辅助阅读方法和装置与流程
本发明涉及移动终端技术领域,特别是一种辅助阅读方法和装置。
背景技术:
在现今信息爆炸的阶段,高效的获取更多信息是用户迫切的需求。平板电脑、手机等移动终端的使用使新闻阅读、信息获取更加便捷,用户可以随时随地利用移动终端阅读热点信息。但是,由于不同媒体会就同一新闻事件、热点话题分别采编,且会交叉引用、互相转载,导致互联网上的相似甚至重复内容很多。
当用户使用移动终端进行互联网内容阅读时,由于文本编辑的不同,用户可能需要阅读一部分才能识别出该事件或话题已经阅读过,对于一些较为热点的内容更容易出现重复阅读的情况,极大地影响了阅读的效率。
技术实现要素:
本发明的一个目的在于提出一种帮助用户识别已经阅读过的文档、提高阅读效率的方案。
根据本发明的一个方面,提出一种辅助阅读方法,包括:获取用户当前阅读的文档;获取当前阅读的文档与用户已读文档的相似度指数;将相似度指数展示给用户,以便用户判断是否继续阅读当前阅读的文档。
可选地,获取当前阅读的文档与用户已读文档的相似度指数包括:提取当前阅读的文档的特征向量和用户已读文档的特征向量;根据用户已读文档的阅读时刻确定基于遗忘曲线的时间衰减因子,根据时间衰减因子优化用户已读文档的特征向量,获取优化已读特征向量;根据当前阅读文档的特征向量和优化已读特征向量确定当前阅读的文档与用户已读文档的相似度指数。
可选地,提取当前阅读文档的特征向量和用户已读文档的特征向量包括:提取当前阅读的文档的特征词条,基于特征词条对应的权值生成当前特征向量;获取当前阅读文档的特征词条在单篇已读文档中对应的权值,生成单文档特征向量。
根据时间衰减因子优化用户已读文档的特征向量,获取优化已读特征向量包括:根据时间衰减因子优化单文档特征向量,获取优化单文档特征向量;提取全部已读文档的优化单文档特征向量中每项特征词条对应的权值最大值,生成优化已读特征向量。
根据优化已读特征向量确定当前阅读的文档与用户已读文档的相似度指数包括:通过计算当前特征向量与优化已读特征向量的余弦值确定当前阅读的文档与用户已读文档的相似度指数。
可选地,还包括:将当前阅读的文档更新到已读文档库中。
可选地,将当前阅读的文档更新到已读文档库中包括:将当前阅读的文档的特征词条、特征词条对应的权值和用户阅读时刻保存到已读文档库中。
可选地,将当前阅读的文档更新到已读文档库中包括:判断用户在当前阅读的文档界面停留的时间是否超过阈值;若用户在当前阅读的文档界面停留的时间超过阈值,则将当前阅读的文档更新到已读文档库中。
可选地,将当前阅读的文档更新到已读文档库中包括:判断用户在当前阅读的文档界面是否执行过交互;若用户在当前阅读的文档界面执行过交互,则将当前阅读的文档更新到已读文档库中。
通过这样的方法,能够实时分析用户当前阅读的文档与已读文档库中文档的相似度指数并展示给用户,以便用户判断是否继续阅读该文档,从而避免了用户重复阅读相似的文档,提高了用户阅读的效率。
根据本发明的另一个方面,提出一种辅助阅读装置,包括:文档获取模块,用于获取用户当前阅读的文档;相似度指数获取模块,用于获取当前阅读的文档与用户已读文档的相似度指数;展示模块,用于将相似度指数展示给用户,以便用户判断是否继续阅读当前阅读的文档。
可选地,相似度指数获取模块包括:特征向量提取单元,用于提取当前阅读文档的特征向量和用户已读文档的特征向量;已读特征向量确定单元,用于根据用户已读文档的阅读时刻确定基于遗忘曲线的时间衰减因子,根据时间衰减因子优化用户已读文档的特征向量,获取优化已读特征向量;相似度指数计算单元,用于根据当前阅读文档的特征向量和优化已读特征向量确定当前阅读的文档与用户已读文档的相似度指数。
