一种基于视觉的机器人避障方法与流程
本发明涉及机器人避障技术领域,具体而言涉及一种基于视觉的机器人避障方法。
背景技术:
自主导航与定位的技术是智能机器人的关键技术之一,定位技术可以使机器人知道“我在哪”;建图技术可以对机器人周围环境进行建图,它服务于定位,也能使机器人知道“我要去哪”;导航技术可以让机器人知道“怎么去”。在未知环境即没有地图的情况下,需要机器人具备同时定位和建图的能力(slam,simultaneouslocalizationandmapping)。在已知环境(有地图)的情况,需要机器人在已有地图上进行定位,并保持全局一致。用于定位与建图的传感器主要是相机和激光雷达。现有机器人中激光定位与建图技术成熟、精度高、计算量小,但无法处理无结构区域或无法区分结构相似的区域,在一些人群密集等复杂场景也会出现丢失情况。基于视觉传感器的定位与建图技术可以充分利用丰富视觉信息进而对基于激光的slam技术做辅助定位。在导航方面,机器人最重要的特性是能够进行实施避障。机器人常用的单线雷达是二维传感器,扫描的是固定高度的障碍物,低于或者高于雷达面的障碍物都不会被标记,机器人很容易于其他层面障碍物发生碰撞。深度视觉传感器可以捕捉三维世界中的障碍,然后标记到slam算法构建好的地图中,协助单线雷达实现三维避障。例如,专利号为cn110285813a的发明中提出一种室内移动机器人人机共融导航装置及方法,在每个规划周期基于动态代价地图构建搜索图计算当前规划周期最佳的规划结果。
然而,目前与视觉相关机器人边缘设备通常存在如下问题:1.以视觉为核心传感器的设备,由于必须基于视觉本身的视觉方法对采集数据进行处理,计算量大;并且其在弱纹理、光照变化剧烈等情况无法正常工作。2.通常该类设备都是单独负责机器人定位功能和避障功能中的一种,在安装面积有限的小型机器人身上同时安装会浪费大量空间,同样也存在功耗高的问题。3.当前视觉相关边缘设备使用的计算模块通常存在低性能高功耗等缺点,同时只能搭载较为笨重的linux主流发行版本。
技术实现要素:
本发明针对现有技术中的不足,提供一种基于视觉的机器人避障方法,能够同时实现全局定位和三维避障的功能,具有占用面积小、运算轻量化、高性能低功耗等优点,为以单线激光雷达为主的定位和导航算法提供有力支撑。
为实现上述目的,本发明采用以下技术方案:
一种基于视觉的机器人避障方法,所述避障方法包括以下步骤:
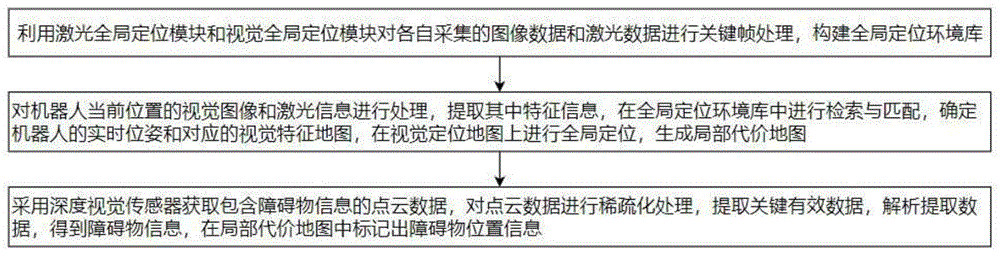
s1,利用激光全局定位模块和视觉全局定位模块对各自采集的图像数据和激光数据进行关键帧处理,构建全局定位环境库,所述全局定位环境库包括视觉全局定位库和激光全局定位库;其中,视觉全局定位模块同时接收激光定位模块发送的所有视觉帧的位姿和激光全局定位模块发送的关键帧信息,基于激光建图结果,构建激光地图坐标系下的视觉定位地图;
s2,对机器人当前位置的视觉图像和激光信息进行处理,提取其中特征信息,在全局定位环境库中进行检索与匹配,确定机器人的实时位姿和对应的视觉特征地图,在视觉定位地图上进行全局定位,生成局部代价地图;
s3,采用深度视觉传感器获取包含障碍物信息的点云数据,对点云数据进行稀疏化处理,提取关键有效数据,解析提取数据,结合激光数据得到三维方向上的障碍物信息,在局部代价地图中标记出障碍物位置信息。
为优化上述技术方案,采取的具体措施还包括:
进一步地,所述激光全局定位模块采用激光雷达。
进一步地,所述视觉全局定位模块采用单目视觉传感器。
