一种自主导航机器人
本发明涉及移动机器人,尤其涉及一种自主导航机器人。
背景技术:
1、自主导航机器人技术在近年来得到广泛应用,涵盖了诸多领域,包括但不限于送货、清洁、巡逻等任务。这些机器人通过感知、决策和执行模块的协同工作,能够在未知或动态环境中进行智能导航和任务执行。
2、目前,自主导航机器人技术已经取得了显著的进展。感知模块常使用激光雷达、红外线、超声波、rgb-d相机等传感器,以获取环境信息和自身状态。计算模块则依赖于高性能处理器如cpu、gpu,通过深度学习算法进行智能决策。通信模块使用wi-fi、蓝牙、usb等技术,实现与其他设备或人员的数据交换。
3、例如已公开的cn 114815816a专利,该技术面向各种具有动态和静态障碍物的复杂场景设计机器人的自主导航策略,可以弥补传统路径规划方法无法躲避动态障碍物,监督式学习方法泛化能力差,强化学习方法在简单以及紧急情况下输出策略不理想的缺陷,尽管现有技术已经取得了一定的成果,但仍然存在一些挑战和不足:感知模块的局限性:传统传感器可能面临感知范围有限、精度不高等问题,限制了机器人在复杂环境中的应用。计算资源有限:在某些场景下,机器人需要在边缘设备上进行实时决策,但这些设备的计算资源有限,影响了机器人的决策效率。深度学习算法的训练样本效率低:对于深度强化学习算法,尤其是dqn算法,其在样本效率上可能不够高,需要大量的样本进行训练,增加了系统开发的成本和时间。通信安全性:在与其他设备或人员进行数据交换时,通信模块的安全性可能存在隐患,尤其是在对数据保密性要求较高的应用场景中。
技术实现思路
1、本说明书介绍了一种自主导航机器人的方案,该方案基于深度强化学习的理论和方法,利用深度q网络的算法和实现,使机器人能够在复杂的环境中自主地移动和探索,以及完成一些特定的任务,例如送货,清洁,巡逻等。
2、硬件组成
3、该方案的硬件组成主要包括以下几个部分:
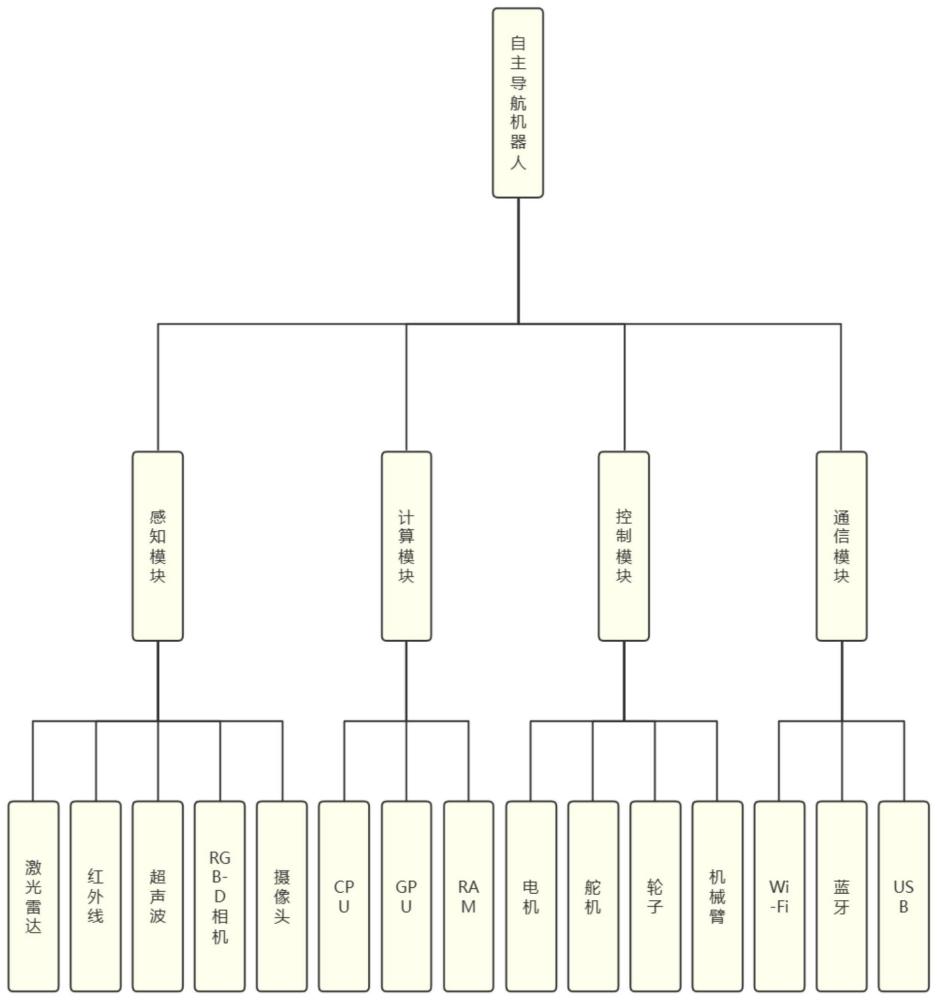
4、感知模块:感知模块是用于获取环境信息和自身状态的部分,它包括一些传感器和摄像头,例如激光雷达,红外线,超声波,rgb-d相机等,它们可以提供机器人的位置,速度,方向,以及周围的障碍物,物体,人员等的信息。
5、计算模块:计算模块是用于处理感知模块的数据,以及运行深度强化学习算法的部分,它包括一些处理器和内存,例如cpu,gpu,ram等,它们可以实现数据的预处理,特征提取,模型训练,策略生成等功能。
6、控制模块:控制模块是用于执行计算模块的指令,以及控制机器人的运动的部分,它包括一些驱动器和执行器,例如电机,舵机,轮子,机械臂等,它们可以实现机器人的前进,后退,转向,抓取,放置等动作。
7、通信模块:通信模块是用于与其他设备或人员进行数据交换的部分,它包括一些无线网络和接口,例如wi-fi,蓝牙,usb等,它们可以实现机器人的远程控制,数据传输,任务接收等功能。
