一种基于强化学习的无人机自主着陆方法
1.本发明涉及无人机自主着陆的技术领域,尤其涉及一种基于强化学习的无人机自主着陆方法。
背景技术:
2.近年来无人机在越来越多的领域得到应用,特别是用于执行那些枯燥、肮脏或危险的任务,如搜索救援、遥感、精准农业、监视、货物运送。在这些应用中,无人机着陆是至关重要的一个环节。
3.了解决无人机着陆问题,以前的方法使用多种机载传感器或地面辅助设备来估计无人机的姿态,然后对无人机进行控制。但机载传感器通常昂贵且耗电,而地面辅助设备并不总是存在。由于无人机通常配备一个单目摄像头,研究人员提出了各种基于视觉的无人机着陆方法,但这些方法容易受到光照和无人机姿态变化的影响,或者只适用于专门设计的地面着陆标志。受深度强化学习在游戏和机器人控制领域取得显著突破的启发,研究人员开始采用深度强化学习来解决无人机自主着陆的问题,但学到的着陆策略仅在已知环境中表现良好,不能很好地泛化到新的未知环境中。
4.为了实现着陆策略更好的泛化,本发明首先将无人机自主着陆任务分解为在水平方向与地面标志对齐和在垂直方向下降两个子任务,然后分别使用带有地面标志辅助定位任务的深度强化学习模型去完成每个子任务。模型将基于深度强化学习的着陆任务与基于监督学习的辅助定位任务联合起来进行学习,以提高学习到的着陆策略的泛化能力。地面标志定位与着陆策略共享了图像特征表示,因此辅助定位任务可以帮助强化学习智能体学习到有用的图像特征,从而高精度定位地面标志,提升着陆策略在新的未知环境中的泛化能力。本发明分别设计了分类辅助定位任务和归回辅助定位任务来提升图像特征学习。为了解决深度强化学习中奖励的稀疏和延迟问题,本发明提出了一种新颖的动态采样方法,称为动态分区经验回放采样,使用不同的采样比例从不同的经验分区中采样。这种采样方法可以提高学习效率,同时保持较低的计算复杂度。
技术实现要素:
5.本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
6.鉴于上述现有基于强化学习的无人机自主着陆方法存在的问题,提出了本发明。
7.因此,本发明目的是提供一种基于强化学习的无人机自主着陆方法,在深度q网络训练中采用动态分区经验回放方式以稳定和加快训练过程,结合辅助定位任务与改进的采样策略,使训练的模型更好地泛化到未知环境中,最终显著提升了无人机的着陆性能。
8.为解决上述技术问题,本发明提供如下技术方案:一种基于强化学习的无人机自主着陆方法,包括以下步骤:s1:采集无人机摄像头的图像信息,形成原始数据,将采集的原
始数据和位置信息存入样本合集;s2:对样本合集进行采样,对采样数据进行带有辅助定位任务的深度q网络训练,进行无人机动作q1值的预测;根据q1值,采用贪婪策略选择无人机动作d1,使无人机自身与地面标志水平对齐;s3:对样本合集采用动态分区经验回放采样方法进行采样,对采样数据进行带有辅助定位任务的深度q网络训练,进行无人机动作q2值的预测;采用贪婪策略选择无人机动作d2,使得无人机自身在垂直方向下降,并在水平方向调整位置保持与地面标志对齐;s4:无人机着陆。
9.作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:在所述带有辅助定位任务的深度q网络训练中包括两种辅助定位任务:分类辅助定位任务或者回归辅助定位任务。
10.作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:所述分类辅助定位任务,在s2阶段采样数据通过卷积层处理输出为23
×
23维分类向量,在s3阶段采样数据通过卷积层处理输出为7维分类向量。
11.作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:在回归辅助定位任务中,采用神经网络来回归预测出无人机和标志的相对坐标(δx,δy,δz);其中,标志的空间坐标为(x
marker
,y
marker
,z
marker
),无人机的空间坐标为(x
uav
,y
uav
,z
uav
),则无人机与标志的3维相对坐标可以表示为:
12.(δx,δy,δz)=(x
uav-x
marker
,y
uav-y
marker
,z
uav-z
marker
)
13.作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:在s2阶段深度q网络训练的奖励函数为
[0014][0015]
其中s是无人机的状态,a是无人机执行的动作。
[0016]
