否已被校准,可以使用用于求解F的8点算法或用于求解E的5点算法。例如,给定基本矩阵E,可以通过使用奇异值分解(SVD)来恢复R和t,即E=UΣVT。令
以下公式6中所示的E=[R|t]的四个解决方案,所述四种解决方案是R(即,R1和R2)的两种可能解决方案以及T(即,T1和T2)的两种可能解决方案,所述公式6如下所示:
R1=UWVT,R2=UWTVT,T1=U3,T2=-U3(6)
为了选择真实的配置,首先计算R的行列式,并且需要det(R)=1时有有效解,因为det(R)=-1指R是映射。然后可以使用三角互证来计算3D点,并且有效的解可以具有正的Z值。
在另一个实施例中,从多个(多于两个)连续视图中提取连续视图之间的基本矩阵,并且从多个(多于两个)连续视图中,估计相对初始相机位姿的当前相机位姿,所述初始相机位姿在初始参考图像中获得。可以认为从具有多个视图的运动获取结构是从一组二维视图估计三维结构的过程。在所公开的实施例中,可以认为从一组二维视图估计所述三维结构的处理是当所述无人机飞行时从一系列视图估计已校准相机位姿的过程,并同时重建所述场景达到未知的比例因子的三维结构。
图5为本发明具体实施方式的相比于多个连续视图的初始相机位姿估计现在相机位姿的流程图。如图5所示,从多个(多于两个)连续视图中提取连续视图之间的基本矩阵,并且从多个(多于两个)连续视图估计相对于所述初始相机位姿的当前相机位姿可以包括以下步骤:
步骤S502:对于每对连续的图像,相对点跟踪器找到一组点;
步骤S504:估计当前视图的相对相机位姿,其中当前视图的相对相机位姿包括相对于之前视图的当前视图的相机取向和位置;
步骤S506:将所述当前视图的所述相对相机位姿变换为序列的第一视图I_ref(即,初始参考图像)的坐标系统;
步骤S508:存储包括所述相机位姿和所述图像点的当前视图属性;
步骤S510:存储先前视图和当前视图之间的所述初始匹配;
步骤S512:给定I_ref,通过目前为止接收到的所有视图找到点轨迹;
步骤S514:应用具有多个视图的三角互证来计算对应于点轨迹的初始三维位置;
步骤S516:应用光束平差法同时改进相机位姿和三维点;和
步骤S518:给出目前为止的所有视图,通过矩阵乘法求出相对于所述第一视图I_ref的最终旋转R和平移T.特别地,每个时间戳t的矩阵中的所述旋转R和所述平移T可以存储在如下的等式(7)中的Ht:
回到图4,在相对于从所述初始参考图像(即I_ref)获得的相对初始相机位姿的所述当前相机位姿之后,基于深度门控循环Q网络(DGRQN)来预测用于抵消UAV的横向干扰的理想动作(S408)。
在游戏上,深度Q网络(DQN)已经显示出它们学习人类水平控制策略的能力。然而,仅使用最后几个系统状态训练所述经典DQN作为输入,这限制了任务中需要长期存储器模型的性能。在所公开的实施例中,为了防止所述无人机漂移,该序列的信息对于防止无人机漂移是非常重要的。另一方面,循环神经网络(RNN)在序列处理任务中学习能力很强。所述DGRQN可以用于将所述门控RNN和简化的深度Q网络结合。
图6为本发明具体实施方式的深度门控循环Q网络(DGRQN)。如图6所示,所述DGRQN可以包括特征编码602,深度神经网络(DNN)604,深度门控递归神经网络(DGRN)606和Q学习608。图7为本发明具体实施方式的用于预测基于深度门控循环Q网络DGRQN的无人机抵消横向干扰的理想动作的方法流程图。
如图7所示,首先,将所述所述已估计的相机位姿编码为用作DGRQN输入的特征向量(S702)。特别地,如图6所示,所述DGRQN的原始输入可以是每个时间戳t的4×4矩阵Ht。然后,可以根据以下等式8将Ht编码为6个特征向量v(θroll,θpitch,θyaw,Tx,Ty,Tz)的长度,等式(8)如下所示:
其中θroll表示方向的滚动角,且θroll=atan2(h32,h33);θpitch表示方向的俯仰角,θywa表示方向的偏航角,且θyaw=atan2(H21h11);Tx表示x轴上的平移,且Tx=h14;Ty表示y轴上的平移,Ty=h24;Tz表示z轴上的平移,Tz=h34。所述已编码的特征向量v(θroll,θpitch,θyaw,Tx,Ty,Tz)会由于所述已估计的无人机当前位姿与所述无人机的初始位姿之间的变化而呈现无人机的当前状态。
返回到图7,在将已估计的相机位姿编码为特征向量后,所述特征向量由深度神经网络(DNN)处理(S704)。特别地,如图6所示,将所述特征向量传递到三个隐层的DNN604,并且相应数量的隐藏单元可以是150,200和100。所有单元之后可以是带漏洞的线性修正单元(LReLU)。可以将所述DNN 604的输出馈送到DGRN 606。
返回如图7,在由DNN处理所述特征向量之后,由深度门控的神经网络(DGRN)处理所述特征向量(S706)。可以认为无人机的运动是随时间变化的位姿序列,因此,基于无人机之前的状态执行动作是非常期望的。在所公开的实施例中,可以采用作为长短期记忆递归神经网络(LSTM RNN)变量的双层DGRN。所述双层DGRN可以将经典的长短期记忆(LSTM)单元的忘记门和输入门组合成一个“更新门”。
