一种联邦迁移学习增强的多智能体车间动态调控方法
本发明属于智能工厂,特别是涉及一种联邦迁移学习增强的多智能体车间动态调控方法。
背景技术:
1、随着制造业的数字化进程加速,大量的生产数据被收集、分析并用于指导生产决策。从设备的运行状态到员工的操作习惯,从物料流动到产品的质量控制,每一个环节都产生了海量的数据。这为提高生产效率和质量提供了前所未有的机会,但同时也引发了对数据隐私的深切关注。
2、尤其在多智能体系统的应用中,多个智能体之间需要频繁地交换信息以完成协同任务。这些信息可能包括技术参数、生产计划、员工操作习惯等敏感数据。一旦这些数据被未经授权的第三方获取,不仅可能导致企业的核心竞争力受损,也可能危及到员工的个人隐私和企业的商业机密。
3、目前,随着工业物联网和边缘计算,数据的处理和决策日益从云端转向设备端,这为数据安全带来了新的机遇与挑战。综上所述,面对当前的挑战和机遇,迫切需要一种有效、可靠、具有强大泛化能力的车间动态调度策略。
技术实现思路
1、为了解决上述问题,本发明提出了一种联邦迁移学习增强的多智能体车间动态调控方法,这种技术结合了多智能体的自主决策与群体智能的优势,能够更灵活地分配生产任务,根据实时情境动态调整生产调控。
2、为达到上述目的,本发明采用的技术方案是:一种联邦迁移学习增强的多智能体车间动态调控方法,包括步骤:
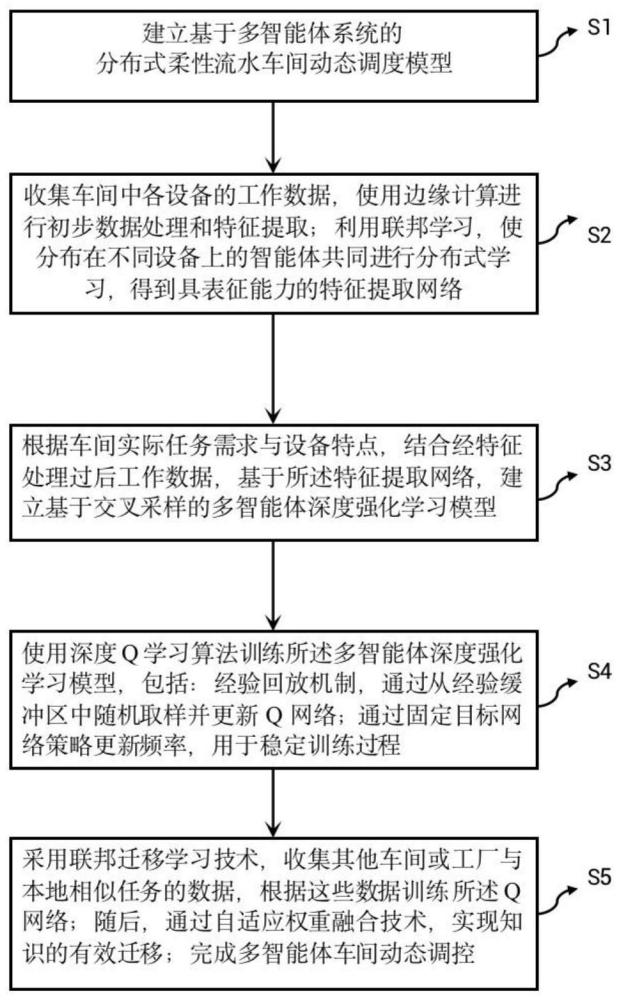
3、s1:建立基于多智能体系统的分布式柔性流水车间动态调度模型;
4、s2:收集车间中各设备的工作数据,使用边缘计算进行初步数据处理和特征提取;利用联邦学习,使分布在不同设备上的智能体共同进行分布式学习,得到具表征能力的特征提取网络;
5、s3:根据车间实际任务需求与设备特点,结合经特征处理过后工作数据,基于所述特征提取网络,建立基于交叉采样的多智能体深度强化学习模型;在所述多智能体深度强化学习模型建立过程中,定义每个智能体的状态空间s、动作空间a和状态转移函数t,并通过将步骤s1中的分布式柔性流水车间动态调度模型转化为一个优化问题来构建奖励函数r;
6、s4:使用深度q学习算法训练所述多智能体深度强化学习模型,包括:经验回放机制,通过从经验缓冲区中随机取样并更新q网络;通过固定目标网络策略更新频率,用于稳定训练过程;
7、s5:采用联邦迁移学习技术,收集其他车间或工厂与本地相似任务的数据,根据这些数据训练所述q网络;随后,通过自适应权重融合技术,实现知识的有效迁移;完成多智能体车间动态调控。
8、进一步的是,在所述步骤s1中,建立基于多智能体系统的分布式柔性流水车间动态调度模型,包括:
9、(1)建立目标函数,最小化工厂的最大完成时间;
10、(2)建立决策变量;
11、(3)约束条件:在同一时刻,相同工序只能在同一台机器上执行;
12、在同一时刻,同一台机器只能执行一道工序;
13、任何一道工序都需要加工时间;
14、任意工件在两机器间的运输时间不小于该工件在机器滞留区的放置时间;
15、每个工件在第i个工序加工完成的时间不早于第i-1个工序加工完成的时间、调运时间、以及考虑效率折损的该工序加工时间之和;
16、第h件产品的完成时间不小于每个部件的加工时间与产品装配时间之和;
17、总处理时间不低于所有产品完成时间之和;
18、工厂最大完工时间不低于总处理时间。
19、进一步的是,在所述步骤s2中,利用联邦学习,使分布在不同设备上的智能体共同进行分布式学习,得到具表征能力的特征提取网络,包括步骤:
20、s21:初始化服务器模型组件包括特征提取器t、分类器q和分布生成器g参数wt,wq和wg,以及客户端模型组件包括鉴别器d参数wd;
21、s22:将服务器模型参数下发至客户端,客户端利用本地鉴别器结合本地数据进行训练;
22、s23:完成本地训练后,客户端将参数wt,wq和wg上传至服务器,服务器聚合来自所有客户端模型参数,以获得更新参数;
23、s24:服务器将聚合后的更新参数发送给客户端,经过多轮的服务器至客户端交互后,特征提取网络得到充分训练。
24、进一步的是,在步骤s22中:将服务器模型参数下发至客户端,客户端利用本地鉴别器结合本地数据进行训练,包括步骤:
25、首先,更新参数wt,wq以达到最小化;
26、然后,更新参数wg,wd以达到最小化式。