可选地,特征向量提取单元包括:当前特征向量获取子单元,用于提取当前阅读的文档的特征词条,基于特征词条对应的权值生成当前特征向量;单文档特征向量获取子单元,用于提取当前阅读的文档的特征词条在单篇已读文档中对应的权值,生成单文档特征向量。
已读特征向量确定单元包括:优化单文档特征向量获取子单元,用于根据时间衰减因子优化单文档特征向量,获取优化单文档特征向量;优化已读特征向量获取子单元,用于提取已读文档的优化单文档特征向量中每项特征词条对应的权值最大值,生成优化已读特征向量。
相似度指数计算单元用于通过计算当前特征向量与优化已读特征向量的余弦值确定当前阅读的文档与用户已读文档的相似度指数。
可选地,还包括:更新模块,用于将当前阅读文档更新到已读文档库中。
可选地,更新模块用于将当前阅读文档的特征词条、特征词条对应的权值和用户阅读时刻保存到已读文档库中。
可选地,更新模块包括:阈值判断单元,用于判断用户在当前阅读的文档界面停留的时间是否超过阈值;文档库更新单元,用于当用户在当前阅读的文档界面停留的时间超过阈值时,将当前阅读的文档更新到已读文档库中。
可选地,更新模块包括:交互判断单元,用于判断用户在当前阅读的文档界面是否执行了交互;文档库更新单元,用于当用户在当前阅读的文档界面执行了交互时,将当前阅读的文档更新到已读文档库中。
这样的装置能够实时分析用户当前阅读的文档与已读文档库中文档的相似度指数并展示给用户,以便用户判断是否继续阅读该文档,从而避免了用户重复阅读相似的文档,提高了用户阅读的效率。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1为本发明的辅助阅读方法的一个实施例的流程图。
图2为本发明的辅助阅读方法的另一个实施例的流程图。
图3为本发明的辅助阅读方法的又一个实施例的流程图。
图4为本发明的辅助阅读方法的再一个实施例的流程图。
图5为本发明的辅助阅读方法中更新已读文档库的一个实施例的流程图。
图6为本发明的辅助阅读装置的一个实施例的示意图。
图7为本发明的辅助阅读装置中相似度指数获取模块的一个实施例的示意图。
图8为本发明的辅助阅读装置中相似度指数获取模块的另一个实施例的示意图。
图9为本发明的辅助阅读装置的另一个实施例的示意图。
图10为本发明的辅助阅读装置中更新模块一个实施例的示意图。
图11为本发明的辅助阅读装置的应用场景的一个实施例的示意图。
具体实施方式
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
本发明的辅助阅读方法的一个实施例的流程图如图1所示。
在步骤101中,当用户使用阅读工具进行互联网内容阅读时,获取用户当前阅读的文档。在一个实施例中,阅读工具可以是电脑、平板电脑、手机等设备。在一个实施例中,可以通过爬取的方式获取当前阅读文档的文本内容信息,可以通过获取页面url(uniformresourcelocator,统一资源定位符)并调用爬虫工具的方式爬取文本内容,也可以通过拷贝屏幕调用ocr(opticalcharacterrecognition,光学字符识别)工具识别文字的方式爬取文本内容。
在步骤102中,根据获取的当前阅读的文档的文本内容信息获取与用户已读文档的相似度指数。在一个实施例中,可以建立用户已读文档库,基于已读文档库中的文档计算与当前阅读的文档的相似度指数。
在步骤103中,将相似度指数展示给用户。用户可以根据相似度指数迅速的判断是否需要继续阅读本文档。在一个实施例中,可以通过工具栏、通知栏或者程序间接口向用户展示相似度指数。