进一步地,所述激光雷达位于机器人侧面临近底面处,沿机器人环向采集机器人所处区域的激光数据;所述单目视觉传感器安装在机器人侧面临近顶面处,采用广角镜头,根据外部控制指令以动态调节其视场角,单目视觉传感器用于采集机器人所处区域的视觉图像;所述深度视觉传感器安装在激光雷达和单目视觉传感器之间,用于采集机器人前进方向上的障碍物点云信息。
进一步地,所述关键帧至少满足以下条件中的任意一个:
(1)机器人转动角度大于预设角度阈值,(2)机器人移动距离大于预设距离阈值,(3)采用当前帧图像与前一个关键帧图像的特征点的匹配信息评估两者之间的内容重叠度时,当前帧图像与前一个关键帧图像的内容重叠度小于第一预设重叠度阈值,(4)采用icp算法计算当前帧激光与前一个关键帧激光两者之间激光数据配准程度,评估得到的当前帧激光与前一个关键帧激光的内容重叠度小于第二预设重叠度阈值。
进一步地,步骤s1中,所述构建全局定位环境库的过程包括以下步骤:
s11,对激光定位模块、视觉全局定位模块和激光全局定位模块进行系统时钟对准;
s12,接收用户界面模块发送的开始建图命令,依次进行以下操作:
s121,利用视觉全局定位模块采集当前场景的视觉图像,对采集的视觉图像进行在线预处理,从视觉图像中提取并保存图像特征信息;
s122,驱使激光定位模块构建当前场景下的激光地图;
s123,利用激光全局定位模块采集当前场景下的激光数据,对采集的激光数据进行在线预处理,从激光数据中检测得到关键帧,提取并保存关键帧中的激光特征信息;
s13,接收用户界面模块发送的结束建图命令;
s14,视觉全局定位模块调用激光定位模块的接口获取所有图像帧的位姿,同时接收激光全局定位模块发送的关键帧信息,对保存的图像特征进行特征点帧间匹配与跟踪,提取额外的关键帧,对特征点3d坐标优化,建立关键帧的视觉词袋库,保存得到视觉全局定位库;
s15,激光全局定位模块调用激光定位模块的接口获取所有关键帧的位姿和子地图信息,建立关键帧和子地图间的关系,构建关键帧的激光词袋库,保存得到激光全局定位库。
进一步地,步骤s2中,所述对机器人当前位置的视觉图像和激光信息进行处理,提取其中特征信息,在全局定位环境库中进行检索与匹配,确定机器人的实时位姿和对应的视觉特征地图的过程包括以下步骤:
s21,对激光定位模块、视觉全局定位模块和激光全局定位模块进行系统时钟对准;
s22,视觉全局定位模块加载视觉全局定位库,激光全局定位模块加载激光全局定位库,订阅odomtf;
s23,视觉全局定位模块对当前帧图像提取图像特征,计算词袋向量,在视觉全局定位库中检索关键帧;
s24,激光全局定位模块对当前帧对应的激光数据提取激光特征,计算词袋向量,在激光全局定位库中检索关键帧;
s25,综合视觉全局定位模块和激光全局定位模块的关键帧检索结果,构建候选关键帧集合;
s26,对候选关键帧集合中的每个关键帧,与当前帧进行图像特征匹配以及激光特征匹配,剔除无效关键帧,构建优选关键帧集合;
s27,对优选关键帧集合中的每个关键帧,得到其与当前帧图像特征匹配结果,基于匹配结果估计得到视觉位姿,评估视觉位姿的估计质量;
s28,将优选关键帧集合对应的激光子地图集合中的每个子地图,与当前帧的激光数据依次进行匹配,估计得到激光位姿,评估激光位姿的估计质量;
s29,综合视觉全局定位模块和激光全局定位模块的位姿估计和质量评估结果,确定并发布最终的全局定位结果
进一步地,步骤s29中,所述综合视觉全局定位模块和激光全局定位模块的位姿估计和质量评估结果,确定并发布最终的全局定位结果包括以下步骤:
s291,将重投影误差作为视觉位姿估计的质量评估指标;
s292,将当前帧激光与关键帧激光间的配准程度和子地图匹配程度作为激光位姿估计的质量评估指标;