8、运行逻辑结构
9、该方案的运行逻辑结构主要包括以下几个步骤:
10、初始化:初始化是指在机器人开始运行之前,进行一些必要的设置和准备的步骤,例如加载模型参数,设置探索率,清空经验池等。
11、感知:感知是指在机器人运行过程中,不断地从感知模块获取环境信息和自身状态的步骤,例如获取当前的位置,速度,方向,以及周围的障碍物,物体,人员等的信息。
12、计算:计算是指在机器人运行过程中,根据感知模块的数据,以及深度强化学习算法,生成最优的动作指令的步骤,例如根据当前的状态,使用∈-贪婪策略选择一个动作,计算目标函数和梯度,更新模型参数等。
13、控制:控制是指在机器人运行过程中,根据计算模块的指令,控制机器人的运动的步骤,例如根据当前的动作,控制机器人的前进,后退,转向,抓取,放置等动作。
14、通信:通信是指在机器人运行过程中,与其他设备或人员进行数据交换的步骤,例如接收任务,发送数据,接收反馈等。
15、反馈:反馈是指在机器人运行过程中,根据机器人的运动结果,获取相应的奖励或惩罚的步骤,例如根据机器人是否完成任务,是否碰撞,是否安全等,给予机器人正向或负向的奖励或惩罚。
16、存储:存储是指在机器人运行过程中,将机器人的转移,即状态,动作,奖励,和下一个状态的四元组,存储到经验池中的步骤,以便于后续的训练和重用。
17、重复:重复是指在机器人运行过程中,不断地循环上述的步骤,直到机器人停止运行或达到最大的迭代次数的步骤,以实现机器人的自主导航和学习。
18、公式和算法
19、该方案使用的公式和算法主要包括以下几个部分:
20、深度强化学习的原理
21、深度强化学习是一种结合了深度学习和强化学习的方法,它可以让模型通过与环境的交互来学习最优策略。深度学习是一种使用多层神经网络来进行数据表示和学习的方法,它可以处理高维数据和复杂问题。强化学习是一种让模型通过试错和奖励来学习最优行为的方法,它可以处理不确定性和动态性。深度强化学习的基本框架如下:
22、模型:模型是指在深度强化学习中,用于近似或优化某个目标函数的深度神经网络,例如值函数,策略函数,或者优势函数等,它可以根据输入的状态或动作,输出相应的值或概率。
23、环境:环境是指在深度强化学习中,与模型进行交互的外部系统,它可以根据模型的动作,输出相应的状态和奖励,它可以是真实的或者模拟的,它可以是确定的或者随机的,它可以是静态的或者动态的。
24、状态:状态是指在深度强化学习中,描述环境的当前情况的一组变量,它可以是完全的或者部分的,它可以是离散的或者连续的,它可以是低维的或者高维的,它可以是原始的或者抽象的。
25、动作:动作是指在深度强化学习中,模型在每个状态下可以采取的一种行为,它可以是离散的或者连续的,它可以是单一的或者复合的,它可以是确定的或者随机的,它可以是主动的或者被动的。
26、奖励:奖励是指在深度强化学习中,环境根据模型的动作,给予模型的一种反馈,它可以是正的或者负的,它可以是固定的或者变化的,它可以是即时的或者延迟的,它可以是稀疏的或者密集的。