通过这样的方法,能够实时分析用户当前阅读的文档与已读文档库中文档的相似度指数并展示给用户,以便用户判断是否继续阅读该文档,从而避免了用户重复阅读相似的文档,提高了用户阅读的效率。
在一个实施例中,由于用户对于已阅读过的文本的记忆会随时间逐渐模糊,即使是用户已经阅读过的文档也会由于用户的遗忘具有一定的阅读价值。在计算相似度指数时,可以考虑到上次阅读时刻与当前时刻的时间间隔,将用户的遗忘特点计算在内,从而实现基于用户记忆,而并非基于数据库记忆的文档相似度指数计算。
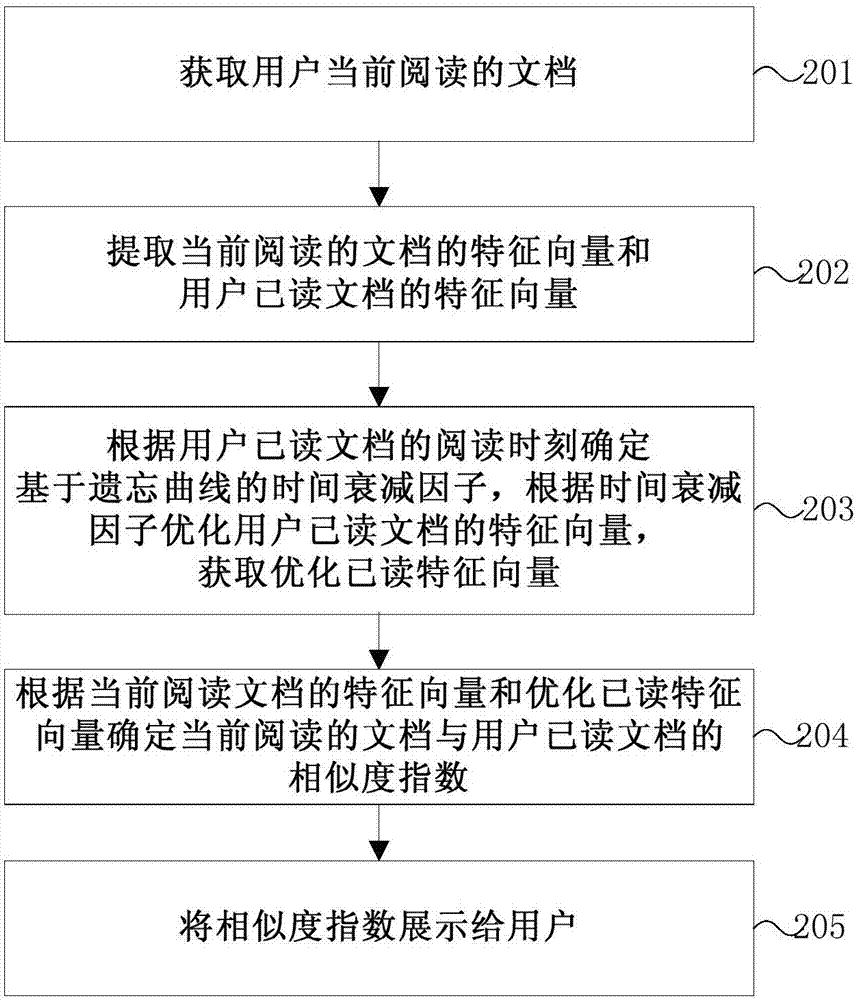
本发明的辅助阅读方法的另一个实施例的流程图如图2所示。
在步骤201中,获取用户当前阅读的文档。
在步骤202中,提取用户当前阅读的文档的特征向量和用户已读文档的特征向量。在一个实施例中,可以先提取当前阅读的文档的特征词,再分析每个特征词在当前阅读的文档中对应的权值,根据特征词及其权值生成特征向量。提取当前阅读文档的特征词在用户已读文档中的权值,生成用户已读文档的特征向量。
在步骤203中,根据用户已读文档的阅读时刻确定基于遗忘曲线的时间衰减因子。在一个实施例中,可以引入艾宾浩斯遗忘曲线计算时间衰减因子。可以根据艾宾浩斯遗忘曲线的近似拟合函数y=1-0.56x0.06计算时间衰减因子,其中,x为用户阅读信息时刻与当前时刻的时间差(单位:小时),y为经过了x小时后用户的信息记忆水平,即时间衰减因子。根据时间衰减因子分别优化已读文档的特征向量,生成优化已读特征向量。
在步骤204中,根据当前阅读文档的特征向量和优化已读特征向量确定当前阅读的文档与用户已读文档的相似度指数。
在步骤205中,将相似度指数展示给用户。用户可以根据相似度指数迅速的判断是否需要继续阅读本文档。
通过这样的方法,能够通过引入艾宾浩斯遗忘曲线确定时间衰减因子,进而优化已读文档的特征向量,从而使得计算出的相似度指数更加符合用户的记忆情况,使相似度指数的计算更加人性化,提高了用户体验。
本发明的辅助阅读方法的又一个实施例的流程图如图3所示。
在步骤301中,获取用户当前阅读的文档。
在步骤302中,提取当前阅读的文档的特征词,再分析每个特征词在当前阅读的文档中对应的权值,根据特征词及其权值生成特征向量。在一个实施例中,可以基于tf-idf(termfrequency–inversedocumentfrequency,词频-逆文本频率)规则的向量空间模型,将用户当前阅读文档d映射为一个向量v(d)=(t1,ω1(d);...;tn,ωn(d)),其中ti(i=1,2,…,n)为一系列不同的特征词条,ωi(d)为ti在d中的权值,公式可以简写为v(d)=(ω1(d),...,ωn(d))。
在步骤303中,提取当前阅读文档的特征词在单篇用户已读文档中的权值,生成单篇已读文档的单文档特征向量。
对于用户已读文档特征库的任意文档dk(k=1,2…n),根据当前阅读文档的特征词条ti确定单文档特征向量v(dk)=(t1,ω1(dk);t2,ω2(dk);……tn,ωn(dk)),简写为v(dk)=(ω1(dk);ω2(dk);……ωn(dk)),其中,k为已读文档库中的文档编号。
在步骤304中,根据单篇已读文档的阅读时刻与当前时刻的时间间隔,基于遗忘曲线的近似函数确定时间衰减因子,使用该时间衰减因子优化单文档特征向量,生成优化单文档特征向量。在一个实施例中,对单文档特征向量v(dk)引入遗忘曲线的近似函数作为调整因子进行优化,得到优化单文档特征向量:
其中,xk为用户阅读文档k的时刻与当前的时间差。
在步骤305中,提取全部已读文档的优化单文档特征向量中每个特征词条对应的权值的最大值,生成优化已读特征向量。在一个实施例中,对每个词条项,取所有m个已读文档校正后特征向量该项最大值,得到优化已读特征向量v’作为用户对已读文档整体信息掌握的定量化度量:
在步骤306中,根据当前阅读文档的特征向量和优化已读特征向量确定当前阅读的文档与用户已读文档的相似度指数。在一个实施例中,可以通过计算用户当前阅读的文档的特征向量v(d)与优化已读特征向量v’之间夹角的余弦值作为用户当前阅读文档与已读文档的相似度指数:
其中,ρ为相似度指数,已读文档库中有m篇已读文档。
在步骤307中,将相似度指数展示给用户。用户可以根据相似度指数迅速的判断是否需要继续阅读本文档。
通过这样的方法,能够计算当前阅读的文档与用户已读文档整体信息的相似度指数,相比于计算当前阅读文档与单一已读文档特征向量一对一的相似度指数计算,得到的结果更加全面准确;在计算已读文档的特征向量时采用时间遗忘因子进行优化,使得计算出的相似度指数更加符合用户的记忆情况,提高了用户体验。
在一个实施例中,可以随着用户的阅读随时更新已读文档库,从而实现对用户当前阅读文档的更准确的判断。
本发明的辅助阅读方法的再一个实施例的流程图如图4所示。
在步骤401中,获取用户当前阅读的文档。
在步骤402中,将当前阅读的文档更新到已读文档库中。在一个实施例中,可以提取当前阅读的文档的特征词条和对应的权值并存储,并不需要存储当前阅读的文档的全文,从而节省已读文档库的存储空间,也能够提高相似度指数的计算效率。在一个实施例中,还需要记录当前的阅读时刻,便于在相似度计算时基于阅读时刻计算时间衰减因子,优化相似度指数的计算结果。
通过这样的方法,随着用户的阅读随时更新已读文档库,从而保证实时的更新用户已读文档数据,保证相似度指数计算的准确性。
在一个实施例中,当用户打开一个页面后不一定会阅读该文档的内容,因此在进行已读文档库的文档更新时,可以先判断是否需要将当前界面的文档更新到已读文档库中。在一个实施例中,可以通过判断用户在当前阅读的文档界面停留的时间长度来确定是否将当前阅读的文档更新到已读文档库中。若用户在当前界面停留的时间超过了阈值,则可以认为用户阅读了该文档,将当前阅读的文档更新到已读文档库中;若用户在当前界面停留的时间不超过阈值,则可以认为用户并没有真的阅读当前文档,无需更新已读文档库。在另一个实施例中,还可以通过判断用户是否在当前界面执行过交互的方式确定是否将当前阅读的文档更新到已读文档库中。若用户在当前界面执行过交互,如发生拉动进度条、点击、输入等操作时,判断用户阅读了当前文档,将当前阅读的文档更新到已读文档库中,否则不执行已读文档库更新操作。
通过这样的方法,能够先判断用户是否阅读过当前文档后再执行已读文档库更新的操作,从而使已读文档库中存储的数据更加符合用户真实的阅读情况,进一步提高文档相似度指数计算的效果,为用户提供更加准确的相似度指数。
在一个实施例中,可以按照图5的流程图判断是否更新已读文档库。
在步骤501中,判断用户在阈值时间内在当前文档的界面是否进行了交互操作。若执行了交互操作,则执行步骤503;若未执行交互操作,则执行步骤502。
在步骤502中,判断用户在当前阅读的文档界面的停留时间是否超过了阈值。若用户在当前阅读的文档界面的停留时间超过了阈值,则执行步骤503;若用户在当前阅读的文档界面的停留时间未超过阈值,则执行步骤504。
在步骤503中,将当前阅读的文档更新到已读文档库中。在一个实施例中,可以提取当前阅读的文档的特征词条和对应的权值并存储,从而节省已读文档库的存储空间,也能够提高相似度指数的计算效率。在一个实施例中,还需要记录当前的阅读时刻,便于在相似度计算时基于阅读时刻计算时间衰减因子,优化相似度指数的计算结果。