s293,通过综合的质量评估加权下的位姿图优化,自动剔除不可靠的位姿估计结果,并融合多种视觉位姿估计与激光位姿估计结果,输出最终的全局定位结果。
本发明的有益效果是:
(1)能够同时实现全局定位和三维避障的功能,分布式架构设计实现运算轻量化,使得各模块易于垂直安装在水平面积有限的机器人上,视觉定位或建图、激光定位或建图和导航分别在三块低功耗arm开发板进行计算,单块处理器横截面积小,可以在水平面积有限的机器人上垂直安装。具有占用面积小、运算轻量化、高性能低功耗等优点,为以单线激光雷达为主的定位和导航算法提供有力支撑。
(2)边缘计算设备实现了各模块之间的解耦,有利于各模块独立的生产和开发。
(3)全局定位摄像头采用广角镜头,摄像头外包固件的视场角可动态调节,使用上述硬件选型与设计使得视觉模块最大化利用动态场景中的稳定视觉特征,进而提高视觉特征地图的质量,输出高精度的定位结果。
(4)视觉避障模块配合单线雷达传感器,有效扫描雷达的地面盲区和部分悬空盲区,进而实现三维避障,节省了存储空间,提高了处理速度。
(5)核心计算开发板支持国产openeuler系统,有着轻量简洁运算速度快等优点,同时有利于我国突破国外技术封锁。
附图说明
图1是本发明的基于视觉的机器人避障方法流程图。
图2是本发明的各模块安装位置示意图。
图3是激光与视觉融合的一体化室内机器人全局定位方法流程图。
具体实施方式
现在结合附图对本发明作进一步详细的说明。
需要注意的是,发明中所引用的如“上”、“下”、“左”、“右”、“前”、“后”等的用语,亦仅为便于叙述的明了,而非用以限定本发明可实施的范围,其相对关系的改变或调整,在无实质变更技术内容下,当亦视为本发明可实施的范畴。
结合图1,本发明提及一种基于视觉的机器人避障方法,所述避障方法包括以下步骤:
s1,利用激光全局定位模块和视觉全局定位模块对各自采集的图像数据和激光数据进行关键帧处理,构建全局定位环境库,所述全局定位环境库包括视觉全局定位库和激光全局定位库;其中,视觉全局定位模块同时接收激光定位模块发送的所有视觉帧的位姿和激光全局定位模块发送的关键帧信息,基于激光建图结果,构建激光地图坐标系下的视觉定位地图。
s2,对机器人当前位置的视觉图像和激光信息进行处理,提取其中特征信息,在全局定位环境库中进行检索与匹配,确定机器人的实时位姿和对应的视觉特征地图,在视觉定位地图上进行全局定位,生成局部代价地图。
s3,采用深度视觉传感器获取包含障碍物信息的点云数据,对点云数据进行稀疏化处理,提取关键有效数据,解析提取数据,结合激光数据得到三维方向上的障碍物信息,在局部代价地图中标记出障碍物位置信息。
本发明包含激光定位模块、激光全局定位模块、视觉全局定位模块和深度视觉传感器四个模块,结合这四个模块同步实现室内机器人的全局定位功能和视觉避障功能,可用于解决现有技术中存在的数据源单一、复杂场景定位成功率低、功耗高、实时性差等问题。
具体的,所述激光全局定位模块采用激光雷达。所述视觉全局定位模块采用单目视觉传感器,所述单目视觉传感器通过全局快门摄像头在设定频率下获取外界环境信息并转换成灰度图,用于视觉模块算法进行生成视觉特征地图以及实时全局定位。所述激光雷达位于机器人侧面临近底面处,沿机器人环向采集机器人所处区域的激光数据;所述单目视觉传感器安装在机器人侧面临近顶面处,采用广角镜头,根据外部控制指令以动态调节其视场角,单目视觉传感器用于采集机器人所处区域的视觉图像;所述深度视觉传感器安装在激光雷达和单目视觉传感器之间,用于采集机器人前进方向上的障碍物点云信息。分布式架构设计实现运算轻量化,使得各模块易于垂直安装在水平面积有限的机器人上。视觉定位或建图、激光定位或建图和导航分别在三块低功耗arm开发板进行计算,单块处理器横截面积小,可以在水平面积有限的机器人上垂直安装。整个设备具有占用面积小、运算轻量化、高性能低功耗等优点,为以单线激光雷达为主的定位和导航算法提供有力支撑。图2是本发明的各模块安装位置示意图。