图8为本发明具体实施方式的单个门控循环单元(GRU)800。如图8所示,所述信号GRU800将xt和最后一步单位的输出ht-1作为输入。同时,ht表示GRU800的输出,并且可以将ht馈送到下一个RNN层和下一步的GRU。所公开的DGRQN可以具有两层门控神经网络(GRN),所述GRN可以采用先前的DNN输出作为输入。可以将GRN的输出形成为每个候选动作的Q值的向量。
由每个GRU 800执行的计算由以下等式表示:
zt=σ(Wz·[ht-1,xt]) (9)
rt=σ(Wr·[ht-1,xt]) (10)
返回图7,在通过所述DGRN处理所述特征向量之后,通过Q学习处理所述特征向量以获得所述已估计的当前相机位姿与所述初始相机位姿之间的差异(S708)。特别地,所述增强学习可以允许机器通过交互和接收来自随机环境的反馈来学习作为代理的最佳行为。所述强化学习的经典模型具有作为马尔可夫决策过程(MDP)的形式化环境,并且可以由四元组(S,A,P,R)表示来描述。在每个时间戳t,系统观察状态st∈S,,并执行导致奖励rt~R(st,at)和下一状态st+1~P(st,at).的动作at∈A。
Q学习是一种用于估计在给定状态下执行操作的最大最终奖励值的策略。Q学习将Q函数Q(st,at)定义为系统在状态st执行at的最佳最终奖励。然后根据下一个状态的Q值,可以通过以下等式(13)获得当前状态Q值,等式(13)如下所述:
其中r表示当前状态下的实例报酬。在所公开的实施例中,奖励可以通过等式(14)计算,等式(14如下),
其中I表示4×4的恒等矩阵。r的值显示所述已估计的当前相机位姿与所述初始相机位姿之间的差异。
使用优化的Q函数,所述代理只需要在每个状态下执行最高Q值的动作。所述深度Q网络框架可以克服传统Q学习中的挑战,例如,在真正任务中的大量独特状态可以使学习不可训练。所公开的方法可以通过查询来自网络的输出来在线估计Q值。所述最终网络的所述最终输出层可以具有8的长度以呈现8种不同动作的Q值(所有加法,滚动,俯仰和偏航上的正和负运动)。所述激活函数可以是线性回归,因为Q值可以是任何实数。在所公开的实施例中,所述已编码特征向量vt呈现所述状态st。
在某些实施例中,用于无人机的深度门控循环Q网络的视觉的自稳定的方法还包括训练Q网络以获得最终网络。在训练中采用所述平方误差损失函数等式(15),等式(15)如下所示:
图9所示为本发明具体实施方式的训练Q网络的方法。如图9所示,训练Q网络包括以下所述步骤:
步骤S902:基于所述当前状态st,通过整个所述RDQN进行正向传播,获得每个动作的Q值预测的向量,并执行动作at;
步骤S904:基于下一个状态st+1,执行正向传播并选择最大输出的Q值作为所述
步骤S906:设定动作的目标值at作为并计算损失;和
步骤S908:执行反向传播来更新权重。
如图4所示,在根据深度门控循环Q网络(DGRQN)预测到抵消无人机横向打扰的理想动作之后,所述UAV被驱动回到其初始位置,从而实现自稳定(S410)。
所公开的飞行自稳定系统和方法可以仅需要视觉信息,即由车载单目相机拍摄的多个相机视图来抵消横向干扰。也就是说,所公开的飞行自稳定系统和方法可以仅对图像或视觉传感器进行回应。给定初始参考图像,基于与所述相机位姿估计结合的状态评估机制,所公开的飞行自稳定系统和方法能够逐渐地了解在开放环境中实现自稳定的最佳控制行为。所述深度Q框架可以基于由循环神经网络(RNN)启用的长/短期状态存储器来学习这种最佳控制行为。
此外,所公开的修改的深度Q框架可以用从所述相机位姿估计模块提取的输入替代来自卷积神经网络(CNN)的输入,从而提高计算效率。DGRQN控制引擎目标的设计可以实现无人机在无需手动拼接条件下仍智能地停留在初始位姿。与传统的深Q网络相比,所公开的系统可以采用所述相机位姿估计模块来提取无人机的位姿信息,通过该位姿信息可以允许网络获得基于视觉的特征,而不是通过常规处理。
所公开的框架可以简化整个系统并降低计算成本,这可以满足安装在低端无人机中的车载处理器的系统要求以实现实时处理。此外,已修改的DGRQN可以允许系统具有比传统深度Q网络更多帧的存储空间,这可以会提高最终动作决策的最优性,因为结果不仅与当前状态相关,而且与先前帧相关。
这些技术将进一步转化,本发明具体实施例提供将各种显示模块和方法步骤用做电子硬件,计算机软件,或者软硬件结合。为了清楚说明软硬件的互换性,各种显示,单元和步骤已在上文就其功能进行描述。在软硬件上是否能够实施此功能取决于具体应用和对全系统的限制。本领域技术人员可以对于每个具体申请采用各种方法实施上述描述的功能,但是不应该将这些实施决定解释为不在本发明保护范围内。
本发明提供实例用于向本领域普通技术人员描述本发明。对所述实例的各种修改对本领域普通技术人员是显而易见的,并且在本发明实施例中给出的一般性原则在不脱离本发明的精神或者保护范围的情况下,也可以应用于其他实施例中。因此,本发明不限于本文所述实例中,而应给予本发明实例所述原则和新特征的更广范的领域。
- 还没有人留言评论。精彩留言会获得点赞!