在步骤504中,不进行已读文档库的更新操作。
通过这样的方法,能够通过两方面的判断确定是否将当前阅读的文档更新到已读文档库中,使逻辑更加严密,进一步提高已读文档库中存储的数据的准确性,提高文档相似度指数计算的效果,为用户提供更加准确的相似度指数。
在一个实施例中,用户可以通过登录相同账号,或者设备绑定的方式,采用不同的设备阅读文档,并更新已读文档库。用户使用任一设备阅读时,能够根据该用户在所有设备中已读的文档进行文档相似度指数计算,从而方便用户根据需要使用不同设备阅读文档,进一步提高用户友好度。
本发明的辅助阅读装置的一个实施例的示意图如图6所示。其中,文档获取模块61用于在用户使用阅读工具进行互联网内容阅读时获取用户当前阅读的文档。在一个实施例中,可以通过爬取电脑、平板电脑、手机等设备当前界面的方式获取当前阅读文档的文本内容信息,可以通过获取页面url并调用爬虫工具的方式爬取文本内容,也可以通过拷贝屏幕调用ocr工具识别文字的方式爬取文本内容。相似度指数获取模块62能够根据获取的当前阅读的文档的文本内容信息获取与用户已读文档的相似度指数。在一个实施例中,可以基于已读文档库中的文档计算与当前阅读的文档的相似度指数。展示模块63能够将相似度指数展示给用户,以便用户根据相似度指数迅速的判断是否需要继续阅读本文档。
这样的装置能够实时分析用户当前阅读的文档与已读文档库中文档的相似度指数并展示给用户,以便用户判断是否继续阅读该文档,从而避免了用户重复阅读相似的文档,提高了用户阅读的效率。
在一个实施例中,相似度指数获取模块可以如图7所示,包括特征向量提取单元701、已读特征向量确定单元702和相似度指数计算单元703。其中,特征向量提取单元701用于提取用户当前阅读的文档的特征向量和用户已读文档的特征向量。在一个实施例中,可以先提取当前阅读的文档的特征词,再分析每个特征词在当前阅读的文档中对应的权值,根据特征词及其权值生成特征向量。提取当前阅读文档的特征词在用户已读文档中的权值,生成用户已读文档的特征向量。已读特征向量确定单元702用于根据用户已读文档的阅读时刻确定基于遗忘曲线的时间衰减因子。在一个实施例中,可以引入艾宾浩斯遗忘曲线计算时间衰减因子。根据时间衰减因子分别优化已读文档的特征向量,生成优化已读特征向量。相似度指数计算单元703用于根据当前阅读文档的特征向量和优化已读特征向量确定当前阅读的文档与用户已读文档的相似度指数。
这样的装置能够通过引入艾宾浩斯遗忘曲线确定时间衰减因子,进而优化已读文档的特征向量,从而使得计算出的相似度指数更加符合用户的记忆情况,使相似度指数的计算更加人性化,提高了用户体验。
在一个实施例中,相似度指数获取模块可以如图8所示,其中,特征向量提取单元包括当前特征向量获取子单元811和单文档特征向量获取子单元812。当前特征向量获取子单元811用于提取当前阅读的文档的特征词,再分析每个特征词在当前阅读的文档中对应的权值,根据特征词及其权值生成特征向量;单文档特征向量获取子单元812用于提取当前阅读文档的特征词在单篇用户已读文档中的权值,生成单篇已读文档的单文档特征向量。已读特征向量确定单元包括优化单文档特征向量获取子单元821和优化已读特征向量获取子单元822,优化单文档特征向量获取子单元821能够根据单篇已读文档的阅读时刻与当前时刻的时间间隔,基于遗忘曲线的近似函数确定时间衰减因子,使用该时间衰减因子优化单文档特征向量,生成优化单文档特征向量;优化已读特征向量获取子单元822能够提取全部已读文档的优化单文档特征向量中每个特征词条对应的权值的最大值,生成优化已读特征向量。相似度指数计算单元83能够根据当前阅读文档的特征向量和优化已读特征向量确定当前阅读的文档与用户已读文档的相似度指数。