全局定位功能是在机器人全局定位失效情况下提供快速精确有效的全局定位结果,具体功能包括:
(1)将图像数据保存为只包含特征点及其描述子的帧。
(2)基于激光雷达建图模块回传的优化后的轨迹,在已知机体位姿时建立视觉特征地图。
(3)在已知全局视觉地图上进行全局定位,并将定位结果回传给制图模块。
具体的,激光定位模块整体负责机器人的环境定位,从视觉全局定位模块和激光全局定位模块接收机器人全局定位信息,对全局定位信息进行整体评估,在机器人随时随地开机时利用全局定位信息进行定位系统的初始化,以及在机器人定位丢失时利用全局定位信息进行重定位等,保证机器人环境定位的实用性、长期稳定性和可靠性。在建库时,视觉全局定位模块和激光全局定位模块将接收激光定位模块提供的机器人位姿信息,并同时采集视觉图像和激光数据,建立全局定位库。在全局定位运行时,视觉全局定位模块利用视觉图像信息,激光全局定位模块利用激光信息,在全局定位库中进行检索与匹配,计算和输出机器人的位姿,为激光定位模块提供初始化位姿、闭环检测和重定位等信息。
在本发明中,为了实现高效的全局定位过程,采用基于关键帧的地图内容组织形式。关键帧可以看成为整个地图的一块局部子地图。通过建立关键帧检索库,可以用给定帧的图像与激光数据快速检索出相似的关键帧候选集,然后再进行速度相对较慢的精细内容匹配与结构验证,并确定最终全局定位结果。通过快速检索出关键帧候选集缩小搜索范围,可以有效减少速度相对较慢的精细匹配与验证的执行次数,从而实现高效的全局定位过程。
全局定位方法分为两个阶段:建库阶段和定位阶段。如图3所示,建库阶段的目标是在机器人到达新的环境时或环境发生改变时,建立用于全局定位所需要的图像和激光的特征点、关键帧等地图信息库和快速检索库。定位阶段的目标是利用机器人当前位置的图像和激光信息,在全局定位环境库中进行检索与匹配,确定机器人的位姿,用于机器人在随时随地开机后激光定位模块的初始化、在定位丢失时为激光定位模块提供重定位信息、以及为激光定位模块提供闭环检测信息等。
如图3所示,在全局定位模块的定位阶段,对给定帧的图像和激光数据,在提取特征点后,计算当前帧的词袋描述向量,从关键帧库中检索出相似关键帧的候选集合,然后与每个候选关键帧进行图像和激光的特征匹配和结构验证,选择最可靠的关键帧输出给定帧与定位地图间的关联信息,以及估计给定帧在定位地图中的位姿。
在进行当前帧与候选关键帧间的特征匹配时,对当前帧的每个特征,利用特征词袋描述获得其在关键帧中的待匹配的特征集合,然后与待匹配特征逐个比较,获得最佳匹配特征。基于当前帧与候选关键帧间的特征匹配结果,利用关键帧中特征点在全局坐标系下的坐标,估计当前帧的位姿并进行结构验证,保证当前帧与候选关键帧间有足够匹配的特征满足刚体约束。最后在关键帧的候选集合中,选择在满足刚体约束条件下的匹配程度最高的关键帧,输出给定帧在定位地图中的位姿。
一、下面对全局环境定位方法的工作流程做具体阐述。
1、建库阶段的工作流程如下:
(1.1)多模块间系统时钟对准。
(1.2)用户界面模块发送开始建图命令。
(1.3)视觉全局定位模块收到命令后开始在线预处理:接收图像,提取特征,保存图像特征。
(1.4)激光定位模块开始建图。
(1.5)激光全局定位模块收到命令后开始在线处理:接收激光数据,检测关键帧,提取特征,保存激光特征。