27、深度q网络的算法
28、深度q网络(dqn)是一种基于值函数的深度强化学习算法,它可以用一个深度神经网络来近似q函数,即状态-动作值函数,表示在给定状态下采取某个动作的期望回报。dqn的算法流程如下:
29、初始化q网络的参数θ和目标网络的参数θ-,设置探索率∈,清空经验池d。
30、对于每个回合,执行以下步骤:
31、初始化状态s。
32、对于每个步骤,执行以下步骤:以概率∈随机选择一个动作a,以概率1-∈选择q函数最大的动作a=argmaxa′q(s,a′;θ)。
33、执行动作a,观察下一个状态s′和奖励r。
34、将转移(s,a,r,s′)存储到经验池d中。
35、从经验池d中随机抽取一个小批量的转移b=(sj,aj,rj,sj′)j=1m,其中m是小批量的大小。
36、对于每个转移(sj,aj,rj,sj′),计算目标值yj=rj+γmaxaj′q(sj′,aj′;θ-),其中γ是折扣因子。
37、计算目标函数j(θ)=m1 ∑j=1m(yj-q(sj,aj;θ))2,并使用梯度下降法或其他优化算法来更新q网络的参数其中α是学习率。
38、定期地将q网络的参数θ复制到目标网络的参数θ
39、-,以减少目标值的震荡。将状态s更新为s′。
40、定期地将探索率∈衰减,以平衡探索和利用的关系
41、本发明的有益效果:
42、1.提高机器人的工作效率:该方案可以使机器人能够在复杂的环境中自主地移动和探索,以及完成一些特定的任务,例如送货,清洁,巡逻等。这样可以提高机器人的工作效率,因为机器人不需要人类的干预和指导,可以根据环境的变化,自适应地选择最优的动作,以达到任务的目标。机器人也可以通过与环境的交互,不断地学习和优化自己的策略,以提高自己的性能和效果。相比于传统的机器人,该方案的机器人可以更快,更准确,更灵活地完成工作。
43、2.降低人力成本:该方案可以使机器人能够在复杂的环境中自主地移动和探索,以及完成一些特定的任务,例如送货,清洁,巡逻等。这样可以降低人力成本,因为机器人可以替代人类来执行一些重复性,劳累性,危险性的工作,从而节省了人力资源,降低了人力开支,减少了人力风险。机器人也可以提高人类的工作效率,因为机器人可以协助人类来完成一些辅助性,监督性,管理性的工作,从而提高了人类的工作质量和满意度。
44、3.提高服务质量和安全性:该方案可以使机器人能够在复杂的环境中自主地移动和探索,以及完成一些特定的任务,例如送货,清洁,巡逻等。这样可以提高服务质量和安全性,因为机器人可以更好地满足客户的需求,提供更优质的服务,例如机器人可以更快地送达物品,更彻底地清理区域,更有效地巡视场所等。机器人也可以更好地保障自身和他人的安全,因为机器人可以更准确地识别和回避障碍物,更稳定地控制自身的运动,更及时地报告和处理异常情况等。
- 还没有人留言评论。精彩留言会获得点赞!