这样的装置能够计算当前阅读的文档与用户已读文档整体信息的相似度指数,相比于计算当前阅读文档与单一已读文档特征向量一对一的相似度指数,得到的结果更加全面准确;在计算已读文档的特征向量时采用时间遗忘因子进行优化,使得计算出的相似度指数更加符合用户的记忆情况,提高了用户体验。
本发明的辅助阅读装置的另一个实施例的示意图如图9所示。其中,文档获取模块91、相似度指数获取模块92和展示模块93的结构和功能与图6的实施例中相似。本发明的辅助阅读装置还包括更新模块94,能够将当前阅读的文档更新到已读文档库中。在一个实施例中,可以提取当前阅读的文档的特征词条和对应的权值并存储,无需存储当前阅读的文档的全文,从而节省已读文档库的存储空间,也能够提高相似度指数的计算效率。在一个实施例中,还需要记录当前的阅读时刻,便于在相似度计算时基于阅读时刻计算时间衰减因子,优化相似度指数的计算结果。
这样的装置能够随着用户的阅读随时更新已读文档库,从而保证实时的更新用户已读文档数据,保证相似度指数计算的准确性。
在一个实施例中,更新模块可以包括交互判断单元和文档库更新单元。其中,交互判断单元可以通过判断用户是否在当前界面执行过交互的方式确定是否将当前阅读的文档更新到已读文档库中。若交互判断单元确定用户在当前界面执行过交互,则文档库更新单元将当前阅读的文档更新到已读文档库中。在另一个实施例中,更新模块可以包括阈值判断单元和文档库更新单元,其中,阈值判断单元可以通过判断用户在当前阅读的文档界面停留的时间长度来确定是否将当前阅读的文档更新到已读文档库中。若阈值判断单元确定用户在当前界面停留的时间超过了阈值,则文档库更新单元将当前阅读的文档更新到已读文档库中。
这样的装置能够先判断用户是否阅读过当前文档后再执行已读文档库更新的操作,从而使已读文档库中存储的数据更加符合用户真实的阅读情况,进一步提高文档相似度指数计算的效果,为用户提供更加准确的相似度指数。
在一个实施例中,更新模块可以如图10所示。其中,交互判断单元1041用于判断用户在阈值时间内在当前文档的界面是否进行了交互操作,交互操作可以包括发生拉动进度条、点击、输入等操作。若用户执行了交互操作,则激活文档库更新单元1043将当前阅读的文档更新到已读文档库中。若用户未执行交互操作,则阈值判断单元1042判断用户在当前阅读的文档界面的停留时间是否超过了阈值。若用户在当前阅读的文档界面的停留时间超过了阈值,则激活文档库更新单元1043将当前阅读的文档更新到已读文档库中。
这样的装置能够通过两方面的判断确定是否将当前阅读的文档更新到已读文档库中,使逻辑更加严密,进一步提高已读文档库中存储的数据的准确性,提高文档相似度指数计算的效果,为用户提供更加准确的相似度指数。
本发明的辅助阅读装置的应用场景的一个实施例的示意图如图11所示。用户可以通过登录相同账号,或者设备绑定的方式,采用不同的设备阅读文档。辅助阅读装置1101分别与多个阅读工具建立联系并更新已读文档库。用户使用任一设备阅读时,辅助阅读装置1101能够根据该用户在所有设备中已读的文档进行文档相似度指数计算,从而方便用户根据需要使用不同设备阅读文档,进一步提高用户友好度。
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制;尽管参照较佳实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者对部分技术特征进行等同替换;而不脱离本发明技术方案的精神,其均应涵盖在本发明请求保护的技术方案范围当中。
- 还没有人留言评论。精彩留言会获得点赞!