(1.6)用户界面模块发送结束建图命令。
(1.7)视觉全局定位模块调用激光定位模块的接口获取所有帧的位姿,并同时接收激光全局定位模块的关键帧信息,对保存的图像特征进行特征点帧间匹配与跟踪,提取额外的关键帧,对特征点3d坐标优化,建立关键帧的视觉词袋库,最后保存视觉全局定位库。
(1.8)激光全局定位模块调用激光定位模块的接口获取所有关键帧的位姿和子地图信息,建立关键帧和子地图间的关系,并建立关键帧词袋库,保存激光全局定位库。
2、定位阶段的工作流程如下:
(2.1)多模块间系统时钟对准。
(2.2)视觉和激光全局定位模块加载全局定位库,同时订阅odomtf。
(2.3)视觉全局定位模块对当前帧图像提取特征,计算词袋向量,在视觉定位库中检索关键帧。
(2.4)激光全局定位模块对当前帧激光数据提取特征,计算词袋向量,在激光定位库中检索关键帧。
(2.5)综合两个模块的关键帧检索结果,构建候选关键帧集合。
(2.6)对候选关键帧集合中的每个关键帧,与当前帧进行图像特征匹配以及激光特征匹配,剔除无效关键帧,构建优选后的关键帧集合。
(2.7)对优选关键帧集合中的每个关键帧,基于与当前帧图像特征匹配结果估计位姿,并且评估视觉位姿估计质量。
(2.8)对优选关键帧集合对应的激光子地图集合中的每个子地图,与当前帧的激光数据进行匹配,估计位姿,并且评估激光位姿估计质量。
(2.9)综合两个模块的位姿估计和质量评估结果,确定最终的全局定位结果,并且发布全局定位结果(为map2odom的变换)。
三、关于全局环境定位方法中的诸多细节技术
1、图像特征点检测与匹配
检测图像中的角点特征,利用图像特征点处灰度变化规律,建立角点特征的快速检测算法。先利用特征点周围少数像素信息,快速过滤非特征点区域。然后对剩下的区域,利用周围完整像素信息,进行特征检测,并通过非极大抑制,保留局部稳定和稀疏的特征点。计算图像灰度梯度,统计特征点周围像素的梯度方向和强度信息,构建特征点描述向量。利用特征点描述向量进行特征点匹配。考虑两种情况的特征点匹配问题,分别为建库阶段的帧间匹配和全局定位阶段的帧与关键帧间的匹配。在帧间匹配时,利用帧间运动预测,对前一帧的每个特征点,获得当前帧的特征点预测位置,然后与预测位置周围的特征点进行匹配,选取特征向量最相近的作为匹配结果。在帧与关键帧间的匹配时,利用特征点向量聚类结果,对当前帧的每一个特征点,与关键帧中选取属于同一个聚类类别的特征点进行匹配,选取特征向量最相近的作为匹配结果。
2、激光特征点检测与匹配
通过评估每个激光数据点处的曲率大小(通过原始激光数据与平滑后的数据间的差异来评估),检测激光数据中的曲率点特征。并通过非极大抑制,保留局部稳定和稀疏的特征点。利用每个特征点周围的激光数据点的分块分布信息作为特征点描述向量。利用特征点描述向量进行特征点匹配,并利用ransac算法从特征点匹配结果中计算两帧激光数据间的位姿关系。
3、关键帧检测
关键帧检测采用多个准则,只要满足任意一个,则把当前帧作为关键帧。具体的准则包括如下几个:1)机器人转动角度足够大,2)机器人移动距离足够大,3)当前帧图像与前一个关键帧图像的内容重叠度小于一定值,通过它们特征点的匹配信息评估内容重叠度,4)当前帧激光与前一个关键帧激光的内容重叠度小于一定值,通过它们激光数据配准程度(利用icp算法)评估内容重叠度。
4、图像特征点的3d坐标优化