作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:所述无人机周身存在五个方向,分别是周身的第一方向,第二方向,第三方向,第四方向,处在无人机机翼上空的第五方向,无人机动作包括往第一方向飞行的向前,第二方向飞行的向后,第三方向飞行的向左,第四方向飞行的向右,第五方向飞行的下降,当无人机电机停转时的着陆,动作d1值包括5个动作,分别是向前、向后、向左、向右和下降,当d1值为下降时,进入s3阶段。
[0017]
作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:所述s3的动态分区经验回放采样方法,将样本合集划分为中立、负和正分区,通过加权优先采样对每个分区进行采样;每个经验样本的优先级与其时间差分误差的绝对值成正比;将三个分区的平均绝对时间差分误差进行归一化,归一化结果分别作为每个采样批次中该分区样本的采样比例;每次采集一个批次的经验对网络参数进行更新,然后使用更新后的网络对该批次经验的时间差分误差进行重新计算,并更新该批次经验的优先级。
[0018]
作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:在s3阶段深度q网络训练的奖励函数为:
[0019][0020]
其中s是无人机的状态,a是无人机执行的动作。
[0021]
作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:所述无人机动作d2值包括向前,向后,向左,向右,下降,着陆6个动作,当d2为着陆时,无人机着陆。
[0022]
作为本发明所述基于强化学习的无人机自主着陆方法的一种优选方案,其中:所述分类辅助定位任务使用交叉熵损失函数处理数据,所述回归辅助定位任务使用均方差损失处理数据。
[0023]
本发明的有益效果:本发明仅通过一个单目摄像头进行采样,对采样结果进行深度q网络训练,在训练中采用动态分区经验回放方式以稳定和加快训练过程,结合辅助定位任务与改进的采样策略,使训练的模型更好地泛化到未知环境中,在训练中,可以在砖头,草地,沙地,土壤、沥青等样本中准确识别处着陆点,最终显著提升了无人机的着陆性能。
附图说明
[0024]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
[0025]
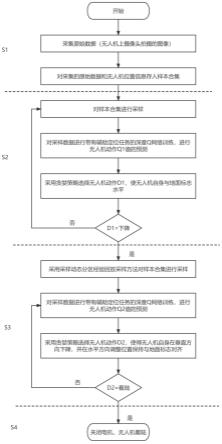
图1为本发明的整体流程图。
[0026]
图2为本发明地面标志分类辅助定位任务中,无人机与标志水平对齐阶段的分类方式(左)和无人机垂直下降阶段的分类方式(右)。
[0027]
图3为本发明为地面标志回归辅助定位任务中无人机和标志的相对位置表示。
具体实施方式
[0028]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明。
[0029]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0030]
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
[0031]
再其次,本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。
[0032]
实施例1
[0033]
参照图1,为本发明第一个实施例,提供了一种基于强化学习的无人机自主着陆方法,该方法步骤包括:
[0034]
s1(无人机飞行准备降落状态):此时无人机的偏航角是随机的,且在固定高度的水平坐标也是随机的,本发明采用摄像头是常见的单目摄像头,采集无人机摄像头的图像信息,形成原始数据,将采集的原始数据和无人机的位置信息存入样本合集;
[0035]
s2(无人机与地面标志水平对齐阶段):对样本合集进行采样,对采样数据进行带有辅助定位任务的深度q网络训练,进行无人机动作q1值的预测;根据q1值,采用贪婪策略选择无人机动作d1,使无人机自身与地面标志水平,无人机动作d1值包括向前、向后、向左、向右和下降5个动作;深度q网络中卷积神经网络提取的图像特征由辅助定位任务网络和策略网络共享。策略网络用于预测每个动作的q值。辅助定位网络位于最后一层卷积层之后,辅助卷积层学习特征提取;辅助定位任务共两种:分类辅助定位任务和回归辅助定位任务。分类辅助定位任务使用交叉熵损失,回归辅助定位任务使用均方差损失。该阶段模型训练时奖励函数为:
[0036][0037]
其中s是无人机的状态,a是无人机执行的动作。
[0038]