27、进一步的是,在步骤s23中:完成本地训练后,客户端将参数wt,wq和wg上传至服务器,服务器聚合来自所有客户端模型参数,以获得新的参数,参数更新公式为:
28、
29、其中,表示t轮客户端i上传的本地参数,ωi为,x为本地数据,label为标签,ωt为服务器下发参数,t为最大训练轮次,表示客户端i训练所采用的样本数量,表示样本级损失函数,表示训练集。
30、进一步的是,在所述步骤s4中,使用深度q学习算法训练所述多智能体深度强化学习模型,包括步骤:
31、s41:初始化经验重放缓冲区随机初始化q网络参数目标网络参数获取初始状态s0;
32、s42:通过q网络计算q值,选择动作;
33、s43:对所选动作执行平均互交叉采样,利用当前状态选择最终动作;
34、s44:将上一步的历史操作数据存储到经验重放缓冲区从经验重放缓冲区中随机采样一个小批量的状态转换;
35、s45:根据优化目标,采用小批量梯度下降法对q值网络进行更新;
36、然后,更新目标网络的参数
37、最后,重复上述过程直至训练结束,从而得到适应于本地客户端任务q网络。
38、进一步的是,在步骤s42中,通过q网络计算q值,选择动作,根据下述公式选择动作:
39、
40、其中,a*是候选动作空间集,s是状态向量,是第个动作空间内的第1个候选动作,是第个动作空间内的第k个候选动作,是是第个动作空间内的第i个候选动作,{n1,...,nk}表示动作空间a*在执行不同生产任务时的动作候选集,q(·)表示q网络。
41、进一步的是,在步骤s43中,对所选动作执行平均互交叉采样,公式为:
42、
43、其中,ξ(·)表示采样运算符,为第个动作空间内的第个候选动作,为第个动作空间内的第i个候选动作,为第个动作空间内的第j个候选动作,表示交叉采样动作空间,通过在步骤s2中所获得的特征提取网络获取当前状态s;
44、然后,利用当前状态s选择最终动作,公式为:
45、
46、其中,q(a|s)表示状态为s时执行动作a的条件概率,为第个动作空间内的第1个候选动作,ak为第k个动作空间,q(·)表示q网络。
47、进一步的是,在所述步骤s5中,采用联邦迁移学习技术,通过评估客户端训练数据的质量,自适应地设置客户端网络聚合权重系数,从而实现步骤s4中q网络的知识迁移,包括步骤:
48、s51:初始化服务器模型参数并将全局模型发送至客户端;在客户端进行多轮训练后,将源客户端模型特征向量与模型参数回传至服务器;
49、s52:服务器模型参数源客户端模型特征向量以及模型参数发送至目标客户端,并获取目标客户端无标签数据的特征向量
50、s53:计算多个源客户端与目标客户端特征向量间的距离,进而利用所述距离算出自适应聚合权重系数;
51、s54:将权重系数上传至服务器,如此往复,方可训练出更具适应性的q网络。
52、进一步的是,计算多个源客户端与目标客户端特征向量间的距离,距离计算公式为:
53、
54、其中,κ<x,·>表示再生核希尔伯特空间函数;
55、进而利用所述距离算出自适应聚合权重系数;进而计算出自适应聚合权重系数为:
56、m为客户端的总数。
57、采用本技术方案的有益效果:
58、本发明通过多智能体协同工作,实现生产流程的高效、稳定和安全运行。这种技术结合了多智能体的自主决策与群体智能的优势,能够更灵活地分配生产任务,根据实时情境动态调整生产策略。采用边缘计算与联邦学习技术,有效地结合了数据隐私性与集中式学习的优势。智能体能在本地进行数据预处理并参与分布式学习,既保证了数据的安全性,又实现了跨设备的知识共享。使用基于交叉采样的dqn模型,配合经验回放与固定目标网络策略,大大提高了深度强化学习的稳定性和效率。此外,引入联邦迁移学习技术,使得该技术具有出色的可扩展性,可以轻松集成新的智能体,满足不断变化的生产需求。
59、本发明通过基于多智能体系统的分布式建模,为柔性流水车间动态调度提供了更高的灵活性与自适应性。每个智能体的独立策略-动作建模使得其能够快速适应环境变化,确保生产效率。提出了一种改进的深度q学习方法,采用了交叉采样策略,解决了智能提在大规模动作空间中的低效探索问题。设计了一种根据边端数据质量自动调节的联邦知识迁移算法。考虑到不同训练客户端之间领域差异以及数据质量差异的问题使得智能体不仅能从本地环境中学习,还能从其他车间或工厂获得知识,进一步增强了模型的泛化能力与调度效果。
- 还没有人留言评论。精彩留言会获得点赞!