利用激光定位模块提供的位姿信息,对每个特征点,首先通过两个位姿差异比较大的关键帧直接计算特征点的3d坐标。然后利用特征点在多个关键帧中的像素坐标,优化特征点在全局地图坐标系下的3d坐标。优化的目标是求解最优的特征点3d坐标,使得特征点按照每个关键帧位姿投影到关键帧图像上的投影坐标与特征点的像素坐标间的误差(即重投影误差)尽量小。利用lm算法实现特征点3d坐标的优化。
5、词袋向量计算
为了计算某一帧图像或激光数据的词袋向量,首先对多帧图像或激光数据的特征点描述向量进行聚类,获得特征点描述词典。然后对于某一帧图像或激光数据,计算其中所有特征点描述向量在词典下的类型编号,进而计算图像或激光数据中所有词出现的频率,用词频作为图像或激光数据的词袋向量,用于关键帧建库和检索。
6、关键帧建库与检索
将分别建立图像关键帧和激光关键帧的高效检索库。把关键帧比作文件,关键帧的词袋向量比作文件中不同词出现的频率,利用信息检索的相关算法和技术进行关键帧建库与检索。利用信息检索中的tf-idf算法对所有关键帧的词袋向量进行分析,计算不同词的逆向文件频率,建立关键帧的tf-idf检索库。然后利用tf-idf模型对应的检索算法进行关键帧检索。
7、视觉位姿估计与质量评估
在获得当前帧图像与关键帧图像间的特征匹配结果后,利用建库阶段优化得到的关键帧中特征点的3d坐标,估计当前帧的位姿。姿态估计的目标是求解最优的当前帧位姿,使得利用当前帧位姿把特征点3d坐标投影到当前帧图像中的坐标与特征点在当前帧图像中的像素坐标间的误差(即重投影误差)尽量小。利用lm算法完成视觉位姿估计。可以将重投影误差作为视觉位姿估计的质量评估指标。
8、激光位姿估计与质量评估
在获得当前帧激光与关键帧激光间的特征匹配结果后,利用ransac算法从特征点匹配结果中计算两帧激光数据间的初步位姿关系。以初步位姿关系作为初值,利用icp算法进行当前帧激光与关键帧激光间的精细配准,获得当前帧激光的配准位姿。然后进一步将当前帧激光与子地图进行匹配,获得当前帧的激光位姿估计结果。可以将当前帧激光与关键帧激光间的配准程度和子地图匹配程度作为激光位姿估计的质量评估指标。
9、全局定位结果综合评估
综合考虑视觉位姿估计与激光位姿估计的不同定位结果,通过综合的质量评估加权下的位姿图优化,自动剔除不可靠的位姿估计结果,并融合多种视觉位姿估计与激光位姿估计结果,输出最终的全局定位结果。通过位姿图优化,利用多种视觉位姿估计与激光位姿估计结果间的互相印证,自动识别不可靠的位姿估计结果,提升全局定位的鲁棒性和可靠性。通过位姿图优化,通过融合多种视觉位姿估计与激光位姿估计结果,提升全局定位的稳定性和精度。
在此基础上,视觉避障软件部分包含点云切片和相机障碍物层的障碍物标记两个子模块。点云切片子模块用于稀疏化相机的原始数据,提取关键有效数据,减少计算资源的使用,其中,点云切片的点云数据来源于深度相机传感器,用于获取相机的深度信息数据,再将处理过的点云数据传给相机障碍物层的障碍物标记子模块。障碍物标记模子模块用于将障碍物信息与代价地图(costmap)相结合,在局部代价地图中标记障碍物,使机器人在导航中避开相机观察到的障碍。
在本发明中,采用激光和视觉融合的全局定位方法可以保证快速进行全局定位(例如重定位时间只需要1秒以内,比以有算法快2-10倍),在获取局部代价地图的基础上,融入视觉避障模块计算得到的障碍物信息,深度视觉传感器又能够配合激光雷达,有效扫描雷达的地面盲区和部分悬空盲区,实现三维避障,节省了存储空间,提高了处理速度。在本发明中,无论是定位还是避障,都只是辅助雷达进行工作,从而降低了对硬件传感器的性能要求和对处理器的运算要求,有效实现了高性能低功耗的嵌入式硬件结构。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!