s3(无人机垂直下降阶段):当d1值为下降时,无人机进入s3阶段,对样本合集采用动态分区经验回放采样方法进行采样,对采样数据进行带有辅助定位任务的深度q网络训练,进行无人机动作q2值的预测;采用贪婪策略选择无人机动作d2,使得无人机自身在垂直方向下降,并在水平方向调整位置保持与地面标志对齐,无人机动作d2值包括向前,向后,向左,向右,下降,着陆6个动作;辅助定位网络位于最后一层卷积层之后,辅助卷积层学习特征提取;辅助定位任务共两种:分类辅助定位任务和回归辅助定位任务;分类辅助定位任务使用交叉熵损失,回归辅助定位任务使用均方差损失。该阶段模型训练时奖励函数为:
[0039][0040]
其中s是无人机的状态,a是无人机执行的动作。
[0041]
s4:当d2为着陆时,无人机关闭旋翼电机,在地面标志上着陆。
[0042]
实施例2
[0043]
参照图2为本发明无人机与标志水平对齐阶段和垂直下降阶段的分类辅助定位方式,参照图3位地面标志回归辅助定位任务中无人机和标志的相对位置表示,分类辅助定位任务使用交叉熵损失,回归辅助定位任务使用均方差损失,增加地面标志定位作为辅助任务可以提高收敛速度,有利于学习到更好的无人机着陆策略,学到的策略在已知和未知的环境中都表现得更好。
[0044]
无人机周身存在五个方向,分别是周身的第一方向,第二方向,第三方向,第四方
向,处在无人机机翼上空的第五方向,无人机动作包括往第一方向飞行的向前,第二方向飞行的向后,第三方向飞行的向左,第四方向飞行的向右,第五方向飞行的下降,当无人机电机停转时的着陆。
[0045]
分类辅助任务通过将无人机视野划分为多个区域,每个区域代表一个类别,根据地面标志中心所处的区域进行分类。在无人机与地面标志水平对齐阶段,由于无人机高度不变,其视野大小和视野内标志的大小都是固定,视野宽度为标志宽度的23倍,可以将摄像头拍摄到的图像划分为个区域。图像经过卷积层处理后输入到辅助定位网络,输出维分类向量。在垂直降落阶段,由于无人机的高度在不断变化,无人机视野内的标志大小也在不断变化,高度越低视野中的标志越大。根据视野内标志变化的特点并结合输出的控制指令,本发明将无人机视野划分为7个区域。根据标志中心所处的区域将图像分为7个类别。该分类辅助任务可以帮助卷积层学习到更准确的标志特征,同时不同分类类别也包含了地面标志相应的空间位置信息,使提取的特征更有利于着陆策略的学习。图像经过卷积层处理后输入到辅助定位网络,输出7维分类向量。
[0046]
回归辅助任务通过神经网络来回归预测出无人机和标志的相对坐标。假设标志的空间坐标为(x
marker
,y
marker
,z
marker
),无人机的空间坐标为(x
uav
,y
uav
,z
uav
),则无人机与标志的相对坐标可以表示为:
[0047]
(δx,δy,δz)=(x
uav-x
marker
,y
uav-y
marker
,z
uav-z
marker
);
[0048]
能够正确预测代表网络具有良好的特征提取能力,因此本发明设计回归辅助任务网络,输出为2维相对坐标。图像经过卷积层处理后输入到回归网络,首先经过空间softmax层处理。对卷积层提取的特征中k个通道的特征图分别用softmax函数处理,然后用处理后的特征图去预测2维相对坐标,输出共k组相对坐标,即一个2k维坐标向量;最后对所有坐标进行线性回归预测2维相对坐标(δx,δy)。
[0049]
实施例3
[0050]
参照图1,为本发明的第三个实施例,该实施例不同于第二个实施例的是:在训练深度q网络,控制无人机在垂直方向降落中,本发明使用了动态分区经验回放采样方法;将样本集合划分为中立、负和正分区,通过加权优先采样对每个分区进行采样;每个经验样本的优先级与其时间差分误差的绝对值成正比。将三个分区的平均绝对时间差分误差进行归一化,归一化结果分别作为每个采样批次中该分区样本的采样比例;每次采集一个批次的经验对网络参数进行更新,然后使用更新后的网络对该批次经验的时间差分误差进行重新计算,并更新该批次经验的优先级。
[0051]
进一步测试了这五个模型六种不同类型的背景纹理,包括砖,草,路面,沙子,雪和土壤。每种类型的纹理包含13个实例,我们在每个背景样本上测试每个代理100次,共有7800次测试。我们做以下两个观察,首先,添加标记定位作为辅助任务显著提高了普遍性学习策略的学习能力,第二,制定标记物的定位作为一个回归任务进一步提高了本发明泛化性,详细来说,平均成功回归代理对所有背景纹理的速率都在0.85以上,我们通过辅助定位任务对标记物的位置提供了更强的监督信号,从而更好地推断出地面标志和设置的背景纹理,这意味着该模型可以学习通过添加辅助任务更快速准确地标记特征。
[0052]
应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术
方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1